 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Large-Scale Domain-Specific Pretraining for Biomedical Vision-Language Processing
Mar 02, 2023
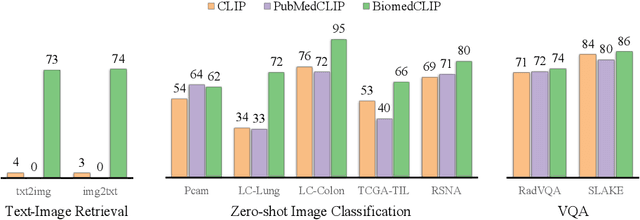



Contrastive pretraining on parallel image-text data has attained great success in vision-language processing (VLP), as exemplified by CLIP and related methods. However, prior explorations tend to focus on general domains in the web. Biomedical images and text are rather different, but publicly available datasets are small and skew toward chest X-ray, thus severely limiting progress. In this paper, we conducted by far the largest study on biomedical VLP, using 15 million figure-caption pairs extracted from biomedical research articles in PubMed Central. Our dataset (PMC-15M) is two orders of magnitude larger than existing biomedical image-text datasets such as MIMIC-CXR, and spans a diverse range of biomedical images. The standard CLIP method is suboptimal for the biomedical domain. We propose BiomedCLIP with domain-specific adaptations tailored to biomedical VLP. We conducted extensive experiments and ablation studies on standard biomedical imaging tasks from retrieval to classification to visual question-answering (VQA). BiomedCLIP established new state of the art in a wide range of standard datasets, substantially outperformed prior VLP approaches. Surprisingly, BiomedCLIP even outperformed radiology-specific state-of-the-art models such as BioViL on radiology-specific tasks such as RSNA pneumonia detection, thus highlighting the utility in large-scale pretraining across all biomedical image types. We will release our models at https://aka.ms/biomedclip to facilitate future research in biomedical VLP.
PAC-Based Formal Verification for Out-of-Distribution Data Detection
Apr 04, 2023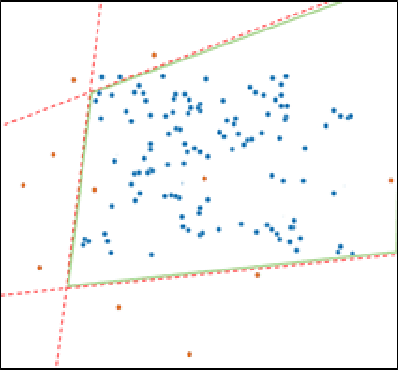
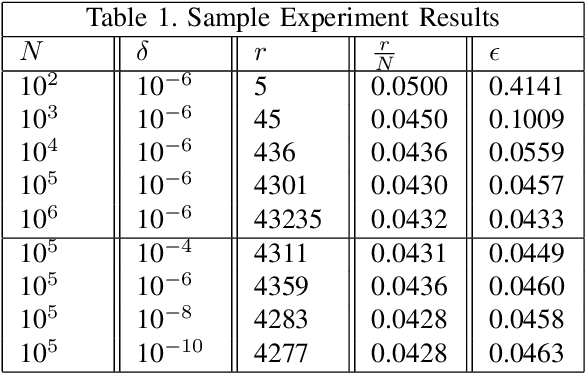
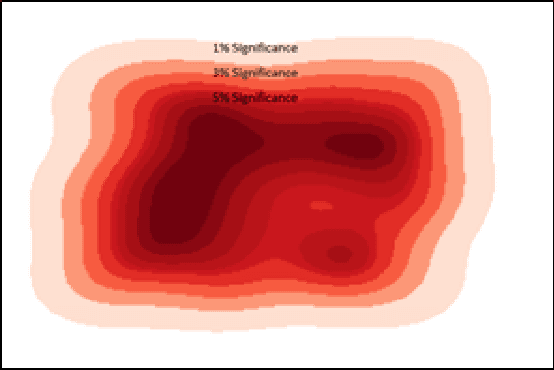
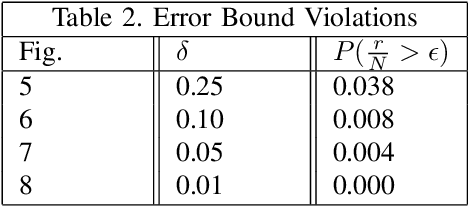
Cyber-physical systems (CPS) like autonomous vehicles, that utilize learning components, are often sensitive to noise and out-of-distribution (OOD) instances encountered during runtime. As such, safety critical tasks depend upon OOD detection subsystems in order to restore the CPS to a known state or interrupt execution to prevent safety from being compromised. However, it is difficult to guarantee the performance of OOD detectors as it is difficult to characterize the OOD aspect of an instance, especially in high-dimensional unstructured data. To distinguish between OOD data and data known to the learning component through the training process, an emerging technique is to incorporate variational autoencoders (VAE) within systems and apply classification or anomaly detection techniques on their latent spaces. The rationale for doing so is the reduction of the data domain size through the encoding process, which benefits real-time systems through decreased processing requirements, facilitates feature analysis for unstructured data and allows more explainable techniques to be implemented. This study places probably approximately correct (PAC) based guarantees on OOD detection using the encoding process within VAEs to quantify image features and apply conformal constraints over them. This is used to bound the detection error on unfamiliar instances with user-defined confidence. The approach used in this study is to empirically establish these bounds by sampling the latent probability distribution and evaluating the error with respect to the constraint violations that are encountered. The guarantee is then verified using data generated from CARLA, an open-source driving simulator.
Self-Supervised Image Restoration with Blurry and Noisy Pairs
Nov 14, 2022
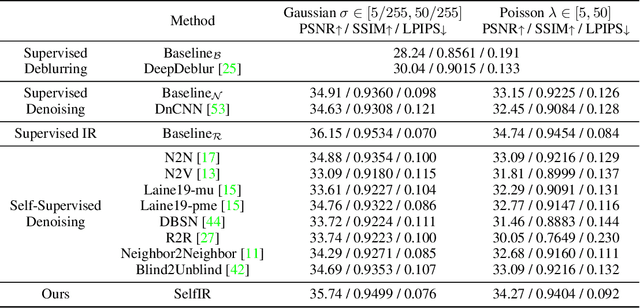
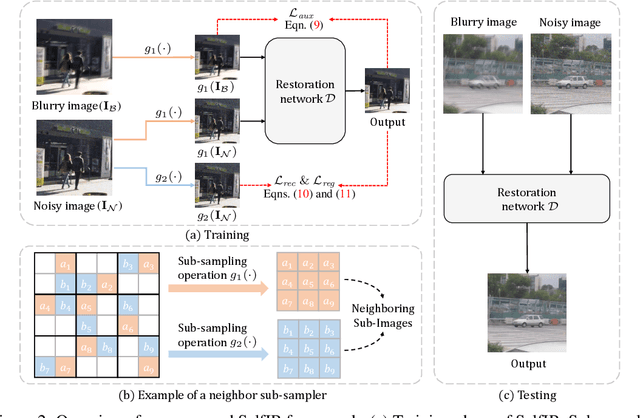
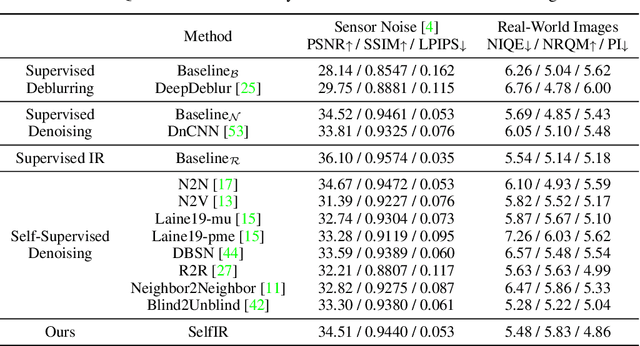
When taking photos under an environment with insufficient light, the exposure time and the sensor gain usually require to be carefully chosen to obtain images with satisfying visual quality. For example, the images with high ISO usually have inescapable noise, while the long-exposure ones may be blurry due to camera shake or object motion. Existing solutions generally suggest to seek a balance between noise and blur, and learn denoising or deblurring models under either full- or self-supervision. However, the real-world training pairs are difficult to collect, and the self-supervised methods merely rely on blurry or noisy images are limited in performance. In this work, we tackle this problem by jointly leveraging the short-exposure noisy image and the long-exposure blurry image for better image restoration. Such setting is practically feasible due to that short-exposure and long-exposure images can be either acquired by two individual cameras or synthesized by a long burst of images. Moreover, the short-exposure images are hardly blurry, and the long-exposure ones have negligible noise. Their complementarity makes it feasible to learn restoration model in a self-supervised manner. Specifically, the noisy images can be used as the supervision information for deblurring, while the sharp areas in the blurry images can be utilized as the auxiliary supervision information for self-supervised denoising. By learning in a collaborative manner, the deblurring and denoising tasks in our method can benefit each other. Experiments on synthetic and real-world images show the effectiveness and practicality of the proposed method. Codes are available at https://github.com/cszhilu1998/SelfIR.
High-Resolution Image Editing via Multi-Stage Blended Diffusion
Oct 24, 2022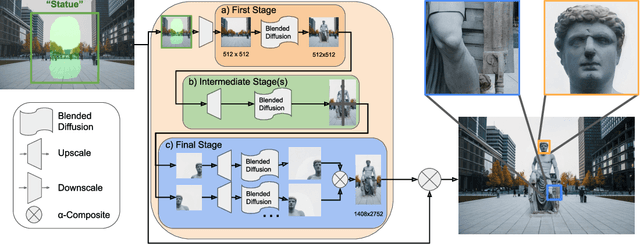

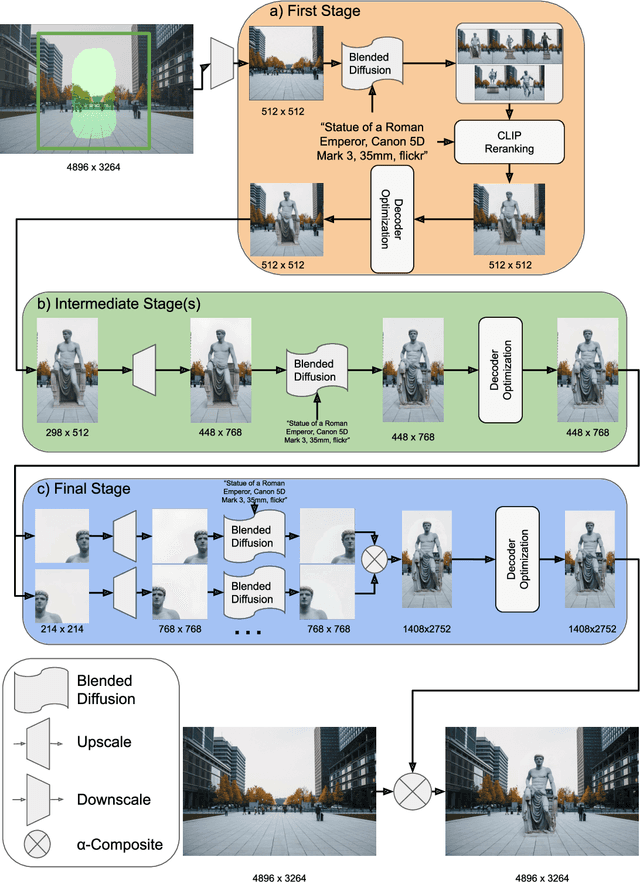

Diffusion models have shown great results in image generation and in image editing. However, current approaches are limited to low resolutions due to the computational cost of training diffusion models for high-resolution generation. We propose an approach that uses a pre-trained low-resolution diffusion model to edit images in the megapixel range. We first use Blended Diffusion to edit the image at a low resolution, and then upscale it in multiple stages, using a super-resolution model and Blended Diffusion. Using our approach, we achieve higher visual fidelity than by only applying off the shelf super-resolution methods to the output of the diffusion model. We also obtain better global consistency than directly using the diffusion model at a higher resolution.
Learn to See Faster: Pushing the Limits of High-Speed Camera with Deep Underexposed Image Denoising
Nov 29, 2022
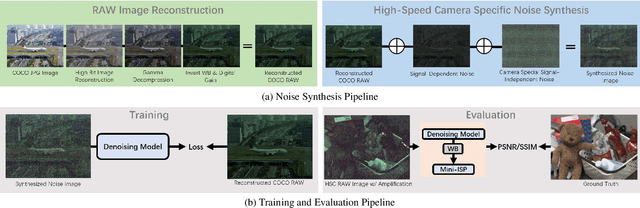
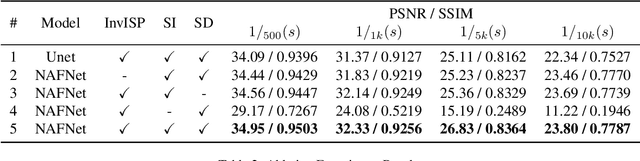
The ability to record high-fidelity videos at high acquisition rates is central to the study of fast moving phenomena. The difficulty of imaging fast moving scenes lies in a trade-off between motion blur and underexposure noise: On the one hand, recordings with long exposure times suffer from motion blur effects caused by movements in the recorded scene. On the other hand, the amount of light reaching camera photosensors decreases with exposure times so that short-exposure recordings suffer from underexposure noise. In this paper, we propose to address this trade-off by treating the problem of high-speed imaging as an underexposed image denoising problem. We combine recent advances on underexposed image denoising using deep learning and adapt these methods to the specificity of the high-speed imaging problem. Leveraging large external datasets with a sensor-specific noise model, our method is able to speedup the acquisition rate of a High-Speed Camera over one order of magnitude while maintaining similar image quality.
A New Benchmark: On the Utility of Synthetic Data with Blender for Bare Supervised Learning and Downstream Domain Adaptation
Mar 16, 2023
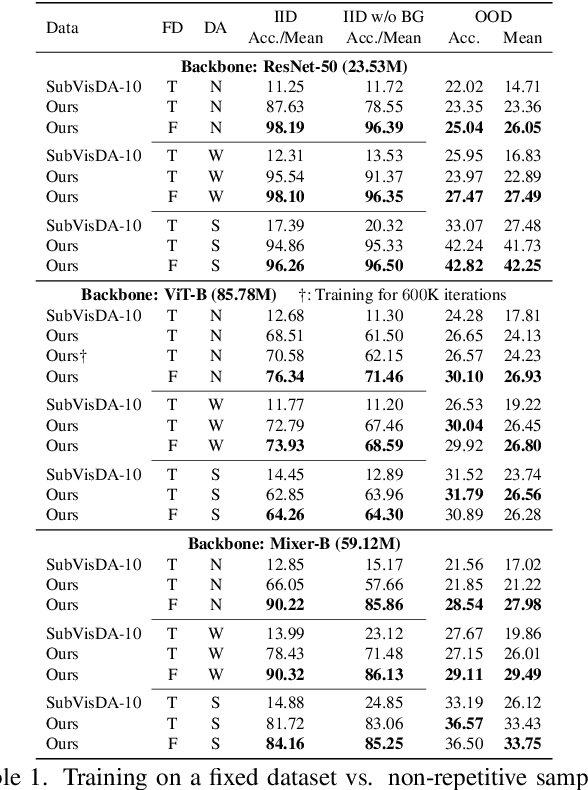

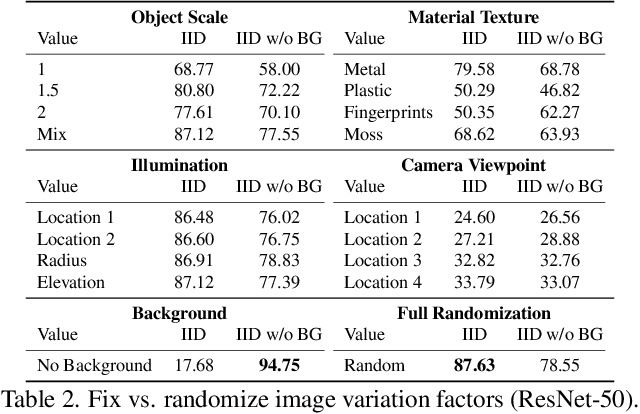
Deep learning in computer vision has achieved great success with the price of large-scale labeled training data. However, exhaustive data annotation is impracticable for each task of all domains of interest, due to high labor costs and unguaranteed labeling accuracy. Besides, the uncontrollable data collection process produces non-IID training and test data, where undesired duplication may exist. All these nuisances may hinder the verification of typical theories and exposure to new findings. To circumvent them, an alternative is to generate synthetic data via 3D rendering with domain randomization. We in this work push forward along this line by doing profound and extensive research on bare supervised learning and downstream domain adaptation. Specifically, under the well-controlled, IID data setting enabled by 3D rendering, we systematically verify the typical, important learning insights, e.g., shortcut learning, and discover the new laws of various data regimes and network architectures in generalization. We further investigate the effect of image formation factors on generalization, e.g., object scale, material texture, illumination, camera viewpoint, and background in a 3D scene. Moreover, we use the simulation-to-reality adaptation as a downstream task for comparing the transferability between synthetic and real data when used for pre-training, which demonstrates that synthetic data pre-training is also promising to improve real test results. Lastly, to promote future research, we develop a new large-scale synthetic-to-real benchmark for image classification, termed S2RDA, which provides more significant challenges for transfer from simulation to reality. The code and datasets are available at https://github.com/huitangtang/On_the_Utility_of_Synthetic_Data.
Few-shot Image Generation with Diffusion Models
Nov 11, 2022
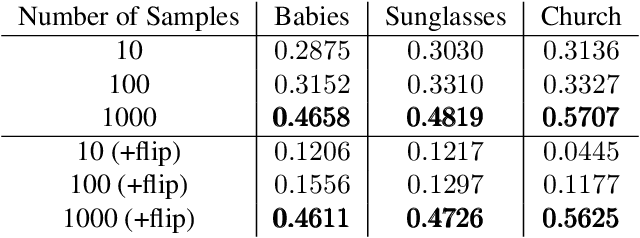

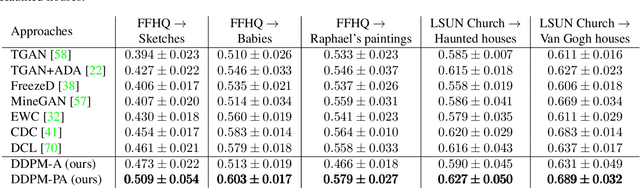
Denoising diffusion probabilistic models (DDPMs) have been proven capable of synthesizing high-quality images with remarkable diversity when trained on large amounts of data. However, to our knowledge, few-shot image generation tasks have yet to be studied with DDPM-based approaches. Modern approaches are mainly built on Generative Adversarial Networks (GANs) and adapt models pre-trained on large source domains to target domains using a few available samples. In this paper, we make the first attempt to study when do DDPMs overfit and suffer severe diversity degradation as training data become scarce. Then we fine-tune DDPMs pre-trained on large source domains on limited target data directly. Our results show that utilizing knowledge from pre-trained models can accelerate convergence and improve generation quality and diversity compared with training from scratch. However, the fine-tuned models still fail to retain some diverse features and can only achieve limited diversity. Therefore, we propose a pairwise DDPM adaptation (DDPM-PA) approach based on a pairwise similarity loss to preserve the relative distances between generated samples during domain adaptation. DDPM-PA further improves generation diversity and achieves results better than current state-of-the-art GAN-based approaches. We demonstrate the effectiveness of DDPM-PA on a series of few-shot image generation tasks qualitatively and quantitatively.
Spatial-Spectral Transformer for Hyperspectral Image Denoising
Nov 25, 2022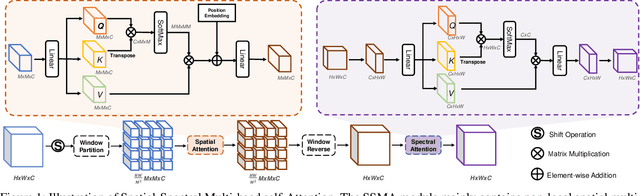
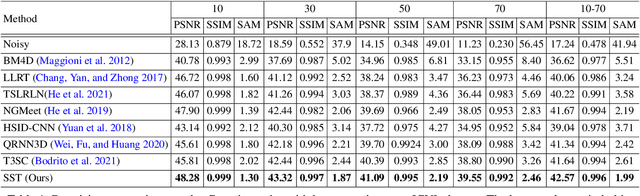
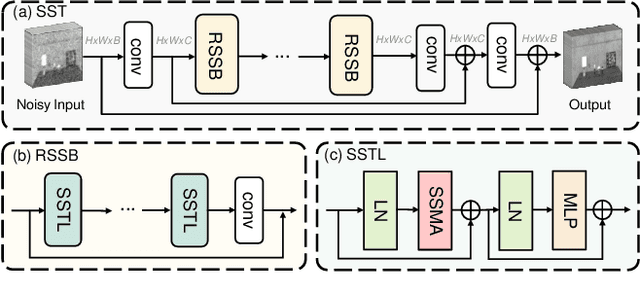
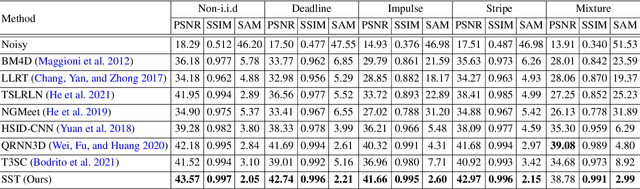
Hyperspectral image (HSI) denoising is a crucial preprocessing procedure for the subsequent HSI applications. Unfortunately, though witnessing the development of deep learning in HSI denoising area, existing convolution-based methods face the trade-off between computational efficiency and capability to model non-local characteristics of HSI. In this paper, we propose a Spatial-Spectral Transformer (SST) to alleviate this problem. To fully explore intrinsic similarity characteristics in both spatial dimension and spectral dimension, we conduct non-local spatial self-attention and global spectral self-attention with Transformer architecture. The window-based spatial self-attention focuses on the spatial similarity beyond the neighboring region. While, spectral self-attention exploits the long-range dependencies between highly correlative bands. Experimental results show that our proposed method outperforms the state-of-the-art HSI denoising methods in quantitative quality and visual results.
Towards Unifying Medical Vision-and-Language Pre-training via Soft Prompts
Feb 17, 2023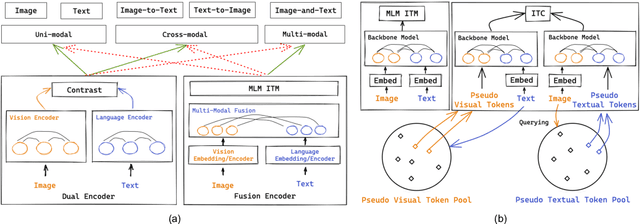
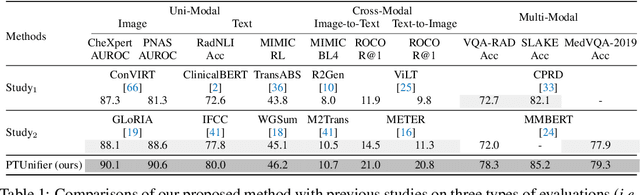
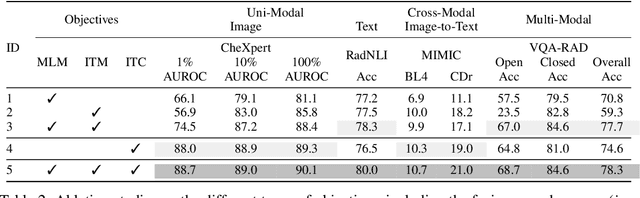
Medical vision-and-language pre-training (Med-VLP) has shown promising improvements on many downstream medical tasks owing to its applicability to extracting generic representations from medical images and texts. Practically, there exist two typical types, \textit{i.e.}, the fusion-encoder type and the dual-encoder type, depending on whether a heavy fusion module is used. The former is superior at multi-modal tasks owing to the sufficient interaction between modalities; the latter is good at uni-modal and cross-modal tasks due to the single-modality encoding ability. To take advantage of these two types, we propose an effective yet straightforward scheme named PTUnifier to unify the two types. We first unify the input format by introducing visual and textual prompts, which serve as a feature bank that stores the most representative images/texts. By doing so, a single model could serve as a \textit{foundation model} that processes various tasks adopting different input formats (\textit{i.e.}, image-only, text-only, and image-text-pair). Furthermore, we construct a prompt pool (instead of static ones) to improve diversity and scalability. Experimental results show that our approach achieves state-of-the-art results on a broad range of tasks, spanning uni-modal tasks (\textit{i.e.}, image/text classification and text summarization), cross-modal tasks (\textit{i.e.}, image-to-text generation and image-text/text-image retrieval), and multi-modal tasks (\textit{i.e.}, visual question answering), demonstrating the effectiveness of our approach. Note that the adoption of prompts is orthogonal to most existing Med-VLP approaches and could be a beneficial and complementary extension to these approaches.
MLP-SRGAN: A Single-Dimension Super Resolution GAN using MLP-Mixer
Mar 11, 2023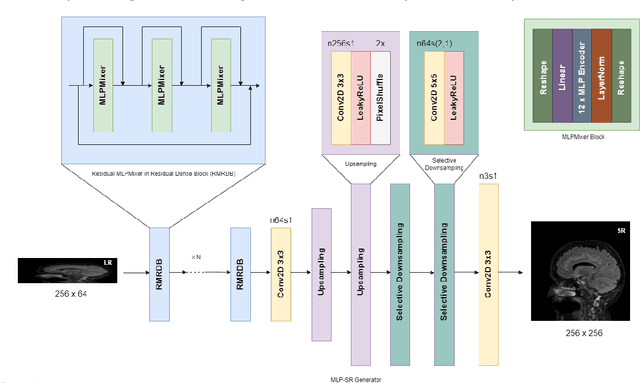
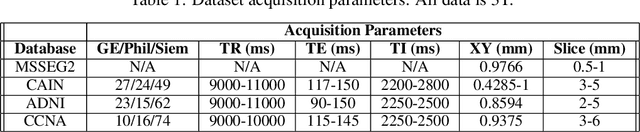
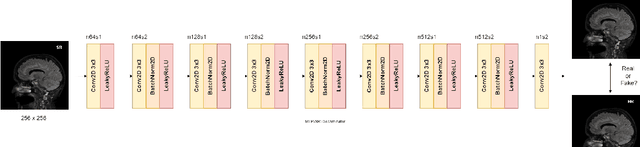
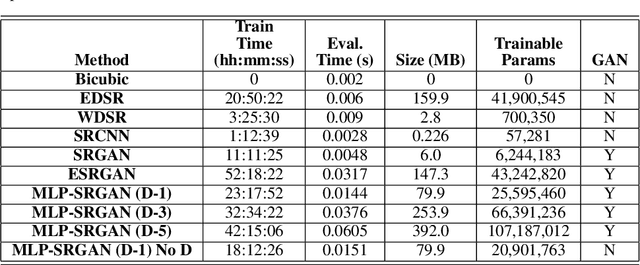
We propose a novel architecture called MLP-SRGAN, which is a single-dimension Super Resolution Generative Adversarial Network (SRGAN) that utilizes Multi-Layer Perceptron Mixers (MLP-Mixers) along with convolutional layers to upsample in the slice direction. MLP-SRGAN is trained and validated using high resolution (HR) FLAIR MRI from the MSSEG2 challenge dataset. The method was applied to three multicentre FLAIR datasets (CAIN, ADNI, CCNA) of images with low spatial resolution in the slice dimension to examine performance on held-out (unseen) clinical data. Upsampled results are compared to several state-of-the-art SR networks. For images with high resolution (HR) ground truths, peak-signal-to-noise-ratio (PSNR) and structural similarity index (SSIM) are used to measure upsampling performance. Several new structural, no-reference image quality metrics were proposed to quantify sharpness (edge strength), noise (entropy), and blurriness (low frequency information) in the absence of ground truths. Results show MLP-SRGAN results in sharper edges, less blurring, preserves more texture and fine-anatomical detail, with fewer parameters, faster training/evaluation time, and smaller model size than existing methods. Code for MLP-SRGAN training and inference, data generators, models and no-reference image quality metrics will be available at https://github.com/IAMLAB-Ryerson/MLP-SRGAN.