 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Visual Prompting via Image Inpainting
Sep 01, 2022
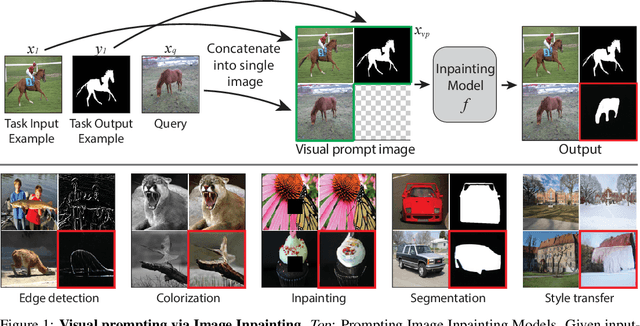
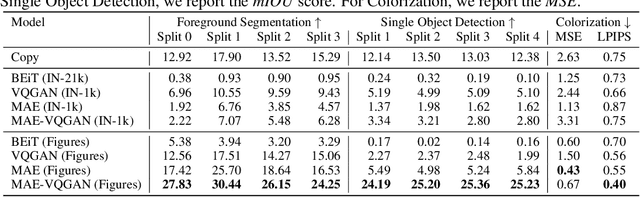
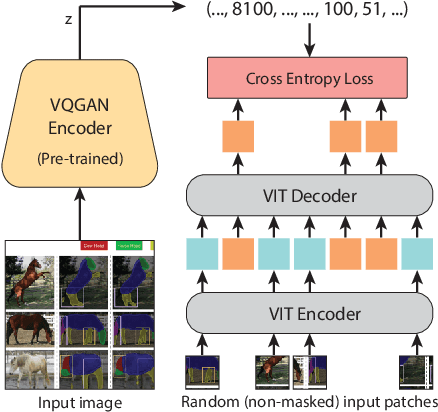
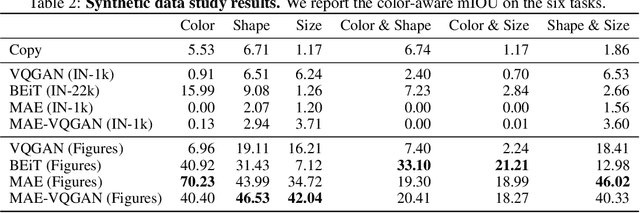
How does one adapt a pre-trained visual model to novel downstream tasks without task-specific finetuning or any model modification? Inspired by prompting in NLP, this paper investigates visual prompting: given input-output image example(s) of a new task at test time and a new input image, the goal is to automatically produce the output image, consistent with the given examples. We show that posing this problem as simple image inpainting - literally just filling in a hole in a concatenated visual prompt image - turns out to be surprisingly effective, provided that the inpainting algorithm has been trained on the right data. We train masked auto-encoders on a new dataset that we curated - 88k unlabeled figures from academic papers sources on Arxiv. We apply visual prompting to these pretrained models and demonstrate results on various downstream image-to-image tasks, including foreground segmentation, single object detection, colorization, edge detection, etc.
A study on the use of perceptual hashing to detect manipulation of embedded messages in images
Feb 28, 2023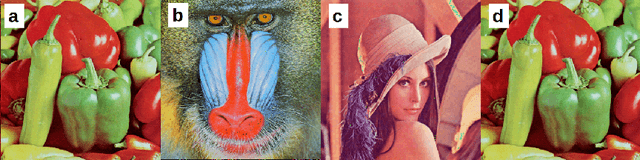
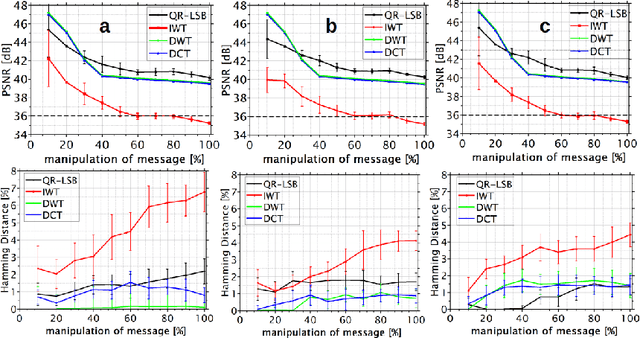
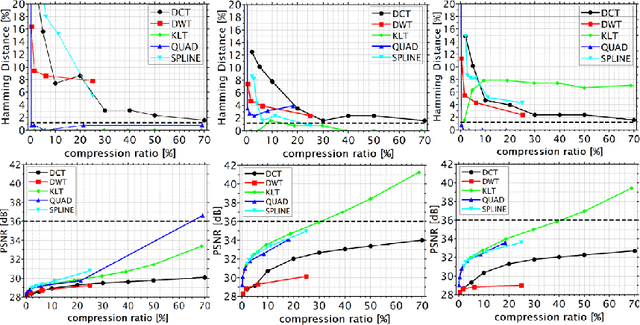
Typically, metadata of images are stored in a specific data segment of the image file. However, to securely detect changes, data can also be embedded within images. This follows the goal to invisibly and robustly embed as much information as possible to, ideally, even survive compression. This work searches for embedding principles which allow to distinguish between unintended changes by lossy image compression and malicious manipulation of the embedded message based on the change of its perceptual or robust hash. Different embedding and compression algorithms are compared. The study shows that embedding a message via integer wavelet transform and compression with Karhunen-Loeve-transform yields the best results. However, it was not possible to distinguish between manipulation and compression in all cases.
3D Human Pose Estimation via Intuitive Physics
Mar 31, 2023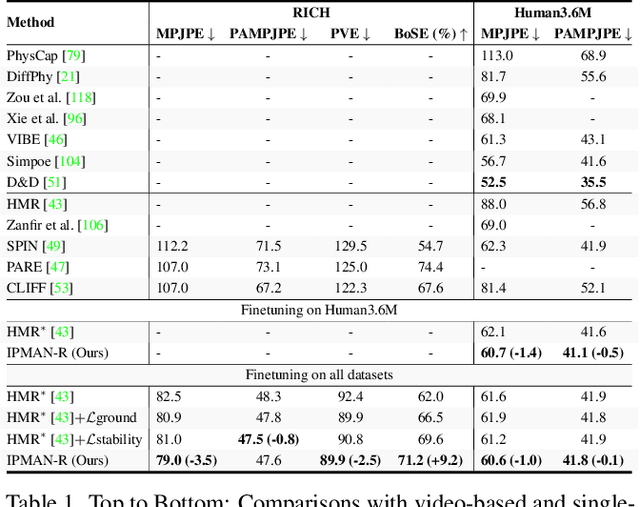
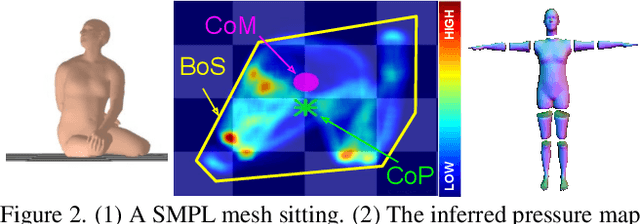
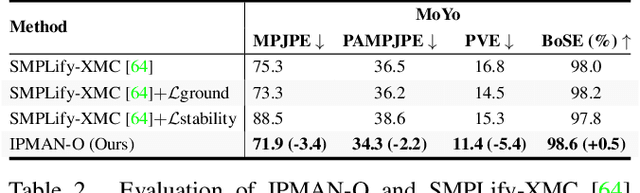
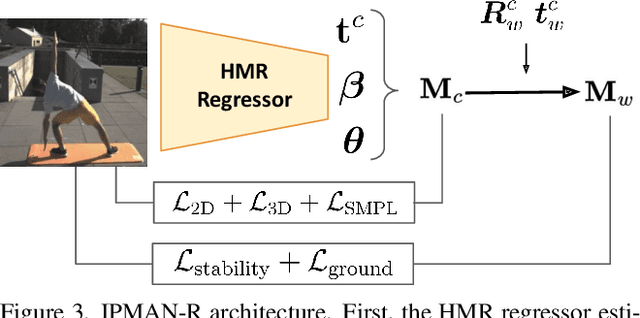
Estimating 3D humans from images often produces implausible bodies that lean, float, or penetrate the floor. Such methods ignore the fact that bodies are typically supported by the scene. A physics engine can be used to enforce physical plausibility, but these are not differentiable, rely on unrealistic proxy bodies, and are difficult to integrate into existing optimization and learning frameworks. In contrast, we exploit novel intuitive-physics (IP) terms that can be inferred from a 3D SMPL body interacting with the scene. Inspired by biomechanics, we infer the pressure heatmap on the body, the Center of Pressure (CoP) from the heatmap, and the SMPL body's Center of Mass (CoM). With these, we develop IPMAN, to estimate a 3D body from a color image in a "stable" configuration by encouraging plausible floor contact and overlapping CoP and CoM. Our IP terms are intuitive, easy to implement, fast to compute, differentiable, and can be integrated into existing optimization and regression methods. We evaluate IPMAN on standard datasets and MoYo, a new dataset with synchronized multi-view images, ground-truth 3D bodies with complex poses, body-floor contact, CoM and pressure. IPMAN produces more plausible results than the state of the art, improving accuracy for static poses, while not hurting dynamic ones. Code and data are available for research at https://ipman.is.tue.mpg.de.
Understanding and Constructing Latent Modality Structures in Multi-modal Representation Learning
Mar 10, 2023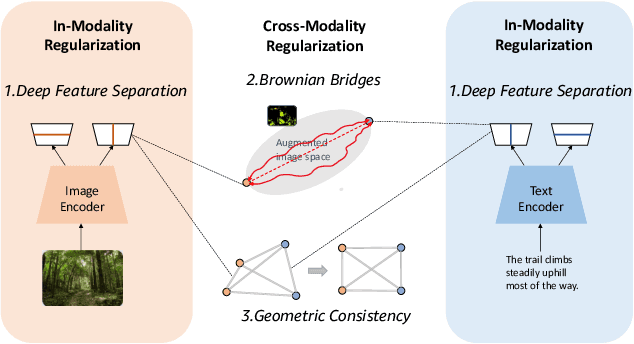


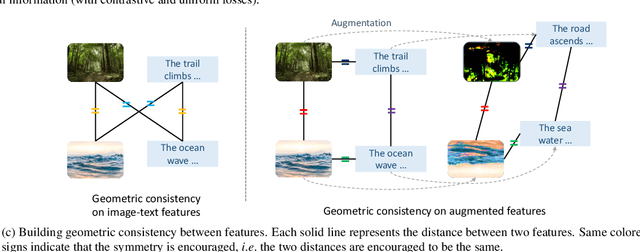
Contrastive loss has been increasingly used in learning representations from multiple modalities. In the limit, the nature of the contrastive loss encourages modalities to exactly match each other in the latent space. Yet it remains an open question how the modality alignment affects the downstream task performance. In this paper, based on an information-theoretic argument, we first prove that exact modality alignment is sub-optimal in general for downstream prediction tasks. Hence we advocate that the key of better performance lies in meaningful latent modality structures instead of perfect modality alignment. To this end, we propose three general approaches to construct latent modality structures. Specifically, we design 1) a deep feature separation loss for intra-modality regularization; 2) a Brownian-bridge loss for inter-modality regularization; and 3) a geometric consistency loss for both intra- and inter-modality regularization. Extensive experiments are conducted on two popular multi-modal representation learning frameworks: the CLIP-based two-tower model and the ALBEF-based fusion model. We test our model on a variety of tasks including zero/few-shot image classification, image-text retrieval, visual question answering, visual reasoning, and visual entailment. Our method achieves consistent improvements over existing methods, demonstrating the effectiveness and generalizability of our proposed approach on latent modality structure regularization.
Diffusion-based Document Layout Generation
Mar 19, 2023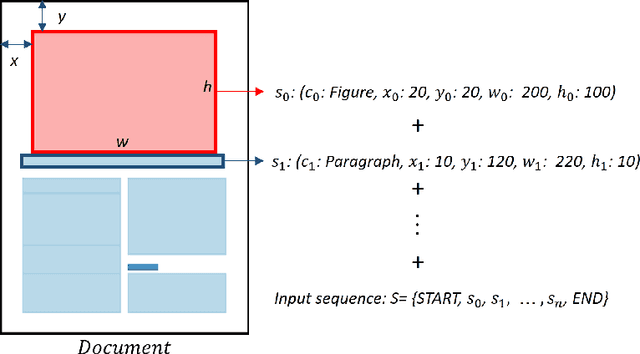
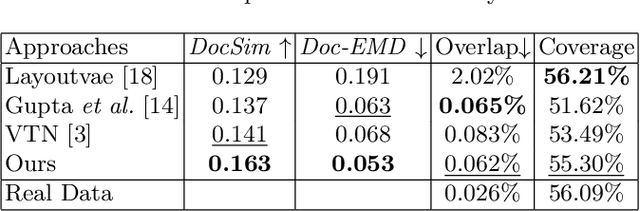

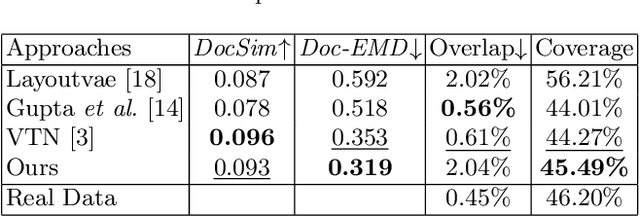
We develop a diffusion-based approach for various document layout sequence generation. Layout sequences specify the contents of a document design in an explicit format. Our novel diffusion-based approach works in the sequence domain rather than the image domain in order to permit more complex and realistic layouts. We also introduce a new metric, Document Earth Mover's Distance (Doc-EMD). By considering similarity between heterogeneous categories document designs, we handle the shortcomings of prior document metrics that only evaluate the same category of layouts. Our empirical analysis shows that our diffusion-based approach is comparable to or outperforming other previous methods for layout generation across various document datasets. Moreover, our metric is capable of differentiating documents better than previous metrics for specific cases.
Active Learning Enhances Classification of Histopathology Whole Slide Images with Attention-based Multiple Instance Learning
Mar 02, 2023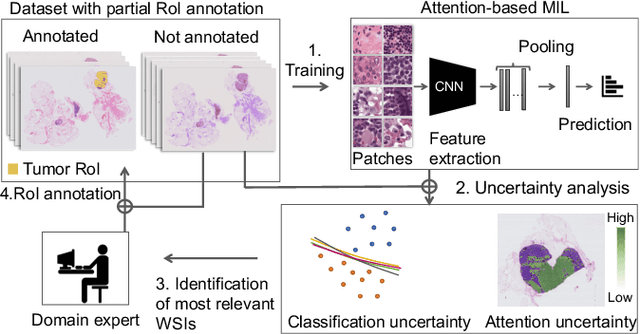
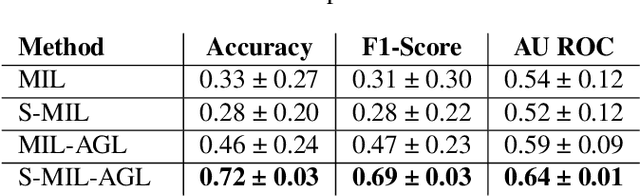
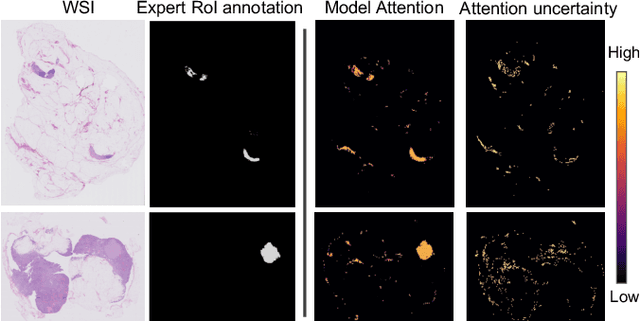
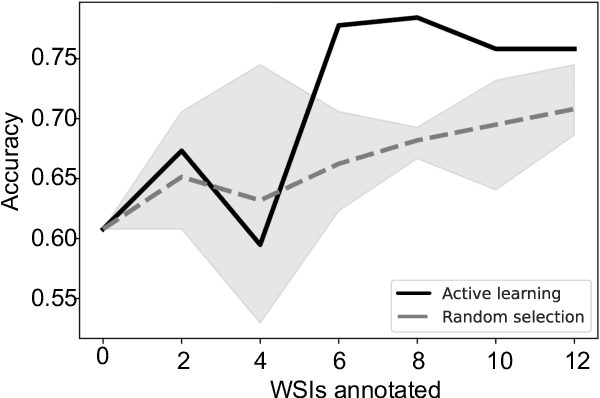
In many histopathology tasks, sample classification depends on morphological details in tissue or single cells that are only visible at the highest magnification. For a pathologist, this implies tedious zooming in and out, while for a computational decision support algorithm, it leads to the analysis of a huge number of small image patches per whole slide image (WSI). Attention-based multiple instance learning (MIL), where attention estimation is learned in a weakly supervised manner, has been successfully applied in computational histopathology, but it is challenged by large numbers of irrelevant patches, reducing its accuracy. Here, we present an active learning approach to the problem. Querying the expert to annotate regions of interest in a WSI guides the formation of high-attention regions for MIL. We train an attention-based MIL and calculate a confidence metric for every image in the dataset to select the most uncertain WSIs for expert annotation. We test our approach on the CAMELYON17 dataset classifying metastatic lymph node sections in breast cancer. With a novel attention guiding loss, this leads to an accuracy boost of the trained models with few regions annotated for each class. Active learning thus improves WSIs classification accuracy, leads to faster and more robust convergence, and speeds up the annotation process. It may in the future serve as an important contribution to train MIL models in the clinically relevant context of cancer classification in histopathology.
CoreDiff: Contextual Error-Modulated Generalized Diffusion Model for Low-Dose CT Denoising and Generalization
Apr 04, 2023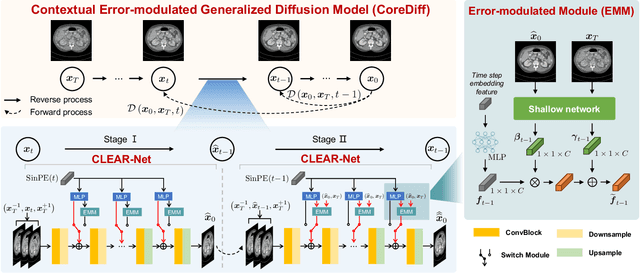
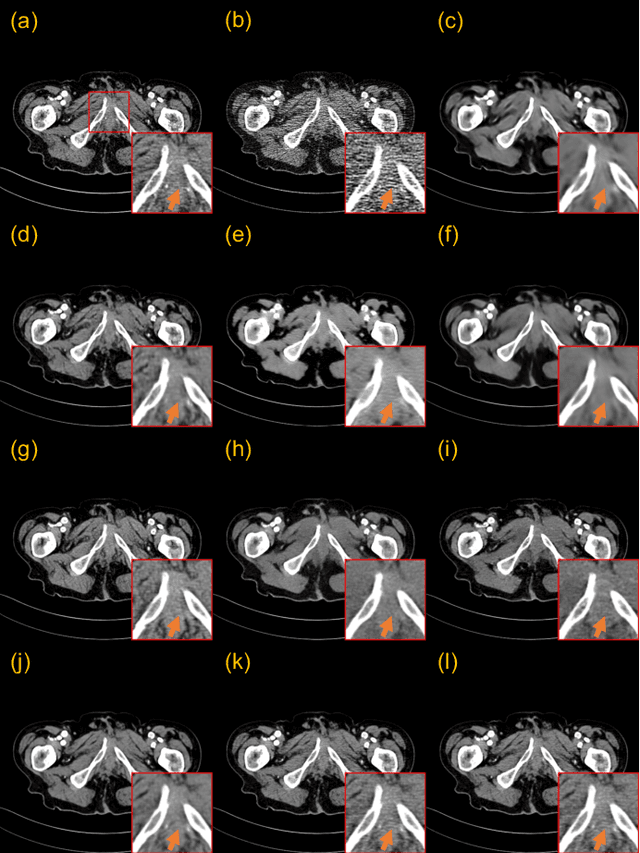
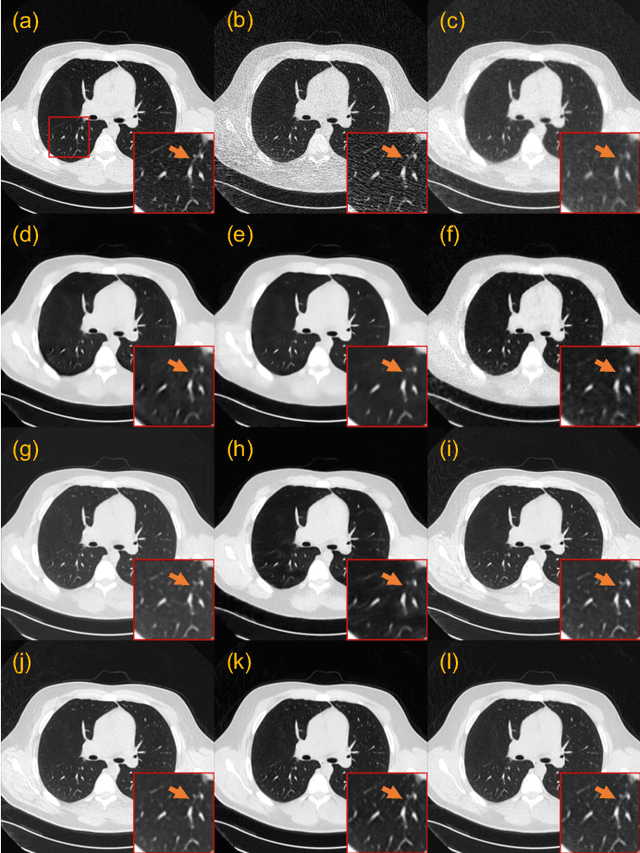

Low-dose computed tomography (CT) images suffer from noise and artifacts due to photon starvation and electronic noise. Recently, some works have attempted to use diffusion models to address the over-smoothness and training instability encountered by previous deep-learning-based denoising models. However, diffusion models suffer from long inference times due to the large number of sampling steps involved. Very recently, cold diffusion model generalizes classical diffusion models and has greater flexibility. Inspired by the cold diffusion, this paper presents a novel COntextual eRror-modulated gEneralized Diffusion model for low-dose CT (LDCT) denoising, termed CoreDiff. First, CoreDiff utilizes LDCT images to displace the random Gaussian noise and employs a novel mean-preserving degradation operator to mimic the physical process of CT degradation, significantly reducing sampling steps thanks to the informative LDCT images as the starting point of the sampling process. Second, to alleviate the error accumulation problem caused by the imperfect restoration operator in the sampling process, we propose a novel ContextuaL Error-modulAted Restoration Network (CLEAR-Net), which can leverage contextual information to constrain the sampling process from structural distortion and modulate time step embedding features for better alignment with the input at the next time step. Third, to rapidly generalize to a new, unseen dose level with as few resources as possible, we devise a one-shot learning framework to make CoreDiff generalize faster and better using only a single LDCT image (un)paired with NDCT. Extensive experimental results on two datasets demonstrate that our CoreDiff outperforms competing methods in denoising and generalization performance, with a clinically acceptable inference time.
OCR-VQGAN: Taming Text-within-Image Generation
Oct 19, 2022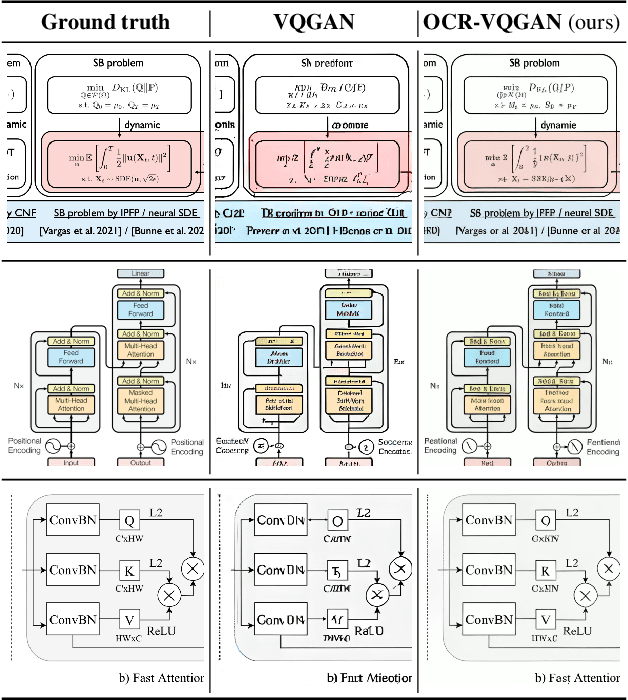
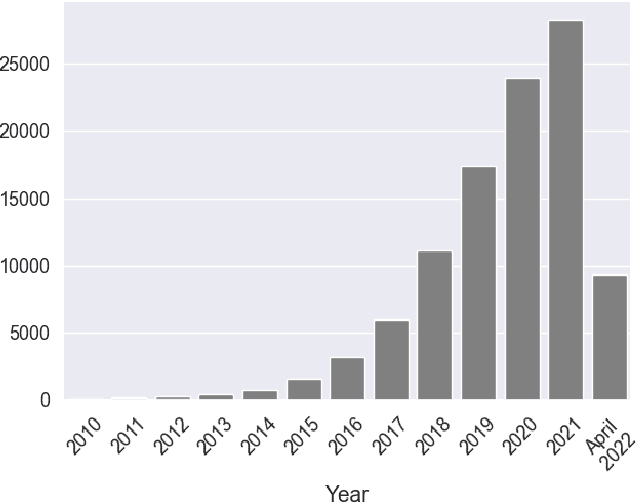
Synthetic image generation has recently experienced significant improvements in domains such as natural image or art generation. However, the problem of figure and diagram generation remains unexplored. A challenging aspect of generating figures and diagrams is effectively rendering readable texts within the images. To alleviate this problem, we present OCR-VQGAN, an image encoder, and decoder that leverages OCR pre-trained features to optimize a text perceptual loss, encouraging the architecture to preserve high-fidelity text and diagram structure. To explore our approach, we introduce the Paper2Fig100k dataset, with over 100k images of figures and texts from research papers. The figures show architecture diagrams and methodologies of articles available at arXiv.org from fields like artificial intelligence and computer vision. Figures usually include text and discrete objects, e.g., boxes in a diagram, with lines and arrows that connect them. We demonstrate the effectiveness of OCR-VQGAN by conducting several experiments on the task of figure reconstruction. Additionally, we explore the qualitative and quantitative impact of weighting different perceptual metrics in the overall loss function. We release code, models, and dataset at https://github.com/joanrod/ocr-vqgan.
Progressive Denoising Model for Fine-Grained Text-to-Image Generation
Oct 05, 2022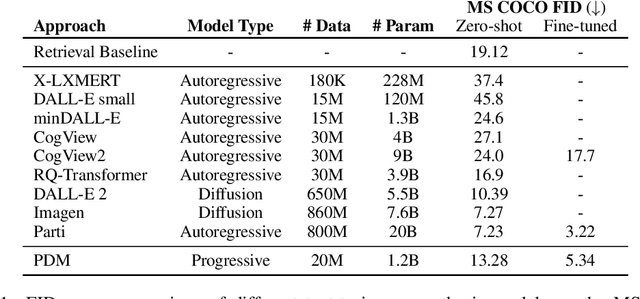

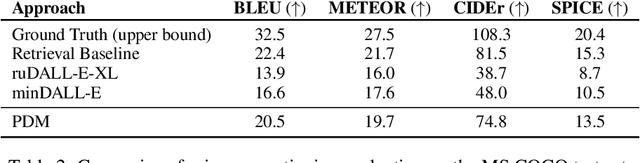
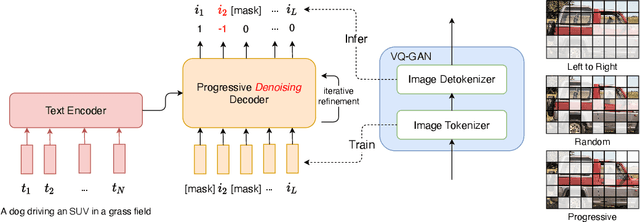
Recently, vector quantized autoregressive (VQ-AR) models have shown remarkable results in text-to-image synthesis by equally predicting discrete image tokens from the top left to bottom right in the latent space. Although the simple generative process surprisingly works well, is this the best way to generate the image? For instance, human creation is more inclined to the outline-to-fine of an image, while VQ-AR models themselves do not consider any relative importance of each component. In this paper, we present a progressive denoising model for high-fidelity text-to-image image generation. The proposed method takes effect by creating new image tokens from coarse to fine based on the existing context in a parallel manner and this procedure is recursively applied until an image sequence is completed. The resulting coarse-to-fine hierarchy makes the image generation process intuitive and interpretable. Extensive experiments demonstrate that the progressive model produces significantly better results when compared with the previous VQ-AR method in FID score across a wide variety of categories and aspects. Moreover, the text-to-image generation time of traditional AR increases linearly with the output image resolution and hence is quite time-consuming even for normal-size images. In contrast, our approach allows achieving a better trade-off between generation quality and speed.
Feature-based Adaptive Contrastive Distillation for Efficient Single Image Super-Resolution
Nov 29, 2022
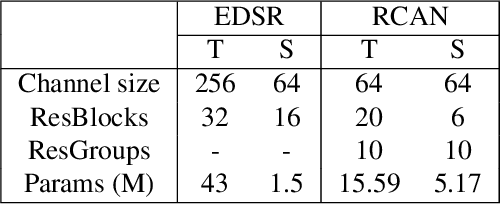

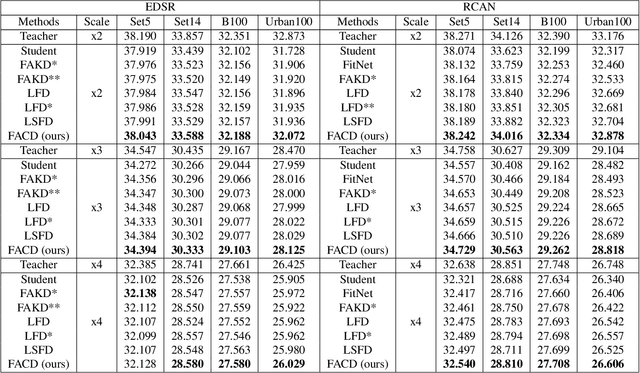
Convolution Neural Networks (CNNs) have been used in various fields and are showing demonstrated excellent performance, especially in Single-Image Super Resolution (SISR). However, recently, CNN-based SISR has numerous parameters and computational costs for obtaining better performance. As one of the methods to make the network efficient, Knowledge Distillation (KD) which optimizes the performance trade-off by adding a loss term to the existing network architecture is currently being studied. KD for SISR is mainly proposed as a feature distillation (FD) to minimize L1-distance loss of feature maps between teacher and student networks, but it does not fully take into account the amount and importance of information that the student can accept. In this paper, we propose a feature-based adaptive contrastive distillation (FACD) method for efficiently training lightweight SISR networks. We show the limitations of the existing feature-distillation (FD) with L1-distance loss, and propose a feature-based contrastive loss that maximizes the mutual information between the feature maps of the teacher and student networks. The experimental results show that the proposed FACD improves not only the PSNR performance of the entire benchmark datasets and scales but also the subjective image quality compared to the conventional FD approach.