 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Local Rose Breeds Detection System Using Transfer Learning Techniques
Apr 07, 2023
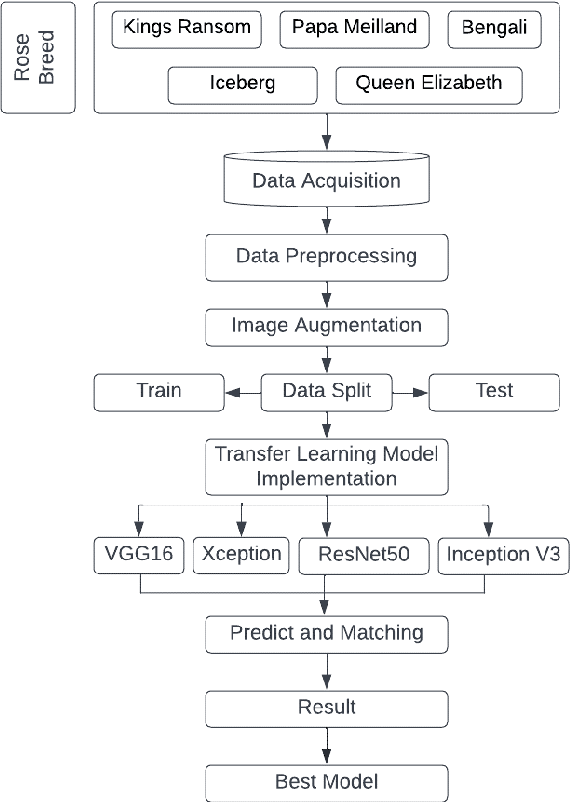
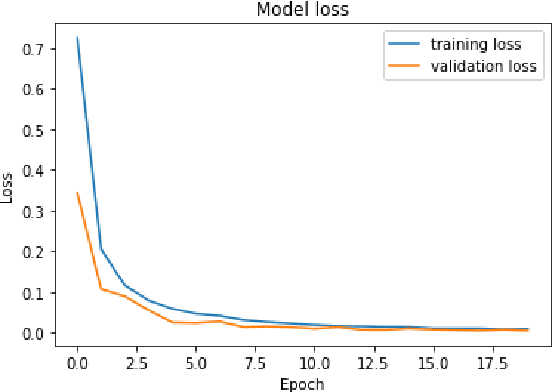
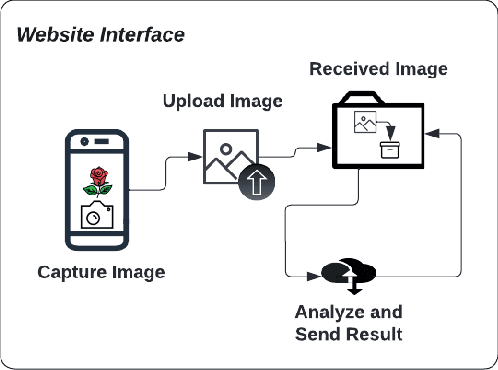

Flower breed detection and giving details of that breed with the suggestion of cultivation processes and the way of taking care is important for flower cultivation, breed invention, and the flower business. Among all the local flowers in Bangladesh, the rose is one of the most popular and demanded flowers. Roses are the most desirable flower not only in Bangladesh but also throughout the world. Roses can be used for many other purposes apart from decoration. As roses have a great demand in the flower business so rose breed detection will be very essential. However, there is no remarkable work for breed detection of a particular flower unlike the classification of different flowers. In this research, we have proposed a model to detect rose breeds from images using transfer learning techniques. For such work in flowers, resources are not enough in image processing and classification, so we needed a large dataset of the massive number of images to train our model. we have used 1939 raw images of five different breeds and we have generated 9306 images for the training dataset and 388 images for the testing dataset to validate the model using augmentation. We have applied four transfer learning models in this research, which are Inception V3, ResNet50, Xception, and VGG16. Among these four models, VGG16 achieved the highest accuracy of 99%, which is an excellent outcome. Breed detection of a rose by using transfer learning methods is the first work on breed detection of a particular flower that is publicly available according to the study.
Mimic before Reconstruct: Enhancing Masked Autoencoders with Feature Mimicking
Mar 09, 2023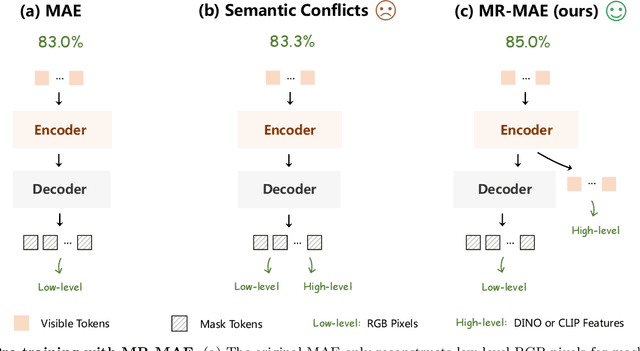
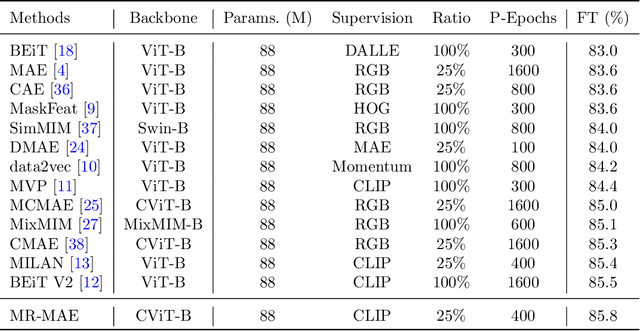
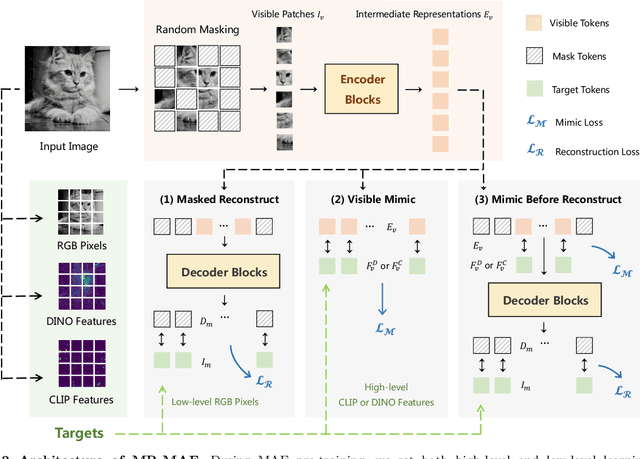
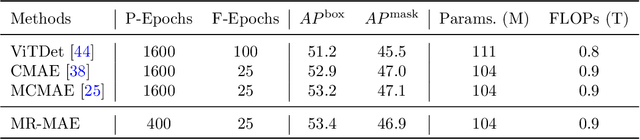
Masked Autoencoders (MAE) have been popular paradigms for large-scale vision representation pre-training. However, MAE solely reconstructs the low-level RGB signals after the decoder and lacks supervision upon high-level semantics for the encoder, thus suffering from sub-optimal learned representations and long pre-training epochs. To alleviate this, previous methods simply replace the pixel reconstruction targets of 75% masked tokens by encoded features from pre-trained image-image (DINO) or image-language (CLIP) contrastive learning. Different from those efforts, we propose to Mimic before Reconstruct for Masked Autoencoders, named as MR-MAE, which jointly learns high-level and low-level representations without interference during pre-training. For high-level semantics, MR-MAE employs a mimic loss over 25% visible tokens from the encoder to capture the pre-trained patterns encoded in CLIP and DINO. For low-level structures, we inherit the reconstruction loss in MAE to predict RGB pixel values for 75% masked tokens after the decoder. As MR-MAE applies high-level and low-level targets respectively at different partitions, the learning conflicts between them can be naturally overcome and contribute to superior visual representations for various downstream tasks. On ImageNet-1K, the MR-MAE base pre-trained for only 400 epochs achieves 85.8% top-1 accuracy after fine-tuning, surpassing the 1600-epoch MAE base by +2.2% and the previous state-of-the-art BEiT V2 base by +0.3%. Code and pre-trained models will be released at https://github.com/Alpha-VL/ConvMAE.
Fourier-Net: Fast Image Registration with Band-limited Deformation
Nov 29, 2022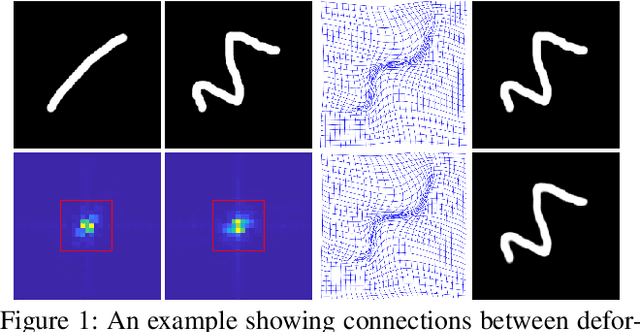
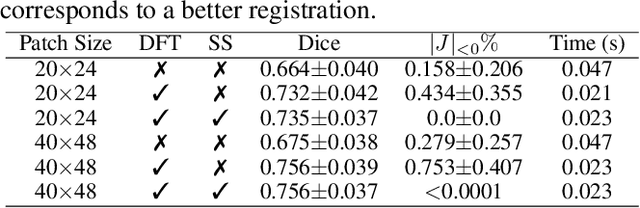
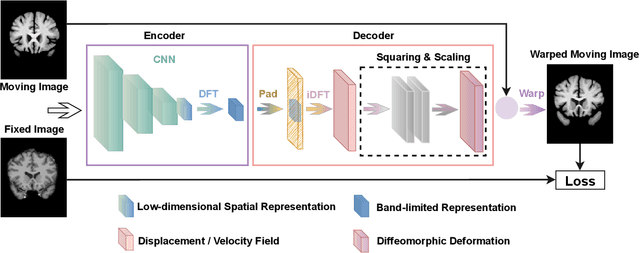
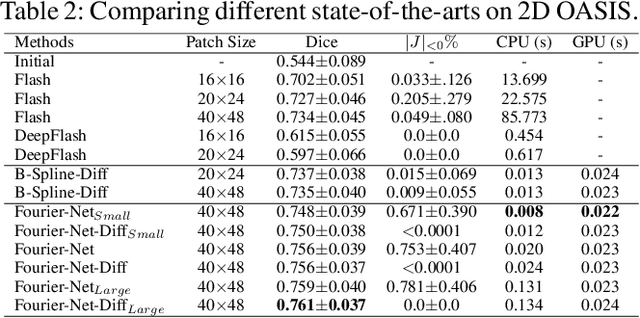
Unsupervised image registration commonly adopts U-Net style networks to predict dense displacement fields in the full-resolution spatial domain. For high-resolution volumetric image data, this process is however resource intensive and time-consuming. To tackle this problem, we propose the Fourier-Net, replacing the expansive path in a U-Net style network with a parameter-free model-driven decoder. Specifically, instead of our Fourier-Net learning to output a full-resolution displacement field in the spatial domain, we learn its low-dimensional representation in a band-limited Fourier domain. This representation is then decoded by our devised model-driven decoder (consisting of a zero padding layer and an inverse discrete Fourier transform layer) to the dense, full-resolution displacement field in the spatial domain. These changes allow our unsupervised Fourier-Net to contain fewer parameters and computational operations, resulting in faster inference speeds. Fourier-Net is then evaluated on two public 3D brain datasets against various state-of-the-art approaches. For example, when compared to a recent transformer-based method, i.e., TransMorph, our Fourier-Net, only using 0.22$\%$ of its parameters and 6.66$\%$ of the mult-adds, achieves a 0.6\% higher Dice score and an 11.48$\times$ faster inference speed. Code is available at \url{https://github.com/xi-jia/Fourier-Net}.
Applications of No-Collision Transportation Maps in Manifold Learning
Apr 01, 2023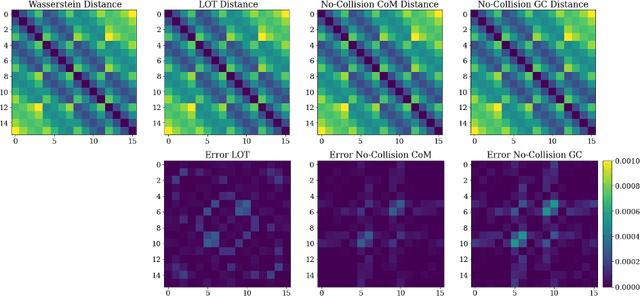

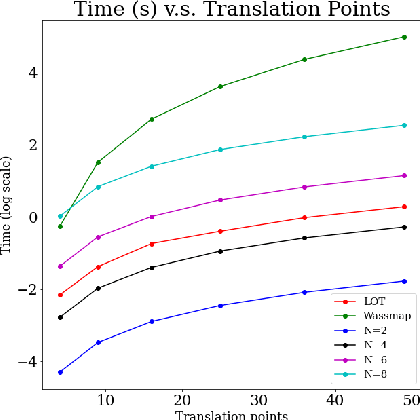

In this work, we investigate applications of no-collision transportation maps introduced in [Nurbekyan et. al., 2020] in manifold learning for image data. Recently, there has been a surge in applying transportation-based distances and features for data representing motion-like or deformation-like phenomena. Indeed, comparing intensities at fixed locations often does not reveal the data structure. No-collision maps and distances developed in [Nurbekyan et. al., 2020] are sensitive to geometric features similar to optimal transportation (OT) maps but much cheaper to compute due to the absence of optimization. In this work, we prove that no-collision distances provide an isometry between translations (respectively dilations) of a single probability measure and the translation (respectively dilation) vectors equipped with a Euclidean distance. Furthermore, we prove that no-collision transportation maps, as well as OT and linearized OT maps, do not in general provide an isometry for rotations. The numerical experiments confirm our theoretical findings and show that no-collision distances achieve similar or better performance on several manifold learning tasks compared to other OT and Euclidean-based methods at a fraction of a computational cost.
SeSDF: Self-evolved Signed Distance Field for Implicit 3D Clothed Human Reconstruction
Apr 01, 2023
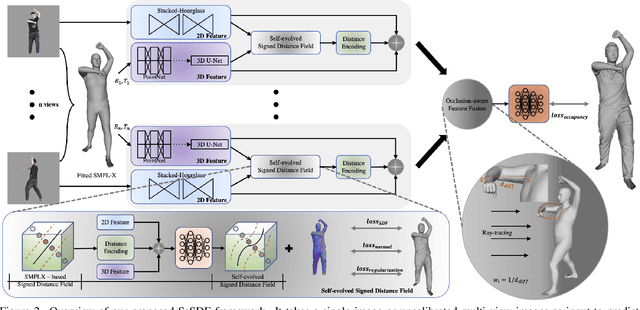
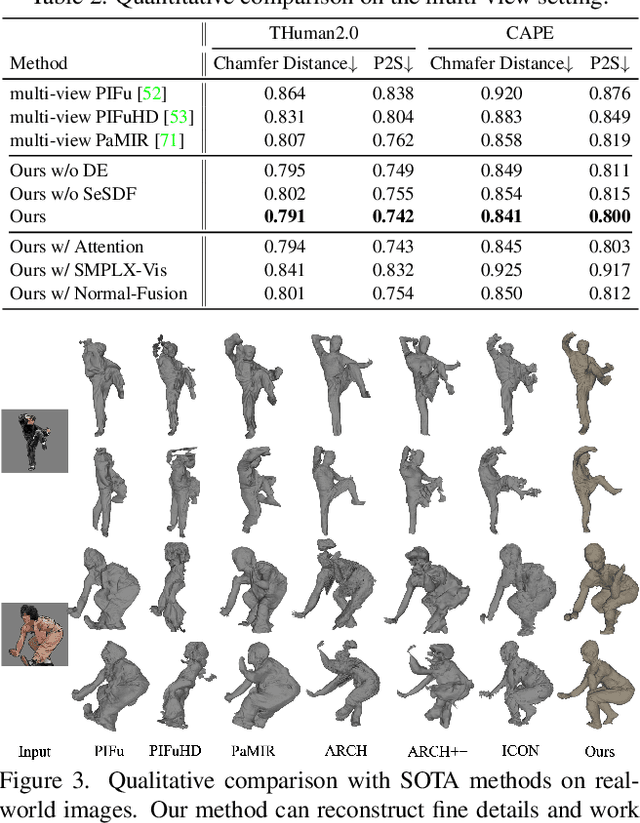

We address the problem of clothed human reconstruction from a single image or uncalibrated multi-view images. Existing methods struggle with reconstructing detailed geometry of a clothed human and often require a calibrated setting for multi-view reconstruction. We propose a flexible framework which, by leveraging the parametric SMPL-X model, can take an arbitrary number of input images to reconstruct a clothed human model under an uncalibrated setting. At the core of our framework is our novel self-evolved signed distance field (SeSDF) module which allows the framework to learn to deform the signed distance field (SDF) derived from the fitted SMPL-X model, such that detailed geometry reflecting the actual clothed human can be encoded for better reconstruction. Besides, we propose a simple method for self-calibration of multi-view images via the fitted SMPL-X parameters. This lifts the requirement of tedious manual calibration and largely increases the flexibility of our method. Further, we introduce an effective occlusion-aware feature fusion strategy to account for the most useful features to reconstruct the human model. We thoroughly evaluate our framework on public benchmarks, demonstrating significant superiority over the state-of-the-arts both qualitatively and quantitatively.
DCS-RISR: Dynamic Channel Splitting for Efficient Real-world Image Super-Resolution
Dec 15, 2022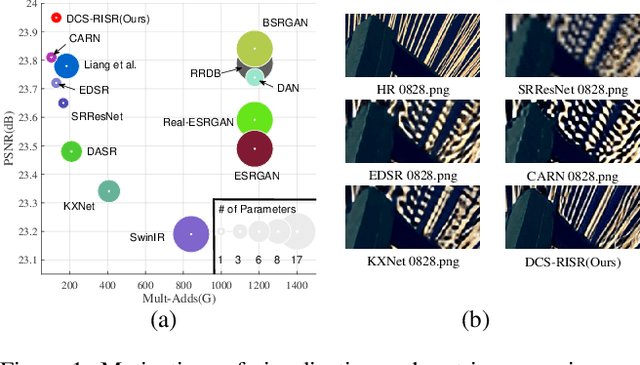
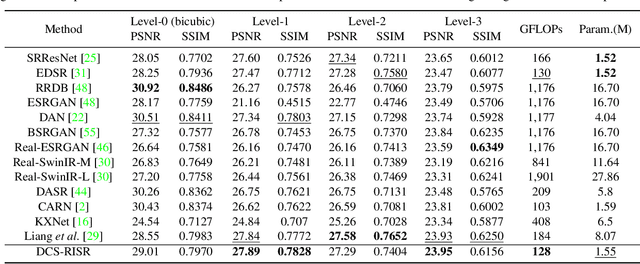
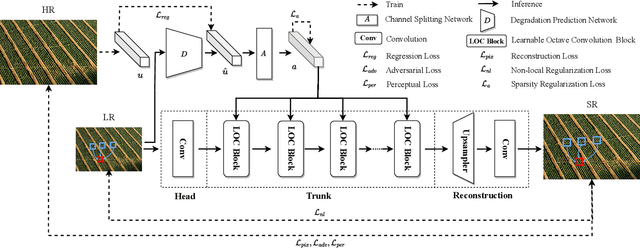
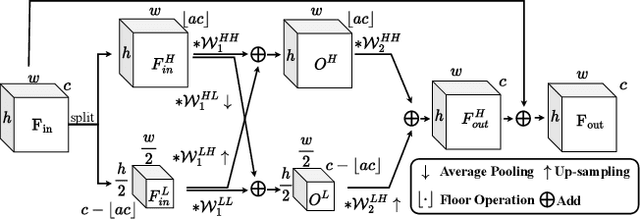
Real-world image super-resolution (RISR) has received increased focus for improving the quality of SR images under unknown complex degradation. Existing methods rely on the heavy SR models to enhance low-resolution (LR) images of different degradation levels, which significantly restricts their practical deployments on resource-limited devices. In this paper, we propose a novel Dynamic Channel Splitting scheme for efficient Real-world Image Super-Resolution, termed DCS-RISR. Specifically, we first introduce the light degradation prediction network to regress the degradation vector to simulate the real-world degradations, upon which the channel splitting vector is generated as the input for an efficient SR model. Then, a learnable octave convolution block is proposed to adaptively decide the channel splitting scale for low- and high-frequency features at each block, reducing computation overhead and memory cost by offering the large scale to low-frequency features and the small scale to the high ones. To further improve the RISR performance, Non-local regularization is employed to supplement the knowledge of patches from LR and HR subspace with free-computation inference. Extensive experiments demonstrate the effectiveness of DCS-RISR on different benchmark datasets. Our DCS-RISR not only achieves the best trade-off between computation/parameter and PSNR/SSIM metric, and also effectively handles real-world images with different degradation levels.
Unsupervised Out-of-Distribution Detection with Diffusion Inpainting
Feb 20, 2023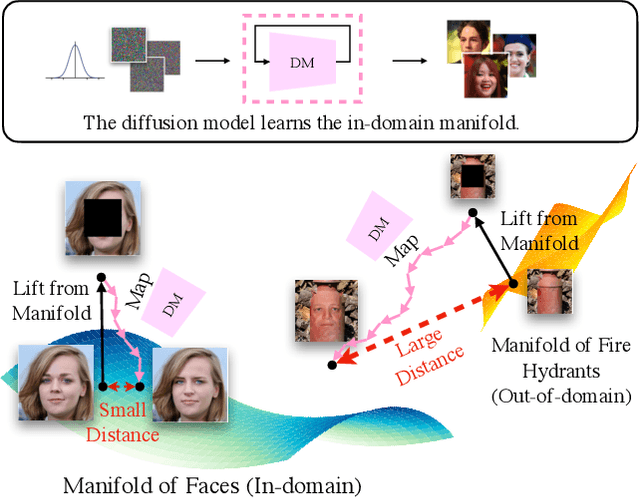
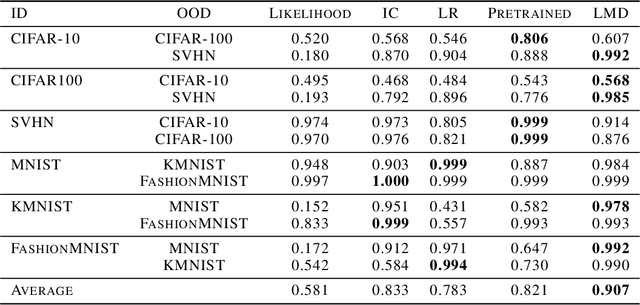
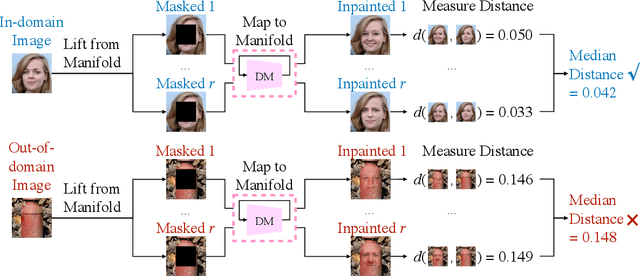

Unsupervised out-of-distribution detection (OOD) seeks to identify out-of-domain data by learning only from unlabeled in-domain data. We present a novel approach for this task - Lift, Map, Detect (LMD) - that leverages recent advancement in diffusion models. Diffusion models are one type of generative models. At their core, they learn an iterative denoising process that gradually maps a noisy image closer to their training manifolds. LMD leverages this intuition for OOD detection. Specifically, LMD lifts an image off its original manifold by corrupting it, and maps it towards the in-domain manifold with a diffusion model. For an out-of-domain image, the mapped image would have a large distance away from its original manifold, and LMD would identify it as OOD accordingly. We show through extensive experiments that LMD achieves competitive performance across a broad variety of datasets.
2nd Place Solution to Google Universal Image Embedding
Oct 19, 2022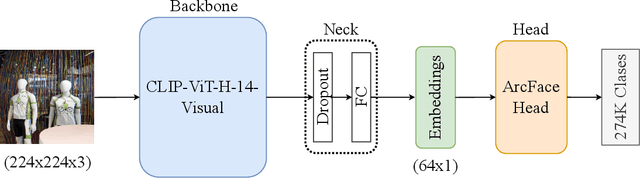
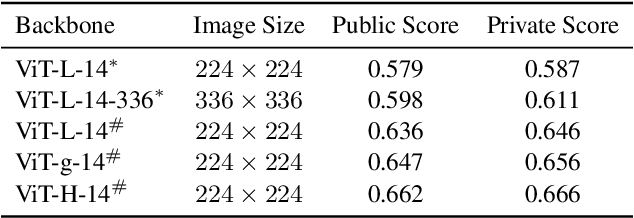

Image representations are a critical building block of computer vision applications. This paper presents the 2nd place solution to the Google Universal Image Embedding Competition, which is part of the ECCV2022 instance-level recognition workshops. We use the instance-level fine-grained image classification method to complete this competition. We focus on data building and processing, model structure, and training strategies. Finally, the solution scored 0.713 on the public leaderboard and 0.709 on the private leaderboard.
3D-Aware Object Localization using Gaussian Implicit Occupancy Function
Mar 03, 2023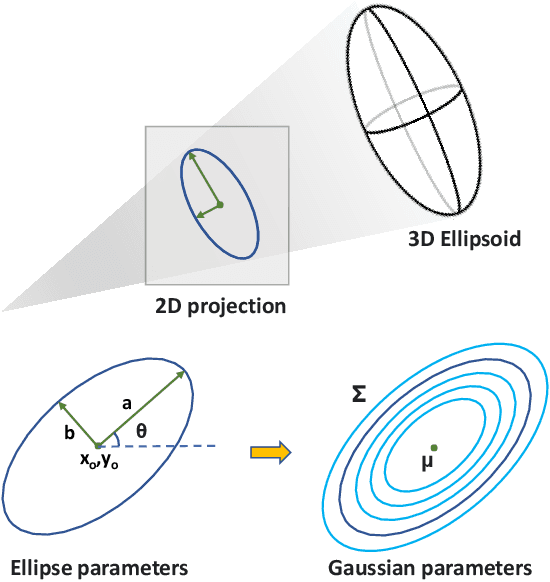

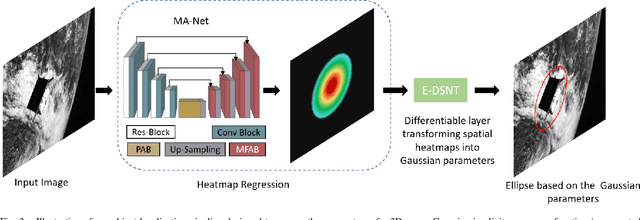

To automatically localize a target object in an image is crucial for many computer vision applications. Recently ellipse representations have been identified as an alternative to axis-aligned bounding boxes for object localization. This paper considers 3D-aware ellipse labels, i.e., which are projections of a 3D ellipsoidal approximation of the object in the images for 2D target localization. Such generic ellipsoidal models allow for handling coarsely known targets, and 3D-aware ellipse detections carry more geometric information about the object than traditional 3D-agnostic bounding box labels. We propose to have a new look at ellipse regression and replace the geometric ellipse parameters with the parameters of an implicit Gaussian distribution encoding object occupancy in the image. The models are trained to regress the values of this bivariate Gaussian distribution over the image pixels using a continuous statistical loss function. We introduce a novel non-trainable differentiable layer, E-DSNT, to extract the distribution parameters. Also, we describe how to readily generate consistent 3D-aware Gaussian occupancy parameters using only coarse dimensions of the target and relative pose labels. We extend three existing spacecraft pose estimation datasets with 3D-aware Gaussian occupancy labels to validate our hypothesis.
A Complex Quasi-Newton Proximal Method for Image Reconstruction in Compressed Sensing MRI
Mar 05, 2023
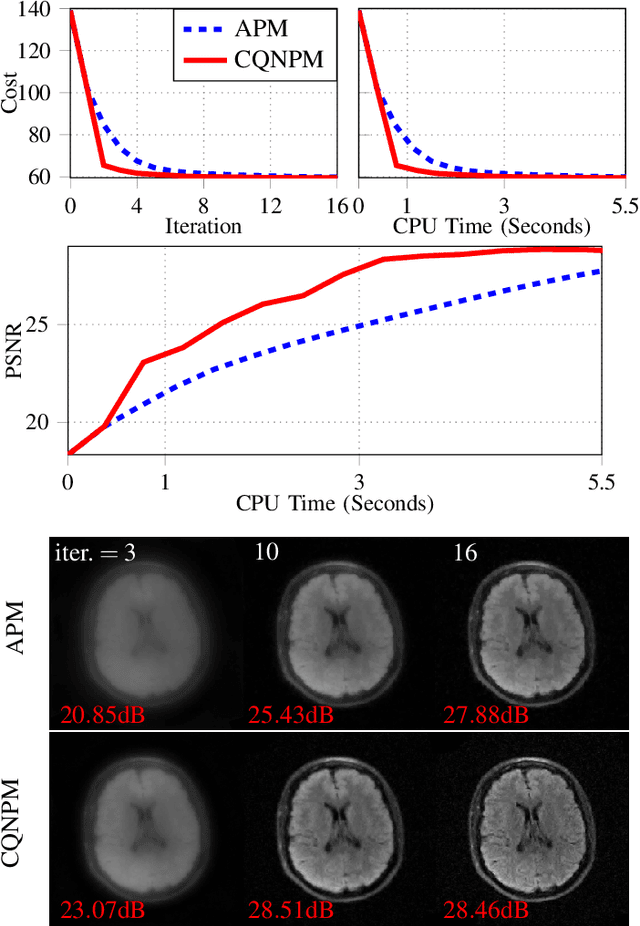
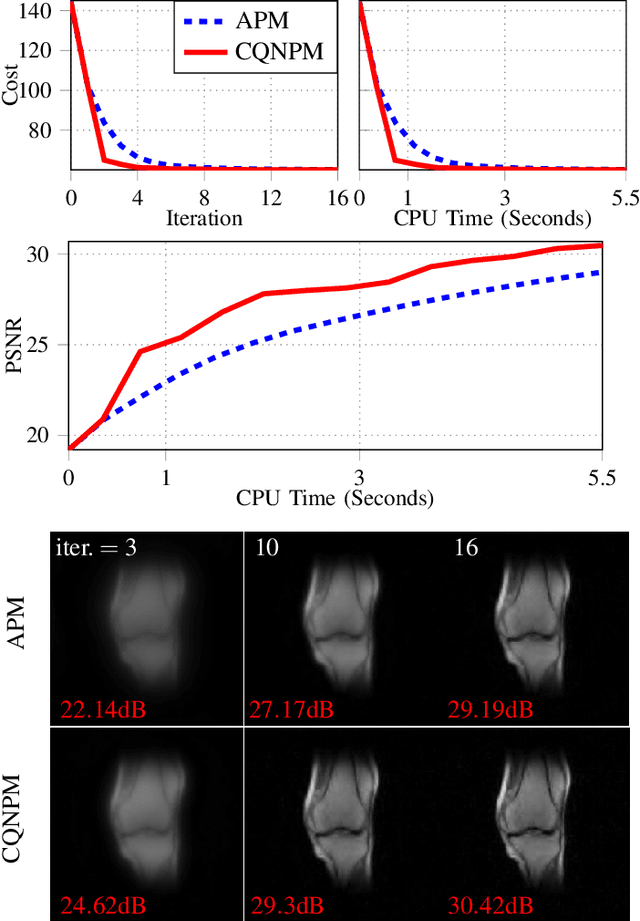
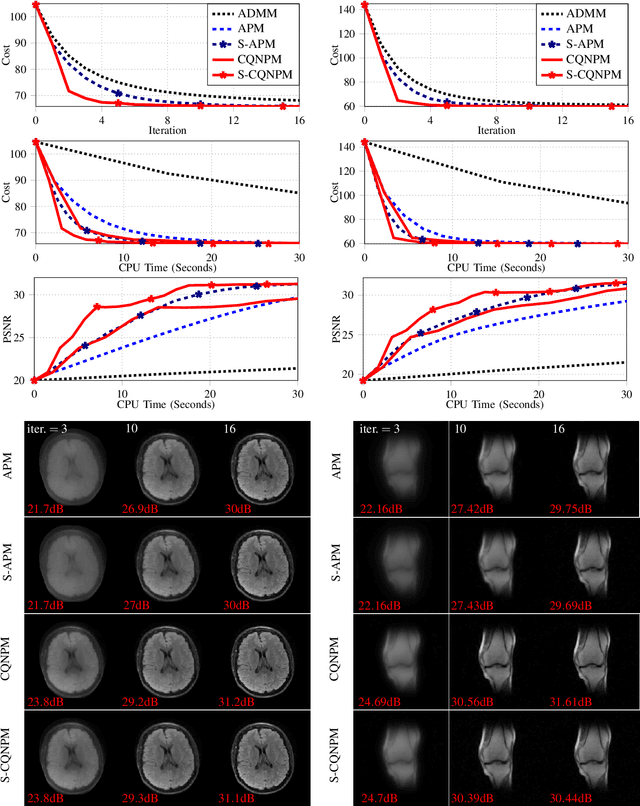
Model-based methods are widely used for reconstruction in compressed sensing (CS) magnetic resonance imaging (MRI), using priors to describe the images of interest. The reconstruction process is equivalent to solving a composite optimization problem. Accelerated proximal methods (APMs) are very popular approaches for such problems. This paper proposes a complex quasi-Newton proximal method (CQNPM) for the wavelet and total variation based CS MRI reconstruction. Compared with APMs, CQNPM requires fewer iterations to converge but needs to compute a more challenging proximal mapping called weighted proximal mapping (WPM). To make CQNPM more practical, we propose efficient methods to solve the related WPM. Numerical experiments demonstrate the effectiveness and efficiency of CQNPM.