 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Road Redesign Technique Achieving Enhanced Road Safety by Inpainting with a Diffusion Model
Feb 15, 2023
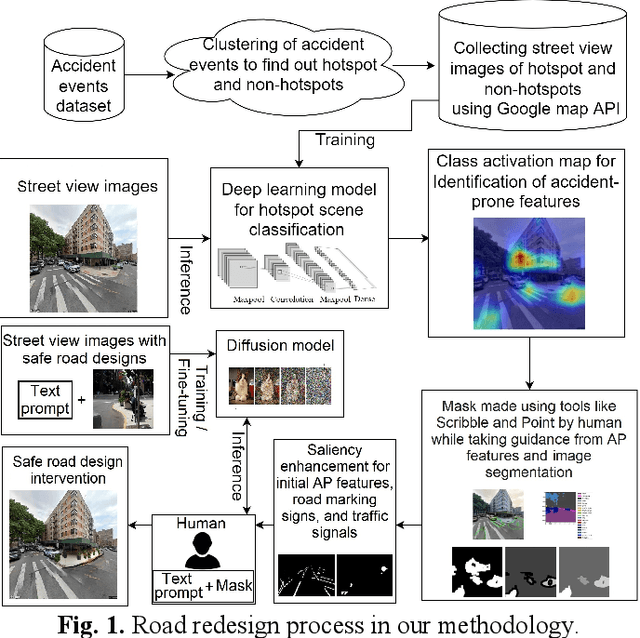
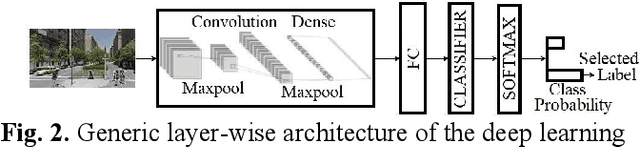

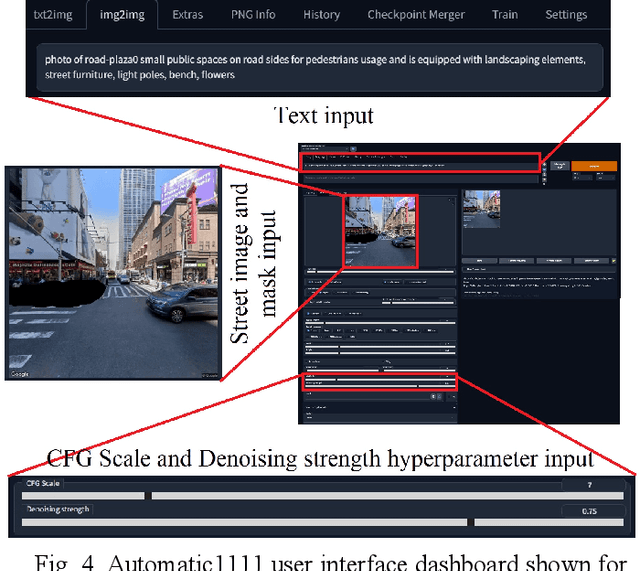
Road infrastructure can affect the occurrence of road accidents. Therefore, identifying roadway features with high accident probability is crucial. Here, we introduce image inpainting that can assist authorities in achieving safe roadway design with minimal intervention in the current roadway structure. Image inpainting is based on inpainting safe roadway elements in a roadway image, replacing accident-prone (AP) features by using a diffusion model. After object-level segmentation, the AP features identified by the properties of accident hotspots are masked by a human operator and safe roadway elements are inpainted. With only an average time of 2 min for image inpainting, the likelihood of an image being classified as an accident hotspot drops by an average of 11.85%. In addition, safe urban spaces can be designed considering human factors of commuters such as gaze saliency. Considering this, we introduce saliency enhancement that suggests chrominance alteration for a safe road view.
EPVT: Environment-aware Prompt Vision Transformer for Domain Generalization in Skin Lesion Recognition
Apr 04, 2023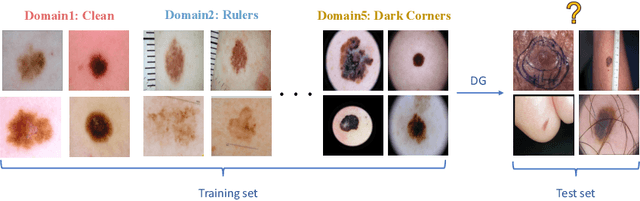
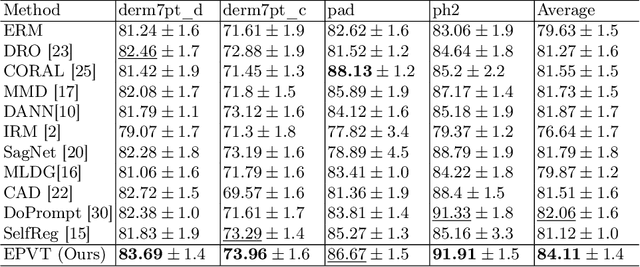
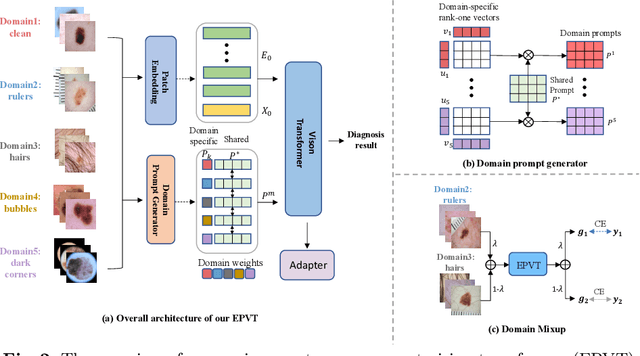
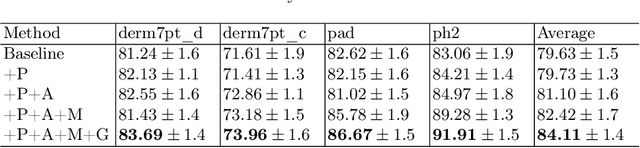
Skin lesion recognition using deep learning has made remarkable progress, and there is an increasing need for deploying these systems in real-world scenarios. However, recent research has revealed that deep neural networks for skin lesion recognition may overly depend on disease-irrelevant image artifacts (i.e. dark corners, dense hairs), leading to poor generalization in unseen environments. To address this issue, we propose a novel domain generalization method called EPVT, which involves embedding prompts into the vision transformer to collaboratively learn knowledge from diverse domains. Concretely, EPVT leverages a set of domain prompts, each of which plays as a domain expert, to capture domain-specific knowledge; and a shared prompt for general knowledge over the entire dataset. To facilitate knowledge sharing and the interaction of different prompts, we introduce a domain prompt generator that enables low-rank multiplicative updates between domain prompts and the shared prompt. A domain mixup strategy is additionally devised to reduce the co-occurring artifacts in each domain, which allows for more flexible decision margins and mitigates the issue of incorrectly assigned domain labels. Experiments on four out-of-distribution datasets and six different biased ISIC datasets demonstrate the superior generalization ability of EPVT in skin lesion recognition across various environments. Our code and dataset will be released at https://github.com/SiyuanYan1/EPVT.
Adaptive Ensemble Learning: Boosting Model Performance through Intelligent Feature Fusion in Deep Neural Networks
Apr 04, 2023In this paper, we present an Adaptive Ensemble Learning framework that aims to boost the performance of deep neural networks by intelligently fusing features through ensemble learning techniques. The proposed framework integrates ensemble learning strategies with deep learning architectures to create a more robust and adaptable model capable of handling complex tasks across various domains. By leveraging intelligent feature fusion methods, the Adaptive Ensemble Learning framework generates more discriminative and effective feature representations, leading to improved model performance and generalization capabilities. We conducted extensive experiments and evaluations on several benchmark datasets, including image classification, object detection, natural language processing, and graph-based learning tasks. The results demonstrate that the proposed framework consistently outperforms baseline models and traditional feature fusion techniques, highlighting its effectiveness in enhancing deep learning models' performance. Furthermore, we provide insights into the impact of intelligent feature fusion on model performance and discuss the potential applications of the Adaptive Ensemble Learning framework in real-world scenarios. The paper also explores the design and implementation of adaptive ensemble models, ensemble training strategies, and meta-learning techniques, which contribute to the framework's versatility and adaptability. In conclusion, the Adaptive Ensemble Learning framework represents a significant advancement in the field of feature fusion and ensemble learning for deep neural networks, with the potential to transform a wide range of applications across multiple domains.
Learning to Recover Spectral Reflectance from RGB Images
Apr 04, 2023
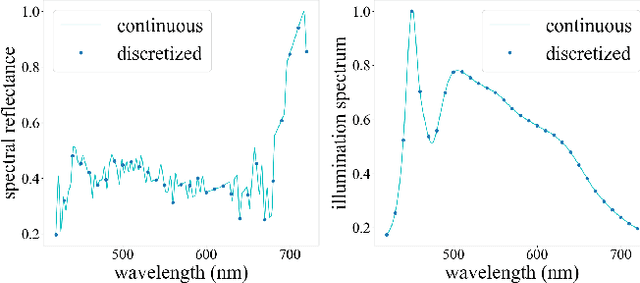
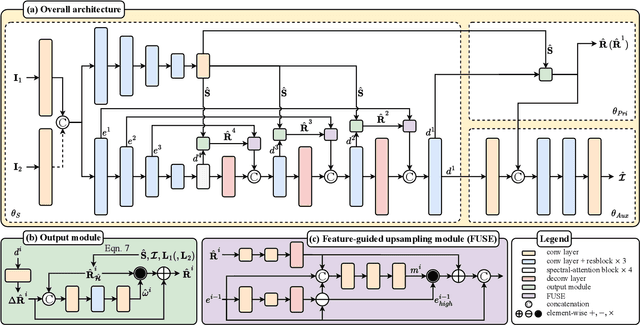

This paper tackles spectral reflectance recovery (SRR) from RGB images. Since capturing ground-truth spectral reflectance and camera spectral sensitivity are challenging and costly, most existing approaches are trained on synthetic images and utilize the same parameters for all unseen testing images, which are suboptimal especially when the trained models are tested on real images because they never exploit the internal information of the testing images. To address this issue, we adopt a self-supervised meta-auxiliary learning (MAXL) strategy that fine-tunes the well-trained network parameters with each testing image to combine external with internal information. To the best of our knowledge, this is the first work that successfully adapts the MAXL strategy to this problem. Instead of relying on naive end-to-end training, we also propose a novel architecture that integrates the physical relationship between the spectral reflectance and the corresponding RGB images into the network based on our mathematical analysis. Besides, since the spectral reflectance of a scene is independent to its illumination while the corresponding RGB images are not, we recover the spectral reflectance of a scene from its RGB images captured under multiple illuminations to further reduce the unknown. Qualitative and quantitative evaluations demonstrate the effectiveness of our proposed network and of the MAXL. Our code and data are available at https://github.com/Dong-Huo/SRR-MAXL.
Generative Model Based Highly Efficient Semantic Communication Approach for Image Transmission
Nov 18, 2022

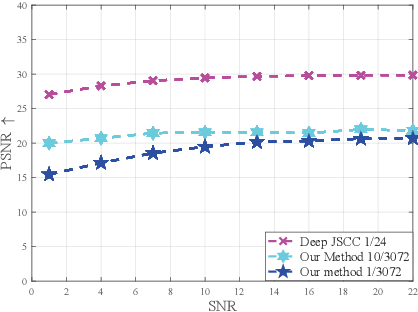
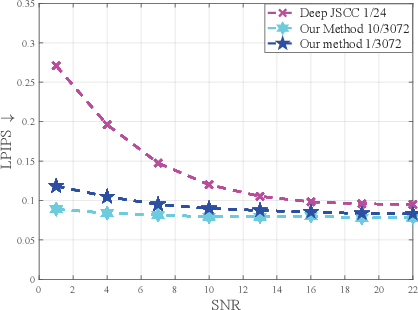
Deep learning (DL) based semantic communication methods have been explored to transmit images efficiently in recent years. In this paper, we propose a generative model based semantic communication to further improve the efficiency of image transmission and protect private information. In particular, the transmitter extracts the interpretable latent representation from the original image by a generative model exploiting the GAN inversion method. We also employ a privacy filter and a knowledge base to erase private information and replace it with natural features in the knowledge base. The simulation results indicate that our proposed method achieves comparable quality of received images while significantly reducing communication costs compared to the existing methods.
Adaptive Rotated Convolution for Rotated Object Detection
Mar 14, 2023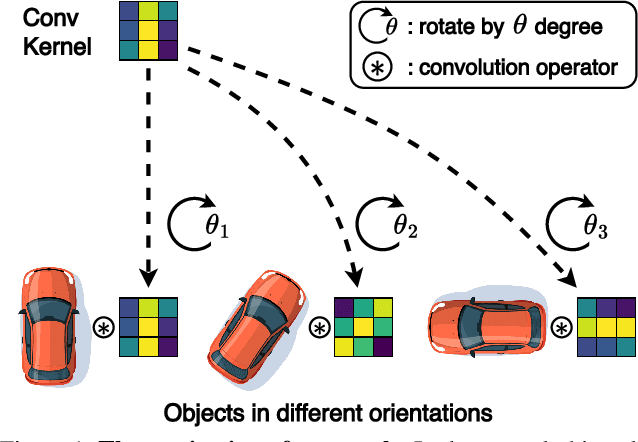
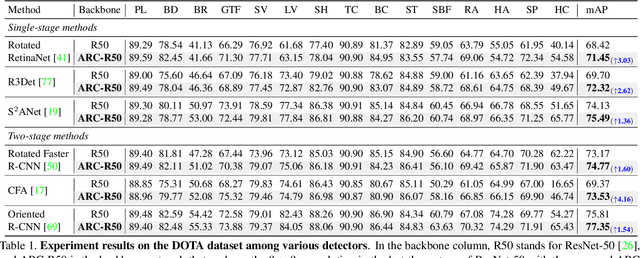
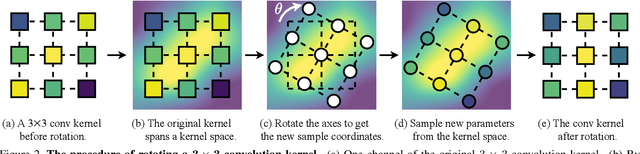
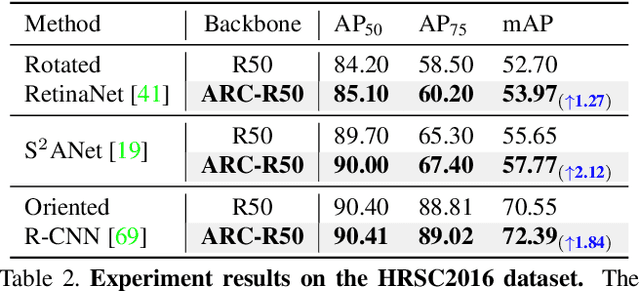
Rotated object detection aims to identify and locate objects in images with arbitrary orientation. In this scenario, the oriented directions of objects vary considerably across different images, while multiple orientations of objects exist within an image. This intrinsic characteristic makes it challenging for standard backbone networks to extract high-quality features of these arbitrarily orientated objects. In this paper, we present Adaptive Rotated Convolution (ARC) module to handle the aforementioned challenges. In our ARC module, the convolution kernels rotate adaptively to extract object features with varying orientations in different images, and an efficient conditional computation mechanism is introduced to accommodate the large orientation variations of objects within an image. The two designs work seamlessly in rotated object detection problem. Moreover, ARC can conveniently serve as a plug-and-play module in various vision backbones to boost their representation ability to detect oriented objects accurately. Experiments on commonly used benchmarks (DOTA and HRSC2016) demonstrate that equipped with our proposed ARC module in the backbone network, the performance of multiple popular oriented object detectors is significantly improved (e.g. +3.03% mAP on Rotated RetinaNet and +4.16% on CFA). Combined with the highly competitive method Oriented R-CNN, the proposed approach achieves state-of-the-art performance on the DOTA dataset with 81.77% mAP.
SMUG: Towards robust MRI reconstruction by smoothed unrolling
Mar 14, 2023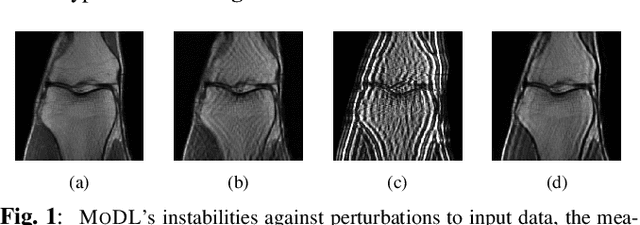
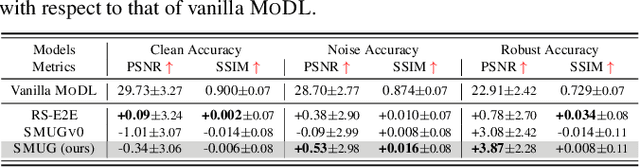
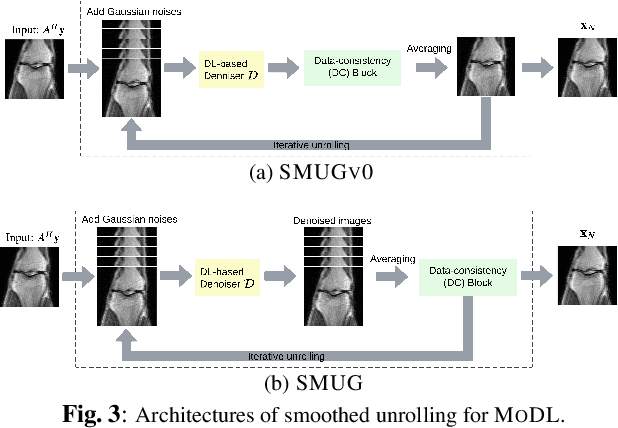
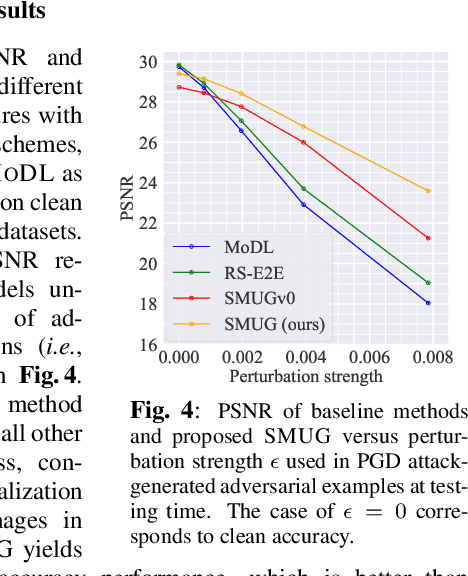
Although deep learning (DL) has gained much popularity for accelerated magnetic resonance imaging (MRI), recent studies have shown that DL-based MRI reconstruction models could be oversensitive to tiny input perturbations (that are called 'adversarial perturbations'), which cause unstable, low-quality reconstructed images. This raises the question of how to design robust DL methods for MRI reconstruction. To address this problem, we propose a novel image reconstruction framework, termed SMOOTHED UNROLLING (SMUG), which advances a deep unrolling-based MRI reconstruction model using a randomized smoothing (RS)-based robust learning operation. RS, which improves the tolerance of a model against input noises, has been widely used in the design of adversarial defense for image classification. Yet, we find that the conventional design that applies RS to the entire DL process is ineffective for MRI reconstruction. We show that SMUG addresses the above issue by customizing the RS operation based on the unrolling architecture of the DL-based MRI reconstruction model. Compared to the vanilla RS approach and several variants of SMUG, we show that SMUG improves the robustness of MRI reconstruction with respect to a diverse set of perturbation sources, including perturbations to the input measurements, different measurement sampling rates, and different unrolling steps. Code for SMUG will be available at https://github.com/LGM70/SMUG.
Transformer-based Generative Adversarial Networks in Computer Vision: A Comprehensive Survey
Feb 17, 2023
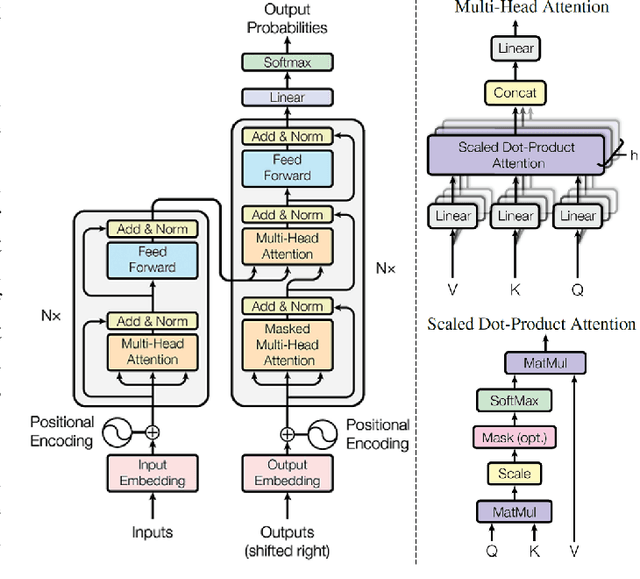
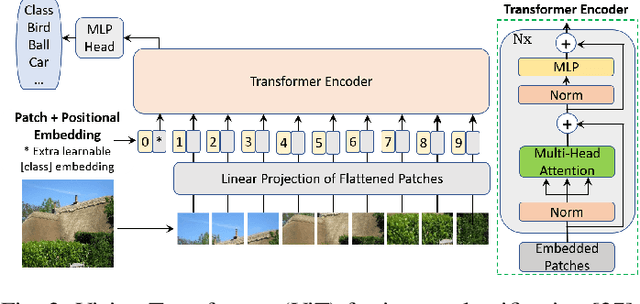
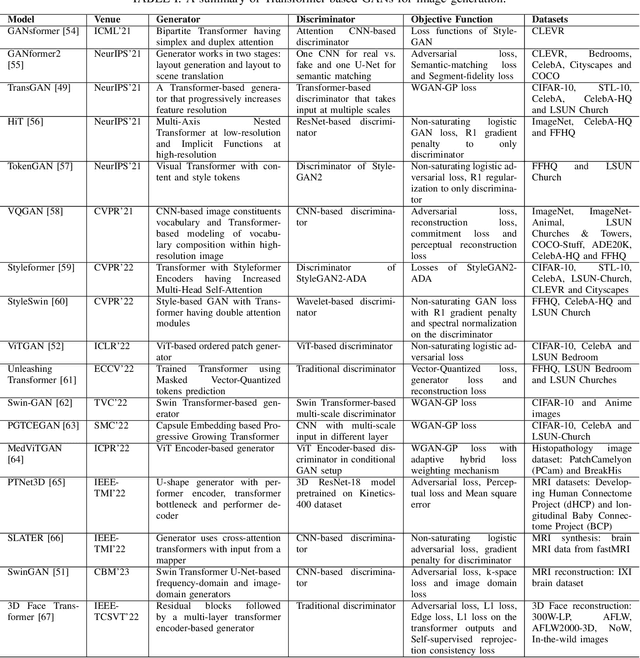
Generative Adversarial Networks (GANs) have been very successful for synthesizing the images in a given dataset. The artificially generated images by GANs are very realistic. The GANs have shown potential usability in several computer vision applications, including image generation, image-to-image translation, video synthesis, and others. Conventionally, the generator network is the backbone of GANs, which generates the samples and the discriminator network is used to facilitate the training of the generator network. The discriminator network is usually a Convolutional Neural Network (CNN). Whereas, the generator network is usually either an Up-CNN for image generation or an Encoder-Decoder network for image-to-image translation. The convolution-based networks exploit the local relationship in a layer, which requires the deep networks to extract the abstract features. Hence, CNNs suffer to exploit the global relationship in the feature space. However, recently developed Transformer networks are able to exploit the global relationship at every layer. The Transformer networks have shown tremendous performance improvement for several problems in computer vision. Motivated from the success of Transformer networks and GANs, recent works have tried to exploit the Transformers in GAN framework for the image/video synthesis. This paper presents a comprehensive survey on the developments and advancements in GANs utilizing the Transformer networks for computer vision applications. The performance comparison for several applications on benchmark datasets is also performed and analyzed. The conducted survey will be very useful to deep learning and computer vision community to understand the research trends \& gaps related with Transformer-based GANs and to develop the advanced GAN architectures by exploiting the global and local relationships for different applications.
DreamArtist: Towards Controllable One-Shot Text-to-Image Generation via Contrastive Prompt-Tuning
Nov 21, 2022
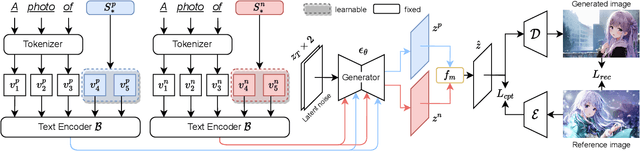
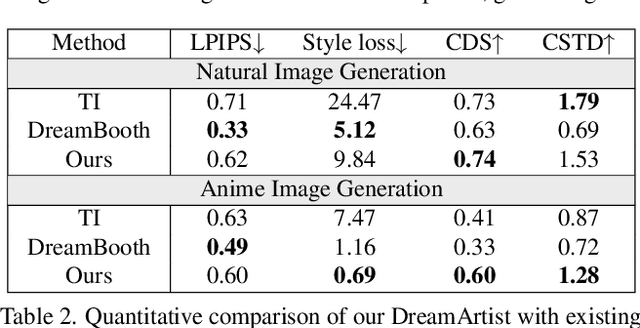

Large-scale text-to-image generation models with an exponential evolution can currently synthesize high-resolution, feature-rich, high-quality images based on text guidance. However, they are often overwhelmed by words of new concepts, styles, or object entities that always emerge. Although there are some recent attempts to use fine-tuning or prompt-tuning methods to teach the model a new concept as a new pseudo-word from a given reference image set, these methods are not only still difficult to synthesize diverse and high-quality images without distortion and artifacts, but also suffer from low controllability. To address these problems, we propose a DreamArtist method that employs a learning strategy of contrastive prompt-tuning, which introduces both positive and negative embeddings as pseudo-words and trains them jointly. The positive embedding aggressively learns characteristics in the reference image to drive the model diversified generation, while the negative embedding introspects in a self-supervised manner to rectify the mistakes and inadequacies from positive embedding in reverse. It learns not only what is correct but also what should be avoided. Extensive experiments on image quality and diversity analysis, controllability analysis, model learning analysis and task expansion have demonstrated that our model learns not only concept but also form, content and context. Pseudo-words of DreamArtist have similar properties as true words to generate high-quality images.
Video Pretraining Advances 3D Deep Learning on Chest CT Tasks
Apr 02, 2023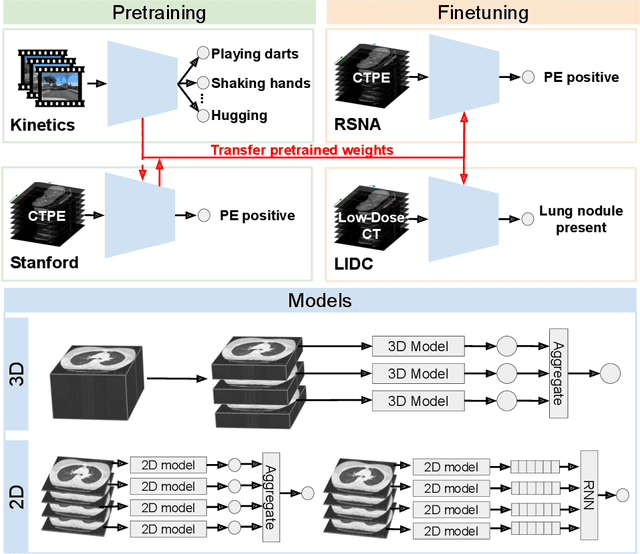
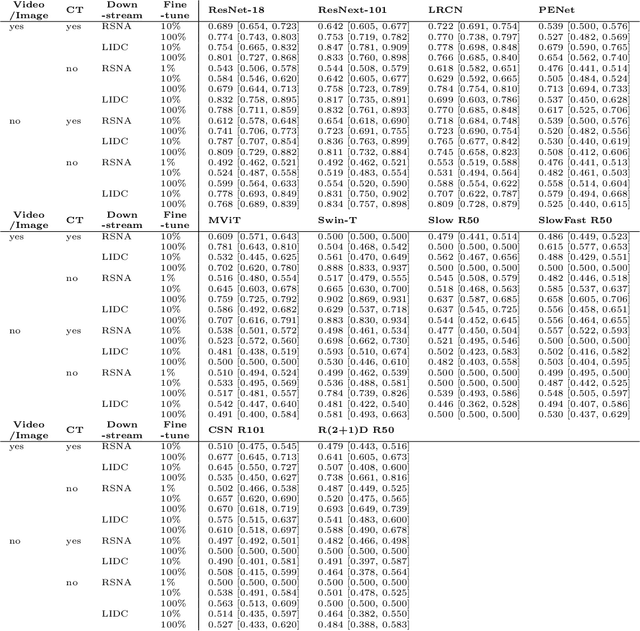
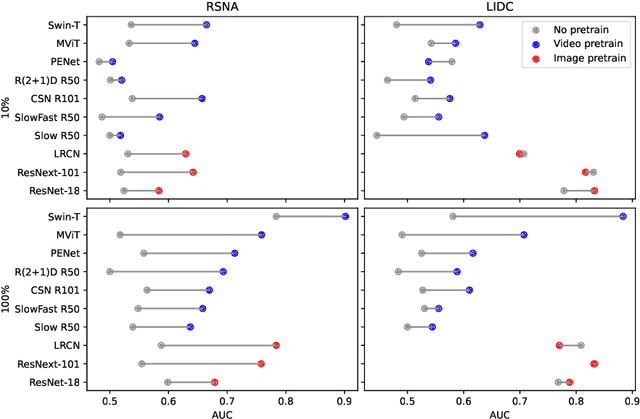
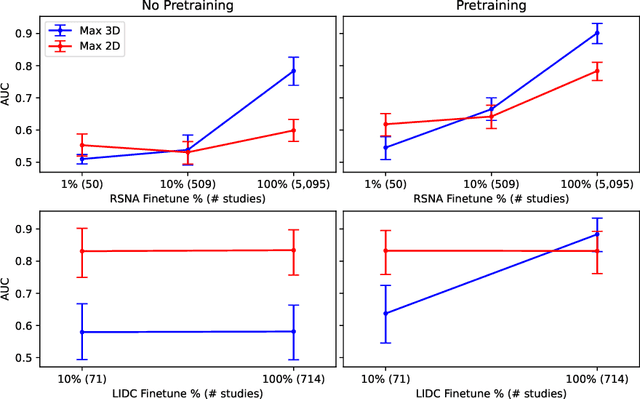
Pretraining on large natural image classification datasets such as ImageNet has aided model development on data-scarce 2D medical tasks. 3D medical tasks often have much less data than 2D medical tasks, prompting practitioners to rely on pretrained 2D models to featurize slices. However, these 2D models have been surpassed by 3D models on 3D computer vision benchmarks since they do not natively leverage cross-sectional or temporal information. In this study, we explore whether natural video pretraining for 3D models can enable higher performance on smaller datasets for 3D medical tasks. We demonstrate video pretraining improves the average performance of seven 3D models on two chest CT datasets, regardless of finetuning dataset size, and that video pretraining allows 3D models to outperform 2D baselines. Lastly, we observe that pretraining on the large-scale out-of-domain Kinetics dataset improves performance more than pretraining on a typically-sized in-domain CT dataset. Our results show consistent benefits of video pretraining across a wide array of architectures, tasks, and training dataset sizes, supporting a shift from small-scale in-domain pretraining to large-scale out-of-domain pretraining for 3D medical tasks. Our code is available at: https://github.com/rajpurkarlab/chest-ct-pretraining