 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Devil's on the Edges: Selective Quad Attention for Scene Graph Generation
Apr 07, 2023
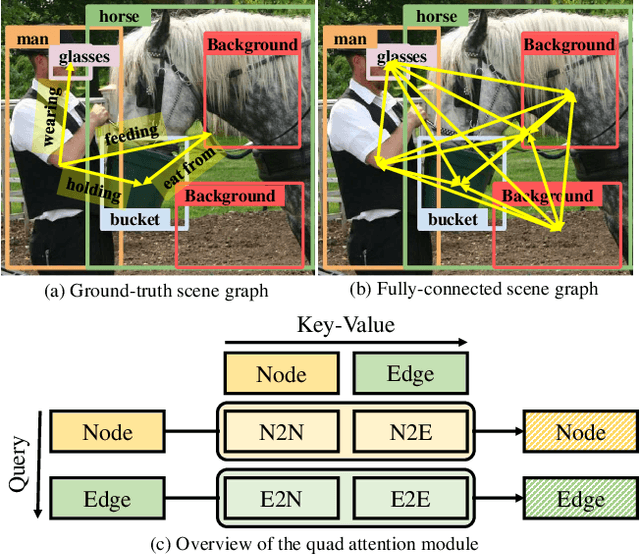
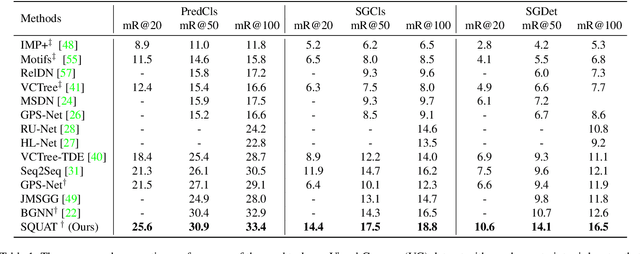
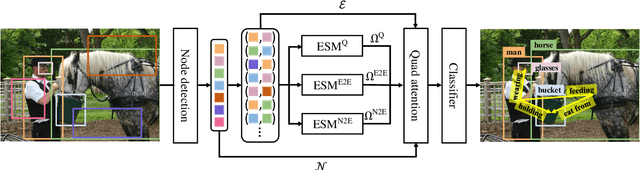
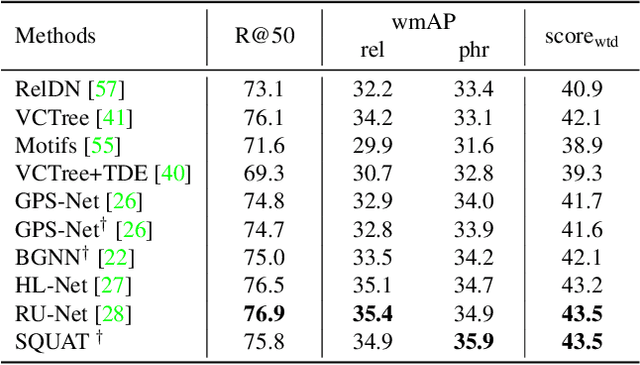
Scene graph generation aims to construct a semantic graph structure from an image such that its nodes and edges respectively represent objects and their relationships. One of the major challenges for the task lies in the presence of distracting objects and relationships in images; contextual reasoning is strongly distracted by irrelevant objects or backgrounds and, more importantly, a vast number of irrelevant candidate relations. To tackle the issue, we propose the Selective Quad Attention Network (SQUAT) that learns to select relevant object pairs and disambiguate them via diverse contextual interactions. SQUAT consists of two main components: edge selection and quad attention. The edge selection module selects relevant object pairs, i.e., edges in the scene graph, which helps contextual reasoning, and the quad attention module then updates the edge features using both edge-to-node and edge-to-edge cross-attentions to capture contextual information between objects and object pairs. Experiments demonstrate the strong performance and robustness of SQUAT, achieving the state of the art on the Visual Genome and Open Images v6 benchmarks.
Efficient View Synthesis and 3D-based Multi-Frame Denoising with Multiplane Feature Representations
Apr 05, 2023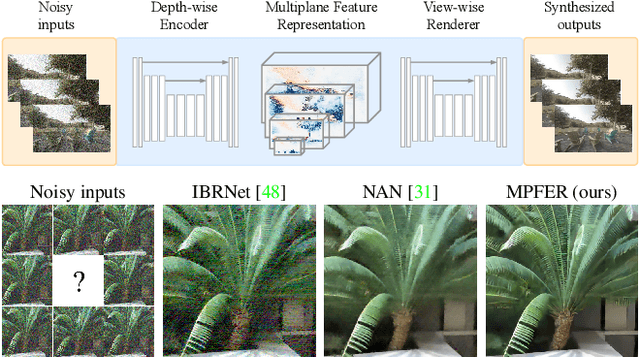
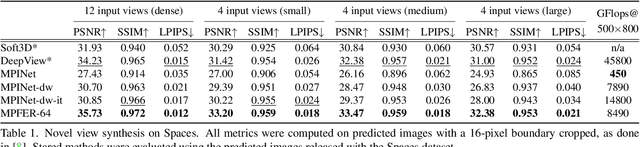
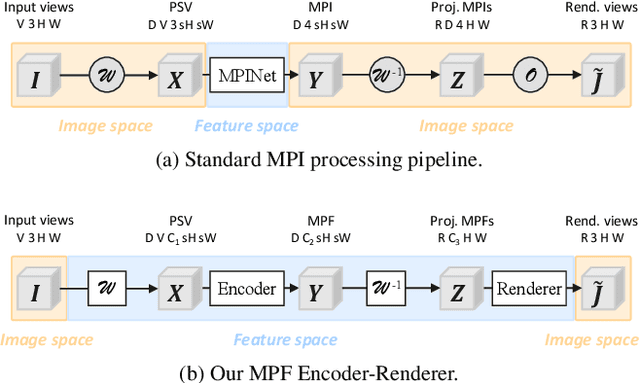
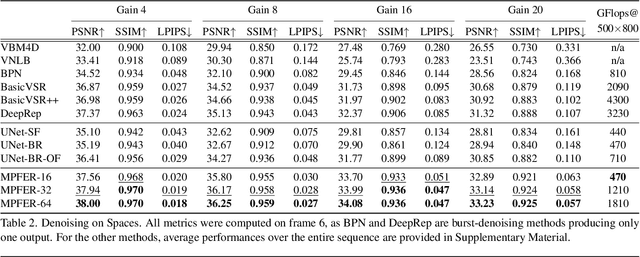
While current multi-frame restoration methods combine information from multiple input images using 2D alignment techniques, recent advances in novel view synthesis are paving the way for a new paradigm relying on volumetric scene representations. In this work, we introduce the first 3D-based multi-frame denoising method that significantly outperforms its 2D-based counterparts with lower computational requirements. Our method extends the multiplane image (MPI) framework for novel view synthesis by introducing a learnable encoder-renderer pair manipulating multiplane representations in feature space. The encoder fuses information across views and operates in a depth-wise manner while the renderer fuses information across depths and operates in a view-wise manner. The two modules are trained end-to-end and learn to separate depths in an unsupervised way, giving rise to Multiplane Feature (MPF) representations. Experiments on the Spaces and Real Forward-Facing datasets as well as on raw burst data validate our approach for view synthesis, multi-frame denoising, and view synthesis under noisy conditions.
Exploring the Utility of Self-Supervised Pretraining Strategies for the Detection of Absent Lung Sliding in M-Mode Lung Ultrasound
Apr 05, 2023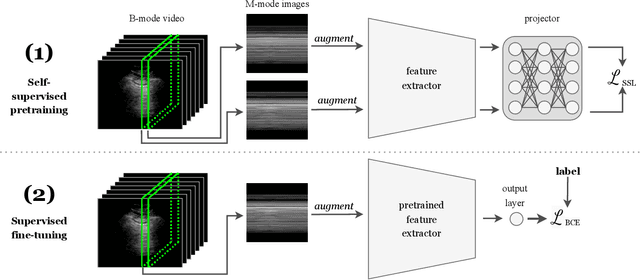
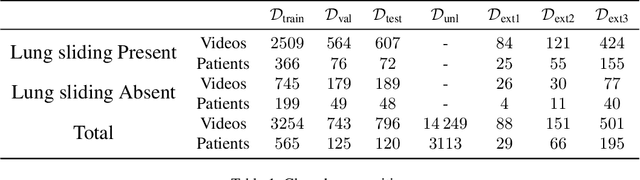
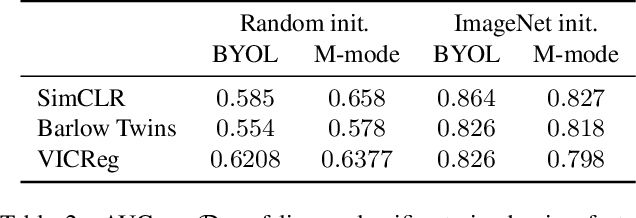
Self-supervised pretraining has been observed to improve performance in supervised learning tasks in medical imaging. This study investigates the utility of self-supervised pretraining prior to conducting supervised fine-tuning for the downstream task of lung sliding classification in M-mode lung ultrasound images. We propose a novel pairwise relationship that couples M-mode images constructed from the same B-mode image and investigate the utility of data augmentation procedure specific to M-mode lung ultrasound. The results indicate that self-supervised pretraining yields better performance than full supervision, most notably for feature extractors not initialized with ImageNet-pretrained weights. Moreover, we observe that including a vast volume of unlabelled data results in improved performance on external validation datasets, underscoring the value of self-supervision for improving generalizability in automatic ultrasound interpretation. To the authors' best knowledge, this study is the first to characterize the influence of self-supervised pretraining for M-mode ultrasound.
Img2Tab: Automatic Class Relevant Concept Discovery from StyleGAN Features for Explainable Image Classification
Jan 16, 2023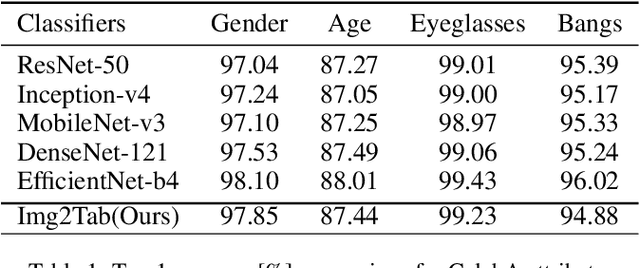
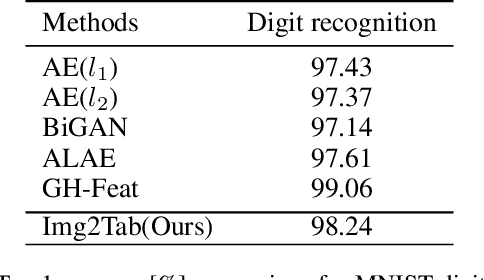
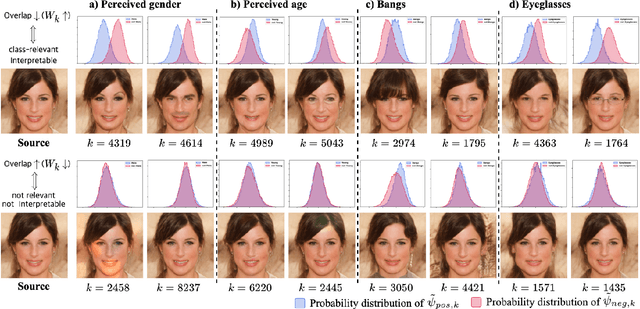
Traditional tabular classifiers provide explainable decision-making with interpretable features(concepts). However, using their explainability in vision tasks has been limited due to the pixel representation of images. In this paper, we design Img2Tabs that classify images by concepts to harness the explainability of tabular classifiers. Img2Tabs encode image pixels into tabular features by StyleGAN inversion. Since not all of the resulting features are class-relevant or interpretable due to their generative nature, we expect Img2Tab classifiers to discover class-relevant concepts automatically from the StyleGAN features. Thus, we propose a novel method using the Wasserstein-1 metric to quantify class-relevancy and interpretability simultaneously. Using this method, we investigate whether important features extracted by tabular classifiers are class-relevant concepts. Consequently, we determine the most effective classifier for Img2Tabs in terms of discovering class-relevant concepts automatically from StyleGAN features. In evaluations, we demonstrate concept-based explanations through importance and visualization. Img2Tab achieves top-1 accuracy that is on par with CNN classifiers and deep feature learning baselines. Additionally, we show that users can easily debug Img2Tab classifiers at the concept level to ensure unbiased and fair decision-making without sacrificing accuracy.
Joint Embedding of 2D and 3D Networks for Medical Image Anomaly Detection
Dec 23, 2022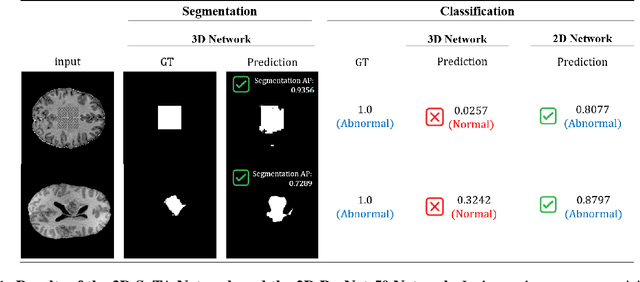
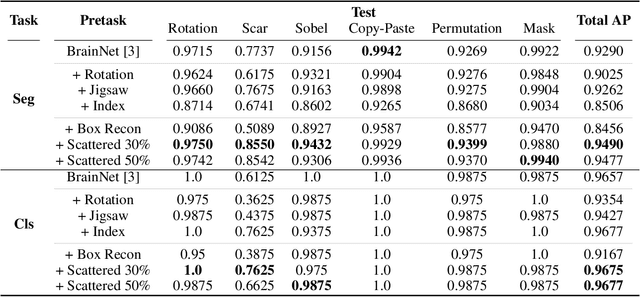
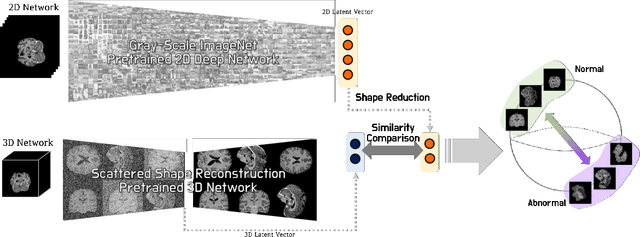
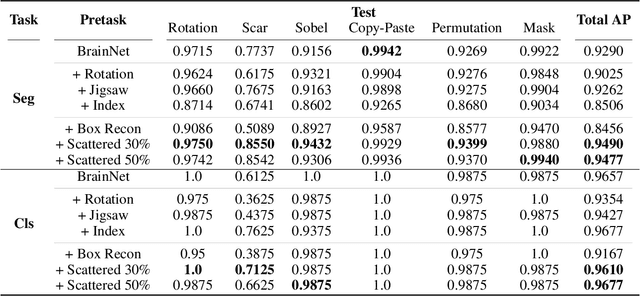
Obtaining ground truth data in medical imaging has difficulties due to the fact that it requires a lot of annotating time from the experts in the field. Also, when trained with supervised learning, it detects only the cases included in the labels. In real practice, we want to also open to other possibilities than the named cases while examining the medical images. As a solution, the need for anomaly detection that can detect and localize abnormalities by learning the normal characteristics using only normal images is emerging. With medical image data, we can design either 2D or 3D networks of self-supervised learning for anomaly detection task. Although 3D networks, which learns 3D structures of the human body, show good performance in 3D medical image anomaly detection, they cannot be stacked in deeper layers due to memory problems. While 2D networks have advantage in feature detection, they lack 3D context information. In this paper, we develop a method for combining the strength of the 3D network and the strength of the 2D network through joint embedding. We also propose the pretask of self-supervised learning to make it possible for the networks to learn efficiently. Through the experiments, we show that the proposed method achieves better performance in both classification and segmentation tasks compared to the SoTA method.
Learning-based Framework for US Signals Super-resolution
Apr 17, 2023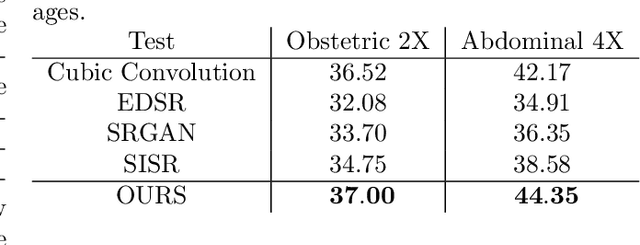
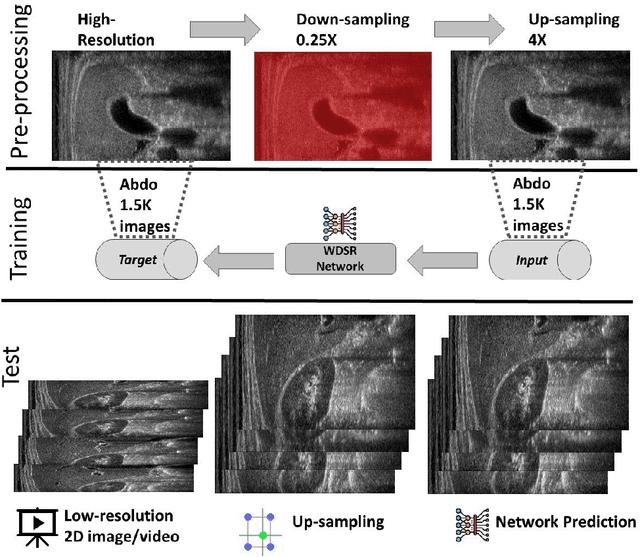

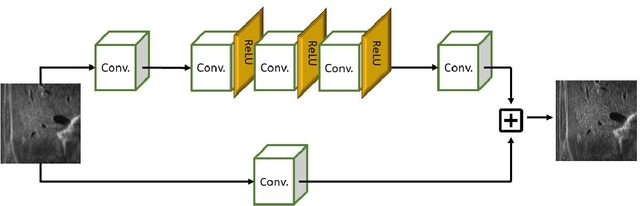
We propose a novel deep-learning framework for super-resolution ultrasound images and videos in terms of spatial resolution and line reconstruction. We up-sample the acquired low-resolution image through a vision-based interpolation method; then, we train a learning-based model to improve the quality of the up-sampling. We qualitatively and quantitatively test our model on different anatomical districts (e.g., cardiac, obstetric) images and with different up-sampling resolutions (i.e., 2X, 4X). Our method improves the PSNR median value with respect to SOTA methods of $1.7\%$ on obstetric 2X raw images, $6.1\%$ on cardiac 2X raw images, and $4.4\%$ on abdominal raw 4X images; it also improves the number of pixels with a low prediction error of $9.0\%$ on obstetric 4X raw images, $5.2\%$ on cardiac 4X raw images, and $6.2\%$ on abdominal 4X raw images. The proposed method is then applied to the spatial super-resolution of 2D videos, by optimising the sampling of lines acquired by the probe in terms of the acquisition frequency. Our method specialises trained networks to predict the high-resolution target through the design of the network architecture and the loss function, taking into account the anatomical district and the up-sampling factor and exploiting a large ultrasound data set. The use of deep learning on large data sets overcomes the limitations of vision-based algorithms that are general and do not encode the characteristics of the data. Furthermore, the data set can be enriched with images selected by medical experts to further specialise the individual networks. Through learning and high-performance computing, our super-resolution is specialised to different anatomical districts by training multiple networks. Furthermore, the computational demand is shifted to centralised hardware resources with a real-time execution of the network's prediction on local devices.
Fast Random Approximation of Multi-channel Room Impulse Response
Apr 17, 2023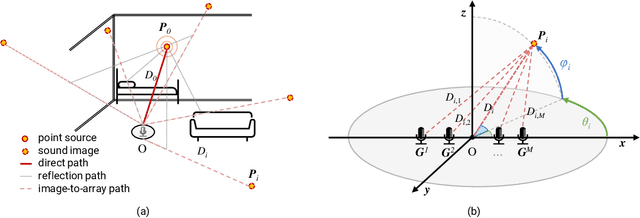
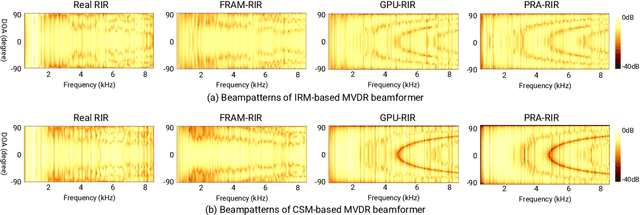
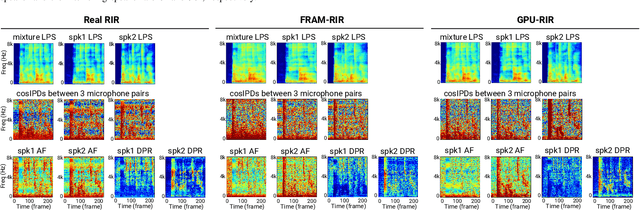
Modern neural-network-based speech processing systems are typically required to be robust against reverberation, and the training of such systems thus needs a large amount of reverberant data. During the training of the systems, on-the-fly simulation pipeline is nowadays preferred as it allows the model to train on infinite number of data samples without pre-generating and saving them on harddisk. An RIR simulation method thus needs to not only generate more realistic artificial room impulse response (RIR) filters, but also generate them in a fast way to accelerate the training process. Existing RIR simulation tools have proven effective in a wide range of speech processing tasks and neural network architectures, but their usage in on-the-fly simulation pipeline remains questionable due to their computational complexity or the quality of the generated RIR filters. In this paper, we propose FRAM-RIR, a fast random approximation method of the widely-used image-source method (ISM), to efficiently generate realistic multi-channel RIR filters. FRAM-RIR bypasses the explicit calculation of sound propagation paths in ISM-based algorithms by randomly sampling the location and number of reflections of each virtual sound source based on several heuristic assumptions, while still maintains accurate direction-of-arrival (DOA) information of all sound sources. Visualization of oracle beampatterns and directional features shows that FRAM-RIR can generate more realistic RIR filters than existing widely-used ISM-based tools, and experiment results on multi-channel noisy speech separation and dereverberation tasks with a wide range of neural network architectures show that models trained with FRAM-RIR can also achieve on par or better performance on real RIRs compared to other RIR simulation tools with a significantly accelerated training procedure. A Python implementation of FRAM-RIR is released.
DejaVu: Conditional Regenerative Learning to Enhance Dense Prediction
Mar 02, 2023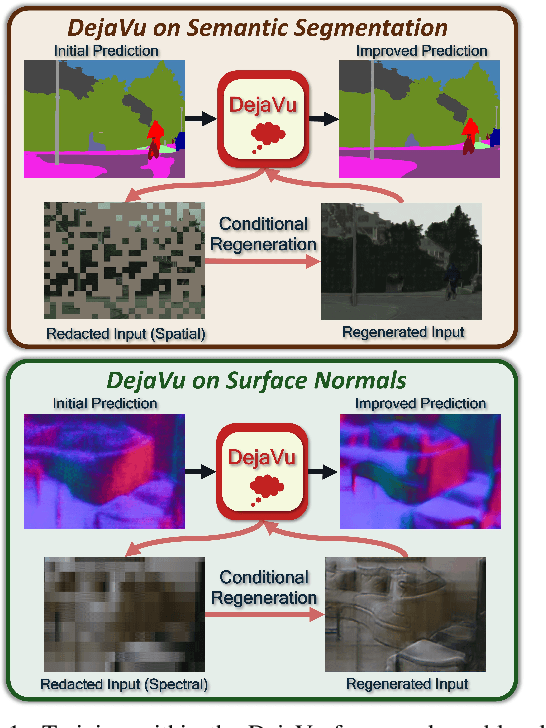
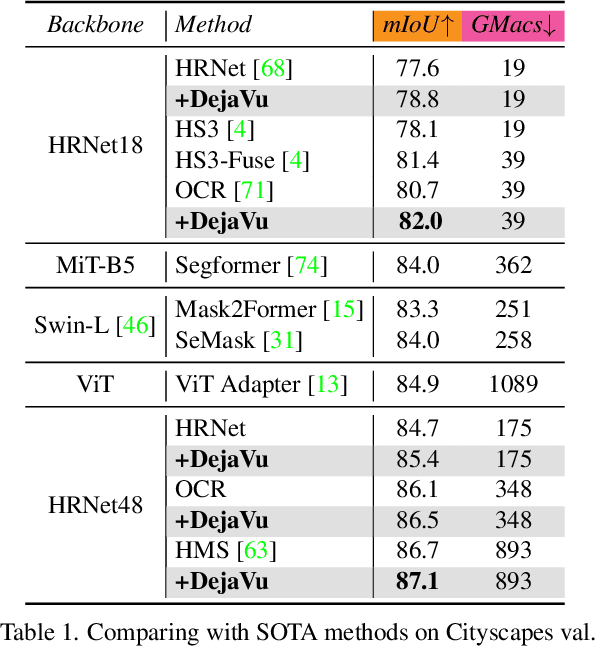
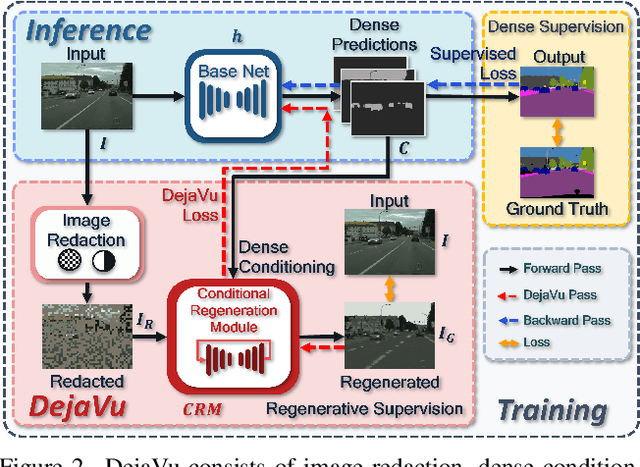
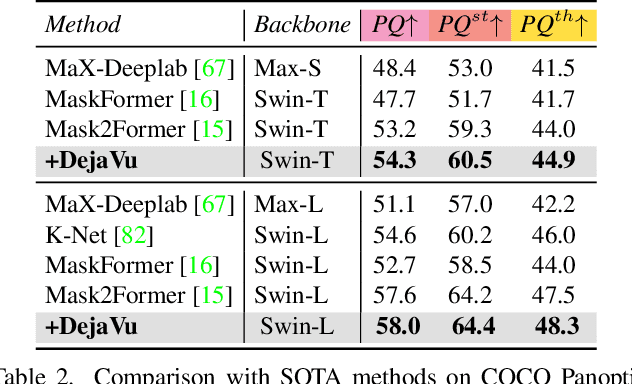
We present DejaVu, a novel framework which leverages conditional image regeneration as additional supervision during training to improve deep networks for dense prediction tasks such as segmentation, depth estimation, and surface normal prediction. First, we apply redaction to the input image, which removes certain structural information by sparse sampling or selective frequency removal. Next, we use a conditional regenerator, which takes the redacted image and the dense predictions as inputs, and reconstructs the original image by filling in the missing structural information. In the redacted image, structural attributes like boundaries are broken while semantic context is largely preserved. In order to make the regeneration feasible, the conditional generator will then require the structure information from the other input source, i.e., the dense predictions. As such, by including this conditional regeneration objective during training, DejaVu encourages the base network to learn to embed accurate scene structure in its dense prediction. This leads to more accurate predictions with clearer boundaries and better spatial consistency. When it is feasible to leverage additional computation, DejaVu can be extended to incorporate an attention-based regeneration module within the dense prediction network, which further improves accuracy. Through extensive experiments on multiple dense prediction benchmarks such as Cityscapes, COCO, ADE20K, NYUD-v2, and KITTI, we demonstrate the efficacy of employing DejaVu during training, as it outperforms SOTA methods at no added computation cost.
NeRFInvertor: High Fidelity NeRF-GAN Inversion for Single-shot Real Image Animation
Nov 30, 2022
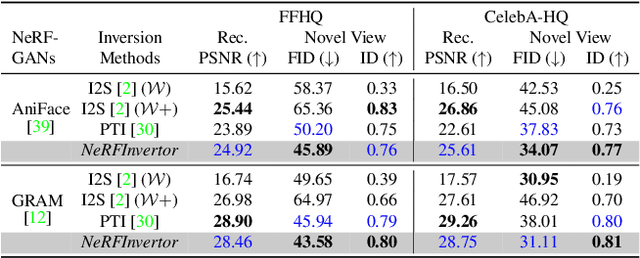

Nerf-based Generative models have shown impressive capacity in generating high-quality images with consistent 3D geometry. Despite successful synthesis of fake identity images randomly sampled from latent space, adopting these models for generating face images of real subjects is still a challenging task due to its so-called inversion issue. In this paper, we propose a universal method to surgically fine-tune these NeRF-GAN models in order to achieve high-fidelity animation of real subjects only by a single image. Given the optimized latent code for an out-of-domain real image, we employ 2D loss functions on the rendered image to reduce the identity gap. Furthermore, our method leverages explicit and implicit 3D regularizations using the in-domain neighborhood samples around the optimized latent code to remove geometrical and visual artifacts. Our experiments confirm the effectiveness of our method in realistic, high-fidelity, and 3D consistent animation of real faces on multiple NeRF-GAN models across different datasets.
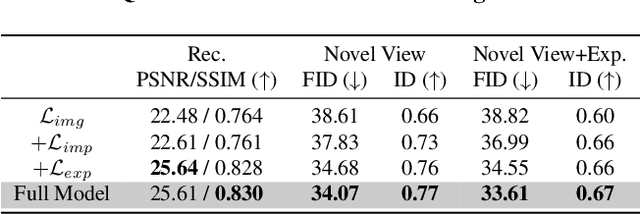
Multimodal Pre-training Framework for Sequential Recommendation via Contrastive Learning
Mar 21, 2023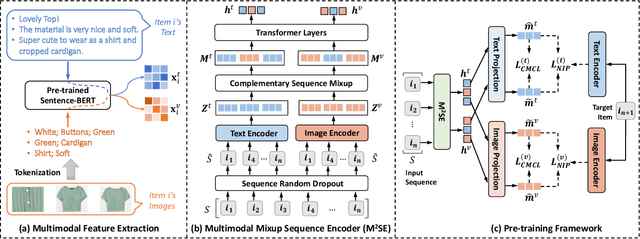
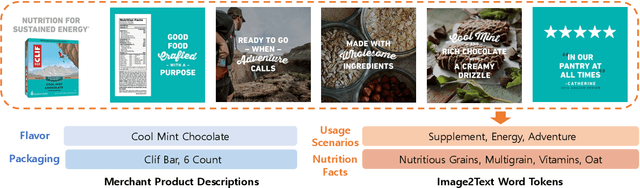
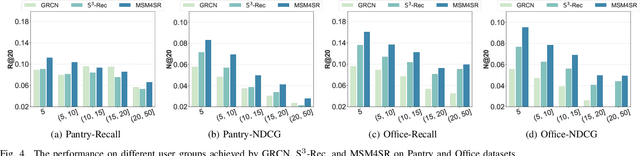
Sequential recommendation systems utilize the sequential interactions of users with items as their main supervision signals in learning users' preferences. However, existing methods usually generate unsatisfactory results due to the sparsity of user behavior data. To address this issue, we propose a novel pre-training framework, named Multimodal Sequence Mixup for Sequential Recommendation (MSM4SR), which leverages both users' sequential behaviors and items' multimodal content (\ie text and images) for effectively recommendation. Specifically, MSM4SR tokenizes each item image into multiple textual keywords and uses the pre-trained BERT model to obtain initial textual and visual features of items, for eliminating the discrepancy between the text and image modalities. A novel backbone network, \ie Multimodal Mixup Sequence Encoder (M$^2$SE), is proposed to bridge the gap between the item multimodal content and the user behavior, using a complementary sequence mixup strategy. In addition, two contrastive learning tasks are developed to assist M$^2$SE in learning generalized multimodal representations of the user behavior sequence. Extensive experiments on real-world datasets demonstrate that MSM4SR outperforms state-of-the-art recommendation methods. Moreover, we further verify the effectiveness of MSM4SR on other challenging tasks including cold-start and cross-domain recommendation.