 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
From Images to Features: Unbiased Morphology Classification via Variational Auto-Encoders and Domain Adaptation
Mar 15, 2023

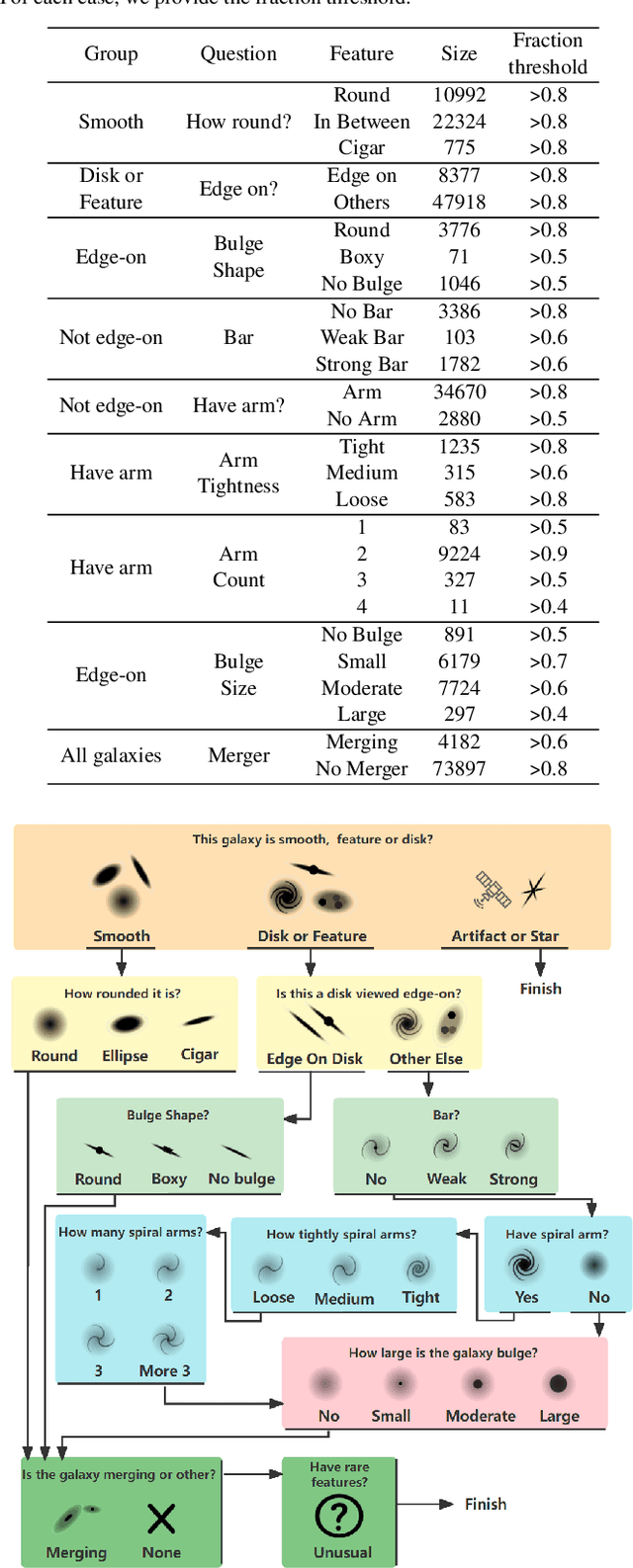
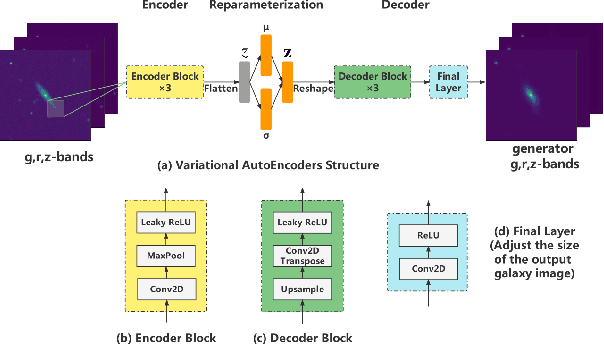
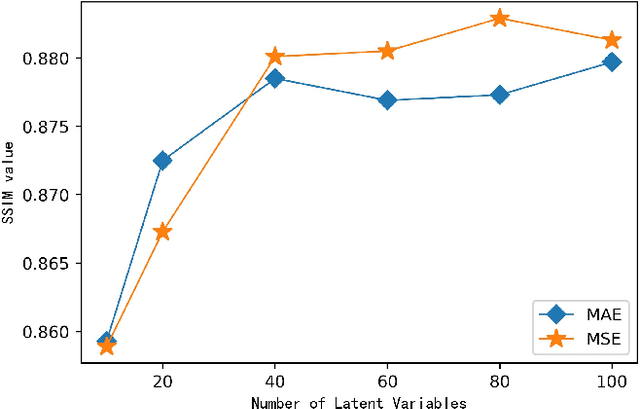
We present a novel approach for the dimensionality reduction of galaxy images by leveraging a combination of variational auto-encoders (VAE) and domain adaptation (DA). We demonstrate the effectiveness of this approach using a sample of low redshift galaxies with detailed morphological type labels from the Galaxy-Zoo DECaLS project. We show that 40-dimensional latent variables can effectively reproduce most morphological features in galaxy images. To further validate the effectiveness of our approach, we utilised a classical random forest (RF) classifier on the 40-dimensional latent variables to make detailed morphology feature classifications. This approach performs similarly to a direct neural network application on galaxy images. We further enhance our model by tuning the VAE network via DA using galaxies in the overlapping footprint of DECaLS and BASS+MzLS, enabling the unbiased application of our model to galaxy images in both surveys. We observed that noise suppression during DA led to even better morphological feature extraction and classification performance. Overall, this combination of VAE and DA can be applied to achieve image dimensionality reduction, defect image identification, and morphology classification in large optical surveys.
Global Learnable Attention for Single Image Super-Resolution
Dec 02, 2022
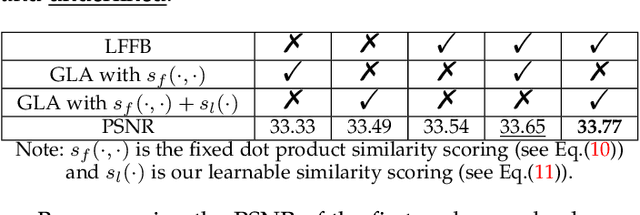
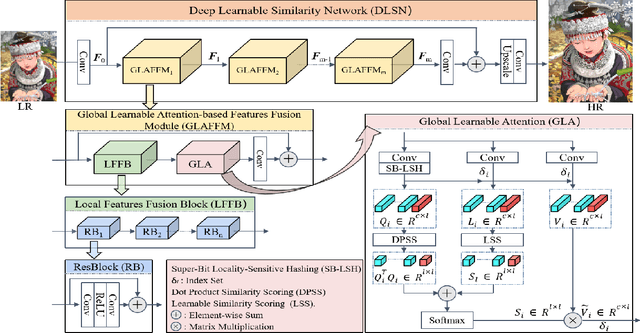
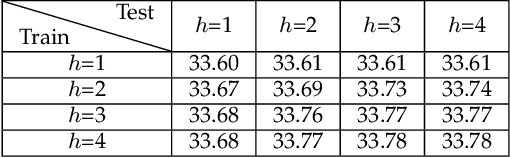
Self-similarity is valuable to the exploration of non-local textures in single image super-resolution (SISR). Researchers usually assume that the importance of non-local textures is positively related to their similarity scores. In this paper, we surprisingly found that when repairing severely damaged query textures, some non-local textures with low-similarity which are closer to the target can provide more accurate and richer details than the high-similarity ones. In these cases, low-similarity does not mean inferior but is usually caused by different scales or orientations. Utilizing this finding, we proposed a Global Learnable Attention (GLA) to adaptively modify similarity scores of non-local textures during training instead of only using a fixed similarity scoring function such as the dot product. The proposed GLA can explore non-local textures with low-similarity but more accurate details to repair severely damaged textures. Furthermore, we propose to adopt Super-Bit Locality-Sensitive Hashing (SB-LSH) as a preprocessing method for our GLA. With the SB-LSH, the computational complexity of our GLA is reduced from quadratic to asymptotic linear with respect to the image size. In addition, the proposed GLA can be integrated into existing deep SISR models as an efficient general building block. Based on the GLA, we constructed a Deep Learnable Similarity Network (DLSN), which achieves state-of-the-art performance for SISR tasks of different degradation types (e.g. blur and noise). Our code and a pre-trained DLSN have been uploaded to GitHub{\dag} for validation.
Delving StyleGAN Inversion for Image Editing: A Foundation Latent Space Viewpoint
Nov 21, 2022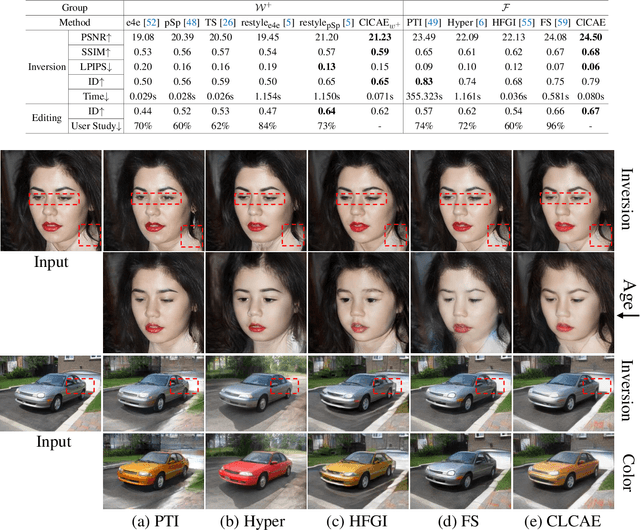
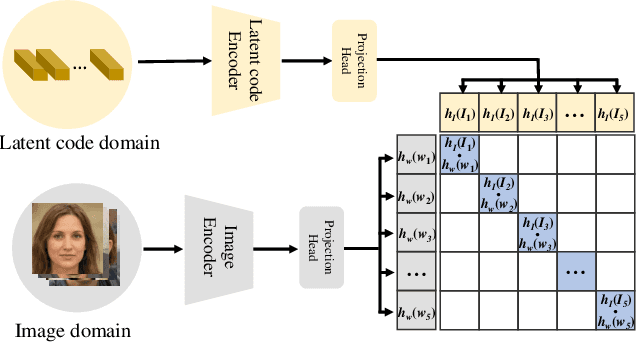
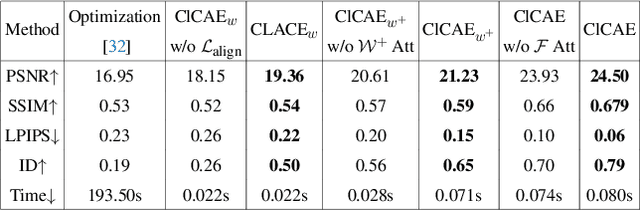
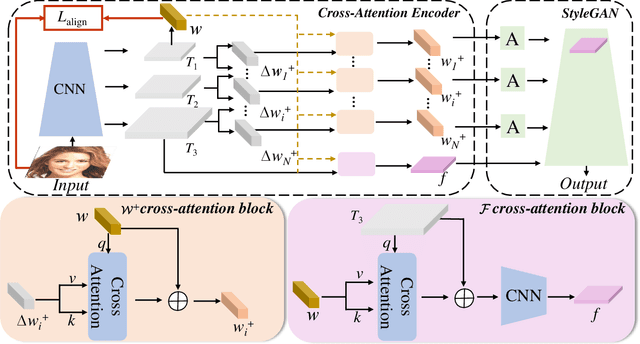
GAN inversion and editing via StyleGAN maps an input image into the embedding spaces ($\mathcal{W}$, $\mathcal{W^+}$, and $\mathcal{F}$) to simultaneously maintain image fidelity and meaningful manipulation. From latent space $\mathcal{W}$ to extended latent space $\mathcal{W^+}$ to feature space $\mathcal{F}$ in StyleGAN, the editability of GAN inversion decreases while its reconstruction quality increases. Recent GAN inversion methods typically explore $\mathcal{W^+}$ and $\mathcal{F}$ rather than $\mathcal{W}$ to improve reconstruction fidelity while maintaining editability. As $\mathcal{W^+}$ and $\mathcal{F}$ are derived from $\mathcal{W}$ that is essentially the foundation latent space of StyleGAN, these GAN inversion methods focusing on $\mathcal{W^+}$ and $\mathcal{F}$ spaces could be improved by stepping back to $\mathcal{W}$. In this work, we propose to first obtain the precise latent code in foundation latent space $\mathcal{W}$. We introduce contrastive learning to align $\mathcal{W}$ and the image space for precise latent code discovery. %The obtaining process is by using contrastive learning to align $\mathcal{W}$ and the image space. Then, we leverage a cross-attention encoder to transform the obtained latent code in $\mathcal{W}$ into $\mathcal{W^+}$ and $\mathcal{F}$, accordingly. Our experiments show that our exploration of the foundation latent space $\mathcal{W}$ improves the representation ability of latent codes in $\mathcal{W^+}$ and features in $\mathcal{F}$, which yields state-of-the-art reconstruction fidelity and editability results on the standard benchmarks. Project page: \url{https://github.com/KumapowerLIU/CLCAE}.
Inductive Graph Unlearning
Apr 07, 2023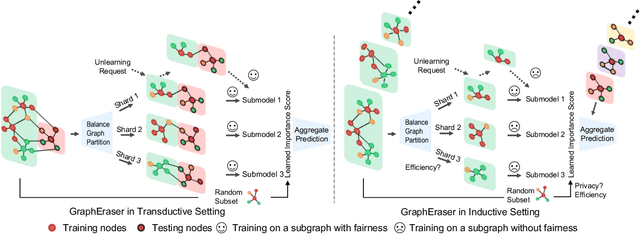
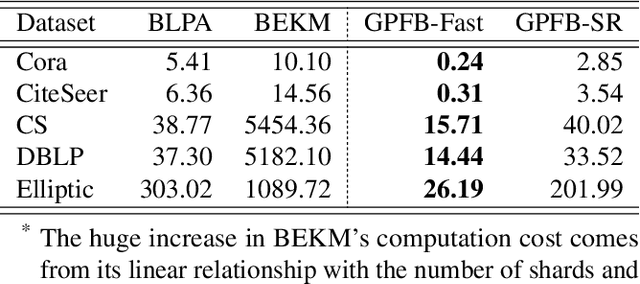
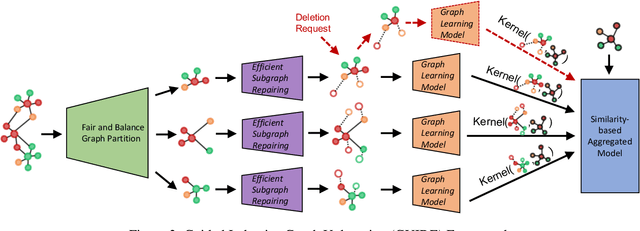
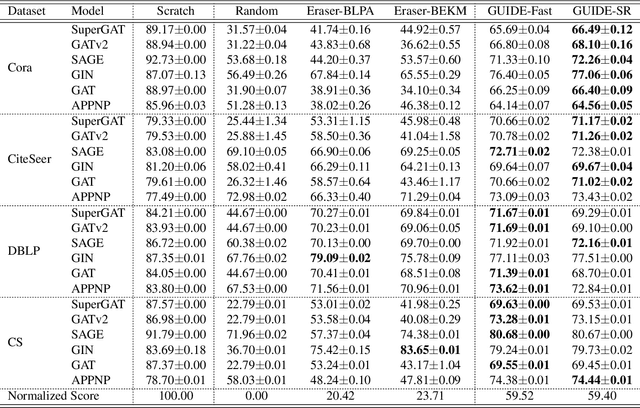
As a way to implement the "right to be forgotten" in machine learning, \textit{machine unlearning} aims to completely remove the contributions and information of the samples to be deleted from a trained model without affecting the contributions of other samples. Recently, many frameworks for machine unlearning have been proposed, and most of them focus on image and text data. To extend machine unlearning to graph data, \textit{GraphEraser} has been proposed. However, a critical issue is that \textit{GraphEraser} is specifically designed for the transductive graph setting, where the graph is static and attributes and edges of test nodes are visible during training. It is unsuitable for the inductive setting, where the graph could be dynamic and the test graph information is invisible in advance. Such inductive capability is essential for production machine learning systems with evolving graphs like social media and transaction networks. To fill this gap, we propose the \underline{{\bf G}}\underline{{\bf U}}ided \underline{{\bf I}}n\underline{{\bf D}}uctiv\underline{{\bf E}} Graph Unlearning framework (GUIDE). GUIDE consists of three components: guided graph partitioning with fairness and balance, efficient subgraph repair, and similarity-based aggregation. Empirically, we evaluate our method on several inductive benchmarks and evolving transaction graphs. Generally speaking, GUIDE can be efficiently implemented on the inductive graph learning tasks for its low graph partition cost, no matter on computation or structure information. The code will be available here: https://github.com/Happy2Git/GUIDE.
DCS-RISR: Dynamic Channel Splitting for Efficient Real-world Image Super-Resolution
Dec 17, 2022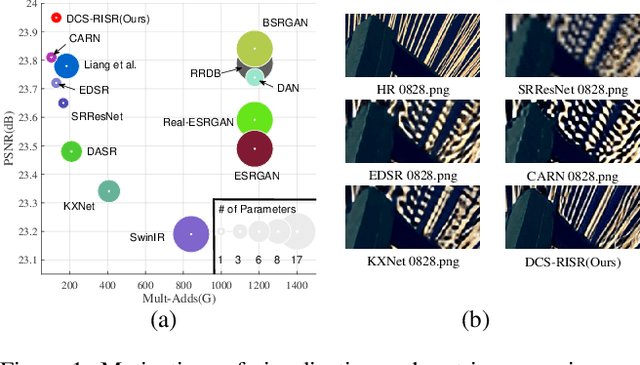
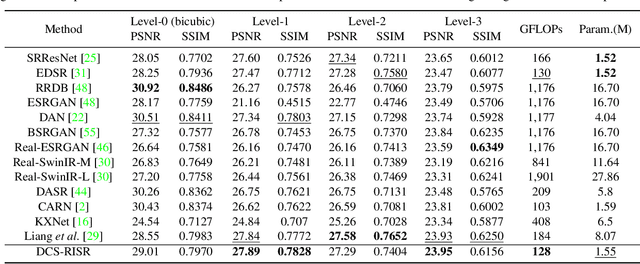
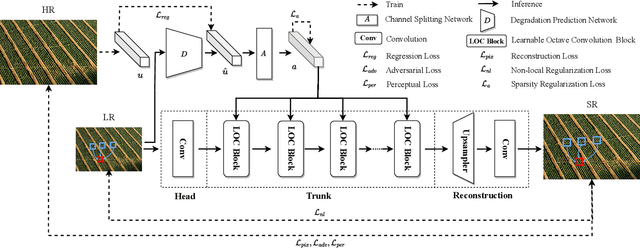
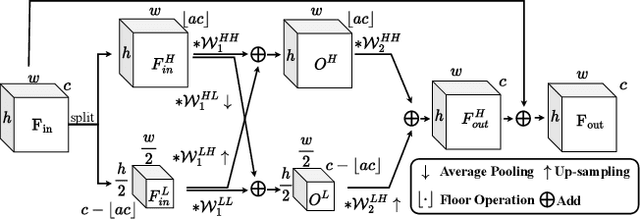
Real-world image super-resolution (RISR) has received increased focus for improving the quality of SR images under unknown complex degradation. Existing methods rely on the heavy SR models to enhance low-resolution (LR) images of different degradation levels, which significantly restricts their practical deployments on resource-limited devices. In this paper, we propose a novel Dynamic Channel Splitting scheme for efficient Real-world Image Super-Resolution, termed DCS-RISR. Specifically, we first introduce the light degradation prediction network to regress the degradation vector to simulate the real-world degradations, upon which the channel splitting vector is generated as the input for an efficient SR model. Then, a learnable octave convolution block is proposed to adaptively decide the channel splitting scale for low- and high-frequency features at each block, reducing computation overhead and memory cost by offering the large scale to low-frequency features and the small scale to the high ones. To further improve the RISR performance, Non-local regularization is employed to supplement the knowledge of patches from LR and HR subspace with free-computation inference. Extensive experiments demonstrate the effectiveness of DCS-RISR on different benchmark datasets. Our DCS-RISR not only achieves the best trade-off between computation/parameter and PSNR/SSIM metric, and also effectively handles real-world images with different degradation levels.
Quantum Kernel for Image Classification of Real World Manufacturing Defects
Dec 16, 2022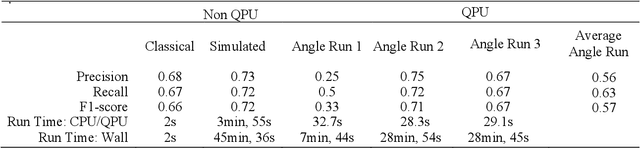
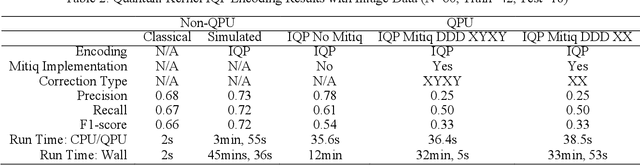
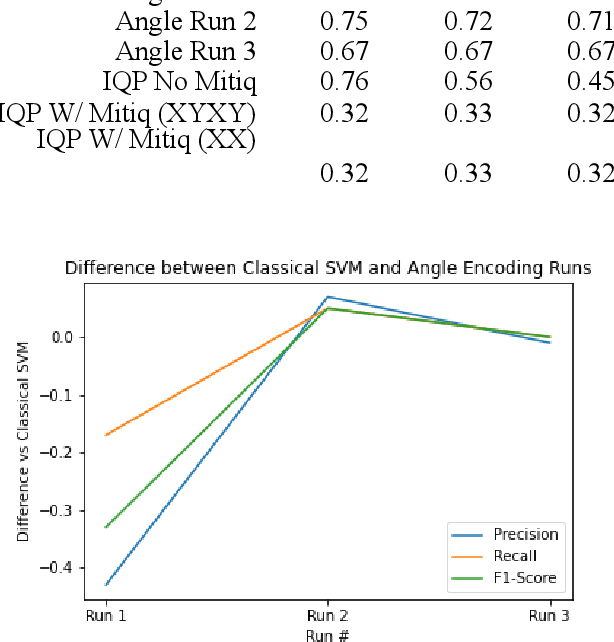
The quantum kernel method results clearly outperformed a classical SVM when analyzing low-resolution images with minimal feature selection on the quantum simulator, with inconsistent results when run on an actual quantum processor. We chose to use an existing quantum kernel method for classification. We applied dynamic decoupling error mitigation using the Mitiq package to the Quantum SVM kernel method, which, to our knowledge, has never been done for quantum kernel methods for image classification. We applied the quantum kernel method to classify real world image data from a manufacturing facility using a superconducting quantum computer. The manufacturing images were used to determine if a product was defective or was produced correctly through the manufacturing process. We also tested the Mitiq dynamical decoupling (DD) methodology to understand effectiveness in decreasing noise-related errors. We also found that the way classical data was encoded onto qubits in quantum states affected our results. All three quantum processing unit (QPU) runs of our angle encoded circuit returned different results, with one run having better than classical results, one run having equivalent to classical results, and a run with worse than classical results. The more complex instantaneous quantum polynomial (IQP) encoding approach showed better precision than classical SVM results when run on a QPU but had a worse recall and F1-score. We found that DD error mitigation did not improve the results of IQP encoded circuits runs and did not have an impact on angle encoded circuits runs on the QPU. In summary, we found that the angle encoded circuit performed the best of the quantum kernel encoding methods on real quantum hardware. In future research projects using quantum kernels to classify images, we recommend exploring other error mitigation techniques than Mitiq DD.
Effective black box adversarial attack with handcrafted kernels
Mar 24, 2023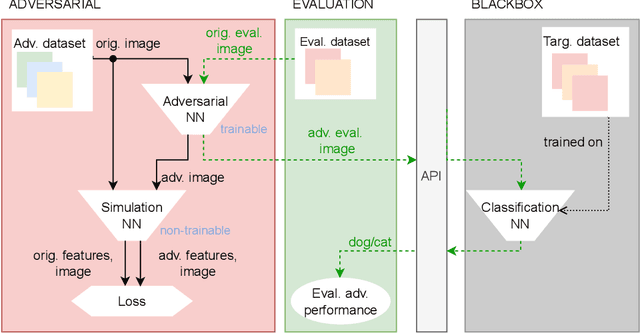


We propose a new, simple framework for crafting adversarial examples for black box attacks. The idea is to simulate the substitution model with a non-trainable model compounded of just one layer of handcrafted convolutional kernels and then train the generator neural network to maximize the distance of the outputs for the original and generated adversarial image. We show that fooling the prediction of the first layer causes the whole network to be fooled and decreases its accuracy on adversarial inputs. Moreover, we do not train the neural network to obtain the first convolutional layer kernels, but we create them using the technique of F-transform. Therefore, our method is very time and resource effective.
Image quality prediction using synthetic and natural codebooks: comparative results
Dec 21, 2022
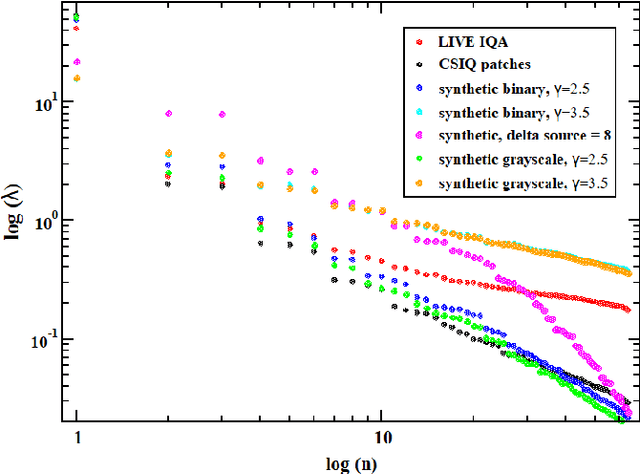
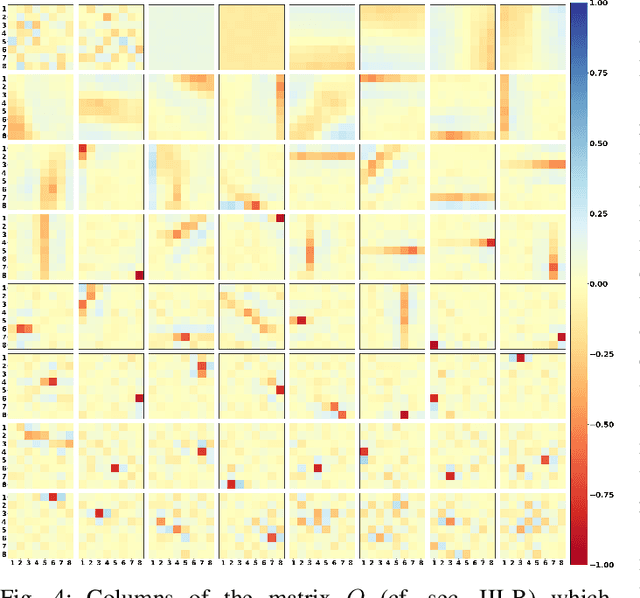
We investigate a model for image/video quality assessment based on building a set of codevectors representing in a sense some basic properties of images, similar to well-known CORNIA model. We analyze the codebook building method and propose some modifications for it. Also the algorithm is investigated from the point of inference time reduction. Both natural and synthetic images are used for building codebooks and some analysis of synthetic images used for codebooks is provided. It is demonstrated the results on quality assessment may be improves with the use if synthetic images for codebook construction. We also demonstrate regimes of the algorithm in which real time execution on CPU is possible for sufficiently high correlations with mean opinion score (MOS). Various pooling strategies are considered as well as the problem of metric sensitivity to bitrate.
Amélioration de la qualité d'images avec un algorithme d'optimisation inspirée par la nature
Mar 13, 2023
Reproducible images preprocessing is important in the field of computer vision, for efficient algorithms comparison or for new images corpus preparation. In this paper, we propose a method to obtain an explicit and ordered sequence of transformations that improves a given image: the computation is performed via a nature-inspired optimization algorithm based on quality assessment techniques. Preliminary tests show the impact of the approach on different state-of-the-art data sets. -- L'application de pr\'etraitements explicites et reproductibles est fondamentale dans le domaine de la vision par ordinateur, pour pouvoir comparer efficacement des algorithmes ou pour pr\'eparer un nouveau corpus d'images. Dans cet article, nous proposons une m\'ethode pour obtenir une s\'equence reproductible de transformations qui am\'eliore une image donn\'ee: le calcul est r\'ealis\'e via un algorithme d'optimisation inspir\'ee par la nature et bas\'e sur des techniques d'\'evaluation de la qualit\'e. Des tests montrent l'impact de l'approche sur diff\'erents ensembles d'images de l'\'etat de l'art.
TRR360D: A dataset for 360 degree rotated rectangular box table detection
Mar 08, 2023



To address the problem of scarcity and high annotation costs of rotated image table detection datasets, this paper proposes a method for building a rotated image table detection dataset. Based on the ICDAR2019MTD modern table detection dataset, we refer to the annotation format of the DOTA dataset to create the TRR360D rotated table detection dataset. The training set contains 600 rotated images and 977 annotated instances, and the test set contains 240 rotated images and 499 annotated instances. The AP50(T<90) evaluation metric is defined, and this dataset is available for future researchers to study rotated table detection algorithms and promote the development of table detection technology. The TRR360D rotated table detection dataset was created by constraining the starting point and annotation direction, and is publicly available at https://github.com/vansin/TRR360D.