 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Gradient Adjusting Networks for Domain Inversion
Feb 22, 2023
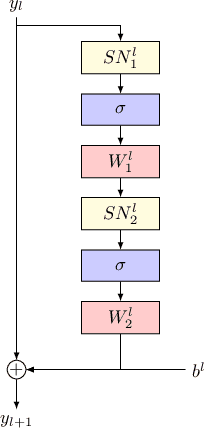
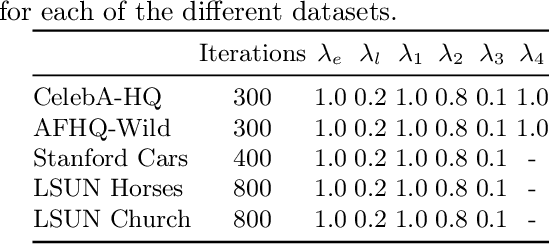
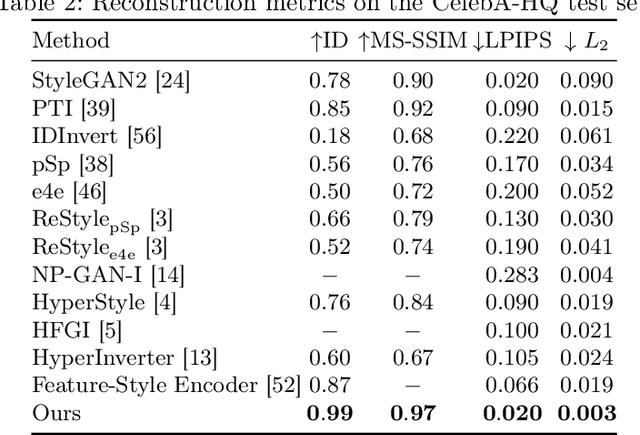

StyleGAN2 was demonstrated to be a powerful image generation engine that supports semantic editing. However, in order to manipulate a real-world image, one first needs to be able to retrieve its corresponding latent representation in StyleGAN's latent space that is decoded to an image as close as possible to the desired image. For many real-world images, a latent representation does not exist, which necessitates the tuning of the generator network. We present a per-image optimization method that tunes a StyleGAN2 generator such that it achieves a local edit to the generator's weights, resulting in almost perfect inversion, while still allowing image editing, by keeping the rest of the mapping between an input latent representation tensor and an output image relatively intact. The method is based on a one-shot training of a set of shallow update networks (aka. Gradient Modification Modules) that modify the layers of the generator. After training the Gradient Modification Modules, a modified generator is obtained by a single application of these networks to the original parameters, and the previous editing capabilities of the generator are maintained. Our experiments show a sizable gap in performance over the current state of the art in this very active domain. Our code is available at \url{https://github.com/sheffier/gani}.
Spectral Transfer Guided Active Domain Adaptation For Thermal Imagery
Apr 14, 2023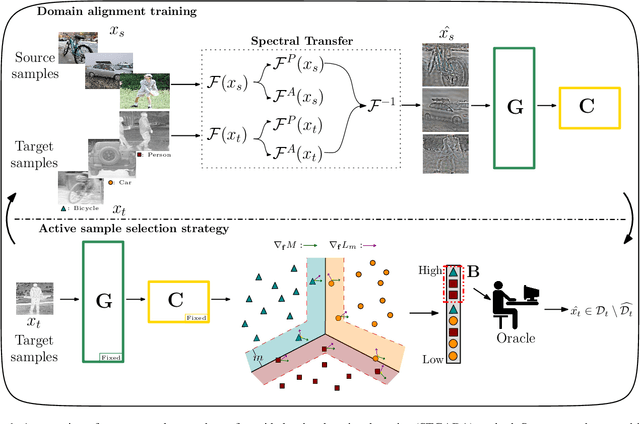
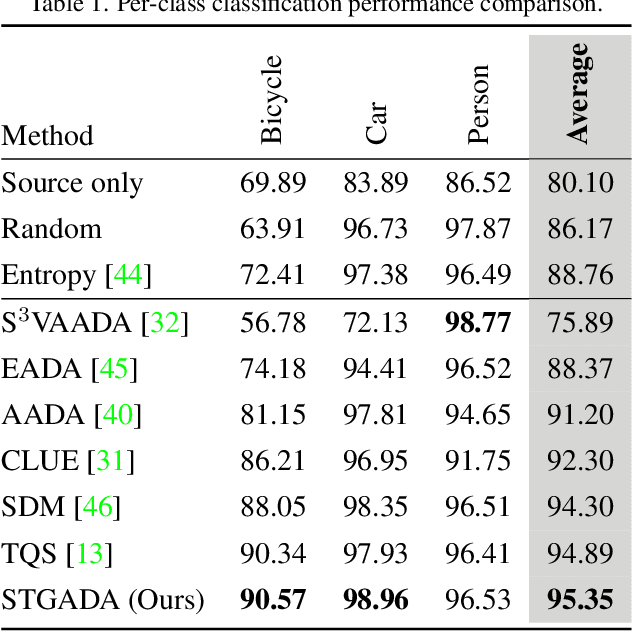
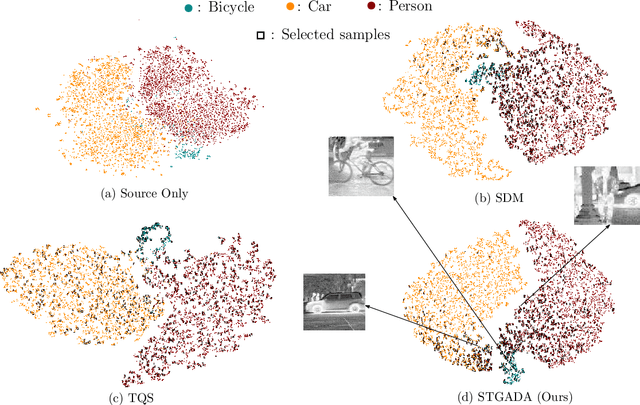
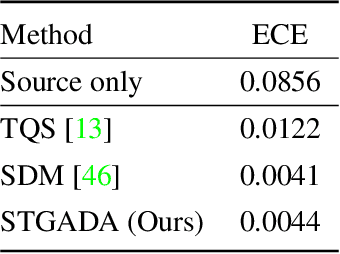
The exploitation of visible spectrum datasets has led deep networks to show remarkable success. However, real-world tasks include low-lighting conditions which arise performance bottlenecks for models trained on large-scale RGB image datasets. Thermal IR cameras are more robust against such conditions. Therefore, the usage of thermal imagery in real-world applications can be useful. Unsupervised domain adaptation (UDA) allows transferring information from a source domain to a fully unlabeled target domain. Despite substantial improvements in UDA, the performance gap between UDA and its supervised learning counterpart remains significant. By picking a small number of target samples to annotate and using them in training, active domain adaptation tries to mitigate this gap with minimum annotation expense. We propose an active domain adaptation method in order to examine the efficiency of combining the visible spectrum and thermal imagery modalities. When the domain gap is considerably large as in the visible-to-thermal task, we may conclude that the methods without explicit domain alignment cannot achieve their full potential. To this end, we propose a spectral transfer guided active domain adaptation method to select the most informative unlabeled target samples while aligning source and target domains. We used the large-scale visible spectrum dataset MS-COCO as the source domain and the thermal dataset FLIR ADAS as the target domain to present the results of our method. Extensive experimental evaluation demonstrates that our proposed method outperforms the state-of-the-art active domain adaptation methods. The code and models are publicly available.
Unsupervised Learning Optical Flow in Multi-frame Dynamic Environment Using Temporal Dynamic Modeling
Apr 14, 2023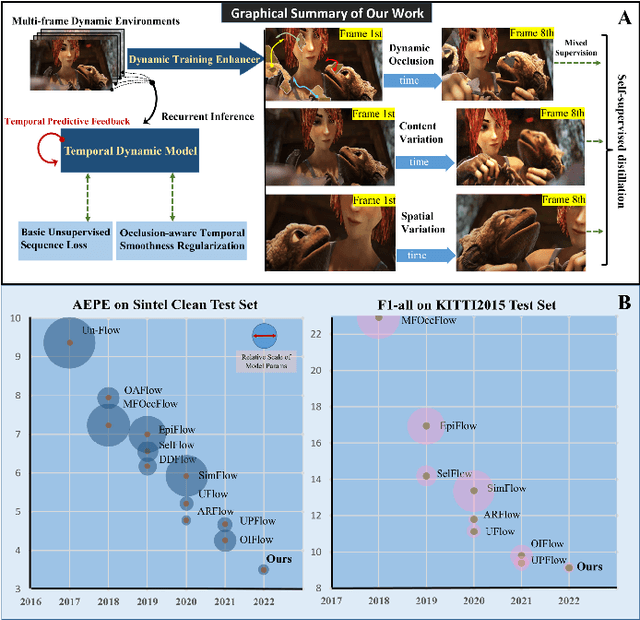
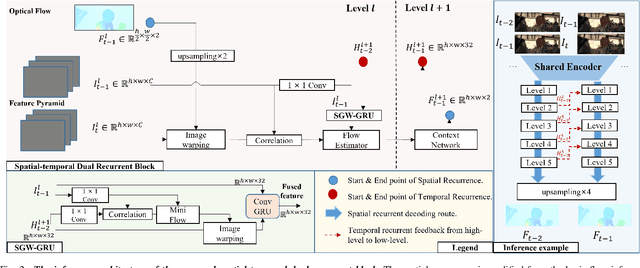
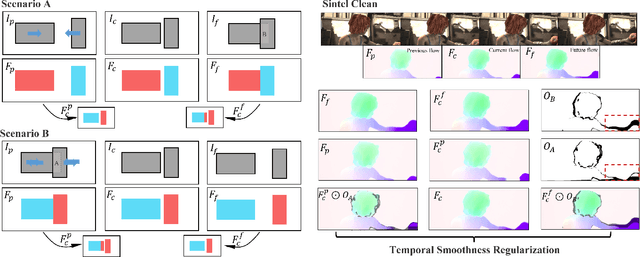
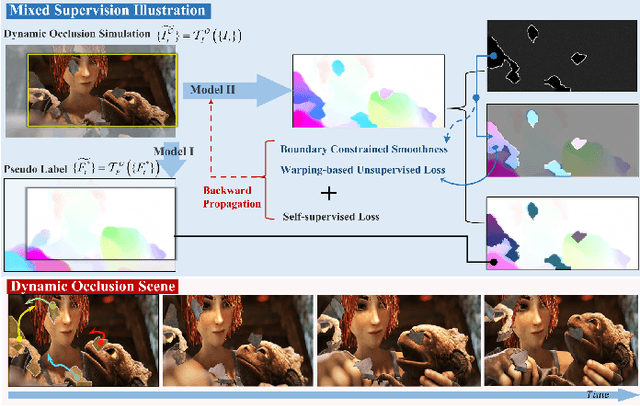
For visual estimation of optical flow, a crucial function for many vision tasks, unsupervised learning, using the supervision of view synthesis has emerged as a promising alternative to supervised methods, since ground-truth flow is not readily available in many cases. However, unsupervised learning is likely to be unstable when pixel tracking is lost due to occlusion and motion blur, or the pixel matching is impaired due to variation in image content and spatial structure over time. In natural environments, dynamic occlusion or object variation is a relatively slow temporal process spanning several frames. We, therefore, explore the optical flow estimation from multiple-frame sequences of dynamic scenes, whereas most of the existing unsupervised approaches are based on temporal static models. We handle the unsupervised optical flow estimation with a temporal dynamic model by introducing a spatial-temporal dual recurrent block based on the predictive coding structure, which feeds the previous high-level motion prior to the current optical flow estimator. Assuming temporal smoothness of optical flow, we use motion priors of the adjacent frames to provide more reliable supervision of the occluded regions. To grasp the essence of challenging scenes, we simulate various scenarios across long sequences, including dynamic occlusion, content variation, and spatial variation, and adopt self-supervised distillation to make the model understand the object's motion patterns in a prolonged dynamic environment. Experiments on KITTI 2012, KITTI 2015, Sintel Clean, and Sintel Final datasets demonstrate the effectiveness of our methods on unsupervised optical flow estimation. The proposal achieves state-of-the-art performance with advantages in memory overhead.
RobCaps: Evaluating the Robustness of Capsule Networks against Affine Transformations and Adversarial Attacks
Apr 08, 2023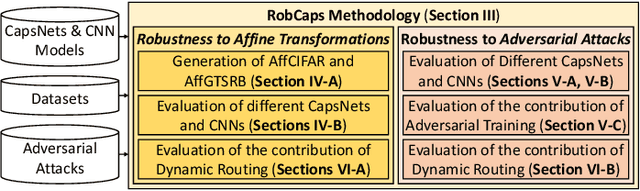

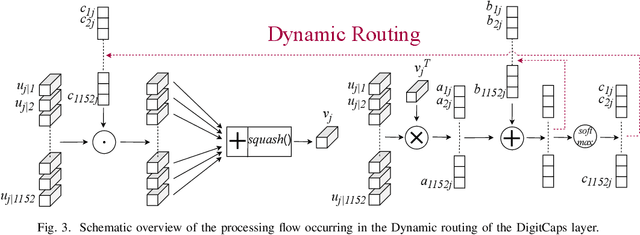
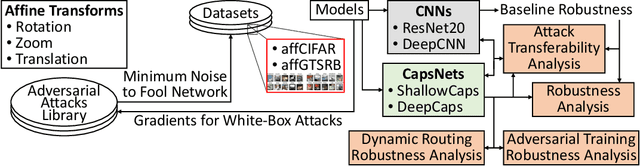
Capsule Networks (CapsNets) are able to hierarchically preserve the pose relationships between multiple objects for image classification tasks. Other than achieving high accuracy, another relevant factor in deploying CapsNets in safety-critical applications is the robustness against input transformations and malicious adversarial attacks. In this paper, we systematically analyze and evaluate different factors affecting the robustness of CapsNets, compared to traditional Convolutional Neural Networks (CNNs). Towards a comprehensive comparison, we test two CapsNet models and two CNN models on the MNIST, GTSRB, and CIFAR10 datasets, as well as on the affine-transformed versions of such datasets. With a thorough analysis, we show which properties of these architectures better contribute to increasing the robustness and their limitations. Overall, CapsNets achieve better robustness against adversarial examples and affine transformations, compared to a traditional CNN with a similar number of parameters. Similar conclusions have been derived for deeper versions of CapsNets and CNNs. Moreover, our results unleash a key finding that the dynamic routing does not contribute much to improving the CapsNets' robustness. Indeed, the main generalization contribution is due to the hierarchical feature learning through capsules.
Reference-Guided Large-Scale Face Inpainting with Identity and Texture Control
Mar 13, 2023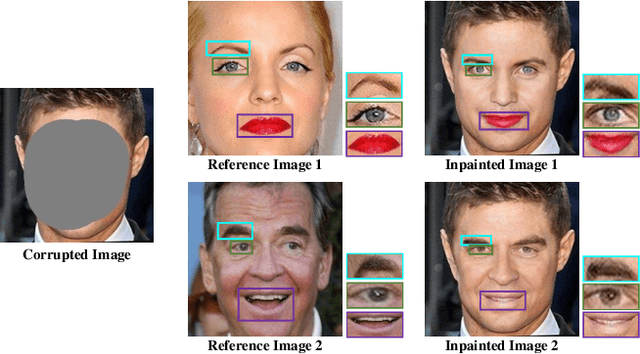



Face inpainting aims at plausibly predicting missing pixels of face images within a corrupted region. Most existing methods rely on generative models learning a face image distribution from a big dataset, which produces uncontrollable results, especially with large-scale missing regions. To introduce strong control for face inpainting, we propose a novel reference-guided face inpainting method that fills the large-scale missing region with identity and texture control guided by a reference face image. However, generating high-quality results under imposing two control signals is challenging. To tackle such difficulty, we propose a dual control one-stage framework that decouples the reference image into two levels for flexible control: High-level identity information and low-level texture information, where the identity information figures out the shape of the face and the texture information depicts the component-aware texture. To synthesize high-quality results, we design two novel modules referred to as Half-AdaIN and Component-Wise Style Injector (CWSI) to inject the two kinds of control information into the inpainting processing. Our method produces realistic results with identity and texture control faithful to reference images. To the best of our knowledge, it is the first work to concurrently apply identity and component-level controls in face inpainting to promise more precise and controllable results. Code is available at https://github.com/WuyangLuo/RefFaceInpainting
Thermal Infrared Image Inpainting via Edge-Aware Guidance
Oct 28, 2022
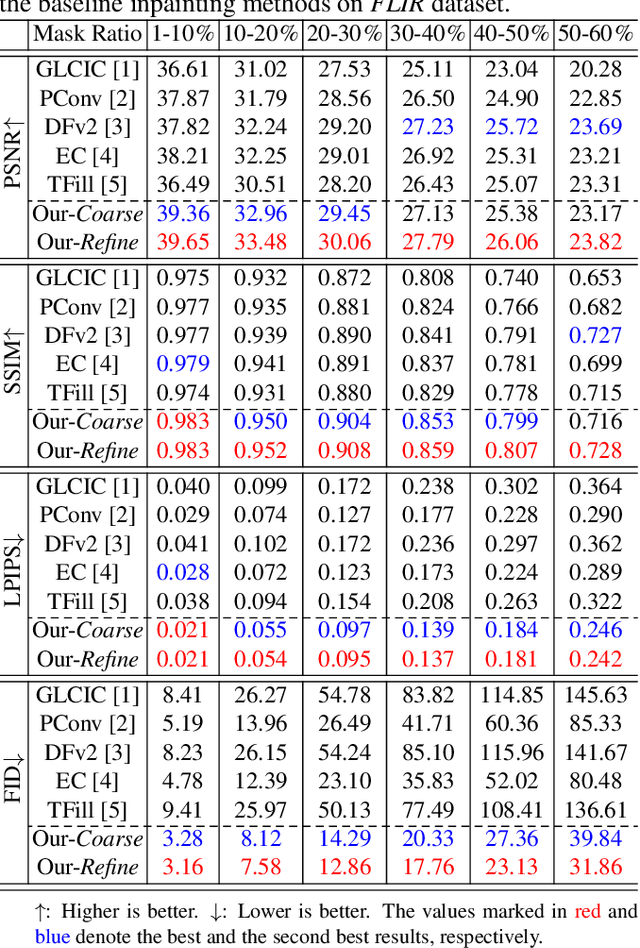
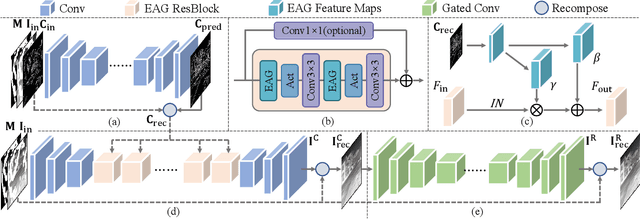

Image inpainting has achieved fundamental advances with deep learning. However, almost all existing inpainting methods aim to process natural images, while few target Thermal Infrared (TIR) images, which have widespread applications. When applied to TIR images, conventional inpainting methods usually generate distorted or blurry content. In this paper, we propose a novel task -- Thermal Infrared Image Inpainting, which aims to reconstruct missing regions of TIR images. Crucially, we propose a novel deep-learning-based model TIR-Fill. We adopt the edge generator to complete the canny edges of broken TIR images. The completed edges are projected to the normalization weights and biases to enhance edge awareness of the model. In addition, a refinement network based on gated convolution is employed to improve TIR image consistency. The experiments demonstrate that our method outperforms state-of-the-art image inpainting approaches on FLIR thermal dataset.
From Coarse to Fine: Hierarchical Pixel Integration for Lightweight Image Super-Resolution
Nov 30, 2022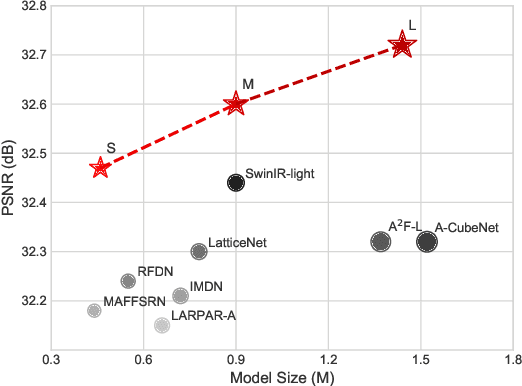
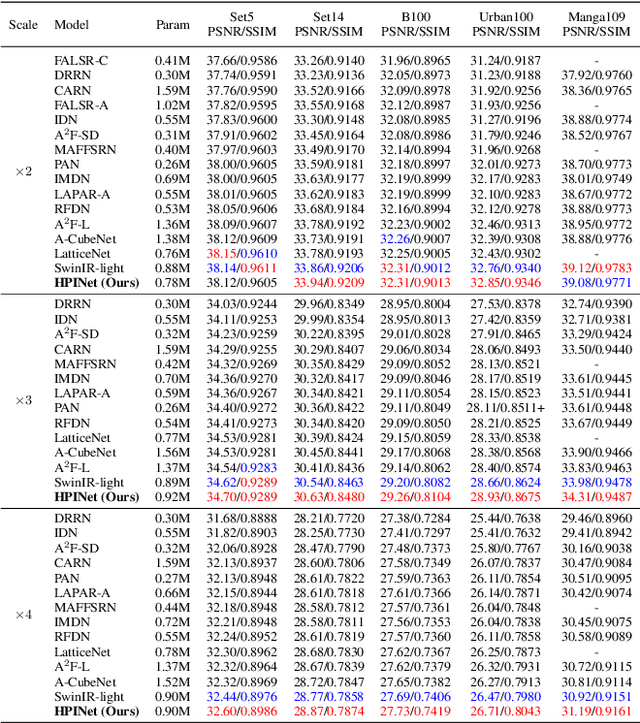
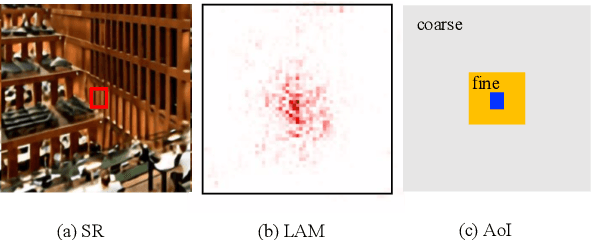

Image super-resolution (SR) serves as a fundamental tool for the processing and transmission of multimedia data. Recently, Transformer-based models have achieved competitive performances in image SR. They divide images into fixed-size patches and apply self-attention on these patches to model long-range dependencies among pixels. However, this architecture design is originated for high-level vision tasks, which lacks design guideline from SR knowledge. In this paper, we aim to design a new attention block whose insights are from the interpretation of Local Attribution Map (LAM) for SR networks. Specifically, LAM presents a hierarchical importance map where the most important pixels are located in a fine area of a patch and some less important pixels are spread in a coarse area of the whole image. To access pixels in the coarse area, instead of using a very large patch size, we propose a lightweight Global Pixel Access (GPA) module that applies cross-attention with the most similar patch in an image. In the fine area, we use an Intra-Patch Self-Attention (IPSA) module to model long-range pixel dependencies in a local patch, and then a $3\times3$ convolution is applied to process the finest details. In addition, a Cascaded Patch Division (CPD) strategy is proposed to enhance perceptual quality of recovered images. Extensive experiments suggest that our method outperforms state-of-the-art lightweight SR methods by a large margin. Code is available at https://github.com/passerer/HPINet.
USER: Unified Semantic Enhancement with Momentum Contrast for Image-Text Retrieval
Jan 17, 2023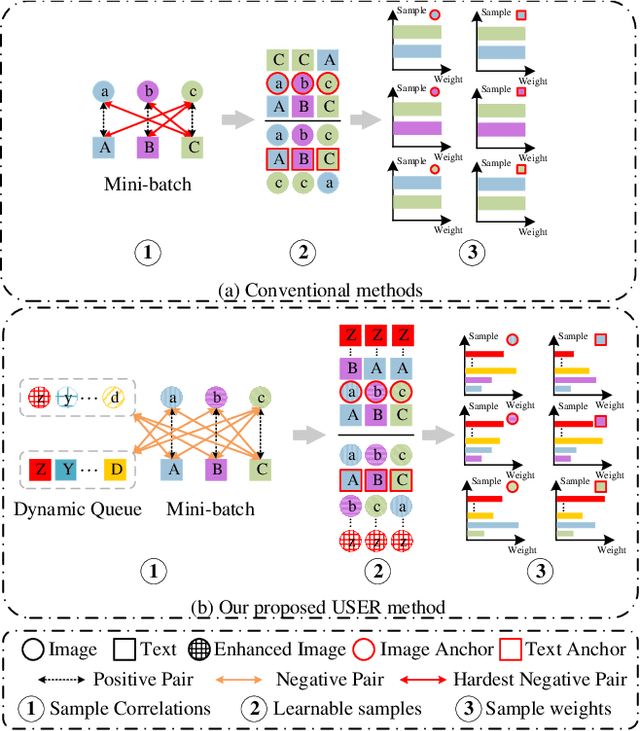
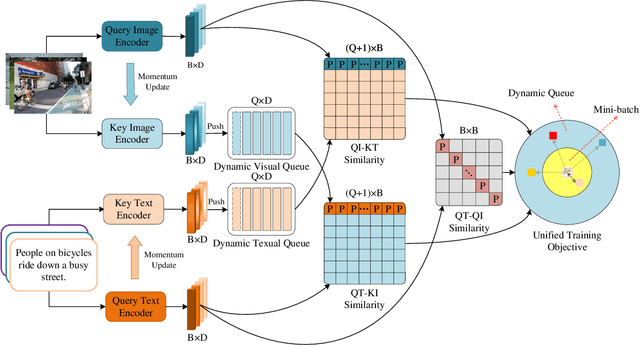
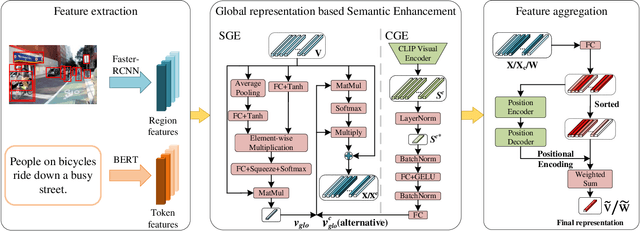
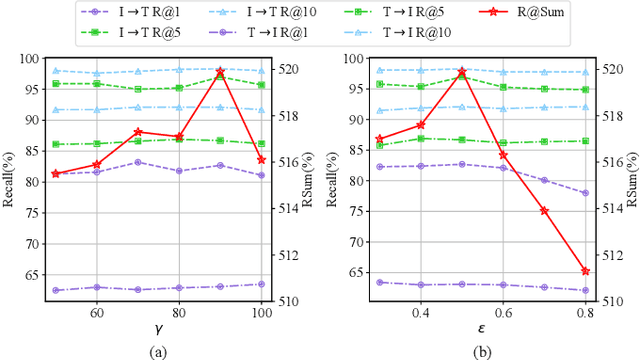
As a fundamental and challenging task in bridging language and vision domains, Image-Text Retrieval (ITR) aims at searching for the target instances that are semantically relevant to the given query from the other modality, and its key challenge is to measure the semantic similarity across different modalities. Although significant progress has been achieved, existing approaches typically suffer from two major limitations: (1) It hurts the accuracy of the representation by directly exploiting the bottom-up attention based region-level features where each region is equally treated. (2) It limits the scale of negative sample pairs by employing the mini-batch based end-to-end training mechanism. To address these limitations, we propose a Unified Semantic Enhancement Momentum Contrastive Learning (USER) method for ITR. Specifically, we delicately design two simple but effective Global representation based Semantic Enhancement (GSE) modules. One learns the global representation via the self-attention algorithm, noted as Self-Guided Enhancement (SGE) module. The other module benefits from the pre-trained CLIP module, which provides a novel scheme to exploit and transfer the knowledge from an off-the-shelf model, noted as CLIP-Guided Enhancement (CGE) module. Moreover, we incorporate the training mechanism of MoCo into ITR, in which two dynamic queues are employed to enrich and enlarge the scale of negative sample pairs. Meanwhile, a Unified Training Objective (UTO) is developed to learn from mini-batch based and dynamic queue based samples. Extensive experiments on the benchmark MSCOCO and Flickr30K datasets demonstrate the superiority of both retrieval accuracy and inference efficiency. Our source code will be released at https://github.com/zhangy0822/USER.
Topology Reasoning for Driving Scenes
Apr 11, 2023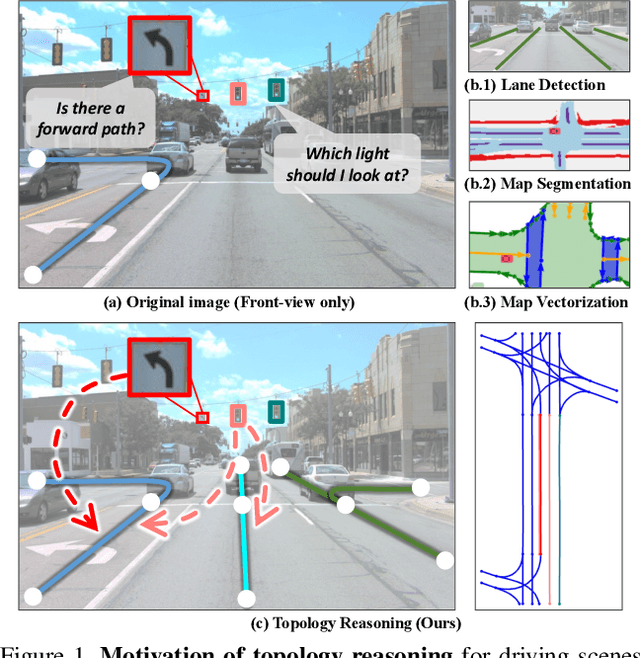
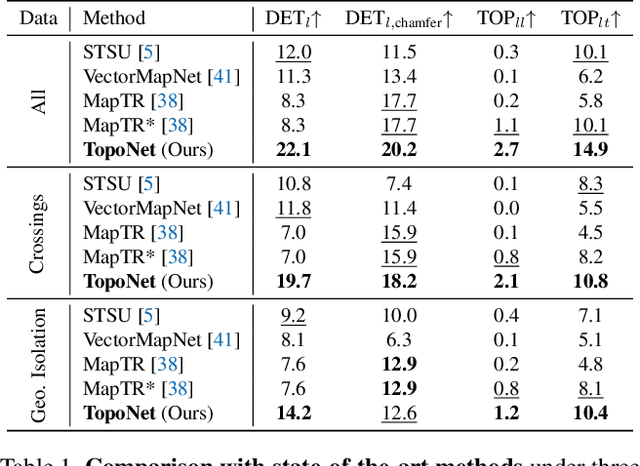
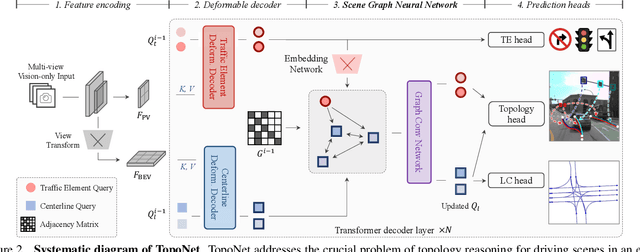
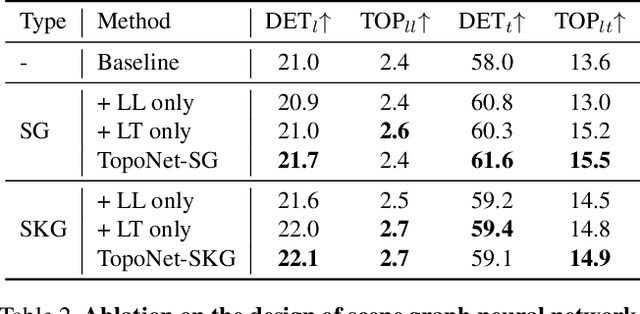
Understanding the road genome is essential to realize autonomous driving. This highly intelligent problem contains two aspects - the connection relationship of lanes, and the assignment relationship between lanes and traffic elements, where a comprehensive topology reasoning method is vacant. On one hand, previous map learning techniques struggle in deriving lane connectivity with segmentation or laneline paradigms; or prior lane topology-oriented approaches focus on centerline detection and neglect the interaction modeling. On the other hand, the traffic element to lane assignment problem is limited in the image domain, leaving how to construct the correspondence from two views an unexplored challenge. To address these issues, we present TopoNet, the first end-to-end framework capable of abstracting traffic knowledge beyond conventional perception tasks. To capture the driving scene topology, we introduce three key designs: (1) an embedding module to incorporate semantic knowledge from 2D elements into a unified feature space; (2) a curated scene graph neural network to model relationships and enable feature interaction inside the network; (3) instead of transmitting messages arbitrarily, a scene knowledge graph is devised to differentiate prior knowledge from various types of the road genome. We evaluate TopoNet on the challenging scene understanding benchmark, OpenLane-V2, where our approach outperforms all previous works by a great margin on all perceptual and topological metrics. The code would be released soon.
Re-imagine the Negative Prompt Algorithm: Transform 2D Diffusion into 3D, alleviate Janus problem and Beyond
Apr 11, 2023
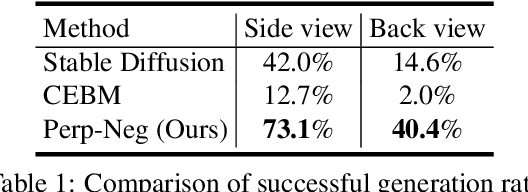

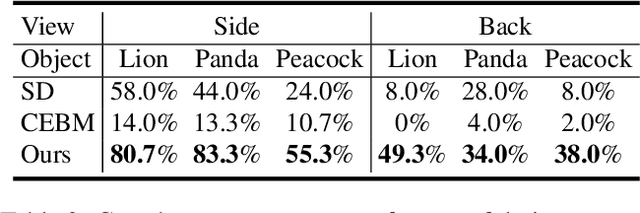
Although text-to-image diffusion models have made significant strides in generating images from text, they are sometimes more inclined to generate images like the data on which the model was trained rather than the provided text. This limitation has hindered their usage in both 2D and 3D applications. To address this problem, we explored the use of negative prompts but found that the current implementation fails to produce desired results, particularly when there is an overlap between the main and negative prompts. To overcome this issue, we propose Perp-Neg, a new algorithm that leverages the geometrical properties of the score space to address the shortcomings of the current negative prompts algorithm. Perp-Neg does not require any training or fine-tuning of the model. Moreover, we experimentally demonstrate that Perp-Neg provides greater flexibility in generating images by enabling users to edit out unwanted concepts from the initially generated images in 2D cases. Furthermore, to extend the application of Perp-Neg to 3D, we conducted a thorough exploration of how Perp-Neg can be used in 2D to condition the diffusion model to generate desired views, rather than being biased toward the canonical views. Finally, we applied our 2D intuition to integrate Perp-Neg with the state-of-the-art text-to-3D (DreamFusion) method, effectively addressing its Janus (multi-head) problem.