 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SimTS: Rethinking Contrastive Representation Learning for Time Series Forecasting
Mar 31, 2023
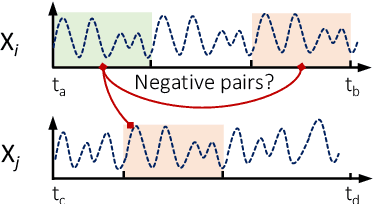
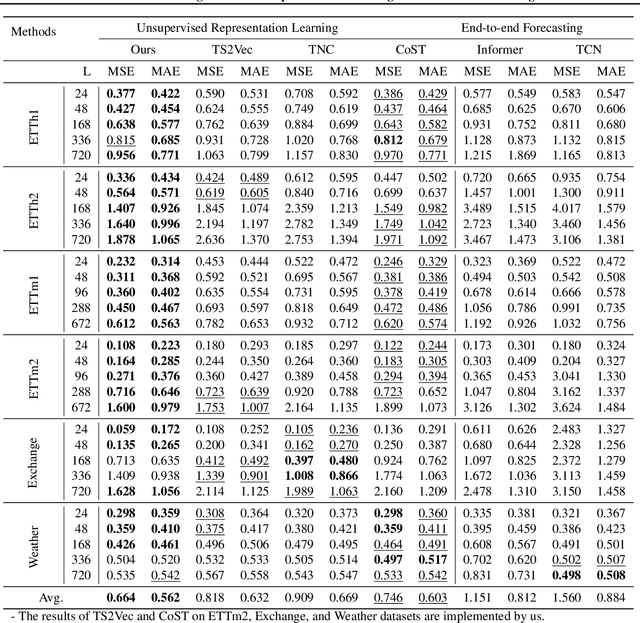
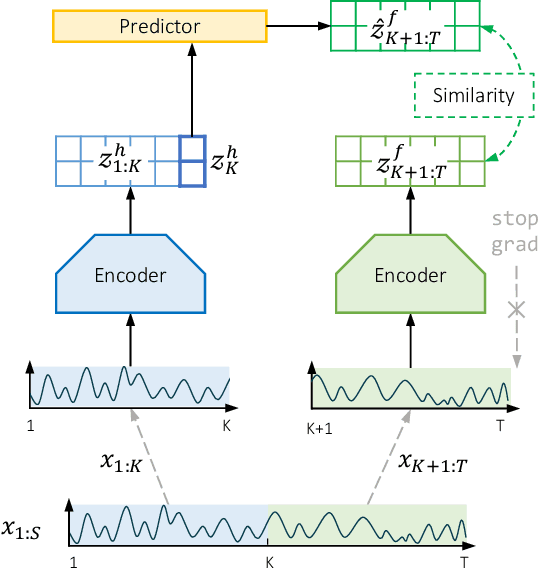
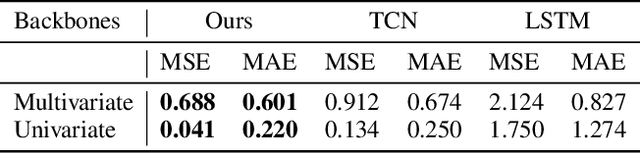
Contrastive learning methods have shown an impressive ability to learn meaningful representations for image or time series classification. However, these methods are less effective for time series forecasting, as optimization of instance discrimination is not directly applicable to predicting the future state from the history context. Moreover, the construction of positive and negative pairs in current technologies strongly relies on specific time series characteristics, restricting their generalization across diverse types of time series data. To address these limitations, we propose SimTS, a simple representation learning approach for improving time series forecasting by learning to predict the future from the past in the latent space. SimTS does not rely on negative pairs or specific assumptions about the characteristics of the particular time series. Our extensive experiments on several benchmark time series forecasting datasets show that SimTS achieves competitive performance compared to existing contrastive learning methods. Furthermore, we show the shortcomings of the current contrastive learning framework used for time series forecasting through a detailed ablation study. Overall, our work suggests that SimTS is a promising alternative to other contrastive learning approaches for time series forecasting.
LivePose: Online 3D Reconstruction from Monocular Video with Dynamic Camera Poses
Mar 31, 2023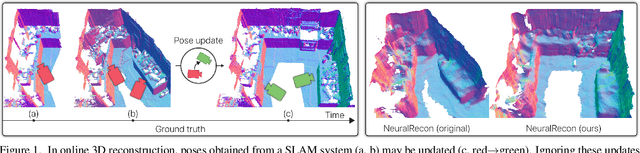

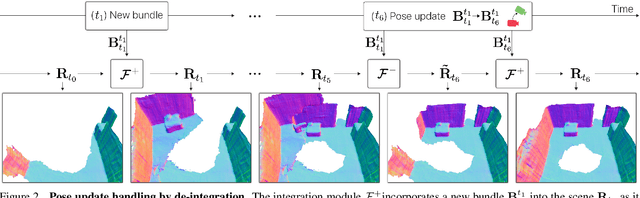
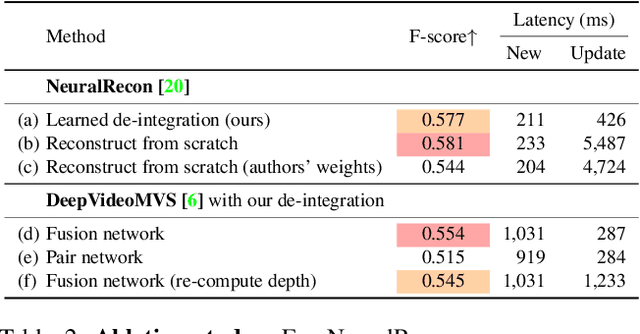
Dense 3D reconstruction from RGB images traditionally assumes static camera pose estimates. This assumption has endured, even as recent works have increasingly focused on real-time methods for mobile devices. However, the assumption of one pose per image does not hold for online execution: poses from real-time SLAM are dynamic and may be updated following events such as bundle adjustment and loop closure. This has been addressed in the RGB-D setting, by de-integrating past views and re-integrating them with updated poses, but it remains largely untreated in the RGB-only setting. We formalize this problem to define the new task of online reconstruction from dynamically-posed images. To support further research, we introduce a dataset called LivePose containing the dynamic poses from a SLAM system running on ScanNet. We select three recent reconstruction systems and apply a framework based on de-integration to adapt each one to the dynamic-pose setting. In addition, we propose a novel, non-linear de-integration module that learns to remove stale scene content. We show that responding to pose updates is critical for high-quality reconstruction, and that our de-integration framework is an effective solution.
Adaptive Rotated Convolution for Rotated Object Detection
Mar 14, 2023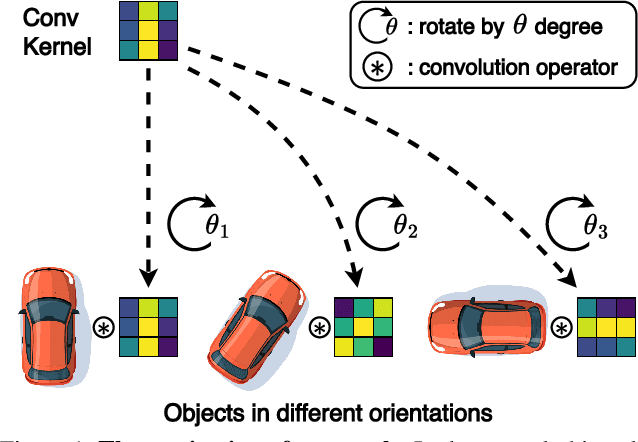
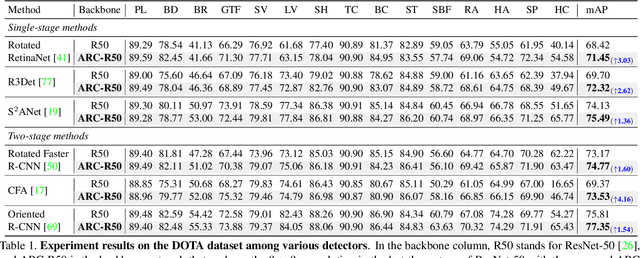
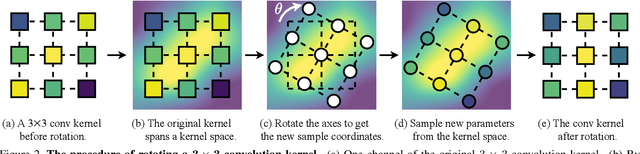
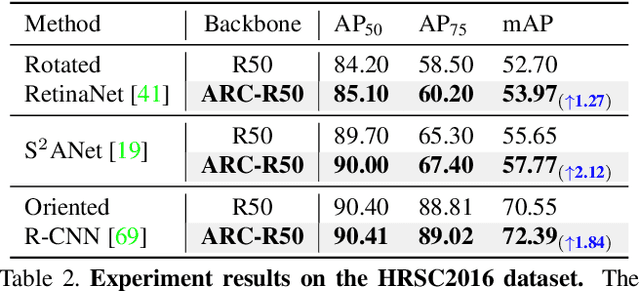
Rotated object detection aims to identify and locate objects in images with arbitrary orientation. In this scenario, the oriented directions of objects vary considerably across different images, while multiple orientations of objects exist within an image. This intrinsic characteristic makes it challenging for standard backbone networks to extract high-quality features of these arbitrarily orientated objects. In this paper, we present Adaptive Rotated Convolution (ARC) module to handle the aforementioned challenges. In our ARC module, the convolution kernels rotate adaptively to extract object features with varying orientations in different images, and an efficient conditional computation mechanism is introduced to accommodate the large orientation variations of objects within an image. The two designs work seamlessly in rotated object detection problem. Moreover, ARC can conveniently serve as a plug-and-play module in various vision backbones to boost their representation ability to detect oriented objects accurately. Experiments on commonly used benchmarks (DOTA and HRSC2016) demonstrate that equipped with our proposed ARC module in the backbone network, the performance of multiple popular oriented object detectors is significantly improved (e.g. +3.03% mAP on Rotated RetinaNet and +4.16% on CFA). Combined with the highly competitive method Oriented R-CNN, the proposed approach achieves state-of-the-art performance on the DOTA dataset with 81.77% mAP.
SMUG: Towards robust MRI reconstruction by smoothed unrolling
Mar 14, 2023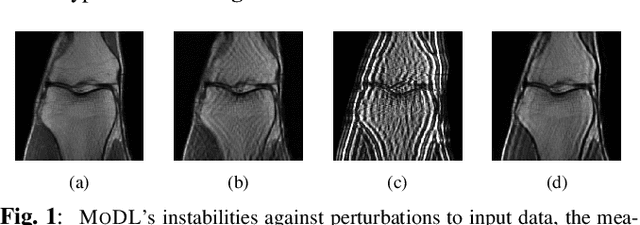
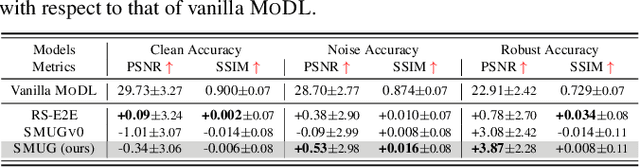
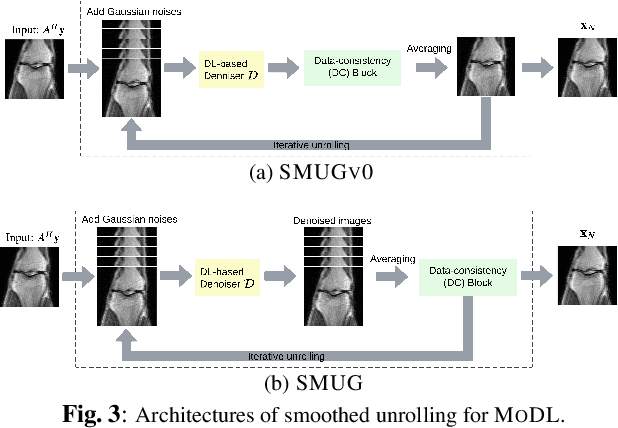
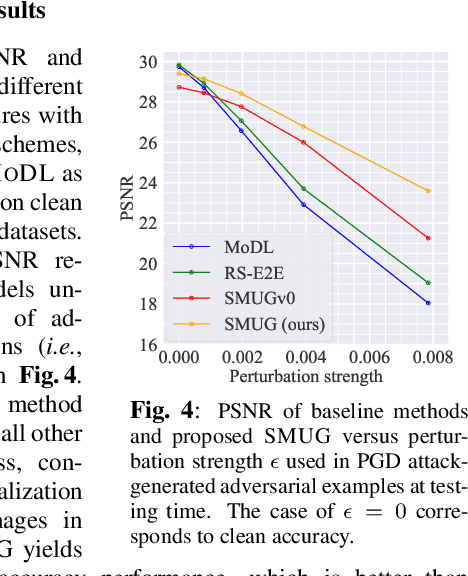
Although deep learning (DL) has gained much popularity for accelerated magnetic resonance imaging (MRI), recent studies have shown that DL-based MRI reconstruction models could be oversensitive to tiny input perturbations (that are called 'adversarial perturbations'), which cause unstable, low-quality reconstructed images. This raises the question of how to design robust DL methods for MRI reconstruction. To address this problem, we propose a novel image reconstruction framework, termed SMOOTHED UNROLLING (SMUG), which advances a deep unrolling-based MRI reconstruction model using a randomized smoothing (RS)-based robust learning operation. RS, which improves the tolerance of a model against input noises, has been widely used in the design of adversarial defense for image classification. Yet, we find that the conventional design that applies RS to the entire DL process is ineffective for MRI reconstruction. We show that SMUG addresses the above issue by customizing the RS operation based on the unrolling architecture of the DL-based MRI reconstruction model. Compared to the vanilla RS approach and several variants of SMUG, we show that SMUG improves the robustness of MRI reconstruction with respect to a diverse set of perturbation sources, including perturbations to the input measurements, different measurement sampling rates, and different unrolling steps. Code for SMUG will be available at https://github.com/LGM70/SMUG.
Image-Text Retrieval with Binary and Continuous Label Supervision
Oct 20, 2022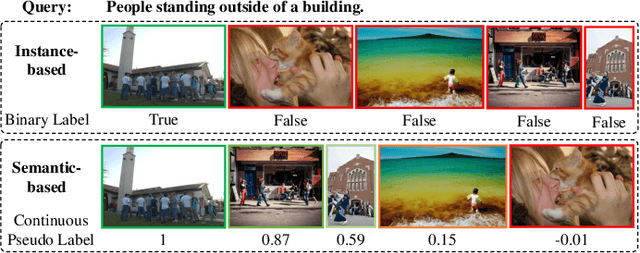
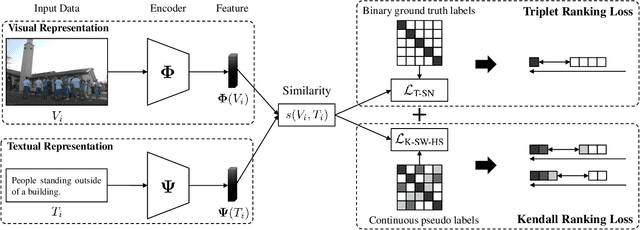
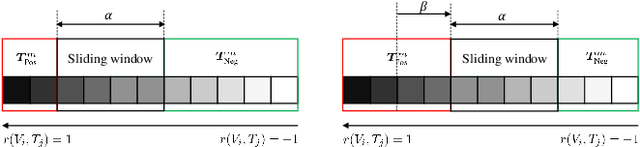
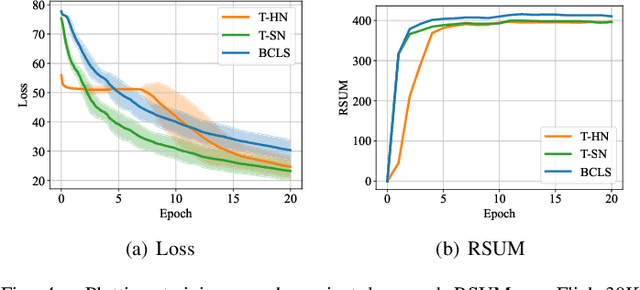
Most image-text retrieval work adopts binary labels indicating whether a pair of image and text matches or not. Such a binary indicator covers only a limited subset of image-text semantic relations, which is insufficient to represent relevance degrees between images and texts described by continuous labels such as image captions. The visual-semantic embedding space obtained by learning binary labels is incoherent and cannot fully characterize the relevance degrees. In addition to the use of binary labels, this paper further incorporates continuous pseudo labels (generally approximated by text similarity between captions) to indicate the relevance degrees. To learn a coherent embedding space, we propose an image-text retrieval framework with Binary and Continuous Label Supervision (BCLS), where binary labels are used to guide the retrieval model to learn limited binary correlations, and continuous labels are complementary to the learning of image-text semantic relations. For the learning of binary labels, we improve the common Triplet ranking loss with Soft Negative mining (Triplet-SN) to improve convergence. For the learning of continuous labels, we design Kendall ranking loss inspired by Kendall rank correlation coefficient (Kendall), which improves the correlation between the similarity scores predicted by the retrieval model and the continuous labels. To mitigate the noise introduced by the continuous pseudo labels, we further design Sliding Window sampling and Hard Sample mining strategy (SW-HS) to alleviate the impact of noise and reduce the complexity of our framework to the same order of magnitude as the triplet ranking loss. Extensive experiments on two image-text retrieval benchmarks demonstrate that our method can improve the performance of state-of-the-art image-text retrieval models.
ISTA-Inspired Network for Image Super-Resolution
Oct 14, 2022
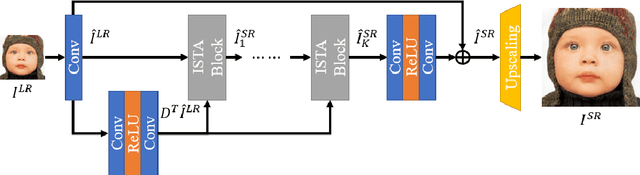
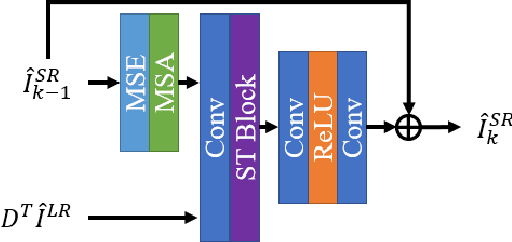
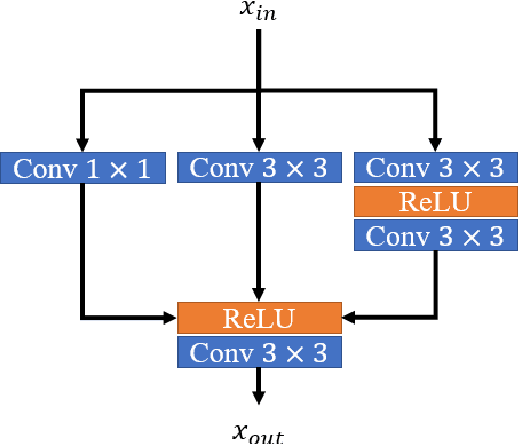
Deep learning for image super-resolution (SR) has been investigated by numerous researchers in recent years. Most of the works concentrate on effective block designs and improve the network representation but lack interpretation. There are also iterative optimization-inspired networks for image SR, which take the solution step as a whole without giving an explicit optimization step. This paper proposes an unfolding iterative shrinkage thresholding algorithm (ISTA) inspired network for interpretable image SR. Specifically, we analyze the problem of image SR and propose a solution based on the ISTA method. Inspired by the mathematical analysis, the ISTA block is developed to conduct the optimization in an end-to-end manner. To make the exploration more effective, a multi-scale exploitation block and multi-scale attention mechanism are devised to build the ISTA block. Experimental results show the proposed ISTA-inspired restoration network (ISTAR) achieves competitive or better performances than other optimization-inspired works with fewer parameters and lower computation complexity.
Verifying Properties of Tsetlin Machines
Mar 25, 2023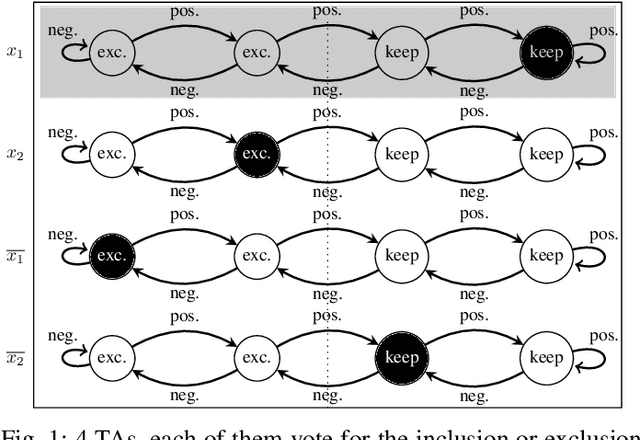
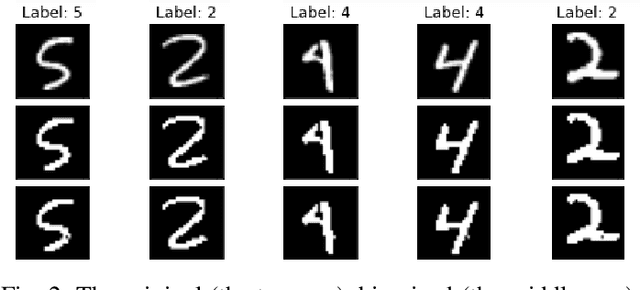


Tsetlin Machines (TsMs) are a promising and interpretable machine learning method which can be applied for various classification tasks. We present an exact encoding of TsMs into propositional logic and formally verify properties of TsMs using a SAT solver. In particular, we introduce in this work a notion of similarity of machine learning models and apply our notion to check for similarity of TsMs. We also consider notions of robustness and equivalence from the literature and adapt them for TsMs. Then, we show the correctness of our encoding and provide results for the properties: adversarial robustness, equivalence, and similarity of TsMs. In our experiments, we employ the MNIST and IMDB datasets for (respectively) image and sentiment classification. We discuss the results for verifying robustness obtained with TsMs with those in the literature obtained with Binarized Neural Networks on MNIST.
Langevin algorithms for very deep Neural Networks with application to image classification
Dec 27, 2022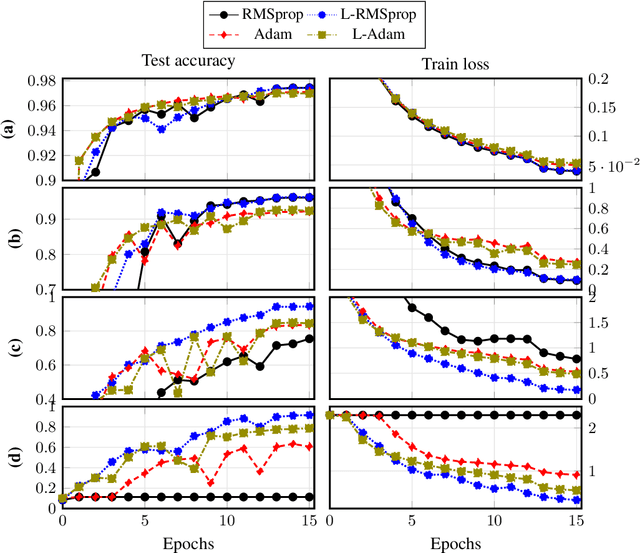

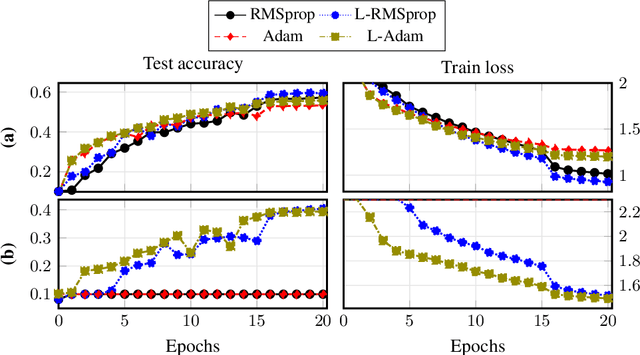
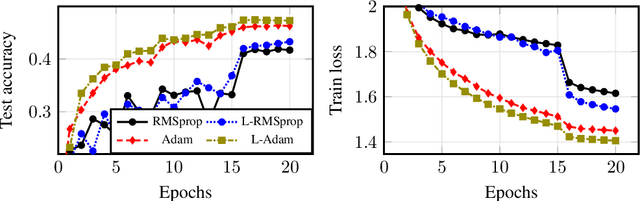
Training a very deep neural network is a challenging task, as the deeper a neural network is, the more non-linear it is. We compare the performances of various preconditioned Langevin algorithms with their non-Langevin counterparts for the training of neural networks of increasing depth. For shallow neural networks, Langevin algorithms do not lead to any improvement, however the deeper the network is and the greater are the gains provided by Langevin algorithms. Adding noise to the gradient descent allows to escape from local traps, which are more frequent for very deep neural networks. Following this heuristic we introduce a new Langevin algorithm called Layer Langevin, which consists in adding Langevin noise only to the weights associated to the deepest layers. We then prove the benefits of Langevin and Layer Langevin algorithms for the training of popular deep residual architectures for image classification.
Learning Generative Models with Goal-conditioned Reinforcement Learning
Mar 26, 2023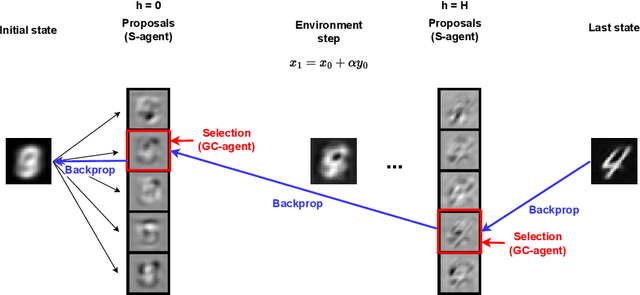
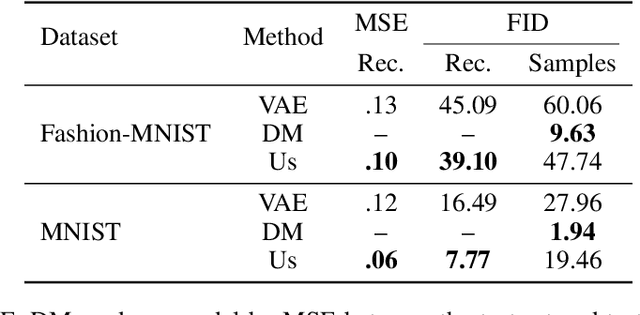


We present a novel, alternative framework for learning generative models with goal-conditioned reinforcement learning. We define two agents, a goal conditioned agent (GC-agent) and a supervised agent (S-agent). Given a user-input initial state, the GC-agent learns to reconstruct the training set. In this context, elements in the training set are the goals. During training, the S-agent learns to imitate the GC-agent while remaining agnostic of the goals. At inference we generate new samples with the S-agent. Following a similar route as in variational auto-encoders, we derive an upper bound on the negative log-likelihood that consists of a reconstruction term and a divergence between the GC-agent policy and the (goal-agnostic) S-agent policy. We empirically demonstrate that our method is able to generate diverse and high quality samples in the task of image synthesis.
Are Data-driven Explanations Robust against Out-of-distribution Data?
Mar 29, 2023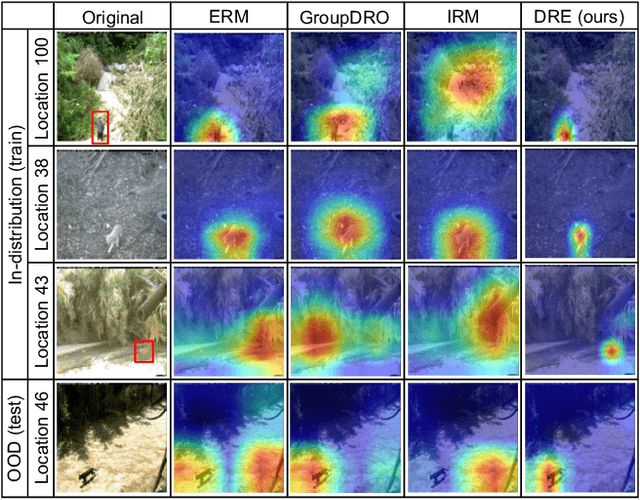
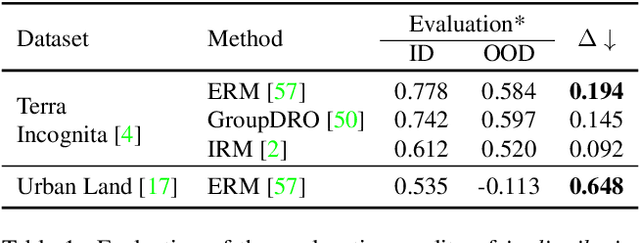
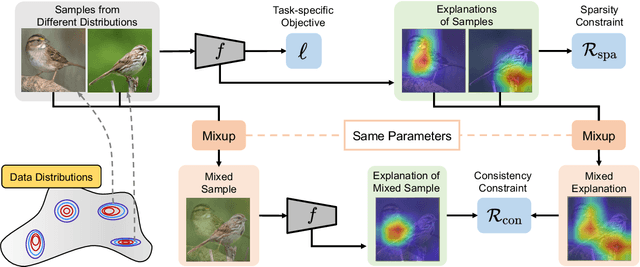

As black-box models increasingly power high-stakes applications, a variety of data-driven explanation methods have been introduced. Meanwhile, machine learning models are constantly challenged by distributional shifts. A question naturally arises: Are data-driven explanations robust against out-of-distribution data? Our empirical results show that even though predict correctly, the model might still yield unreliable explanations under distributional shifts. How to develop robust explanations against out-of-distribution data? To address this problem, we propose an end-to-end model-agnostic learning framework Distributionally Robust Explanations (DRE). The key idea is, inspired by self-supervised learning, to fully utilizes the inter-distribution information to provide supervisory signals for the learning of explanations without human annotation. Can robust explanations benefit the model's generalization capability? We conduct extensive experiments on a wide range of tasks and data types, including classification and regression on image and scientific tabular data. Our results demonstrate that the proposed method significantly improves the model's performance in terms of explanation and prediction robustness against distributional shifts.