 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Attention-Based Generative Neural Image Compression on Solar Dynamics Observatory
Oct 12, 2022
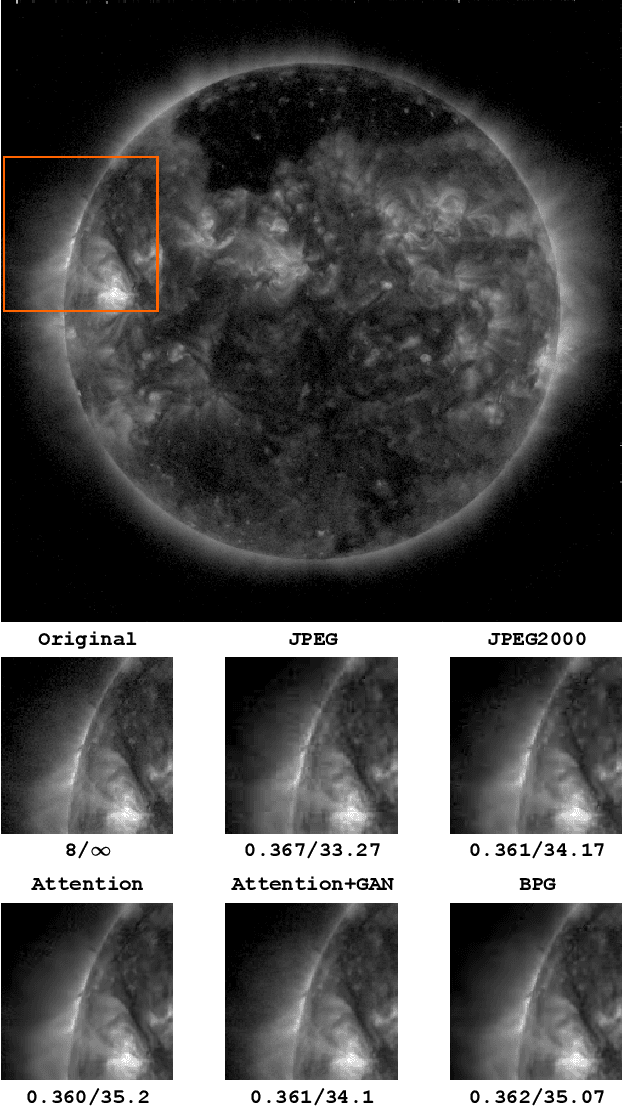
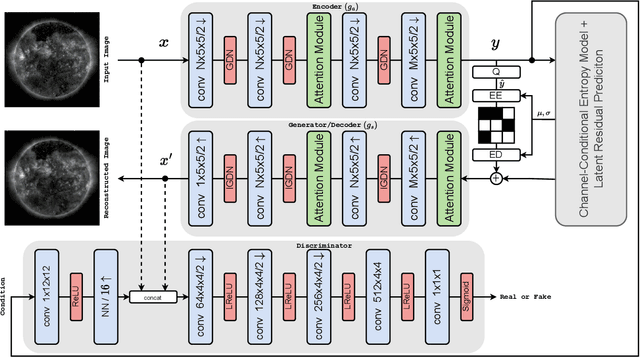
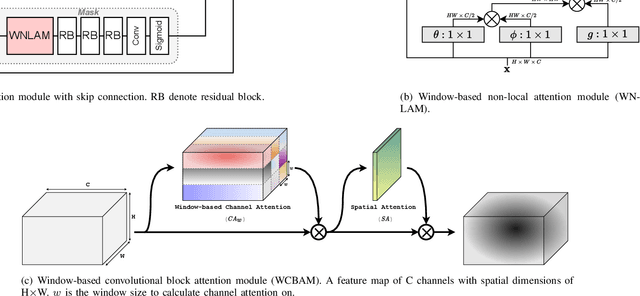
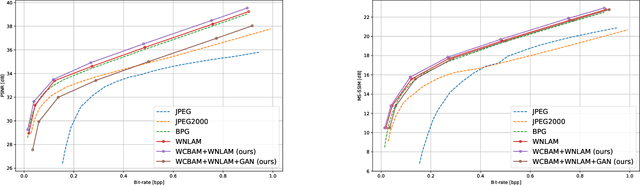
NASA's Solar Dynamics Observatory (SDO) mission gathers 1.4 terabytes of data each day from its geosynchronous orbit in space. SDO data includes images of the Sun captured at different wavelengths, with the primary scientific goal of understanding the dynamic processes governing the Sun. Recently, end-to-end optimized artificial neural networks (ANN) have shown great potential in performing image compression. ANN-based compression schemes have outperformed conventional hand-engineered algorithms for lossy and lossless image compression. We have designed an ad-hoc ANN-based image compression scheme to reduce the amount of data needed to be stored and retrieved on space missions studying solar dynamics. In this work, we propose an attention module to make use of both local and non-local attention mechanisms in an adversarially trained neural image compression network. We have also demonstrated the superior perceptual quality of this neural image compressor. Our proposed algorithm for compressing images downloaded from the SDO spacecraft performs better in rate-distortion trade-off than the popular currently-in-use image compression codecs such as JPEG and JPEG2000. In addition we have shown that the proposed method outperforms state-of-the art lossy transform coding compression codec, i.e., BPG.
Depth- and Semantics-aware Multi-modal Domain Translation: Generating 3D Panoramic Color Images from LiDAR Point Clouds
Feb 15, 2023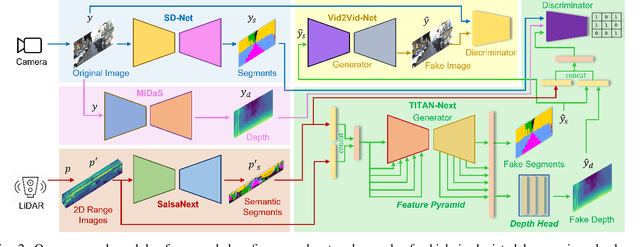



This work presents a new depth- and semantics-aware conditional generative model, named TITAN-Next, for cross-domain image-to-image translation in a multi-modal setup between LiDAR and camera sensors. The proposed model leverages scene semantics as a mid-level representation and is able to translate raw LiDAR point clouds to RGB-D camera images by solely relying on semantic scene segments. We claim that this is the first framework of its kind and it has practical applications in autonomous vehicles such as providing a fail-safe mechanism and augmenting available data in the target image domain. The proposed model is evaluated on the large-scale and challenging Semantic-KITTI dataset, and experimental findings show that it considerably outperforms the original TITAN-Net and other strong baselines by 23.7$\%$ margin in terms of IoU.
ZeroNLG: Aligning and Autoencoding Domains for Zero-Shot Multimodal and Multilingual Natural Language Generation
Mar 11, 2023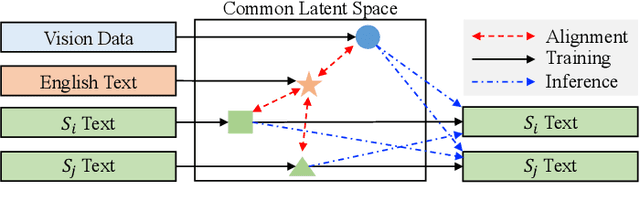
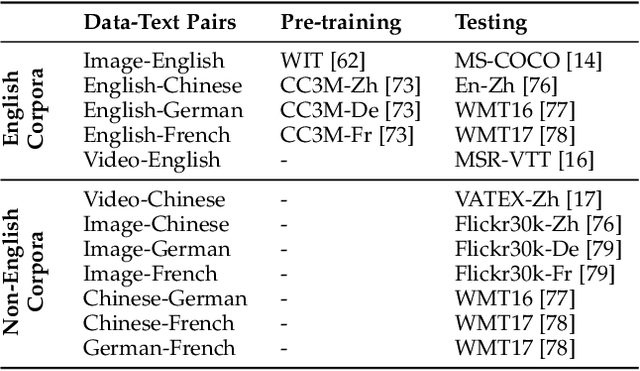
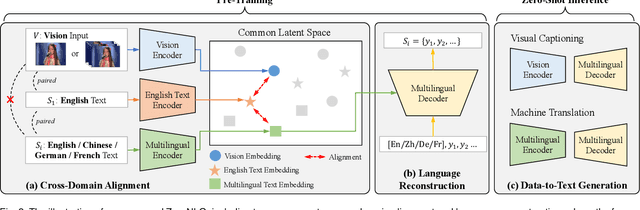
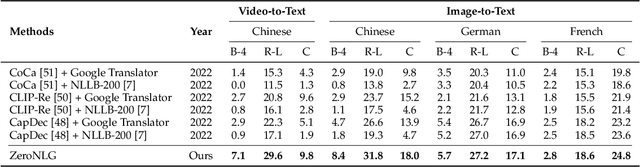
Natural Language Generation (NLG) accepts input data in the form of images, videos, or text and generates corresponding natural language text as output. Existing NLG methods mainly adopt a supervised approach and rely heavily on coupled data-to-text pairs. However, for many targeted scenarios and for non-English languages, sufficient quantities of labeled data are often not available. To relax the dependency on labeled data of downstream tasks, we propose an intuitive and effective zero-shot learning framework, ZeroNLG, which can deal with multiple NLG tasks, including image-to-text (image captioning), video-to-text (video captioning), and text-to-text (neural machine translation), across English, Chinese, German, and French within a unified framework. ZeroNLG does not require any labeled downstream pairs for training. During training, ZeroNLG (i) projects different domains (across modalities and languages) to corresponding coordinates in a shared common latent space; (ii) bridges different domains by aligning their corresponding coordinates in this space; and (iii) builds an unsupervised multilingual auto-encoder to learn to generate text by reconstructing the input text given its coordinate in shared latent space. Consequently, during inference, based on the data-to-text pipeline, ZeroNLG can generate target sentences across different languages given the coordinate of input data in the common space. Within this unified framework, given visual (imaging or video) data as input, ZeroNLG can perform zero-shot visual captioning; given textual sentences as input, ZeroNLG can perform zero-shot machine translation. We present the results of extensive experiments on twelve NLG tasks, showing that, without using any labeled downstream pairs for training, ZeroNLG generates high-quality and believable outputs and significantly outperforms existing zero-shot methods.
FastViT: A Fast Hybrid Vision Transformer using Structural Reparameterization
Mar 24, 2023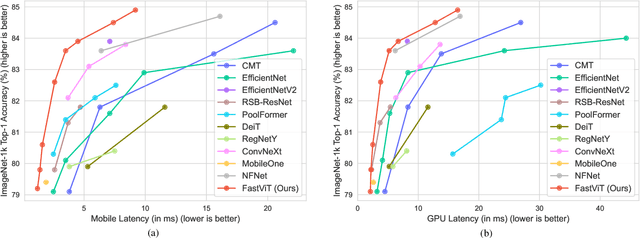
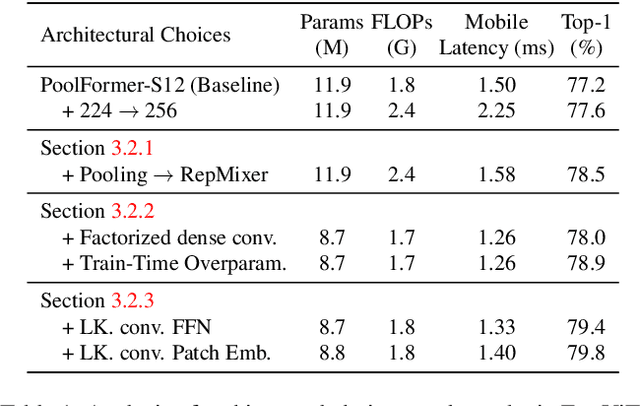
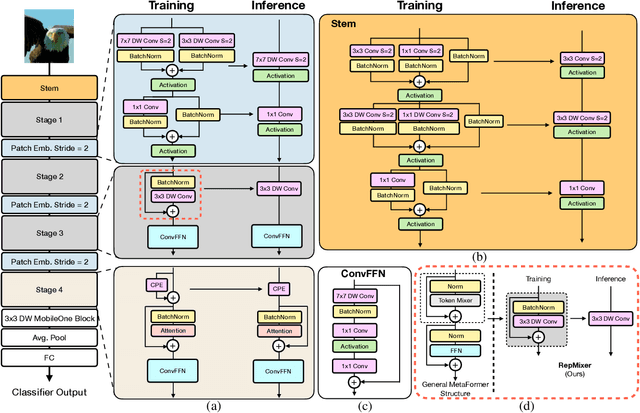
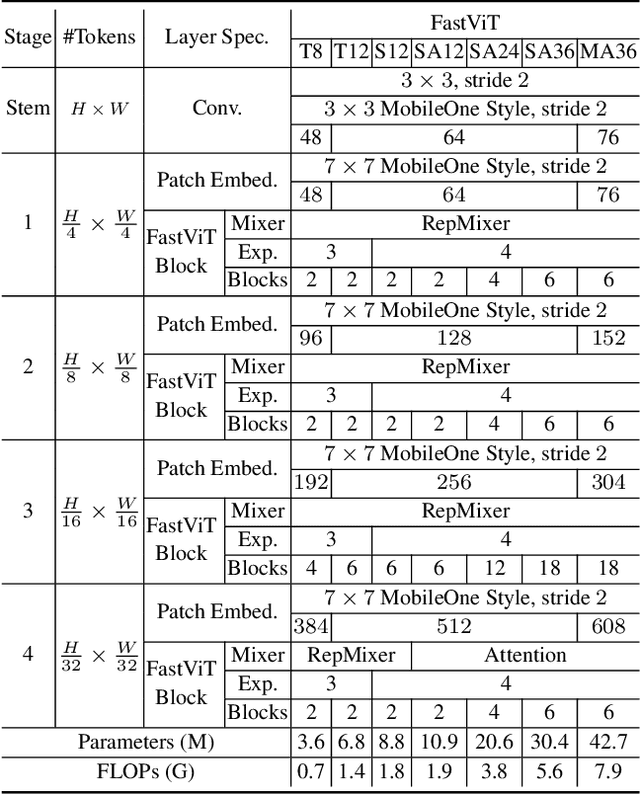
The recent amalgamation of transformer and convolutional designs has led to steady improvements in accuracy and efficiency of the models. In this work, we introduce FastViT, a hybrid vision transformer architecture that obtains the state-of-the-art latency-accuracy trade-off. To this end, we introduce a novel token mixing operator, RepMixer, a building block of FastViT, that uses structural reparameterization to lower the memory access cost by removing skip-connections in the network. We further apply train-time overparametrization and large kernel convolutions to boost accuracy and empirically show that these choices have minimal effect on latency. We show that - our model is 3.5x faster than CMT, a recent state-of-the-art hybrid transformer architecture, 4.9x faster than EfficientNet, and 1.9x faster than ConvNeXt on a mobile device for the same accuracy on the ImageNet dataset. At similar latency, our model obtains 4.2% better Top-1 accuracy on ImageNet than MobileOne. Our model consistently outperforms competing architectures across several tasks -- image classification, detection, segmentation and 3D mesh regression with significant improvement in latency on both a mobile device and a desktop GPU. Furthermore, our model is highly robust to out-of-distribution samples and corruptions, improving over competing robust models.
A Three-Player GAN for Super-Resolution in Magnetic Resonance Imaging
Mar 24, 2023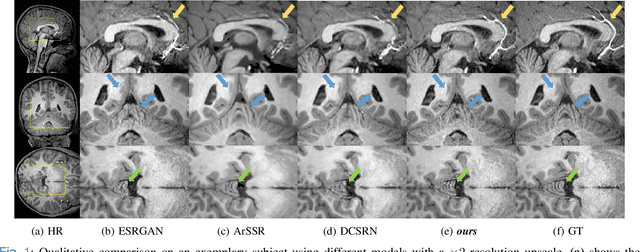
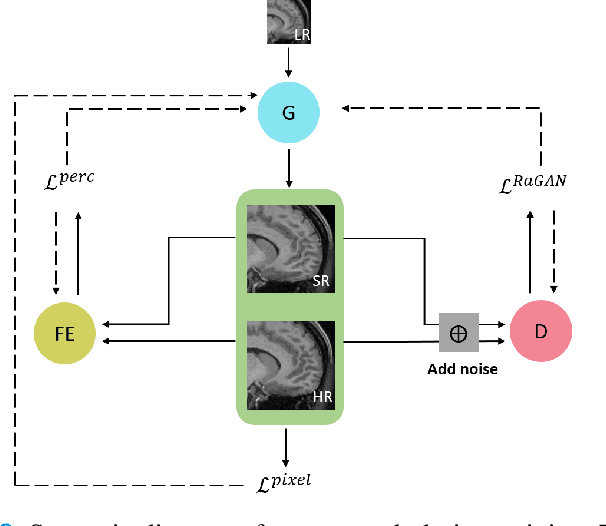
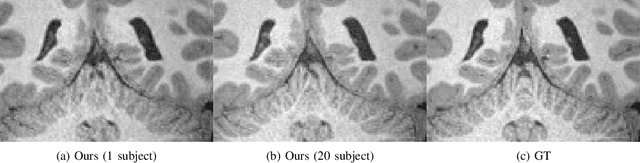
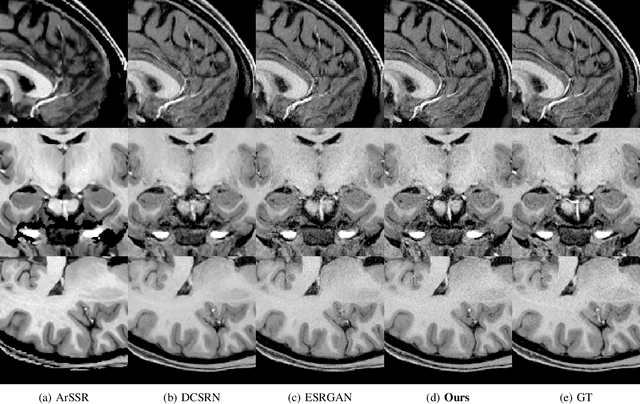
Learning based single image super resolution (SISR) task is well investigated in 2D images. However, SISR for 3D Magnetics Resonance Images (MRI) is more challenging compared to 2D, mainly due to the increased number of neural network parameters, the larger memory requirement and the limited amount of available training data. Current SISR methods for 3D volumetric images are based on Generative Adversarial Networks (GANs), especially Wasserstein GANs due to their training stability. Other common architectures in the 2D domain, e.g. transformer models, require large amounts of training data and are therefore not suitable for the limited 3D data. However, Wasserstein GANs can be problematic because they may not converge to a global optimum and thus produce blurry results. Here, we propose a new method for 3D SR based on the GAN framework. Specifically, we use instance noise to balance the GAN training. Furthermore, we use a relativistic GAN loss function and an updating feature extractor during the training process. We show that our method produces highly accurate results. We also show that we need very few training samples. In particular, we need less than 30 samples instead of thousands of training samples that are typically required in previous studies. Finally, we show improved out-of-sample results produced by our model.
Zero-guidance Segmentation Using Zero Segment Labels
Mar 24, 2023

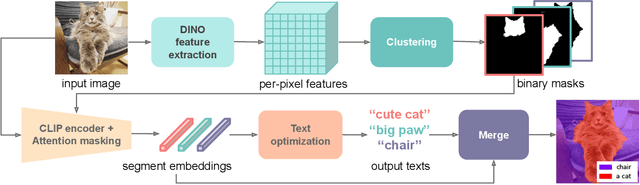

CLIP has enabled new and exciting joint vision-language applications, one of which is open-vocabulary segmentation, which can locate any segment given an arbitrary text query. In our research, we ask whether it is possible to discover semantic segments without any user guidance in the form of text queries or predefined classes, and label them using natural language automatically? We propose a novel problem zero-guidance segmentation and the first baseline that leverages two pre-trained generalist models, DINO and CLIP, to solve this problem without any fine-tuning or segmentation dataset. The general idea is to first segment an image into small over-segments, encode them into CLIP's visual-language space, translate them into text labels, and merge semantically similar segments together. The key challenge, however, is how to encode a visual segment into a segment-specific embedding that balances global and local context information, both useful for recognition. Our main contribution is a novel attention-masking technique that balances the two contexts by analyzing the attention layers inside CLIP. We also introduce several metrics for the evaluation of this new task. With CLIP's innate knowledge, our method can precisely locate the Mona Lisa painting among a museum crowd. Project page: https://zero-guide-seg.github.io/.
2PCNet: Two-Phase Consistency Training for Day-to-Night Unsupervised Domain Adaptive Object Detection
Mar 24, 2023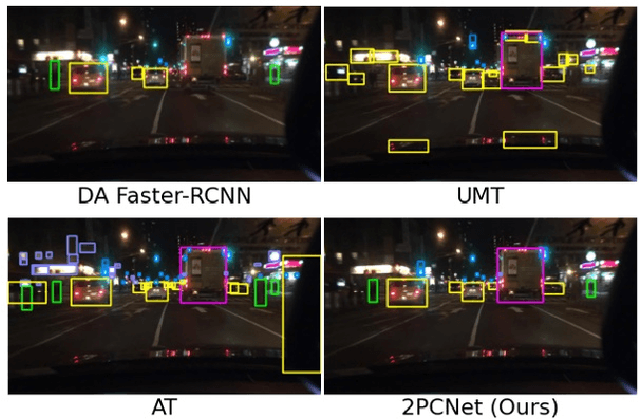
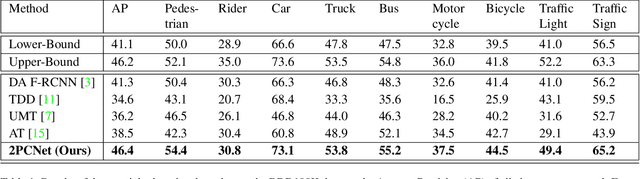
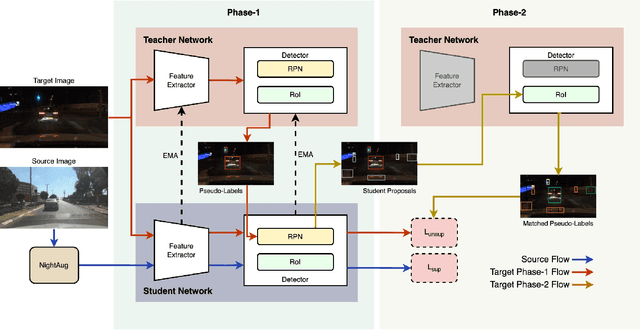
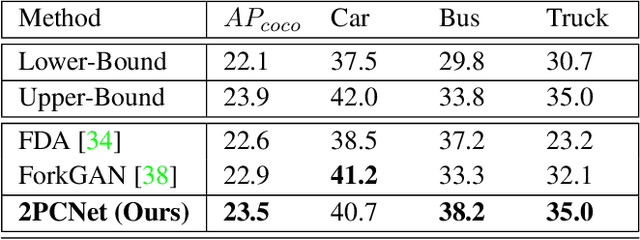
Object detection at night is a challenging problem due to the absence of night image annotations. Despite several domain adaptation methods, achieving high-precision results remains an issue. False-positive error propagation is still observed in methods using the well-established student-teacher framework, particularly for small-scale and low-light objects. This paper proposes a two-phase consistency unsupervised domain adaptation network, 2PCNet, to address these issues. The network employs high-confidence bounding-box predictions from the teacher in the first phase and appends them to the student's region proposals for the teacher to re-evaluate in the second phase, resulting in a combination of high and low confidence pseudo-labels. The night images and pseudo-labels are scaled-down before being used as input to the student, providing stronger small-scale pseudo-labels. To address errors that arise from low-light regions and other night-related attributes in images, we propose a night-specific augmentation pipeline called NightAug. This pipeline involves applying random augmentations, such as glare, blur, and noise, to daytime images. Experiments on publicly available datasets demonstrate that our method achieves superior results to state-of-the-art methods by 20\%, and to supervised models trained directly on the target data.
A-MuSIC: An Adaptive Ensemble System For Visual Place Recognition In Changing Environments
Mar 24, 2023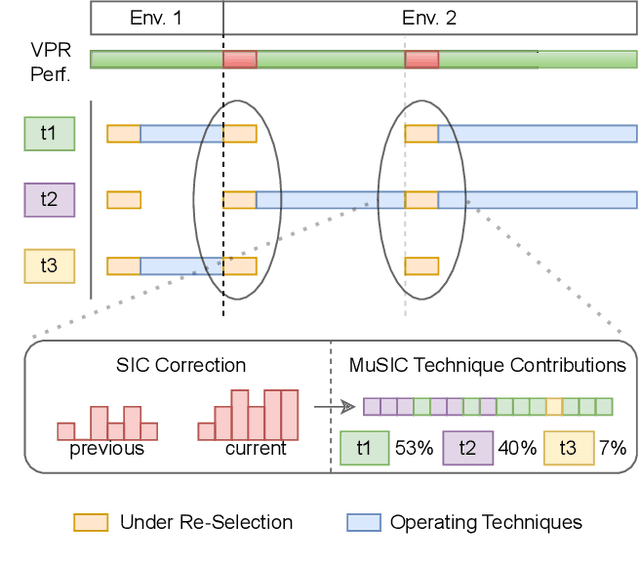
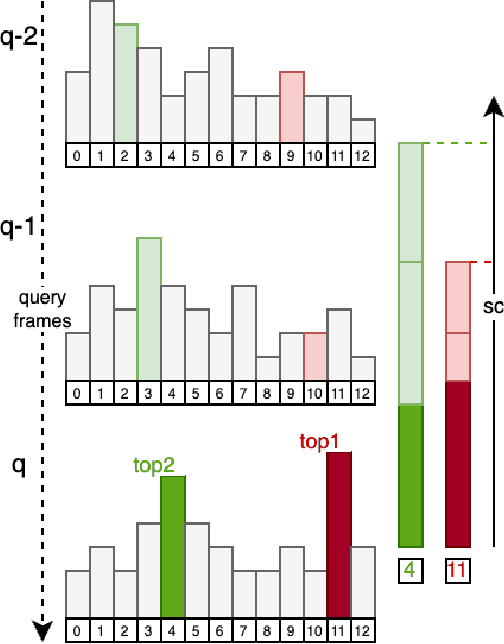
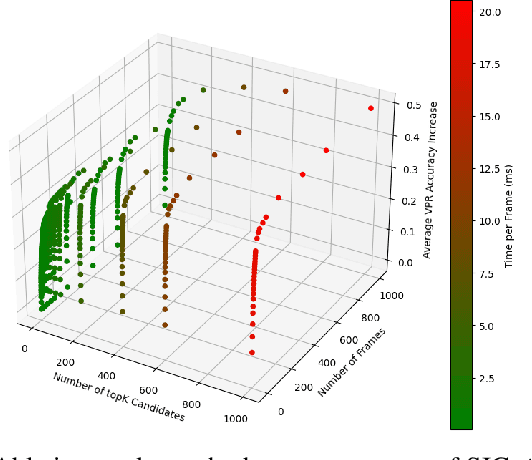
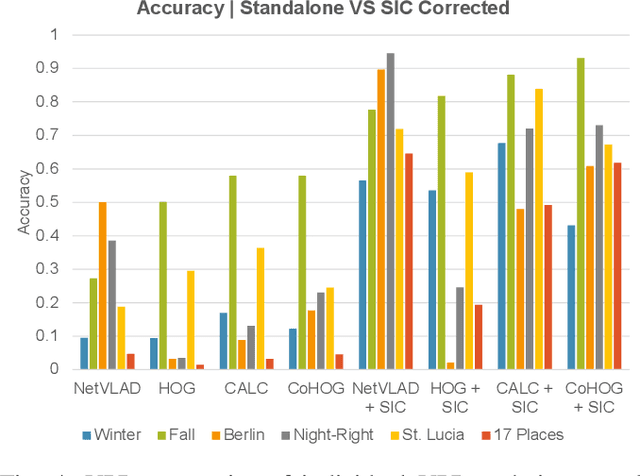
Visual place recognition (VPR) is an essential component of robot navigation and localization systems that allows them to identify a place using only image data. VPR is challenging due to the significant changes in a place's appearance under different illumination throughout the day, with seasonal weather and when observed from different viewpoints. Currently, no single VPR technique excels in every environmental condition, each exhibiting unique benefits and shortcomings. As a result, VPR systems combining multiple techniques achieve more reliable VPR performance in changing environments, at the cost of higher computational loads. Addressing this shortcoming, we propose an adaptive VPR system dubbed Adaptive Multi-Self Identification and Correction (A-MuSIC). We start by developing a method to collect information of the runtime performance of a VPR technique by analysing the frame-to-frame continuity of matched queries. We then demonstrate how to operate the method on a static ensemble of techniques, generating data on which techniques are contributing the most for the current environment. A-MuSIC uses the collected information to both select a minimal subset of techniques and to decide when a re-selection is required during navigation. A-MuSIC matches or beats state-of-the-art VPR performance across all tested benchmark datasets while maintaining its computational load on par with individual techniques.
Seeing Through the Glass: Neural 3D Reconstruction of Object Inside a Transparent Container
Mar 24, 2023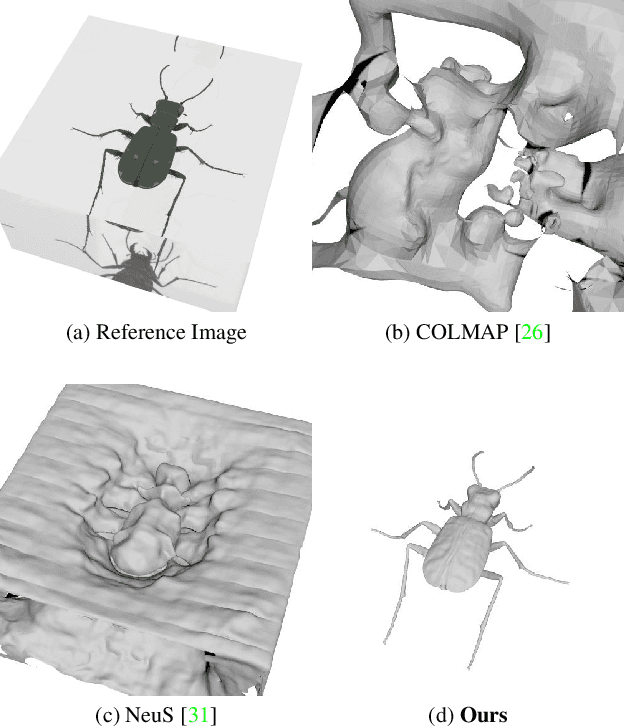
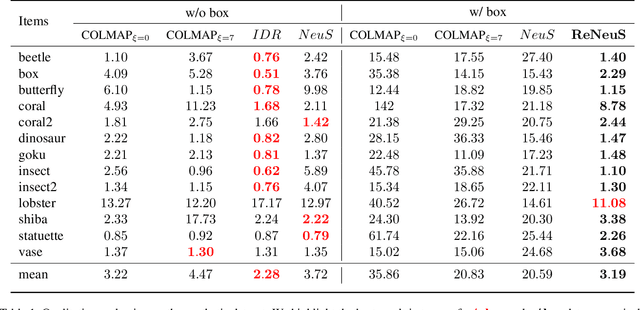
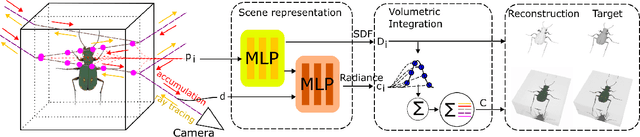

In this paper, we define a new problem of recovering the 3D geometry of an object confined in a transparent enclosure. We also propose a novel method for solving this challenging problem. Transparent enclosures pose challenges of multiple light reflections and refractions at the interface between different propagation media e.g. air or glass. These multiple reflections and refractions cause serious image distortions which invalidate the single viewpoint assumption. Hence the 3D geometry of such objects cannot be reliably reconstructed using existing methods, such as traditional structure from motion or modern neural reconstruction methods. We solve this problem by explicitly modeling the scene as two distinct sub-spaces, inside and outside the transparent enclosure. We use an existing neural reconstruction method (NeuS) that implicitly represents the geometry and appearance of the inner subspace. In order to account for complex light interactions, we develop a hybrid rendering strategy that combines volume rendering with ray tracing. We then recover the underlying geometry and appearance of the model by minimizing the difference between the real and hybrid rendered images. We evaluate our method on both synthetic and real data. Experiment results show that our method outperforms the state-of-the-art (SOTA) methods. Codes and data will be available at https://github.com/hirotong/ReNeuS
Classy Ensemble: A Novel Ensemble Algorithm for Classification
Mar 05, 2023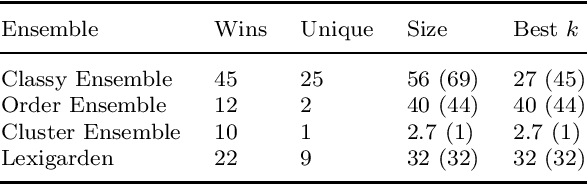
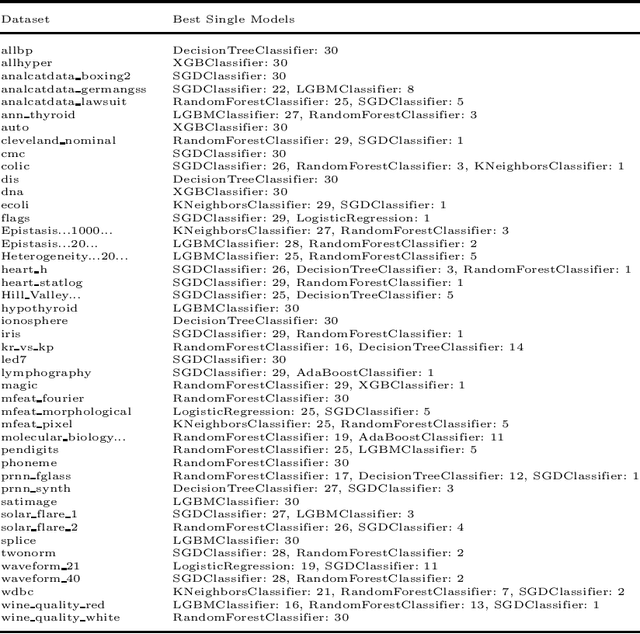
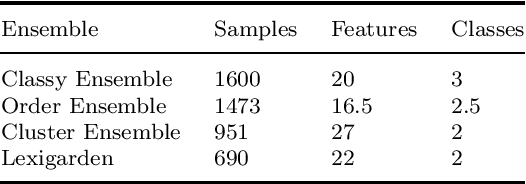
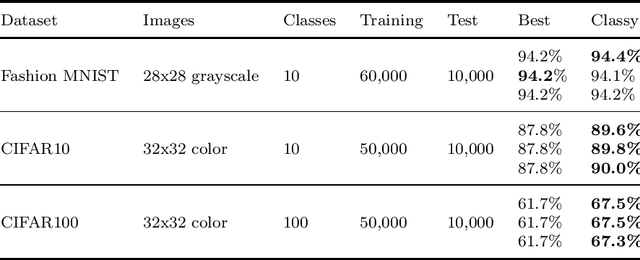
We present Classy Ensemble, a novel ensemble-generation algorithm for classification tasks, which aggregates models through a weighted combination of per-class accuracy. Tested over 153 machine learning datasets we demonstrate that Classy Ensemble outperforms two other well-known aggregation algorithms -- order-based pruning and clustering-based pruning -- as well as the recently introduced lexigarden ensemble generator. Classy Ensemble also fares favorably with deep networks, over four image datasets: Fashion MNIST, CIFAR10, CIFAR100, and ImageNet.