 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Ultra-High-Definition Low-Light Image Enhancement: A Benchmark and Transformer-Based Method
Dec 22, 2022

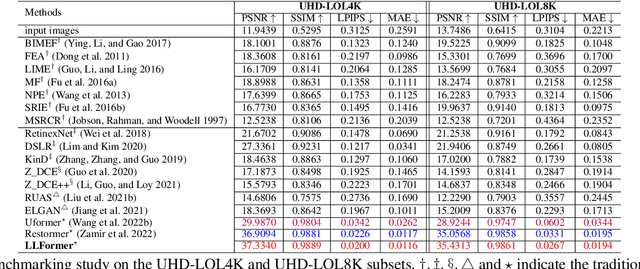
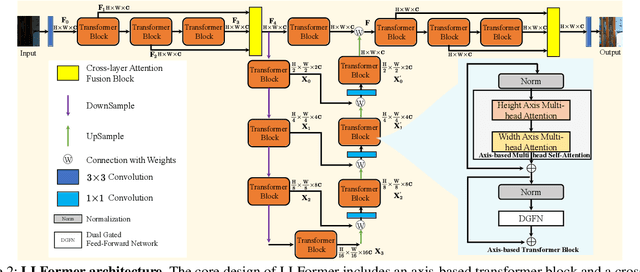
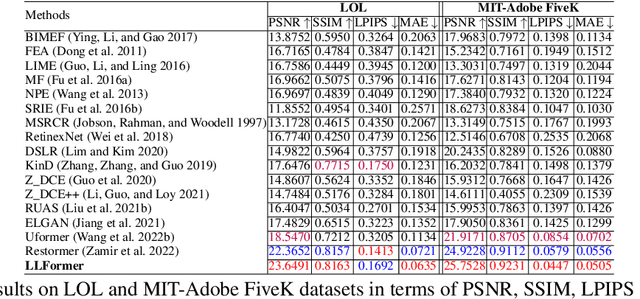
As the quality of optical sensors improves, there is a need for processing large-scale images. In particular, the ability of devices to capture ultra-high definition (UHD) images and video places new demands on the image processing pipeline. In this paper, we consider the task of low-light image enhancement (LLIE) and introduce a large-scale database consisting of images at 4K and 8K resolution. We conduct systematic benchmarking studies and provide a comparison of current LLIE algorithms. As a second contribution, we introduce LLFormer, a transformer-based low-light enhancement method. The core components of LLFormer are the axis-based multi-head self-attention and cross-layer attention fusion block, which significantly reduces the linear complexity. Extensive experiments on the new dataset and existing public datasets show that LLFormer outperforms state-of-the-art methods. We also show that employing existing LLIE methods trained on our benchmark as a pre-processing step significantly improves the performance of downstream tasks, e.g., face detection in low-light conditions. The source code and pre-trained models are available at https://github.com/TaoWangzj/LLFormer.
Dynamic Mobile-Former: Strengthening Dynamic Convolution with Attention and Residual Connection in Kernel Space
Apr 13, 2023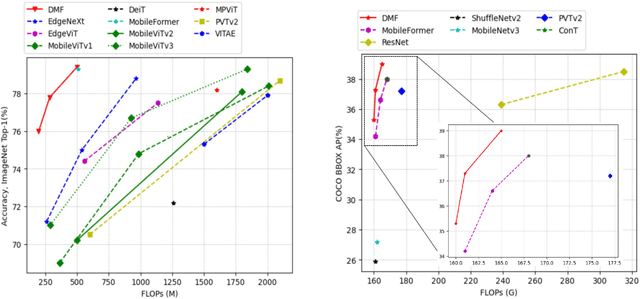
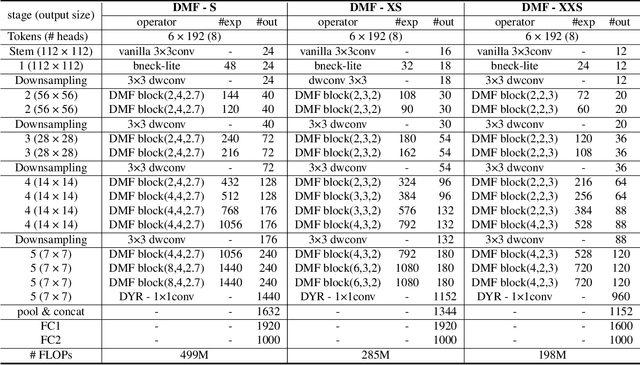
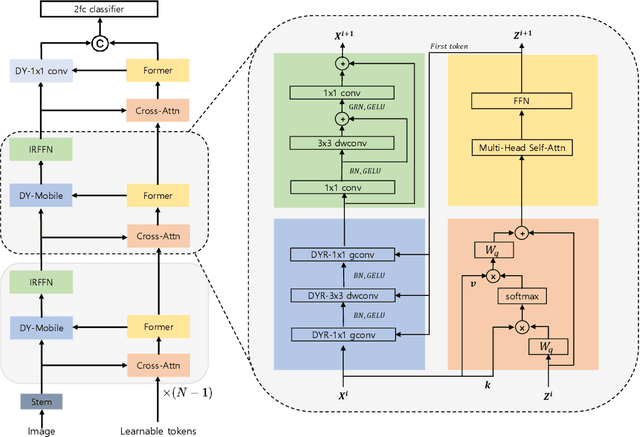
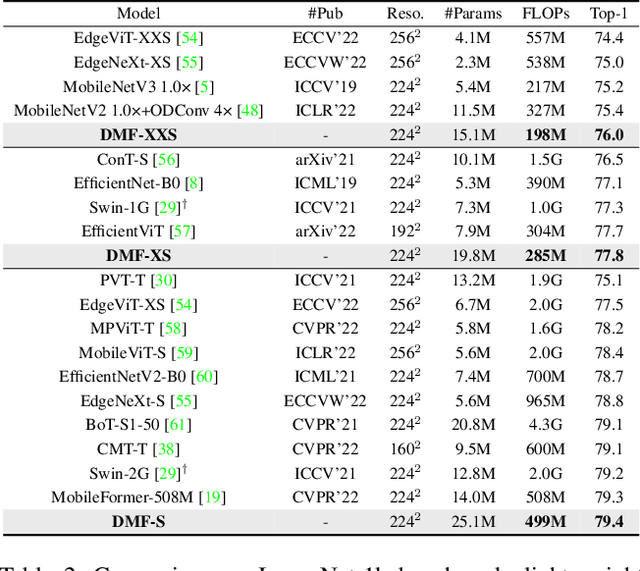
We introduce Dynamic Mobile-Former(DMF), maximizes the capabilities of dynamic convolution by harmonizing it with efficient operators.Our Dynamic MobileFormer effectively utilizes the advantages of Dynamic MobileNet (MobileNet equipped with dynamic convolution) using global information from light-weight attention.A Transformer in Dynamic Mobile-Former only requires a few randomly initialized tokens to calculate global features, making it computationally efficient.And a bridge between Dynamic MobileNet and Transformer allows for bidirectional integration of local and global features.We also simplify the optimization process of vanilla dynamic convolution by splitting the convolution kernel into an input-agnostic kernel and an input-dependent kernel.This allows for optimization in a wider kernel space, resulting in enhanced capacity.By integrating lightweight attention and enhanced dynamic convolution, our Dynamic Mobile-Former achieves not only high efficiency, but also strong performance.We benchmark the Dynamic Mobile-Former on a series of vision tasks, and showcase that it achieves impressive performance on image classification, COCO detection, and instanace segmentation.For example, our DMF hits the top-1 accuracy of 79.4% on ImageNet-1K, much higher than PVT-Tiny by 4.3% with only 1/4 FLOPs.Additionally,our proposed DMF-S model performed well on challenging vision datasets such as COCO, achieving a 39.0% mAP,which is 1% higher than that of the Mobile-Former 508M model, despite using 3 GFLOPs less computations.Code and models are available at https://github.com/ysj9909/DMF
PALF: Pre-Annotation and Camera-LiDAR Late Fusion for the Easy Annotation of Point Clouds
Apr 13, 2023

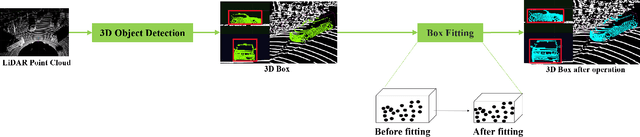
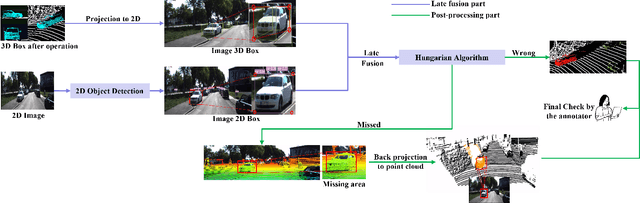
3D object detection has become indispensable in the field of autonomous driving. To date, gratifying breakthroughs have been recorded in 3D object detection research, attributed to deep learning. However, deep learning algorithms are data-driven and require large amounts of annotated point cloud data for training and evaluation. Unlike 2D image labels, annotating point cloud data is difficult due to the limitations of sparsity, irregularity, and low resolution, which requires more manual work, and the annotation efficiency is much lower than 2D image.Therefore, we propose an annotation algorithm for point cloud data, which is pre-annotation and camera-LiDAR late fusion algorithm to easily and accurately annotate. The contributions of this study are as follows. We propose (1) a pre-annotation algorithm that employs 3D object detection and auto fitting for the easy annotation of point clouds, (2) a camera-LiDAR late fusion algorithm using 2D and 3D results for easily error checking, which helps annotators easily identify missing objects, and (3) a point cloud annotation evaluation pipeline to evaluate our experiments. The experimental results show that the proposed algorithm improves the annotating speed by 6.5 times and the annotation quality in terms of the 3D Intersection over Union and precision by 8.2 points and 5.6 points, respectively; additionally, the miss rate is reduced by 31.9 points.
High Dynamic Range Imaging with Context-aware Transformer
Apr 13, 2023
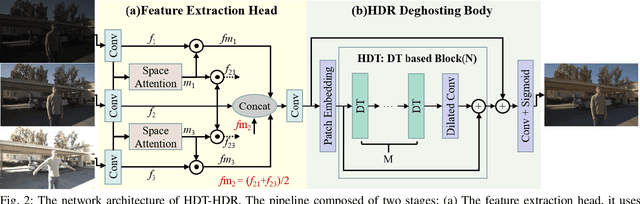
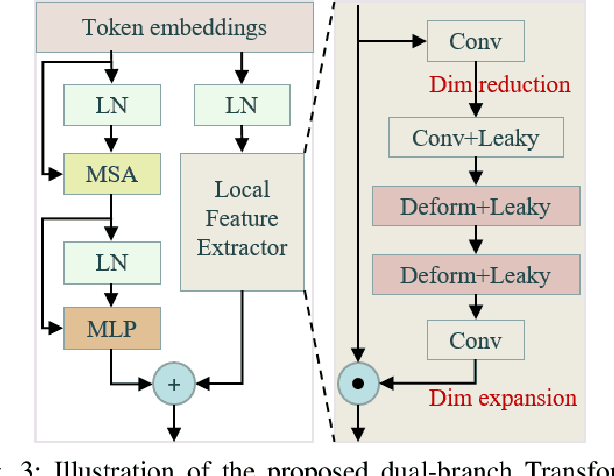

Avoiding the introduction of ghosts when synthesising LDR images as high dynamic range (HDR) images is a challenging task. Convolutional neural networks (CNNs) are effective for HDR ghost removal in general, but are challenging to deal with the LDR images if there are large movements or oversaturation/undersaturation. Existing dual-branch methods combining CNN and Transformer omit part of the information from non-reference images, while the features extracted by the CNN-based branch are bound to the kernel size with small receptive field, which are detrimental to the deblurring and the recovery of oversaturated/undersaturated regions. In this paper, we propose a novel hierarchical dual Transformer method for ghost-free HDR (HDT-HDR) images generation, which extracts global features and local features simultaneously. First, we use a CNN-based head with spatial attention mechanisms to extract features from all the LDR images. Second, the LDR features are delivered to the Hierarchical Dual Transformer (HDT). In each Dual Transformer (DT), the global features are extracted by the window-based Transformer, while the local details are extracted using the channel attention mechanism with deformable CNNs. Finally, the ghost free HDR image is obtained by dimensional mapping on the HDT output. Abundant experiments demonstrate that our HDT-HDR achieves the state-of-the-art performance among existing HDR ghost removal methods.
Learning Accurate Performance Predictors for Ultrafast Automated Model Compression
Apr 13, 2023In this paper, we propose an ultrafast automated model compression framework called SeerNet for flexible network deployment. Conventional non-differen-tiable methods discretely search the desirable compression policy based on the accuracy from exhaustively trained lightweight models, and existing differentiable methods optimize an extremely large supernet to obtain the required compressed model for deployment. They both cause heavy computational cost due to the complex compression policy search and evaluation process. On the contrary, we obtain the optimal efficient networks by directly optimizing the compression policy with an accurate performance predictor, where the ultrafast automated model compression for various computational cost constraint is achieved without complex compression policy search and evaluation. Specifically, we first train the performance predictor based on the accuracy from uncertain compression policies actively selected by efficient evolutionary search, so that informative supervision is provided to learn the accurate performance predictor with acceptable cost. Then we leverage the gradient that maximizes the predicted performance under the barrier complexity constraint for ultrafast acquisition of the desirable compression policy, where adaptive update stepsizes with momentum are employed to enhance optimality of the acquired pruning and quantization strategy. Compared with the state-of-the-art automated model compression methods, experimental results on image classification and object detection show that our method achieves competitive accuracy-complexity trade-offs with significant reduction of the search cost.
SC-ML: Self-supervised Counterfactual Metric Learning for Debiased Visual Question Answering
Apr 04, 2023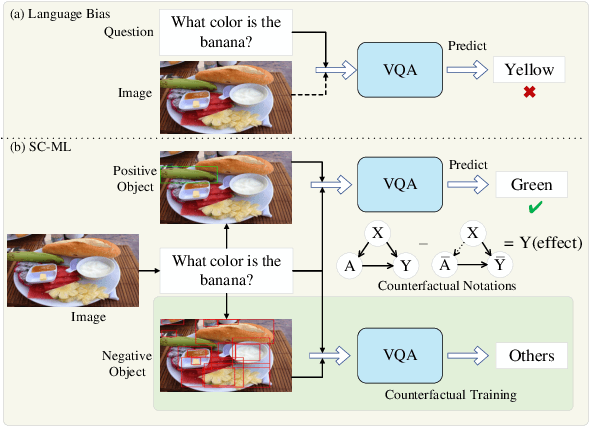
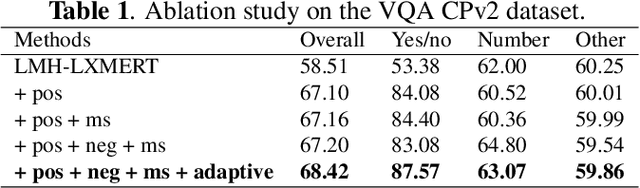
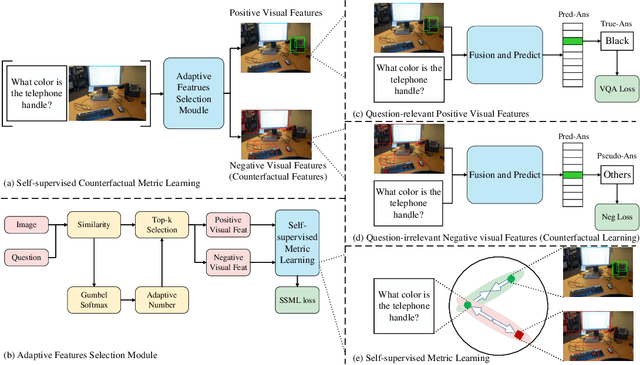
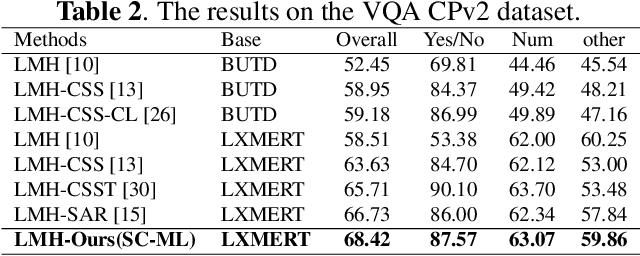
Visual question answering (VQA) is a critical multimodal task in which an agent must answer questions according to the visual cue. Unfortunately, language bias is a common problem in VQA, which refers to the model generating answers only by associating with the questions while ignoring the visual content, resulting in biased results. We tackle the language bias problem by proposing a self-supervised counterfactual metric learning (SC-ML) method to focus the image features better. SC-ML can adaptively select the question-relevant visual features to answer the question, reducing the negative influence of question-irrelevant visual features on inferring answers. In addition, question-irrelevant visual features can be seamlessly incorporated into counterfactual training schemes to further boost robustness. Extensive experiments have proved the effectiveness of our method with improved results on the VQA-CP dataset. Our code will be made publicly available.
Wireless Image Transmission with Semantic and Security Awareness
Dec 01, 2022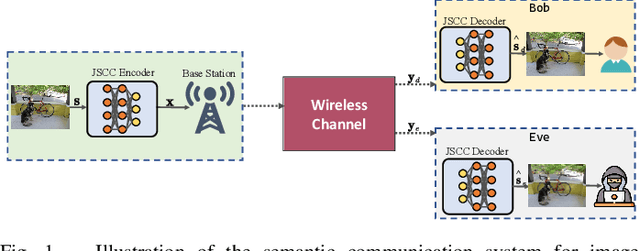
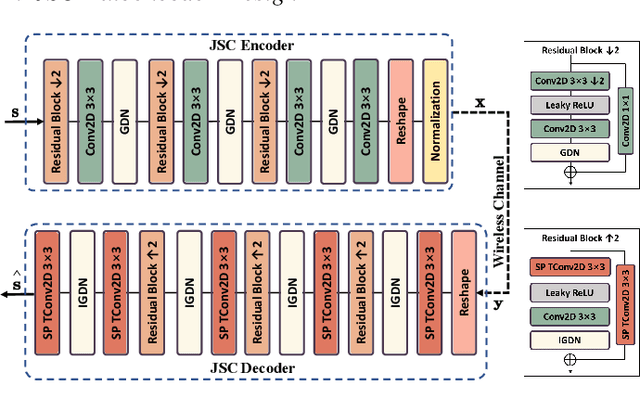

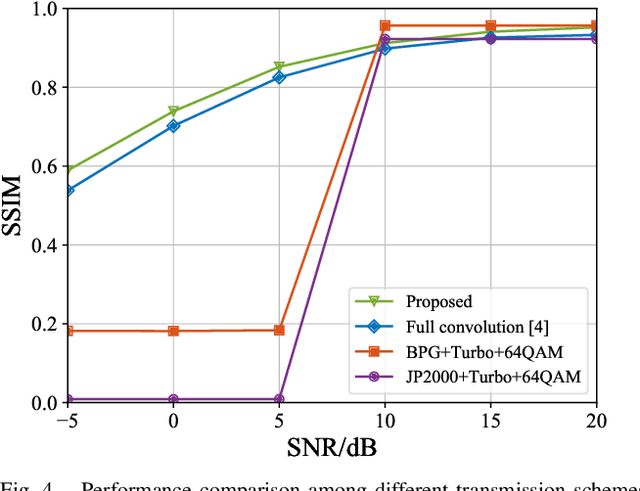
Semantic communication is an increasingly popular framework for wireless image transmission due to its high communication efficiency. With the aid of the joint-source-and-channel (JSC) encoder implemented by neural network, semantic communication directly maps original images into symbol sequences containing semantic information. Compared with the traditional separate source and channel coding design used in bitlevel communication systems, semantic communication systems are known to be more efficient and accurate especially in the low signal-to-the-noise ratio (SNR) regime. This thus prompts an critical while yet to be tackled issue of security in semantic communication: it makes the eavesdropper more easier to crack the semantic information as it can be decoded even in a quite noisy channel. In this letter, we develop a semantic communication framework that accounts for both semantic meaning decoding efficiency and its risk of privacy leakage. To achieve this, targeting wireless image transmission, we on the one hand propose an JSC autoencoder featuring residual for efficient semantic meaning extraction and transmission, and on the other hand, propose a data-driven scheme that balances the efficiency-privacy tradeoff. Extensive experimental results are provided to show the effectiveness and robustness of the proposed scheme.
Efficient Multimodal Sampling via Tempered Distribution Flow
Apr 08, 2023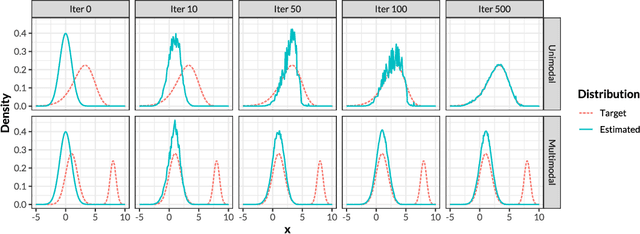


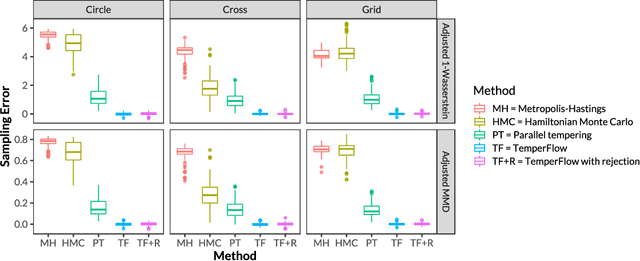
Sampling from high-dimensional distributions is a fundamental problem in statistical research and practice. However, great challenges emerge when the target density function is unnormalized and contains isolated modes. We tackle this difficulty by fitting an invertible transformation mapping, called a transport map, between a reference probability measure and the target distribution, so that sampling from the target distribution can be achieved by pushing forward a reference sample through the transport map. We theoretically analyze the limitations of existing transport-based sampling methods using the Wasserstein gradient flow theory, and propose a new method called TemperFlow that addresses the multimodality issue. TemperFlow adaptively learns a sequence of tempered distributions to progressively approach the target distribution, and we prove that it overcomes the limitations of existing methods. Various experiments demonstrate the superior performance of this novel sampler compared to traditional methods, and we show its applications in modern deep learning tasks such as image generation. The programming code for the numerical experiments is available at https://github.com/yixuan/temperflow.
CoLa-Diff: Conditional Latent Diffusion Model for Multi-Modal MRI Synthesis
Mar 24, 2023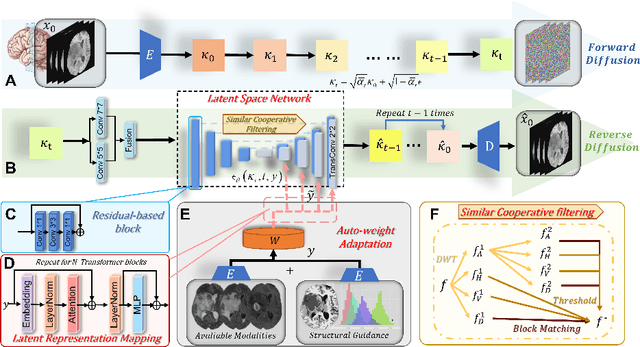
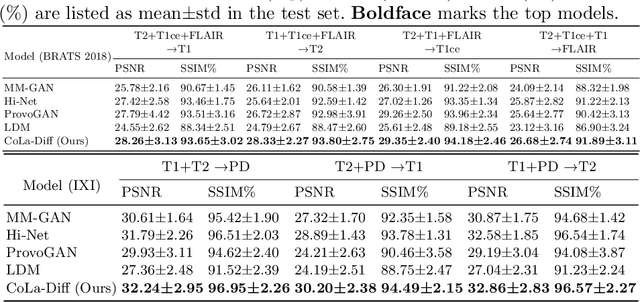
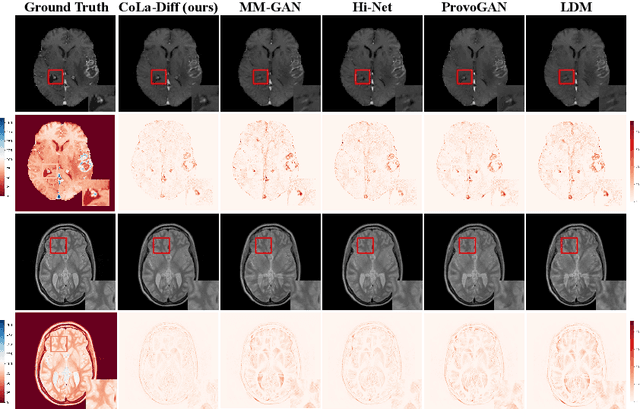
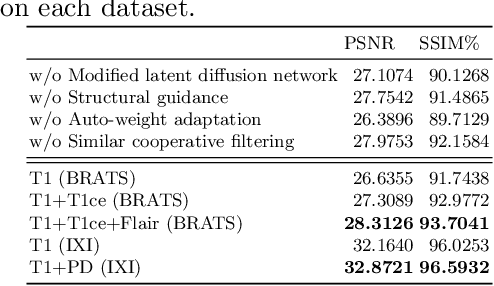
MRI synthesis promises to mitigate the challenge of missing MRI modality in clinical practice. Diffusion model has emerged as an effective technique for image synthesis by modelling complex and variable data distributions. However, most diffusion-based MRI synthesis models are using a single modality. As they operate in the original image domain, they are memory-intensive and less feasible for multi-modal synthesis. Moreover, they often fail to preserve the anatomical structure in MRI. Further, balancing the multiple conditions from multi-modal MRI inputs is crucial for multi-modal synthesis. Here, we propose the first diffusion-based multi-modality MRI synthesis model, namely Conditioned Latent Diffusion Model (CoLa-Diff). To reduce memory consumption, we design CoLa-Diff to operate in the latent space. We propose a novel network architecture, e.g., similar cooperative filtering, to solve the possible compression and noise in latent space. To better maintain the anatomical structure, brain region masks are introduced as the priors of density distributions to guide diffusion process. We further present auto-weight adaptation to employ multi-modal information effectively. Our experiments demonstrate that CoLa-Diff outperforms other state-of-the-art MRI synthesis methods, promising to serve as an effective tool for multi-modal MRI synthesis.
Optimal Smoothing Distribution Exploration for Backdoor Neutralization in Deep Learning-based Traffic Systems
Mar 24, 2023
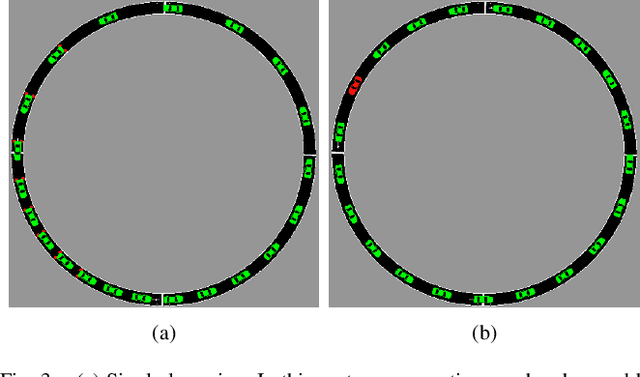
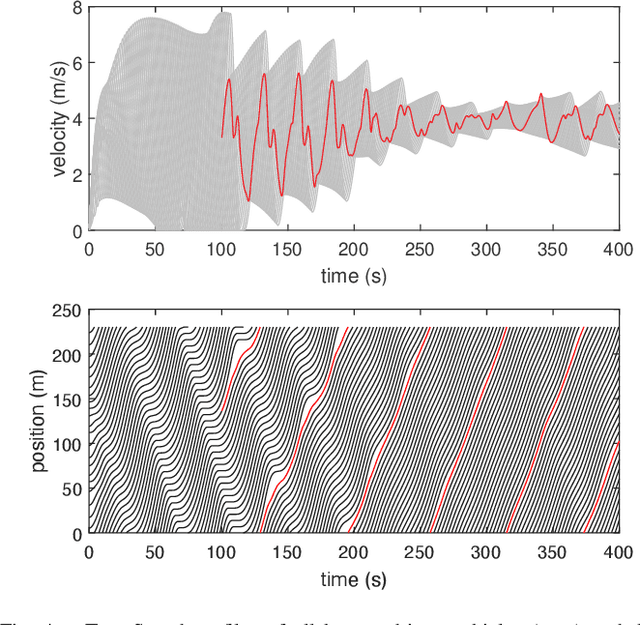
Deep Reinforcement Learning (DRL) enhances the efficiency of Autonomous Vehicles (AV), but also makes them susceptible to backdoor attacks that can result in traffic congestion or collisions. Backdoor functionality is typically incorporated by contaminating training datasets with covert malicious data to maintain high precision on genuine inputs while inducing the desired (malicious) outputs for specific inputs chosen by adversaries. Current defenses against backdoors mainly focus on image classification using image-based features, which cannot be readily transferred to the regression task of DRL-based AV controllers since the inputs are continuous sensor data, i.e., the combinations of velocity and distance of AV and its surrounding vehicles. Our proposed method adds well-designed noise to the input to neutralize backdoors. The approach involves learning an optimal smoothing (noise) distribution to preserve the normal functionality of genuine inputs while neutralizing backdoors. By doing so, the resulting model is expected to be more resilient against backdoor attacks while maintaining high accuracy on genuine inputs. The effectiveness of the proposed method is verified on a simulated traffic system based on a microscopic traffic simulator, where experimental results showcase that the smoothed traffic controller can neutralize all trigger samples and maintain the performance of relieving traffic congestion