 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Dens-PU: PU Learning with Density-Based Positive Labeled Augmentation
Mar 21, 2023


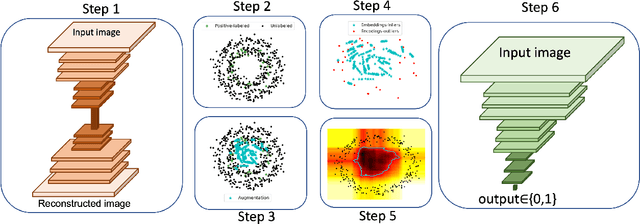
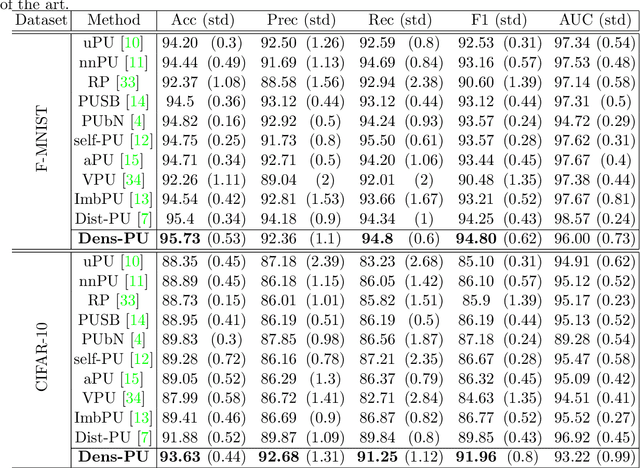
This study proposes a novel approach for solving the PU learning problem based on an anomaly-detection strategy. Latent encodings extracted from positive-labeled data are linearly combined to acquire new samples. These new samples are used as embeddings to increase the density of positive-labeled data and, thus, define a boundary that approximates the positive class. The further a sample is from the boundary the more it is considered as a negative sample. Once a set of negative samples is obtained, the PU learning problem reduces to binary classification. The approach, named Dens-PU due to its reliance on the density of positive-labeled data, was evaluated using benchmark image datasets, and state-of-the-art results were attained.
Set Features for Fine-grained Anomaly Detection
Mar 02, 2023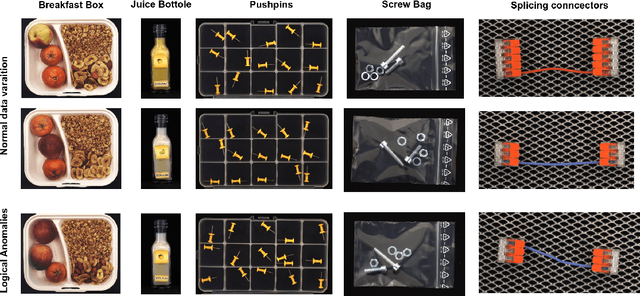
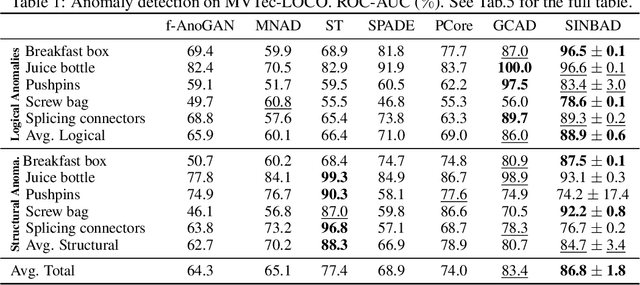
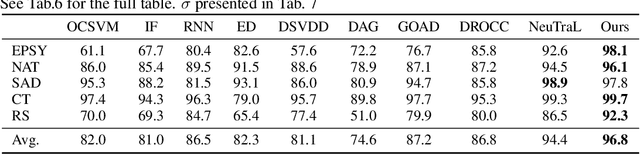
Fine-grained anomaly detection has recently been dominated by segmentation based approaches. These approaches first classify each element of the sample (e.g., image patch) as normal or anomalous and then classify the entire sample as anomalous if it contains anomalous elements. However, such approaches do not extend to scenarios where the anomalies are expressed by an unusual combination of normal elements. In this paper, we overcome this limitation by proposing set features that model each sample by the distribution its elements. We compute the anomaly score of each sample using a simple density estimation method. Our simple-to-implement approach outperforms the state-of-the-art in image-level logical anomaly detection (+3.4%) and sequence-level time-series anomaly detection (+2.4%).
SLLEN: Semantic-aware Low-light Image Enhancement Network
Nov 21, 2022
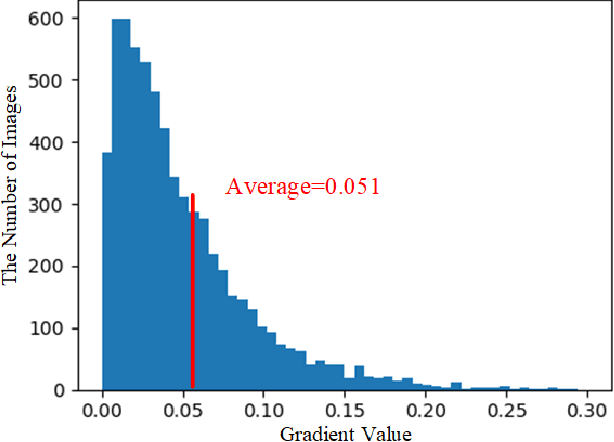
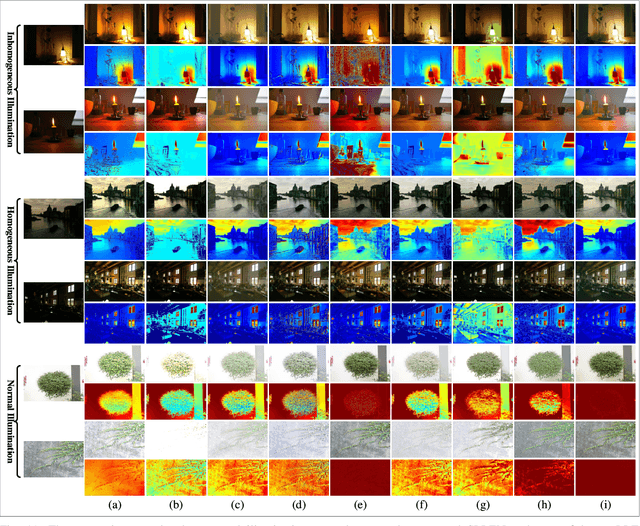

How to effectively explore semantic feature is vital for low-light image enhancement (LLE). Existing methods usually utilize the semantic feature that is only drawn from the semantic map produced by high-level semantic segmentation network (SSN). However, if the semantic map is not accurately estimated, it would affect the high-level semantic feature (HSF) extraction, which accordingly interferes with LLE. In this paper, we develop a simple yet effective two-branch semantic-aware LLE network (SLLEN) that neatly integrates the random intermediate embedding feature (IEF) (i.e., the information extracted from the intermediate layer of semantic segmentation network) together with the HSF into a unified framework for better LLE. Specifically, for one branch, we utilize an attention mechanism to integrate HSF into low-level feature. For the other branch, we extract IEF to guide the adjustment of low-level feature using nonlinear transformation manner. Finally, semantic-aware features obtained from two branches are fused and decoded for image enhancement. It is worth mentioning that IEF has some randomness compared to HSF despite their similarity on semantic characteristics, thus its introduction can allow network to learn more possibilities by leveraging the latent relationships between the low-level feature and semantic feature, just like the famous saying "God rolls the dice" in Physics Nobel Prize 2022. Comparisons between the proposed SLLEN and other state-of-the-art techniques demonstrate the superiority of SLLEN with respect to LLE quality over all the comparable alternatives.
LANIT: Language-Driven Image-to-Image Translation for Unlabeled Data
Aug 31, 2022
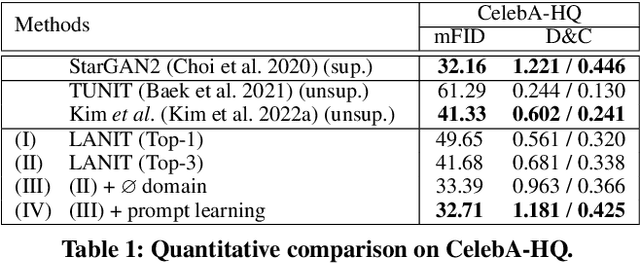
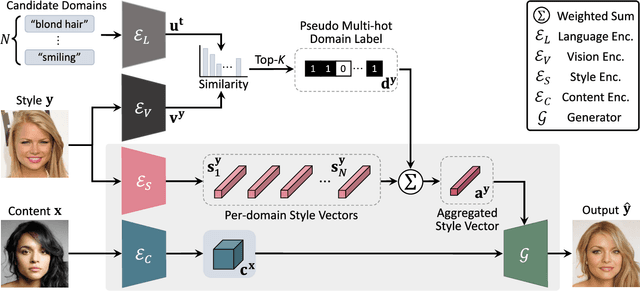
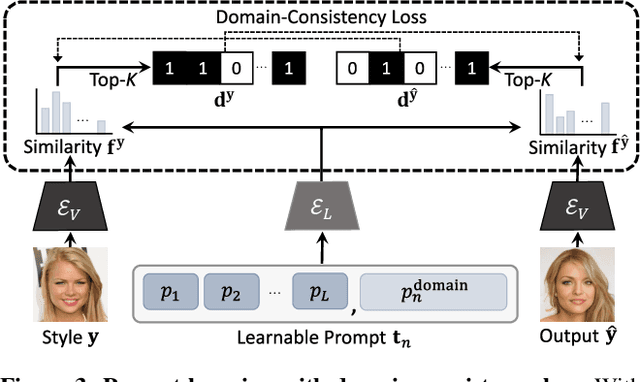
Existing techniques for image-to-image translation commonly have suffered from two critical problems: heavy reliance on per-sample domain annotation and/or inability of handling multiple attributes per image. Recent methods adopt clustering approaches to easily provide per-sample annotations in an unsupervised manner. However, they cannot account for the real-world setting; one sample may have multiple attributes. In addition, the semantics of the clusters are not easily coupled to human understanding. To overcome these, we present a LANguage-driven Image-to-image Translation model, dubbed LANIT. We leverage easy-to-obtain candidate domain annotations given in texts for a dataset and jointly optimize them during training. The target style is specified by aggregating multi-domain style vectors according to the multi-hot domain assignments. As the initial candidate domain texts might be inaccurate, we set the candidate domain texts to be learnable and jointly fine-tune them during training. Furthermore, we introduce a slack domain to cover samples that are not covered by the candidate domains. Experiments on several standard benchmarks demonstrate that LANIT achieves comparable or superior performance to the existing model.
Convolutional neural networks for medical image segmentation
Nov 17, 2022
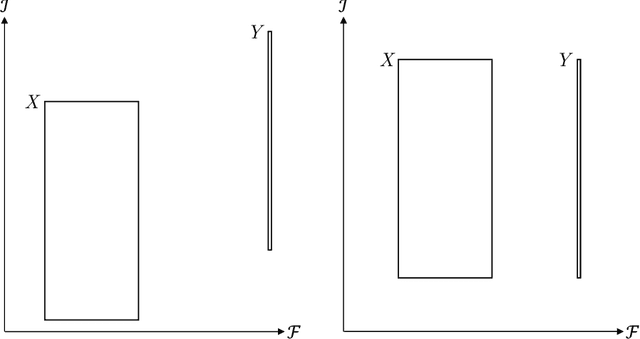
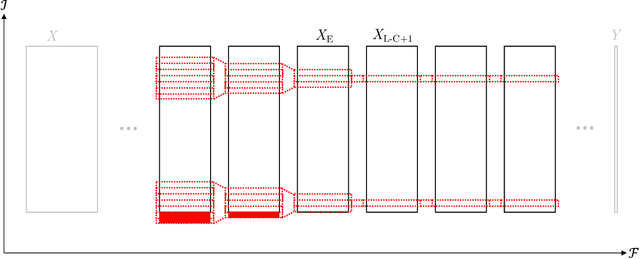
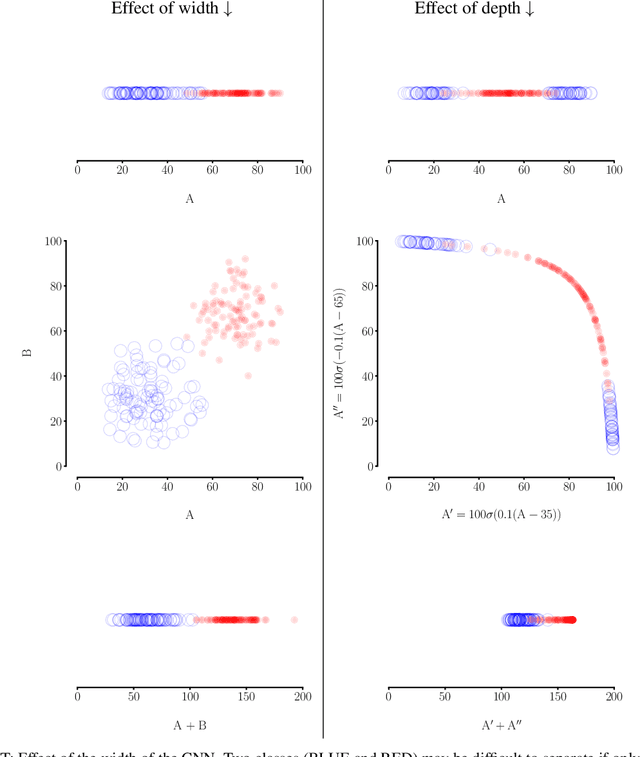
In this article, we look into some essential aspects of convolutional neural networks (CNNs) with the focus on medical image segmentation. First, we discuss the CNN architecture, thereby highlighting the spatial origin of the data, voxel-wise classification and the receptive field. Second, we discuss the sampling of input-output pairs, thereby highlighting the interaction between voxel-wise classification, patch size and the receptive field. Finally, we give a historical overview of crucial changes to CNN architectures for classification and segmentation, giving insights in the relation between three pivotal CNN architectures: FCN, U-Net and DeepMedic.
Inherently Interpretable Multi-Label Classification Using Class-Specific Counterfactuals
Mar 01, 2023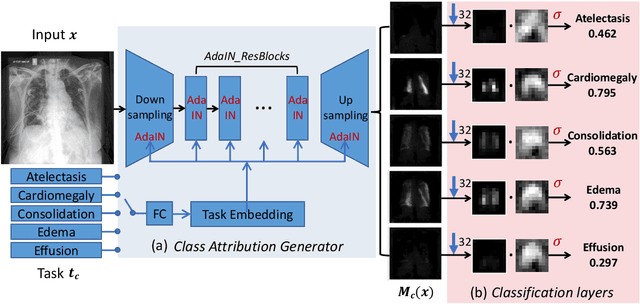
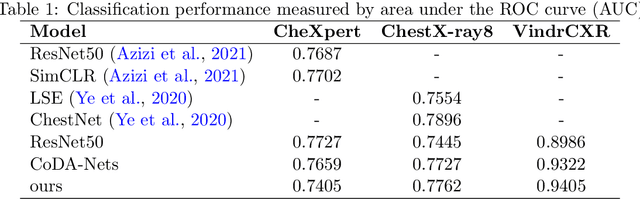
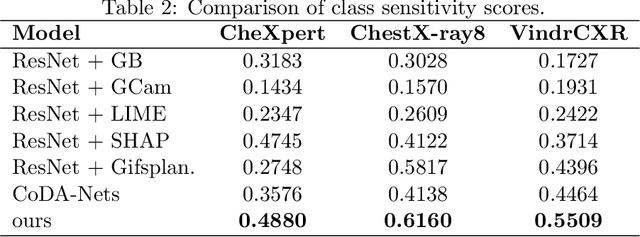
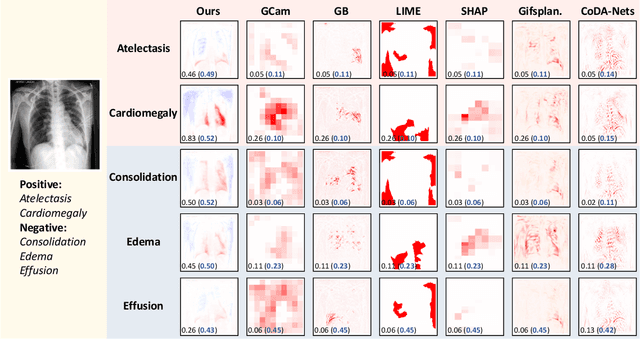
Interpretability is essential for machine learning algorithms in high-stakes application fields such as medical image analysis. However, high-performing black-box neural networks do not provide explanations for their predictions, which can lead to mistrust and suboptimal human-ML collaboration. Post-hoc explanation techniques, which are widely used in practice, have been shown to suffer from severe conceptual problems. Furthermore, as we show in this paper, current explanation techniques do not perform adequately in the multi-label scenario, in which multiple medical findings may co-occur in a single image. We propose Attri-Net, an inherently interpretable model for multi-label classification. Attri-Net is a powerful classifier that provides transparent, trustworthy, and human-understandable explanations. The model first generates class-specific attribution maps based on counterfactuals to identify which image regions correspond to certain medical findings. Then a simple logistic regression classifier is used to make predictions based solely on these attribution maps. We compare Attri-Net to five post-hoc explanation techniques and one inherently interpretable classifier on three chest X-ray datasets. We find that Attri-Net produces high-quality multi-label explanations consistent with clinical knowledge and has comparable classification performance to state-of-the-art classification models.
SLMT-Net: A Self-supervised Learning based Multi-scale Transformer Network for Cross-Modality MR Image Synthesis
Dec 02, 2022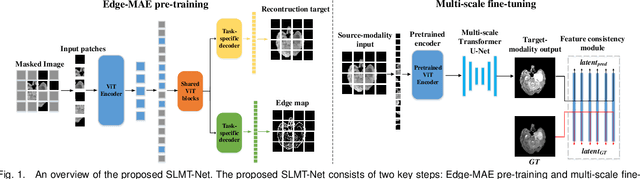
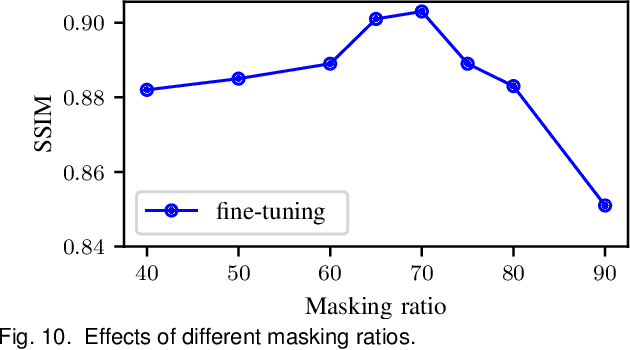
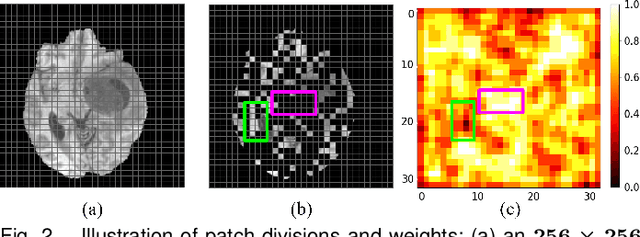
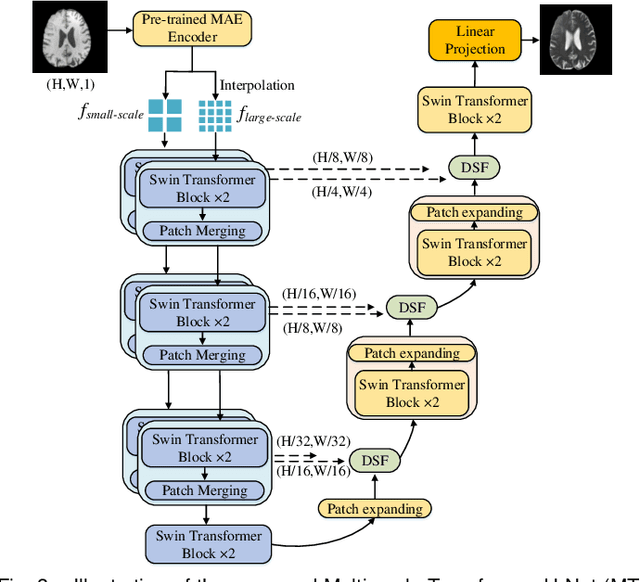
Cross-modality magnetic resonance (MR) image synthesis aims to produce missing modalities from existing ones. Currently, several methods based on deep neural networks have been developed using both source- and target-modalities in a supervised learning manner. However, it remains challenging to obtain a large amount of completely paired multi-modal training data, which inhibits the effectiveness of existing methods. In this paper, we propose a novel Self-supervised Learning-based Multi-scale Transformer Network (SLMT-Net) for cross-modality MR image synthesis, consisting of two stages, \ie, a pre-training stage and a fine-tuning stage. During the pre-training stage, we propose an Edge-preserving Masked AutoEncoder (Edge-MAE), which preserves the contextual and edge information by simultaneously conducting the image reconstruction and the edge generation. Besides, a patch-wise loss is proposed to treat the input patches differently regarding their reconstruction difficulty, by measuring the difference between the reconstructed image and the ground-truth. In this case, our Edge-MAE can fully leverage a large amount of unpaired multi-modal data to learn effective feature representations. During the fine-tuning stage, we present a Multi-scale Transformer U-Net (MT-UNet) to synthesize the target-modality images, in which a Dual-scale Selective Fusion (DSF) module is proposed to fully integrate multi-scale features extracted from the encoder of the pre-trained Edge-MAE. Moreover, we use the pre-trained encoder as a feature consistency module to measure the difference between high-level features of the synthesized image and the ground truth one. Experimental results show the effectiveness of the proposed SLMT-Net, and our model can reliably synthesize high-quality images when the training set is partially unpaired. Our code will be publicly available at https://github.com/lyhkevin/SLMT-Net.
You Only Train Once: Learning a General Anomaly Enhancement Network with Random Masks for Hyperspectral Anomaly Detection
Mar 31, 2023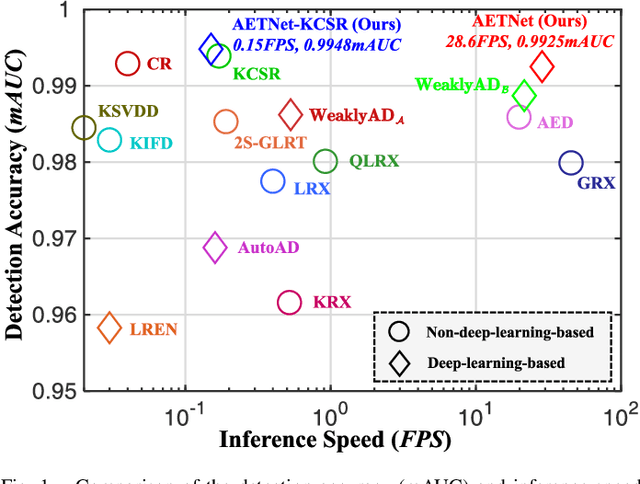
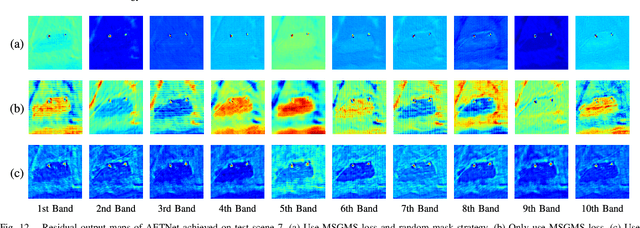
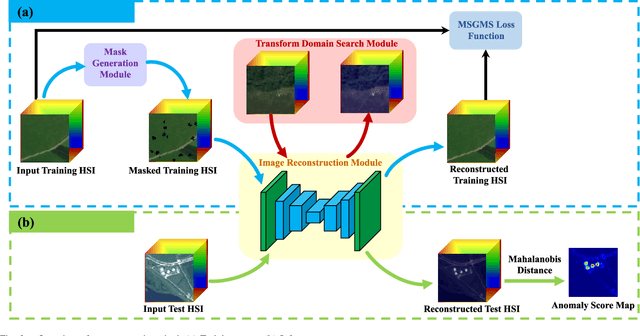
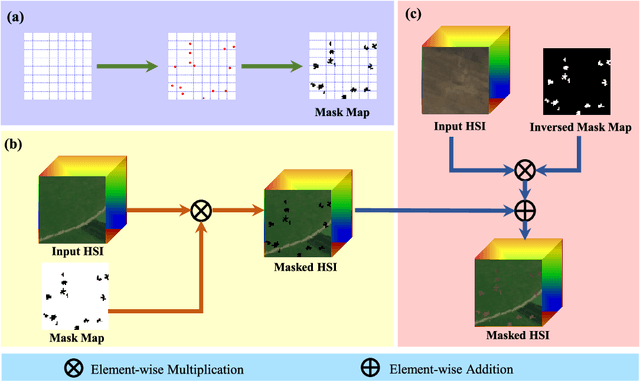
In this paper, we introduce a new approach to address the challenge of generalization in hyperspectral anomaly detection (AD). Our method eliminates the need for adjusting parameters or retraining on new test scenes as required by most existing methods. Employing an image-level training paradigm, we achieve a general anomaly enhancement network for hyperspectral AD that only needs to be trained once. Trained on a set of anomaly-free hyperspectral images with random masks, our network can learn the spatial context characteristics between anomalies and background in an unsupervised way. Additionally, a plug-and-play model selection module is proposed to search for a spatial-spectral transform domain that is more suitable for AD task than the original data. To establish a unified benchmark to comprehensively evaluate our method and existing methods, we develop a large-scale hyperspectral AD dataset (HAD100) that includes 100 real test scenes with diverse anomaly targets. In comparison experiments, we combine our network with a parameter-free detector and achieve the optimal balance between detection accuracy and inference speed among state-of-the-art AD methods. Experimental results also show that our method still achieves competitive performance when the training and test set are captured by different sensor devices. Our code is available at https://github.com/ZhaoxuLi123/AETNet.
Few-shot Image Generation via Masked Discrimination
Oct 27, 2022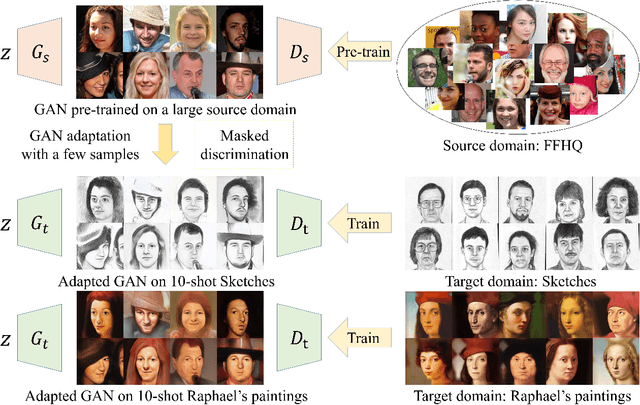
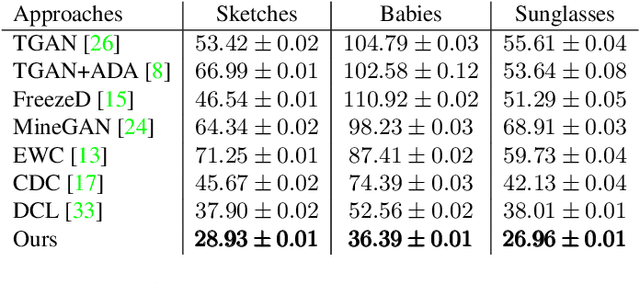
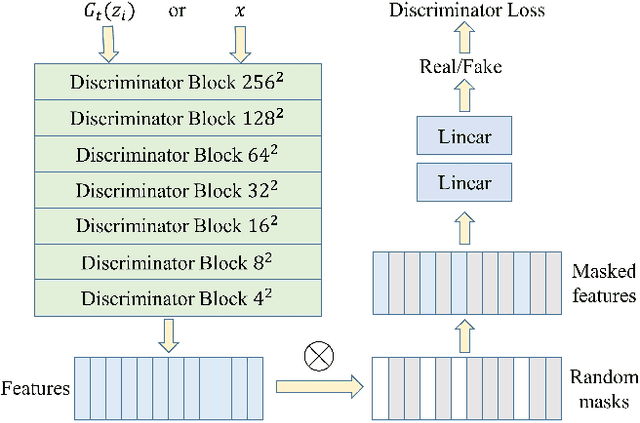

Few-shot image generation aims to generate images of high quality and great diversity with limited data. However, it is difficult for modern GANs to avoid overfitting when trained on only a few images. The discriminator can easily remember all the training samples and guide the generator to replicate them, leading to severe diversity degradation. Several methods have been proposed to relieve overfitting by adapting GANs pre-trained on large source domains to target domains with limited real samples. In this work, we present a novel approach to realize few-shot GAN adaptation via masked discrimination. Random masks are applied to features extracted by the discriminator from input images. We aim to encourage the discriminator to judge more diverse images which share partially common features with training samples as realistic images. Correspondingly, the generator is guided to generate more diverse images instead of replicating training samples. In addition, we employ cross-domain consistency loss for the discriminator to keep relative distances between samples in its feature space. The discriminator cross-domain consistency loss serves as another optimization target in addition to adversarial loss and guides adapted GANs to preserve more information learned from source domains for higher image quality. The effectiveness of our approach is demonstrated both qualitatively and quantitatively with higher quality and greater diversity on a series of few-shot image generation tasks than prior methods.
Image Completion with Heterogeneously Filtered Spectral Hints
Nov 07, 2022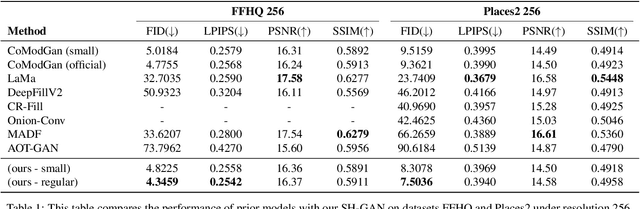
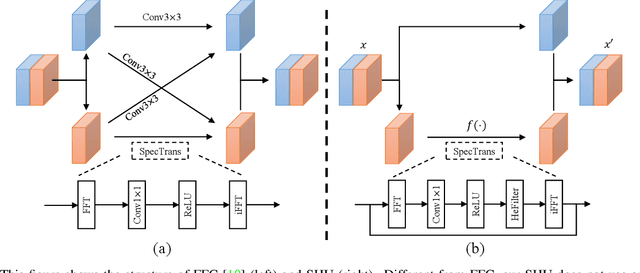
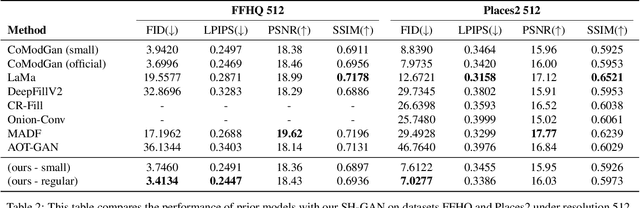
Image completion with large-scale free-form missing regions is one of the most challenging tasks for the computer vision community. While researchers pursue better solutions, drawbacks such as pattern unawareness, blurry textures, and structure distortion remain noticeable, and thus leave space for improvement. To overcome these challenges, we propose a new StyleGAN-based image completion network, Spectral Hint GAN (SH-GAN), inside which a carefully designed spectral processing module, Spectral Hint Unit, is introduced. We also propose two novel 2D spectral processing strategies, Heterogeneous Filtering and Gaussian Split that well-fit modern deep learning models and may further be extended to other tasks. From our inclusive experiments, we demonstrate that our model can reach FID scores of 3.4134 and 7.0277 on the benchmark datasets FFHQ and Places2, and therefore outperforms prior works and reaches a new state-of-the-art. We also prove the effectiveness of our design via ablation studies, from which one may notice that the aforementioned challenges, i.e. pattern unawareness, blurry textures, and structure distortion, can be noticeably resolved. Our code will be open-sourced at: https://github.com/SHI-Labs/SH-GAN.