 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Exploring Deep Learning Methods for Classification of SAR Images: Towards NextGen Convolutions via Transformers
Mar 28, 2023
Images generated by high-resolution SAR have vast areas of application as they can work better in adverse light and weather conditions. One such area of application is in the military systems. This study is an attempt to explore the suitability of current state-of-the-art models introduced in the domain of computer vision for SAR target classification (MSTAR). Since the application of any solution produced for military systems would be strategic and real-time, accuracy is often not the only criterion to measure its performance. Other important parameters like prediction time and input resiliency are equally important. The paper deals with these issues in the context of SAR images. Experimental results show that deep learning models can be suitably applied in the domain of SAR image classification with the desired performance levels.
* 6 pages, 9 figures
DCS-RISR: Dynamic Channel Splitting for Efficient Real-world Image Super-Resolution
Dec 17, 2022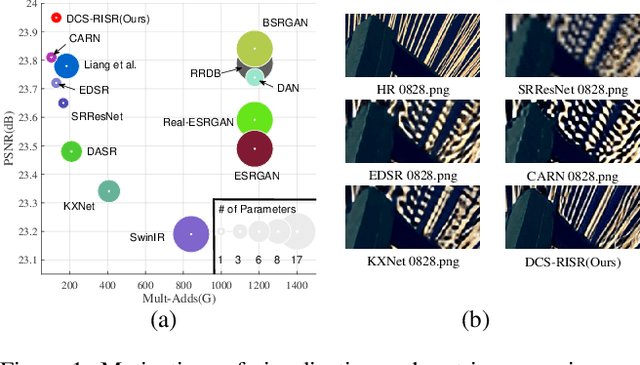
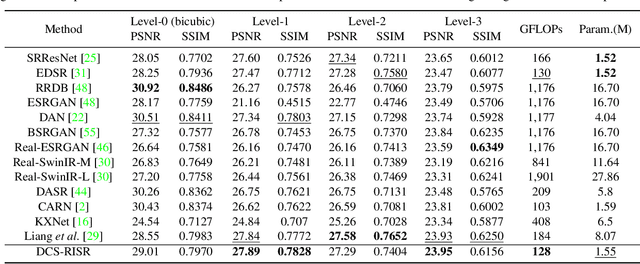
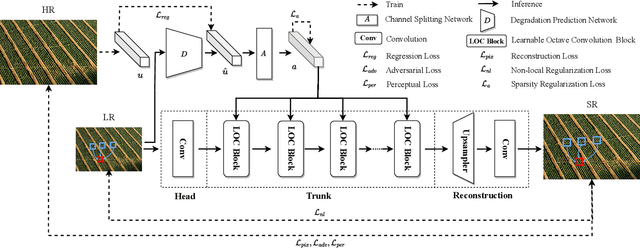
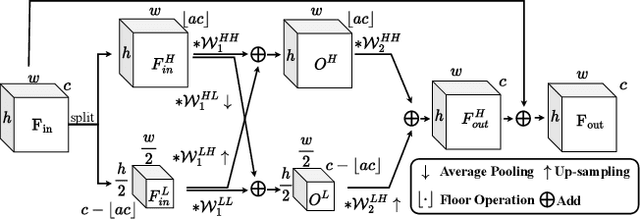
Real-world image super-resolution (RISR) has received increased focus for improving the quality of SR images under unknown complex degradation. Existing methods rely on the heavy SR models to enhance low-resolution (LR) images of different degradation levels, which significantly restricts their practical deployments on resource-limited devices. In this paper, we propose a novel Dynamic Channel Splitting scheme for efficient Real-world Image Super-Resolution, termed DCS-RISR. Specifically, we first introduce the light degradation prediction network to regress the degradation vector to simulate the real-world degradations, upon which the channel splitting vector is generated as the input for an efficient SR model. Then, a learnable octave convolution block is proposed to adaptively decide the channel splitting scale for low- and high-frequency features at each block, reducing computation overhead and memory cost by offering the large scale to low-frequency features and the small scale to the high ones. To further improve the RISR performance, Non-local regularization is employed to supplement the knowledge of patches from LR and HR subspace with free-computation inference. Extensive experiments demonstrate the effectiveness of DCS-RISR on different benchmark datasets. Our DCS-RISR not only achieves the best trade-off between computation/parameter and PSNR/SSIM metric, and also effectively handles real-world images with different degradation levels.
Superresolution Reconstruction of Single Image for Latent features
Nov 25, 2022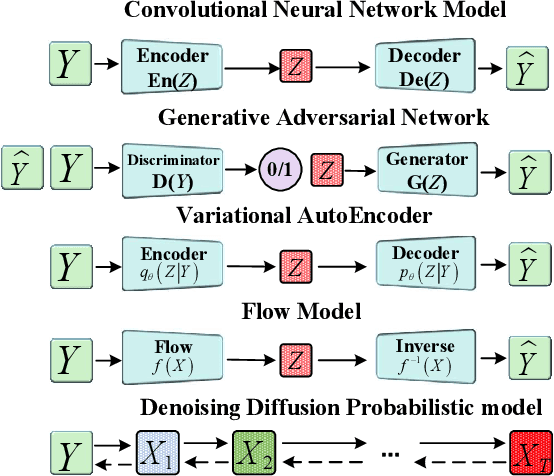

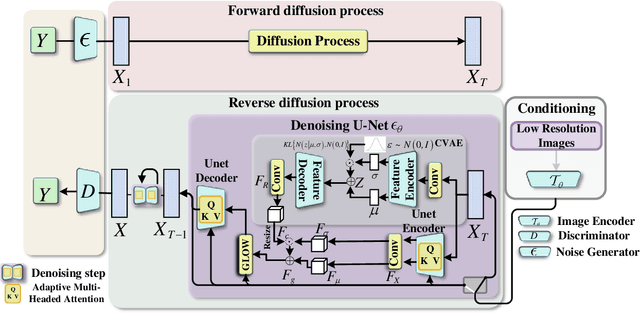
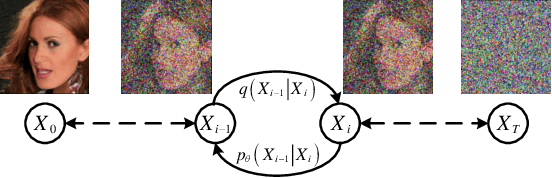
In recent years, Deep Learning has shown good results in the Single Image Superresolution Reconstruction (SISR) task, thus becoming the most widely used methods in this field. The SISR task is a typical task to solve an uncertainty problem. Therefore, it is often challenging to meet the requirements of High-quality sampling, fast Sampling, and diversity of details and texture after Sampling simultaneously in a SISR task.It leads to model collapse, lack of details and texture features after Sampling, and too long Sampling time in High Resolution (HR) image reconstruction methods. This paper proposes a Diffusion Probability model for Latent features (LDDPM) to solve these problems. Firstly, a Conditional Encoder is designed to effectively encode Low-Resolution (LR) images, thereby reducing the solution space of reconstructed images to improve the performance of reconstructed images. Then, the Normalized Flow and Multi-modal adversarial training are used to model the denoising distribution with complex Multi-modal distribution so that the Generative Modeling ability of the model can be improved with a small number of Sampling steps. Experimental results on mainstream datasets demonstrate that our proposed model reconstructs more realistic HR images and obtains better PSNR and SSIM performance compared to existing SISR tasks, thus providing a new idea for SISR tasks.
Quantum Kernel for Image Classification of Real World Manufacturing Defects
Dec 16, 2022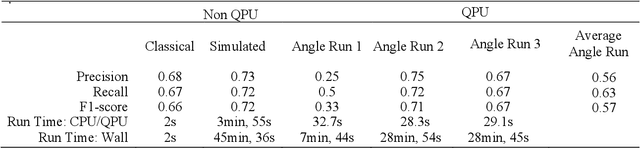
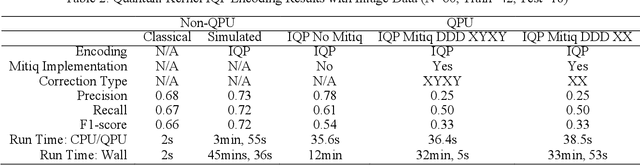
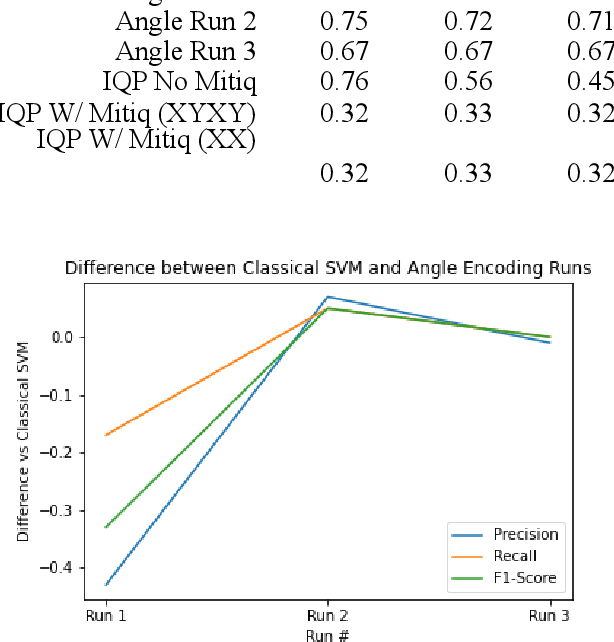
The quantum kernel method results clearly outperformed a classical SVM when analyzing low-resolution images with minimal feature selection on the quantum simulator, with inconsistent results when run on an actual quantum processor. We chose to use an existing quantum kernel method for classification. We applied dynamic decoupling error mitigation using the Mitiq package to the Quantum SVM kernel method, which, to our knowledge, has never been done for quantum kernel methods for image classification. We applied the quantum kernel method to classify real world image data from a manufacturing facility using a superconducting quantum computer. The manufacturing images were used to determine if a product was defective or was produced correctly through the manufacturing process. We also tested the Mitiq dynamical decoupling (DD) methodology to understand effectiveness in decreasing noise-related errors. We also found that the way classical data was encoded onto qubits in quantum states affected our results. All three quantum processing unit (QPU) runs of our angle encoded circuit returned different results, with one run having better than classical results, one run having equivalent to classical results, and a run with worse than classical results. The more complex instantaneous quantum polynomial (IQP) encoding approach showed better precision than classical SVM results when run on a QPU but had a worse recall and F1-score. We found that DD error mitigation did not improve the results of IQP encoded circuits runs and did not have an impact on angle encoded circuits runs on the QPU. In summary, we found that the angle encoded circuit performed the best of the quantum kernel encoding methods on real quantum hardware. In future research projects using quantum kernels to classify images, we recommend exploring other error mitigation techniques than Mitiq DD.
Self-supervised video pretraining yields strong image representations
Oct 12, 2022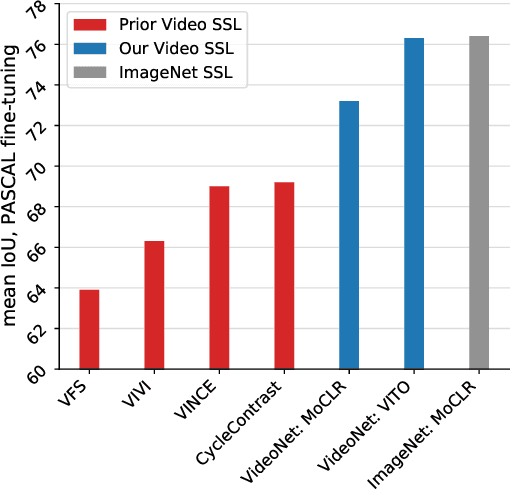
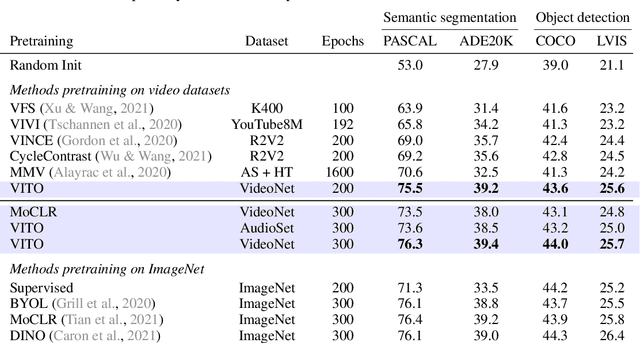
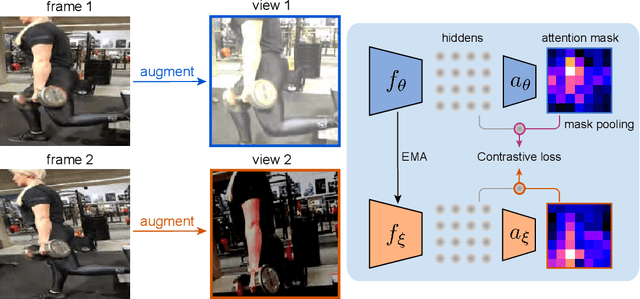
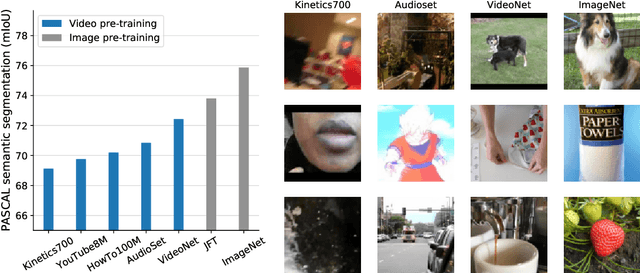
Videos contain far more information than still images and hold the potential for learning rich representations of the visual world. Yet, pretraining on image datasets has remained the dominant paradigm for learning representations that capture spatial information, and previous attempts at video pretraining have fallen short on image understanding tasks. In this work we revisit self-supervised learning of image representations from the dynamic evolution of video frames. To that end, we propose a dataset curation procedure that addresses the domain mismatch between video and image datasets, and develop a contrastive learning framework which handles the complex transformations present in natural videos. This simple paradigm for distilling knowledge from videos to image representations, called VITO, performs surprisingly well on a variety of image-based transfer learning tasks. For the first time, our video-pretrained model closes the gap with ImageNet pretraining on semantic segmentation on PASCAL and ADE20K and object detection on COCO and LVIS, suggesting that video-pretraining could become the new default for learning image representations.
Exploring Vision-Language Models for Imbalanced Learning
Apr 04, 2023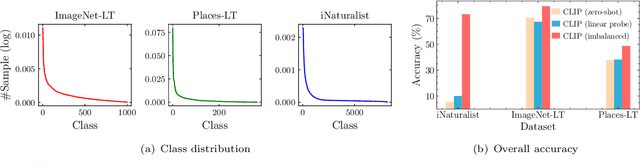
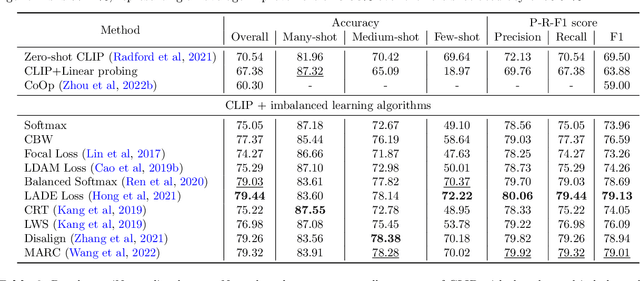
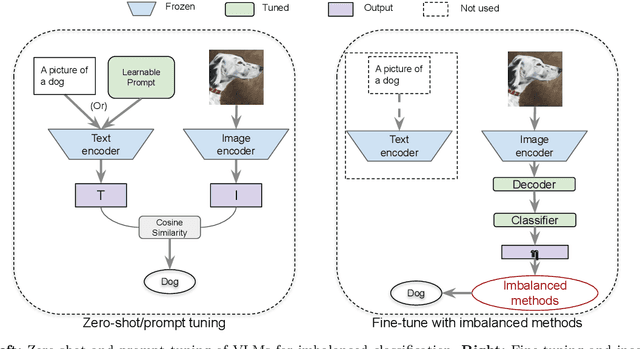
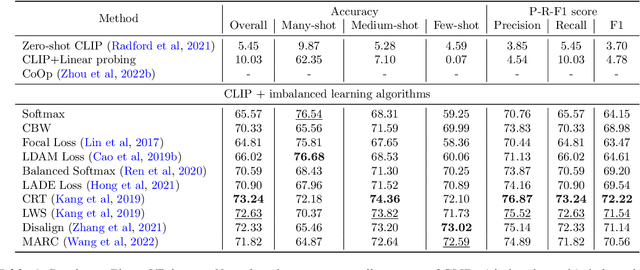
Vision-Language models (VLMs) that use contrastive language-image pre-training have shown promising zero-shot classification performance. However, their performance on imbalanced dataset is relatively poor, where the distribution of classes in the training dataset is skewed, leading to poor performance in predicting minority classes. For instance, CLIP achieved only 5% accuracy on the iNaturalist18 dataset. We propose to add a lightweight decoder to VLMs to avoid OOM (out of memory) problem caused by large number of classes and capture nuanced features for tail classes. Then, we explore improvements of VLMs using prompt tuning, fine-tuning, and incorporating imbalanced algorithms such as Focal Loss, Balanced SoftMax and Distribution Alignment. Experiments demonstrate that the performance of VLMs can be further boosted when used with decoder and imbalanced methods. Specifically, our improved VLMs significantly outperforms zero-shot classification by an average accuracy of 6.58%, 69.82%, and 6.17%, on ImageNet-LT, iNaturalist18, and Places-LT, respectively. We further analyze the influence of pre-training data size, backbones, and training cost. Our study highlights the significance of imbalanced learning algorithms in face of VLMs pre-trained by huge data. We release our code at https://github.com/Imbalance-VLM/Imbalance-VLM.
Uncertainty estimation in Deep Learning for Panoptic segmentation
Apr 04, 2023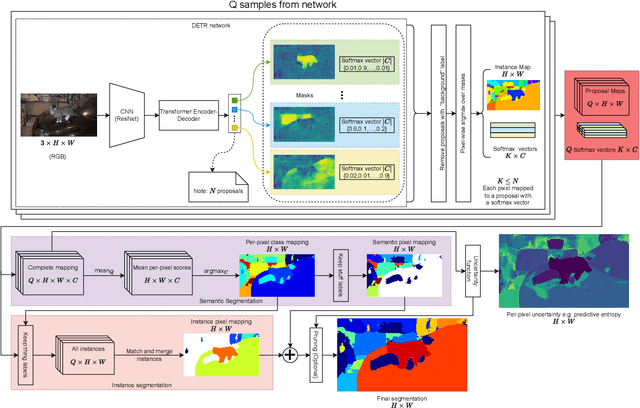
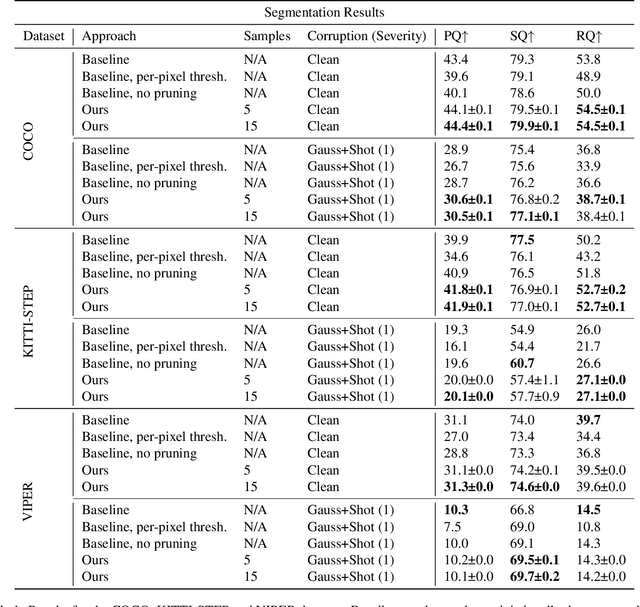
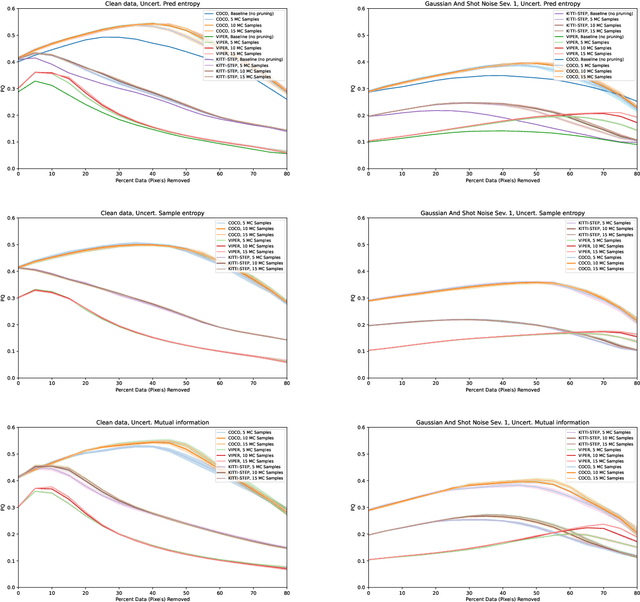
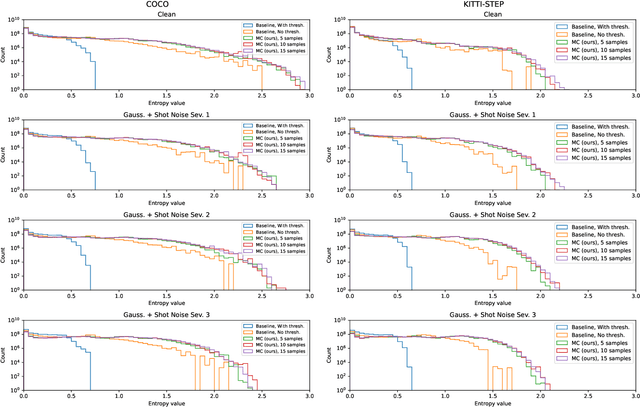
As deep learning-based computer vision algorithms continue to improve and advance the state of the art, their robustness to real-world data continues to lag their performance on datasets. This makes it difficult to bring an algorithm from the lab to the real world. Ensemble-based uncertainty estimation approaches such as Monte Carlo Dropout have been successfully used in many applications in an attempt to address this robustness issue. Unfortunately, it is not always clear if such ensemble-based approaches can be applied to a new problem domain. This is the case with panoptic segmentation, where the structure of the problem and architectures designed to solve it means that unlike image classification or even semantic segmentation, the typical solution of using a mean across samples cannot be directly applied. In this paper, we demonstrate how ensemble-based uncertainty estimation approaches such as Monte Carlo Dropout can be used in the panoptic segmentation domain with no changes to an existing network, providing both improved performance and more importantly a better measure of uncertainty for predictions made by the network. Results are demonstrated quantitatively and qualitatively on the COCO, KITTI-STEP and VIPER datasets.
From Isolated Islands to Pangea: Unifying Semantic Space for Human Action Understanding
Apr 04, 2023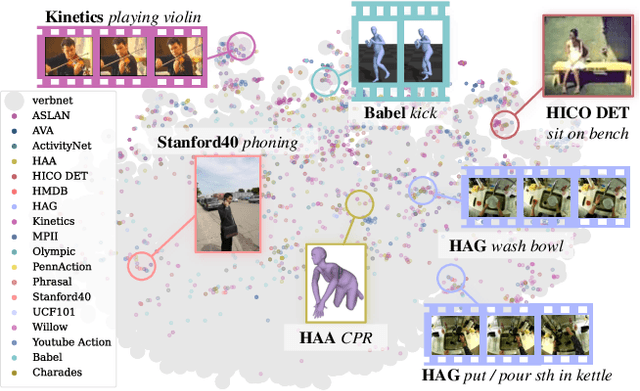
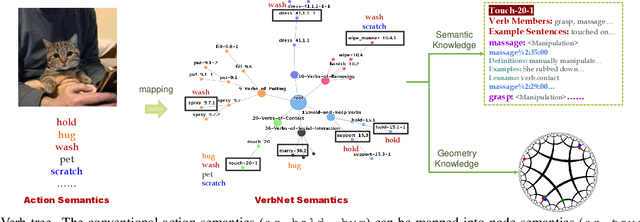
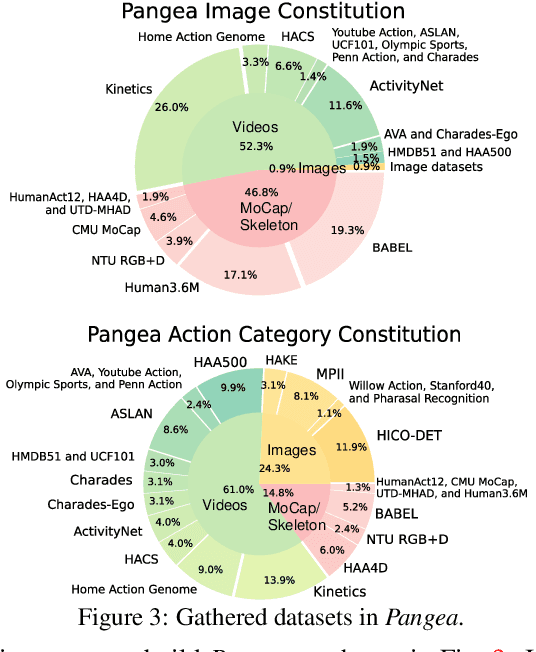
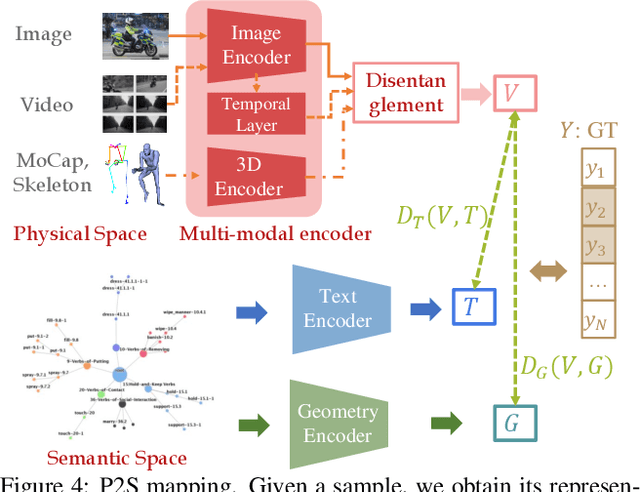
Action understanding matters and attracts attention. It can be formed as the mapping from the action physical space to the semantic space. Typically, researchers built action datasets according to idiosyncratic choices to define classes and push the envelope of benchmarks respectively. Thus, datasets are incompatible with each other like "Isolated Islands" due to semantic gaps and various class granularities, e.g., do housework in dataset A and wash plate in dataset B. We argue that a more principled semantic space is an urgent need to concentrate the community efforts and enable us to use all datasets together to pursue generalizable action learning. To this end, we design a Poincare action semantic space given verb taxonomy hierarchy and covering massive actions. By aligning the classes of previous datasets to our semantic space, we gather (image/video/skeleton/MoCap) datasets into a unified database in a unified label system, i.e., bridging "isolated islands" into a "Pangea". Accordingly, we propose a bidirectional mapping model between physical and semantic space to fully use Pangea. In extensive experiments, our system shows significant superiority, especially in transfer learning. Code and data will be made publicly available.
Sequential Recommendation with Diffusion Models
Apr 10, 2023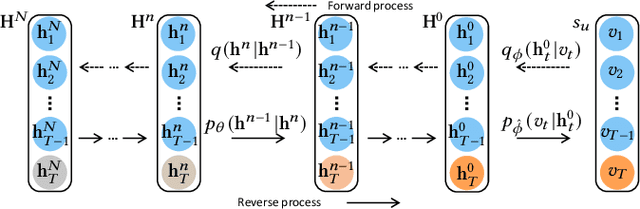
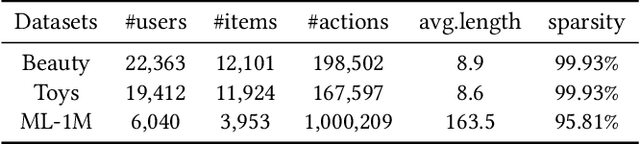
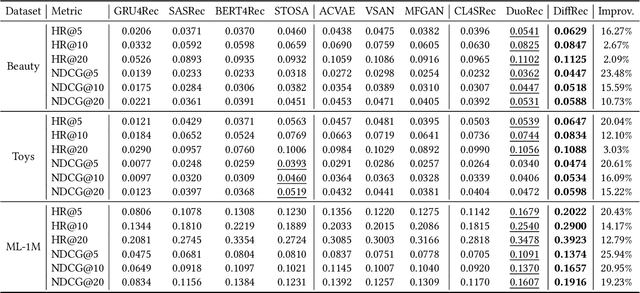

Generative models, such as Variational Auto-Encoder (VAE) and Generative Adversarial Network (GAN), have been successfully applied in sequential recommendation. These methods require sampling from probability distributions and adopt auxiliary loss functions to optimize the model, which can capture the uncertainty of user behaviors and alleviate exposure bias. However, existing generative models still suffer from the posterior collapse problem or the model collapse problem, thus limiting their applications in sequential recommendation. To tackle the challenges mentioned above, we leverage a new paradigm of the generative models, i.e., diffusion models, and present sequential recommendation with diffusion models (DiffRec), which can avoid the issues of VAE- and GAN-based models and show better performance. While diffusion models are originally proposed to process continuous image data, we design an additional transition in the forward process together with a transition in the reverse process to enable the processing of the discrete recommendation data. We also design a different noising strategy that only noises the target item instead of the whole sequence, which is more suitable for sequential recommendation. Based on the modified diffusion process, we derive the objective function of our framework using a simplification technique and design a denoise sequential recommender to fulfill the objective function. As the lengthened diffusion steps substantially increase the time complexity, we propose an efficient training strategy and an efficient inference strategy to reduce training and inference cost and improve recommendation diversity. Extensive experiment results on three public benchmark datasets verify the effectiveness of our approach and show that DiffRec outperforms the state-of-the-art sequential recommendation models.
Polarity is all you need to learn and transfer faster
Mar 29, 2023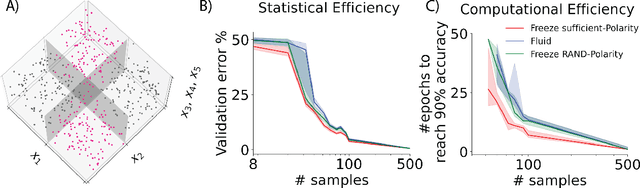
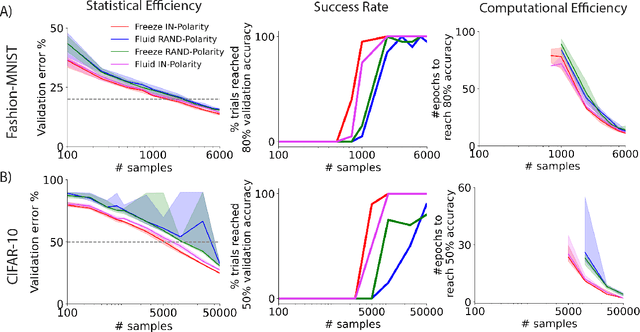
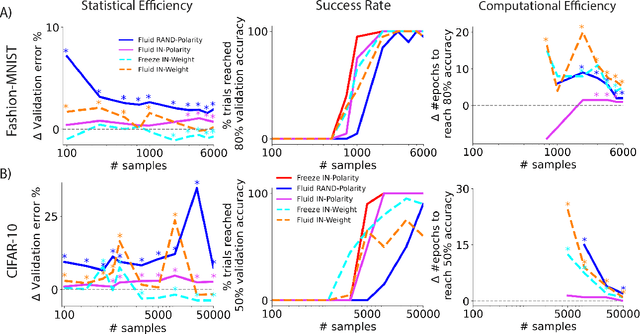
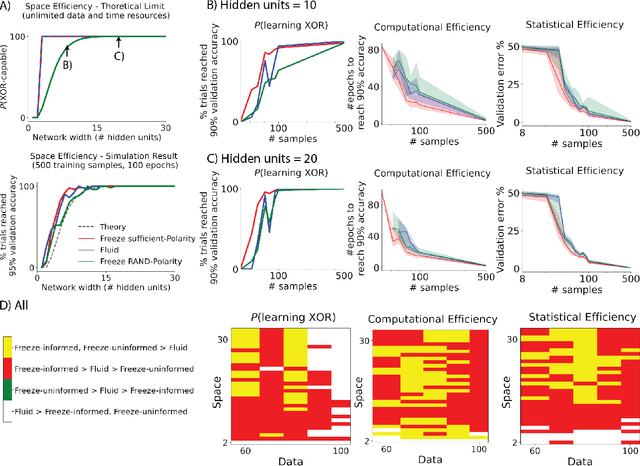
Natural intelligences (NIs) thrive in a dynamic world - they learn quickly, sometimes with only a few samples. In contrast, Artificial intelligences (AIs) typically learn with prohibitive amount of training samples and computational power. What design principle difference between NI and AI could contribute to such a discrepancy? Here, we propose an angle from weight polarity: development processes initialize NIs with advantageous polarity configurations; as NIs grow and learn, synapse magnitudes update yet polarities are largely kept unchanged. We demonstrate with simulation and image classification tasks that if weight polarities are adequately set $\textit{a priori}$, then networks learn with less time and data. We also explicitly illustrate situations in which $\textit{a priori}$ setting the weight polarities is disadvantageous for networks. Our work illustrates the value of weight polarities from the perspective of statistical and computational efficiency during learning.