 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DeepLSD: Line Segment Detection and Refinement with Deep Image Gradients
Dec 15, 2022

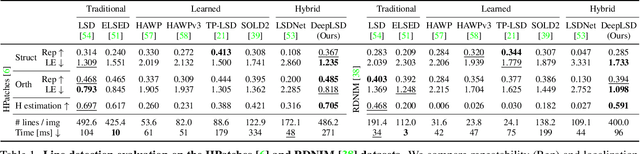
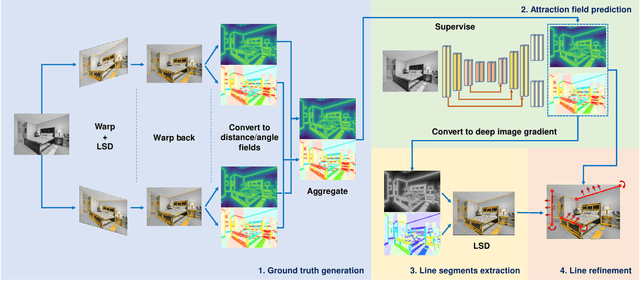
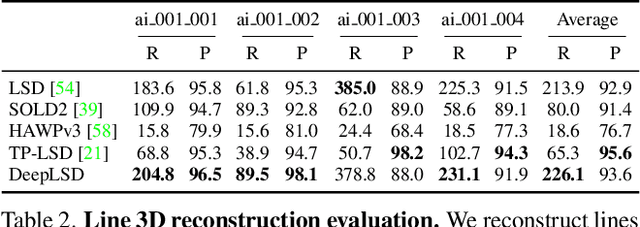
Line segments are ubiquitous in our human-made world and are increasingly used in vision tasks. They are complementary to feature points thanks to their spatial extent and the structural information they provide. Traditional line detectors based on the image gradient are extremely fast and accurate, but lack robustness in noisy images and challenging conditions. Their learned counterparts are more repeatable and can handle challenging images, but at the cost of a lower accuracy and a bias towards wireframe lines. We propose to combine traditional and learned approaches to get the best of both worlds: an accurate and robust line detector that can be trained in the wild without ground truth lines. Our new line segment detector, DeepLSD, processes images with a deep network to generate a line attraction field, before converting it to a surrogate image gradient magnitude and angle, which is then fed to any existing handcrafted line detector. Additionally, we propose a new optimization tool to refine line segments based on the attraction field and vanishing points. This refinement improves the accuracy of current deep detectors by a large margin. We demonstrate the performance of our method on low-level line detection metrics, as well as on several downstream tasks using multiple challenging datasets. The source code and models are available at https://github.com/cvg/DeepLSD.
Person Text-Image Matching via Text-Feature Interpretability Embedding and External Attack Node Implantation
Nov 19, 2022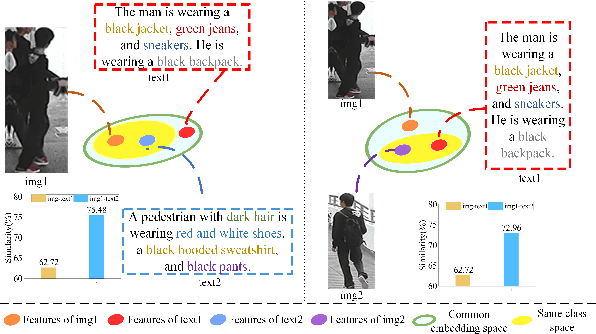
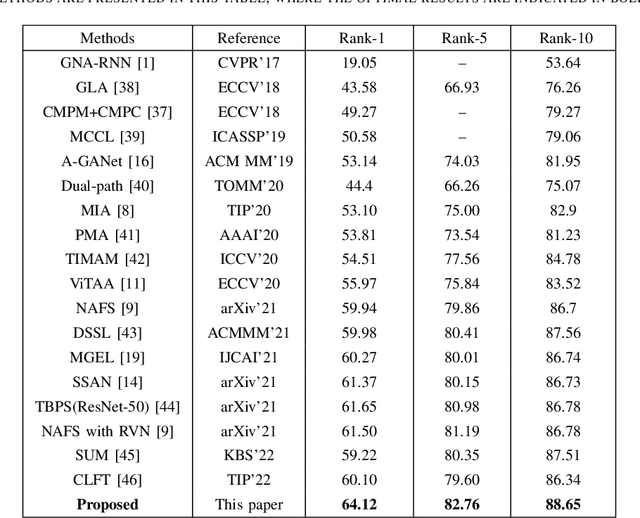
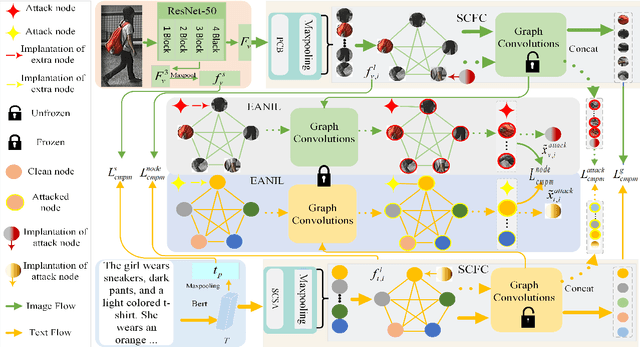
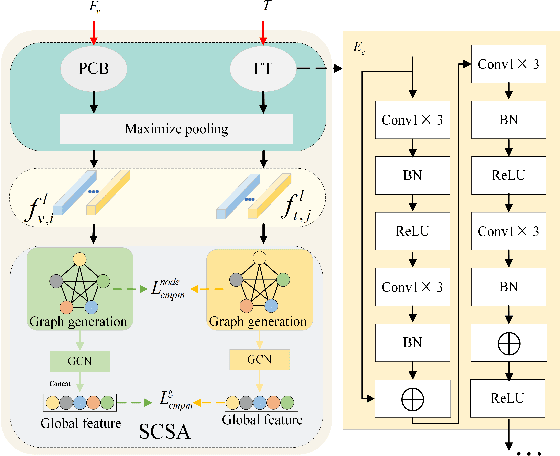
Person text-image matching, also known as text based person search, aims to retrieve images of specific pedestrians using text descriptions. Although person text-image matching has made great research progress, existing methods still face two challenges. First, the lack of interpretability of text features makes it challenging to effectively align them with their corresponding image features. Second, the same pedestrian image often corresponds to multiple different text descriptions, and a single text description can correspond to multiple different images of the same identity. The diversity of text descriptions and images makes it difficult for a network to extract robust features that match the two modalities. To address these problems, we propose a person text-image matching method by embedding text-feature interpretability and an external attack node. Specifically, we improve the interpretability of text features by providing them with consistent semantic information with image features to achieve the alignment of text and describe image region features.To address the challenges posed by the diversity of text and the corresponding person images, we treat the variation caused by diversity to features as caused by perturbation information and propose a novel adversarial attack and defense method to solve it. In the model design, graph convolution is used as the basic framework for feature representation and the adversarial attacks caused by text and image diversity on feature extraction is simulated by implanting an additional attack node in the graph convolution layer to improve the robustness of the model against text and image diversity. Extensive experiments demonstrate the effectiveness and superiority of text-pedestrian image matching over existing methods. The source code of the method is published at
Direct Inversion: Optimization-Free Text-Driven Real Image Editing with Diffusion Models
Nov 15, 2022

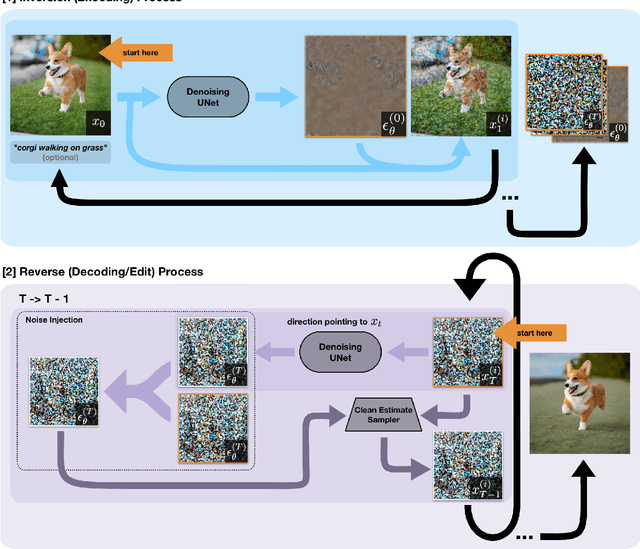
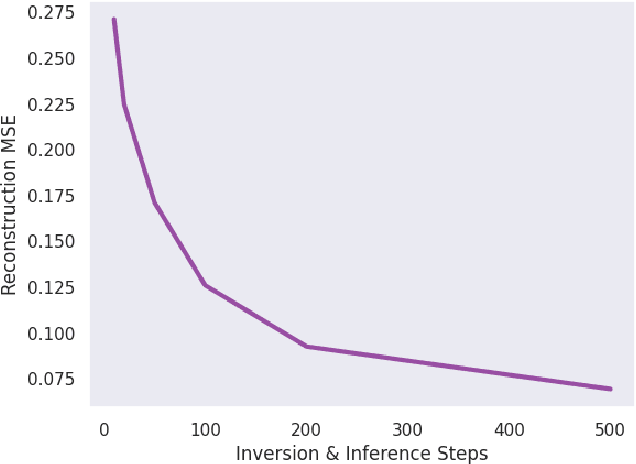
With the rise of large, publicly-available text-to-image diffusion models, text-guided real image editing has garnered much research attention recently. Existing methods tend to either rely on some form of per-instance or per-task fine-tuning and optimization, require multiple novel views, or they inherently entangle preservation of real image identity, semantic coherence, and faithfulness to text guidance. In this paper, we propose an optimization-free and zero fine-tuning framework that applies complex and non-rigid edits to a single real image via a text prompt, avoiding all the pitfalls described above. Using widely-available generic pre-trained text-to-image diffusion models, we demonstrate the ability to modulate pose, scene, background, style, color, and even racial identity in an extremely flexible manner through a single target text detailing the desired edit. Furthermore, our method, which we name $\textit{Direct Inversion}$, proposes multiple intuitively configurable hyperparameters to allow for a wide range of types and extents of real image edits. We prove our method's efficacy in producing high-quality, diverse, semantically coherent, and faithful real image edits through applying it on a variety of inputs for a multitude of tasks. We also formalize our method in well-established theory, detail future experiments for further improvement, and compare against state-of-the-art attempts.
Normal-guided Garment UV Prediction for Human Re-texturing
Mar 11, 2023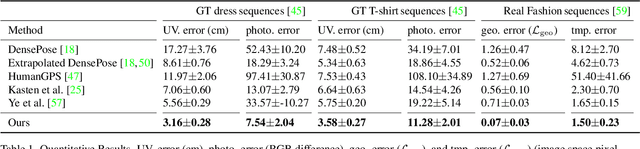
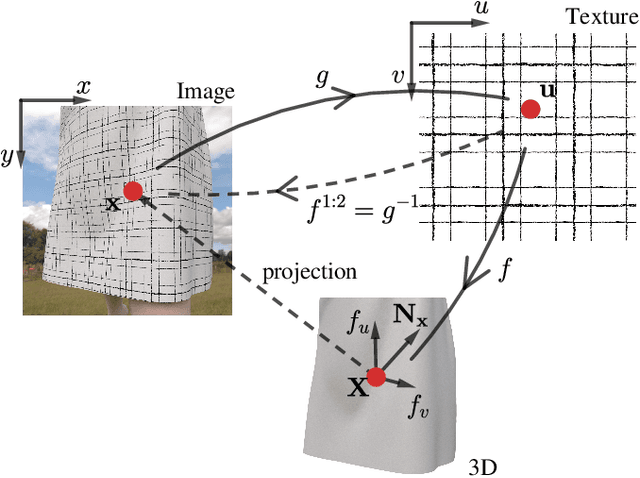
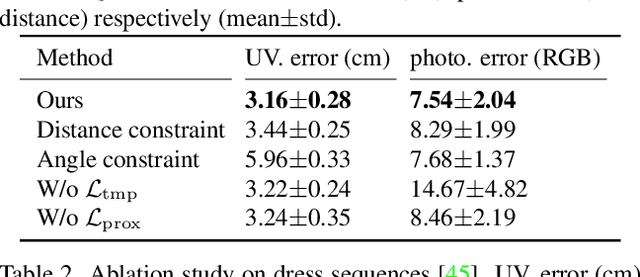

Clothes undergo complex geometric deformations, which lead to appearance changes. To edit human videos in a physically plausible way, a texture map must take into account not only the garment transformation induced by the body movements and clothes fitting, but also its 3D fine-grained surface geometry. This poses, however, a new challenge of 3D reconstruction of dynamic clothes from an image or a video. In this paper, we show that it is possible to edit dressed human images and videos without 3D reconstruction. We estimate a geometry aware texture map between the garment region in an image and the texture space, a.k.a, UV map. Our UV map is designed to preserve isometry with respect to the underlying 3D surface by making use of the 3D surface normals predicted from the image. Our approach captures the underlying geometry of the garment in a self-supervised way, requiring no ground truth annotation of UV maps and can be readily extended to predict temporally coherent UV maps. We demonstrate that our method outperforms the state-of-the-art human UV map estimation approaches on both real and synthetic data.
DETA: Denoised Task Adaptation for Few-Shot Learning
Mar 11, 2023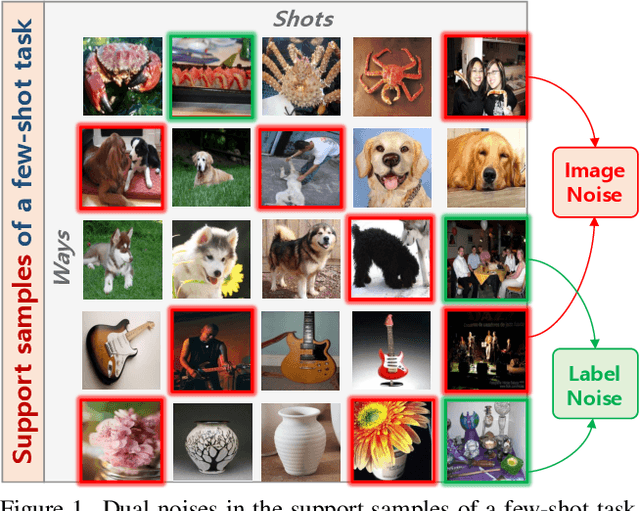

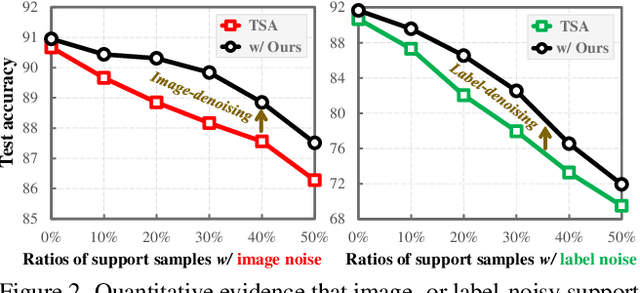
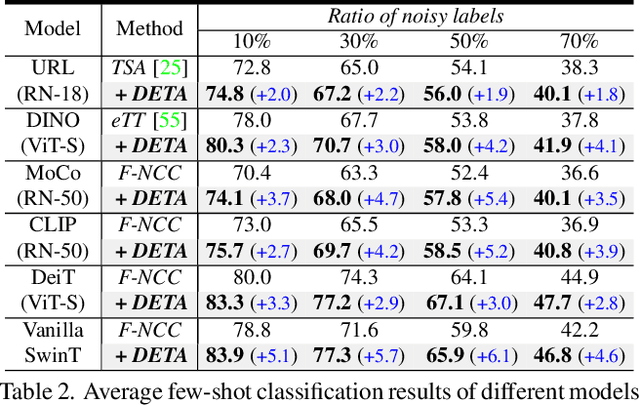
Test-time task adaptation in few-shot learning aims to adapt a pre-trained task-agnostic model for capturing taskspecific knowledge of the test task, rely only on few-labeled support samples. Previous approaches generally focus on developing advanced algorithms to achieve the goal, while neglecting the inherent problems of the given support samples. In fact, with only a handful of samples available, the adverse effect of either the image noise (a.k.a. X-noise) or the label noise (a.k.a. Y-noise) from support samples can be severely amplified. To address this challenge, in this work we propose DEnoised Task Adaptation (DETA), a first, unified image- and label-denoising framework orthogonal to existing task adaptation approaches. Without extra supervision, DETA filters out task-irrelevant, noisy representations by taking advantage of both global visual information and local region details of support samples. On the challenging Meta-Dataset, DETA consistently improves the performance of a broad spectrum of baseline methods applied on various pre-trained models. Notably, by tackling the overlooked image noise in Meta-Dataset, DETA establishes new state-of-the-art results. Code is released at https://github.com/nobody-1617/DETA.
Lafite2: Few-shot Text-to-Image Generation
Oct 25, 2022
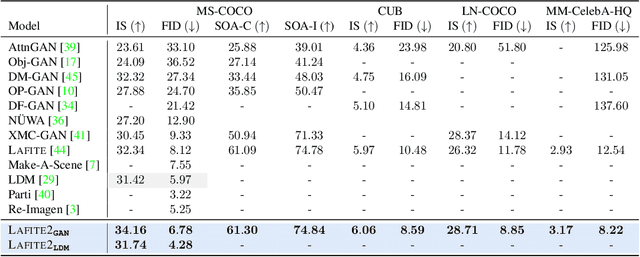
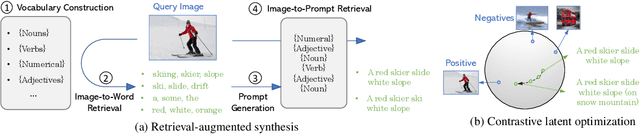
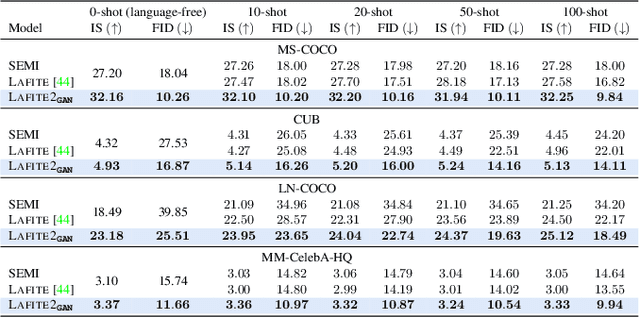
Text-to-image generation models have progressed considerably in recent years, which can now generate impressive realistic images from arbitrary text. Most of such models are trained on web-scale image-text paired datasets, which may not be affordable for many researchers. In this paper, we propose a novel method for pre-training text-to-image generation model on image-only datasets. It considers a retrieval-then-optimization procedure to synthesize pseudo text features: for a given image, relevant pseudo text features are first retrieved, then optimized for better alignment. The low requirement of the proposed method yields high flexibility and usability: it can be beneficial to a wide range of settings, including the few-shot, semi-supervised and fully-supervised learning; it can be applied on different models including generative adversarial networks (GANs) and diffusion models. Extensive experiments illustrate the effectiveness of the proposed method. On MS-COCO dataset, our GAN model obtains Fr\'echet Inception Distance (FID) of 6.78 which is the new state-of-the-art (SoTA) of GANs under fully-supervised setting. Our diffusion model obtains FID of 8.42 and 4.28 on zero-shot and supervised setting respectively, which are competitive to SoTA diffusion models with a much smaller model size.
Joint Multi-Echo/Respiratory Motion-Resolved Compressed Sensing Reconstruction of Free-Breathing Non-Cartesian Abdominal MRI
Apr 03, 2023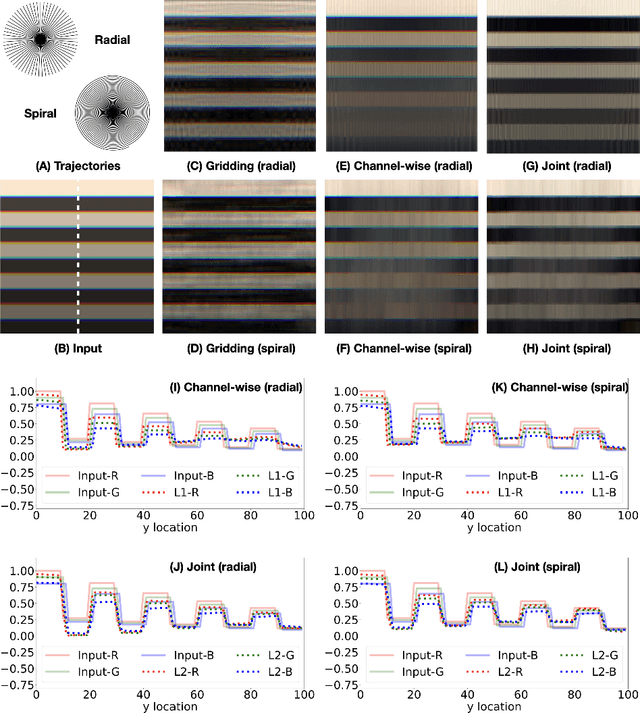
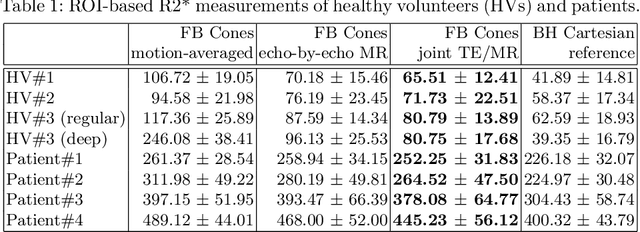
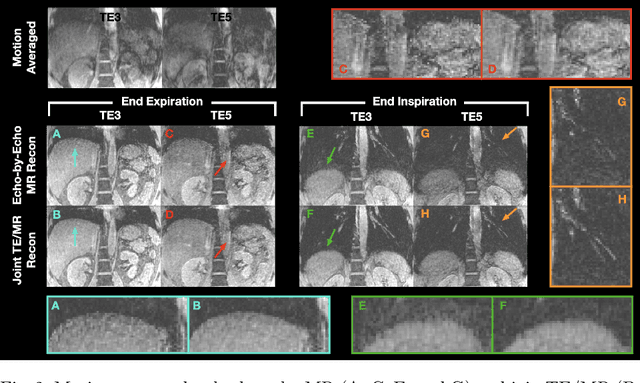
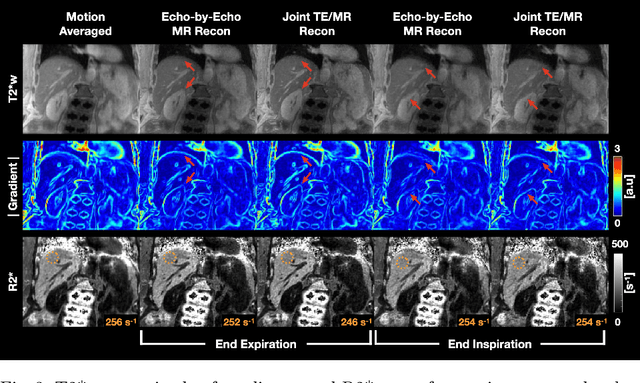
We propose a novel respiratory motion-resolved MR image reconstruction method that jointly treats multi-echo k-space raw data. Continuously acquired non-Cartesian multi-echo/multi-coil k-space data with free breathing are sorted/binned into the motion states from end-expiratory to end-inspiratory phases based on a respiratory motion signal. Temporal total variation applied to the motion state dimension of each echo is then coupled in the $\ell_2$ sense for joint reconstruction of the multiple echoes. Reconstructed source images of the proposed method are compared with conventional echo-by-echo motion-resolved reconstruction, and R2* of the proposed and echo-by-echo methods are compared with respect to a clinical reference. We demonstrate that inconsistency between echoes is successfully suppressed in the proposed joint reconstruction method, producing high-quality source images and R2* measurements compared to clinical reference.
Multi PILOT: Learned Feasible Multiple Acquisition Trajectories for Dynamic MRI
Mar 23, 2023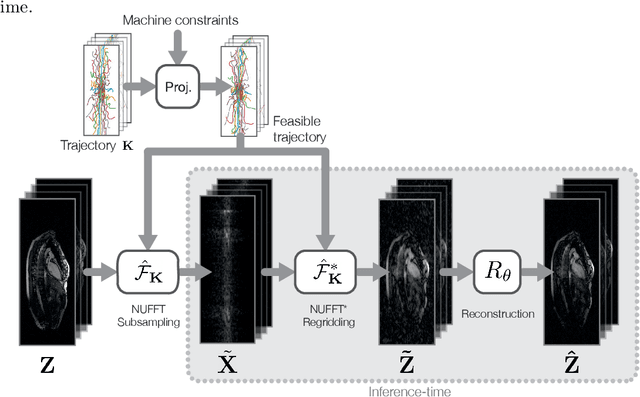
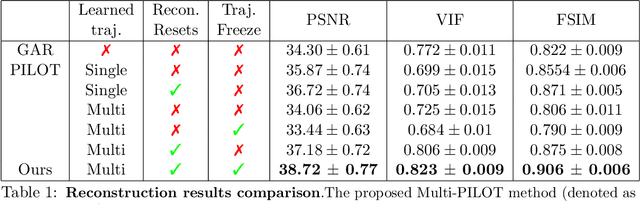
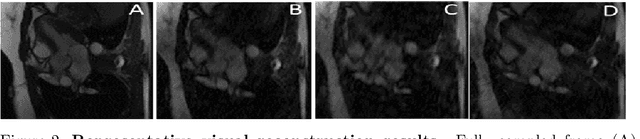
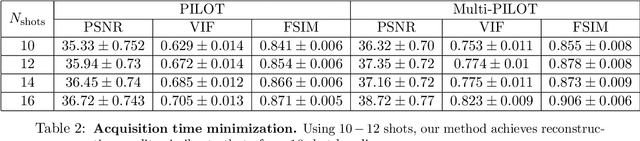
Dynamic Magnetic Resonance Imaging (MRI) is known to be a powerful and reliable technique for the dynamic imaging of internal organs and tissues, making it a leading diagnostic tool. A major difficulty in using MRI in this setting is the relatively long acquisition time (and, hence, increased cost) required for imaging in high spatio-temporal resolution, leading to the appearance of related motion artifacts and decrease in resolution. Compressed Sensing (CS) techniques have become a common tool to reduce MRI acquisition time by subsampling images in the k-space according to some acquisition trajectory. Several studies have particularly focused on applying deep learning techniques to learn these acquisition trajectories in order to attain better image reconstruction, rather than using some predefined set of trajectories. To the best of our knowledge, learning acquisition trajectories has been only explored in the context of static MRI. In this study, we consider acquisition trajectory learning in the dynamic imaging setting. We design an end-to-end pipeline for the joint optimization of multiple per-frame acquisition trajectories along with a reconstruction neural network, and demonstrate improved image reconstruction quality in shorter acquisition times. The code for reproducing all experiments is accessible at https://github.com/tamirshor7/MultiPILOT.
A Bag-of-Prototypes Representation for Dataset-Level Applications
Mar 23, 2023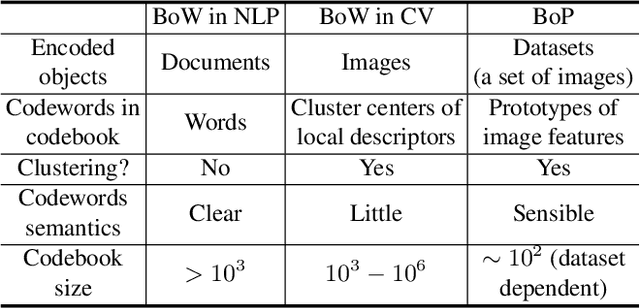
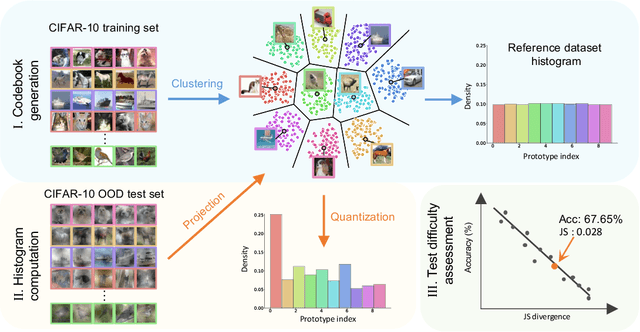
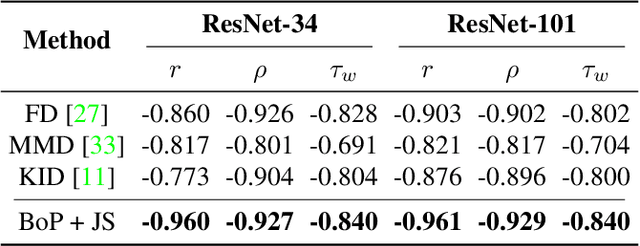
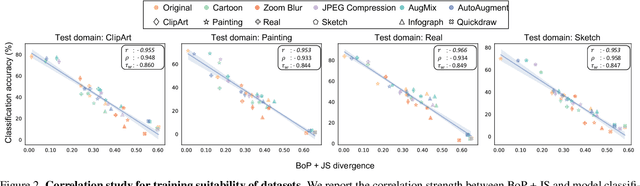
This work investigates dataset vectorization for two dataset-level tasks: assessing training set suitability and test set difficulty. The former measures how suitable a training set is for a target domain, while the latter studies how challenging a test set is for a learned model. Central to the two tasks is measuring the underlying relationship between datasets. This needs a desirable dataset vectorization scheme, which should preserve as much discriminative dataset information as possible so that the distance between the resulting dataset vectors can reflect dataset-to-dataset similarity. To this end, we propose a bag-of-prototypes (BoP) dataset representation that extends the image-level bag consisting of patch descriptors to dataset-level bag consisting of semantic prototypes. Specifically, we develop a codebook consisting of K prototypes clustered from a reference dataset. Given a dataset to be encoded, we quantize each of its image features to a certain prototype in the codebook and obtain a K-dimensional histogram. Without assuming access to dataset labels, the BoP representation provides a rich characterization of the dataset semantic distribution. Furthermore, BoP representations cooperate well with Jensen-Shannon divergence for measuring dataset-to-dataset similarity. Although very simple, BoP consistently shows its advantage over existing representations on a series of benchmarks for two dataset-level tasks.
Seer: Language Instructed Video Prediction with Latent Diffusion Models
Apr 12, 2023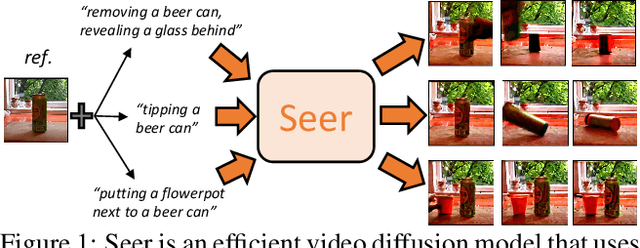
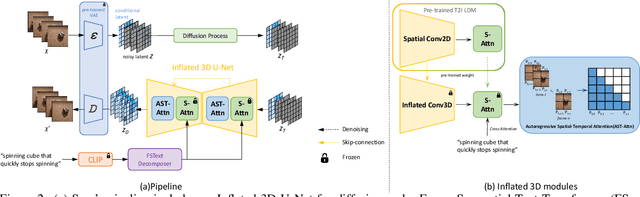
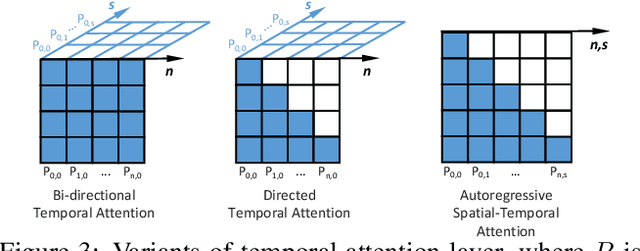
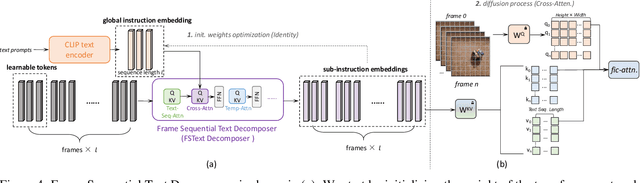
Imagining the future trajectory is the key for robots to make sound planning and successfully reach their goals. Therefore, text-conditioned video prediction (TVP) is an essential task to facilitate general robot policy learning, i.e., predicting future video frames with a given language instruction and reference frames. It is a highly challenging task to ground task-level goals specified by instructions and high-fidelity frames together, requiring large-scale data and computation. To tackle this task and empower robots with the ability to foresee the future, we propose a sample and computation-efficient model, named \textbf{Seer}, by inflating the pretrained text-to-image (T2I) stable diffusion models along the temporal axis. We inflate the denoising U-Net and language conditioning model with two novel techniques, Autoregressive Spatial-Temporal Attention and Frame Sequential Text Decomposer, to propagate the rich prior knowledge in the pretrained T2I models across the frames. With the well-designed architecture, Seer makes it possible to generate high-fidelity, coherent, and instruction-aligned video frames by fine-tuning a few layers on a small amount of data. The experimental results on Something Something V2 (SSv2) and Bridgedata datasets demonstrate our superior video prediction performance with around 210-hour training on 4 RTX 3090 GPUs: decreasing the FVD of the current SOTA model from 290 to 200 on SSv2 and achieving at least 70\% preference in the human evaluation.