 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Diffusion-based Image Translation using Disentangled Style and Content Representation
Sep 30, 2022

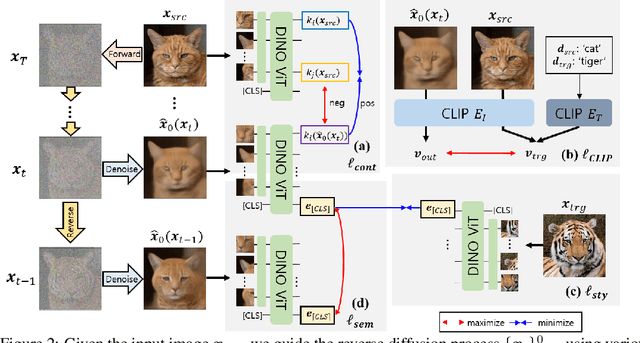
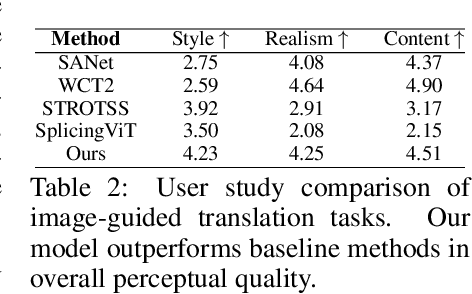

Diffusion-based image translation guided by semantic texts or a single target image has enabled flexible style transfer which is not limited to the specific domains. Unfortunately, due to the stochastic nature of diffusion models, it is often difficult to maintain the original content of the image during the reverse diffusion. To address this, here we present a novel diffusion-based unsupervised image translation method using disentangled style and content representation. Specifically, inspired by the splicing Vision Transformer, we extract intermediate keys of multihead self attention layer from ViT model and used them as the content preservation loss. Then, an image guided style transfer is performed by matching the [CLS] classification token from the denoised samples and target image, whereas additional CLIP loss is used for the text-driven style transfer. To further accelerate the semantic change during the reverse diffusion, we also propose a novel semantic divergence loss and resampling strategy. Our experimental results show that the proposed method outperforms state-of-the-art baseline models in both text-guided and image-guided translation tasks.
Transmission-Guided Bayesian Generative Model for Smoke Segmentation
Mar 02, 2023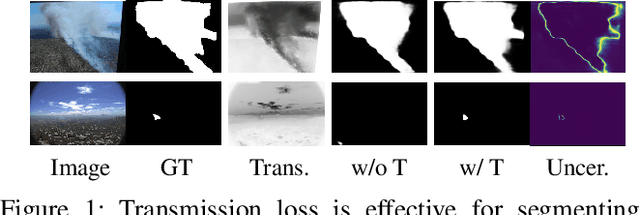

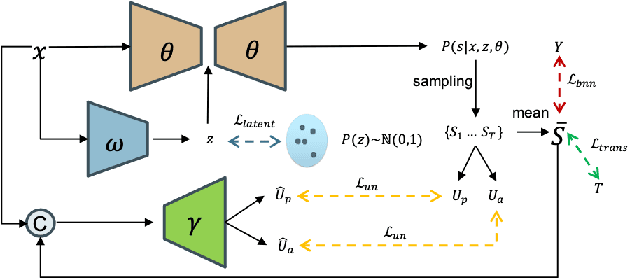

Smoke segmentation is essential to precisely localize wildfire so that it can be extinguished in an early phase. Although deep neural networks have achieved promising results on image segmentation tasks, they are prone to be overconfident for smoke segmentation due to its non-rigid shape and transparent appearance. This is caused by both knowledge level uncertainty due to limited training data for accurate smoke segmentation and labeling level uncertainty representing the difficulty in labeling ground-truth. To effectively model the two types of uncertainty, we introduce a Bayesian generative model to simultaneously estimate the posterior distribution of model parameters and its predictions. Further, smoke images suffer from low contrast and ambiguity, inspired by physics-based image dehazing methods, we design a transmission-guided local coherence loss to guide the network to learn pair-wise relationships based on pixel distance and the transmission feature. To promote the development of this field, we also contribute a high-quality smoke segmentation dataset, SMOKE5K, consisting of 1,400 real and 4,000 synthetic images with pixel-wise annotation. Experimental results on benchmark testing datasets illustrate that our model achieves both accurate predictions and reliable uncertainty maps representing model ignorance about its prediction. Our code and dataset are publicly available at: https://github.com/redlessme/Transmission-BVM.
Evaluation of drain, a deep-learning approach to rain retrieval from gpm passive microwave radiometer
Mar 02, 2023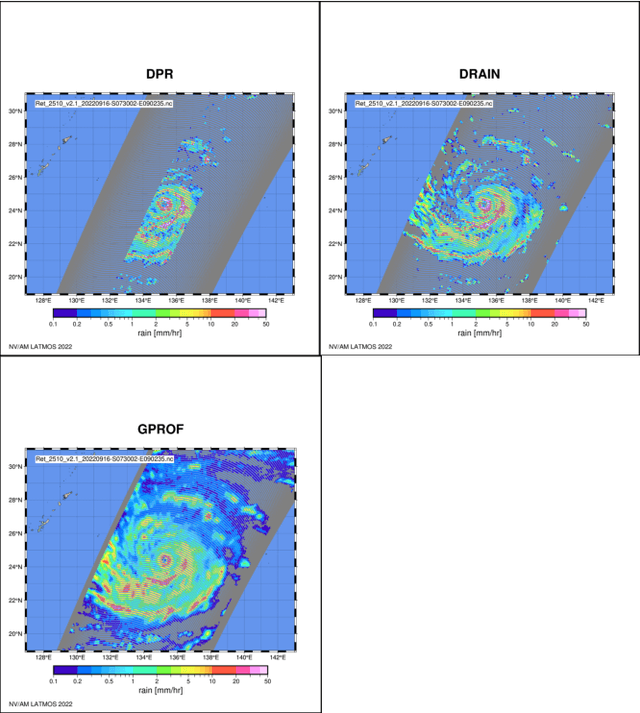
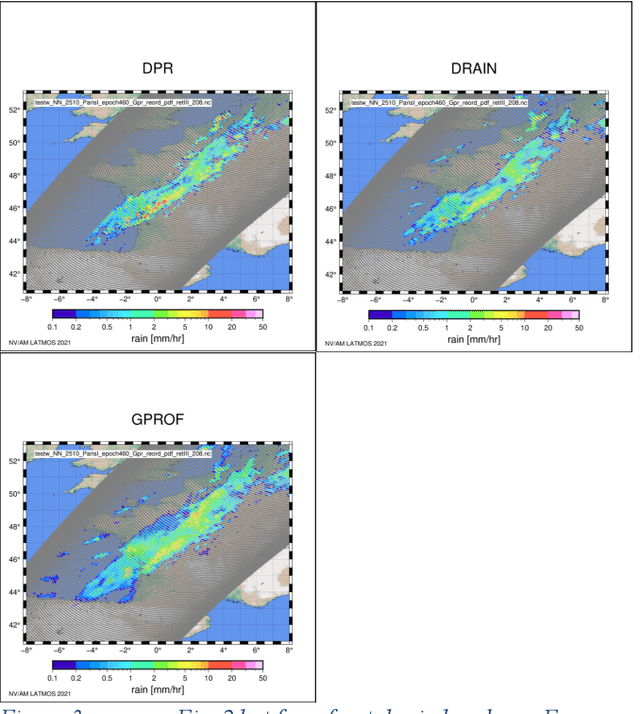
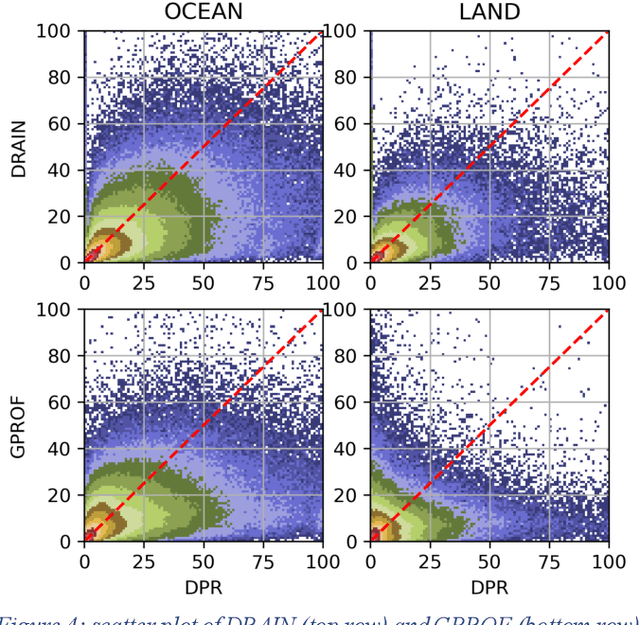
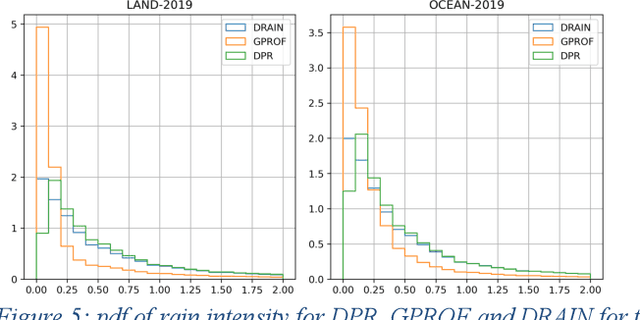
Retrieval of rain from Passive Microwave radiometers data has been a challenge ever since the launch of the first Defense Meteorological Satellite Program in the late 70s. Enormous progress has been made since the launch of the Tropical Rainfall Measuring Mission (TRMM) in 1997 but until recently the data were processed pixel-by-pixel or taking a few neighboring pixels into account. Deep learning has obtained remarkable improvement in the computer vision field, and offers a whole new way to tackle the rain retrieval problem. The Global Precipitation Measurement (GPM) Core satellite carries similarly to TRMM, a passive microwave radiometer and a radar that share part of their swath. The brightness temperatures measured in the 37 and 89 GHz channels are used like the RGB components of a regular image while rain rate from Dual Frequency radar provides the surface rain. A U-net is then trained on these data to develop a retrieval algorithm: Deep-learning RAIN (DRAIN). With only four brightness temperatures as an input and no other a priori information, DRAIN is offering similar or slightly better performances than GPROF, the GPM official algorithm, in most situations. These performances are assumed to be due to the fact that DRAIN works on an image basis instead of the classical pixel-by-pixel basis.
A study on the invariance in security whatever the dimension of images for the steganalysis by deep-learning
Feb 22, 2023

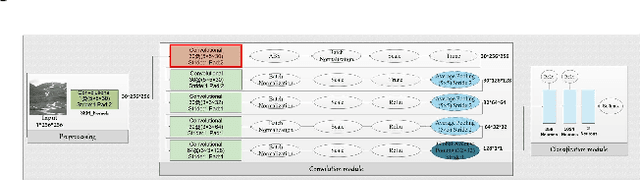
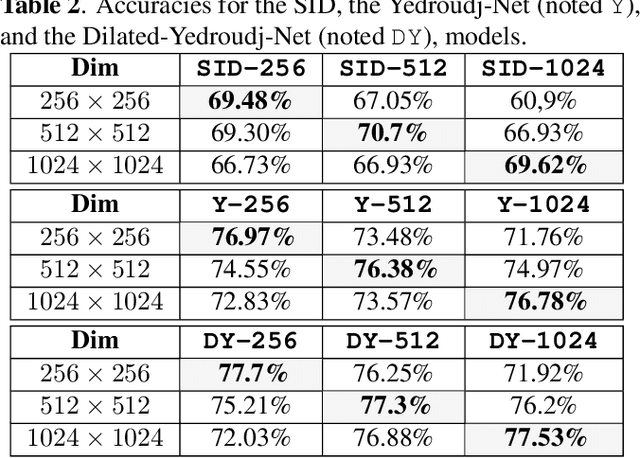
In this paper, we study the performance invariance of convolutional neural networks when confronted with variable image sizes in the context of a more "wild steganalysis". First, we propose two algorithms and definitions for a fine experimental protocol with datasets owning "similar difficulty" and "similar security". The "smart crop 2" algorithm allows the introduction of the Nearly Nested Image Datasets (NNID) that ensure "a similar difficulty" between various datasets, and a dichotomous research algorithm allows a "similar security". Second, we show that invariance does not exist in state-of-the-art architectures. We also exhibit a difference in behavior depending on whether we test on images larger or smaller than the training images. Finally, based on the experiments, we propose to use the dilated convolution which leads to an improvement of a state-of-the-art architecture.
Identification of Novel Classes for Improving Few-Shot Object Detection
Mar 18, 2023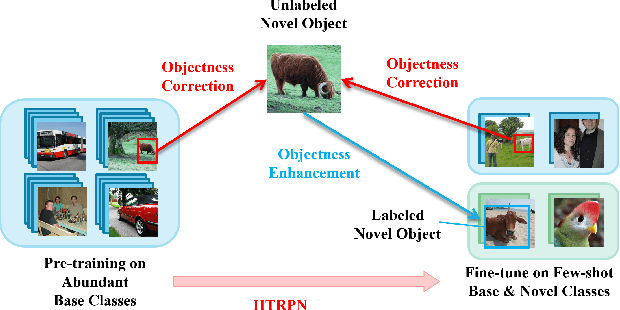
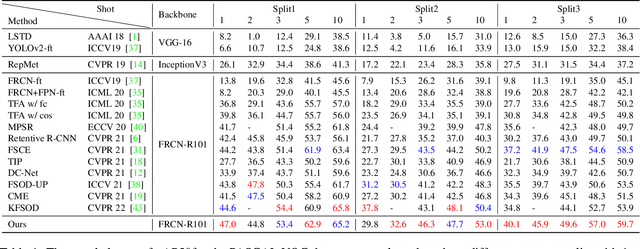

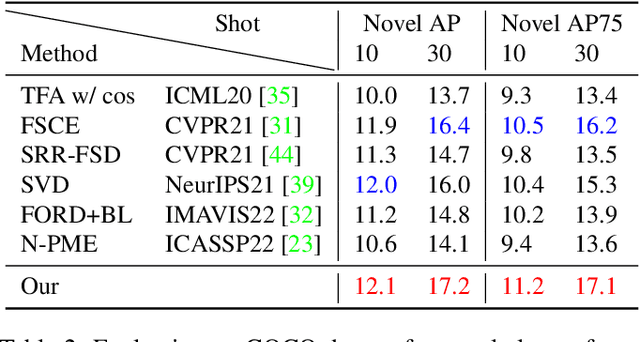
Conventional training of deep neural networks requires a large number of the annotated image which is a laborious and time-consuming task, particularly for rare objects. Few-shot object detection (FSOD) methods offer a remedy by realizing robust object detection using only a few training samples per class. An unexplored challenge for FSOD is that instances from unlabeled novel classes that do not belong to the fixed set of training classes appear in the background. These objects behave similarly to label noise, leading to FSOD performance degradation. We develop a semi-supervised algorithm to detect and then utilize these unlabeled novel objects as positive samples during training to improve FSOD performance. Specifically, we propose a hierarchical ternary classification region proposal network (HTRPN) to localize the potential unlabeled novel objects and assign them new objectness labels. Our improved hierarchical sampling strategy for the region proposal network (RPN) also boosts the perception ability of the object detection model for large objects. Our experimental results indicate that our method is effective and outperforms the existing state-of-the-art (SOTA) FSOD methods.
ElegantSeg: End-to-End Holistic Learning for Extra-Large Image Semantic Segmentation
Nov 21, 2022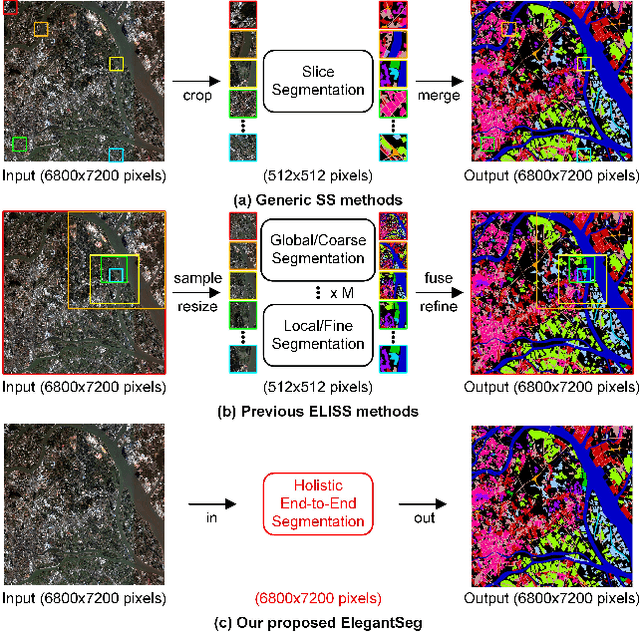
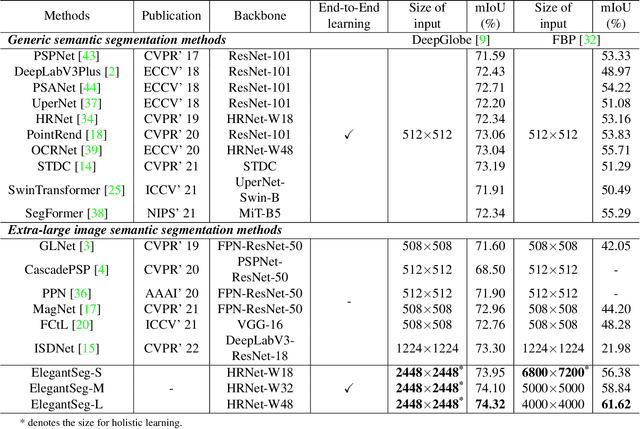


This paper presents a new paradigm for Extra-large image semantic Segmentation, called ElegantSeg, that capably processes holistic extra-large image semantic segmentation (ELISS). The extremely large sizes of extra-large images (ELIs) tend to cause GPU memory exhaustion. To tackle this issue, prevailing works either follow the global-local fusion pipeline or conduct the multi-stage refinement. These methods can only process limited information at one time, and they are not able to thoroughly exploit the abundant information in ELIs. Unlike previous methods, ElegantSeg can elegantly process holistic ELISS by extending the tensor storage from GPU memory to host memory. To the best of our knowledge, it is the first time that ELISS can be performed holistically. Besides, ElegantSeg is specifically designed with three modules to utilize the characteristics of ELIs, including the multiple large kernel module for developing long-range dependency, the efficient class relation module for building holistic contextual relationships, and the boundary-aware enhancement module for obtaining complete object boundaries. ElegantSeg outperforms previous state-of-the-art on two typical ELISS datasets. We hope that ElegantSeg can open a new perspective for ELISS. The code and models will be made publicly available.
Development of A Real-time POCUS Image Quality Assessment and Acquisition Guidance System
Dec 19, 2022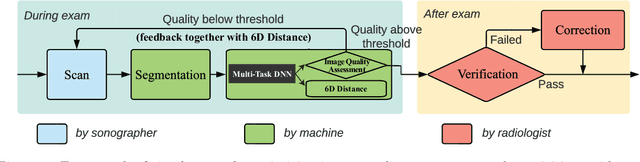
Point-of-care ultrasound (POCUS) is one of the most commonly applied tools for cardiac function imaging in the clinical routine of the emergency department and pediatric intensive care unit. The prior studies demonstrate that AI-assisted software can guide nurses or novices without prior sonography experience to acquire POCUS by recognizing the interest region, assessing image quality, and providing instructions. However, these AI algorithms cannot simply replace the role of skilled sonographers in acquiring diagnostic-quality POCUS. Unlike chest X-ray, CT, and MRI, which have standardized imaging protocols, POCUS can be acquired with high inter-observer variability. Though being with variability, they are usually all clinically acceptable and interpretable. In challenging clinical environments, sonographers employ novel heuristics to acquire POCUS in complex scenarios. To help novice learners to expedite the training process while reducing the dependency on experienced sonographers in the curriculum implementation, We will develop a framework to perform real-time AI-assisted quality assessment and probe position guidance to provide training process for novice learners with less manual intervention.
See Blue Sky: Deep Image Dehaze Using Paired and Unpaired Training Images
Oct 14, 2022
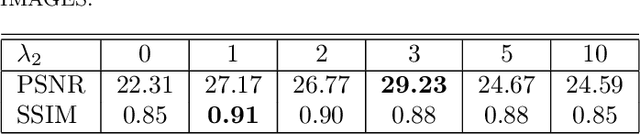
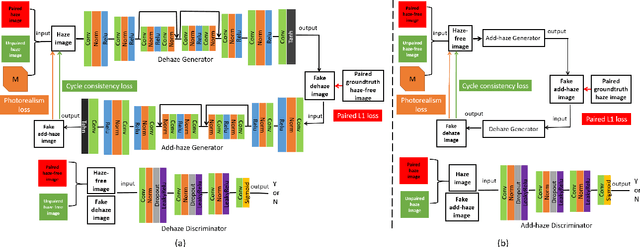
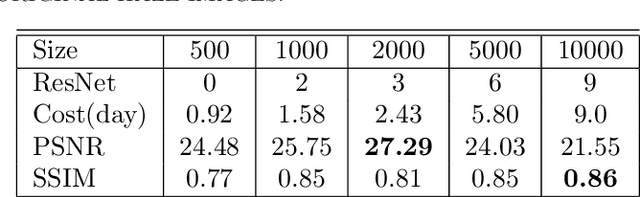
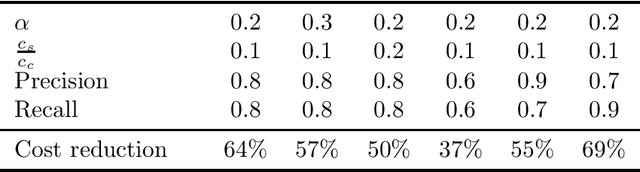
The issue of image haze removal has attracted wide attention in recent years. However, most existing haze removal methods cannot restore the scene with clear blue sky, since the color and texture information of the object in the original haze image is insufficient. To remedy this, we propose a cycle generative adversarial network to construct a novel end-to-end image dehaze model. We adopt outdoor image datasets to train our model, which includes a set of real-world unpaired image dataset and a set of paired image dataset to ensure that the generated images are close to the real scene. Based on the cycle structure, our model adds four different kinds of loss function to constrain the effect including adversarial loss, cycle consistency loss, photorealism loss and paired L1 loss. These four constraints can improve the overall quality of such degraded images for better visual appeal and ensure reconstruction of images to keep from distortion. The proposed model could remove the haze of images and also restore the sky of images to be clean and blue (like captured in a sunny weather).
Natural Scene Image Annotation Using Local Semantic Concepts and Spatial Bag of Visual Words
Oct 17, 2022
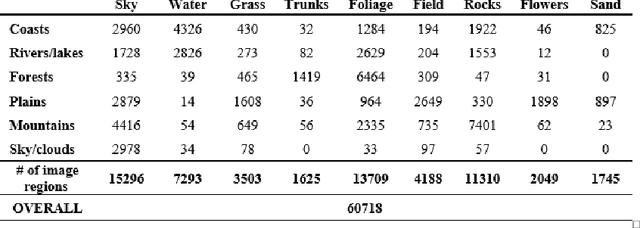
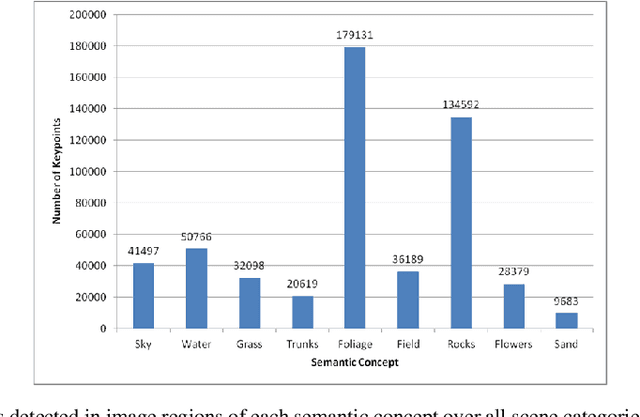
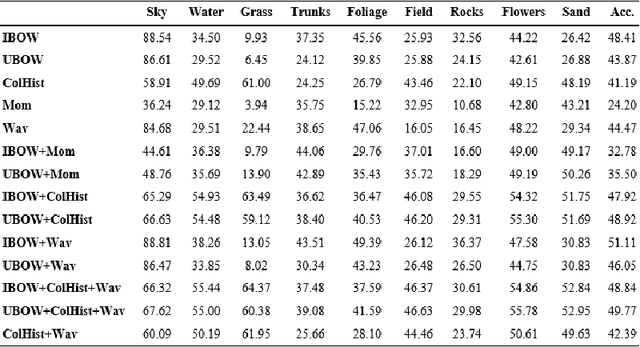
The use of bag of visual words (BOW) model for modelling images based on local invariant features computed at interest point locations has become a standard choice for many computer vision tasks. Visual vocabularies generated from image feature vectors are expected to produce visual words that are discriminative to improve the performance of image annotation systems. Most techniques that adopt the BOW model in annotating images declined favorable information that can be mined from image categories to build discriminative visual vocabularies. To this end, this paper introduces a detailed framework for automatically annotating natural scene images with local semantic labels from a predefined vocabulary. The framework is based on a hypothesis that assumes that, in natural scenes, intermediate semantic concepts are correlated with the local keypoints. Based on this hypothesis, image regions can be efficiently represented by BOW model and using a machine learning approach, such as SVM, to label image regions with semantic annotations. Another objective of this paper is to address the implications of generating visual vocabularies from image halves, instead of producing them from the whole image, on the performance of annotating image regions with semantic labels. All BOW-based approaches as well as baseline methods have been extensively evaluated on 6-categories dataset of natural scenes using the SVM and KNN classifiers. The reported results have shown the plausibility of using the BOW model to represent the semantic information of image regions and thus to automatically annotate image regions with labels.
Lightweight Estimation of Hand Mesh and Biomechanically Feasible Kinematic Parameters
Mar 26, 2023


3D hand pose estimation is a long-standing challenge in both robotics and computer vision communities due to its implicit depth ambiguity and often strong self-occlusion. Recently, in addition to the hand skeleton, jointly estimating hand pose and shape has gained more attraction. State-of-the-art methods adopt a model-free approach, estimating the vertices of the hand mesh directly and providing superior accuracy compared to traditional model-based methods directly regressing the parameters of the parametric hand mesh. However, with the large number of mesh vertices to estimate, these methods are often slow in inference. We propose an efficient variation of the previously proposed image-to-lixel approach to efficiently estimate hand meshes from the images. Leveraging recent developments in efficient neural architectures, we significantly reduce the computation complexity without sacrificing the estimation accuracy. Furthermore, we introduce an inverted kinematic(IK) network to translate the estimated hand mesh to a biomechanically feasible set of joint rotation parameters, which is necessary for applications that leverage pose estimation for controlling robotic hands. Finally, an optional post-processing module is proposed to refine the rotation and shape parameters to compensate for the error introduced by the IK net. Our Lite I2L Mesh Net achieves state-of-the-art joint and mesh estimation accuracy with less than $13\%$ of the total computational complexity of the original I2L hand mesh estimator. Adding the IK net and post-optimization modules can improve the accuracy slightly at a small computation cost, but more importantly, provide the kinematic parameters required for robotic applications.