 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Adversarial Counterfactual Visual Explanations
Mar 17, 2023
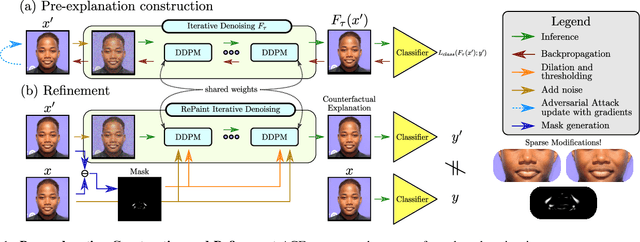
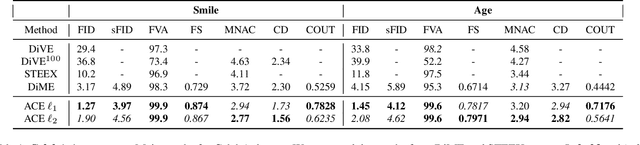
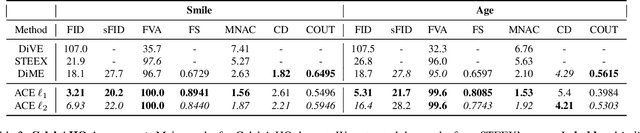

Counterfactual explanations and adversarial attacks have a related goal: flipping output labels with minimal perturbations regardless of their characteristics. Yet, adversarial attacks cannot be used directly in a counterfactual explanation perspective, as such perturbations are perceived as noise and not as actionable and understandable image modifications. Building on the robust learning literature, this paper proposes an elegant method to turn adversarial attacks into semantically meaningful perturbations, without modifying the classifiers to explain. The proposed approach hypothesizes that Denoising Diffusion Probabilistic Models are excellent regularizers for avoiding high-frequency and out-of-distribution perturbations when generating adversarial attacks. The paper's key idea is to build attacks through a diffusion model to polish them. This allows studying the target model regardless of its robustification level. Extensive experimentation shows the advantages of our counterfactual explanation approach over current State-of-the-Art in multiple testbeds.
A Pathway Towards Responsible AI Generated Content
Mar 17, 2023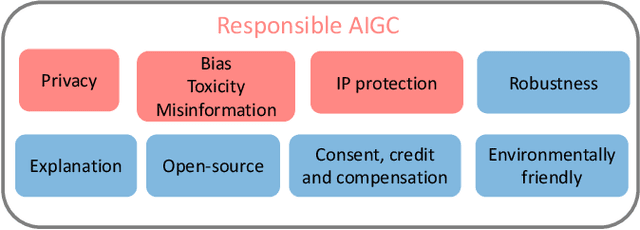
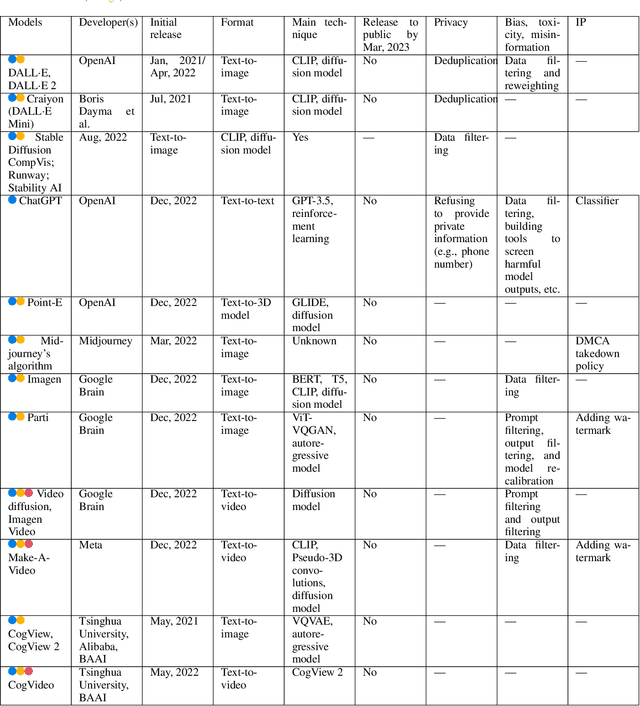
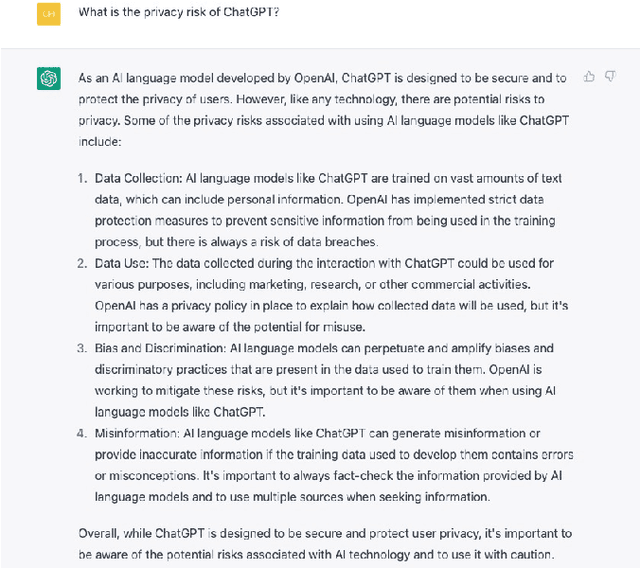

AI Generated Content (AIGC) has received tremendous attention within the past few years, with content ranging from image, text, to audio, video, etc. Meanwhile, AIGC has become a double-edged sword and recently received much criticism regarding its responsible usage. In this vision paper, we focus on three main concerns that may hinder the healthy development and deployment of AIGC in practice, including risks from privacy, bias, toxicity, misinformation, and intellectual property (IP). By documenting known and potential risks, as well as any possible misuse scenarios of AIGC, the aim is to draw attention to potential risks and misuse, help society to eliminate obstacles, and promote the more ethical and secure deployment of AIGC. Additionally, we provide insights into the promising directions for tackling these risks while constructing generative models, enabling AIGC to be used responsibly to benefit society.
Learning Stationary Markov Processes with Contrastive Adjustment
Mar 17, 2023
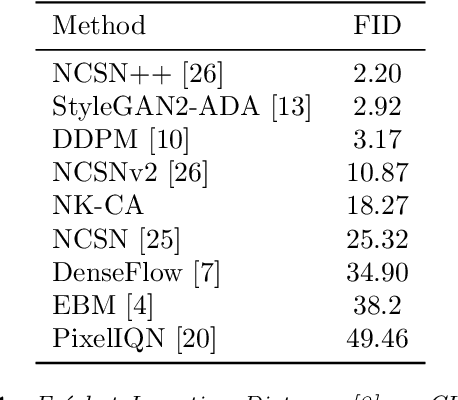
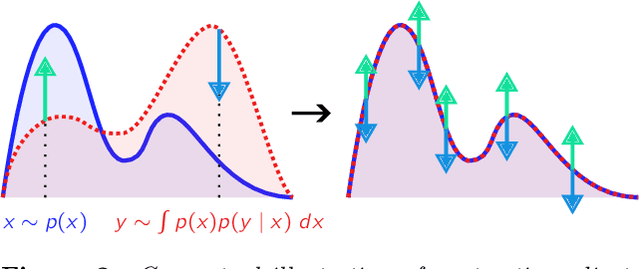
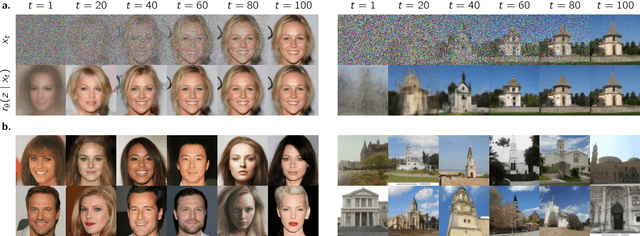
We introduce a new optimization algorithm, termed contrastive adjustment, for learning Markov transition kernels whose stationary distribution matches the data distribution. Contrastive adjustment is not restricted to a particular family of transition distributions and can be used to model data in both continuous and discrete state spaces. Inspired by recent work on noise-annealed sampling, we propose a particular transition operator, the noise kernel, that can trade mixing speed for sample fidelity. We show that contrastive adjustment is highly valuable in human-computer design processes, as the stationarity of the learned Markov chain enables local exploration of the data manifold and makes it possible to iteratively refine outputs by human feedback. We compare the performance of noise kernels trained with contrastive adjustment to current state-of-the-art generative models and demonstrate promising results on a variety of image synthesis tasks.
Operating critical machine learning models in resource constrained regimes
Mar 17, 2023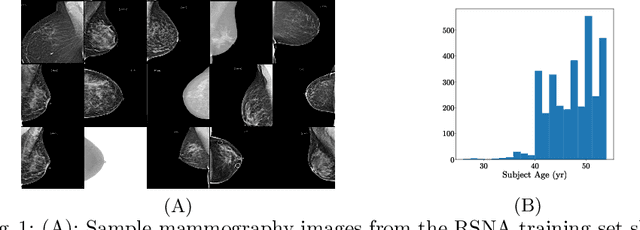
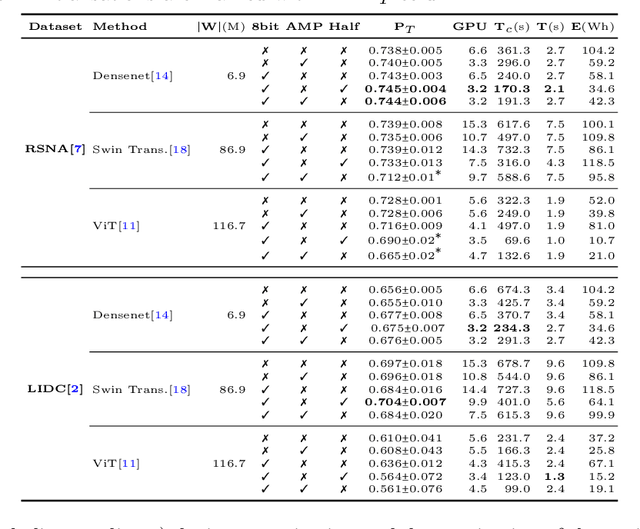

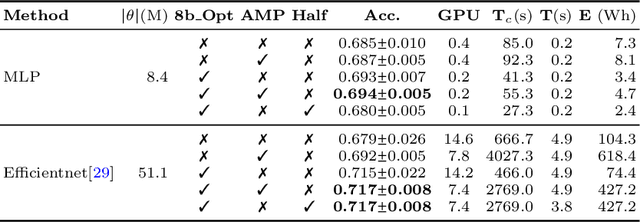
The accelerated development of machine learning methods, primarily deep learning, are causal to the recent breakthroughs in medical image analysis and computer aided intervention. The resource consumption of deep learning models in terms of amount of training data, compute and energy costs are known to be massive. These large resource costs can be barriers in deploying these models in clinics, globally. To address this, there are cogent efforts within the machine learning community to introduce notions of resource efficiency. For instance, using quantisation to alleviate memory consumption. While most of these methods are shown to reduce the resource utilisation, they could come at a cost in performance. In this work, we probe into the trade-off between resource consumption and performance, specifically, when dealing with models that are used in critical settings such as in clinics.
Deep Learning-Assisted Localisation of Nanoparticles in synthetically generated two-photon microscopy images
Mar 17, 2023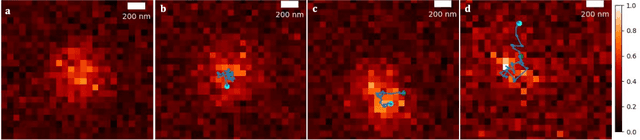
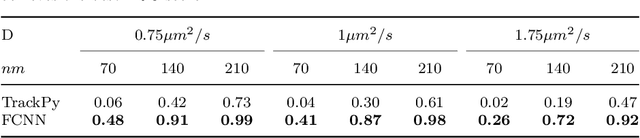

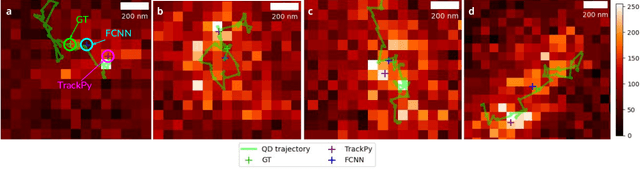
Tracking single molecules is instrumental for quantifying the transport of molecules and nanoparticles in biological samples, e.g., in brain drug delivery studies. Existing intensity-based localisation methods are not developed for imaging with a scanning microscope, typically used for in vivo imaging. Low signal-to-noise ratios, movement of molecules out-of-focus, and high motion blur on images recorded with scanning two-photon microscopy (2PM) in vivo pose a challenge to the accurate localisation of molecules. Using data-driven models is challenging due to low data volumes, typical for in vivo experiments. We developed a 2PM image simulator to supplement scarce training data. The simulator mimics realistic motion blur, background fluorescence, and shot noise observed in vivo imaging. Training a data-driven model with simulated data improves localisation quality in simulated images and shows why intensity-based methods fail.
ShabbyPages: A Reproducible Document Denoising and Binarization Dataset
Mar 17, 2023
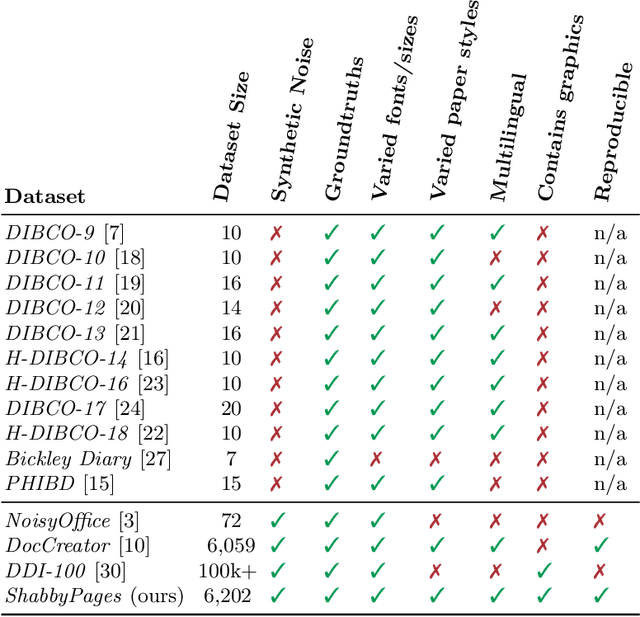

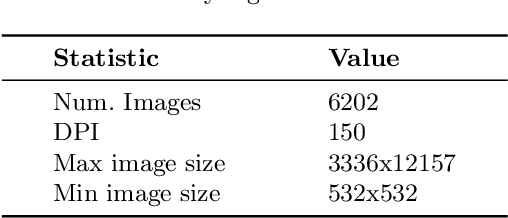
Document denoising and binarization are fundamental problems in the document processing space, but current datasets are often too small and lack sufficient complexity to effectively train and benchmark modern data-driven machine learning models. To fill this gap, we introduce ShabbyPages, a new document image dataset designed for training and benchmarking document denoisers and binarizers. ShabbyPages contains over 6,000 clean "born digital" images with synthetically-noised counterparts ("shabby pages") that were augmented using the Augraphy document augmentation tool to appear as if they have been printed and faxed, photocopied, or otherwise altered through physical processes. In this paper, we discuss the creation process of ShabbyPages and demonstrate the utility of ShabbyPages by training convolutional denoisers which remove real noise features with a high degree of human-perceptible fidelity, establishing baseline performance for a new ShabbyPages benchmark.
DDT: A Diffusion-Driven Transformer-based Framework for Human Mesh Recovery from a Video
Mar 23, 2023

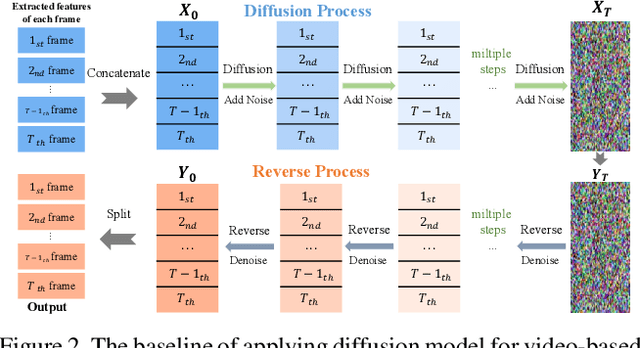
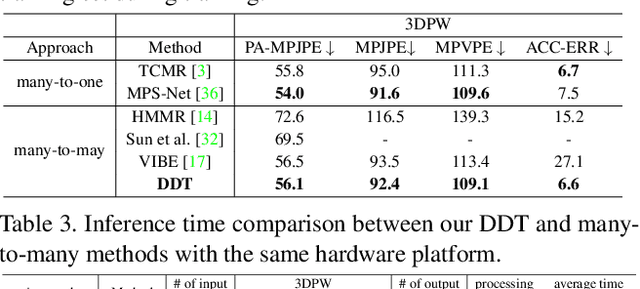
Human mesh recovery (HMR) provides rich human body information for various real-world applications such as gaming, human-computer interaction, and virtual reality. Compared to single image-based methods, video-based methods can utilize temporal information to further improve performance by incorporating human body motion priors. However, many-to-many approaches such as VIBE suffer from motion smoothness and temporal inconsistency. While many-to-one approaches such as TCMR and MPS-Net rely on the future frames, which is non-causal and time inefficient during inference. To address these challenges, a novel Diffusion-Driven Transformer-based framework (DDT) for video-based HMR is presented. DDT is designed to decode specific motion patterns from the input sequence, enhancing motion smoothness and temporal consistency. As a many-to-many approach, the decoder of our DDT outputs the human mesh of all the frames, making DDT more viable for real-world applications where time efficiency is crucial and a causal model is desired. Extensive experiments are conducted on the widely used datasets (Human3.6M, MPI-INF-3DHP, and 3DPW), which demonstrated the effectiveness and efficiency of our DDT.
SU-Net: Pose estimation network for non-cooperative spacecraft on-orbit
Feb 21, 2023
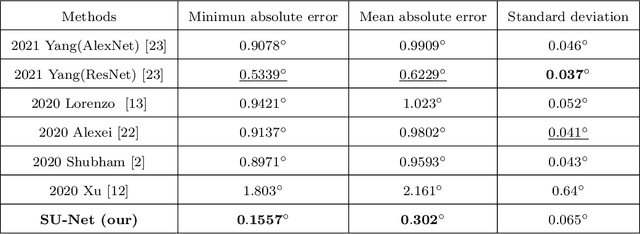
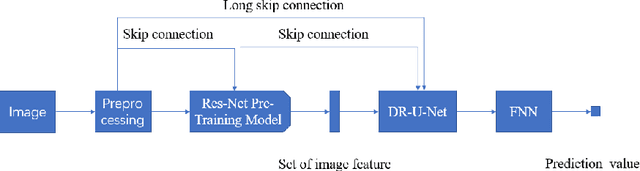
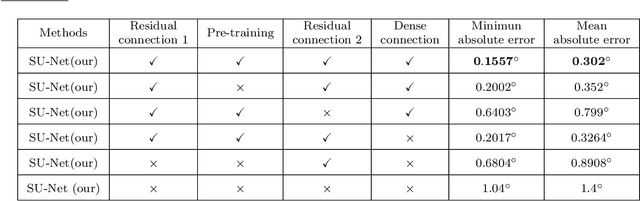
Spacecraft pose estimation plays a vital role in many on-orbit space missions, such as rendezvous and docking, debris removal, and on-orbit maintenance. At present, space images contain widely varying lighting conditions, high contrast and low resolution, pose estimation of space objects is more challenging than that of objects on earth. In this paper, we analyzing the radar image characteristics of spacecraft on-orbit, then propose a new deep learning neural Network structure named Dense Residual U-shaped Network (DR-U-Net) to extract image features. We further introduce a novel neural network based on DR-U-Net, namely Spacecraft U-shaped Network (SU-Net) to achieve end-to-end pose estimation for non-cooperative spacecraft. Specifically, the SU-Net first preprocess the image of non-cooperative spacecraft, then transfer learning was used for pre-training. Subsequently, in order to solve the problem of radar image blur and low ability of spacecraft contour recognition, we add residual connection and dense connection to the backbone network U-Net, and we named it DR-U-Net. In this way, the feature loss and the complexity of the model is reduced, and the degradation of deep neural network during training is avoided. Finally, a layer of feedforward neural network is used for pose estimation of non-cooperative spacecraft on-orbit. Experiments prove that the proposed method does not rely on the hand-made object specific features, and the model has robust robustness, and the calculation accuracy outperforms the state-of-the-art pose estimation methods. The absolute error is 0.1557 to 0.4491 , the mean error is about 0.302 , and the standard deviation is about 0.065 .
Rethinking Performance Gains in Image Dehazing Networks
Sep 23, 2022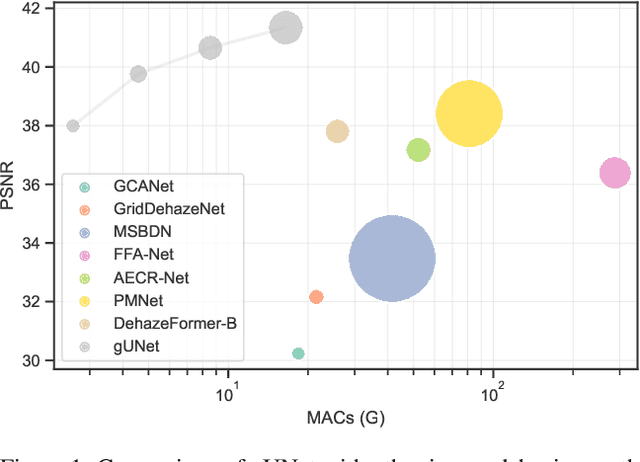
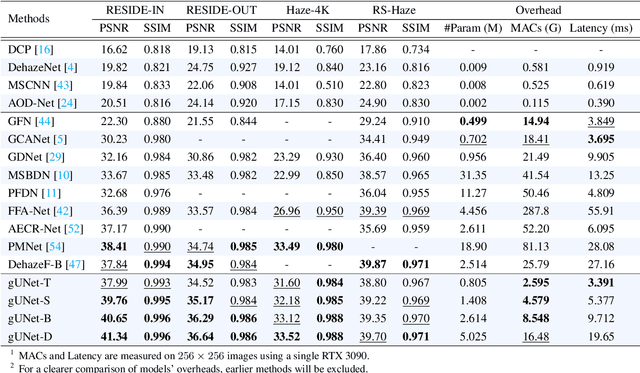
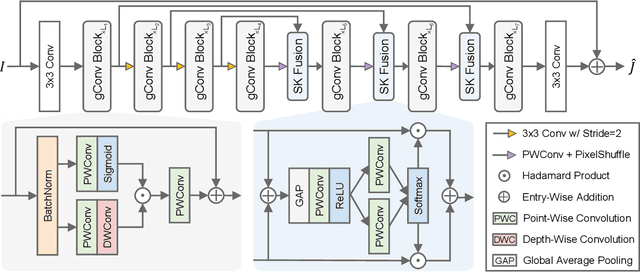
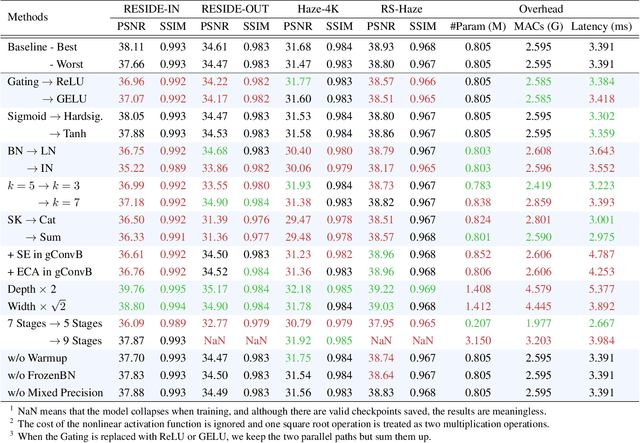
Image dehazing is an active topic in low-level vision, and many image dehazing networks have been proposed with the rapid development of deep learning. Although these networks' pipelines work fine, the key mechanism to improving image dehazing performance remains unclear. For this reason, we do not target to propose a dehazing network with fancy modules; rather, we make minimal modifications to popular U-Net to obtain a compact dehazing network. Specifically, we swap out the convolutional blocks in U-Net for residual blocks with the gating mechanism, fuse the feature maps of main paths and skip connections using the selective kernel, and call the resulting U-Net variant gUNet. As a result, with a significantly reduced overhead, gUNet is superior to state-of-the-art methods on multiple image dehazing datasets. Finally, we verify these key designs to the performance gain of image dehazing networks through extensive ablation studies.
Deep Curvilinear Editing: Commutative and Nonlinear Image Manipulation for Pretrained Deep Generative Model
Nov 26, 2022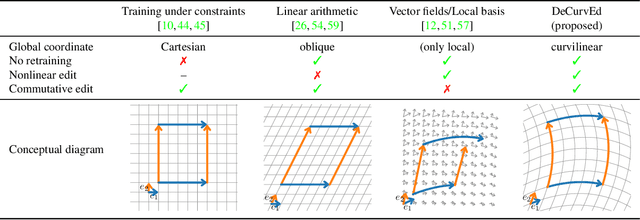
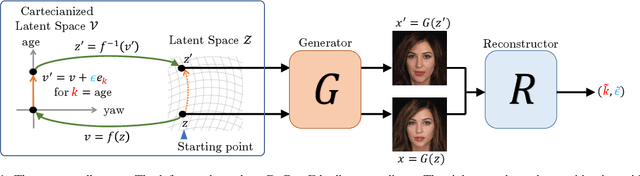


Semantic editing of images is the fundamental goal of computer vision. Although deep learning methods, such as generative adversarial networks (GANs), are capable of producing high-quality images, they often do not have an inherent way of editing generated images semantically. Recent studies have investigated a way of manipulating the latent variable to determine the images to be generated. However, methods that assume linear semantic arithmetic have certain limitations in terms of the quality of image editing, whereas methods that discover nonlinear semantic pathways provide non-commutative editing, which is inconsistent when applied in different orders. This study proposes a novel method called deep curvilinear editing (DeCurvEd) to determine semantic commuting vector fields on the latent space. We theoretically demonstrate that owing to commutativity, the editing of multiple attributes depends only on the quantities and not on the order. Furthermore, we experimentally demonstrate that compared to previous methods, the nonlinear and commutative nature of DeCurvEd facilitates the disentanglement of image attributes and provides higher-quality editing.