 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Pinpointing Why Object Recognition Performance Degrades Across Income Levels and Geographies
Apr 11, 2023
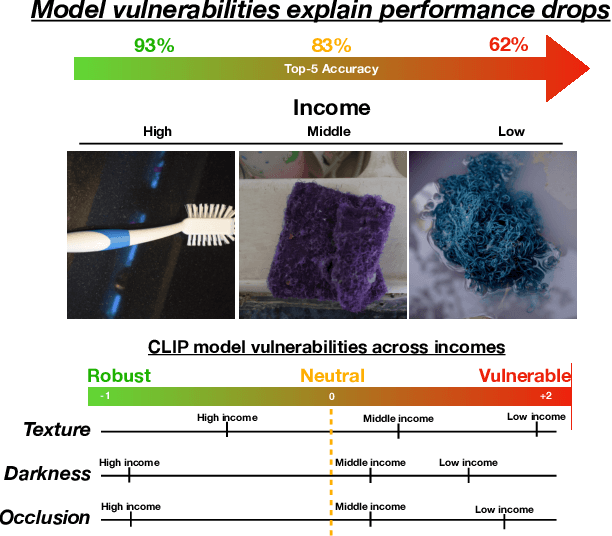
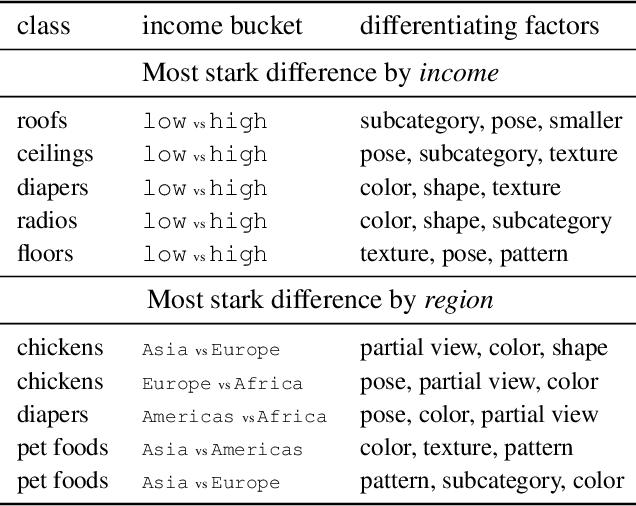
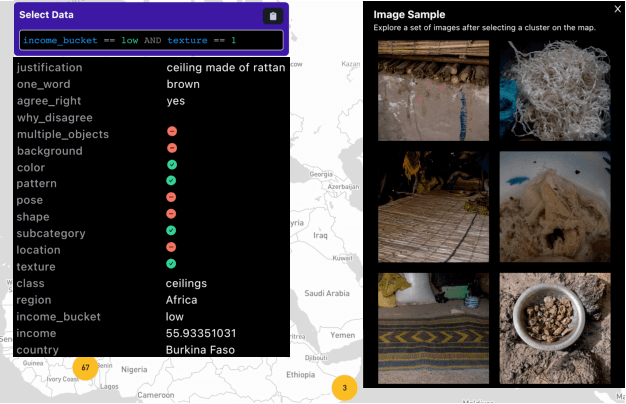

Despite impressive advances in object-recognition, deep learning systems' performance degrades significantly across geographies and lower income levels raising pressing concerns of inequity. Addressing such performance gaps remains a challenge, as little is understood about why performance degrades across incomes or geographies. We take a step in this direction by annotating images from Dollar Street, a popular benchmark of geographically and economically diverse images, labeling each image with factors such as color, shape, and background. These annotations unlock a new granular view into how objects differ across incomes and regions. We then use these object differences to pinpoint model vulnerabilities across incomes and regions. We study a range of modern vision models, finding that performance disparities are most associated with differences in texture, occlusion, and images with darker lighting. We illustrate how insights from our factor labels can surface mitigations to improve models' performance disparities. As an example, we show that mitigating a model's vulnerability to texture can improve performance on the lower income level. We release all the factor annotations along with an interactive dashboard to facilitate research into more equitable vision systems.
Non-pooling Network for medical image segmentation
Feb 21, 2023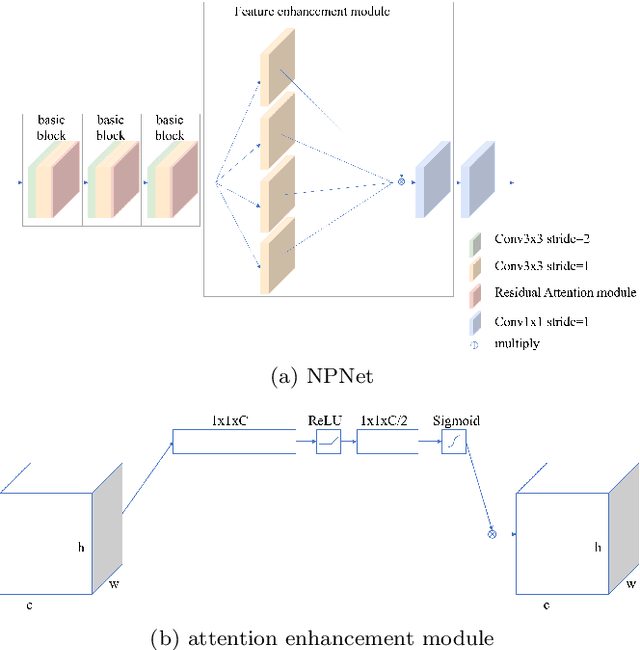
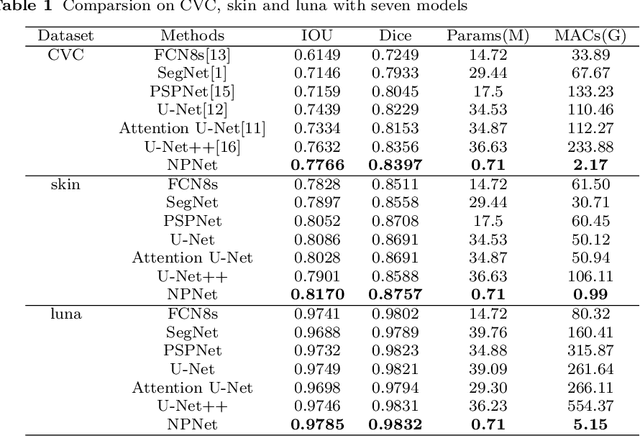
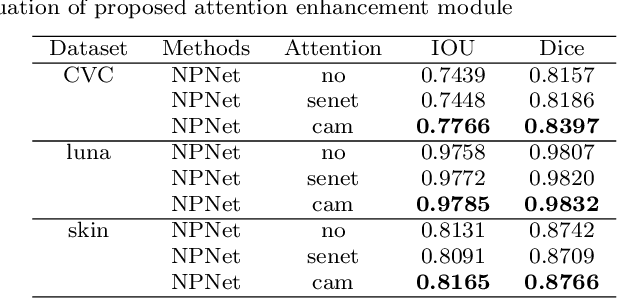
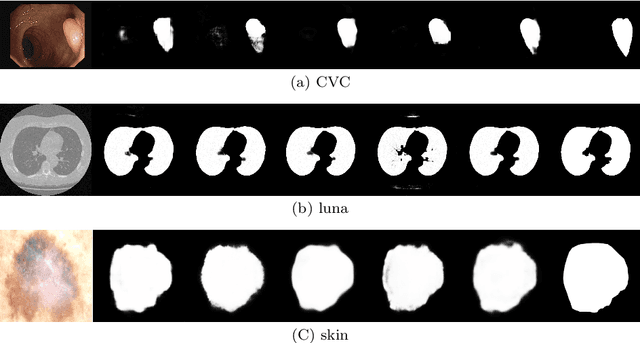
Existing studies tend tofocus onmodel modifications and integration with higher accuracy, which improve performance but also carry huge computational costs, resulting in longer detection times. Inmedical imaging, the use of time is extremely sensitive. And at present most of the semantic segmentation models have encoder-decoder structure or double branch structure. Their several times of the pooling use with high-level semantic information extraction operation cause information loss although there si a reverse pooling or other similar action to restore information loss of pooling operation. In addition, we notice that visual attention mechanism has superior performance on a variety of tasks. Given this, this paper proposes non-pooling network(NPNet), non-pooling commendably reduces the loss of information and attention enhancement m o d u l e ( A M ) effectively increases the weight of useful information. The method greatly reduces the number of parametersand computation costs by the shallow neural network structure. We evaluate the semantic segmentation model of our NPNet on three benchmark datasets comparing w i t h multiple current state-of-the-art(SOTA) models, and the implementation results show thatour NPNetachieves SOTA performance, with an excellent balance between accuracyand speed.
Human Evaluation of Text-to-Image Models on a Multi-Task Benchmark
Nov 22, 2022
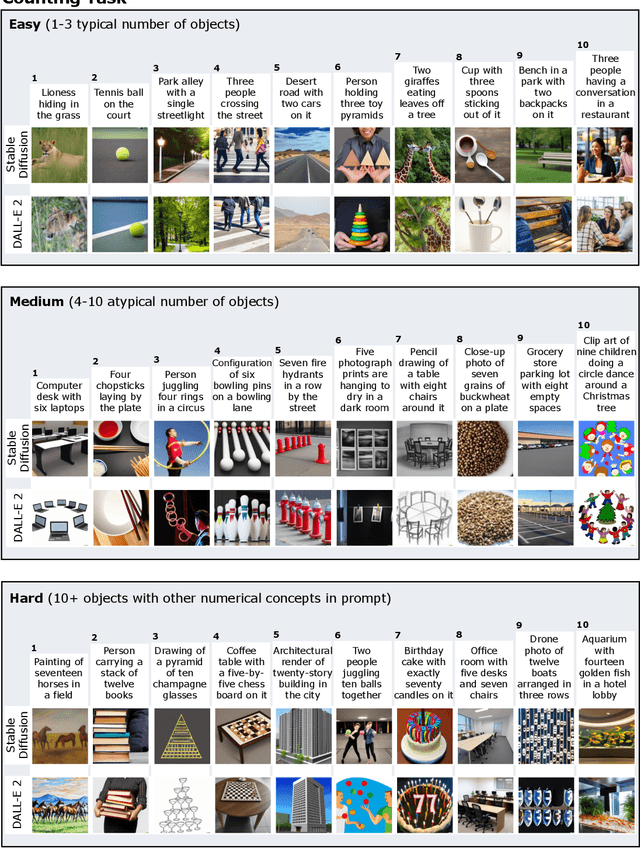

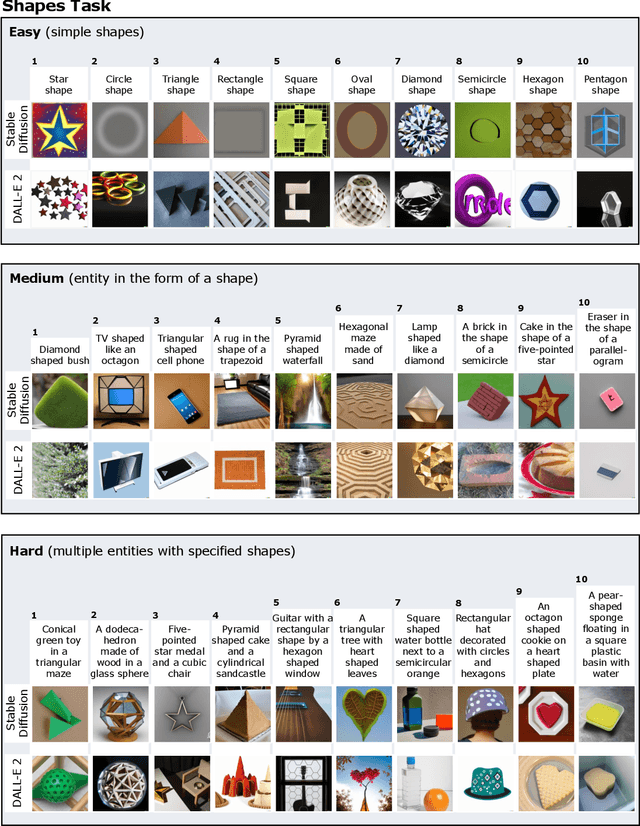
We provide a new multi-task benchmark for evaluating text-to-image models. We perform a human evaluation comparing the most common open-source (Stable Diffusion) and commercial (DALL-E 2) models. Twenty computer science AI graduate students evaluated the two models, on three tasks, at three difficulty levels, across ten prompts each, providing 3,600 ratings. Text-to-image generation has seen rapid progress to the point that many recent models have demonstrated their ability to create realistic high-resolution images for various prompts. However, current text-to-image methods and the broader body of research in vision-language understanding still struggle with intricate text prompts that contain many objects with multiple attributes and relationships. We introduce a new text-to-image benchmark that contains a suite of thirty-two tasks over multiple applications that capture a model's ability to handle different features of a text prompt. For example, asking a model to generate a varying number of the same object to measure its ability to count or providing a text prompt with several objects that each have a different attribute to identify its ability to match objects and attributes correctly. Rather than subjectively evaluating text-to-image results on a set of prompts, our new multi-task benchmark consists of challenge tasks at three difficulty levels (easy, medium, and hard) and human ratings for each generated image.
EvidenceCap: Towards trustworthy medical image segmentation via evidential identity cap
Jan 01, 2023
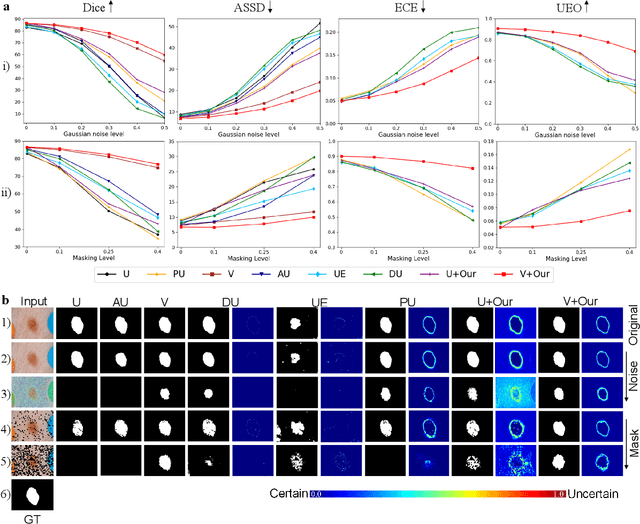
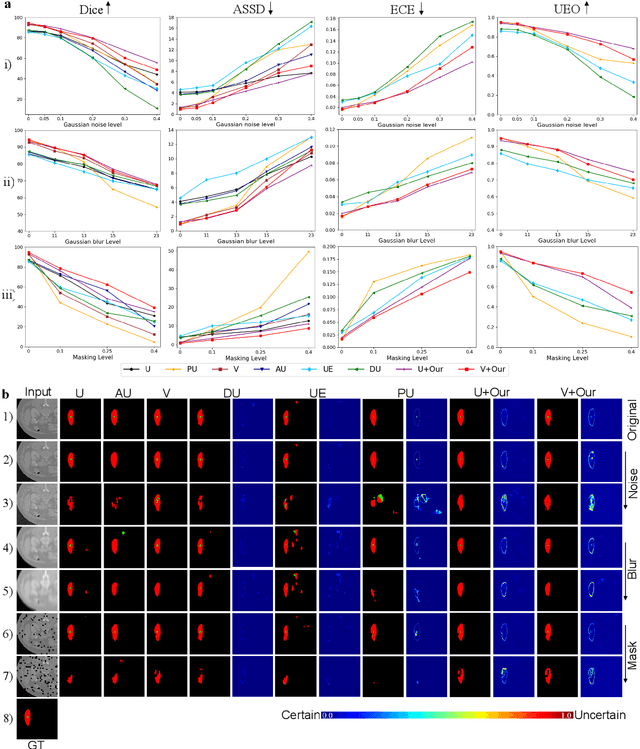
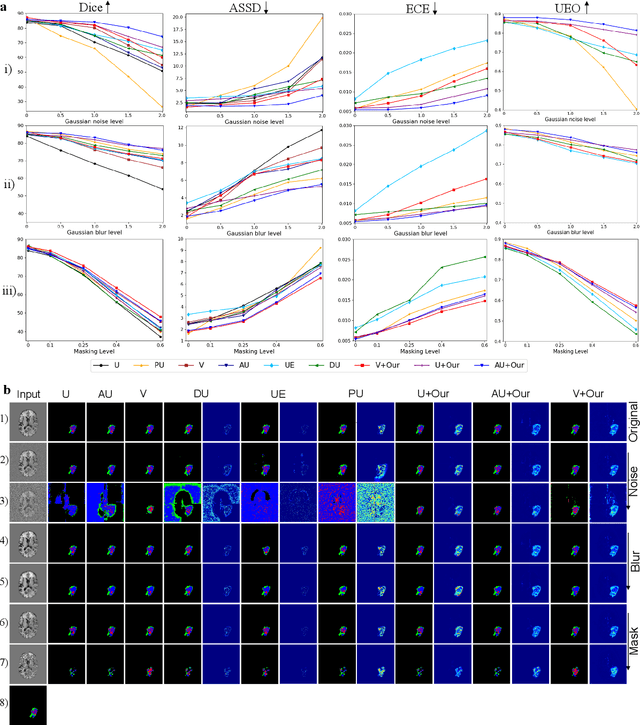
Medical image segmentation (MIS) is essential for supporting disease diagnosis and treatment effect assessment. Despite considerable advances in artificial intelligence (AI) for MIS, clinicians remain skeptical of its utility, maintaining low confidence in such black box systems, with this problem being exacerbated by low generalization for out-of-distribution (OOD) data. To move towards effective clinical utilization, we propose a foundation model named EvidenceCap, which makes the box transparent in a quantifiable way by uncertainty estimation. EvidenceCap not only makes AI visible in regions of uncertainty and OOD data, but also enhances the reliability, robustness, and computational efficiency of MIS. Uncertainty is modeled explicitly through subjective logic theory to gather strong evidence from features. We show the effectiveness of EvidenceCap in three segmentation datasets and apply it to the clinic. Our work sheds light on clinical safe applications and explainable AI, and can contribute towards trustworthiness in the medical domain.
Attacking Image Splicing Detection and Localization Algorithms Using Synthetic Traces
Nov 22, 2022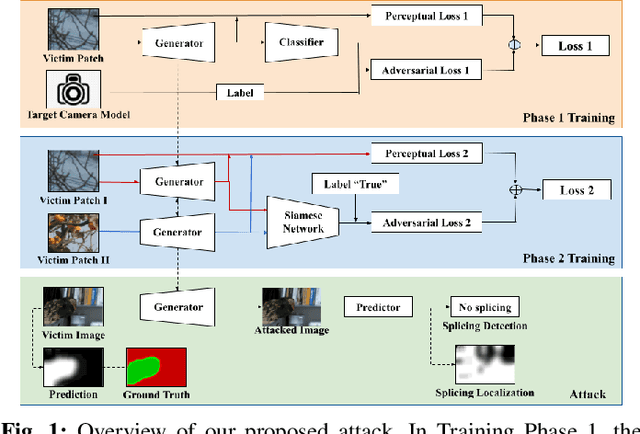


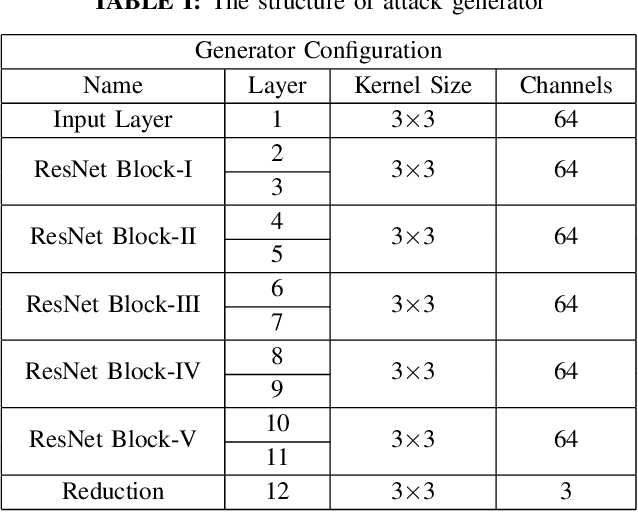
Recent advances in deep learning have enabled forensics researchers to develop a new class of image splicing detection and localization algorithms. These algorithms identify spliced content by detecting localized inconsistencies in forensic traces using Siamese neural networks, either explicitly during analysis or implicitly during training. At the same time, deep learning has enabled new forms of anti-forensic attacks, such as adversarial examples and generative adversarial network (GAN) based attacks. Thus far, however, no anti-forensic attack has been demonstrated against image splicing detection and localization algorithms. In this paper, we propose a new GAN-based anti-forensic attack that is able to fool state-of-the-art splicing detection and localization algorithms such as EXIF-Net, Noiseprint, and Forensic Similarity Graphs. This attack operates by adversarially training an anti-forensic generator against a set of Siamese neural networks so that it is able to create synthetic forensic traces. Under analysis, these synthetic traces appear authentic and are self-consistent throughout an image. Through a series of experiments, we demonstrate that our attack is capable of fooling forensic splicing detection and localization algorithms without introducing visually detectable artifacts into an attacked image. Additionally, we demonstrate that our attack outperforms existing alternative attack approaches. %
Model Predictive Control with Self-supervised Representation Learning
Apr 14, 2023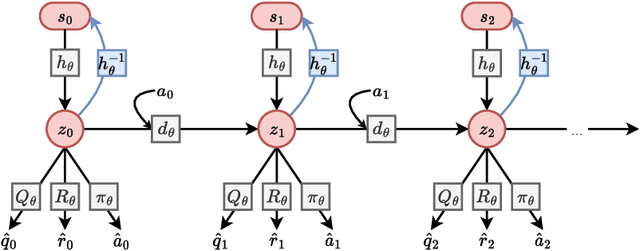
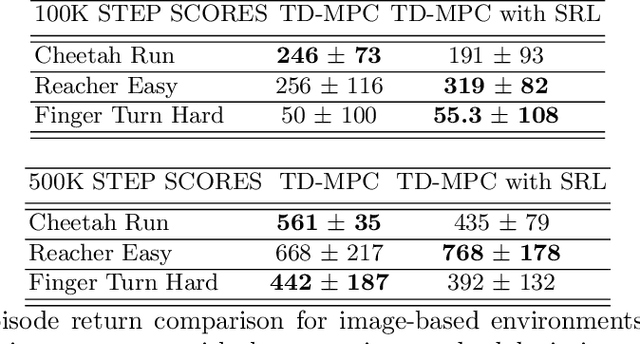
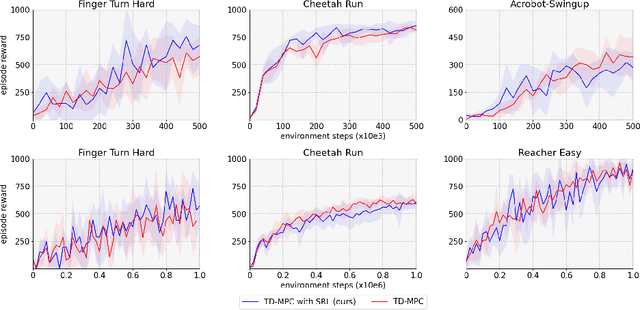
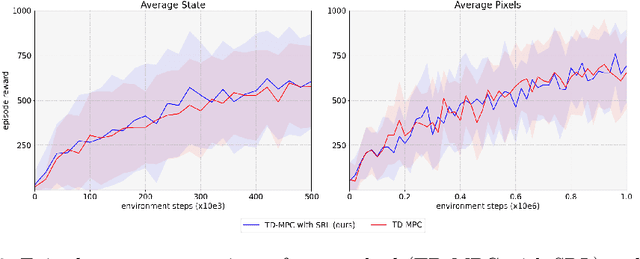
Over the last few years, we have not seen any major developments in model-free or model-based learning methods that would make one obsolete relative to the other. In most cases, the used technique is heavily dependent on the use case scenario or other attributes, e.g. the environment. Both approaches have their own advantages, for example, sample efficiency or computational efficiency. However, when combining the two, the advantages of each can be combined and hence achieve better performance. The TD-MPC framework is an example of this approach. On the one hand, a world model in combination with model predictive control is used to get a good initial estimate of the value function. On the other hand, a Q function is used to provide a good long-term estimate. Similar to algorithms like MuZero a latent state representation is used, where only task-relevant information is encoded to reduce the complexity. In this paper, we propose the use of a reconstruction function within the TD-MPC framework, so that the agent can reconstruct the original observation given the internal state representation. This allows our agent to have a more stable learning signal during training and also improves sample efficiency. Our proposed addition of another loss term leads to improved performance on both state- and image-based tasks from the DeepMind-Control suite.
DGD-cGAN: A Dual Generator for Image Dewatering and Restoration
Nov 18, 2022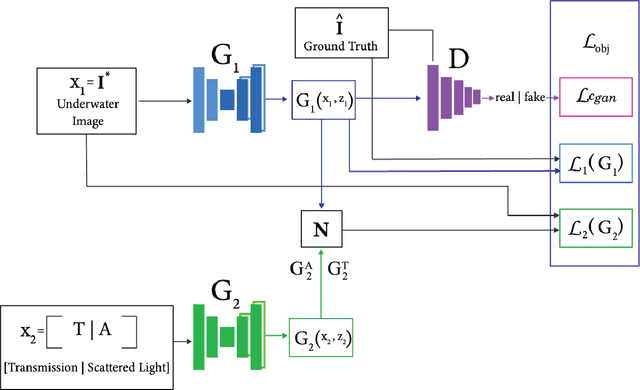
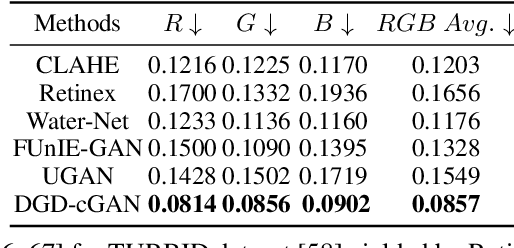
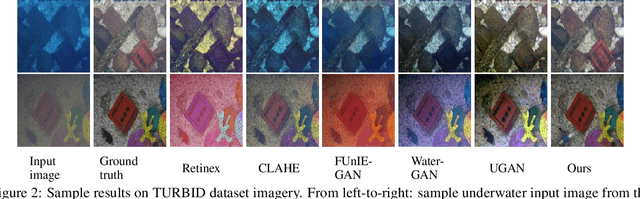
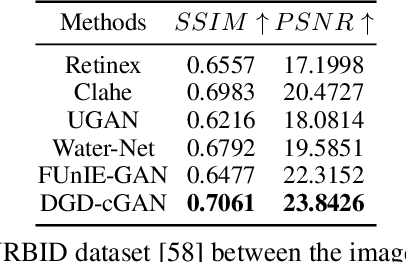
Underwater images are usually covered with a blue-greenish colour cast, making them distorted, blurry or low in contrast. This phenomenon occurs due to the light attenuation given by the scattering and absorption in the water column. In this paper, we present an image enhancement approach for dewatering which employs a conditional generative adversarial network (cGAN) with two generators. Our Dual Generator Dewatering cGAN (DGD-cGAN) removes the haze and colour cast induced by the water column and restores the true colours of underwater scenes whereby the effects of various attenuation and scattering phenomena that occur in underwater images are tackled by the two generators. The first generator takes at input the underwater image and predicts the dewatered scene, while the second generator learns the underwater image formation process by implementing a custom loss function based upon the transmission and the veiling light components of the image formation model. Our experiments show that DGD-cGAN consistently delivers a margin of improvement as compared with the state-of-the-art methods on several widely available datasets.
Indescribable Multi-modal Spatial Evaluator
Mar 01, 2023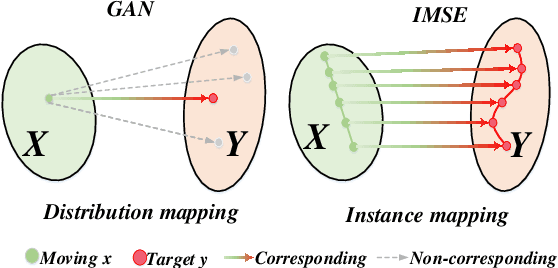

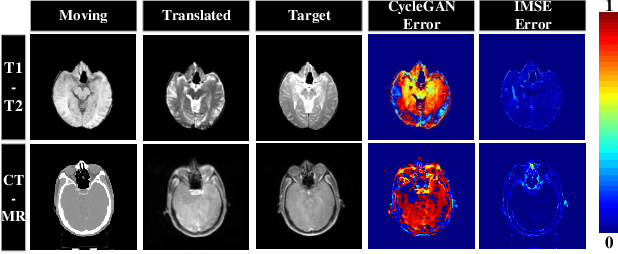
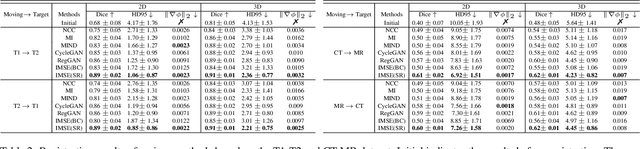
Multi-modal image registration spatially aligns two images with different distributions. One of its major challenges is that images acquired from different imaging machines have different imaging distributions, making it difficult to focus only on the spatial aspect of the images and ignore differences in distributions. In this study, we developed a self-supervised approach, Indescribable Multi-model Spatial Evaluator (IMSE), to address multi-modal image registration. IMSE creates an accurate multi-modal spatial evaluator to measure spatial differences between two images, and then optimizes registration by minimizing the error predicted of the evaluator. To optimize IMSE performance, we also proposed a new style enhancement method called Shuffle Remap which randomizes the image distribution into multiple segments, and then randomly disorders and remaps these segments, so that the distribution of the original image is changed. Shuffle Remap can help IMSE to predict the difference in spatial location from unseen target distributions. Our results show that IMSE outperformed the existing methods for registration using T1-T2 and CT-MRI datasets. IMSE also can be easily integrated into the traditional registration process, and can provide a convenient way to evaluate and visualize registration results. IMSE also has the potential to be used as a new paradigm for image-to-image translation. Our code is available at https://github.com/Kid-Liet/IMSE.
Generative Novel View Synthesis with 3D-Aware Diffusion Models
Apr 05, 2023
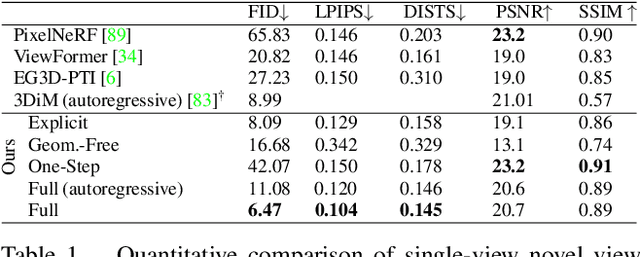

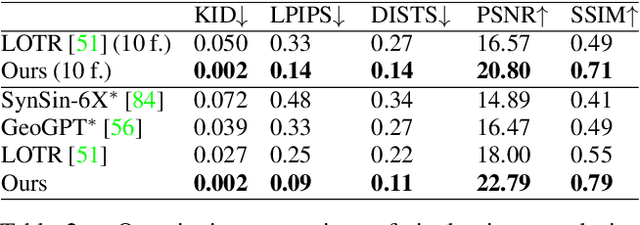
We present a diffusion-based model for 3D-aware generative novel view synthesis from as few as a single input image. Our model samples from the distribution of possible renderings consistent with the input and, even in the presence of ambiguity, is capable of rendering diverse and plausible novel views. To achieve this, our method makes use of existing 2D diffusion backbones but, crucially, incorporates geometry priors in the form of a 3D feature volume. This latent feature field captures the distribution over possible scene representations and improves our method's ability to generate view-consistent novel renderings. In addition to generating novel views, our method has the ability to autoregressively synthesize 3D-consistent sequences. We demonstrate state-of-the-art results on synthetic renderings and room-scale scenes; we also show compelling results for challenging, real-world objects.
MOREA: a GPU-accelerated Evolutionary Algorithm for Multi-Objective Deformable Registration of 3D Medical Images
Mar 08, 2023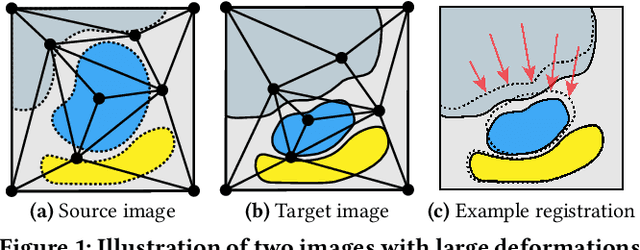

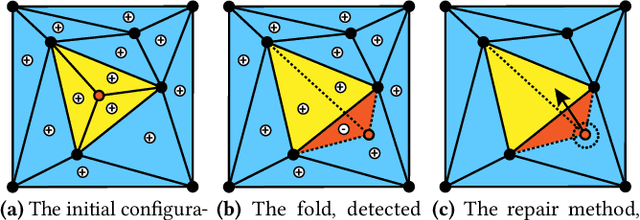
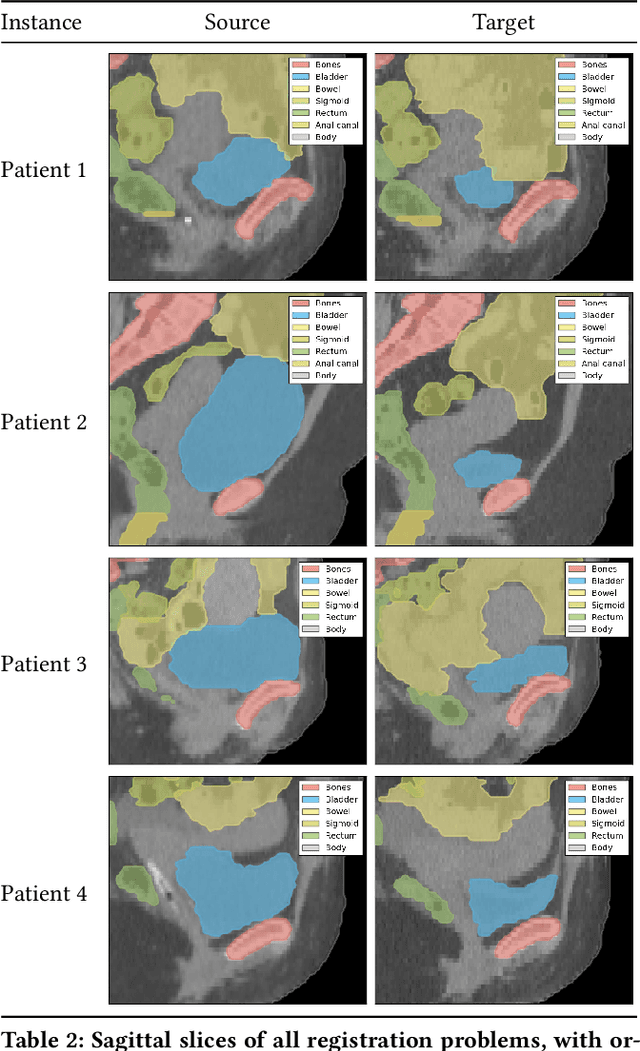
Finding a realistic deformation that transforms one image into another, in case large deformations are required, is considered a key challenge in medical image analysis. Having a proper image registration approach to achieve this could unleash a number of applications requiring information to be transferred between images. Clinical adoption is currently hampered by many existing methods requiring extensive configuration effort before each use, or not being able to (realistically) capture large deformations. A recent multi-objective approach that uses the Multi-Objective Real-Valued Gene-pool Optimal Mixing Evolutionary Algorithm (MO-RV-GOMEA) and a dual-dynamic mesh transformation model has shown promise, exposing the trade-offs inherent to image registration problems and modeling large deformations in 2D. This work builds on this promise and introduces MOREA: the first evolutionary algorithm-based multi-objective approach to deformable registration of 3D images capable of tackling large deformations. MOREA includes a 3D biomechanical mesh model for physical plausibility and is fully GPU-accelerated. We compare MOREA to two state-of-the-art approaches on abdominal CT scans of 4 cervical cancer patients, with the latter two approaches configured for the best results per patient. Without requiring per-patient configuration, MOREA significantly outperforms these approaches on 3 of the 4 patients that represent the most difficult cases.