 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
PromptIQA: Boosting the Performance and Generalization for No-Reference Image Quality Assessment via Prompts
Mar 08, 2024
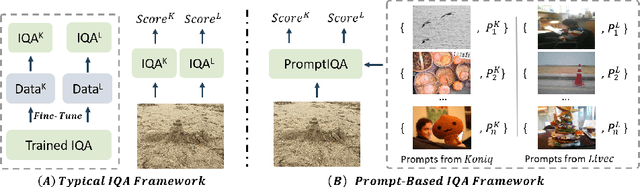
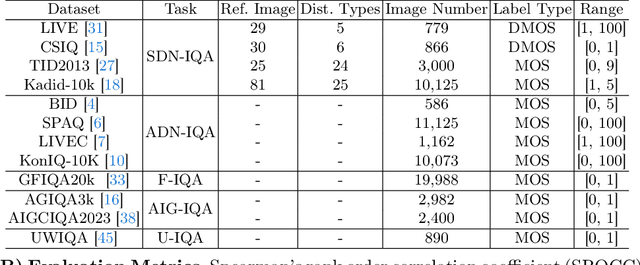
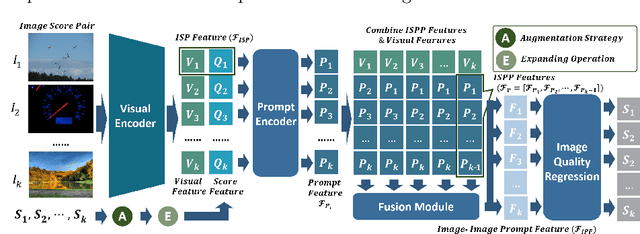
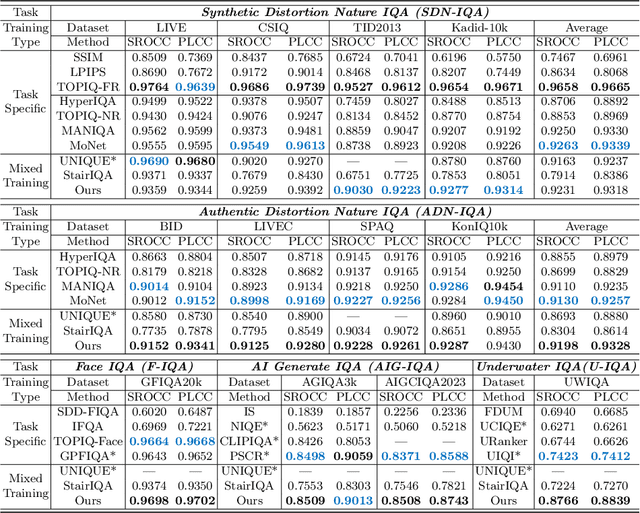
Due to the diversity of assessment requirements in various application scenarios for the IQA task, existing IQA methods struggle to directly adapt to these varied requirements after training. Thus, when facing new requirements, a typical approach is fine-tuning these models on datasets specifically created for those requirements. However, it is time-consuming to establish IQA datasets. In this work, we propose a Prompt-based IQA (PromptIQA) that can directly adapt to new requirements without fine-tuning after training. On one hand, it utilizes a short sequence of Image-Score Pairs (ISP) as prompts for targeted predictions, which significantly reduces the dependency on the data requirements. On the other hand, PromptIQA is trained on a mixed dataset with two proposed data augmentation strategies to learn diverse requirements, thus enabling it to effectively adapt to new requirements. Experiments indicate that the PromptIQA outperforms SOTA methods with higher performance and better generalization. The code will be available.
Modeling the Label Distributions for Weakly-Supervised Semantic Segmentation
Mar 20, 2024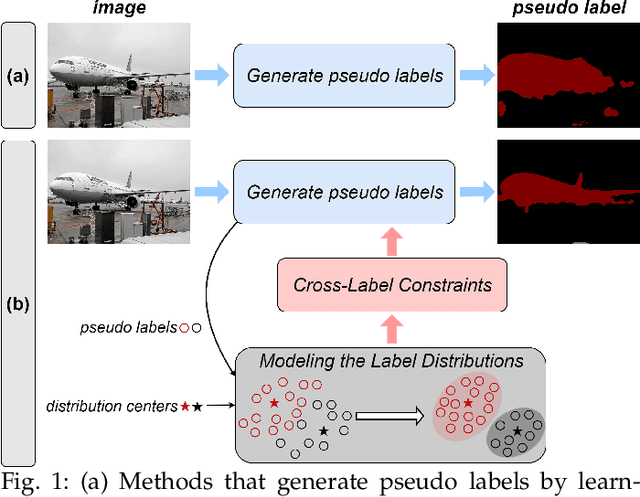
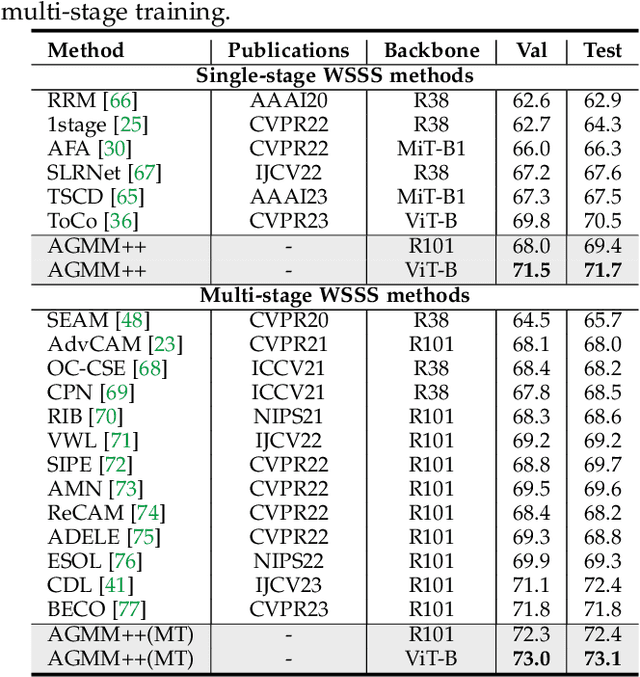
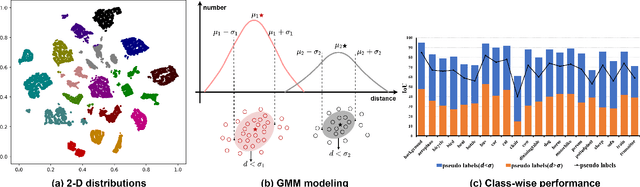
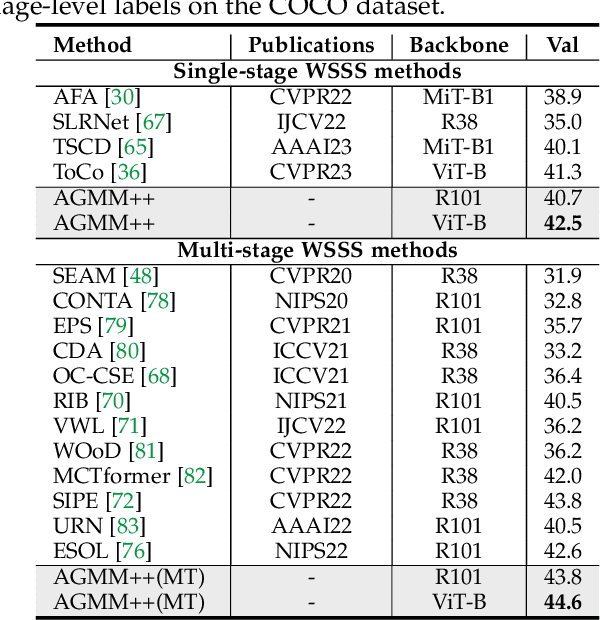
Weakly-Supervised Semantic Segmentation (WSSS) aims to train segmentation models by weak labels, which is receiving significant attention due to its low annotation cost. Existing approaches focus on generating pseudo labels for supervision while largely ignoring to leverage the inherent semantic correlation among different pseudo labels. We observe that pseudo-labeled pixels that are close to each other in the feature space are more likely to share the same class, and those closer to the distribution centers tend to have higher confidence. Motivated by this, we propose to model the underlying label distributions and employ cross-label constraints to generate more accurate pseudo labels. In this paper, we develop a unified WSSS framework named Adaptive Gaussian Mixtures Model, which leverages a GMM to model the label distributions. Specifically, we calculate the feature distribution centers of pseudo-labeled pixels and build the GMM by measuring the distance between the centers and each pseudo-labeled pixel. Then, we introduce an Online Expectation-Maximization (OEM) algorithm and a novel maximization loss to optimize the GMM adaptively, aiming to learn more discriminative decision boundaries between different class-wise Gaussian mixtures. Based on the label distributions, we leverage the GMM to generate high-quality pseudo labels for more reliable supervision. Our framework is capable of solving different forms of weak labels: image-level labels, points, scribbles, blocks, and bounding-boxes. Extensive experiments on PASCAL, COCO, Cityscapes, and ADE20K datasets demonstrate that our framework can effectively provide more reliable supervision and outperform the state-of-the-art methods under all settings. Code will be available at https://github.com/Luffy03/AGMM-SASS.
Controllable Generation with Text-to-Image Diffusion Models: A Survey
Mar 07, 2024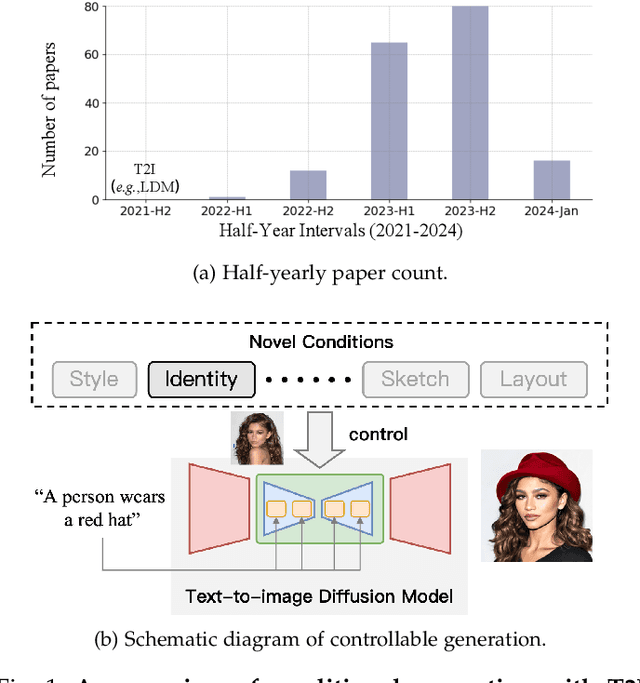
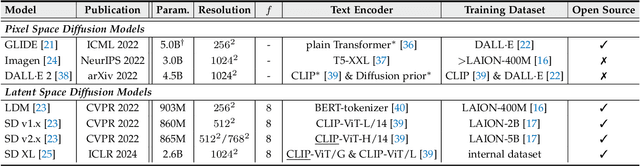
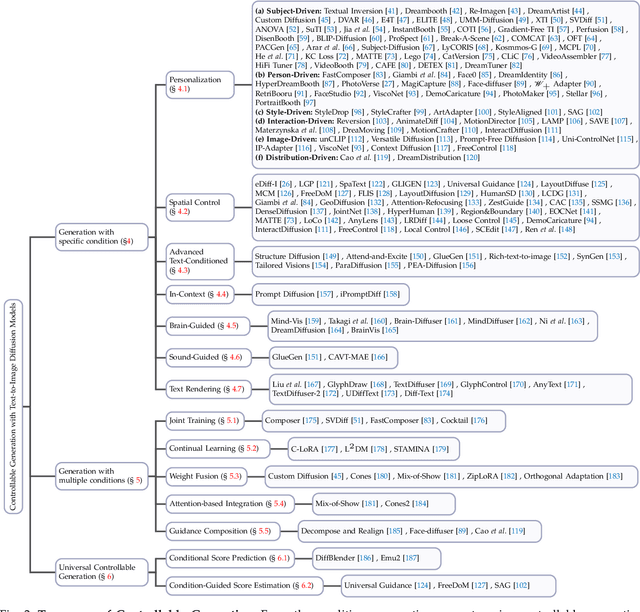
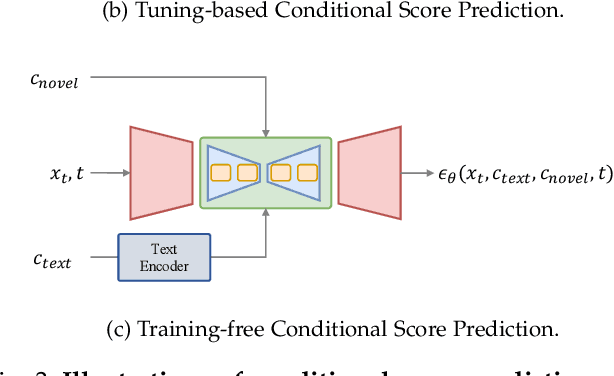
In the rapidly advancing realm of visual generation, diffusion models have revolutionized the landscape, marking a significant shift in capabilities with their impressive text-guided generative functions. However, relying solely on text for conditioning these models does not fully cater to the varied and complex requirements of different applications and scenarios. Acknowledging this shortfall, a variety of studies aim to control pre-trained text-to-image (T2I) models to support novel conditions. In this survey, we undertake a thorough review of the literature on controllable generation with T2I diffusion models, covering both the theoretical foundations and practical advancements in this domain. Our review begins with a brief introduction to the basics of denoising diffusion probabilistic models (DDPMs) and widely used T2I diffusion models. We then reveal the controlling mechanisms of diffusion models, theoretically analyzing how novel conditions are introduced into the denoising process for conditional generation. Additionally, we offer a detailed overview of research in this area, organizing it into distinct categories from the condition perspective: generation with specific conditions, generation with multiple conditions, and universal controllable generation. For an exhaustive list of the controllable generation literature surveyed, please refer to our curated repository at \url{https://github.com/PRIV-Creation/Awesome-Controllable-T2I-Diffusion-Models}.
Visual Inertial Odometry using Focal Plane Binary Features (BIT-VIO)
Mar 14, 2024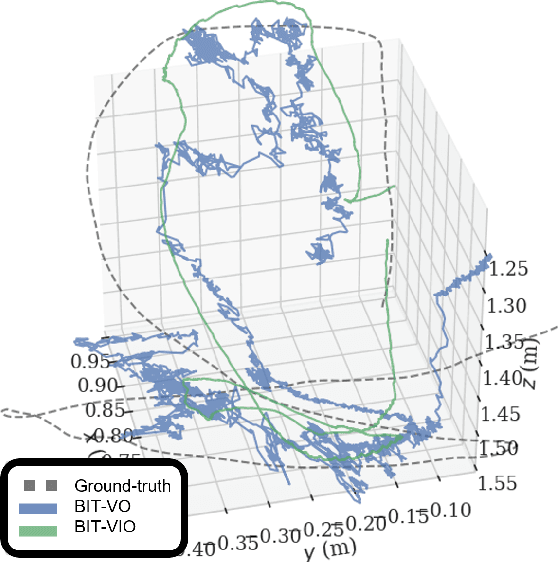
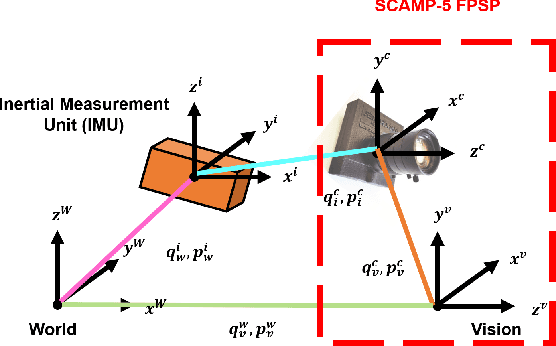
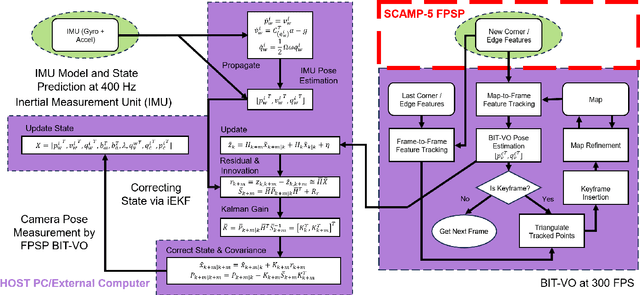
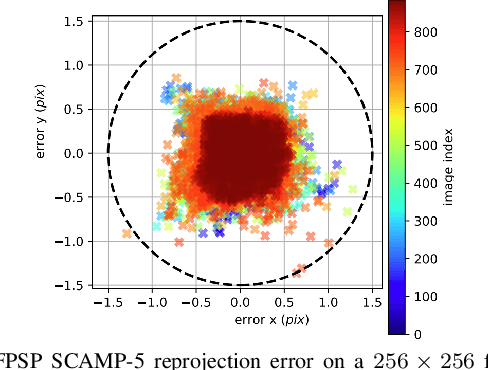
Focal-Plane Sensor-Processor Arrays (FPSP)s are an emerging technology that can execute vision algorithms directly on the image sensor. Unlike conventional cameras, FPSPs perform computation on the image plane -- at individual pixels -- enabling high frame rate image processing while consuming low power, making them ideal for mobile robotics. FPSPs, such as the SCAMP-5, use parallel processing and are based on the Single Instruction Multiple Data (SIMD) paradigm. In this paper, we present BIT-VIO, the first Visual Inertial Odometry (VIO) which utilises SCAMP-5.BIT-VIO is a loosely-coupled iterated Extended Kalman Filter (iEKF) which fuses together the visual odometry running fast at 300 FPS with predictions from 400 Hz IMU measurements to provide accurate and smooth trajectories.
TripoSR: Fast 3D Object Reconstruction from a Single Image
Mar 04, 2024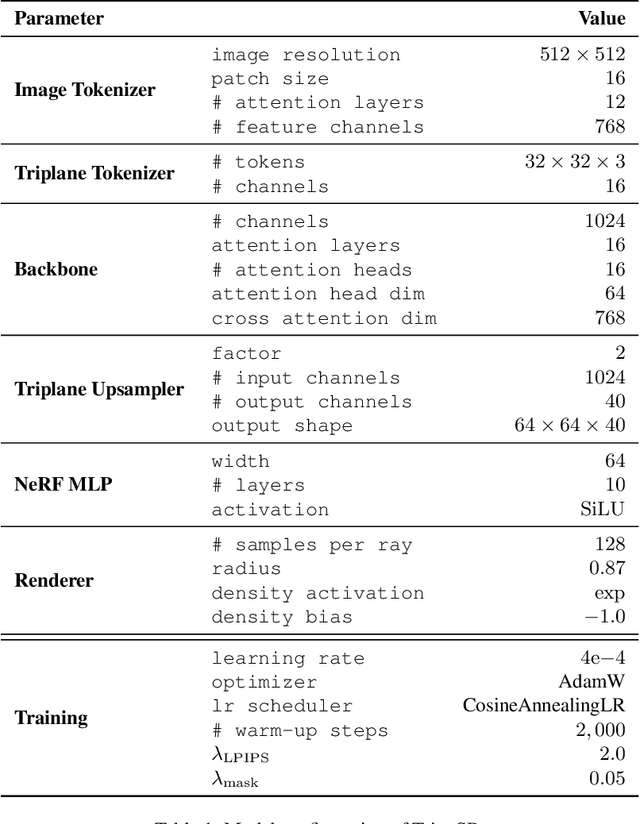
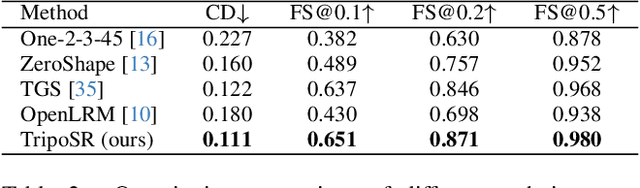
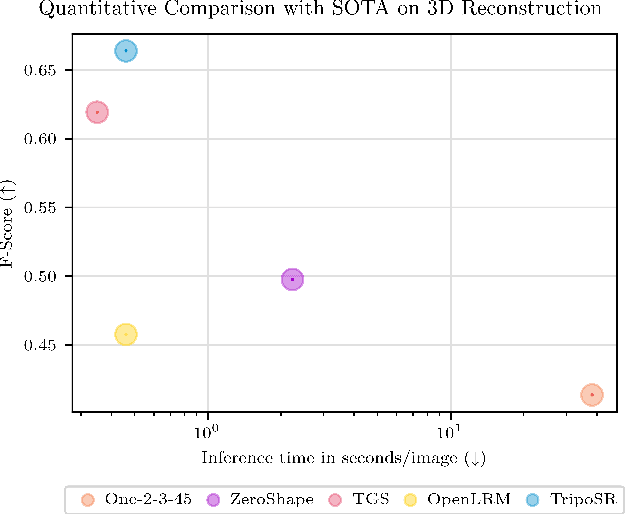
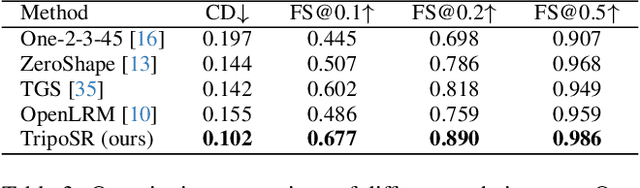
This technical report introduces TripoSR, a 3D reconstruction model leveraging transformer architecture for fast feed-forward 3D generation, producing 3D mesh from a single image in under 0.5 seconds. Building upon the LRM network architecture, TripoSR integrates substantial improvements in data processing, model design, and training techniques. Evaluations on public datasets show that TripoSR exhibits superior performance, both quantitatively and qualitatively, compared to other open-source alternatives. Released under the MIT license, TripoSR is intended to empower researchers, developers, and creatives with the latest advancements in 3D generative AI.
VIXEN: Visual Text Comparison Network for Image Difference Captioning
Feb 29, 2024We present VIXEN - a technique that succinctly summarizes in text the visual differences between a pair of images in order to highlight any content manipulation present. Our proposed network linearly maps image features in a pairwise manner, constructing a soft prompt for a pretrained large language model. We address the challenge of low volume of training data and lack of manipulation variety in existing image difference captioning (IDC) datasets by training on synthetically manipulated images from the recent InstructPix2Pix dataset generated via prompt-to-prompt editing framework. We augment this dataset with change summaries produced via GPT-3. We show that VIXEN produces state-of-the-art, comprehensible difference captions for diverse image contents and edit types, offering a potential mitigation against misinformation disseminated via manipulated image content. Code and data are available at http://github.com/alexblck/vixen
Edge-guided Low-light Image Enhancement with Inertial Bregman Alternating Linearized Minimization
Mar 02, 2024
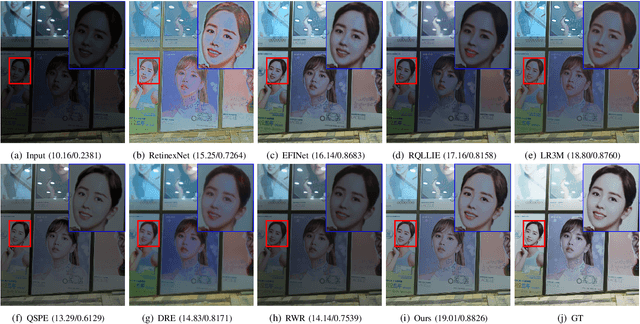


Prior-based methods for low-light image enhancement often face challenges in extracting available prior information from dim images. To overcome this limitation, we introduce a simple yet effective Retinex model with the proposed edge extraction prior. More specifically, we design an edge extraction network to capture the fine edge features from the low-light image directly. Building upon the Retinex theory, we decompose the low-light image into its illumination and reflectance components and introduce an edge-guided Retinex model for enhancing low-light images. To solve the proposed model, we propose a novel inertial Bregman alternating linearized minimization algorithm. This algorithm addresses the optimization problem associated with the edge-guided Retinex model, enabling effective enhancement of low-light images. Through rigorous theoretical analysis, we establish the convergence properties of the algorithm. Besides, we prove that the proposed algorithm converges to a stationary point of the problem through nonconvex optimization theory. Furthermore, extensive experiments are conducted on multiple real-world low-light image datasets to demonstrate the efficiency and superiority of the proposed scheme.
InTeX: Interactive Text-to-texture Synthesis via Unified Depth-aware Inpainting
Mar 18, 2024
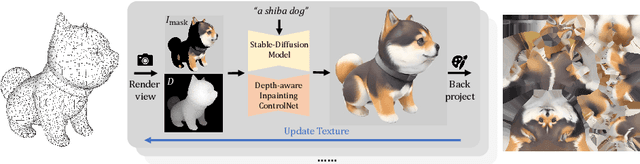


Text-to-texture synthesis has become a new frontier in 3D content creation thanks to the recent advances in text-to-image models. Existing methods primarily adopt a combination of pretrained depth-aware diffusion and inpainting models, yet they exhibit shortcomings such as 3D inconsistency and limited controllability. To address these challenges, we introduce InteX, a novel framework for interactive text-to-texture synthesis. 1) InteX includes a user-friendly interface that facilitates interaction and control throughout the synthesis process, enabling region-specific repainting and precise texture editing. 2) Additionally, we develop a unified depth-aware inpainting model that integrates depth information with inpainting cues, effectively mitigating 3D inconsistencies and improving generation speed. Through extensive experiments, our framework has proven to be both practical and effective in text-to-texture synthesis, paving the way for high-quality 3D content creation.
End-To-End Underwater Video Enhancement: Dataset and Model
Mar 18, 2024
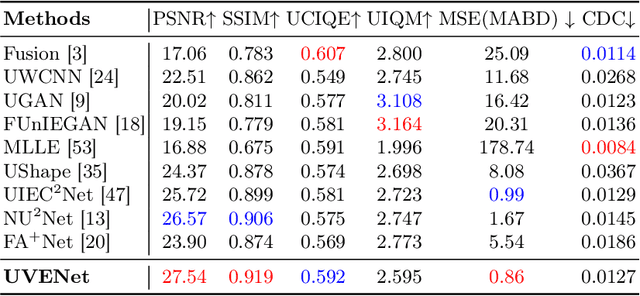
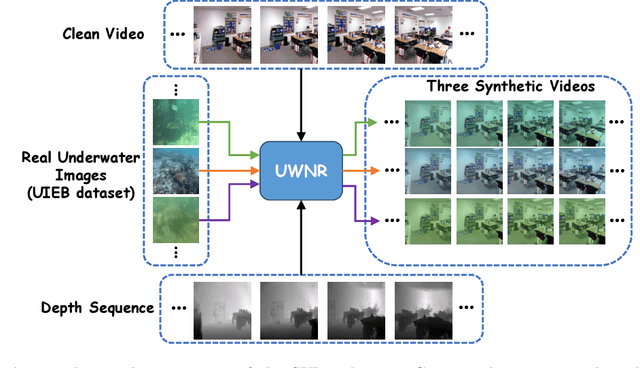
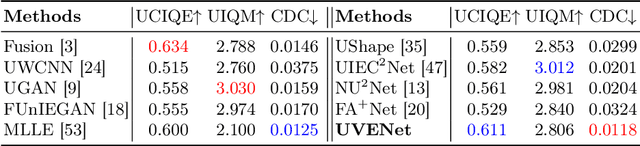
Underwater video enhancement (UVE) aims to improve the visibility and frame quality of underwater videos, which has significant implications for marine research and exploration. However, existing methods primarily focus on developing image enhancement algorithms to enhance each frame independently. There is a lack of supervised datasets and models specifically tailored for UVE tasks. To fill this gap, we construct the Synthetic Underwater Video Enhancement (SUVE) dataset, comprising 840 diverse underwater-style videos paired with ground-truth reference videos. Based on this dataset, we train a novel underwater video enhancement model, UVENet, which utilizes inter-frame relationships to achieve better enhancement performance. Through extensive experiments on both synthetic and real underwater videos, we demonstrate the effectiveness of our approach. This study represents the first comprehensive exploration of UVE to our knowledge. The code is available at https://anonymous.4open.science/r/UVENet.
Self and Mixed Supervision to Improve Training Labels for Multi-Class Medical Image Segmentation
Mar 06, 2024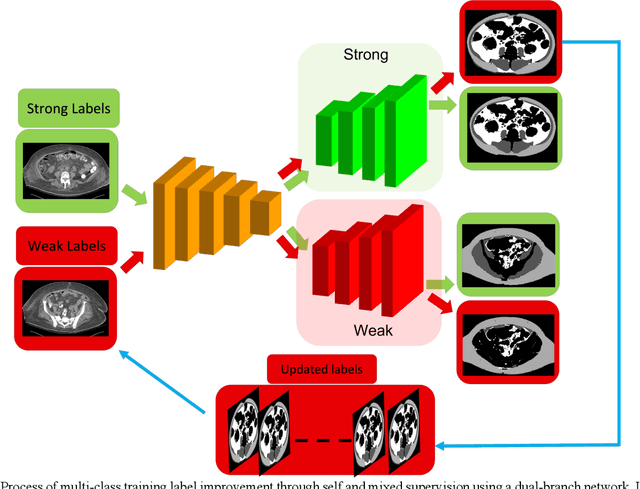
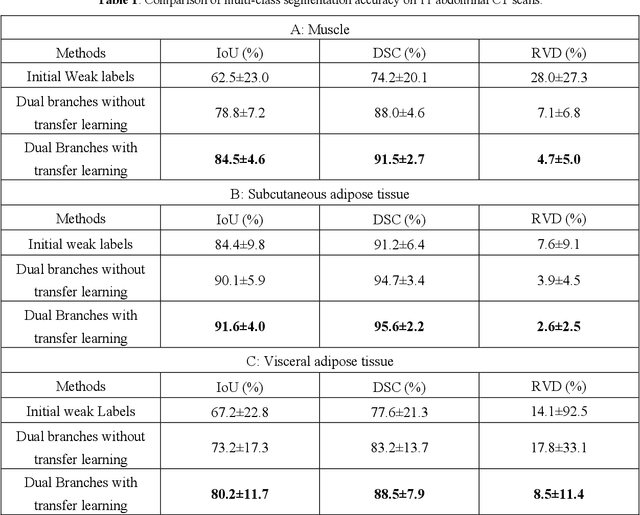
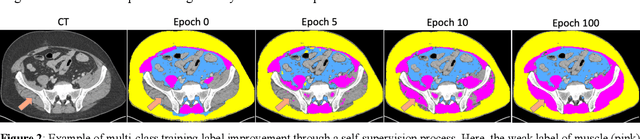
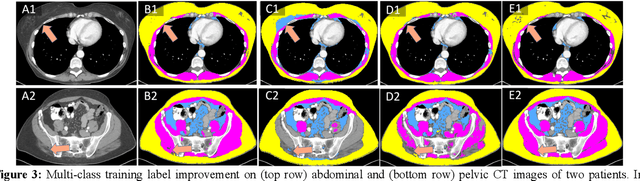
Accurate training labels are a key component for multi-class medical image segmentation. Their annotation is costly and time-consuming because it requires domain expertise. This work aims to develop a dual-branch network and automatically improve training labels for multi-class image segmentation. Transfer learning is used to train the network and improve inaccurate weak labels sequentially. The dual-branch network is first trained by weak labels alone to initialize model parameters. After the network is stabilized, the shared encoder is frozen, and strong and weak decoders are fine-tuned by strong and weak labels together. The accuracy of weak labels is iteratively improved in the fine-tuning process. The proposed method was applied to a three-class segmentation of muscle, subcutaneous and visceral adipose tissue on abdominal CT scans. Validation results on 11 patients showed that the accuracy of training labels was statistically significantly improved, with the Dice similarity coefficient of muscle, subcutaneous and visceral adipose tissue increased from 74.2% to 91.5%, 91.2% to 95.6%, and 77.6% to 88.5%, respectively (p<0.05). In comparison with our earlier method, the label accuracy was also significantly improved (p<0.05). These experimental results suggested that the combination of the dual-branch network and transfer learning is an efficient means to improve training labels for multi-class segmentation.