 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Generalizable Two-Branch Framework for Image Class-Incremental Learning
Mar 09, 2024
Deep neural networks often severely forget previously learned knowledge when learning new knowledge. Various continual learning (CL) methods have been proposed to handle such a catastrophic forgetting issue from different perspectives and achieved substantial improvements.In this paper, a novel two-branch continual learning framework is proposed to further enhance most existing CL methods. Specifically, the main branch can be any existing CL model and the newly introduced side branch is a lightweight convolutional network. The output of each main branch block is modulated by the output of the corresponding side branch block. Such a simple two-branch model can then be easily implemented and learned with the vanilla optimization setting without whistles and bells.Extensive experiments with various settings on multiple image datasets show that the proposed framework yields consistent improvements over state-of-the-art methods.
Unveiling Ancient Maya Settlements Using Aerial LiDAR Image Segmentation
Mar 09, 2024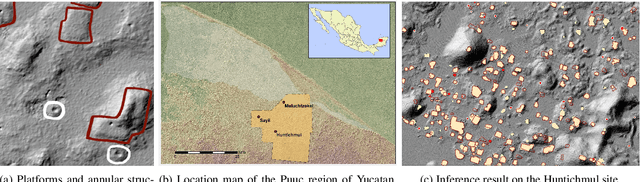

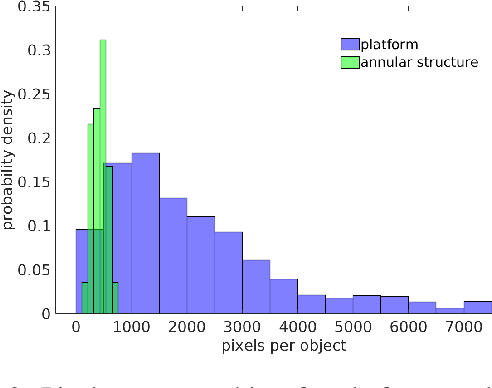
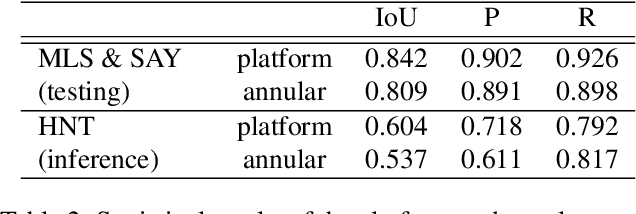
Manual identification of archaeological features in LiDAR imagery is labor-intensive, costly, and requires archaeological expertise. This paper shows how recent advancements in deep learning (DL) present efficient solutions for accurately segmenting archaeological structures in aerial LiDAR images using the YOLOv8 neural network. The proposed approach uses novel pre-processing of the raw LiDAR data and dataset augmentation methods to produce trained YOLOv8 networks to improve accuracy, precision, and recall for the segmentation of two important Maya structure types: annular structures and platforms. The results show an IoU performance of 0.842 for platforms and 0.809 for annular structures which outperform existing approaches. Further, analysis via domain experts considers the topological consistency of segmented regions and performance vs. area providing important insights. The approach automates time-consuming LiDAR image labeling which significantly accelerates accurate analysis of historical landscapes.
Modality-Agnostic Structural Image Representation Learning for Deformable Multi-Modality Medical Image Registration
Feb 29, 2024Establishing dense anatomical correspondence across distinct imaging modalities is a foundational yet challenging procedure for numerous medical image analysis studies and image-guided radiotherapy. Existing multi-modality image registration algorithms rely on statistical-based similarity measures or local structural image representations. However, the former is sensitive to locally varying noise, while the latter is not discriminative enough to cope with complex anatomical structures in multimodal scans, causing ambiguity in determining the anatomical correspondence across scans with different modalities. In this paper, we propose a modality-agnostic structural representation learning method, which leverages Deep Neighbourhood Self-similarity (DNS) and anatomy-aware contrastive learning to learn discriminative and contrast-invariance deep structural image representations (DSIR) without the need for anatomical delineations or pre-aligned training images. We evaluate our method on multiphase CT, abdomen MR-CT, and brain MR T1w-T2w registration. Comprehensive results demonstrate that our method is superior to the conventional local structural representation and statistical-based similarity measures in terms of discriminability and accuracy.
Collage Prompting: Budget-Friendly Visual Recognition with GPT-4V
Mar 18, 2024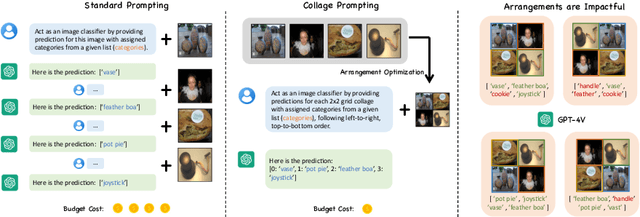
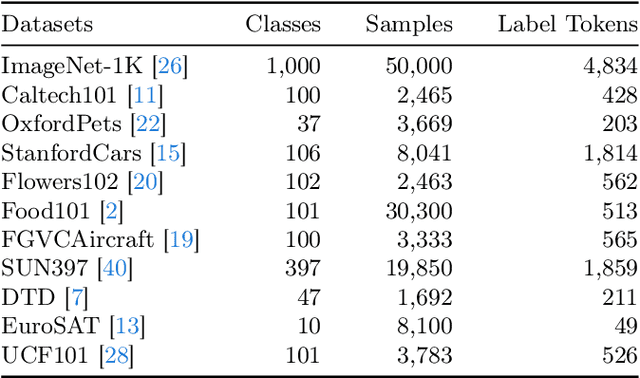
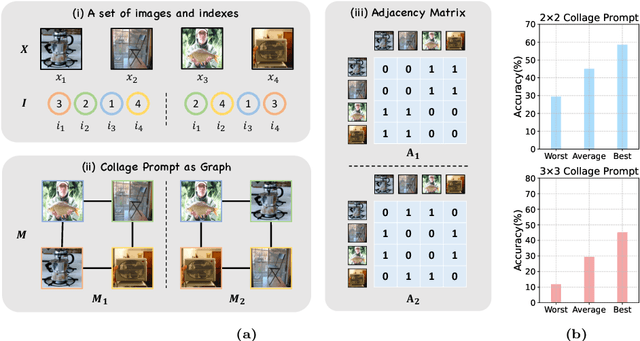
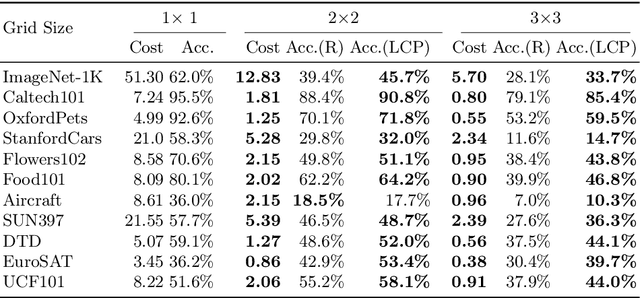
Recent advancements in generative AI have suggested that by taking visual prompt, GPT-4V can demonstrate significant proficiency in image recognition task. Despite its impressive capabilities, the financial cost associated with GPT-4V's inference presents a substantial barrier for its wide use. To address this challenge, our work introduces Collage Prompting, a budget-friendly prompting approach that concatenates multiple images into a single visual input. With collage prompt, GPT-4V is able to perform image recognition on several images simultaneously. Based on the observation that the accuracy of GPT-4V's image recognition varies significantly with the order of images within the collage prompt, our method further learns to optimize the arrangement of images for maximum recognition accuracy. A graph predictor is trained to indicate the accuracy of each collage prompt, then we propose an optimization method to navigate the search space of possible image arrangements. Experiment results across various datasets demonstrate the cost-efficiency score of collage prompt is much larger than standard prompt. Additionally, collage prompt with learned arrangement achieves clearly better accuracy than collage prompt with random arrangement in GPT-4V's visual recognition.
Boarding for ISS: Imbalanced Self-Supervised: Discovery of a Scaled Autoencoder for Mixed Tabular Datasets
Mar 23, 2024The field of imbalanced self-supervised learning, especially in the context of tabular data, has not been extensively studied. Existing research has predominantly focused on image datasets. This paper aims to fill this gap by examining the specific challenges posed by data imbalance in self-supervised learning in the domain of tabular data, with a primary focus on autoencoders. Autoencoders are widely employed for learning and constructing a new representation of a dataset, particularly for dimensionality reduction. They are also often used for generative model learning, as seen in variational autoencoders. When dealing with mixed tabular data, qualitative variables are often encoded using a one-hot encoder with a standard loss function (MSE or Cross Entropy). In this paper, we analyze the drawbacks of this approach, especially when categorical variables are imbalanced. We propose a novel metric to balance learning: a Multi-Supervised Balanced MSE. This approach reduces the reconstruction error by balancing the influence of variables. Finally, we empirically demonstrate that this new metric, compared to the standard MSE: i) outperforms when the dataset is imbalanced, especially when the learning process is insufficient, and ii) provides similar results in the opposite case.
PEaCE: A Chemistry-Oriented Dataset for Optical Character Recognition on Scientific Documents
Mar 23, 2024Optical Character Recognition (OCR) is an established task with the objective of identifying the text present in an image. While many off-the-shelf OCR models exist, they are often trained for either scientific (e.g., formulae) or generic printed English text. Extracting text from chemistry publications requires an OCR model that is capable in both realms. Nougat, a recent tool, exhibits strong ability to parse academic documents, but is unable to parse tables in PubMed articles, which comprises a significant part of the academic community and is the focus of this work. To mitigate this gap, we present the Printed English and Chemical Equations (PEaCE) dataset, containing both synthetic and real-world records, and evaluate the efficacy of transformer-based OCR models when trained on this resource. Given that real-world records contain artifacts not present in synthetic records, we propose transformations that mimic such qualities. We perform a suite of experiments to explore the impact of patch size, multi-domain training, and our proposed transformations, ultimately finding that models with a small patch size trained on multiple domains using the proposed transformations yield the best performance. Our dataset and code is available at https://github.com/ZN1010/PEaCE.
Technical Report: Masked Skeleton Sequence Modeling for Learning Larval Zebrafish Behavior Latent Embeddings
Mar 23, 2024In this report, we introduce a novel self-supervised learning method for extracting latent embeddings from behaviors of larval zebrafish. Drawing inspiration from Masked Modeling techniquesutilized in image processing with Masked Autoencoders (MAE) \cite{he2022masked} and in natural language processing with Generative Pre-trained Transformer (GPT) \cite{radford2018improving}, we treat behavior sequences as a blend of images and language. For the skeletal sequences of swimming zebrafish, we propose a pioneering Transformer-CNN architecture, the Sequence Spatial-Temporal Transformer (SSTFormer), designed to capture the inter-frame correlation of different joints. This correlation is particularly valuable, as it reflects the coordinated movement of various parts of the fish body across adjacent frames. To handle the high frame rate, we segment the skeleton sequence into distinct time slices, analogous to "words" in a sentence, and employ self-attention transformer layers to encode the consecutive frames within each slice, capturing the spatial correlation among different joints. Furthermore, we incorporate a CNN-based attention module to enhance the representations outputted by the transformer layers. Lastly, we introduce a temporal feature aggregation operation between time slices to improve the discrimination of similar behaviors.
AutoInst: Automatic Instance-Based Segmentation of LiDAR 3D Scans
Mar 24, 2024Recently, progress in acquisition equipment such as LiDAR sensors has enabled sensing increasingly spacious outdoor 3D environments. Making sense of such 3D acquisitions requires fine-grained scene understanding, such as constructing instance-based 3D scene segmentations. Commonly, a neural network is trained for this task; however, this requires access to a large, densely annotated dataset, which is widely known to be challenging to obtain. To address this issue, in this work we propose to predict instance segmentations for 3D scenes in an unsupervised way, without relying on ground-truth annotations. To this end, we construct a learning framework consisting of two components: (1) a pseudo-annotation scheme for generating initial unsupervised pseudo-labels; and (2) a self-training algorithm for instance segmentation to fit robust, accurate instances from initial noisy proposals. To enable generating 3D instance mask proposals, we construct a weighted proxy-graph by connecting 3D points with edges integrating multi-modal image- and point-based self-supervised features, and perform graph-cuts to isolate individual pseudo-instances. We then build on a state-of-the-art point-based architecture and train a 3D instance segmentation model, resulting in significant refinement of initial proposals. To scale to arbitrary complexity 3D scenes, we design our algorithm to operate on local 3D point chunks and construct a merging step to generate scene-level instance segmentations. Experiments on the challenging SemanticKITTI benchmark demonstrate the potential of our approach, where it attains 13.3% higher Average Precision and 9.1% higher F1 score compared to the best-performing baseline. The code will be made publicly available at https://github.com/artonson/autoinst.
Low-Dose CT Image Reconstruction by Fine-Tuning a UNet Pretrained for Gaussian Denoising for the Downstream Task of Image Enhancement
Mar 06, 2024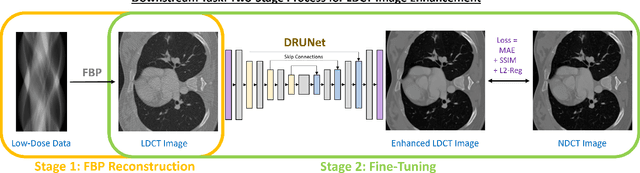

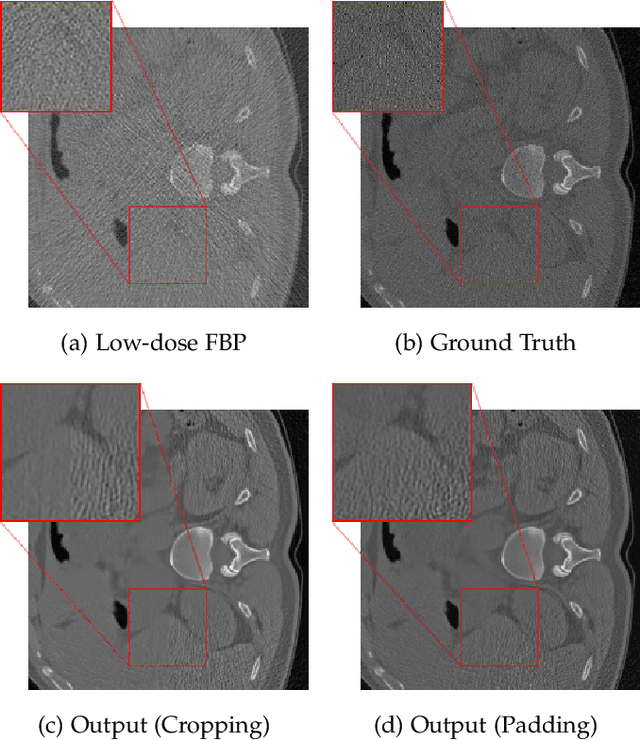

Computed Tomography (CT) is a widely used medical imaging modality, and as it is based on ionizing radiation, it is desirable to minimize the radiation dose. However, a reduced radiation dose comes with reduced image quality, and reconstruction from low-dose CT (LDCT) data is still a challenging task which is subject to research. According to the LoDoPaB-CT benchmark, a benchmark for LDCT reconstruction, many state-of-the-art methods use pipelines involving UNet-type architectures. Specifically the top ranking method, ItNet, employs a three-stage process involving filtered backprojection (FBP), a UNet trained on CT data, and an iterative refinement step. In this paper, we propose a less complex two-stage method. The first stage also employs FBP, while the novelty lies in the training strategy for the second stage, characterized as the CT image enhancement stage. The crucial point of our approach is that the neural network is pretrained on a distinctly different pretraining task with non-CT data, namely Gaussian noise removal on a variety of natural grayscale images (photographs). We then fine-tune this network for the downstream task of CT image enhancement using pairs of LDCT images and corresponding normal-dose CT images (NDCT). Despite being notably simpler than the state-of-the-art, as the pretraining did not depend on domain-specific CT data and no further iterative refinement step was necessary, the proposed two-stage method achieves competitive results. The proposed method achieves a shared top ranking in the LoDoPaB-CT challenge and a first position with respect to the SSIM metric.
Block-wise LoRA: Revisiting Fine-grained LoRA for Effective Personalization and Stylization in Text-to-Image Generation
Mar 12, 2024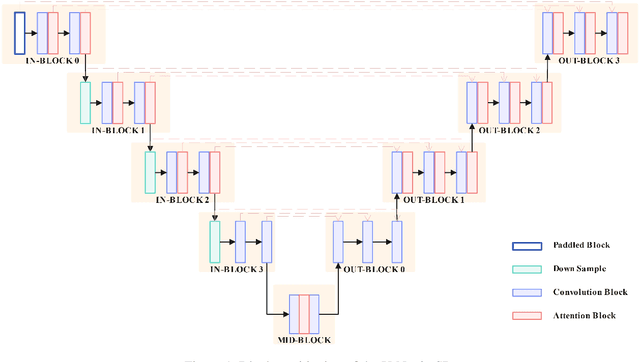



The objective of personalization and stylization in text-to-image is to instruct a pre-trained diffusion model to analyze new concepts introduced by users and incorporate them into expected styles. Recently, parameter-efficient fine-tuning (PEFT) approaches have been widely adopted to address this task and have greatly propelled the development of this field. Despite their popularity, existing efficient fine-tuning methods still struggle to achieve effective personalization and stylization in T2I generation. To address this issue, we propose block-wise Low-Rank Adaptation (LoRA) to perform fine-grained fine-tuning for different blocks of SD, which can generate images faithful to input prompts and target identity and also with desired style. Extensive experiments demonstrate the effectiveness of the proposed method.