 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Instruct-NeRF2NeRF: Editing 3D Scenes with Instructions
Mar 22, 2023

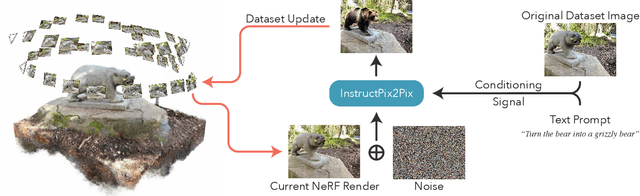


We propose a method for editing NeRF scenes with text-instructions. Given a NeRF of a scene and the collection of images used to reconstruct it, our method uses an image-conditioned diffusion model (InstructPix2Pix) to iteratively edit the input images while optimizing the underlying scene, resulting in an optimized 3D scene that respects the edit instruction. We demonstrate that our proposed method is able to edit large-scale, real-world scenes, and is able to accomplish more realistic, targeted edits than prior work.
SVCNet: Scribble-based Video Colorization Network with Temporal Aggregation
Mar 21, 2023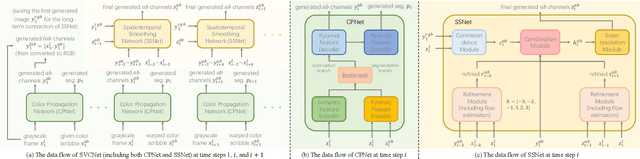



In this paper, we propose a scribble-based video colorization network with temporal aggregation called SVCNet. It can colorize monochrome videos based on different user-given color scribbles. It addresses three common issues in the scribble-based video colorization area: colorization vividness, temporal consistency, and color bleeding. To improve the colorization quality and strengthen the temporal consistency, we adopt two sequential sub-networks in SVCNet for precise colorization and temporal smoothing, respectively. The first stage includes a pyramid feature encoder to incorporate color scribbles with a grayscale frame, and a semantic feature encoder to extract semantics. The second stage finetunes the output from the first stage by aggregating the information of neighboring colorized frames (as short-range connections) and the first colorized frame (as a long-range connection). To alleviate the color bleeding artifacts, we learn video colorization and segmentation simultaneously. Furthermore, we set the majority of operations on a fixed small image resolution and use a Super-resolution Module at the tail of SVCNet to recover original sizes. It allows the SVCNet to fit different image resolutions at the inference. Finally, we evaluate the proposed SVCNet on DAVIS and Videvo benchmarks. The experimental results demonstrate that SVCNet produces both higher-quality and more temporally consistent videos than other well-known video colorization approaches. The codes and models can be found at https://github.com/zhaoyuzhi/SVCNet.
Soft labelling for semantic segmentation: Bringing coherence to label down-sampling
Feb 27, 2023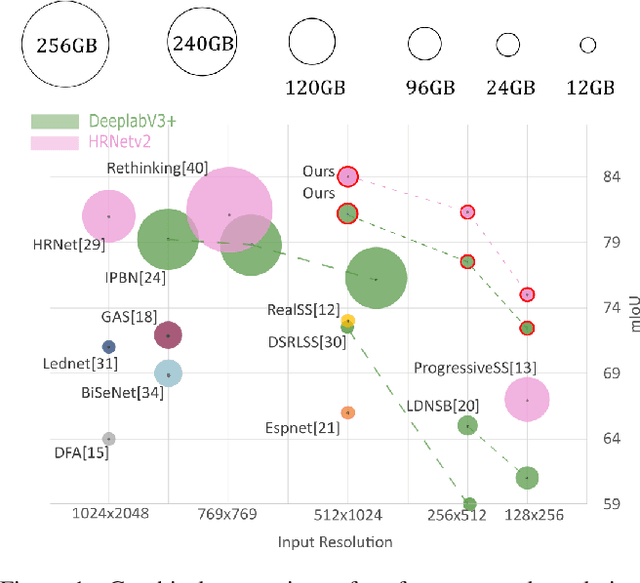


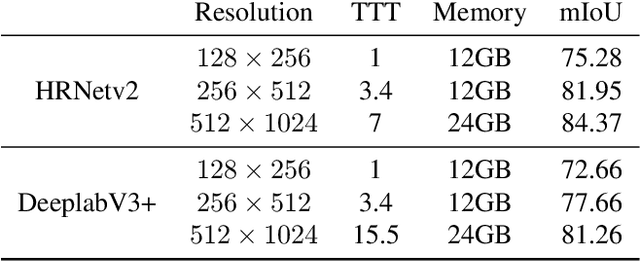
In semantic segmentation, training data down-sampling is commonly performed because of limited resources, adapting image size to the model input, or improving data augmentation. This down-sampling typically employs different strategies for the image data and the annotated labels. Such discrepancy leads to mismatches between the down-sampled pixels and labels. Hence, training performance significantly decreases as the down-sampling factor increases. In this paper, we bring together the downsampling strategies for the image data and annotated labels. To that aim, we propose a soft-labeling method for label down-sampling that takes advantage of structural content prior to down-sampling. Thereby, fully aligning softlabels with image data to keep the distribution of the sampled pixels. This proposal also produces richer annotations for under-represented semantic classes. Altogether, it permits training competitive models at lower resolutions. Experiments show that the proposal outperforms other downsampling strategies. Moreover, state of the art performance is achieved for reference benchmarks, but employing significantly less computational resources than other approaches. This proposal enables competitive research for semantic segmentation under resource constraints.
DATID-3D: Diversity-Preserved Domain Adaptation Using Text-to-Image Diffusion for 3D Generative Model
Nov 29, 2022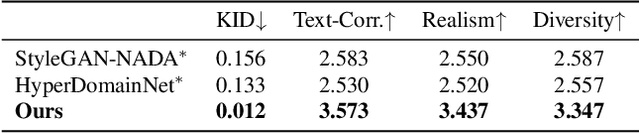
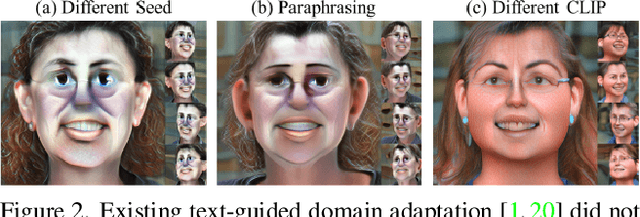
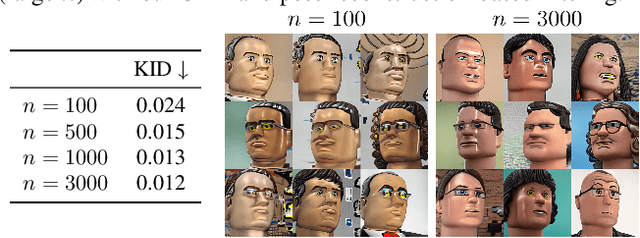
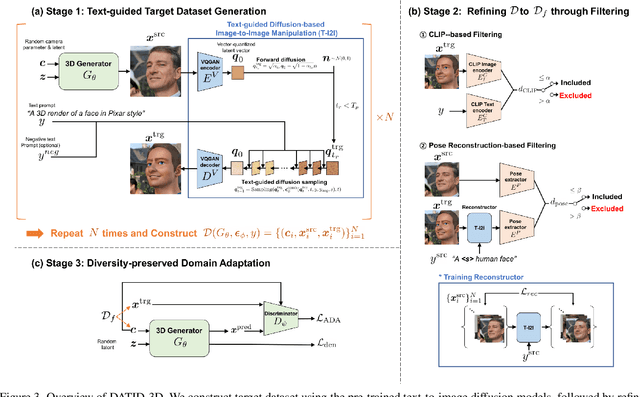
Recent 3D generative models have achieved remarkable performance in synthesizing high resolution photorealistic images with view consistency and detailed 3D shapes, but training them for diverse domains is challenging since it requires massive training images and their camera distribution information. Text-guided domain adaptation methods have shown impressive performance on converting the 2D generative model on one domain into the models on other domains with different styles by leveraging the CLIP (Contrastive Language-Image Pre-training), rather than collecting massive datasets for those domains. However, one drawback of them is that the sample diversity in the original generative model is not well-preserved in the domain-adapted generative models due to the deterministic nature of the CLIP text encoder. Text-guided domain adaptation will be even more challenging for 3D generative models not only because of catastrophic diversity loss, but also because of inferior text-image correspondence and poor image quality. Here we propose DATID-3D, a domain adaptation method tailored for 3D generative models using text-to-image diffusion models that can synthesize diverse images per text prompt without collecting additional images and camera information for the target domain. Unlike 3D extensions of prior text-guided domain adaptation methods, our novel pipeline was able to fine-tune the state-of-the-art 3D generator of the source domain to synthesize high resolution, multi-view consistent images in text-guided targeted domains without additional data, outperforming the existing text-guided domain adaptation methods in diversity and text-image correspondence. Furthermore, we propose and demonstrate diverse 3D image manipulations such as one-shot instance-selected adaptation and single-view manipulated 3D reconstruction to fully enjoy diversity in text.
Zolly: Zoom Focal Length Correctly for Perspective-Distorted Human Mesh Reconstruction
Mar 24, 2023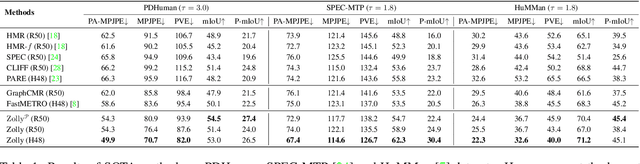
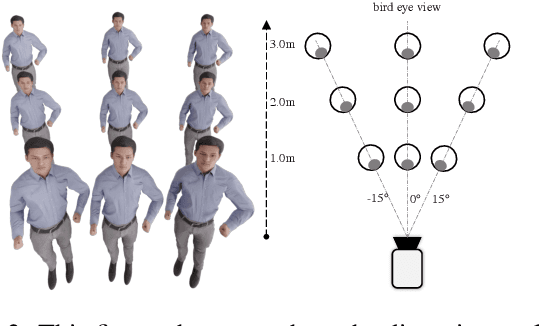
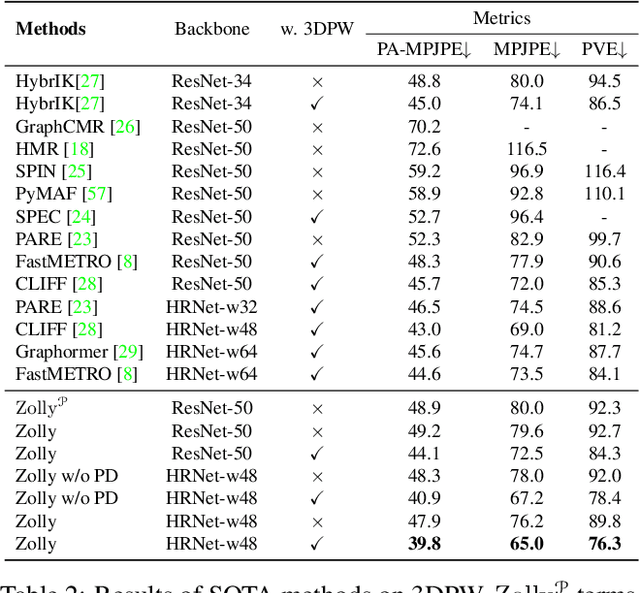
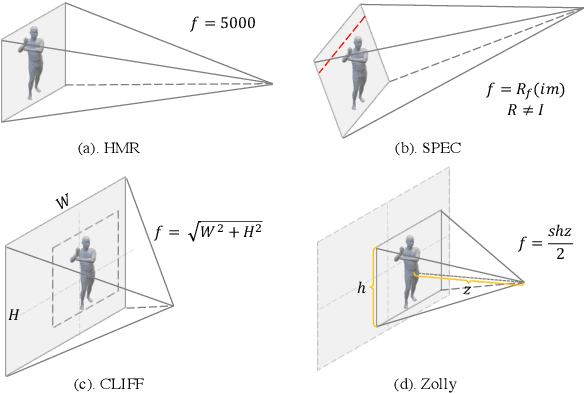
As it is hard to calibrate single-view RGB images in the wild, existing 3D human mesh reconstruction (3DHMR) methods either use a constant large focal length or estimate one based on the background environment context, which can not tackle the problem of the torso, limb, hand or face distortion caused by perspective camera projection when the camera is close to the human body. The naive focal length assumptions can harm this task with the incorrectly formulated projection matrices. To solve this, we propose Zolly, the first 3DHMR method focusing on perspective-distorted images. Our approach begins with analysing the reason for perspective distortion, which we find is mainly caused by the relative location of the human body to the camera center. We propose a new camera model and a novel 2D representation, termed distortion image, which describes the 2D dense distortion scale of the human body. We then estimate the distance from distortion scale features rather than environment context features. Afterwards, we integrate the distortion feature with image features to reconstruct the body mesh. To formulate the correct projection matrix and locate the human body position, we simultaneously use perspective and weak-perspective projection loss. Since existing datasets could not handle this task, we propose the first synthetic dataset PDHuman and extend two real-world datasets tailored for this task, all containing perspective-distorted human images. Extensive experiments show that Zolly outperforms existing state-of-the-art methods on both perspective-distorted datasets and the standard benchmark (3DPW).
Sequential edge detection using joint hierarchical Bayesian learning
Feb 28, 2023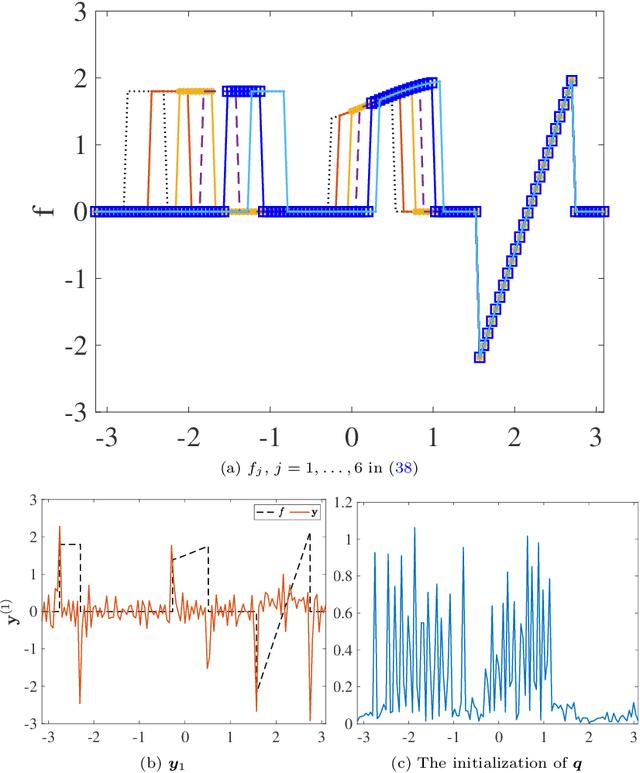
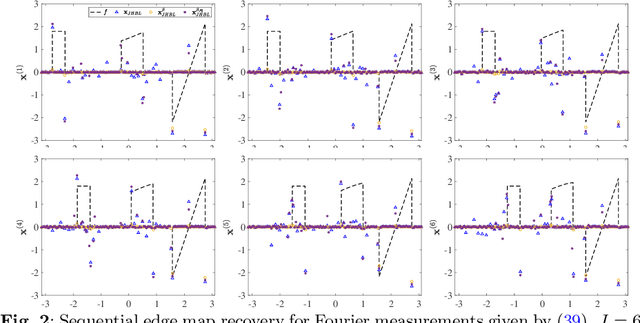
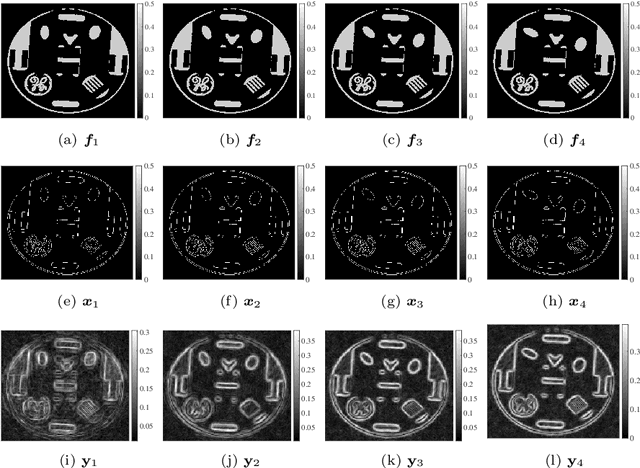

This paper introduces a new sparse Bayesian learning (SBL) algorithm that jointly recovers a temporal sequence of edge maps from noisy and under-sampled Fourier data. The new method is cast in a Bayesian framework and uses a prior that simultaneously incorporates intra-image information to promote sparsity in each individual edge map with inter-image information to promote similarities in any unchanged regions. By treating both the edges as well as the similarity between adjacent images as random variables, there is no need to separately form regions of change. Thus we avoid both additional computational cost as well as any information loss resulting from pre-processing the image. Our numerical examples demonstrate that our new method compares favorably with more standard SBL approaches.
SelfPromer: Self-Prompt Dehazing Transformers with Depth-Consistency
Mar 13, 2023

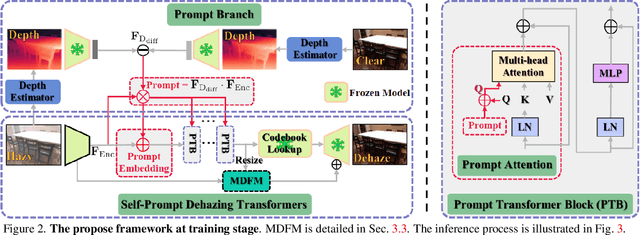
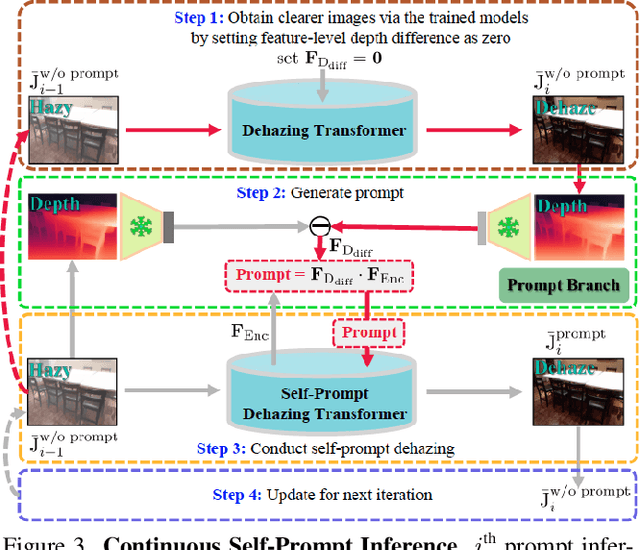
This work presents an effective depth-consistency self-prompt Transformer for image dehazing. It is motivated by an observation that the estimated depths of an image with haze residuals and its clear counterpart vary. Enforcing the depth consistency of dehazed images with clear ones, therefore, is essential for dehazing. For this purpose, we develop a prompt based on the features of depth differences between the hazy input images and corresponding clear counterparts that can guide dehazing models for better restoration. Specifically, we first apply deep features extracted from the input images to the depth difference features for generating the prompt that contains the haze residual information in the input. Then we propose a prompt embedding module that is designed to perceive the haze residuals, by linearly adding the prompt to the deep features. Further, we develop an effective prompt attention module to pay more attention to haze residuals for better removal. By incorporating the prompt, prompt embedding, and prompt attention into an encoder-decoder network based on VQGAN, we can achieve better perception quality. As the depths of clear images are not available at inference, and the dehazed images with one-time feed-forward execution may still contain a portion of haze residuals, we propose a new continuous self-prompt inference that can iteratively correct the dehazing model towards better haze-free image generation. Extensive experiments show that our method performs favorably against the state-of-the-art approaches on both synthetic and real-world datasets in terms of perception metrics including NIQE, PI, and PIQE.
Regional Deep Atrophy: a Self-Supervised Learning Method to Automatically Identify Regions Associated With Alzheimer's Disease Progression From Longitudinal MRI
Apr 10, 2023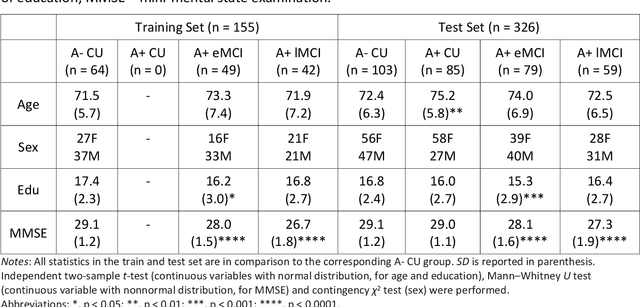
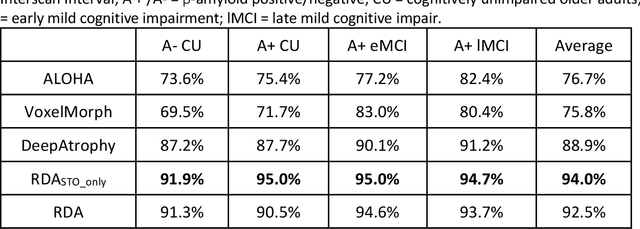
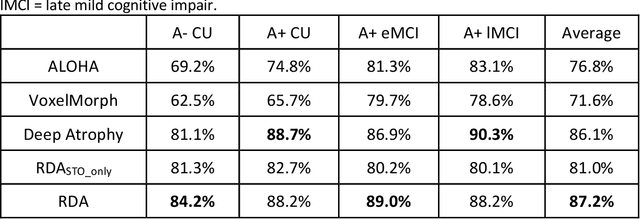
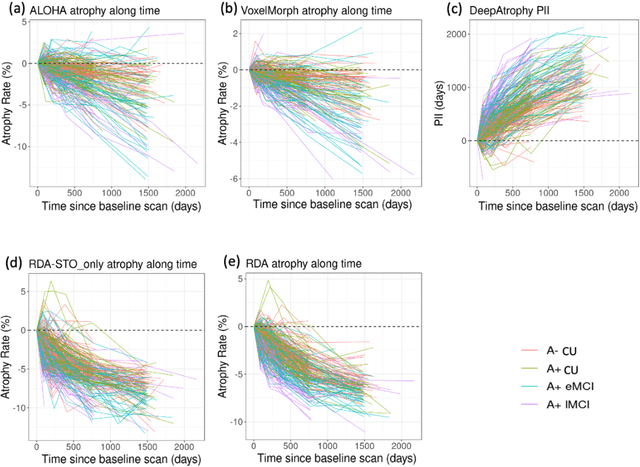
Longitudinal assessment of brain atrophy, particularly in the hippocampus, is a well-studied biomarker for neurodegenerative diseases, such as Alzheimer's disease (AD). In clinical trials, estimation of brain progressive rates can be applied to track therapeutic efficacy of disease modifying treatments. However, most state-of-the-art measurements calculate changes directly by segmentation and/or deformable registration of MRI images, and may misreport head motion or MRI artifacts as neurodegeneration, impacting their accuracy. In our previous study, we developed a deep learning method DeepAtrophy that uses a convolutional neural network to quantify differences between longitudinal MRI scan pairs that are associated with time. DeepAtrophy has high accuracy in inferring temporal information from longitudinal MRI scans, such as temporal order or relative inter-scan interval. DeepAtrophy also provides an overall atrophy score that was shown to perform well as a potential biomarker of disease progression and treatment efficacy. However, DeepAtrophy is not interpretable, and it is unclear what changes in the MRI contribute to progression measurements. In this paper, we propose Regional Deep Atrophy (RDA), which combines the temporal inference approach from DeepAtrophy with a deformable registration neural network and attention mechanism that highlights regions in the MRI image where longitudinal changes are contributing to temporal inference. RDA has similar prediction accuracy as DeepAtrophy, but its additional interpretability makes it more acceptable for use in clinical settings, and may lead to more sensitive biomarkers for disease monitoring in clinical trials of early AD.
SparseFormer: Sparse Visual Recognition via Limited Latent Tokens
Apr 07, 2023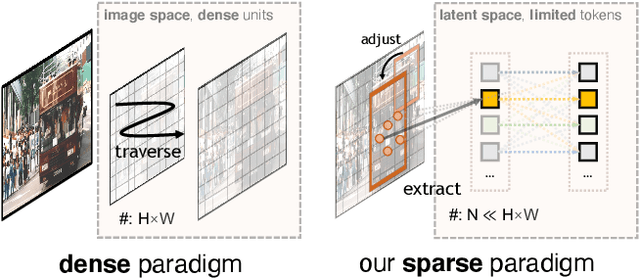

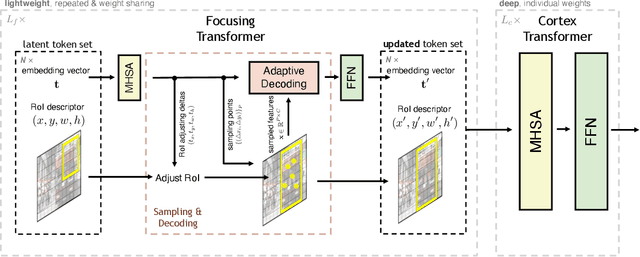
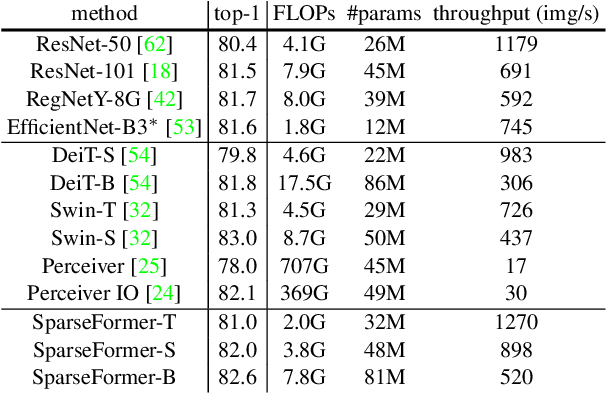
Human visual recognition is a sparse process, where only a few salient visual cues are attended to rather than traversing every detail uniformly. However, most current vision networks follow a dense paradigm, processing every single visual unit (e.g,, pixel or patch) in a uniform manner. In this paper, we challenge this dense paradigm and present a new method, coined SparseFormer, to imitate human's sparse visual recognition in an end-to-end manner. SparseFormer learns to represent images using a highly limited number of tokens (down to 49) in the latent space with sparse feature sampling procedure instead of processing dense units in the original pixel space. Therefore, SparseFormer circumvents most of dense operations on the image space and has much lower computational costs. Experiments on the ImageNet classification benchmark dataset show that SparseFormer achieves performance on par with canonical or well-established models while offering better accuracy-throughput tradeoff. Moreover, the design of our network can be easily extended to the video classification with promising performance at lower computational costs. We hope that our work can provide an alternative way for visual modeling and inspire further research on sparse neural architectures. The code will be publicly available at https://github.com/showlab/sparseformer
Architecture-Preserving Provable Repair of Deep Neural Networks
Apr 07, 2023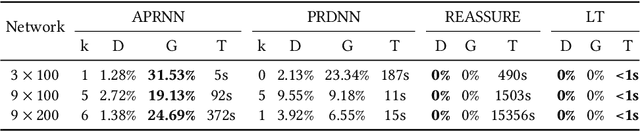
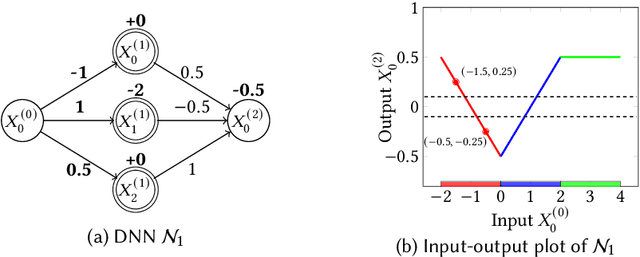
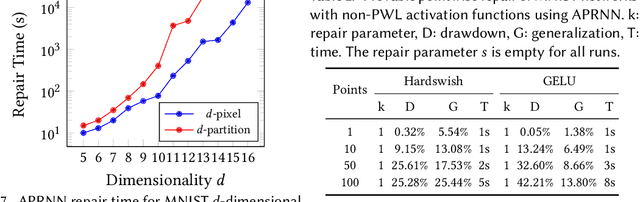
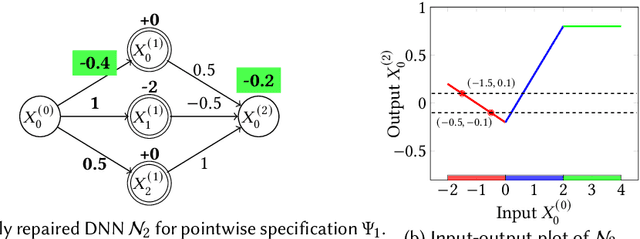
Deep neural networks (DNNs) are becoming increasingly important components of software, and are considered the state-of-the-art solution for a number of problems, such as image recognition. However, DNNs are far from infallible, and incorrect behavior of DNNs can have disastrous real-world consequences. This paper addresses the problem of architecture-preserving V-polytope provable repair of DNNs. A V-polytope defines a convex bounded polytope using its vertex representation. V-polytope provable repair guarantees that the repaired DNN satisfies the given specification on the infinite set of points in the given V-polytope. An architecture-preserving repair only modifies the parameters of the DNN, without modifying its architecture. The repair has the flexibility to modify multiple layers of the DNN, and runs in polynomial time. It supports DNNs with activation functions that have some linear pieces, as well as fully-connected, convolutional, pooling and residual layers. To the best our knowledge, this is the first provable repair approach that has all of these features. We implement our approach in a tool called APRNN. Using MNIST, ImageNet, and ACAS Xu DNNs, we show that it has better efficiency, scalability, and generalization compared to PRDNN and REASSURE, prior provable repair methods that are not architecture preserving.