 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
TeTIm-Eval: a novel curated evaluation data set for comparing text-to-image models
Dec 15, 2022
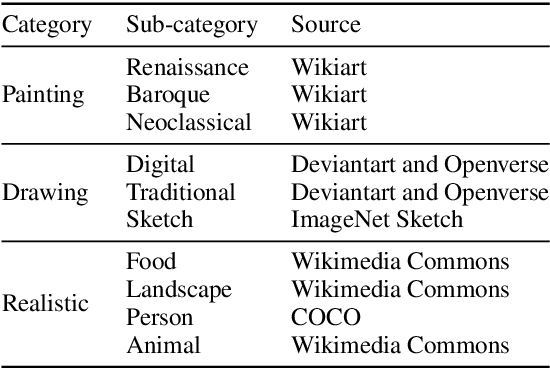
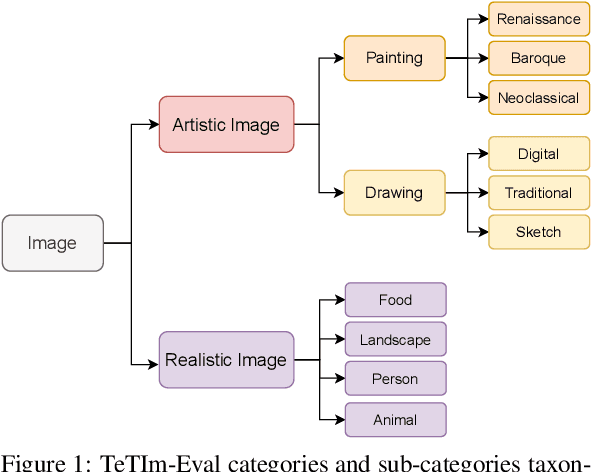

Evaluating and comparing text-to-image models is a challenging problem. Significant advances in the field have recently been made, piquing interest of various industrial sectors. As a consequence, a gold standard in the field should cover a variety of tasks and application contexts. In this paper a novel evaluation approach is experimented, on the basis of: (i) a curated data set, made by high-quality royalty-free image-text pairs, divided into ten categories; (ii) a quantitative metric, the CLIP-score, (iii) a human evaluation task to distinguish, for a given text, the real and the generated images. The proposed method has been applied to the most recent models, i.e., DALLE2, Latent Diffusion, Stable Diffusion, GLIDE and Craiyon. Early experimental results show that the accuracy of the human judgement is fully coherent with the CLIP-score. The dataset has been made available to the public.
How good Neural Networks interpretation methods really are? A quantitative benchmark
Apr 05, 2023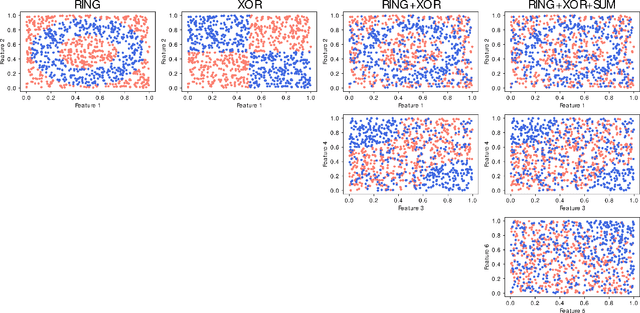
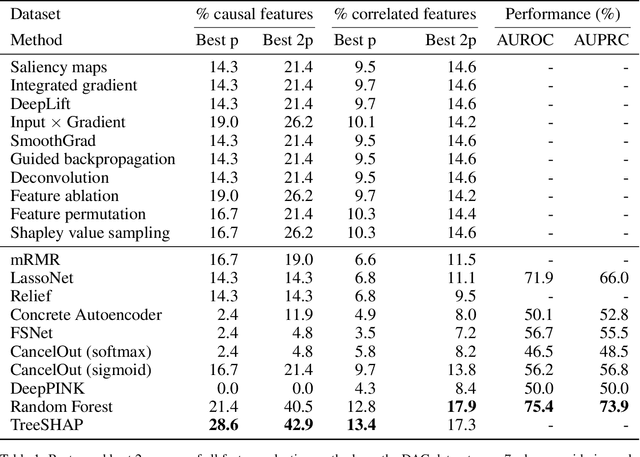
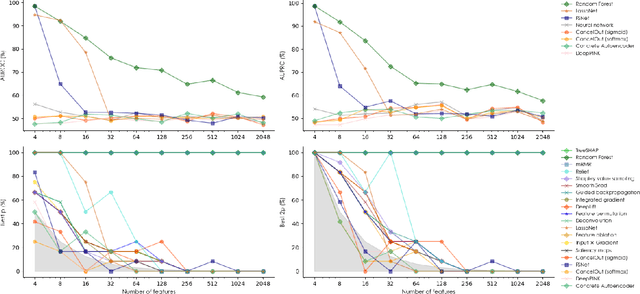
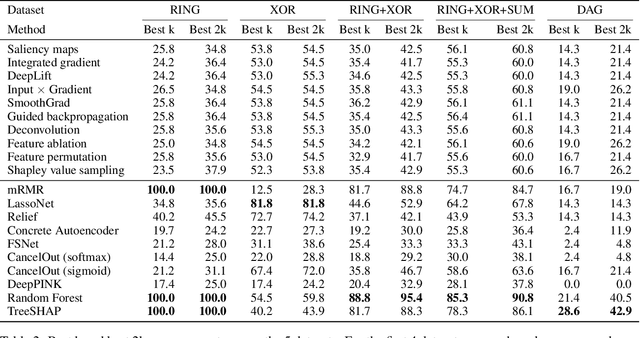
Saliency Maps (SMs) have been extensively used to interpret deep learning models decision by highlighting the features deemed relevant by the model. They are used on highly nonlinear problems, where linear feature selection (FS) methods fail at highlighting relevant explanatory variables. However, the reliability of gradient-based feature attribution methods such as SM has mostly been only qualitatively (visually) assessed, and quantitative benchmarks are currently missing, partially due to the lack of a definite ground truth on image data. Concerned about the apophenic biases introduced by visual assessment of these methods, in this paper we propose a synthetic quantitative benchmark for Neural Networks (NNs) interpretation methods. For this purpose, we built synthetic datasets with nonlinearly separable classes and increasing number of decoy (random) features, illustrating the challenge of FS in high-dimensional settings. We also compare these methods to conventional approaches such as mRMR or Random Forests. Our results show that our simple synthetic datasets are sufficient to challenge most of the benchmarked methods. TreeShap, mRMR and LassoNet are the best performing FS methods. We also show that, when quantifying the relevance of a few non linearly-entangled predictive features diluted in a large number of irrelevant noisy variables, neural network-based FS and interpretation methods are still far from being reliable.
DATID-3D: Diversity-Preserved Domain Adaptation Using Text-to-Image Diffusion for 3D Generative Model
Nov 29, 2022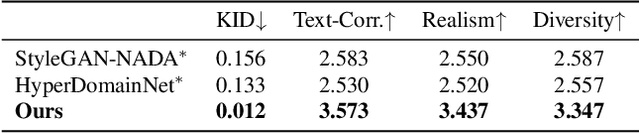
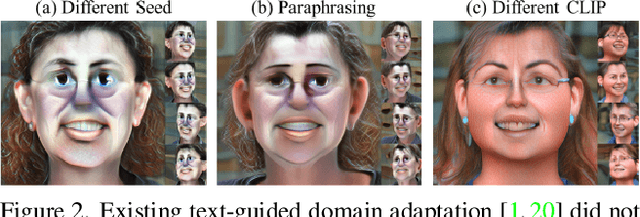
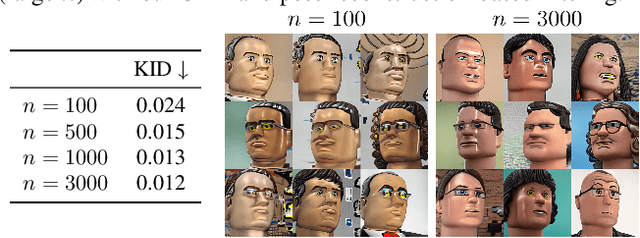
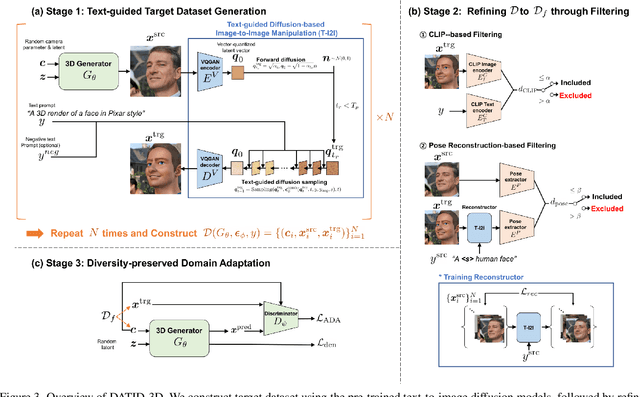
Recent 3D generative models have achieved remarkable performance in synthesizing high resolution photorealistic images with view consistency and detailed 3D shapes, but training them for diverse domains is challenging since it requires massive training images and their camera distribution information. Text-guided domain adaptation methods have shown impressive performance on converting the 2D generative model on one domain into the models on other domains with different styles by leveraging the CLIP (Contrastive Language-Image Pre-training), rather than collecting massive datasets for those domains. However, one drawback of them is that the sample diversity in the original generative model is not well-preserved in the domain-adapted generative models due to the deterministic nature of the CLIP text encoder. Text-guided domain adaptation will be even more challenging for 3D generative models not only because of catastrophic diversity loss, but also because of inferior text-image correspondence and poor image quality. Here we propose DATID-3D, a domain adaptation method tailored for 3D generative models using text-to-image diffusion models that can synthesize diverse images per text prompt without collecting additional images and camera information for the target domain. Unlike 3D extensions of prior text-guided domain adaptation methods, our novel pipeline was able to fine-tune the state-of-the-art 3D generator of the source domain to synthesize high resolution, multi-view consistent images in text-guided targeted domains without additional data, outperforming the existing text-guided domain adaptation methods in diversity and text-image correspondence. Furthermore, we propose and demonstrate diverse 3D image manipulations such as one-shot instance-selected adaptation and single-view manipulated 3D reconstruction to fully enjoy diversity in text.
Universal Deep Image Compression via Content-Adaptive Optimization with Adapters
Nov 02, 2022
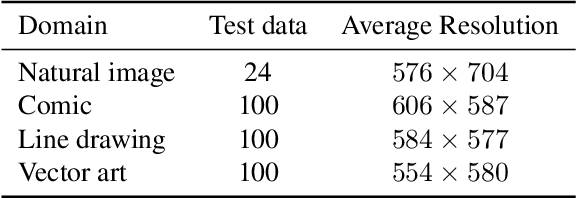
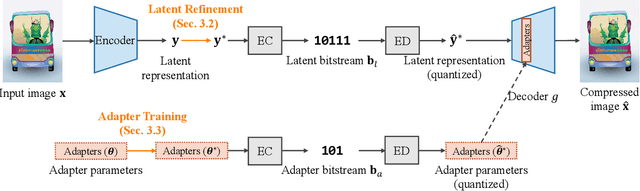
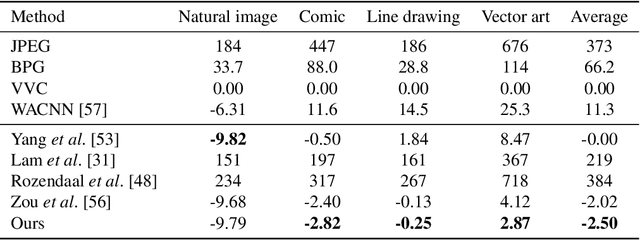
Deep image compression performs better than conventional codecs, such as JPEG, on natural images. However, deep image compression is learning-based and encounters a problem: the compression performance deteriorates significantly for out-of-domain images. In this study, we highlight this problem and address a novel task: universal deep image compression. This task aims to compress images belonging to arbitrary domains, such as natural images, line drawings, and comics. To address this problem, we propose a content-adaptive optimization framework; this framework uses a pre-trained compression model and adapts the model to a target image during compression. Adapters are inserted into the decoder of the model. For each input image, our framework optimizes the latent representation extracted by the encoder and the adapter parameters in terms of rate-distortion. The adapter parameters are additionally transmitted per image. For the experiments, a benchmark dataset containing uncompressed images of four domains (natural images, line drawings, comics, and vector arts) is constructed and the proposed universal deep compression is evaluated. Finally, the proposed model is compared with non-adaptive and existing adaptive compression models. The comparison reveals that the proposed model outperforms these. The code and dataset are publicly available at https://github.com/kktsubota/universal-dic.
HRDFuse: Monocular 360°Depth Estimation by Collaboratively Learning Holistic-with-Regional Depth Distributions
Mar 22, 2023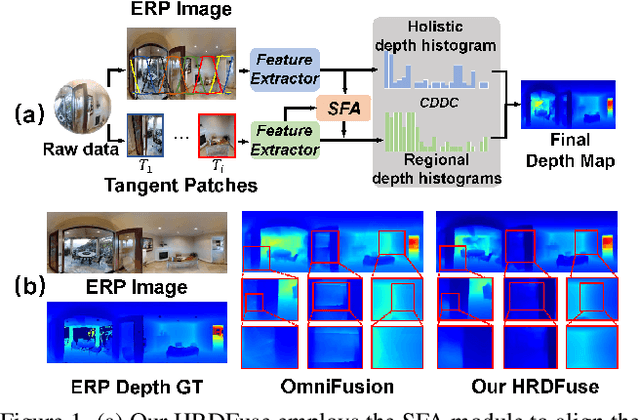
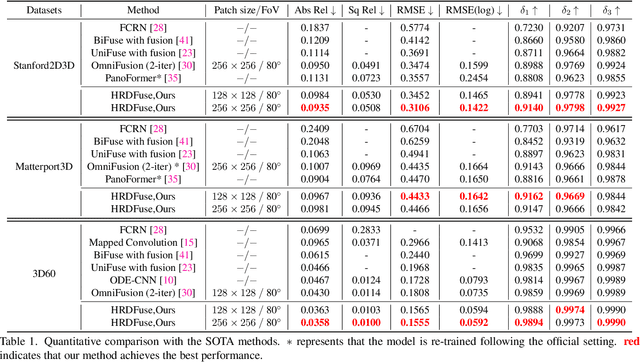
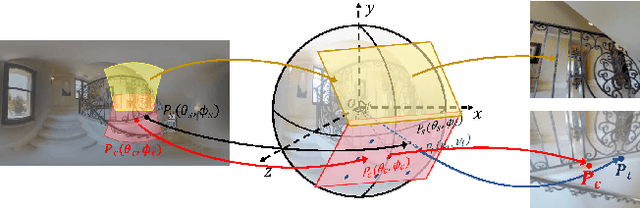
Depth estimation from a monocular 360{\deg} image is a burgeoning problem owing to its holistic sensing of a scene. Recently, some methods, \eg, OmniFusion, have applied the tangent projection (TP) to represent a 360{\deg}image and predicted depth values via patch-wise regressions, which are merged to get a depth map with equirectangular projection (ERP) format. However, these methods suffer from 1) non-trivial process of merging plenty of patches; 2) capturing less holistic-with-regional contextual information by directly regressing the depth value of each pixel. In this paper, we propose a novel framework, \textbf{HRDFuse}, that subtly combines the potential of convolutional neural networks (CNNs) and transformers by collaboratively learning the \textit{holistic} contextual information from the ERP and the \textit{regional} structural information from the TP. Firstly, we propose a spatial feature alignment (\textbf{SFA}) module that learns feature similarities between the TP and ERP to aggregate the TP features into a complete ERP feature map in a pixel-wise manner. Secondly, we propose a collaborative depth distribution classification (\textbf{CDDC}) module that learns the \textbf{holistic-with-regional} histograms capturing the ERP and TP depth distributions. As such, the final depth values can be predicted as a linear combination of histogram bin centers. Lastly, we adaptively combine the depth predictions from ERP and TP to obtain the final depth map. Extensive experiments show that our method predicts\textbf{ more smooth and accurate depth} results while achieving \textbf{favorably better} results than the SOTA methods.
Comprehensive Complexity Assessment of Emerging Learned Image Compression on CPU and GPU
Dec 11, 2022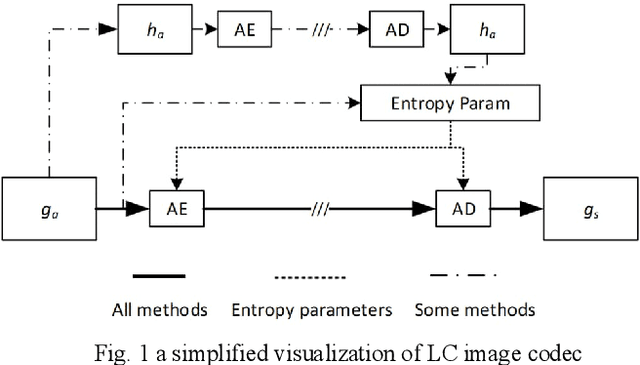
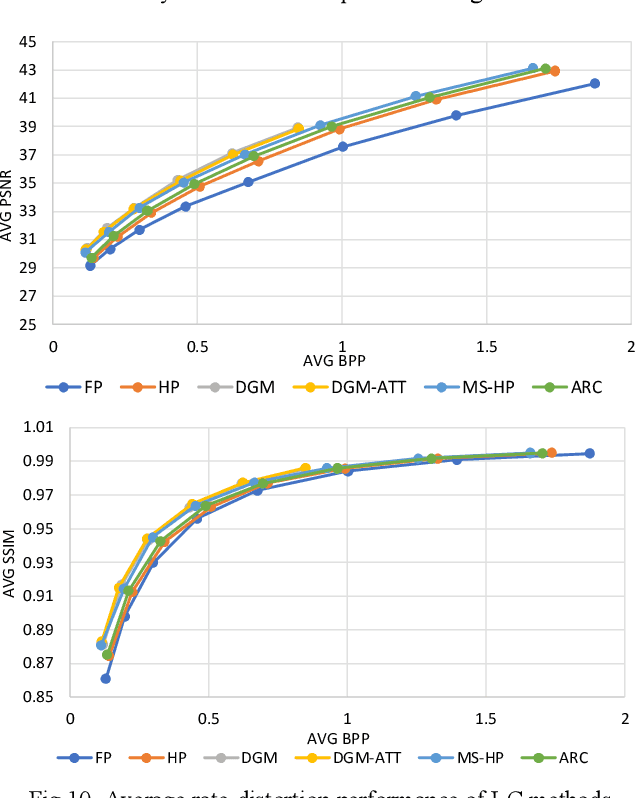
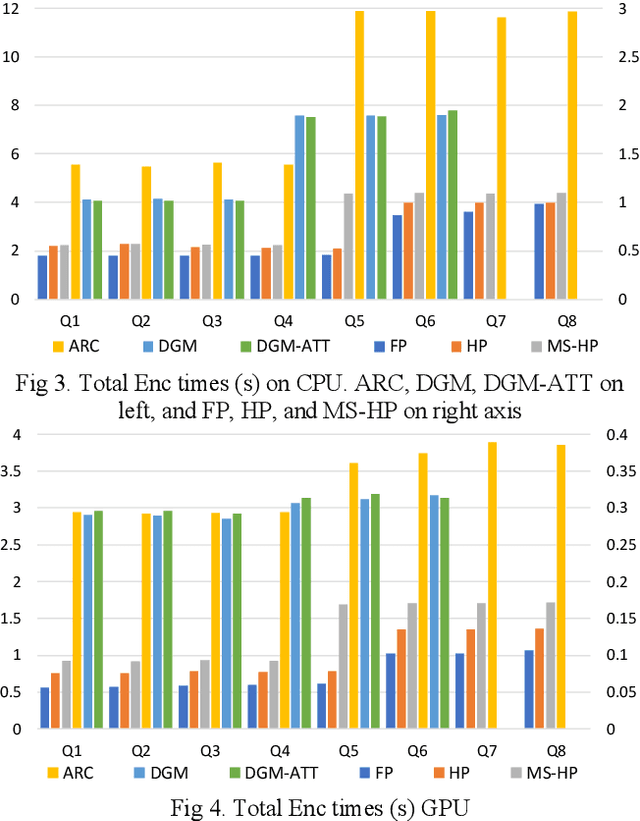
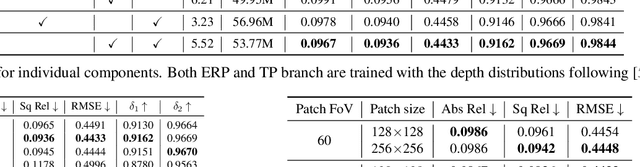
Learned Compression (LC) is the emerging technology for compressing image and video content, using deep neural networks. Despite being new, LC methods have already gained a compression efficiency comparable to state-of-the-art image compression, such as HEVC or even VVC. However, the existing solutions often require a huge computational complexity, which discourages their adoption in international standards or products. This paper provides a comprehensive complexity assessment of several notable methods, that shed light on the matter, and guide the future development of this field by presenting key findings. To do so, six existing methods have been evaluated for both encoding and decoding, on CPU and GPU platforms. Various aspects of complexity such as the overall complexity, share of each coding module, number of operations, number of parameters, most demanding GPU kernels, and memory requirements have been measured and compared on Kodak dataset. The reported results (1) quantify the complexity of LC methods, (2) fairly compare different methods, and (3) a major contribution of the work is identifying and quantifying the key factors affecting the complexity.
Automatic Error Detection in Integrated Circuits Image Segmentation: A Data-driven Approach
Nov 08, 2022
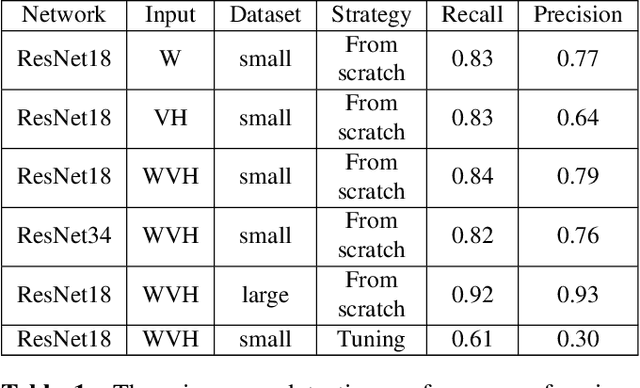
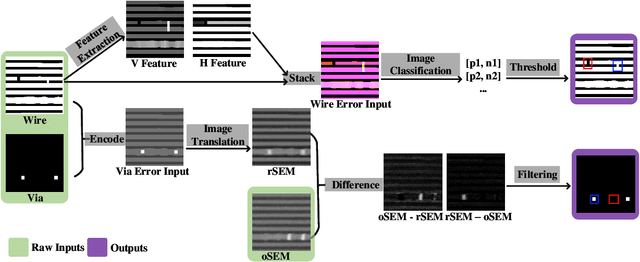

Due to the complicated nanoscale structures of current integrated circuits(IC) builds and low error tolerance of IC image segmentation tasks, most existing automated IC image segmentation approaches require human experts for visual inspection to ensure correctness, which is one of the major bottlenecks in large-scale industrial applications. In this paper, we present the first data-driven automatic error detection approach targeting two types of IC segmentation errors: wire errors and via errors. On an IC image dataset collected from real industry, we demonstrate that, by adapting existing CNN-based approaches of image classification and image translation with additional pre-processing and post-processing techniques, we are able to achieve recall/precision of 0.92/0.93 in wire error detection and 0.96/0.90 in via error detection, respectively.
MAGE: MAsked Generative Encoder to Unify Representation Learning and Image Synthesis
Nov 16, 2022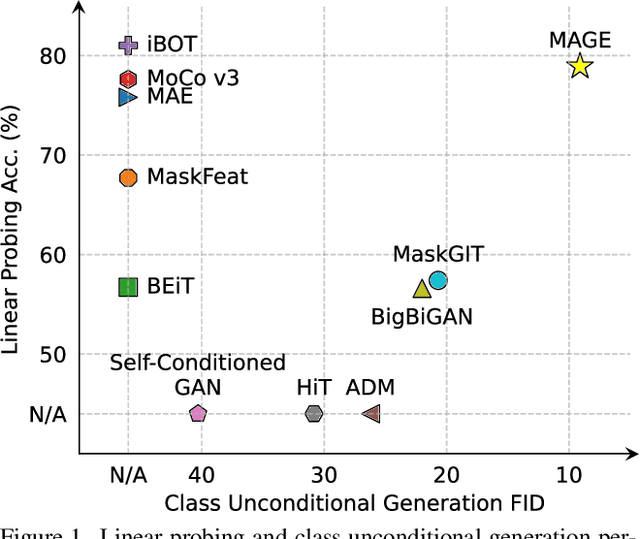
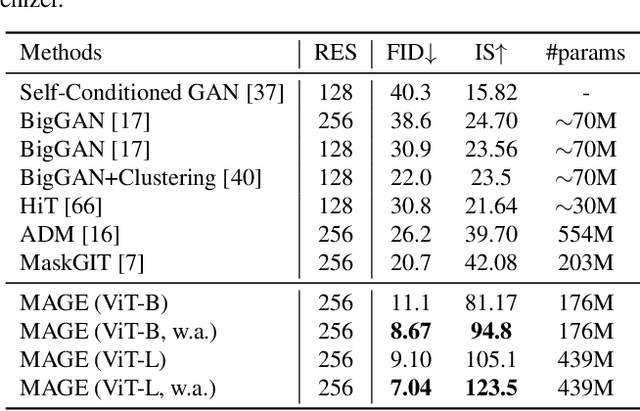

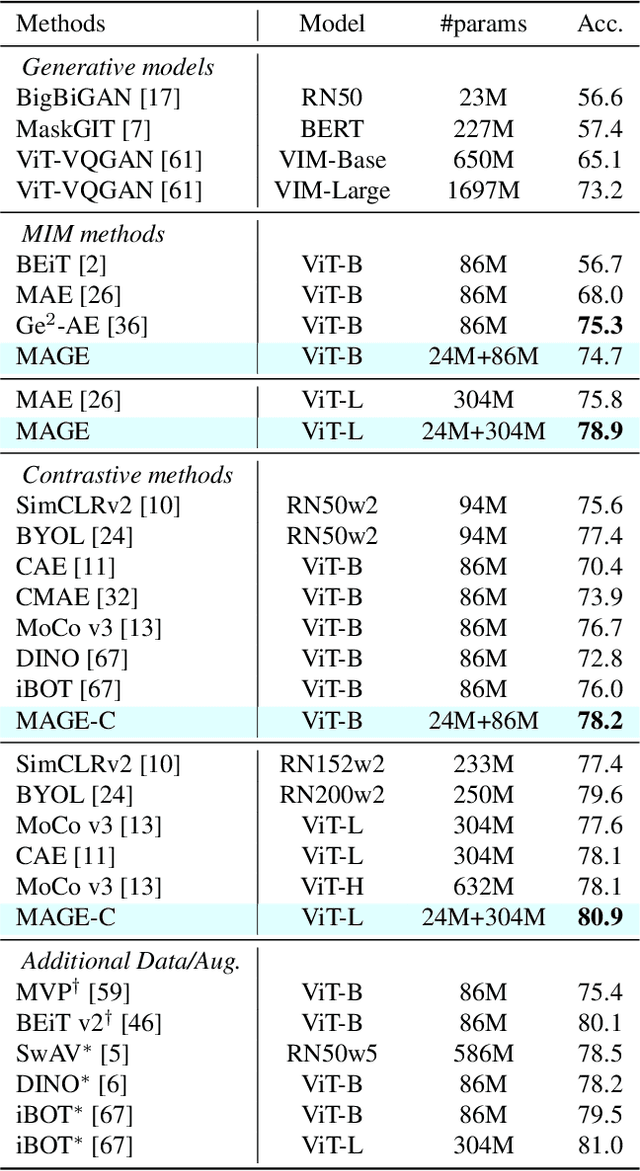
Generative modeling and representation learning are two key tasks in computer vision. However, these models are typically trained independently, which ignores the potential for each task to help the other, and leads to training and model maintenance overheads. In this work, we propose MAsked Generative Encoder (MAGE), the first framework to unify SOTA image generation and self-supervised representation learning. Our key insight is that using variable masking ratios in masked image modeling pre-training can allow generative training (very high masking ratio) and representation learning (lower masking ratio) under the same training framework. Inspired by previous generative models, MAGE uses semantic tokens learned by a vector-quantized GAN at inputs and outputs, combining this with masking. We can further improve the representation by adding a contrastive loss to the encoder output. We extensively evaluate the generation and representation learning capabilities of MAGE. On ImageNet-1K, a single MAGE ViT-L model obtains 9.10 FID in the task of class-unconditional image generation and 78.9% top-1 accuracy for linear probing, achieving state-of-the-art performance in both image generation and representation learning. Code is available at https://github.com/LTH14/mage.
Unsupervised Domain Adaptation for Training Event-Based Networks Using Contrastive Learning and Uncorrelated Conditioning
Mar 22, 2023
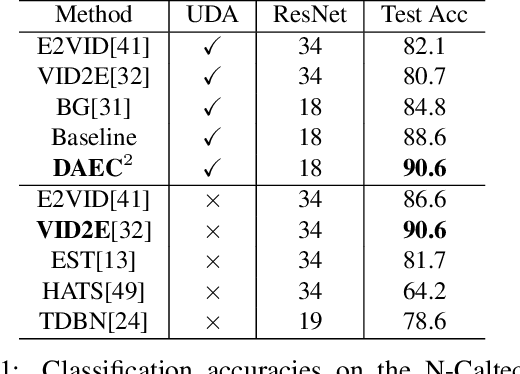
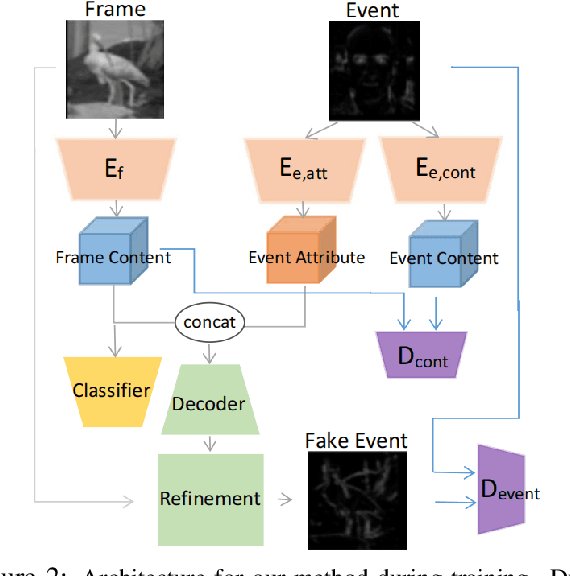
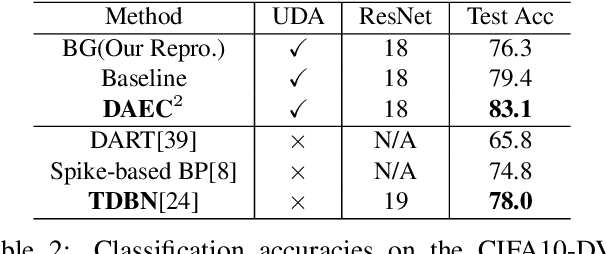
Event-based cameras offer reliable measurements for preforming computer vision tasks in high-dynamic range environments and during fast motion maneuvers. However, adopting deep learning in event-based vision faces the challenge of annotated data scarcity due to recency of event cameras. Transferring the knowledge that can be obtained from conventional camera annotated data offers a practical solution to this challenge. We develop an unsupervised domain adaptation algorithm for training a deep network for event-based data image classification using contrastive learning and uncorrelated conditioning of data. Our solution outperforms the existing algorithms for this purpose.
Monocular Depth Estimation using Diffusion Models
Feb 28, 2023
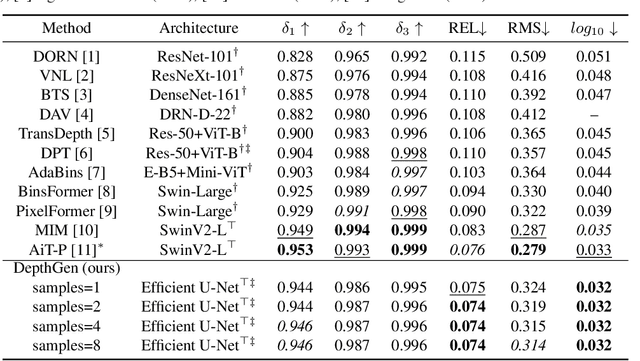
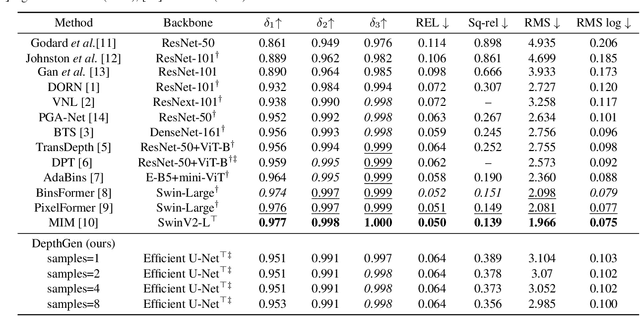

We formulate monocular depth estimation using denoising diffusion models, inspired by their recent successes in high fidelity image generation. To that end, we introduce innovations to address problems arising due to noisy, incomplete depth maps in training data, including step-unrolled denoising diffusion, an $L_1$ loss, and depth infilling during training. To cope with the limited availability of data for supervised training, we leverage pre-training on self-supervised image-to-image translation tasks. Despite the simplicity of the approach, with a generic loss and architecture, our DepthGen model achieves SOTA performance on the indoor NYU dataset, and near SOTA results on the outdoor KITTI dataset. Further, with a multimodal posterior, DepthGen naturally represents depth ambiguity (e.g., from transparent surfaces), and its zero-shot performance combined with depth imputation, enable a simple but effective text-to-3D pipeline. Project page: https://depth-gen.github.io