 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Hard Regularization to Prevent Collapse in Online Deep Clustering without Data Augmentation
Mar 29, 2023
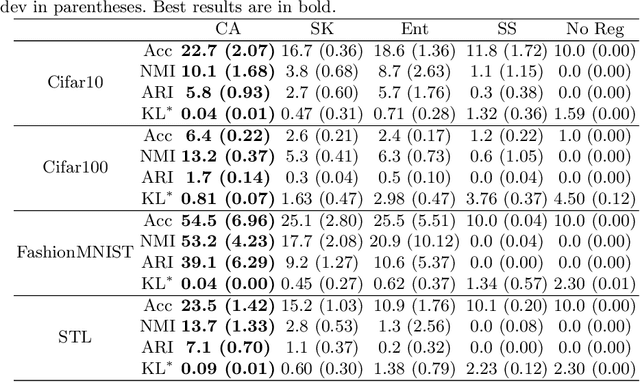
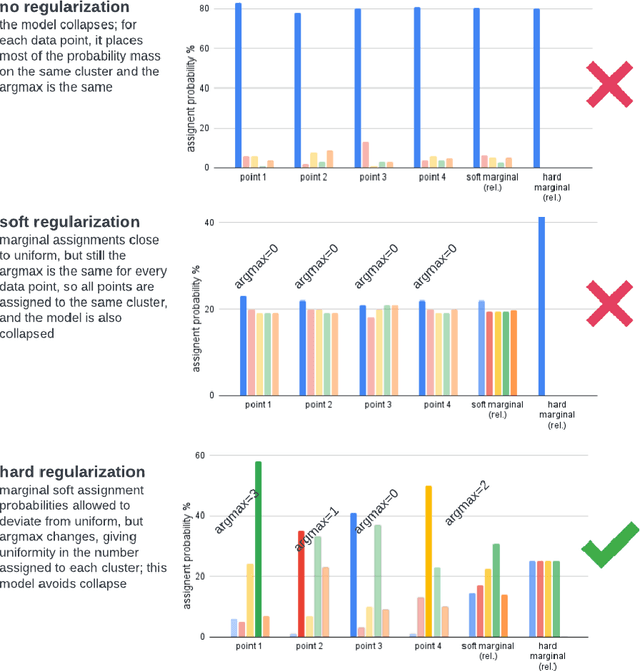
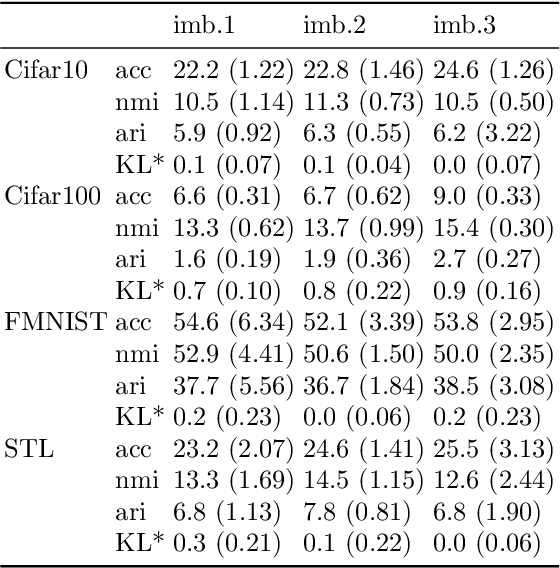
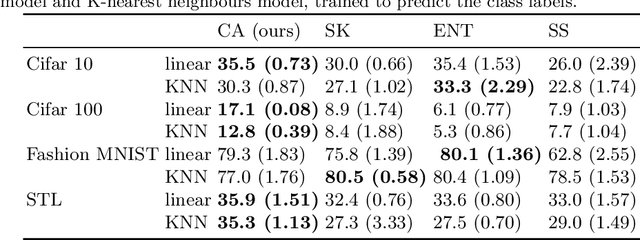
Online deep clustering refers to the joint use of a feature extraction network and a clustering model to assign cluster labels to each new data point or batch as it is processed. While faster and more versatile than offline methods, online clustering can easily reach the collapsed solution where the encoder maps all inputs to the same point and all are put into a single cluster. Successful existing models have employed various techniques to avoid this problem, most of which require data augmentation or which aim to make the average soft assignment across the dataset the same for each cluster. We propose a method that does not require data augmentation, and that, differently from existing methods, regularizes the hard assignments. Using a Bayesian framework, we derive an intuitive optimization objective that can be straightforwardly included in the training of the encoder network. Tested on four image datasets, we show that it consistently avoids collapse more robustly than other methods and that it leads to more accurate clustering. We also conduct further experiments and analyses justifying our choice to regularize the hard cluster assignments.
Monocular 3D Object Detection with Bounding Box Denoising in 3D by Perceiver
Apr 03, 2023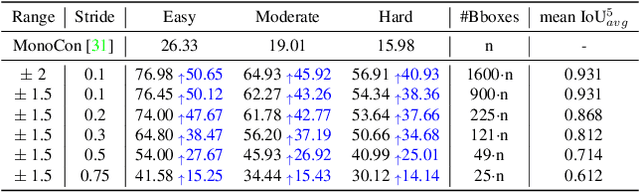
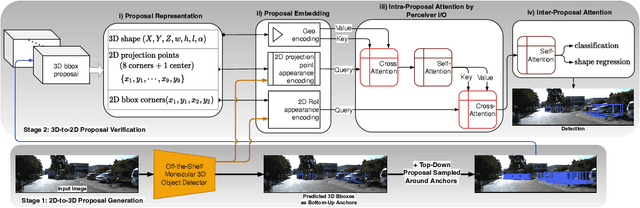
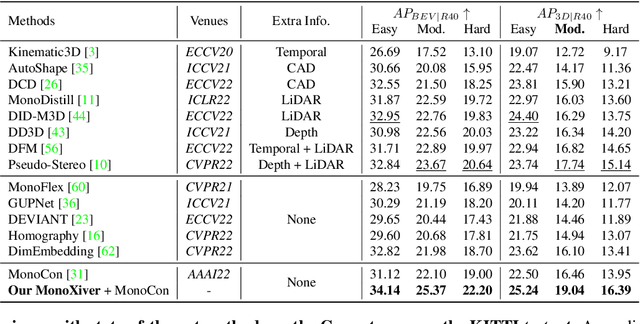
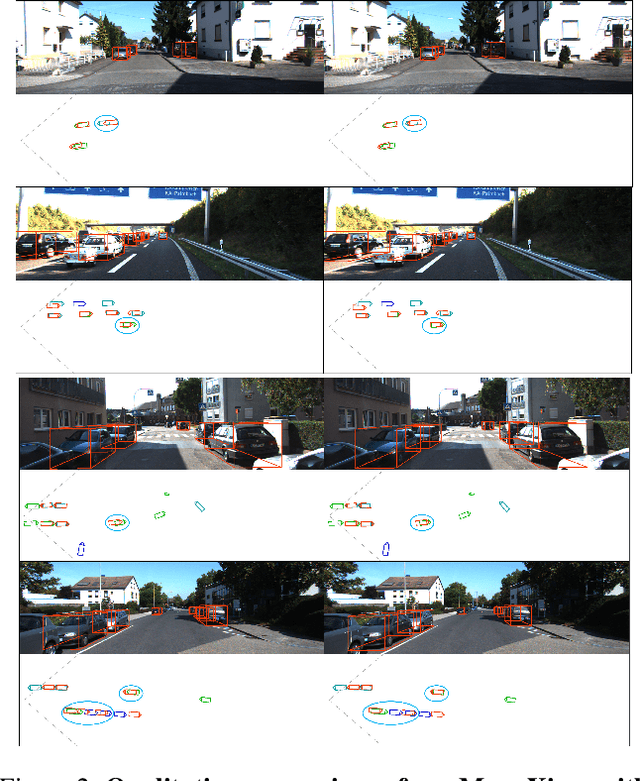
The main challenge of monocular 3D object detection is the accurate localization of 3D center. Motivated by a new and strong observation that this challenge can be remedied by a 3D-space local-grid search scheme in an ideal case, we propose a stage-wise approach, which combines the information flow from 2D-to-3D (3D bounding box proposal generation with a single 2D image) and 3D-to-2D (proposal verification by denoising with 3D-to-2D contexts) in a top-down manner. Specifically, we first obtain initial proposals from off-the-shelf backbone monocular 3D detectors. Then, we generate a 3D anchor space by local-grid sampling from the initial proposals. Finally, we perform 3D bounding box denoising at the 3D-to-2D proposal verification stage. To effectively learn discriminative features for denoising highly overlapped proposals, this paper presents a method of using the Perceiver I/O model to fuse the 3D-to-2D geometric information and the 2D appearance information. With the encoded latent representation of a proposal, the verification head is implemented with a self-attention module. Our method, named as MonoXiver, is generic and can be easily adapted to any backbone monocular 3D detectors. Experimental results on the well-established KITTI dataset and the challenging large-scale Waymo dataset show that MonoXiver consistently achieves improvement with limited computation overhead.
Acceleration-Based Kalman Tracking for Super-Resolution Ultrasound Imaging in vivo
Apr 03, 2023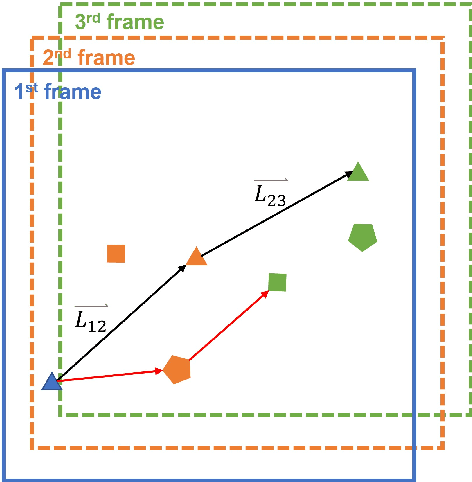
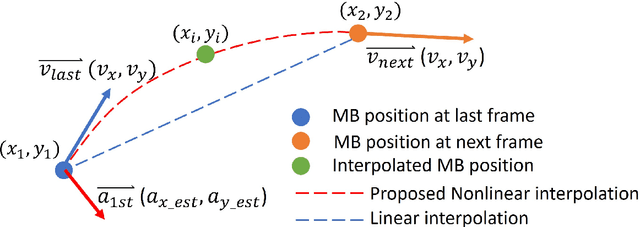
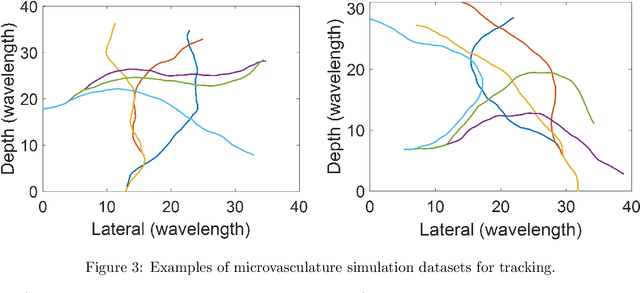
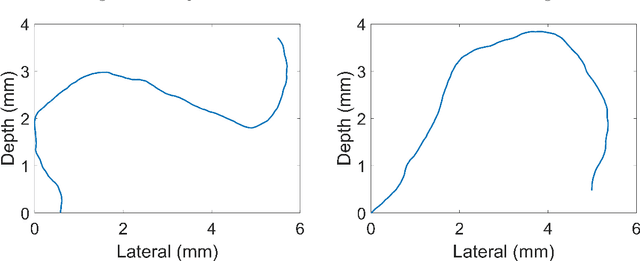
Super-resolution ultrasound can image microvascular structure and flow at sub-wave-diffraction resolution based on localising and tracking microbubbles. Currently, tracking microbubbles accurately under limited imaging frame rates and high microbubble concentrations remains a challenge, especially under the effect of cardiac pulsatility and in highly curved vessels. In this study, an acceleration-incorporated microbubble motion model is introduced into a Kalman tracking framework. The tracking performance was evaluated using simulated microvasculature with different microbubble motion parameters and acquisition frame rates, and in vivo human breast tumour ultrasound datasets. The simulation results show that the acceleration-based method outperformed the non-acceleration-based method at different levels of acceleration and acquisition frame rates and achieved significant improvement in true positive rate (up to 10.03%), false negative rate (up to 28.61%) and correctly pairing fraction (up to 170.14%). The proposed method can also reduce errors in vasculature reconstruction via the acceleration-based nonlinear interpolation, compared with linear interpolation (up to 19 um). The tracking results from temporally downsampled low frame rate in vivo datasets from human breast tumours show that the proposed method has better microbubble tracking performance than the baseline method, if using results from the initial high frame data as reference. Finally, the acceleration estimated from tracking results also provides a spatial speed gradient map that may contain extra valuable diagnostic information.
Scale-aware Two-stage High Dynamic Range Imaging
Mar 12, 2023
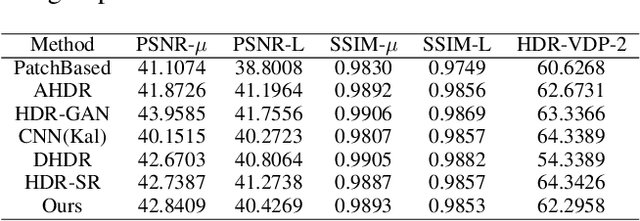
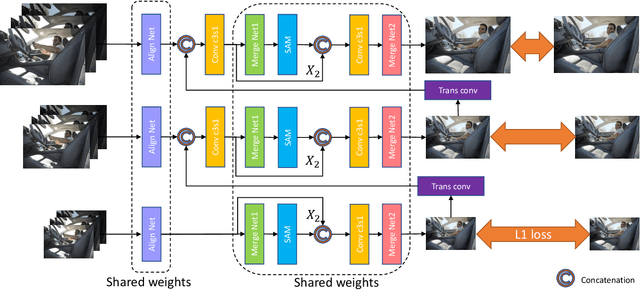
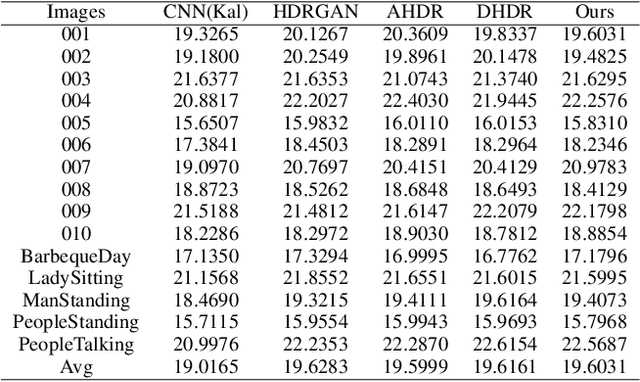
Deep high dynamic range (HDR) imaging as an image translation issue has achieved great performance without explicit optical flow alignment. However, challenges remain over content association ambiguities especially caused by saturation and large-scale movements. To address the ghosting issue and enhance the details in saturated regions, we propose a scale-aware two-stage high dynamic range imaging framework (STHDR) to generate high-quality ghost-free HDR image. The scale-aware technique and two-stage fusion strategy can progressively and effectively improve the HDR composition performance. Specifically, our framework consists of feature alignment and two-stage fusion. In feature alignment, we propose a spatial correct module (SCM) to better exploit useful information among non-aligned features to avoid ghosting and saturation. In the first stage of feature fusion, we obtain a preliminary fusion result with little ghosting. In the second stage, we conflate the results of the first stage with aligned features to further reduce residual artifacts and thus improve the overall quality. Extensive experimental results on the typical test dataset validate the effectiveness of the proposed STHDR in terms of speed and quality.
Prior-RadGraphFormer: A Prior-Knowledge-Enhanced Transformer for Generating Radiology Graphs from X-Rays
Mar 27, 2023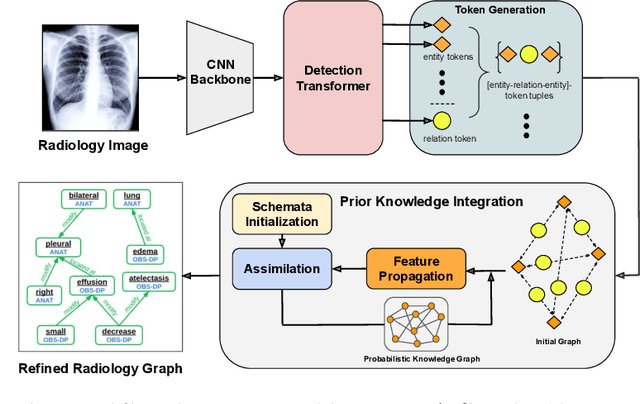
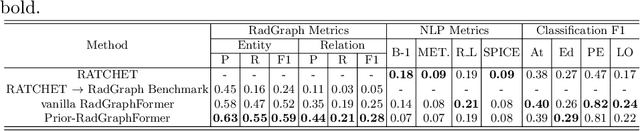
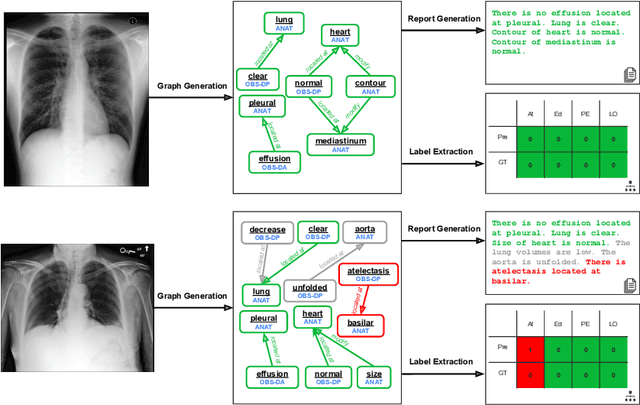
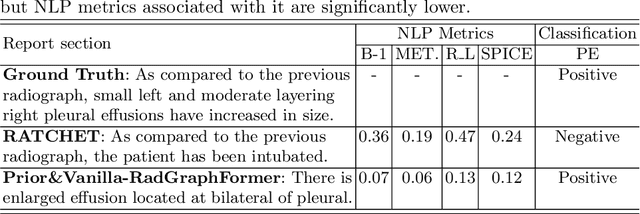
The extraction of structured clinical information from free-text radiology reports in the form of radiology graphs has been demonstrated to be a valuable approach for evaluating the clinical correctness of report-generation methods. However, the direct generation of radiology graphs from chest X-ray (CXR) images has not been attempted. To address this gap, we propose a novel approach called Prior-RadGraphFormer that utilizes a transformer model with prior knowledge in the form of a probabilistic knowledge graph (PKG) to generate radiology graphs directly from CXR images. The PKG models the statistical relationship between radiology entities, including anatomical structures and medical observations. This additional contextual information enhances the accuracy of entity and relation extraction. The generated radiology graphs can be applied to various downstream tasks, such as free-text or structured reports generation and multi-label classification of pathologies. Our approach represents a promising method for generating radiology graphs directly from CXR images, and has significant potential for improving medical image analysis and clinical decision-making.
Spatio-Temporal AU Relational Graph Representation Learning For Facial Action Units Detection
Mar 27, 2023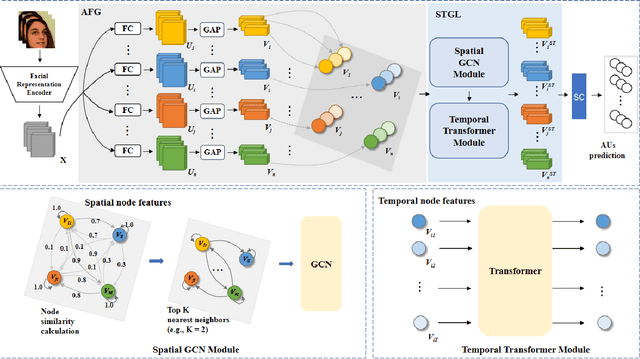

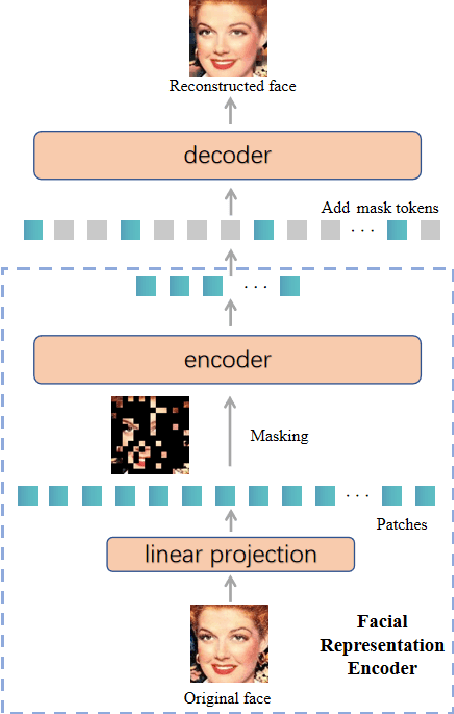

This paper presents our Facial Action Units (AUs) recognition submission to the fifth Affective Behavior Analysis in-the-wild Competition (ABAW). Our approach consists of three main modules: (i) a pre-trained facial representation encoder which produce a strong facial representation from each input face image in the input sequence; (ii) an AU-specific feature generator that specifically learns a set of AU features from each facial representation; and (iii) a spatio-temporal graph learning module that constructs a spatio-temporal graph representation. This graph representation describes AUs contained in all frames and predicts the occurrence of each AU based on both the modeled spatial information within the corresponding face and the learned temporal dynamics among frames. The experimental results show that our approach outperformed the baseline and the spatio-temporal graph representation learning allows our model to generate the best results among all ablated systems. Our model ranks at the 4th place in the AU recognition track at the 5th ABAW Competition.
EVA-CLIP: Improved Training Techniques for CLIP at Scale
Mar 27, 2023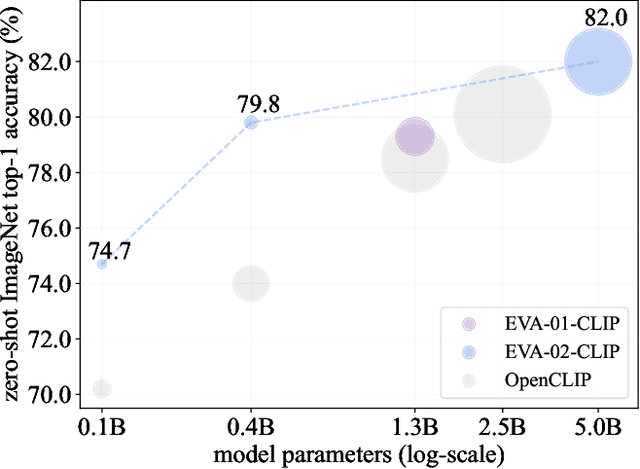
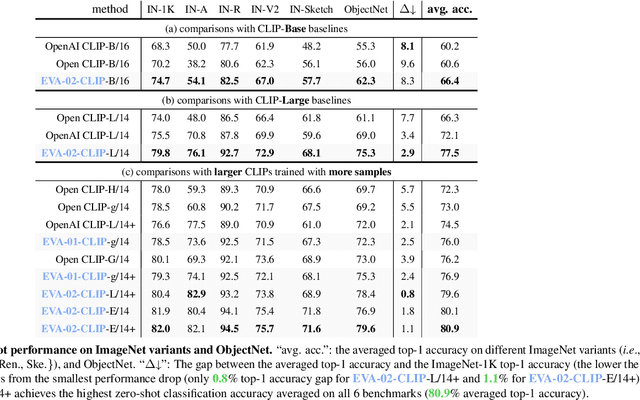
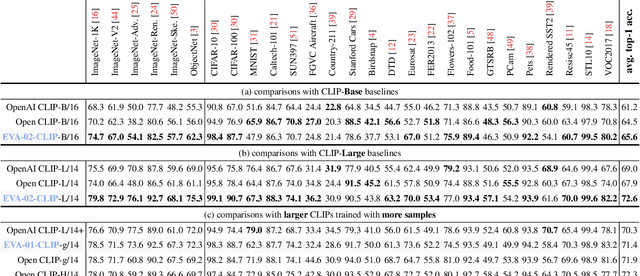
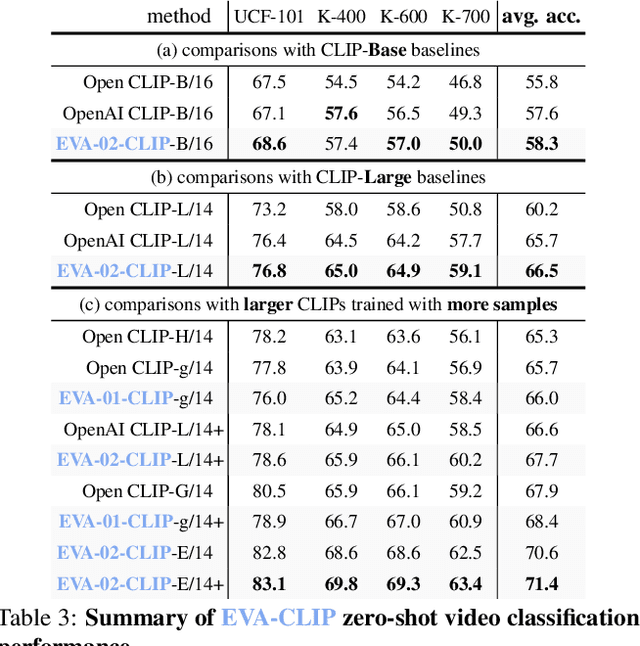
Contrastive language-image pre-training, CLIP for short, has gained increasing attention for its potential in various scenarios. In this paper, we propose EVA-CLIP, a series of models that significantly improve the efficiency and effectiveness of CLIP training. Our approach incorporates new techniques for representation learning, optimization, and augmentation, enabling EVA-CLIP to achieve superior performance compared to previous CLIP models with the same number of parameters but significantly smaller training costs. Notably, our largest 5.0B-parameter EVA-02-CLIP-E/14+ with only 9 billion seen samples achieves 82.0 zero-shot top-1 accuracy on ImageNet-1K val. A smaller EVA-02-CLIP-L/14+ with only 430 million parameters and 6 billion seen samples achieves 80.4 zero-shot top-1 accuracy on ImageNet-1K val. To facilitate open access and open research, we release the complete suite of EVA-CLIP to the community at https://github.com/baaivision/EVA/tree/master/EVA-CLIP.
Manifold Learning by Mixture Models of VAEs for Inverse Problems
Mar 27, 2023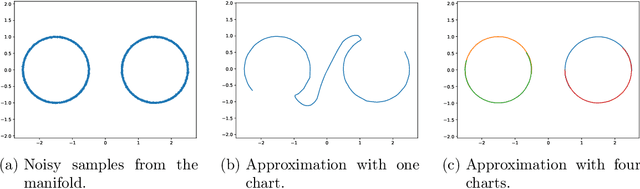
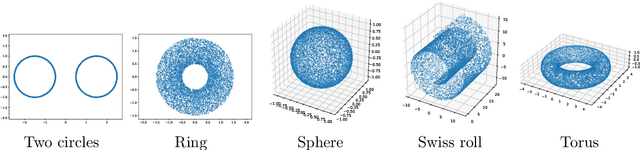
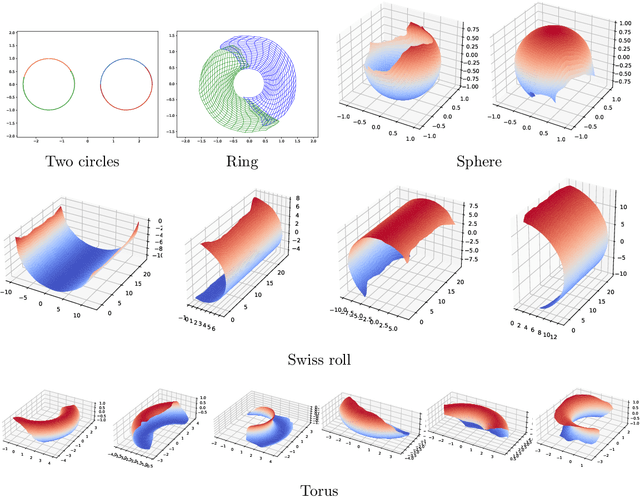
Representing a manifold of very high-dimensional data with generative models has been shown to be computationally efficient in practice. However, this requires that the data manifold admits a global parameterization. In order to represent manifolds of arbitrary topology, we propose to learn a mixture model of variational autoencoders. Here, every encoder-decoder pair represents one chart of a manifold. We propose a loss function for maximum likelihood estimation of the model weights and choose an architecture that provides us the analytical expression of the charts and of their inverses. Once the manifold is learned, we use it for solving inverse problems by minimizing a data fidelity term restricted to the learned manifold. To solve the arising minimization problem we propose a Riemannian gradient descent algorithm on the learned manifold. We demonstrate the performance of our method for low-dimensional toy examples as well as for deblurring and electrical impedance tomography on certain image manifolds.
Intersection over Union with smoothing for bounding box regression
Mar 27, 2023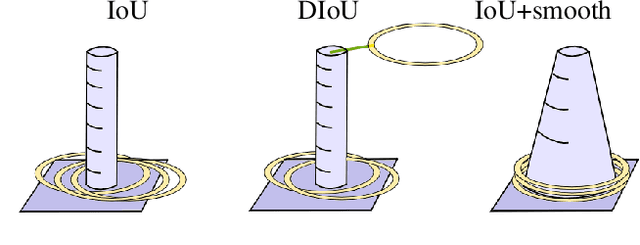



We focus on the construction of a loss function for the bounding box regression. The Intersection over Union (IoU) metric is improved to converge faster, to make the surface of the loss function smooth and continuous over the whole searched space, and to reach a more precise approximation of the labels. The main principle is adding a smoothing part to the original IoU, where the smoothing part is given by a linear space with values that increases from the ground truth bounding box to the border of the input image, and thus covers the whole spatial search space. We show the motivation and formalism behind this loss function and experimentally prove that it outperforms IoU, DIoU, CIoU, and SIoU by a large margin. We experimentally show that the proposed loss function is robust with respect to the noise in the dimension of ground truth bounding boxes. The reference implementation is available at gitlab.com/irafm-ai/smoothing-iou.
PSLT: A Light-weight Vision Transformer with Ladder Self-Attention and Progressive Shift
Apr 07, 2023
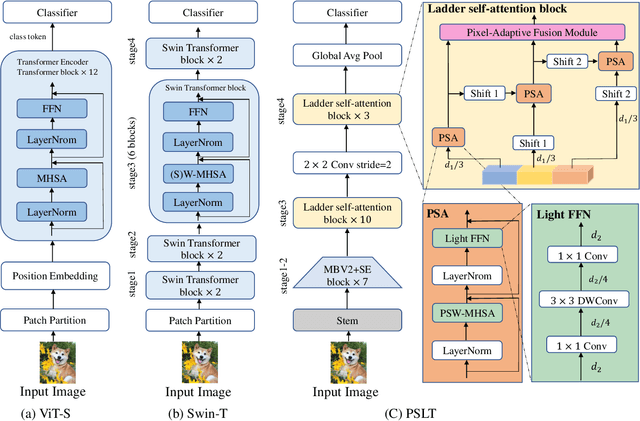
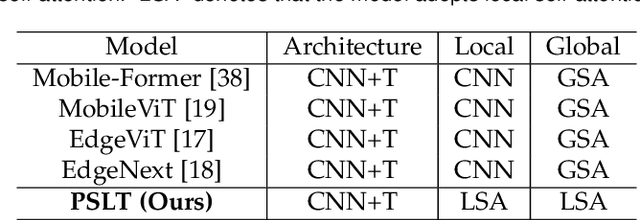
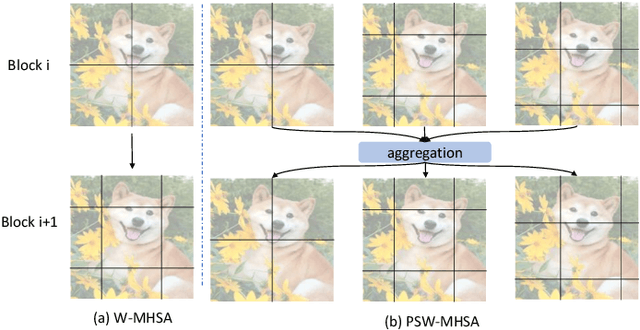
Vision Transformer (ViT) has shown great potential for various visual tasks due to its ability to model long-range dependency. However, ViT requires a large amount of computing resource to compute the global self-attention. In this work, we propose a ladder self-attention block with multiple branches and a progressive shift mechanism to develop a light-weight transformer backbone that requires less computing resources (e.g. a relatively small number of parameters and FLOPs), termed Progressive Shift Ladder Transformer (PSLT). First, the ladder self-attention block reduces the computational cost by modelling local self-attention in each branch. In the meanwhile, the progressive shift mechanism is proposed to enlarge the receptive field in the ladder self-attention block by modelling diverse local self-attention for each branch and interacting among these branches. Second, the input feature of the ladder self-attention block is split equally along the channel dimension for each branch, which considerably reduces the computational cost in the ladder self-attention block (with nearly 1/3 the amount of parameters and FLOPs), and the outputs of these branches are then collaborated by a pixel-adaptive fusion. Therefore, the ladder self-attention block with a relatively small number of parameters and FLOPs is capable of modelling long-range interactions. Based on the ladder self-attention block, PSLT performs well on several vision tasks, including image classification, objection detection and person re-identification. On the ImageNet-1k dataset, PSLT achieves a top-1 accuracy of 79.9% with 9.2M parameters and 1.9G FLOPs, which is comparable to several existing models with more than 20M parameters and 4G FLOPs. Code is available at https://isee-ai.cn/wugaojie/PSLT.html.
* Accepted to IEEE Transaction on Pattern Analysis and Machine Intelligence, 2023 (Submission date: 08-Jul-202)