 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Position-Guided Point Cloud Panoptic Segmentation Transformer
Mar 23, 2023
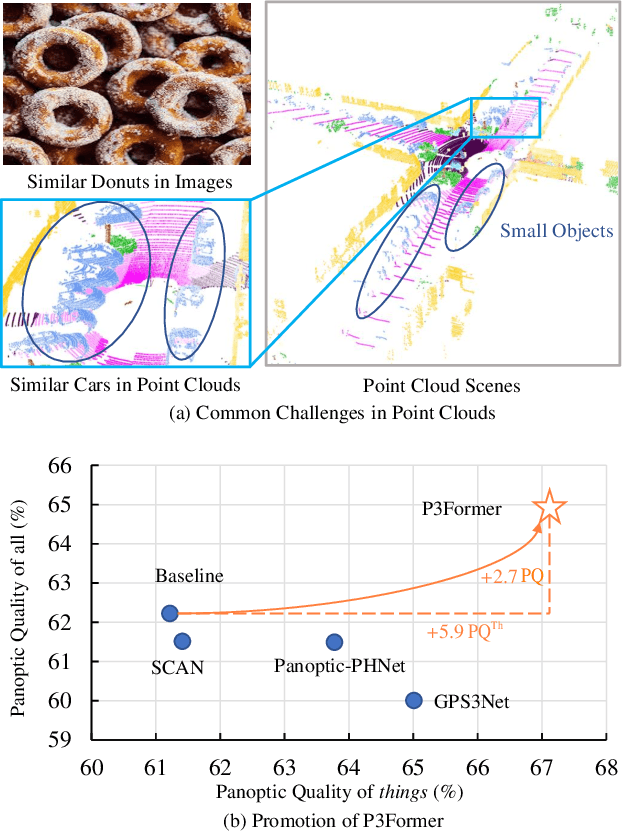
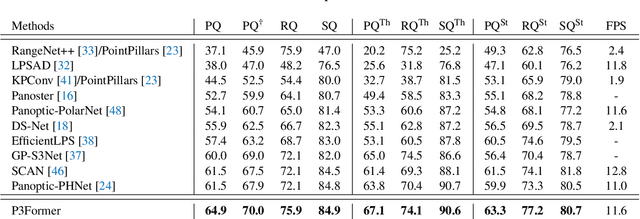
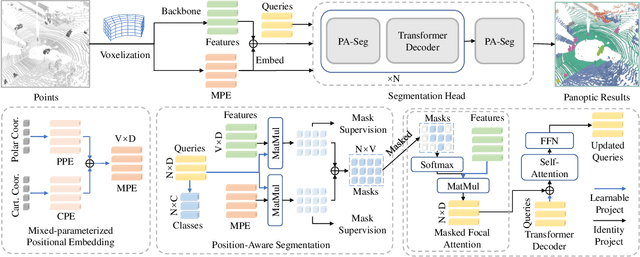
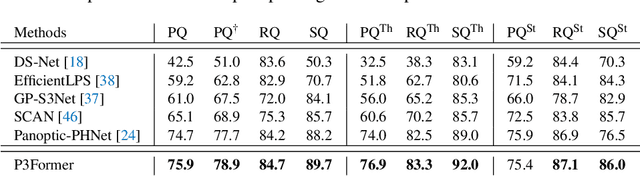
DEtection TRansformer (DETR) started a trend that uses a group of learnable queries for unified visual perception. This work begins by applying this appealing paradigm to LiDAR-based point cloud segmentation and obtains a simple yet effective baseline. Although the naive adaptation obtains fair results, the instance segmentation performance is noticeably inferior to previous works. By diving into the details, we observe that instances in the sparse point clouds are relatively small to the whole scene and often have similar geometry but lack distinctive appearance for segmentation, which are rare in the image domain. Considering instances in 3D are more featured by their positional information, we emphasize their roles during the modeling and design a robust Mixed-parameterized Positional Embedding (MPE) to guide the segmentation process. It is embedded into backbone features and later guides the mask prediction and query update processes iteratively, leading to Position-Aware Segmentation (PA-Seg) and Masked Focal Attention (MFA). All these designs impel the queries to attend to specific regions and identify various instances. The method, named Position-guided Point cloud Panoptic segmentation transFormer (P3Former), outperforms previous state-of-the-art methods by 3.4% and 1.2% PQ on SemanticKITTI and nuScenes benchmark, respectively. The source code and models are available at https://github.com/SmartBot-PJLab/P3Former .
The effectiveness of MAE pre-pretraining for billion-scale pretraining
Mar 23, 2023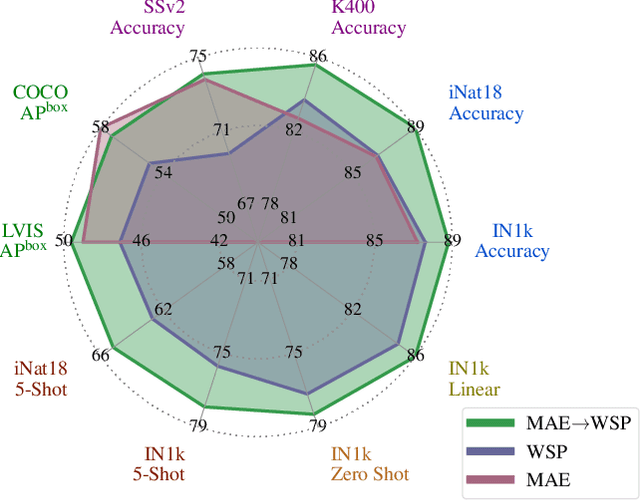

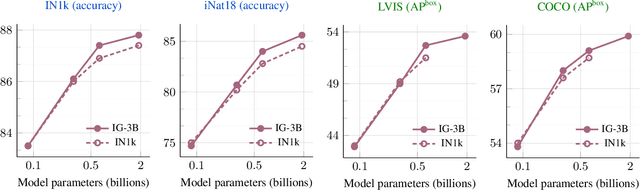
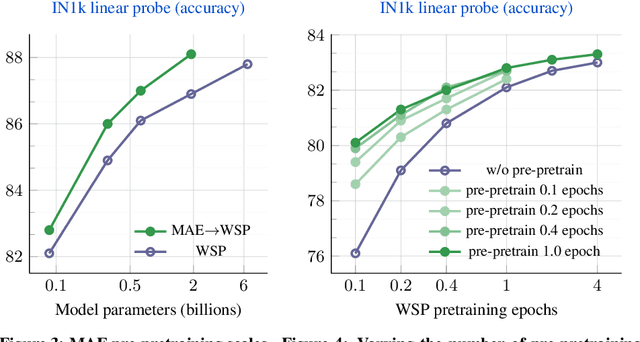
This paper revisits the standard pretrain-then-finetune paradigm used in computer vision for visual recognition tasks. Typically, state-of-the-art foundation models are pretrained using large scale (weakly) supervised datasets with billions of images. We introduce an additional pre-pretraining stage that is simple and uses the self-supervised MAE technique to initialize the model. While MAE has only been shown to scale with the size of models, we find that it scales with the size of the training dataset as well. Thus, our MAE-based pre-pretraining scales with both model and data size making it applicable for training foundation models. Pre-pretraining consistently improves both the model convergence and the downstream transfer performance across a range of model scales (millions to billions of parameters), and dataset sizes (millions to billions of images). We measure the effectiveness of pre-pretraining on 10 different visual recognition tasks spanning image classification, video recognition, object detection, low-shot classification and zero-shot recognition. Our largest model achieves new state-of-the-art results on iNaturalist-18 (91.3%), 1-shot ImageNet-1k (62.1%), and zero-shot transfer on Food-101 (96.0%). Our study reveals that model initialization plays a significant role, even for web-scale pretraining with billions of images.
Semantic Ray: Learning a Generalizable Semantic Field with Cross-Reprojection Attention
Mar 23, 2023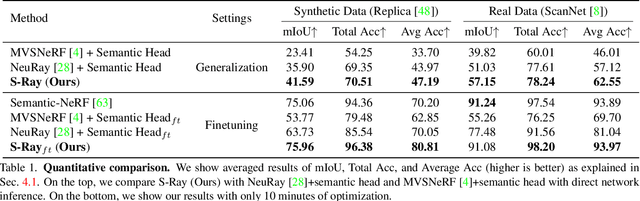
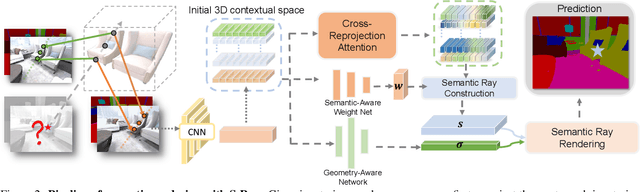
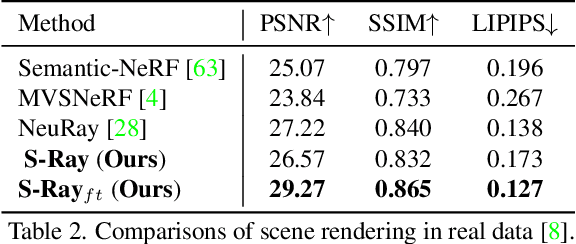
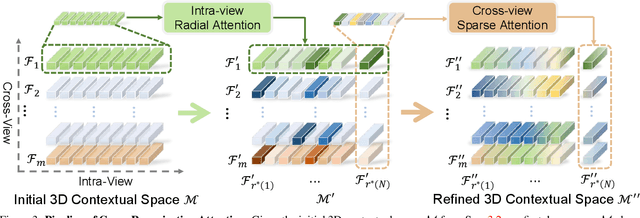
In this paper, we aim to learn a semantic radiance field from multiple scenes that is accurate, efficient and generalizable. While most existing NeRFs target at the tasks of neural scene rendering, image synthesis and multi-view reconstruction, there are a few attempts such as Semantic-NeRF that explore to learn high-level semantic understanding with the NeRF structure. However, Semantic-NeRF simultaneously learns color and semantic label from a single ray with multiple heads, where the single ray fails to provide rich semantic information. As a result, Semantic NeRF relies on positional encoding and needs to train one specific model for each scene. To address this, we propose Semantic Ray (S-Ray) to fully exploit semantic information along the ray direction from its multi-view reprojections. As directly performing dense attention over multi-view reprojected rays would suffer from heavy computational cost, we design a Cross-Reprojection Attention module with consecutive intra-view radial and cross-view sparse attentions, which decomposes contextual information along reprojected rays and cross multiple views and then collects dense connections by stacking the modules. Experiments show that our S-Ray is able to learn from multiple scenes, and it presents strong generalization ability to adapt to unseen scenes.
Weakly-Supervised Text Instance Segmentation
Mar 23, 2023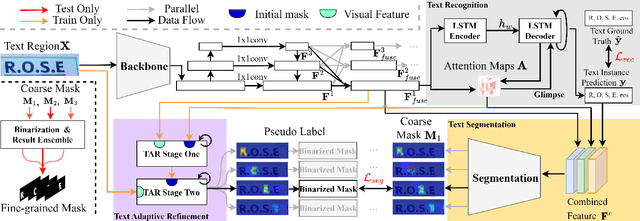
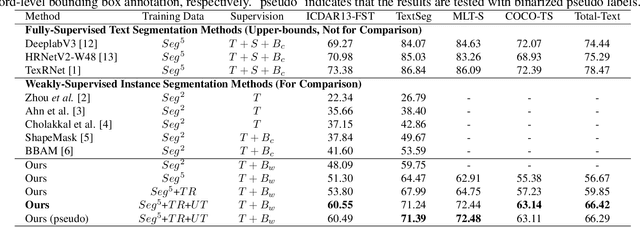


Text segmentation is a challenging vision task with many downstream applications. Current text segmentation methods require pixel-level annotations, which are expensive in the cost of human labor and limited in application scenarios. In this paper, we take the first attempt to perform weakly-supervised text instance segmentation by bridging text recognition and text segmentation. The insight is that text recognition methods provide precise attention position of each text instance, and the attention location can feed to both a text adaptive refinement head (TAR) and a text segmentation head. Specifically, the proposed TAR generates pseudo labels by performing two-stage iterative refinement operations on the attention location to fit the accurate boundaries of the corresponding text instance. Meanwhile, the text segmentation head takes the rough attention location to predict segmentation masks which are supervised by the aforementioned pseudo labels. In addition, we design a mask-augmented contrastive learning by treating our segmentation result as an augmented version of the input text image, thus improving the visual representation and further enhancing the performance of both recognition and segmentation. The experimental results demonstrate that the proposed method significantly outperforms weakly-supervised instance segmentation methods on ICDAR13-FST (18.95$\%$ improvement) and TextSeg (17.80$\%$ improvement) benchmarks.
TriPlaneNet: An Encoder for EG3D Inversion
Mar 23, 2023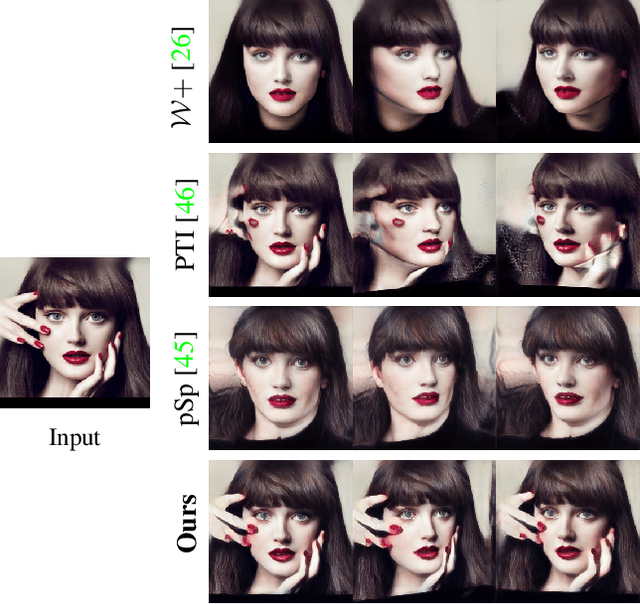
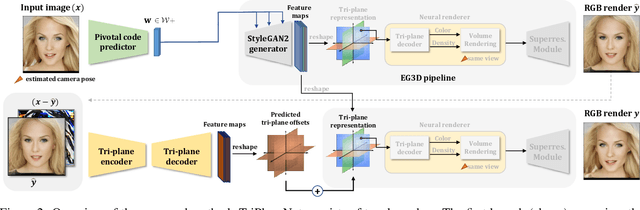
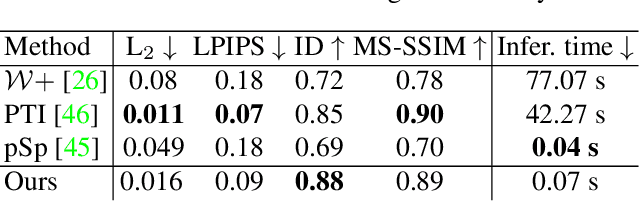

Recent progress in NeRF-based GANs has introduced a number of approaches for high-resolution and high-fidelity generative modeling of human heads with a possibility for novel view rendering. At the same time, one must solve an inverse problem to be able to re-render or modify an existing image or video. Despite the success of universal optimization-based methods for 2D GAN inversion, those, applied to 3D GANs, may fail to produce 3D-consistent renderings. Fast encoder-based techniques, such as those developed for StyleGAN, may also be less appealing due to the lack of identity preservation. In our work, we introduce a real-time method that bridges the gap between the two approaches by directly utilizing the tri-plane representation introduced for EG3D generative model. In particular, we build upon a feed-forward convolutional encoder for the latent code and extend it with a fully-convolutional predictor of tri-plane numerical offsets. As shown in our work, the renderings are similar in quality to optimization-based techniques and significantly outperform the baselines for novel view. As we empirically prove, this is a consequence of directly operating in the tri-plane space, not in the GAN parameter space, while making use of an encoder-based trainable approach.
Controllable Inversion of Black-Box Face-Recognition Models via Diffusion
Mar 23, 2023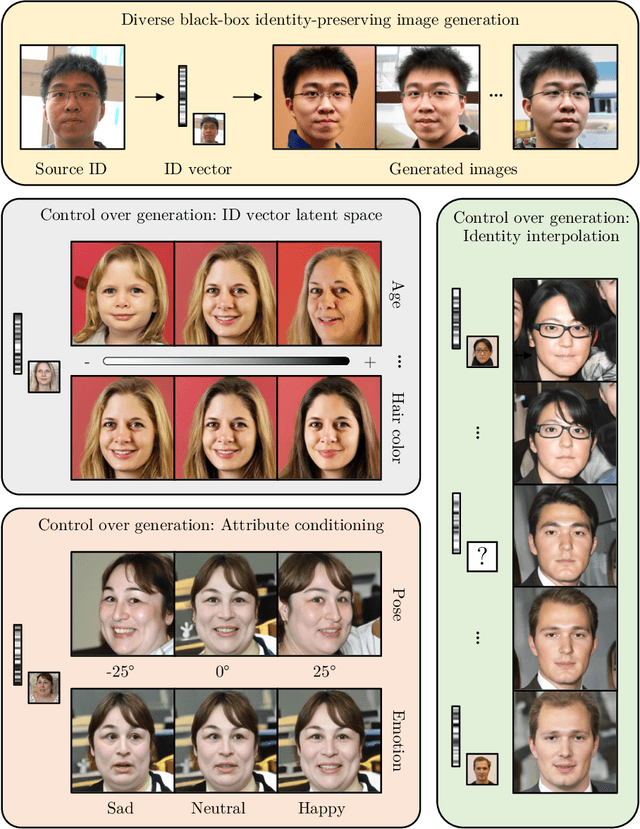

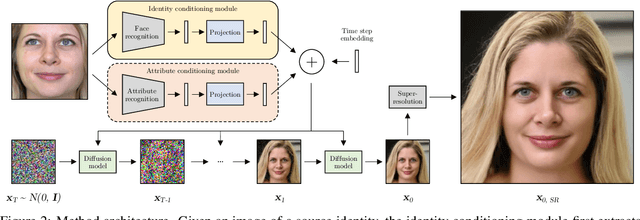
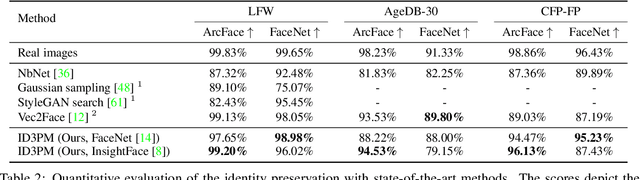
Face recognition models embed a face image into a low-dimensional identity vector containing abstract encodings of identity-specific facial features that allow individuals to be distinguished from one another. We tackle the challenging task of inverting the latent space of pre-trained face recognition models without full model access (i.e. black-box setting). A variety of methods have been proposed in literature for this task, but they have serious shortcomings such as a lack of realistic outputs, long inference times, and strong requirements for the data set and accessibility of the face recognition model. Through an analysis of the black-box inversion problem, we show that the conditional diffusion model loss naturally emerges and that we can effectively sample from the inverse distribution even without an identity-specific loss. Our method, named identity denoising diffusion probabilistic model (ID3PM), leverages the stochastic nature of the denoising diffusion process to produce high-quality, identity-preserving face images with various backgrounds, lighting, poses, and expressions. We demonstrate state-of-the-art performance in terms of identity preservation and diversity both qualitatively and quantitatively. Our method is the first black-box face recognition model inversion method that offers intuitive control over the generation process and does not suffer from any of the common shortcomings from competing methods.
Three ways to improve feature alignment for open vocabulary detection
Mar 23, 2023
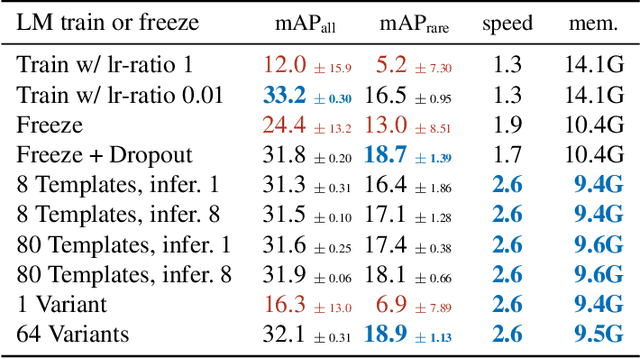
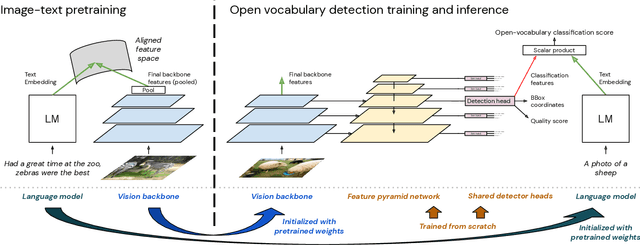
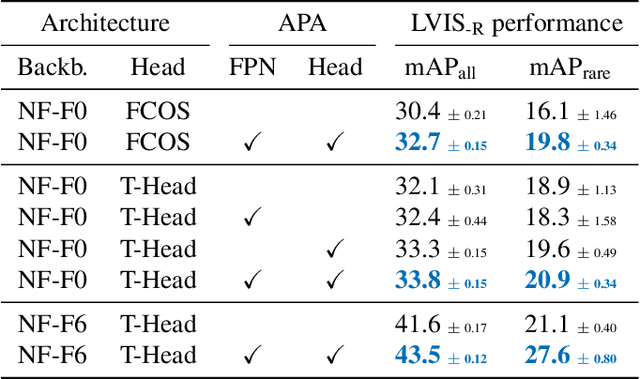
The core problem in zero-shot open vocabulary detection is how to align visual and text features, so that the detector performs well on unseen classes. Previous approaches train the feature pyramid and detection head from scratch, which breaks the vision-text feature alignment established during pretraining, and struggles to prevent the language model from forgetting unseen classes. We propose three methods to alleviate these issues. Firstly, a simple scheme is used to augment the text embeddings which prevents overfitting to a small number of classes seen during training, while simultaneously saving memory and computation. Secondly, the feature pyramid network and the detection head are modified to include trainable gated shortcuts, which encourages vision-text feature alignment and guarantees it at the start of detection training. Finally, a self-training approach is used to leverage a larger corpus of image-text pairs thus improving detection performance on classes with no human annotated bounding boxes. Our three methods are evaluated on the zero-shot version of the LVIS benchmark, each of them showing clear and significant benefits. Our final network achieves the new stateof-the-art on the mAP-all metric and demonstrates competitive performance for mAP-rare, as well as superior transfer to COCO and Objects365.
Mask3D: Pre-training 2D Vision Transformers by Learning Masked 3D Priors
Feb 28, 2023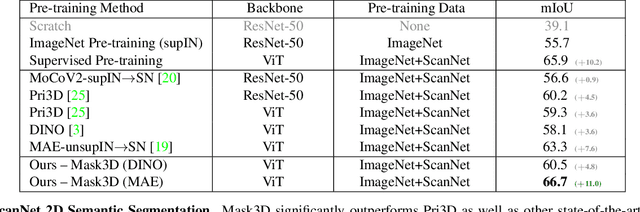
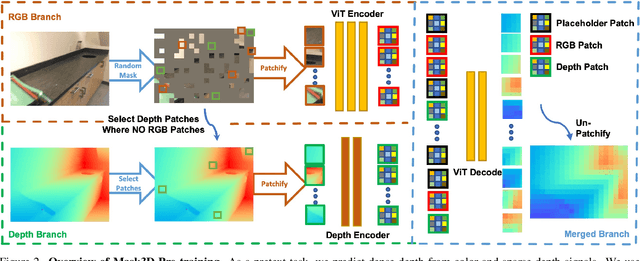
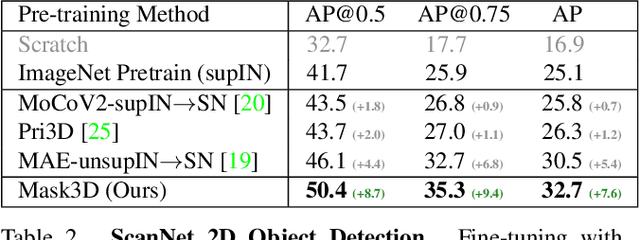
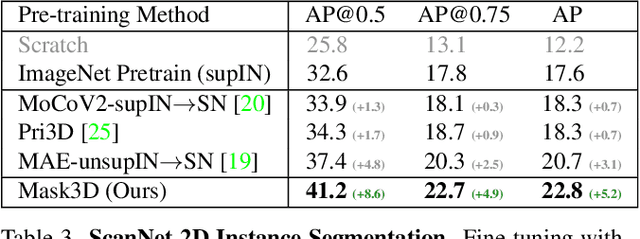
Current popular backbones in computer vision, such as Vision Transformers (ViT) and ResNets are trained to perceive the world from 2D images. However, to more effectively understand 3D structural priors in 2D backbones, we propose Mask3D to leverage existing large-scale RGB-D data in a self-supervised pre-training to embed these 3D priors into 2D learned feature representations. In contrast to traditional 3D contrastive learning paradigms requiring 3D reconstructions or multi-view correspondences, our approach is simple: we formulate a pre-text reconstruction task by masking RGB and depth patches in individual RGB-D frames. We demonstrate the Mask3D is particularly effective in embedding 3D priors into the powerful 2D ViT backbone, enabling improved representation learning for various scene understanding tasks, such as semantic segmentation, instance segmentation and object detection. Experiments show that Mask3D notably outperforms existing self-supervised 3D pre-training approaches on ScanNet, NYUv2, and Cityscapes image understanding tasks, with an improvement of +6.5% mIoU against the state-of-the-art Pri3D on ScanNet image semantic segmentation.
From Nano to Macro: Overview of the IEEE Bio Image and Signal Processing Technical Committee
Oct 31, 2022

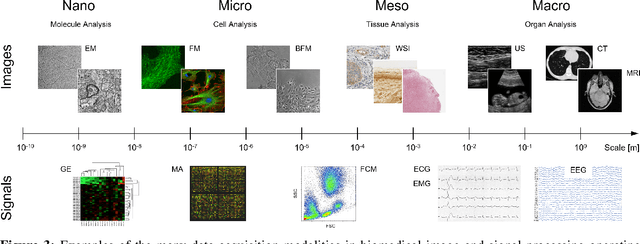
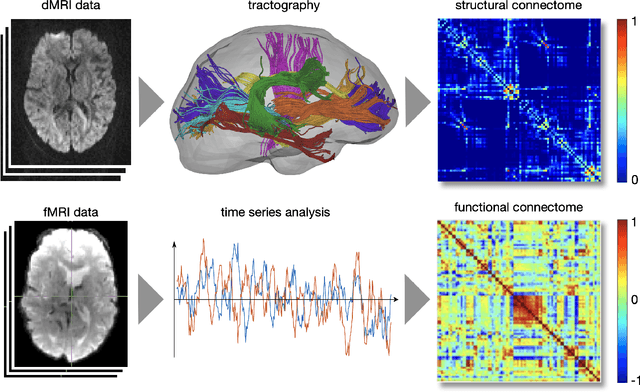
The Bio Image and Signal Processing (BISP) Technical Committee (TC) of the IEEE Signal Processing Society (SPS) promotes activities within the broad technical field of biomedical image and signal processing. Areas of interest include medical and biological imaging, digital pathology, molecular imaging, microscopy, and associated computational imaging, image analysis, and image-guided treatment, alongside physiological signal processing, computational biology, and bioinformatics. BISP has 40 members and covers a wide range of EDICS, including CIS-MI: Medical Imaging, BIO-MIA: Medical Image Analysis, BIO-BI: Biological Imaging, BIO: Biomedical Signal Processing, BIO-BCI: Brain/Human-Computer Interfaces, and BIO-INFR: Bioinformatics. BISP plays a central role in the organization of the IEEE International Symposium on Biomedical Imaging (ISBI) and contributes to the technical sessions at the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), and the IEEE International Conference on Image Processing (ICIP). In this paper, we provide a brief history of the TC, review the technological and methodological contributions its community delivered, and highlight promising new directions we anticipate.
Semantic-enhanced Image Clustering
Aug 21, 2022
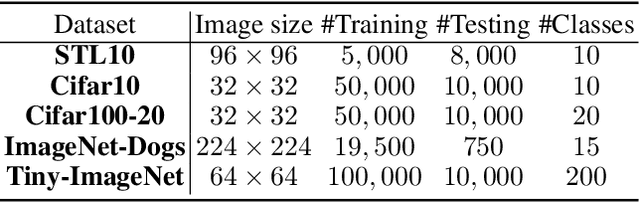
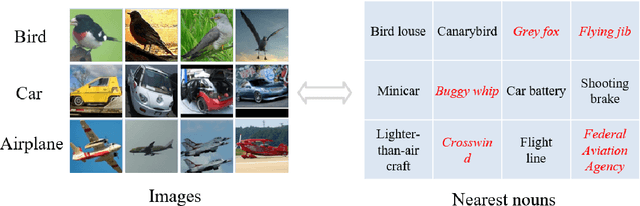
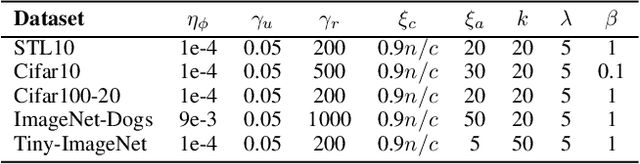
Image clustering is an important, and open challenge task in computer vision. Although many methods have been proposed to solve the image clustering task, they only explore images and uncover clusters according to the image features, thus are unable to distinguish visually similar but semantically different images. In this paper, we propose to investigate the task of image clustering with the help of visual-language pre-training model. Different from the zero-shot setting in which the class names are known, we only know the number of clusters in this setting. Therefore, how to map images to a proper semantic space and how to cluster images from both image and semantic spaces are two key problems. To solve the above problems, we propose a novel image clustering method guided by the visual-language pre-training model CLIP, named as \textbf{Semantic-enhanced Image Clustering (SIC)}. In this new method, we propose a method to map the given images to a proper semantic space first and efficient methods to generate pseudo-labels according to the relationships between images and semantics. Finally, we propose to perform clustering with the consistency learning in both image space and semantic space, in a self-supervised learning fashion. Theoretical result on convergence analysis shows that our proposed method can converge in sublinear speed. Theoretical analysis on expectation risk also shows that we can reduce the expectation risk by improving the neighborhood consistency or prediction confidence or reducing neighborhood imbalance. Experimental results on five benchmark datasets clearly show the superiority of our new method.