 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Generative Enhancement for 3D Medical Images
Mar 19, 2024
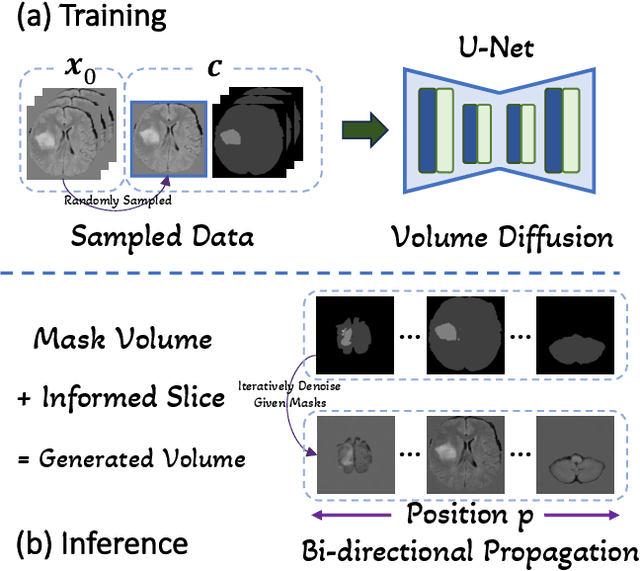
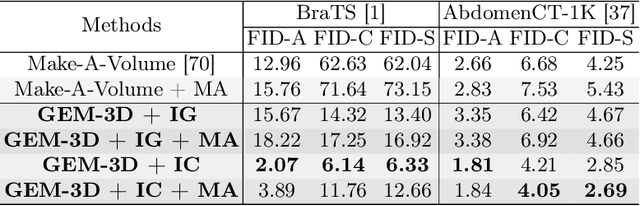
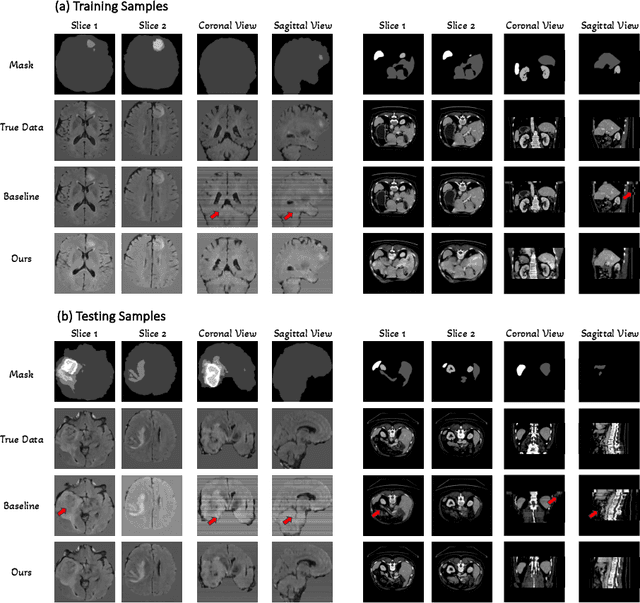

The limited availability of 3D medical image datasets, due to privacy concerns and high collection or annotation costs, poses significant challenges in the field of medical imaging. While a promising alternative is the use of synthesized medical data, there are few solutions for realistic 3D medical image synthesis due to difficulties in backbone design and fewer 3D training samples compared to 2D counterparts. In this paper, we propose GEM-3D, a novel generative approach to the synthesis of 3D medical images and the enhancement of existing datasets using conditional diffusion models. Our method begins with a 2D slice, noted as the informed slice to serve the patient prior, and propagates the generation process using a 3D segmentation mask. By decomposing the 3D medical images into masks and patient prior information, GEM-3D offers a flexible yet effective solution for generating versatile 3D images from existing datasets. GEM-3D can enable dataset enhancement by combining informed slice selection and generation at random positions, along with editable mask volumes to introduce large variations in diffusion sampling. Moreover, as the informed slice contains patient-wise information, GEM-3D can also facilitate counterfactual image synthesis and dataset-level de-enhancement with desired control. Experiments on brain MRI and abdomen CT images demonstrate that GEM-3D is capable of synthesizing high-quality 3D medical images with volumetric consistency, offering a straightforward solution for dataset enhancement during inference. The code is available at https://github.com/HKU-MedAI/GEM-3D.
CLIP-VIS: Adapting CLIP for Open-Vocabulary Video Instance Segmentation
Mar 19, 2024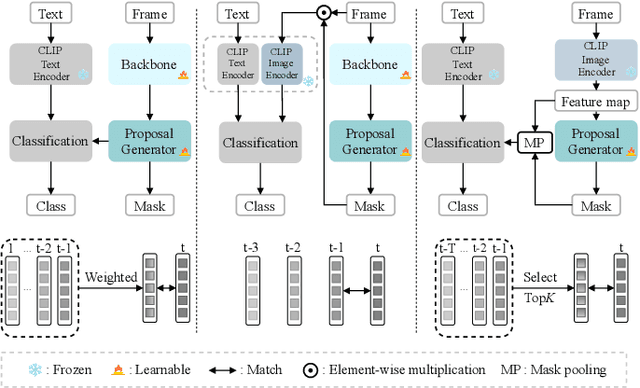
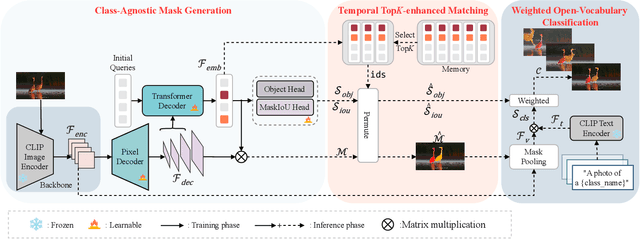
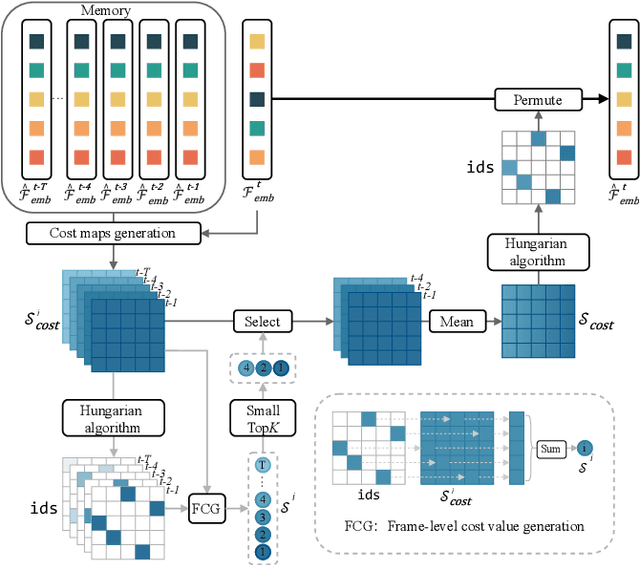
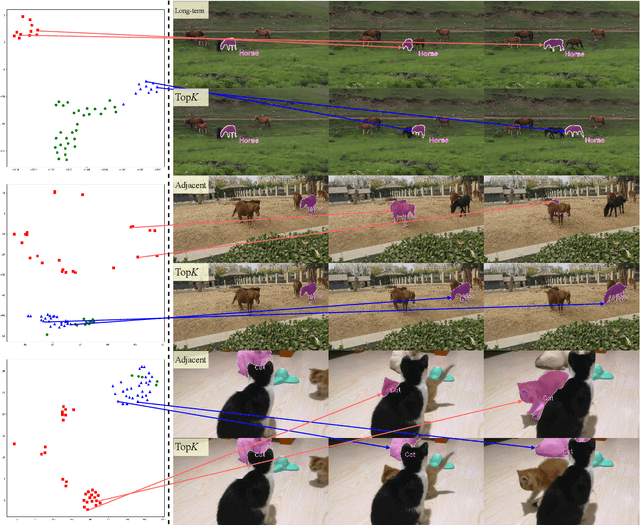
Open-vocabulary video instance segmentation strives to segment and track instances belonging to an open set of categories in a video. The vision-language model Contrastive Language-Image Pre-training (CLIP) has shown strong zero-shot classification ability in image-level open-vocabulary task. In this paper, we propose a simple encoder-decoder network, called CLIP-VIS, to adapt CLIP for open-vocabulary video instance segmentation. Our CLIP-VIS adopts frozen CLIP image encoder and introduces three modules, including class-agnostic mask generation, temporal topK-enhanced matching, and weighted open-vocabulary classification. Given a set of initial queries, class-agnostic mask generation employs a transformer decoder to predict query masks and corresponding object scores and mask IoU scores. Then, temporal topK-enhanced matching performs query matching across frames by using K mostly matched frames. Finally, weighted open-vocabulary classification first generates query visual features with mask pooling, and second performs weighted classification using object scores and mask IoU scores. Our CLIP-VIS does not require the annotations of instance categories and identities. The experiments are performed on various video instance segmentation datasets, which demonstrate the effectiveness of our proposed method, especially on novel categories. When using ConvNeXt-B as backbone, our CLIP-VIS achieves the AP and APn scores of 32.1% and 40.3% on validation set of LV-VIS dataset, which outperforms OV2Seg by 11.0% and 24.0% respectively. We will release the source code and models at https://github.com/zwq456/CLIP-VIS.git.
Boosting Transferability in Vision-Language Attacks via Diversification along the Intersection Region of Adversarial Trajectory
Mar 19, 2024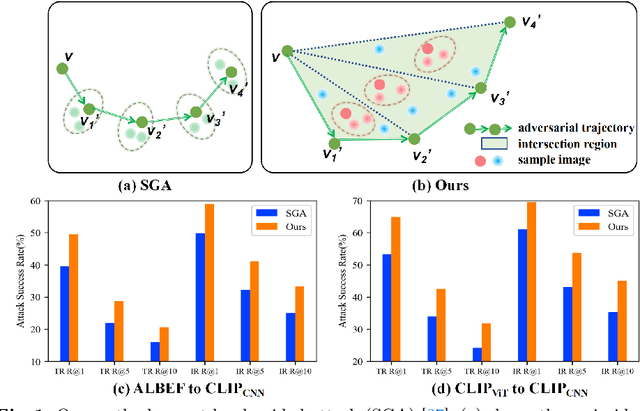


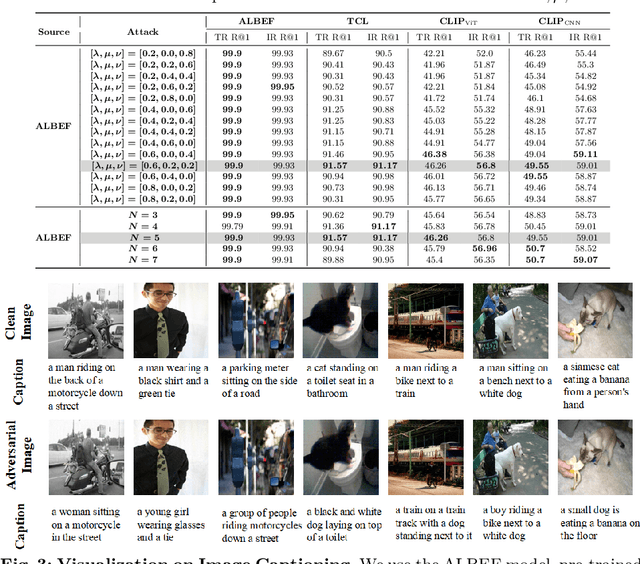
Vision-language pre-training (VLP) models exhibit remarkable capabilities in comprehending both images and text, yet they remain susceptible to multimodal adversarial examples (AEs). Strengthening adversarial attacks and uncovering vulnerabilities, especially common issues in VLP models (e.g., high transferable AEs), can stimulate further research on constructing reliable and practical VLP models. A recent work (i.e., Set-level guidance attack) indicates that augmenting image-text pairs to increase AE diversity along the optimization path enhances the transferability of adversarial examples significantly. However, this approach predominantly emphasizes diversity around the online adversarial examples (i.e., AEs in the optimization period), leading to the risk of overfitting the victim model and affecting the transferability. In this study, we posit that the diversity of adversarial examples towards the clean input and online AEs are both pivotal for enhancing transferability across VLP models. Consequently, we propose using diversification along the intersection region of adversarial trajectory to expand the diversity of AEs. To fully leverage the interaction between modalities, we introduce text-guided adversarial example selection during optimization. Furthermore, to further mitigate the potential overfitting, we direct the adversarial text deviating from the last intersection region along the optimization path, rather than adversarial images as in existing methods. Extensive experiments affirm the effectiveness of our method in improving transferability across various VLP models and downstream vision-and-language tasks (e.g., Image-Text Retrieval(ITR), Visual Grounding(VG), Image Captioning(IC)).
OV9D: Open-Vocabulary Category-Level 9D Object Pose and Size Estimation
Mar 19, 2024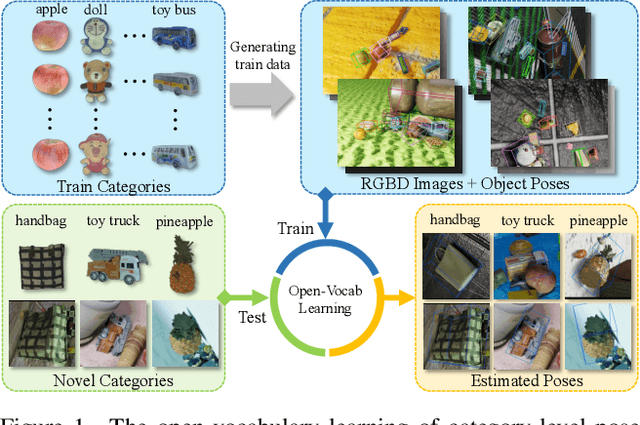
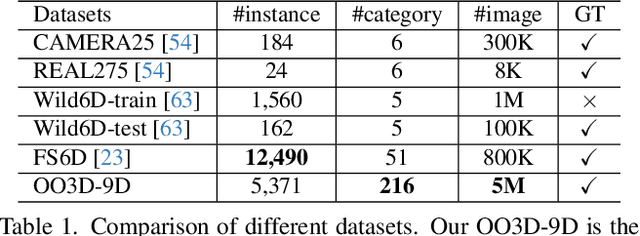

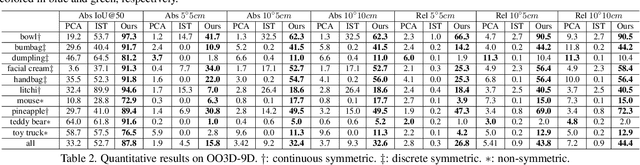
This paper studies a new open-set problem, the open-vocabulary category-level object pose and size estimation. Given human text descriptions of arbitrary novel object categories, the robot agent seeks to predict the position, orientation, and size of the target object in the observed scene image. To enable such generalizability, we first introduce OO3D-9D, a large-scale photorealistic dataset for this task. Derived from OmniObject3D, OO3D-9D is the largest and most diverse dataset in the field of category-level object pose and size estimation. It includes additional annotations for the symmetry axis of each category, which help resolve symmetric ambiguity. Apart from the large-scale dataset, we find another key to enabling such generalizability is leveraging the strong prior knowledge in pre-trained visual-language foundation models. We then propose a framework built on pre-trained DinoV2 and text-to-image stable diffusion models to infer the normalized object coordinate space (NOCS) maps of the target instances. This framework fully leverages the visual semantic prior from DinoV2 and the aligned visual and language knowledge within the text-to-image diffusion model, which enables generalization to various text descriptions of novel categories. Comprehensive quantitative and qualitative experiments demonstrate that the proposed open-vocabulary method, trained on our large-scale synthesized data, significantly outperforms the baseline and can effectively generalize to real-world images of unseen categories. The project page is at https://ov9d.github.io.
Single-Image HDR Reconstruction Assisted Ghost Suppression and Detail Preservation Network for Multi-Exposure HDR Imaging
Mar 07, 2024



The reconstruction of high dynamic range (HDR) images from multi-exposure low dynamic range (LDR) images in dynamic scenes presents significant challenges, especially in preserving and restoring information in oversaturated regions and avoiding ghosting artifacts. While current methods often struggle to address these challenges, our work aims to bridge this gap by developing a multi-exposure HDR image reconstruction network for dynamic scenes, complemented by single-frame HDR image reconstruction. This network, comprising single-frame HDR reconstruction with enhanced stop image (SHDR-ESI) and SHDR-ESI-assisted multi-exposure HDR reconstruction (SHDRA-MHDR), effectively leverages the ghost-free characteristic of single-frame HDR reconstruction and the detail-enhancing capability of ESI in oversaturated areas. Specifically, SHDR-ESI innovatively integrates single-frame HDR reconstruction with the utilization of ESI. This integration not only optimizes the single image HDR reconstruction process but also effectively guides the synthesis of multi-exposure HDR images in SHDR-AMHDR. In this method, the single-frame HDR reconstruction is specifically applied to reduce potential ghosting effects in multiexposure HDR synthesis, while the use of ESI images assists in enhancing the detail information in the HDR synthesis process. Technically, SHDR-ESI incorporates a detail enhancement mechanism, which includes a self-representation module and a mutual-representation module, designed to aggregate crucial information from both reference image and ESI. To fully leverage the complementary information from non-reference images, a feature interaction fusion module is integrated within SHDRA-MHDR. Additionally, a ghost suppression module, guided by the ghost-free results of SHDR-ESI, is employed to suppress the ghosting artifacts.
Enhancing Semantic Fidelity in Text-to-Image Synthesis: Attention Regulation in Diffusion Models
Mar 11, 2024
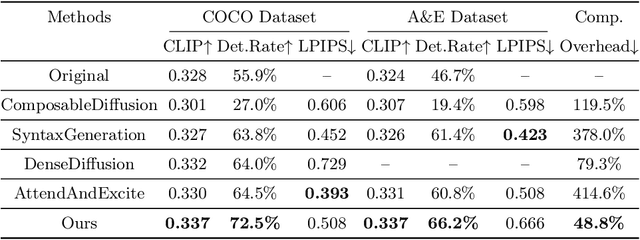
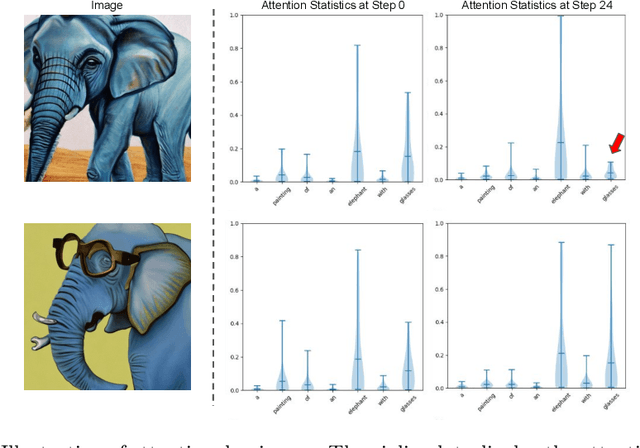

Recent advancements in diffusion models have notably improved the perceptual quality of generated images in text-to-image synthesis tasks. However, diffusion models often struggle to produce images that accurately reflect the intended semantics of the associated text prompts. We examine cross-attention layers in diffusion models and observe a propensity for these layers to disproportionately focus on certain tokens during the generation process, thereby undermining semantic fidelity. To address the issue of dominant attention, we introduce attention regulation, a computation-efficient on-the-fly optimization approach at inference time to align attention maps with the input text prompt. Notably, our method requires no additional training or fine-tuning and serves as a plug-in module on a model. Hence, the generation capacity of the original model is fully preserved. We compare our approach with alternative approaches across various datasets, evaluation metrics, and diffusion models. Experiment results show that our method consistently outperforms other baselines, yielding images that more faithfully reflect the desired concepts with reduced computation overhead. Code is available at https://github.com/YaNgZhAnG-V5/attention_regulation.
A Hybrid Transformer-Sequencer approach for Age and Gender classification from in-wild facial images
Mar 20, 2024The advancements in computer vision and image processing techniques have led to emergence of new application in the domain of visual surveillance, targeted advertisement, content-based searching, and human-computer interaction etc. Out of the various techniques in computer vision, face analysis, in particular, has gained much attention. Several previous studies have tried to explore different applications of facial feature processing for a variety of tasks, including age and gender classification. However, despite several previous studies having explored the problem, the age and gender classification of in-wild human faces is still far from the achieving the desired levels of accuracy required for real-world applications. This paper, therefore, attempts to bridge this gap by proposing a hybrid model that combines self-attention and BiLSTM approaches for age and gender classification problems. The proposed models performance is compared with several state-of-the-art model proposed so far. An improvement of approximately 10percent and 6percent over the state-of-the-art implementations for age and gender classification, respectively, are noted for the proposed model. The proposed model is thus found to achieve superior performance and is found to provide a more generalized learning. The model can, therefore, be applied as a core classification component in various image processing and computer vision problems.
* 22 pages
Solving General Noisy Inverse Problem via Posterior Sampling: A Policy Gradient Viewpoint
Mar 15, 2024
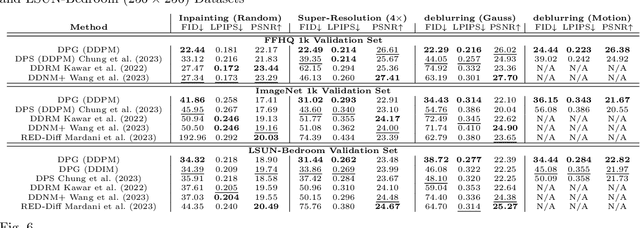

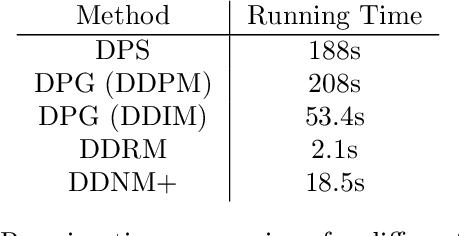
Solving image inverse problems (e.g., super-resolution and inpainting) requires generating a high fidelity image that matches the given input (the low-resolution image or the masked image). By using the input image as guidance, we can leverage a pretrained diffusion generative model to solve a wide range of image inverse tasks without task specific model fine-tuning. To precisely estimate the guidance score function of the input image, we propose Diffusion Policy Gradient (DPG), a tractable computation method by viewing the intermediate noisy images as policies and the target image as the states selected by the policy. Experiments show that our method is robust to both Gaussian and Poisson noise degradation on multiple linear and non-linear inverse tasks, resulting into a higher image restoration quality on FFHQ, ImageNet and LSUN datasets.
Impart: An Imperceptible and Effective Label-Specific Backdoor Attack
Mar 18, 2024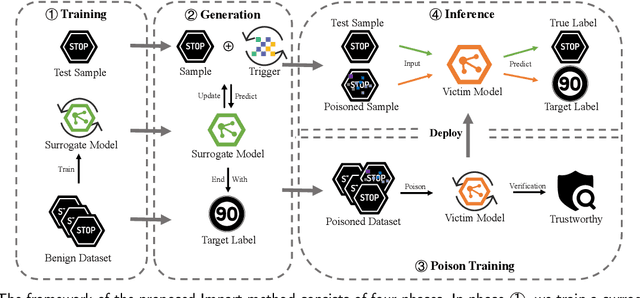

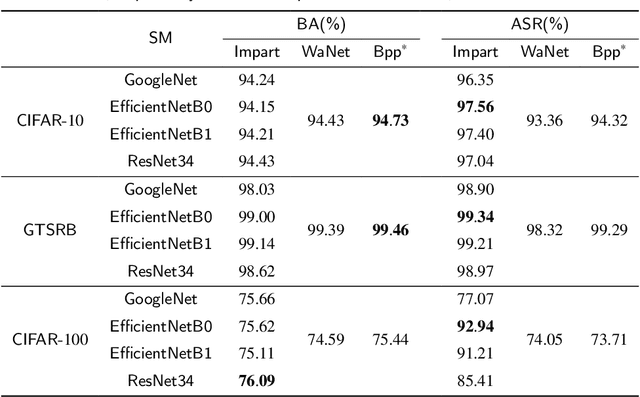
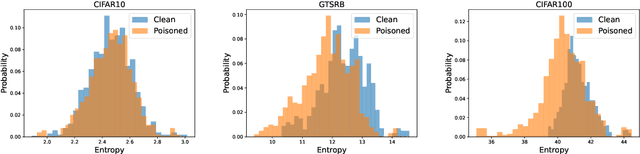
Backdoor attacks have been shown to impose severe threats to real security-critical scenarios. Although previous works can achieve high attack success rates, they either require access to victim models which may significantly reduce their threats in practice, or perform visually noticeable in stealthiness. Besides, there is still room to improve the attack success rates in the scenario that different poisoned samples may have different target labels (a.k.a., the all-to-all setting). In this study, we propose a novel imperceptible backdoor attack framework, named Impart, in the scenario where the attacker has no access to the victim model. Specifically, in order to enhance the attack capability of the all-to-all setting, we first propose a label-specific attack. Different from previous works which try to find an imperceptible pattern and add it to the source image as the poisoned image, we then propose to generate perturbations that align with the target label in the image feature by a surrogate model. In this way, the generated poisoned images are attached with knowledge about the target class, which significantly enhances the attack capability.
TexDreamer: Towards Zero-Shot High-Fidelity 3D Human Texture Generation
Mar 19, 2024
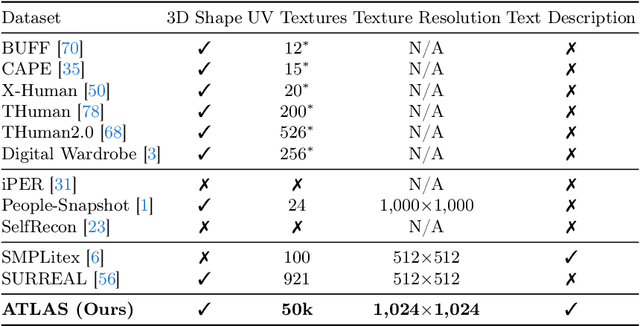
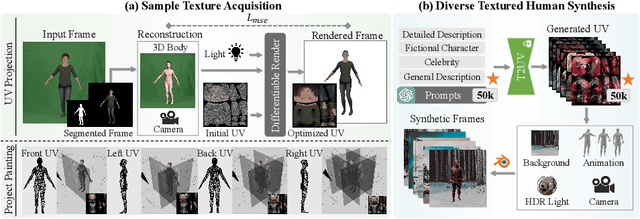
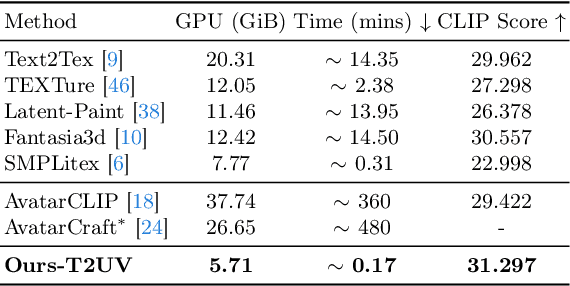
Texturing 3D humans with semantic UV maps remains a challenge due to the difficulty of acquiring reasonably unfolded UV. Despite recent text-to-3D advancements in supervising multi-view renderings using large text-to-image (T2I) models, issues persist with generation speed, text consistency, and texture quality, resulting in data scarcity among existing datasets. We present TexDreamer, the first zero-shot multimodal high-fidelity 3D human texture generation model. Utilizing an efficient texture adaptation finetuning strategy, we adapt large T2I model to a semantic UV structure while preserving its original generalization capability. Leveraging a novel feature translator module, the trained model is capable of generating high-fidelity 3D human textures from either text or image within seconds. Furthermore, we introduce ArTicuLated humAn textureS (ATLAS), the largest high-resolution (1024 X 1024) 3D human texture dataset which contains 50k high-fidelity textures with text descriptions.