 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
GCRE-GPT: A Generative Model for Comparative Relation Extraction
Mar 15, 2023
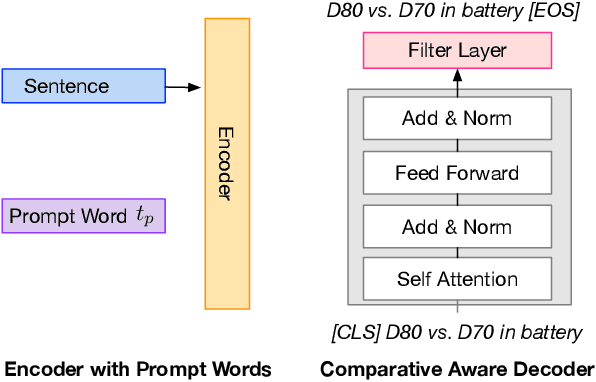
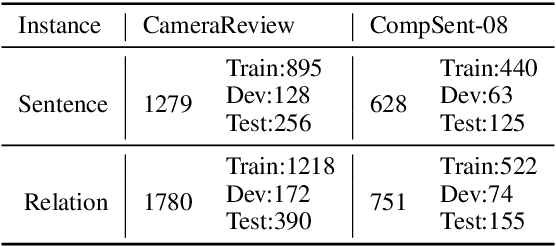
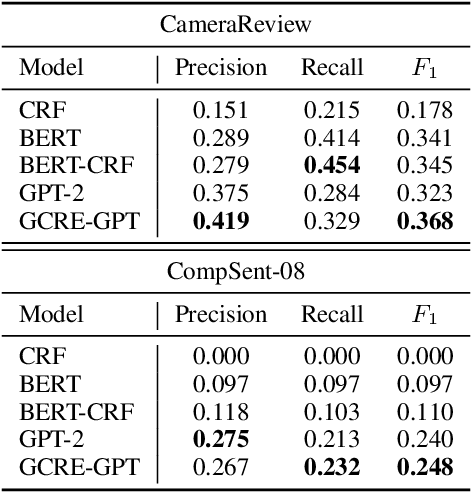
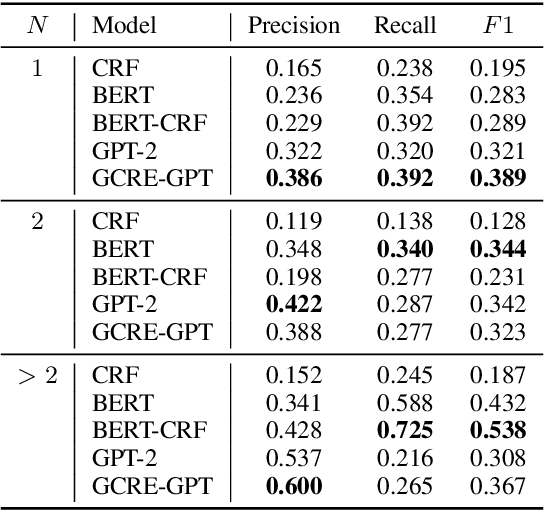
Given comparative text, comparative relation extraction aims to extract two targets (\eg two cameras) in comparison and the aspect they are compared for (\eg image quality). The extracted comparative relations form the basis of further opinion analysis.Existing solutions formulate this task as a sequence labeling task, to extract targets and aspects. However, they cannot directly extract comparative relation(s) from text. In this paper, we show that comparative relations can be directly extracted with high accuracy, by generative model. Based on GPT-2, we propose a Generation-based Comparative Relation Extractor (GCRE-GPT). Experiment results show that \modelname achieves state-of-the-art accuracy on two datasets.
DEPAS: De-novo Pathology Semantic Masks using a Generative Model
Feb 13, 2023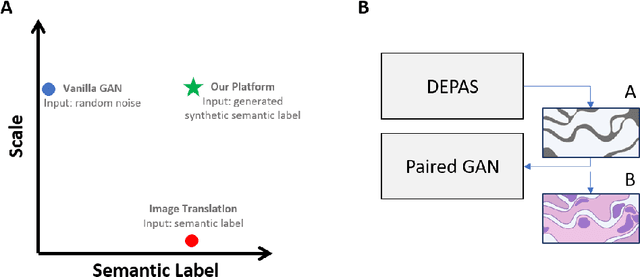
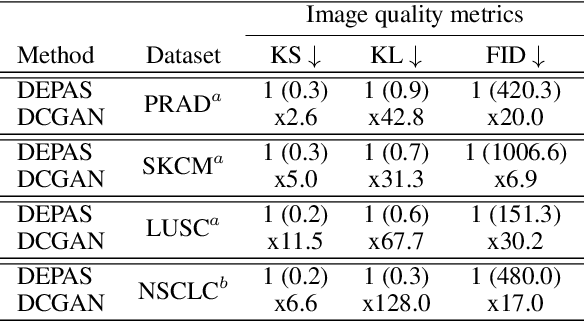
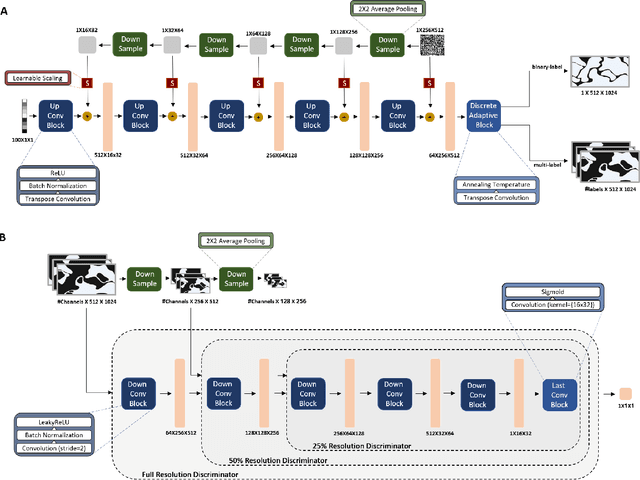
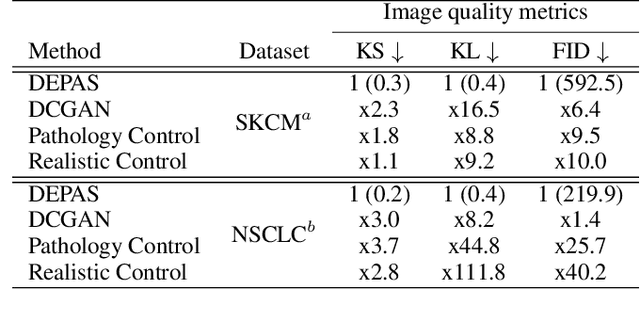
The integration of artificial intelligence into digital pathology has the potential to automate and improve various tasks, such as image analysis and diagnostic decision-making. Yet, the inherent variability of tissues, together with the need for image labeling, lead to biased datasets that limit the generalizability of algorithms trained on them. One of the emerging solutions for this challenge is synthetic histological images. However, debiasing real datasets require not only generating photorealistic images but also the ability to control the features within them. A common approach is to use generative methods that perform image translation between semantic masks that reflect prior knowledge of the tissue and a histological image. However, unlike other image domains, the complex structure of the tissue prevents a simple creation of histology semantic masks that are required as input to the image translation model, while semantic masks extracted from real images reduce the process's scalability. In this work, we introduce a scalable generative model, coined as DEPAS, that captures tissue structure and generates high-resolution semantic masks with state-of-the-art quality. We demonstrate the ability of DEPAS to generate realistic semantic maps of tissue for three types of organs: skin, prostate, and lung. Moreover, we show that these masks can be processed using a generative image translation model to produce photorealistic histology images of two types of cancer with two different types of staining techniques. Finally, we harness DEPAS to generate multi-label semantic masks that capture different cell types distributions and use them to produce histological images with on-demand cellular features. Overall, our work provides a state-of-the-art solution for the challenging task of generating synthetic histological images while controlling their semantic information in a scalable way.
Learning Input-agnostic Manipulation Directions in StyleGAN with Text Guidance
Feb 26, 2023With the advantages of fast inference and human-friendly flexible manipulation, image-agnostic style manipulation via text guidance enables new applications that were not previously available. The state-of-the-art text-guided image-agnostic manipulation method embeds the representation of each channel of StyleGAN independently in the Contrastive Language-Image Pre-training (CLIP) space, and provides it in the form of a Dictionary to quickly find out the channel-wise manipulation direction during inference time. However, in this paper we argue that this dictionary which is constructed by controlling single channel individually is limited to accommodate the versatility of text guidance since the collective and interactive relation among multiple channels are not considered. Indeed, we show that it fails to discover a large portion of manipulation directions that can be found by existing methods, which manually manipulates latent space without texts. To alleviate this issue, we propose a novel method that learns a Dictionary, whose entry corresponds to the representation of a single channel, by taking into account the manipulation effect coming from the interaction with multiple other channels. We demonstrate that our strategy resolves the inability of previous methods in finding diverse known directions from unsupervised methods and unknown directions from random text while maintaining the real-time inference speed and disentanglement ability.
Unpaired Translation from Semantic Label Maps to Images by Leveraging Domain-Specific Simulations
Feb 21, 2023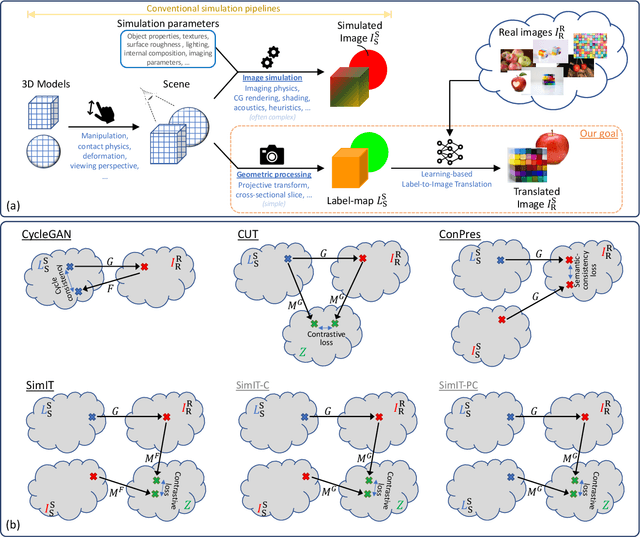
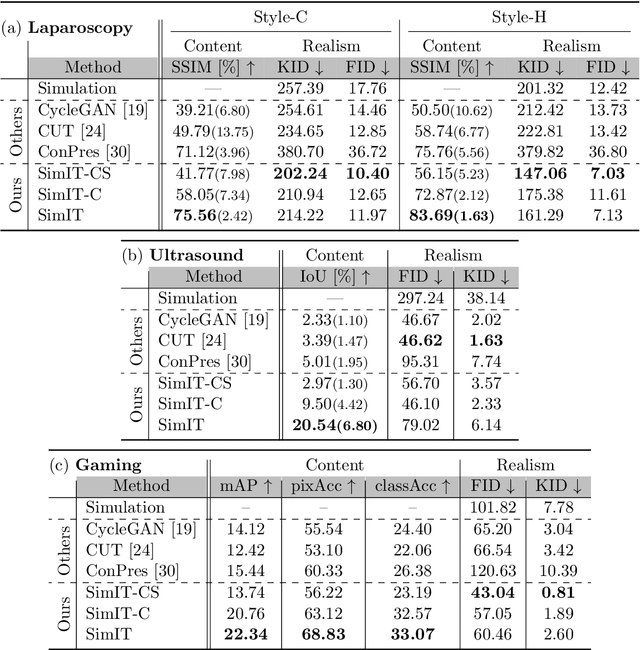
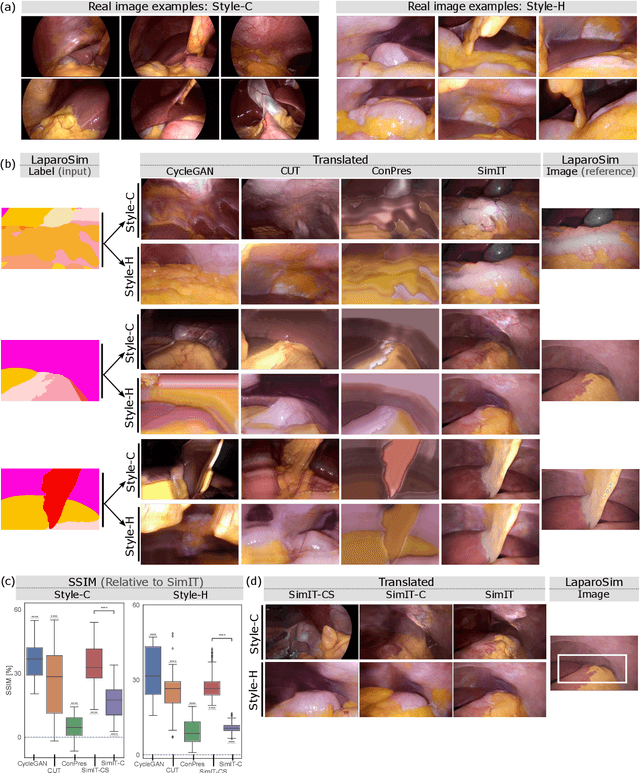
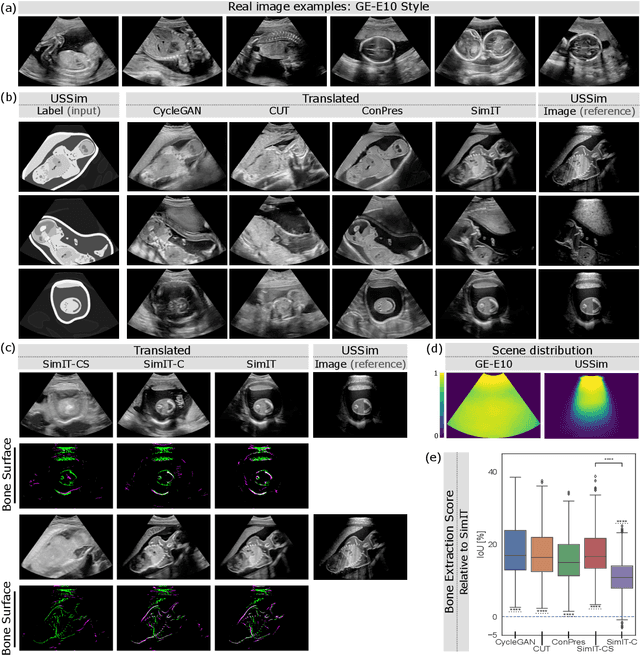
Photorealistic image generation from simulated label maps are necessitated in several contexts, such as for medical training in virtual reality. With conventional deep learning methods, this task requires images that are paired with semantic annotations, which typically are unavailable. We introduce a contrastive learning framework for generating photorealistic images from simulated label maps, by learning from unpaired sets of both. Due to potentially large scene differences between real images and label maps, existing unpaired image translation methods lead to artifacts of scene modification in synthesized images. We utilize simulated images as surrogate targets for a contrastive loss, while ensuring consistency by utilizing features from a reverse translation network. Our method enables bidirectional label-image translations, which is demonstrated in a variety of scenarios and datasets, including laparoscopy, ultrasound, and driving scenes. By comparing with state-of-the-art unpaired translation methods, our proposed method is shown to generate realistic and scene-accurate translations.
Principles of Forgetting in Domain-Incremental Semantic Segmentation in Adverse Weather Conditions
Mar 24, 2023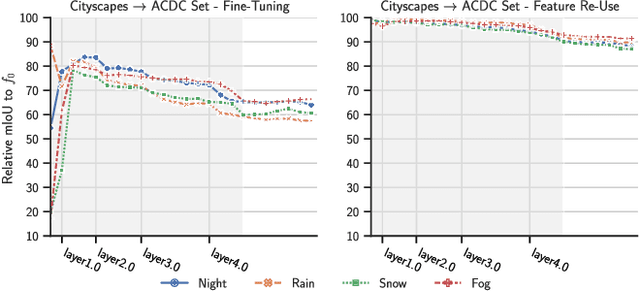
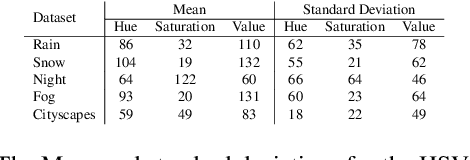
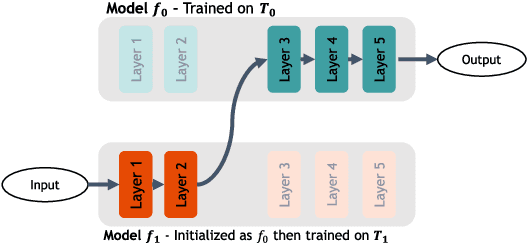
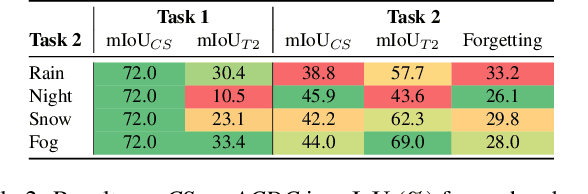
Deep neural networks for scene perception in automated vehicles achieve excellent results for the domains they were trained on. However, in real-world conditions, the domain of operation and its underlying data distribution are subject to change. Adverse weather conditions, in particular, can significantly decrease model performance when such data are not available during training.Additionally, when a model is incrementally adapted to a new domain, it suffers from catastrophic forgetting, causing a significant drop in performance on previously observed domains. Despite recent progress in reducing catastrophic forgetting, its causes and effects remain obscure. Therefore, we study how the representations of semantic segmentation models are affected during domain-incremental learning in adverse weather conditions. Our experiments and representational analyses indicate that catastrophic forgetting is primarily caused by changes to low-level features in domain-incremental learning and that learning more general features on the source domain using pre-training and image augmentations leads to efficient feature reuse in subsequent tasks, which drastically reduces catastrophic forgetting. These findings highlight the importance of methods that facilitate generalized features for effective continual learning algorithms.
Prediction of the morphological evolution of a splashing drop using an encoder-decoder
Mar 24, 2023The impact of a drop on a solid surface is an important phenomenon that has various implications and applications. However, the multiphase nature of this phenomenon causes complications in the prediction of its morphological evolution, especially when the drop splashes. While most machine-learning-based drop-impact studies have centred around physical parameters, this study used a computer-vision strategy by training an encoder-decoder to predict the drop morphologies using image data. Herein, we show that this trained encoder-decoder is able to successfully generate videos that show the morphologies of splashing and non-splashing drops. Remarkably, in each frame of these generated videos, the spreading diameter of the drop was found to be in good agreement with that of the actual videos. Moreover, there was also a high accuracy in splashing/non-splashing prediction. These findings demonstrate the ability of the trained encoder-decoder to generate videos that can accurately represent the drop morphologies. This approach provides a faster and cheaper alternative to experimental and numerical studies.
Application-Driven AI Paradigm for Person Counting in Various Scenarios
Mar 24, 2023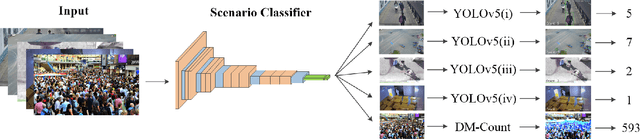
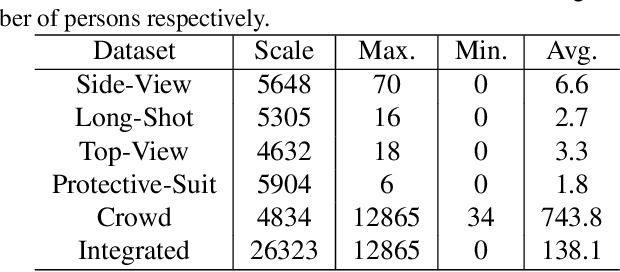
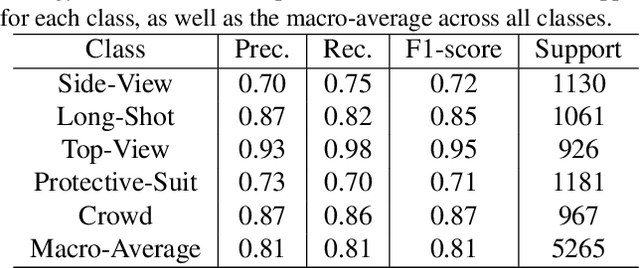
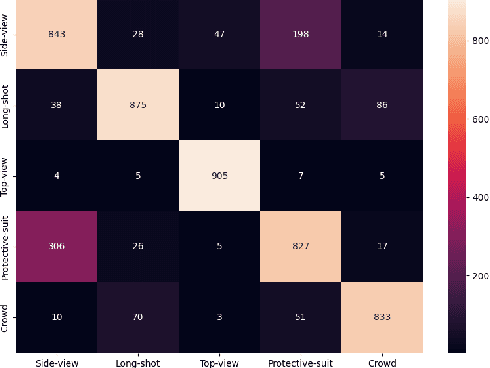
Person counting is considered as a fundamental task in video surveillance. However, the scenario diversity in practical applications makes it difficult to exploit a single person counting model for general use. Consequently, engineers must preview the video stream and manually specify an appropriate person counting model based on the scenario of camera shot, which is time-consuming, especially for large-scale deployments. In this paper, we propose a person counting paradigm that utilizes a scenario classifier to automatically select a suitable person counting model for each captured frame. First, the input image is passed through the scenario classifier to obtain a scenario label, which is then used to allocate the frame to one of five fine-tuned models for person counting. Additionally, we present five augmentation datasets collected from different scenarios, including side-view, long-shot, top-view, customized and crowd, which are also integrated to form a scenario classification dataset containing 26323 samples. In our comparative experiments, the proposed paradigm achieves better balance than any single model on the integrated dataset, thus its generalization in various scenarios has been proved.
TRAK: Attributing Model Behavior at Scale
Mar 24, 2023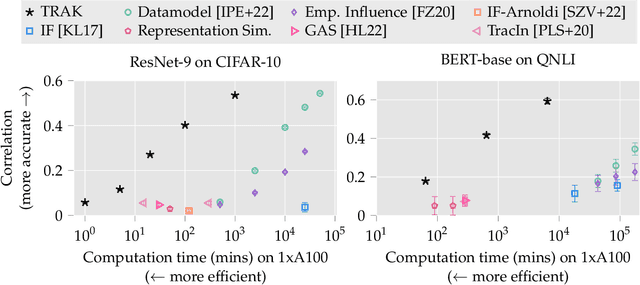
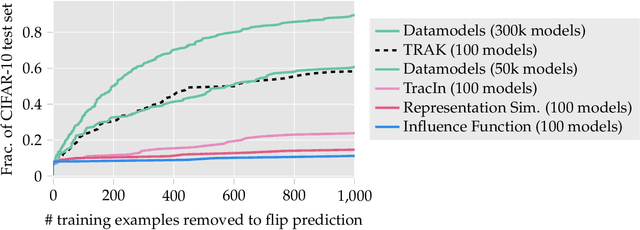
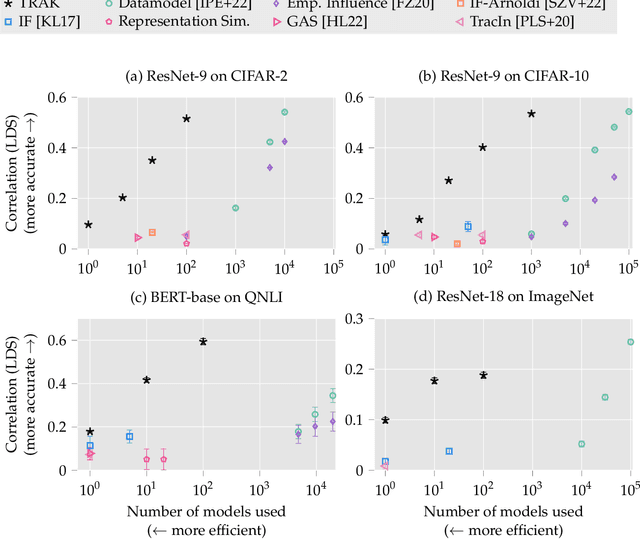

The goal of data attribution is to trace model predictions back to training data. Despite a long line of work towards this goal, existing approaches to data attribution tend to force users to choose between computational tractability and efficacy. That is, computationally tractable methods can struggle with accurately attributing model predictions in non-convex settings (e.g., in the context of deep neural networks), while methods that are effective in such regimes require training thousands of models, which makes them impractical for large models or datasets. In this work, we introduce TRAK (Tracing with the Randomly-projected After Kernel), a data attribution method that is both effective and computationally tractable for large-scale, differentiable models. In particular, by leveraging only a handful of trained models, TRAK can match the performance of attribution methods that require training thousands of models. We demonstrate the utility of TRAK across various modalities and scales: image classifiers trained on ImageNet, vision-language models (CLIP), and language models (BERT and mT5). We provide code for using TRAK (and reproducing our work) at https://github.com/MadryLab/trak .
Transthoracic super-resolution ultrasound localization microscopy of myocardial vasculature in patients
Mar 24, 2023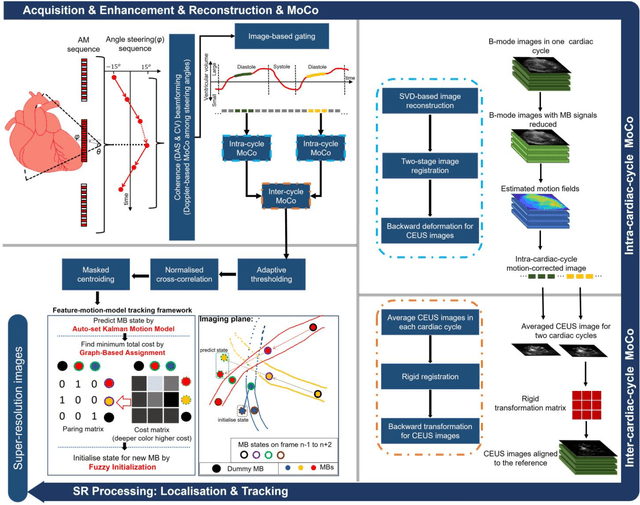
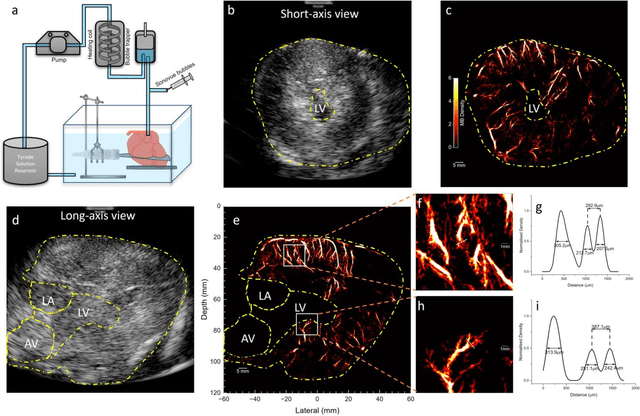
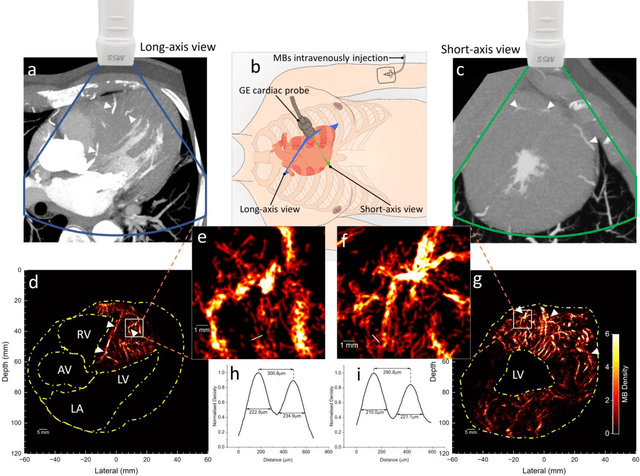
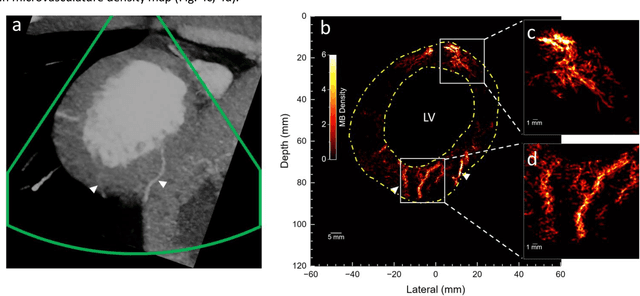
Micro-vascular flow in the myocardium is of significant importance clinically but remains poorly understood. Up to 25% of patients with symptoms of coronary heart diseases have no obstructive coronary arteries and have suspected microvascular diseases. However, such microvasculature is difficult to image in vivo with existing modalities due to the lack of resolution and sensitivity. Here, we demonstrate the feasibility of transthoracic super-resolution ultrasound localisation microscopy (SRUS/ULM) of myocardial microvasculature and hemodynamics in a large animal model and in patients, using a cardiac phased array probe with a customised data acquisition and processing pipeline. A multi-level motion correction strategy was proposed. A tracking framework incorporating multiple features and automatic parameter initialisations was developed to reconstruct microcirculation. In two patients with impaired myocardial function, we have generated SRUS images of myocardial vascular structure and flow with a resolution that is beyond the wave-diffraction limit (half a wavelength), using data acquired within a breath hold. Myocardial SRUS/ULM has potential to improve the understanding of myocardial microcirculation and the management of patients with cardiac microvascular diseases.
Machine learning-based spin structure detection
Mar 24, 2023

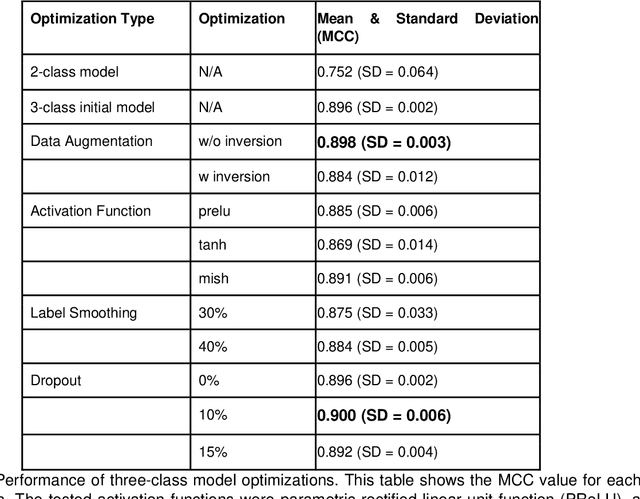

One of the most important magnetic spin structure is the topologically stabilised skyrmion quasi-particle. Its interesting physical properties make them candidates for memory and efficient neuromorphic computation schemes. For the device operation, detection of the position, shape, and size of skyrmions is required and magnetic imaging is typically employed. A frequently used technique is magneto-optical Kerr microscopy where depending on the samples material composition, temperature, material growing procedures, etc., the measurements suffer from noise, low-contrast, intensity gradients, or other optical artifacts. Conventional image analysis packages require manual treatment, and a more automatic solution is required. We report a convolutional neural network specifically designed for segmentation problems to detect the position and shape of skyrmions in our measurements. The network is tuned using selected techniques to optimize predictions and in particular the number of detected classes is found to govern the performance. The results of this study shows that a well-trained network is a viable method of automating data pre-processing in magnetic microscopy. The approach is easily extendable to other spin structures and other magnetic imaging methods.