 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Rethinking Domain Generalization for Face Anti-spoofing: Separability and Alignment
Mar 23, 2023
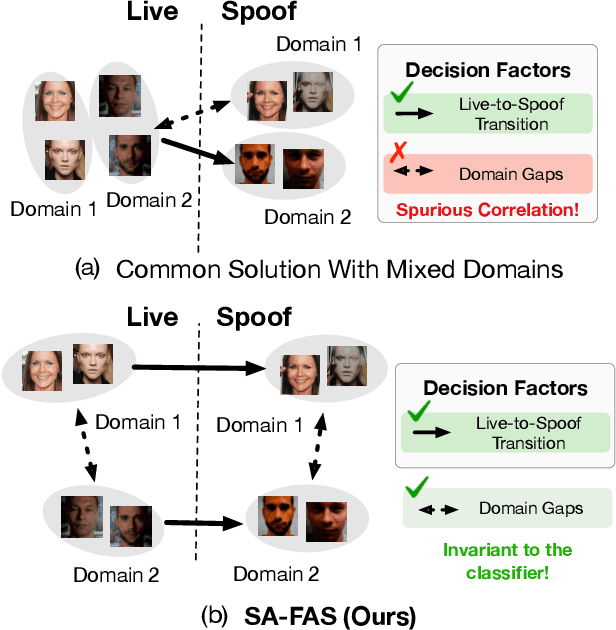
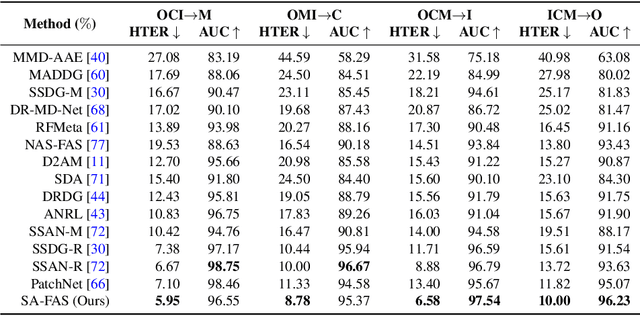
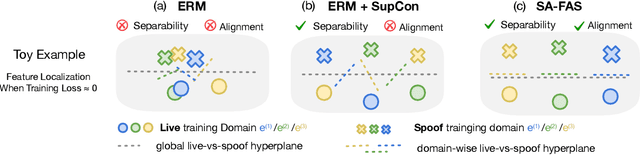

This work studies the generalization issue of face anti-spoofing (FAS) models on domain gaps, such as image resolution, blurriness and sensor variations. Most prior works regard domain-specific signals as a negative impact, and apply metric learning or adversarial losses to remove them from feature representation. Though learning a domain-invariant feature space is viable for the training data, we show that the feature shift still exists in an unseen test domain, which backfires on the generalizability of the classifier. In this work, instead of constructing a domain-invariant feature space, we encourage domain separability while aligning the live-to-spoof transition (i.e., the trajectory from live to spoof) to be the same for all domains. We formulate this FAS strategy of separability and alignment (SA-FAS) as a problem of invariant risk minimization (IRM), and learn domain-variant feature representation but domain-invariant classifier. We demonstrate the effectiveness of SA-FAS on challenging cross-domain FAS datasets and establish state-of-the-art performance.
TAPS3D: Text-Guided 3D Textured Shape Generation from Pseudo Supervision
Mar 23, 2023
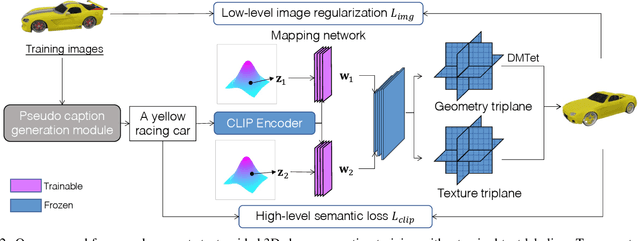
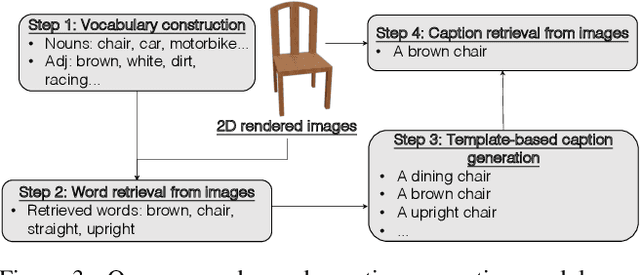
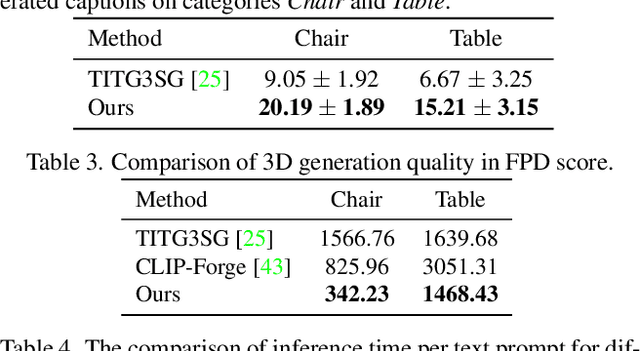
In this paper, we investigate an open research task of generating controllable 3D textured shapes from the given textual descriptions. Previous works either require ground truth caption labeling or extensive optimization time. To resolve these issues, we present a novel framework, TAPS3D, to train a text-guided 3D shape generator with pseudo captions. Specifically, based on rendered 2D images, we retrieve relevant words from the CLIP vocabulary and construct pseudo captions using templates. Our constructed captions provide high-level semantic supervision for generated 3D shapes. Further, in order to produce fine-grained textures and increase geometry diversity, we propose to adopt low-level image regularization to enable fake-rendered images to align with the real ones. During the inference phase, our proposed model can generate 3D textured shapes from the given text without any additional optimization. We conduct extensive experiments to analyze each of our proposed components and show the efficacy of our framework in generating high-fidelity 3D textured and text-relevant shapes.
Complementary Pseudo Multimodal Feature for Point Cloud Anomaly Detection
Mar 23, 2023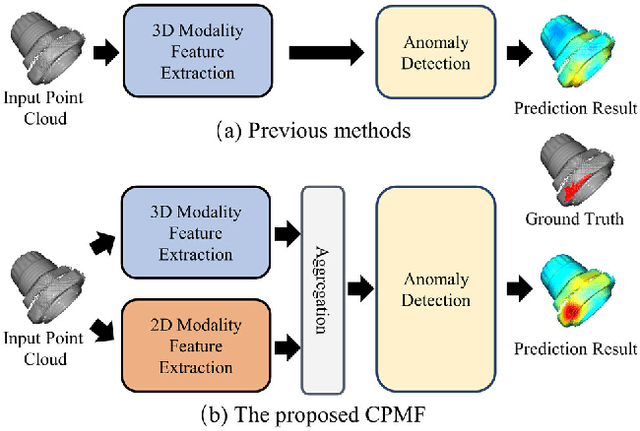
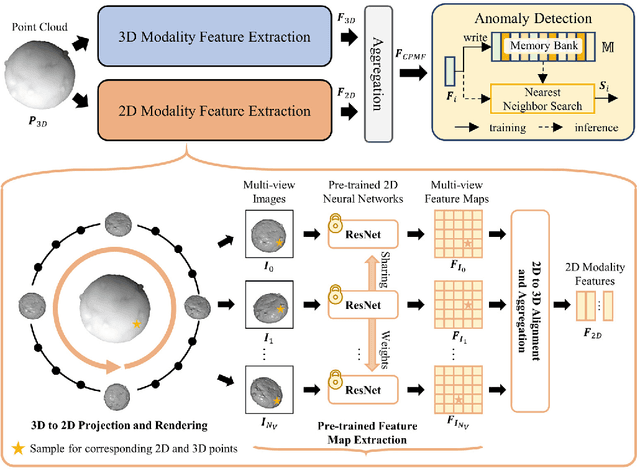

Point cloud (PCD) anomaly detection steadily emerges as a promising research area. This study aims to improve PCD anomaly detection performance by combining handcrafted PCD descriptions with powerful pre-trained 2D neural networks. To this end, this study proposes Complementary Pseudo Multimodal Feature (CPMF) that incorporates local geometrical information in 3D modality using handcrafted PCD descriptors and global semantic information in the generated pseudo 2D modality using pre-trained 2D neural networks. For global semantics extraction, CPMF projects the origin PCD into a pseudo 2D modality containing multi-view images. These images are delivered to pre-trained 2D neural networks for informative 2D modality feature extraction. The 3D and 2D modality features are aggregated to obtain the CPMF for PCD anomaly detection. Extensive experiments demonstrate the complementary capacity between 2D and 3D modality features and the effectiveness of CPMF, with 95.15% image-level AU-ROC and 92.93% pixel-level PRO on the MVTec3D benchmark. Code is available on https://github.com/caoyunkang/CPMF.
Fine-Grained ImageNet Classification in the Wild
Mar 04, 2023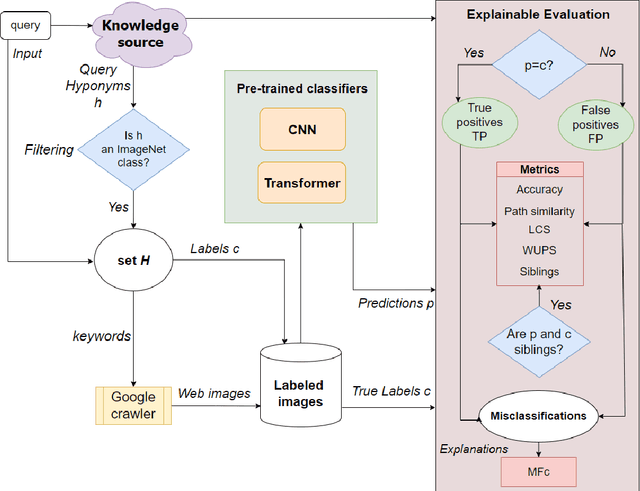
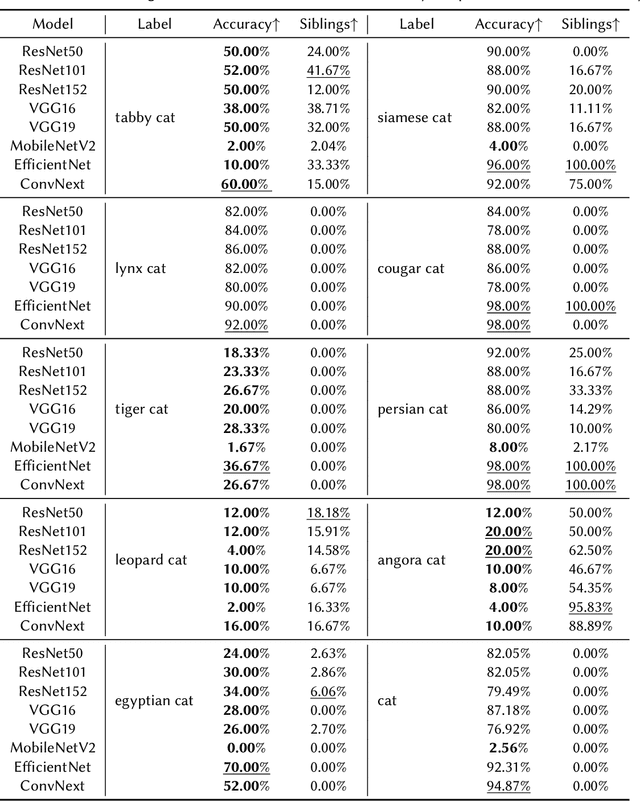
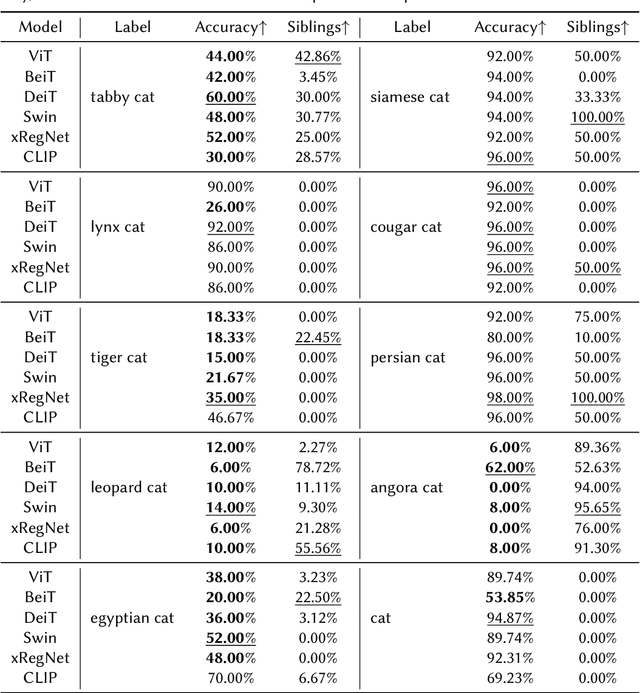
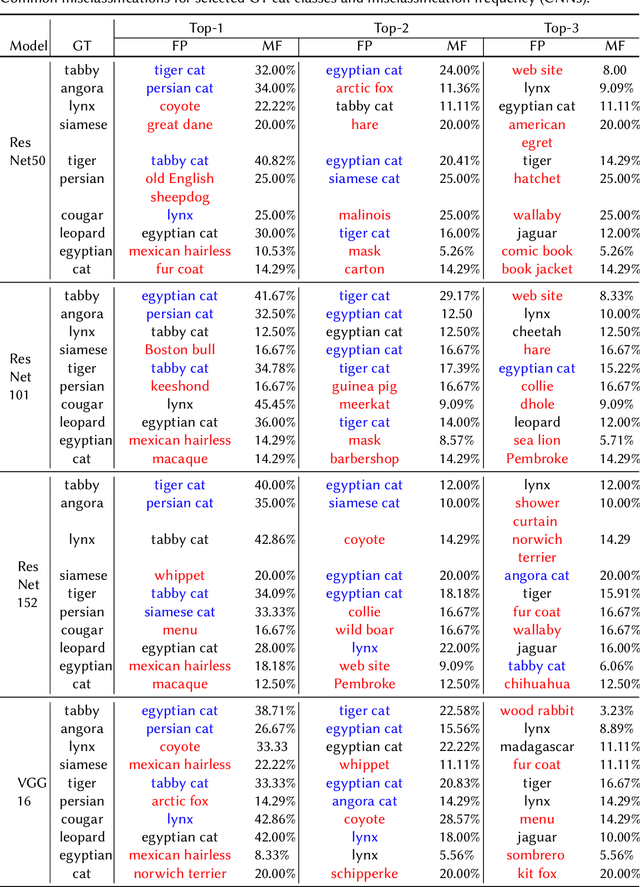
Image classification has been one of the most popular tasks in Deep Learning, seeing an abundance of impressive implementations each year. However, there is a lot of criticism tied to promoting complex architectures that continuously push performance metrics higher and higher. Robustness tests can uncover several vulnerabilities and biases which go unnoticed during the typical model evaluation stage. So far, model robustness under distribution shifts has mainly been examined within carefully curated datasets. Nevertheless, such approaches do not test the real response of classifiers in the wild, e.g. when uncurated web-crawled image data of corresponding classes are provided. In our work, we perform fine-grained classification on closely related categories, which are identified with the help of hierarchical knowledge. Extensive experimentation on a variety of convolutional and transformer-based architectures reveals model robustness in this novel setting. Finally, hierarchical knowledge is again employed to evaluate and explain misclassifications, providing an information-rich evaluation scheme adaptable to any classifier.
A Distance-Geometric Method for Recovering Robot Joint Angles From an RGB Image
Jan 05, 2023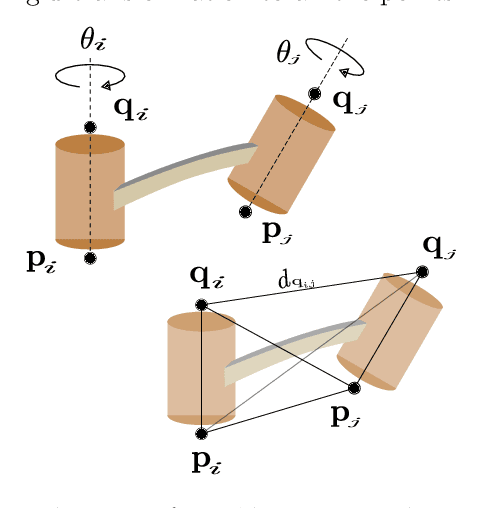
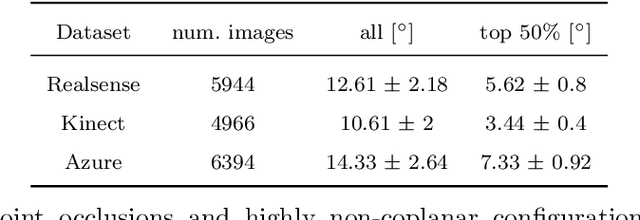

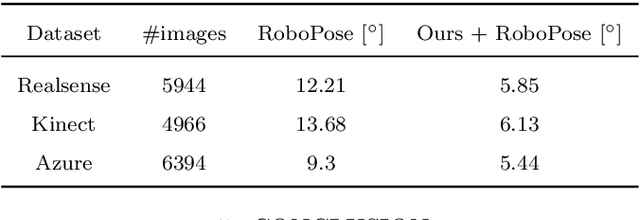
Autonomous manipulation systems operating in domains where human intervention is difficult or impossible (e.g., underwater, extraterrestrial or hazardous environments) require a high degree of robustness to sensing and communication failures. Crucially, motion planning and control algorithms require a stream of accurate joint angle data provided by joint encoders, the failure of which may result in an unrecoverable loss of functionality. In this paper, we present a novel method for retrieving the joint angles of a robot manipulator using only a single RGB image of its current configuration, opening up an avenue for recovering system functionality when conventional proprioceptive sensing is unavailable. Our approach, based on a distance-geometric representation of the configuration space, exploits the knowledge of a robot's kinematic model with the goal of training a shallow neural network that performs a 2D-to-3D regression of distances associated with detected structural keypoints. It is shown that the resulting Euclidean distance matrix uniquely corresponds to the observed configuration, where joint angles can be recovered via multidimensional scaling and a simple inverse kinematics procedure. We evaluate the performance of our approach on real RGB images of a Franka Emika Panda manipulator, showing that the proposed method is efficient and exhibits solid generalization ability. Furthermore, we show that our method can be easily combined with a dense refinement technique to obtain superior results.
ImageNet-E: Benchmarking Neural Network Robustness via Attribute Editing
Mar 30, 2023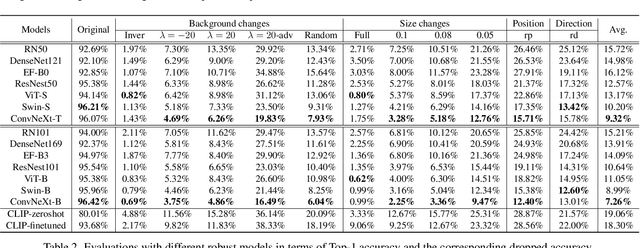
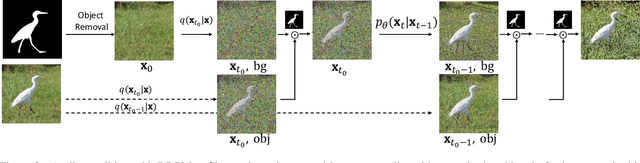

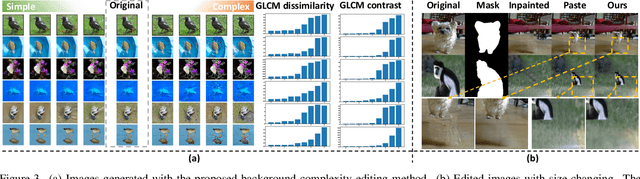
Recent studies have shown that higher accuracy on ImageNet usually leads to better robustness against different corruptions. Therefore, in this paper, instead of following the traditional research paradigm that investigates new out-of-distribution corruptions or perturbations deep models may encounter, we conduct model debugging in in-distribution data to explore which object attributes a model may be sensitive to. To achieve this goal, we create a toolkit for object editing with controls of backgrounds, sizes, positions, and directions, and create a rigorous benchmark named ImageNet-E(diting) for evaluating the image classifier robustness in terms of object attributes. With our ImageNet-E, we evaluate the performance of current deep learning models, including both convolutional neural networks and vision transformers. We find that most models are quite sensitive to attribute changes. A small change in the background can lead to an average of 9.23\% drop on top-1 accuracy. We also evaluate some robust models including both adversarially trained models and other robust trained models and find that some models show worse robustness against attribute changes than vanilla models. Based on these findings, we discover ways to enhance attribute robustness with preprocessing, architecture designs, and training strategies. We hope this work can provide some insights to the community and open up a new avenue for research in robust computer vision. The code and dataset are available at https://github.com/alibaba/easyrobust.
* Accepted by CVPR2023
Understanding the Robustness of 3D Object Detection with Bird's-Eye-View Representations in Autonomous Driving
Mar 30, 2023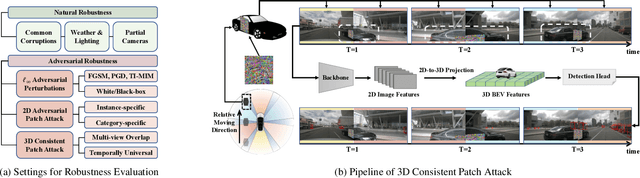
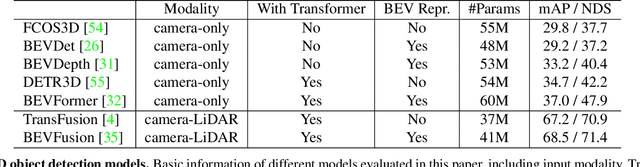

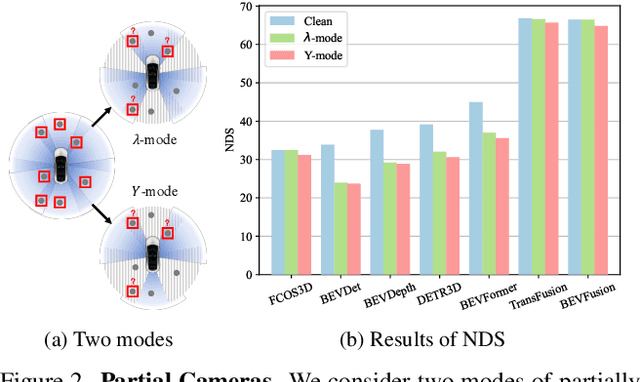
3D object detection is an essential perception task in autonomous driving to understand the environments. The Bird's-Eye-View (BEV) representations have significantly improved the performance of 3D detectors with camera inputs on popular benchmarks. However, there still lacks a systematic understanding of the robustness of these vision-dependent BEV models, which is closely related to the safety of autonomous driving systems. In this paper, we evaluate the natural and adversarial robustness of various representative models under extensive settings, to fully understand their behaviors influenced by explicit BEV features compared with those without BEV. In addition to the classic settings, we propose a 3D consistent patch attack by applying adversarial patches in the 3D space to guarantee the spatiotemporal consistency, which is more realistic for the scenario of autonomous driving. With substantial experiments, we draw several findings: 1) BEV models tend to be more stable than previous methods under different natural conditions and common corruptions due to the expressive spatial representations; 2) BEV models are more vulnerable to adversarial noises, mainly caused by the redundant BEV features; 3) Camera-LiDAR fusion models have superior performance under different settings with multi-modal inputs, but BEV fusion model is still vulnerable to adversarial noises of both point cloud and image. These findings alert the safety issue in the applications of BEV detectors and could facilitate the development of more robust models.
Unsupervised Domain Adaptation with Histogram-gated Image Translation for Delayered IC Image Analysis
Sep 27, 2022
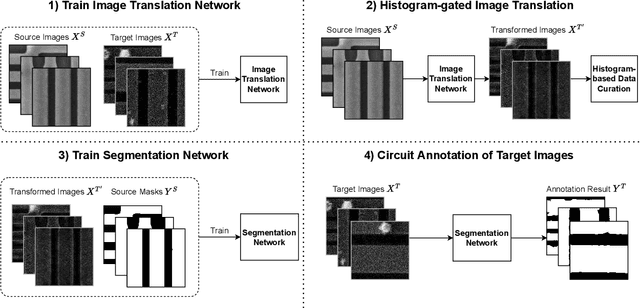

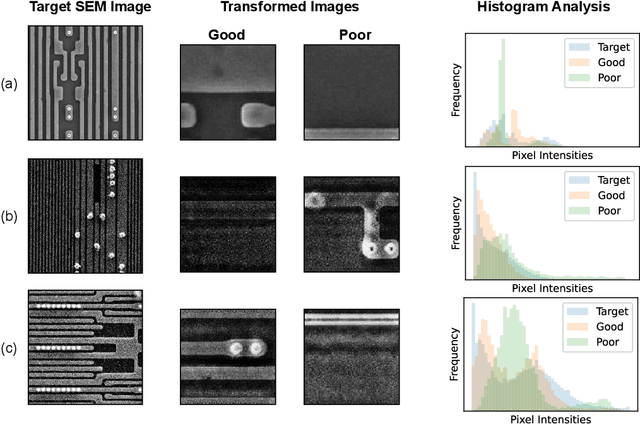
Deep learning has achieved great success in the challenging circuit annotation task by employing Convolutional Neural Networks (CNN) for the segmentation of circuit structures. The deep learning approaches require a large amount of manually annotated training data to achieve a good performance, which could cause a degradation in performance if a deep learning model trained on a given dataset is applied to a different dataset. This is commonly known as the domain shift problem for circuit annotation, which stems from the possibly large variations in distribution across different image datasets. The different image datasets could be obtained from different devices or different layers within a single device. To address the domain shift problem, we propose Histogram-gated Image Translation (HGIT), an unsupervised domain adaptation framework which transforms images from a given source dataset to the domain of a target dataset, and utilize the transformed images for training a segmentation network. Specifically, our HGIT performs generative adversarial network (GAN)-based image translation and utilizes histogram statistics for data curation. Experiments were conducted on a single labeled source dataset adapted to three different target datasets (without labels for training) and the segmentation performance was evaluated for each target dataset. We have demonstrated that our method achieves the best performance compared to the reported domain adaptation techniques, and is also reasonably close to the fully supervised benchmark.
BEL: A Bag Embedding Loss for Transformer enhances Multiple Instance Whole Slide Image Classification
Mar 02, 2023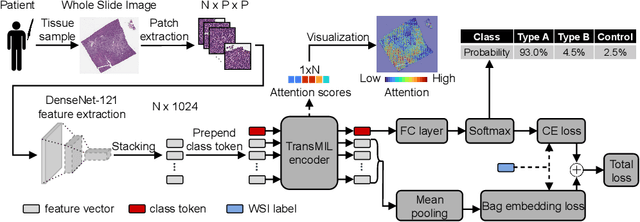
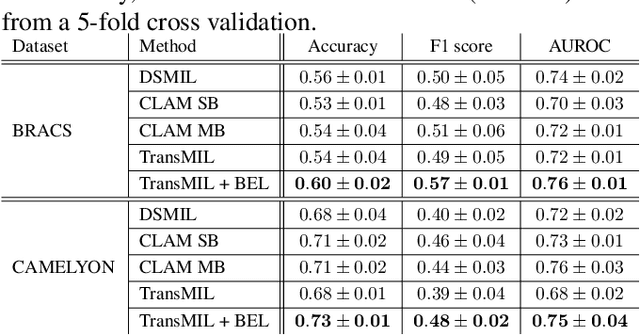
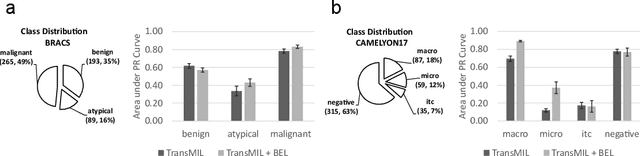
Multiple Instance Learning (MIL) has become the predominant approach for classification tasks on gigapixel histopathology whole slide images (WSIs). Within the MIL framework, single WSIs (bags) are decomposed into patches (instances), with only WSI-level annotation available. Recent MIL approaches produce highly informative bag level representations by utilizing the transformer architecture's ability to model the dependencies between instances. However, when applied to high magnification datasets, problems emerge due to the large number of instances and the weak supervisory learning signal. To address this problem, we propose to additionally train transformers with a novel Bag Embedding Loss (BEL). BEL forces the model to learn a discriminative bag-level representation by minimizing the distance between bag embeddings of the same class and maximizing the distance between different classes. We evaluate BEL with the Transformer architecture TransMIL on two publicly available histopathology datasets, BRACS and CAMELYON17. We show that with BEL, TransMIL outperforms the baseline models on both datasets, thus contributing to the clinically highly relevant AI-based tumor classification of histological patient material.
High-Resolution Image Editing via Multi-Stage Blended Diffusion
Oct 24, 2022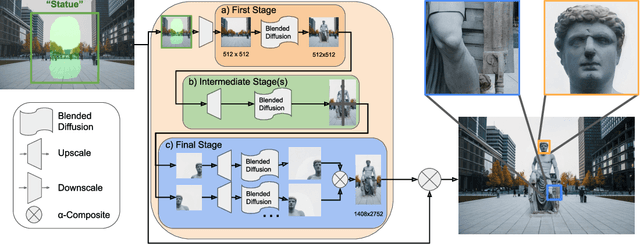

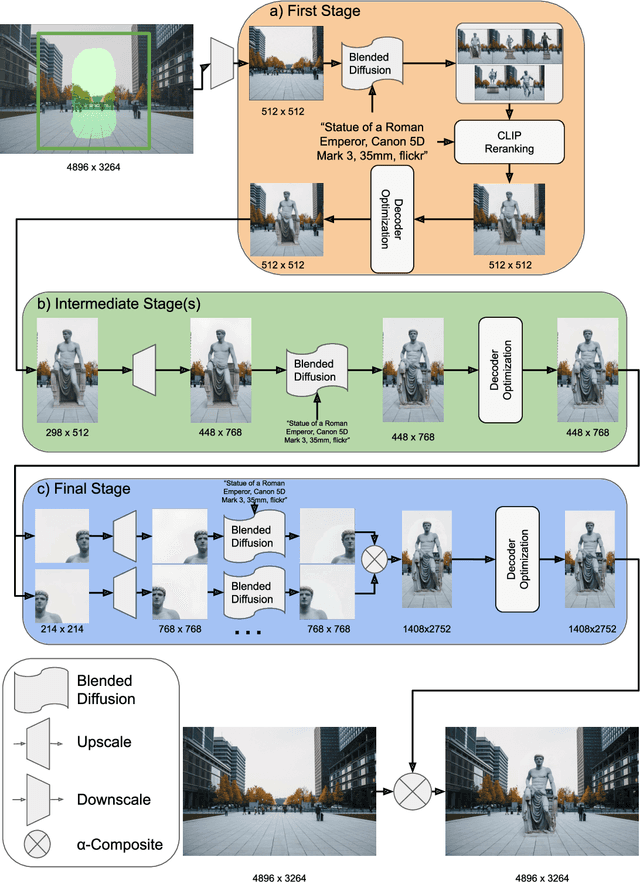

Diffusion models have shown great results in image generation and in image editing. However, current approaches are limited to low resolutions due to the computational cost of training diffusion models for high-resolution generation. We propose an approach that uses a pre-trained low-resolution diffusion model to edit images in the megapixel range. We first use Blended Diffusion to edit the image at a low resolution, and then upscale it in multiple stages, using a super-resolution model and Blended Diffusion. Using our approach, we achieve higher visual fidelity than by only applying off the shelf super-resolution methods to the output of the diffusion model. We also obtain better global consistency than directly using the diffusion model at a higher resolution.