 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DCS-RISR: Dynamic Channel Splitting for Efficient Real-world Image Super-Resolution
Dec 15, 2022
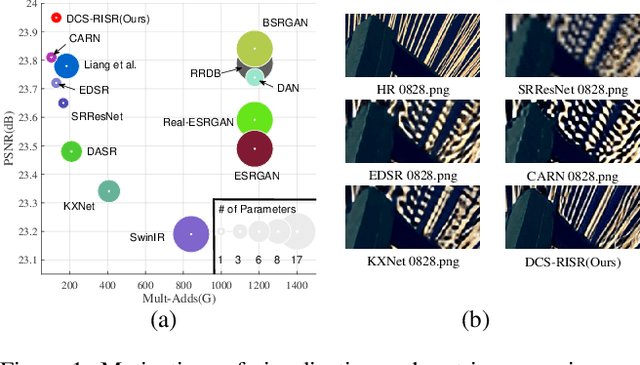
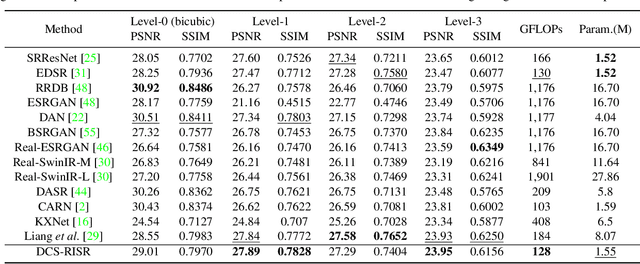
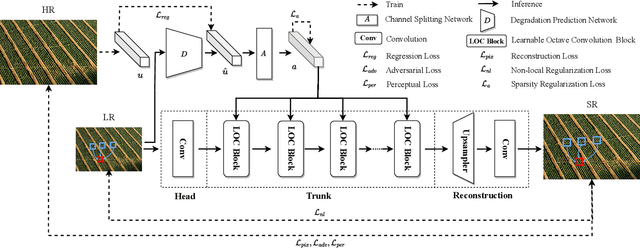
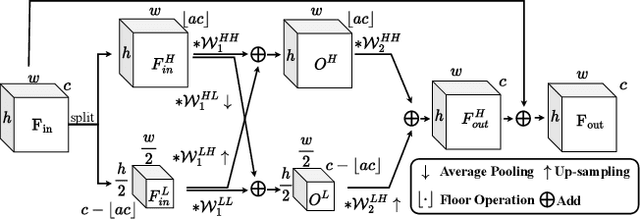
Real-world image super-resolution (RISR) has received increased focus for improving the quality of SR images under unknown complex degradation. Existing methods rely on the heavy SR models to enhance low-resolution (LR) images of different degradation levels, which significantly restricts their practical deployments on resource-limited devices. In this paper, we propose a novel Dynamic Channel Splitting scheme for efficient Real-world Image Super-Resolution, termed DCS-RISR. Specifically, we first introduce the light degradation prediction network to regress the degradation vector to simulate the real-world degradations, upon which the channel splitting vector is generated as the input for an efficient SR model. Then, a learnable octave convolution block is proposed to adaptively decide the channel splitting scale for low- and high-frequency features at each block, reducing computation overhead and memory cost by offering the large scale to low-frequency features and the small scale to the high ones. To further improve the RISR performance, Non-local regularization is employed to supplement the knowledge of patches from LR and HR subspace with free-computation inference. Extensive experiments demonstrate the effectiveness of DCS-RISR on different benchmark datasets. Our DCS-RISR not only achieves the best trade-off between computation/parameter and PSNR/SSIM metric, and also effectively handles real-world images with different degradation levels.
Rethinking the Objectives of Vector-Quantized Tokenizers for Image Synthesis
Dec 06, 2022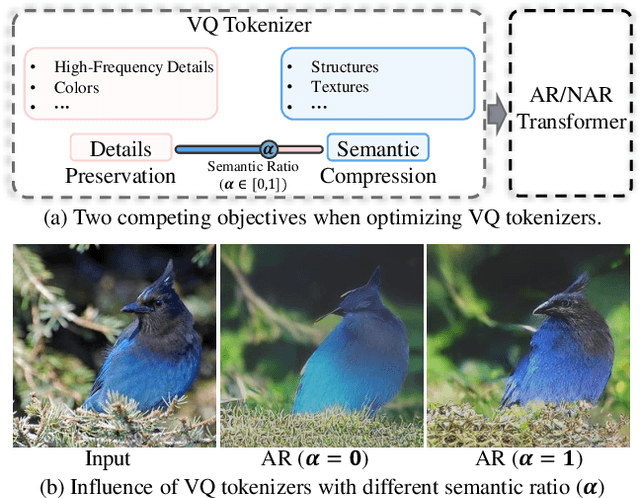
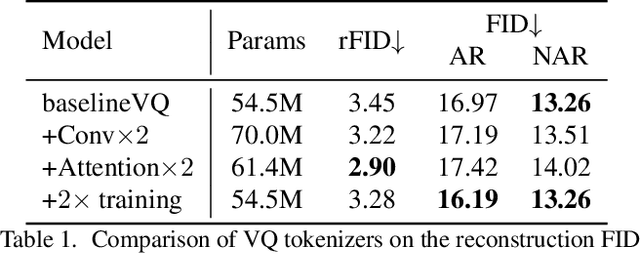

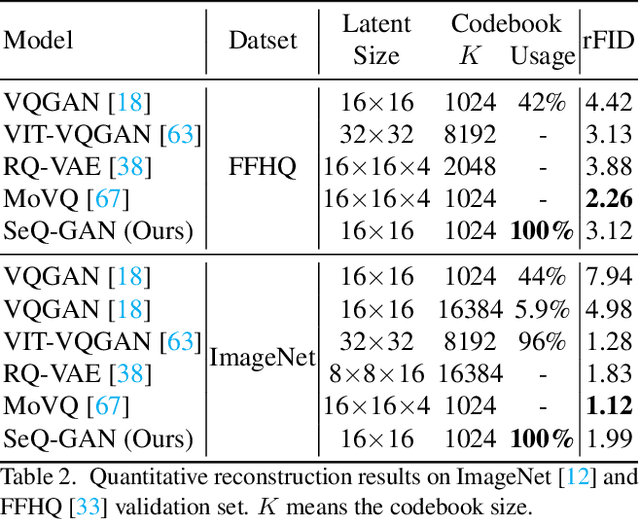
Vector-Quantized (VQ-based) generative models usually consist of two basic components, i.e., VQ tokenizers and generative transformers. Prior research focuses on improving the reconstruction fidelity of VQ tokenizers but rarely examines how the improvement in reconstruction affects the generation ability of generative transformers. In this paper, we surprisingly find that improving the reconstruction fidelity of VQ tokenizers does not necessarily improve the generation. Instead, learning to compress semantic features within VQ tokenizers significantly improves generative transformers' ability to capture textures and structures. We thus highlight two competing objectives of VQ tokenizers for image synthesis: semantic compression and details preservation. Different from previous work that only pursues better details preservation, we propose Semantic-Quantized GAN (SeQ-GAN) with two learning phases to balance the two objectives. In the first phase, we propose a semantic-enhanced perceptual loss for better semantic compression. In the second phase, we fix the encoder and codebook, but enhance and finetune the decoder to achieve better details preservation. The proposed SeQ-GAN greatly improves VQ-based generative models and surpasses the GAN and Diffusion Models on both unconditional and conditional image generation. Our SeQ-GAN (364M) achieves Frechet Inception Distance (FID) of 6.25 and Inception Score (IS) of 140.9 on 256x256 ImageNet generation, a remarkable improvement over VIT-VQGAN (714M), which obtains 11.2 FID and 97.2 IS.
Guided Depth Map Super-resolution: A Survey
Mar 07, 2023

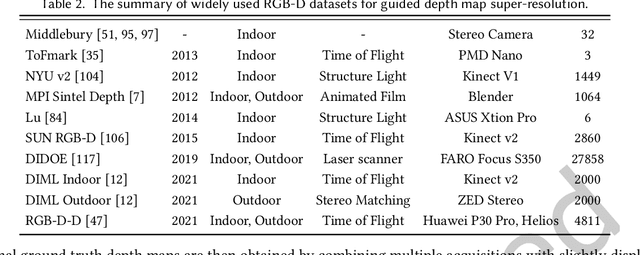
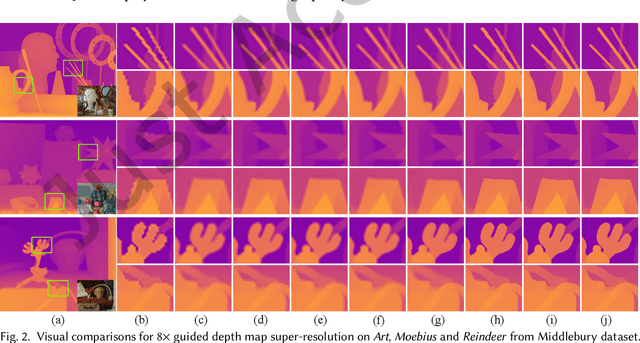
Guided depth map super-resolution (GDSR), which aims to reconstruct a high-resolution (HR) depth map from a low-resolution (LR) observation with the help of a paired HR color image, is a longstanding and fundamental problem, it has attracted considerable attention from computer vision and image processing communities. A myriad of novel and effective approaches have been proposed recently, especially with powerful deep learning techniques. This survey is an effort to present a comprehensive survey of recent progress in GDSR. We start by summarizing the problem of GDSR and explaining why it is challenging. Next, we introduce some commonly used datasets and image quality assessment methods. In addition, we roughly classify existing GDSR methods into three categories, i.e., filtering-based methods, prior-based methods, and learning-based methods. In each category, we introduce the general description of the published algorithms and design principles, summarize the representative methods, and discuss their highlights and limitations. Moreover, the depth related applications are introduced. Furthermore, we conduct experiments to evaluate the performance of some representative methods based on unified experimental configurations, so as to offer a systematic and fair performance evaluation to readers. Finally, we conclude this survey with possible directions and open problems for further research. All the related materials can be found at \url{https://github.com/zhwzhong/Guided-Depth-Map-Super-resolution-A-Survey}.
Inductive Graph Unlearning
Apr 07, 2023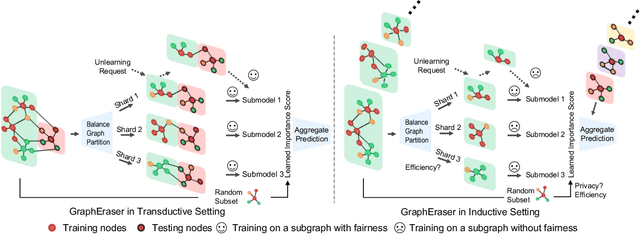
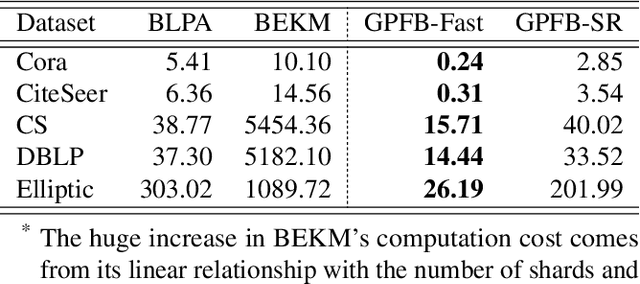
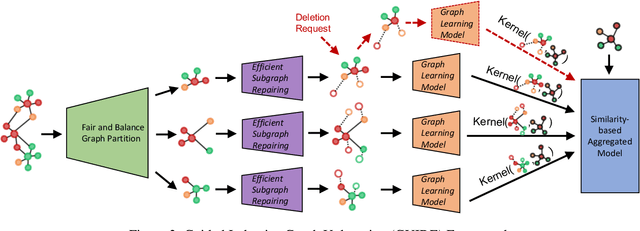
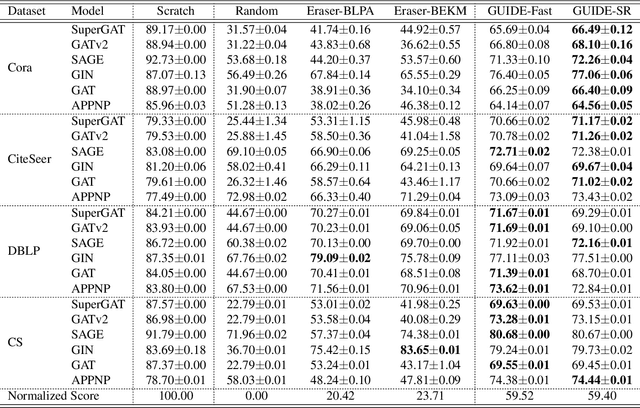
As a way to implement the "right to be forgotten" in machine learning, \textit{machine unlearning} aims to completely remove the contributions and information of the samples to be deleted from a trained model without affecting the contributions of other samples. Recently, many frameworks for machine unlearning have been proposed, and most of them focus on image and text data. To extend machine unlearning to graph data, \textit{GraphEraser} has been proposed. However, a critical issue is that \textit{GraphEraser} is specifically designed for the transductive graph setting, where the graph is static and attributes and edges of test nodes are visible during training. It is unsuitable for the inductive setting, where the graph could be dynamic and the test graph information is invisible in advance. Such inductive capability is essential for production machine learning systems with evolving graphs like social media and transaction networks. To fill this gap, we propose the \underline{{\bf G}}\underline{{\bf U}}ided \underline{{\bf I}}n\underline{{\bf D}}uctiv\underline{{\bf E}} Graph Unlearning framework (GUIDE). GUIDE consists of three components: guided graph partitioning with fairness and balance, efficient subgraph repair, and similarity-based aggregation. Empirically, we evaluate our method on several inductive benchmarks and evolving transaction graphs. Generally speaking, GUIDE can be efficiently implemented on the inductive graph learning tasks for its low graph partition cost, no matter on computation or structure information. The code will be available here: https://github.com/Happy2Git/GUIDE.
Unsupervised Facial Expression Representation Learning with Contrastive Local Warping
Mar 16, 2023
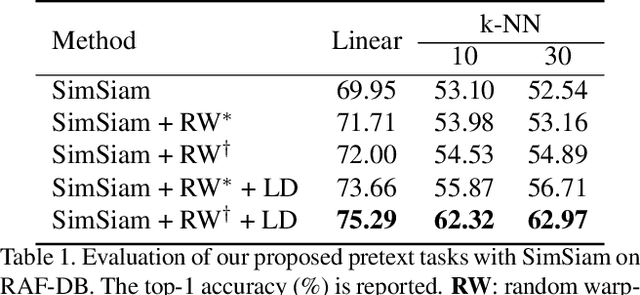
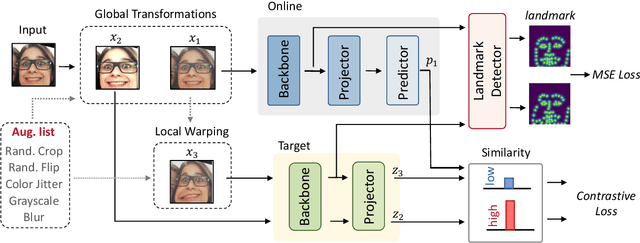
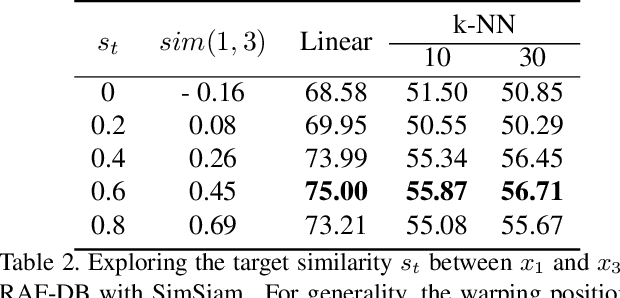
This paper investigates unsupervised representation learning for facial expression analysis. We think Unsupervised Facial Expression Representation (UFER) deserves exploration and has the potential to address some key challenges in facial expression analysis, such as scaling, annotation bias, the discrepancy between discrete labels and continuous emotions, and model pre-training. Such motivated, we propose a UFER method with contrastive local warping (ContraWarping), which leverages the insight that the emotional expression is robust to current global transformation (affine transformation, color jitter, etc.) but can be easily changed by random local warping. Therefore, given a facial image, ContraWarping employs some global transformations and local warping to generate its positive and negative samples and sets up a novel contrastive learning framework. Our in-depth investigation shows that: 1) the positive pairs from global transformations may be exploited with general self-supervised learning (e.g., BYOL) and already bring some informative features, and 2) the negative pairs from local warping explicitly introduce expression-related variation and further bring substantial improvement. Based on ContraWarping, we demonstrate the benefit of UFER under two facial expression analysis scenarios: facial expression recognition and image retrieval. For example, directly using ContraWarping features for linear probing achieves 79.14% accuracy on RAF-DB, significantly reducing the gap towards the full-supervised counterpart (88.92% / 84.81% with/without pre-training).
Identifiability Results for Multimodal Contrastive Learning
Mar 16, 2023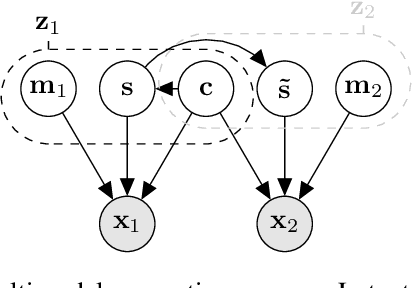
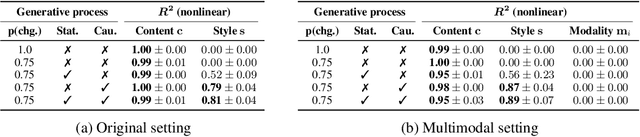

Contrastive learning is a cornerstone underlying recent progress in multi-view and multimodal learning, e.g., in representation learning with image/caption pairs. While its effectiveness is not yet fully understood, a line of recent work reveals that contrastive learning can invert the data generating process and recover ground truth latent factors shared between views. In this work, we present new identifiability results for multimodal contrastive learning, showing that it is possible to recover shared factors in a more general setup than the multi-view setting studied previously. Specifically, we distinguish between the multi-view setting with one generative mechanism (e.g., multiple cameras of the same type) and the multimodal setting that is characterized by distinct mechanisms (e.g., cameras and microphones). Our work generalizes previous identifiability results by redefining the generative process in terms of distinct mechanisms with modality-specific latent variables. We prove that contrastive learning can block-identify latent factors shared between modalities, even when there are nontrivial dependencies between factors. We empirically verify our identifiability results with numerical simulations and corroborate our findings on a complex multimodal dataset of image/text pairs. Zooming out, our work provides a theoretical basis for multimodal representation learning and explains in which settings multimodal contrastive learning can be effective in practice.
MMSR: Multiple-Model Learned Image Super-Resolution Benefiting From Class-Specific Image Priors
Sep 18, 2022
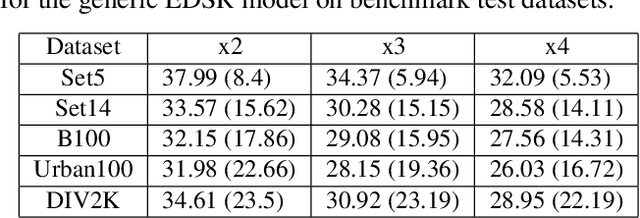
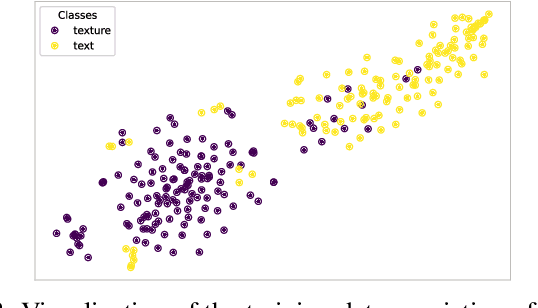

Assuming a known degradation model, the performance of a learned image super-resolution (SR) model depends on how well the variety of image characteristics within the training set matches those in the test set. As a result, the performance of an SR model varies noticeably from image to image over a test set depending on whether characteristics of specific images are similar to those in the training set or not. Hence, in general, a single SR model cannot generalize well enough for all types of image content. In this work, we show that training multiple SR models for different classes of images (e.g., for text, texture, etc.) to exploit class-specific image priors and employing a post-processing network that learns how to best fuse the outputs produced by these multiple SR models surpasses the performance of state-of-the-art generic SR models. Experimental results clearly demonstrate that the proposed multiple-model SR (MMSR) approach significantly outperforms a single pre-trained state-of-the-art SR model both quantitatively and visually. It even exceeds the performance of the best single class-specific SR model trained on similar text or texture images.
ConvFormer: Combining CNN and Transformer for Medical Image Segmentation
Nov 15, 2022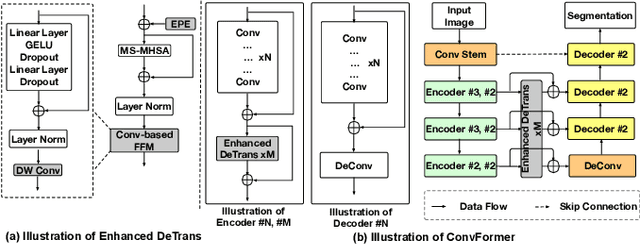
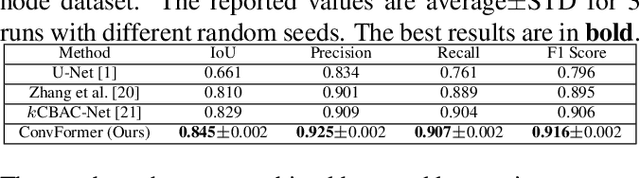
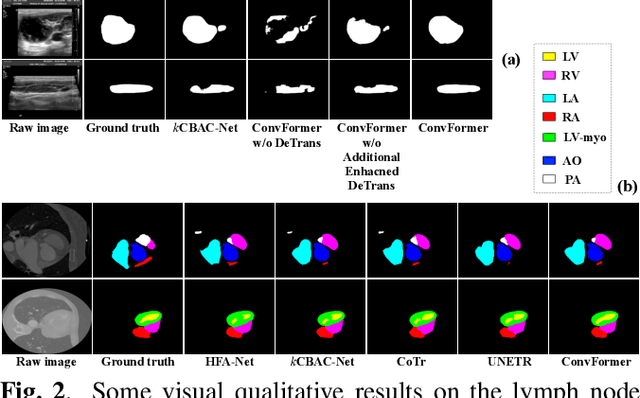
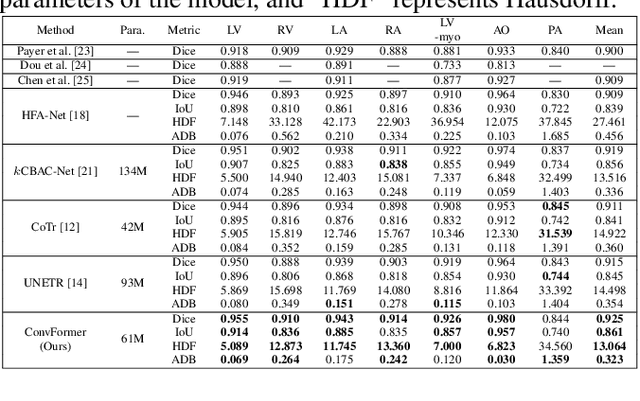
Convolutional neural network (CNN) based methods have achieved great successes in medical image segmentation, but their capability to learn global representations is still limited due to using small effective receptive fields of convolution operations. Transformer based methods are capable of modelling long-range dependencies of information for capturing global representations, yet their ability to model local context is lacking. Integrating CNN and Transformer to learn both local and global representations while exploring multi-scale features is instrumental in further improving medical image segmentation. In this paper, we propose a hierarchical CNN and Transformer hybrid architecture, called ConvFormer, for medical image segmentation. ConvFormer is based on several simple yet effective designs. (1) A feed forward module of Deformable Transformer (DeTrans) is re-designed to introduce local information, called Enhanced DeTrans. (2) A residual-shaped hybrid stem based on a combination of convolutions and Enhanced DeTrans is developed to capture both local and global representations to enhance representation ability. (3) Our encoder utilizes the residual-shaped hybrid stem in a hierarchical manner to generate feature maps in different scales, and an additional Enhanced DeTrans encoder with residual connections is built to exploit multi-scale features with feature maps of different scales as input. Experiments on several datasets show that our ConvFormer, trained from scratch, outperforms various CNN- or Transformer-based architectures, achieving state-of-the-art performance.
Scene-centric vs. Object-centric Image-Text Cross-modal Retrieval: A Reproducibility Study
Jan 12, 2023
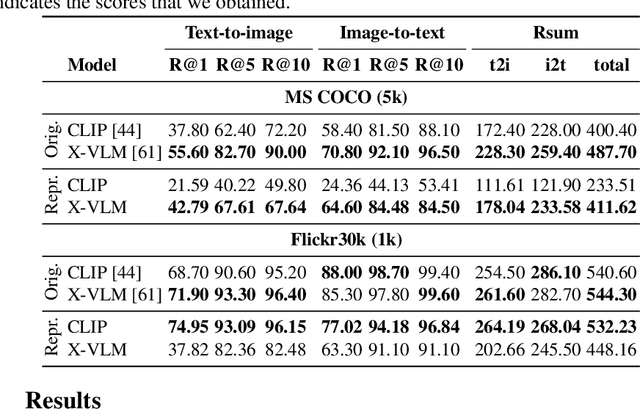
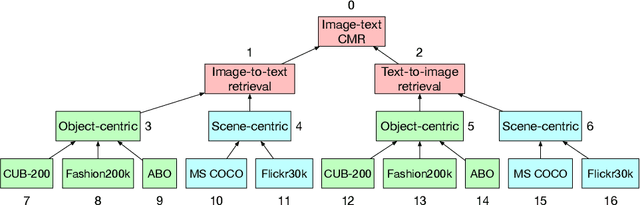
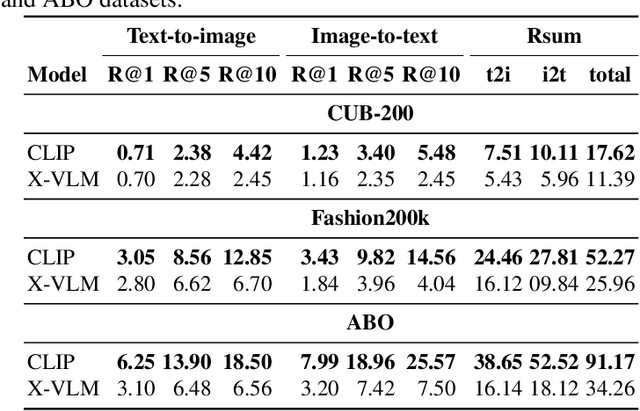
Most approaches to cross-modal retrieval (CMR) focus either on object-centric datasets, meaning that each document depicts or describes a single object, or on scene-centric datasets, meaning that each image depicts or describes a complex scene that involves multiple objects and relations between them. We posit that a robust CMR model should generalize well across both dataset types. Despite recent advances in CMR, the reproducibility of the results and their generalizability across different dataset types has not been studied before. We address this gap and focus on the reproducibility of the state-of-the-art CMR results when evaluated on object-centric and scene-centric datasets. We select two state-of-the-art CMR models with different architectures: (i) CLIP; and (ii) X-VLM. Additionally, we select two scene-centric datasets, and three object-centric datasets, and determine the relative performance of the selected models on these datasets. We focus on reproducibility, replicability, and generalizability of the outcomes of previously published CMR experiments. We discover that the experiments are not fully reproducible and replicable. Besides, the relative performance results partially generalize across object-centric and scene-centric datasets. On top of that, the scores obtained on object-centric datasets are much lower than the scores obtained on scene-centric datasets. For reproducibility and transparency we make our source code and the trained models publicly available.
eDiff-I: Text-to-Image Diffusion Models with an Ensemble of Expert Denoisers
Nov 08, 2022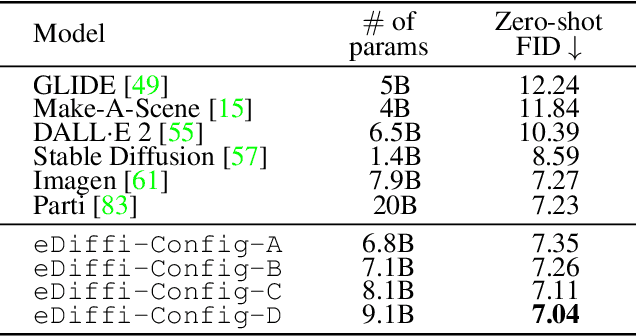
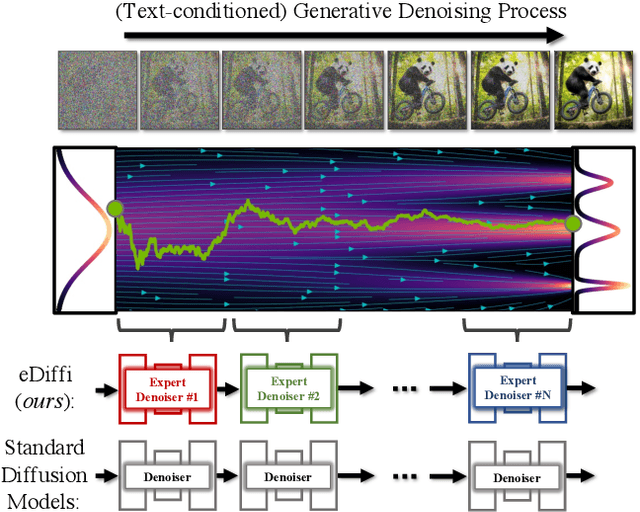

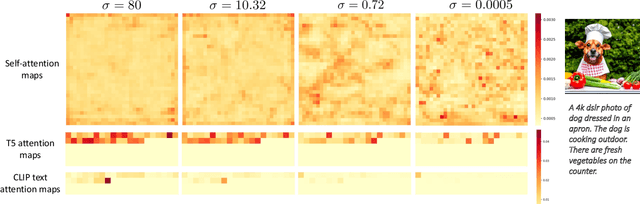
Large-scale diffusion-based generative models have led to breakthroughs in text-conditioned high-resolution image synthesis. Starting from random noise, such text-to-image diffusion models gradually synthesize images in an iterative fashion while conditioning on text prompts. We find that their synthesis behavior qualitatively changes throughout this process: Early in sampling, generation strongly relies on the text prompt to generate text-aligned content, while later, the text conditioning is almost entirely ignored. This suggests that sharing model parameters throughout the entire generation process may not be ideal. Therefore, in contrast to existing works, we propose to train an ensemble of text-to-image diffusion models specialized for different synthesis stages. To maintain training efficiency, we initially train a single model, which is then split into specialized models that are trained for the specific stages of the iterative generation process. Our ensemble of diffusion models, called eDiff-I, results in improved text alignment while maintaining the same inference computation cost and preserving high visual quality, outperforming previous large-scale text-to-image diffusion models on the standard benchmark. In addition, we train our model to exploit a variety of embeddings for conditioning, including the T5 text, CLIP text, and CLIP image embeddings. We show that these different embeddings lead to different behaviors. Notably, the CLIP image embedding allows an intuitive way of transferring the style of a reference image to the target text-to-image output. Lastly, we show a technique that enables eDiff-I's "paint-with-words" capability. A user can select the word in the input text and paint it in a canvas to control the output, which is very handy for crafting the desired image in mind. The project page is available at https://deepimagination.cc/eDiff-I/