 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Extreme Generative Image Compression by Learning Text Embedding from Diffusion Models
Nov 14, 2022

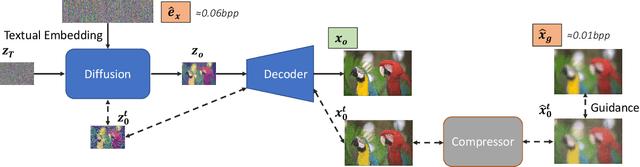
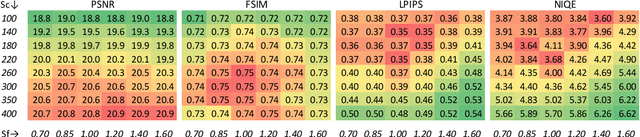
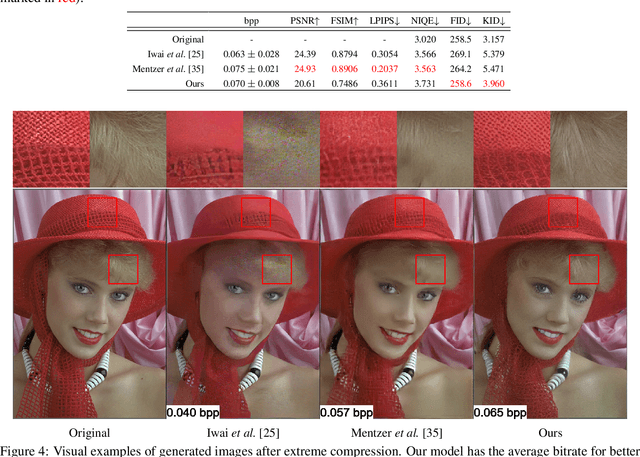
Transferring large amount of high resolution images over limited bandwidth is an important but very challenging task. Compressing images using extremely low bitrates (<0.1 bpp) has been studied but it often results in low quality images of heavy artifacts due to the strong constraint in the number of bits available for the compressed data. It is often said that a picture is worth a thousand words but on the other hand, language is very powerful in capturing the essence of an image using short descriptions. With the recent success of diffusion models for text-to-image generation, we propose a generative image compression method that demonstrates the potential of saving an image as a short text embedding which in turn can be used to generate high-fidelity images which is equivalent to the original one perceptually. For a given image, its corresponding text embedding is learned using the same optimization process as the text-to-image diffusion model itself, using a learnable text embedding as input after bypassing the original transformer. The optimization is applied together with a learning compression model to achieve extreme compression of low bitrates <0.1 bpp. Based on our experiments measured by a comprehensive set of image quality metrics, our method outperforms the other state-of-the-art deep learning methods in terms of both perceptual quality and diversity.
Enhancing Electrical Impedance Tomography reconstruction using Learned Half-Quadratic Splitting Networks with Anderson Acceleration
Apr 16, 2023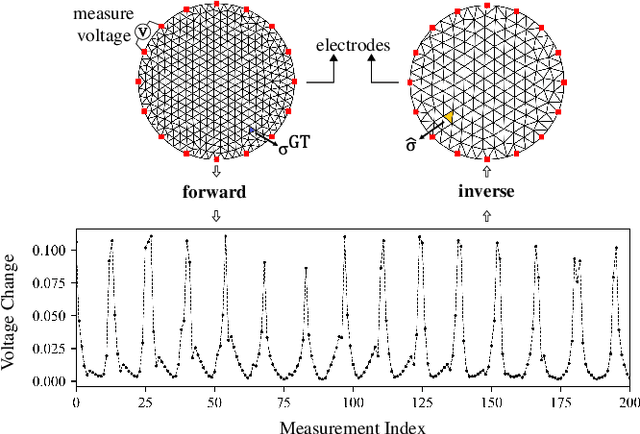

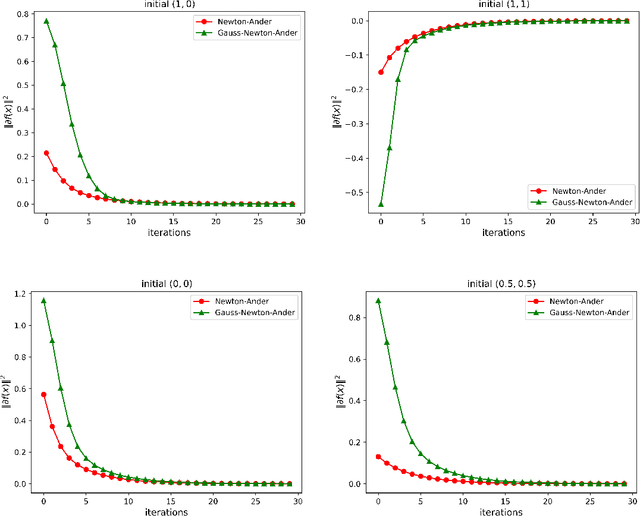
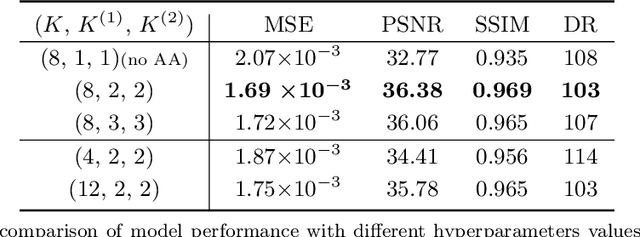
Electrical Impedance Tomography (EIT) is widely applied in medical diagnosis, industrial inspection, and environmental monitoring. Combining the physical principles of the imaging system with the advantages of data-driven deep learning networks, physics-embedded deep unrolling networks have recently emerged as a promising solution in computational imaging. However, the inherent nonlinear and ill-posed properties of EIT image reconstruction still present challenges to existing methods in terms of accuracy and stability. To tackle this challenge, we propose the learned half-quadratic splitting (HQSNet) algorithm for incorporating physics into learning-based EIT imaging. We then apply Anderson acceleration (AA) to the HQSNet algorithm, denoted as AA-HQSNet, which can be interpreted as AA applied to the Gauss-Newton step and the learned proximal gradient descent step of the HQSNet, respectively. AA is a widely-used technique for accelerating the convergence of fixed-point iterative algorithms and has gained significant interest in numerical optimization and machine learning. However, the technique has received little attention in the inverse problems community thus far. Employing AA enhances the convergence rate compared to the standard HQSNet while simultaneously avoiding artifacts in the reconstructions. Lastly, we conduct rigorous numerical and visual experiments to show that the AA module strengthens the HQSNet, leading to robust, accurate, and considerably superior reconstructions compared to state-of-the-art methods. Our Anderson acceleration scheme to enhance HQSNet is generic and can be applied to improve the performance of various physics-embedded deep learning methods.
Adaptive Base-class Suppression and Prior Guidance Network for One-Shot Object Detection
Mar 24, 2023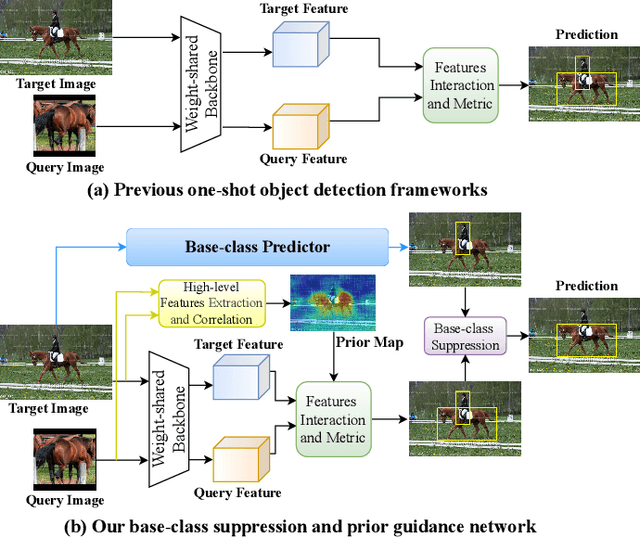
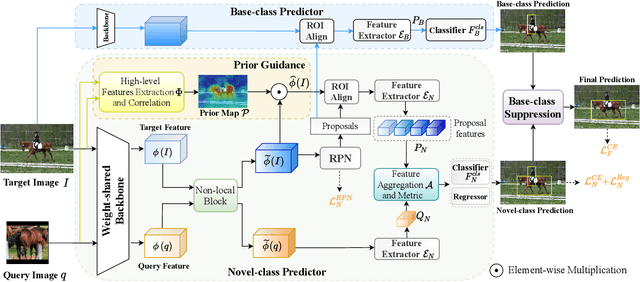
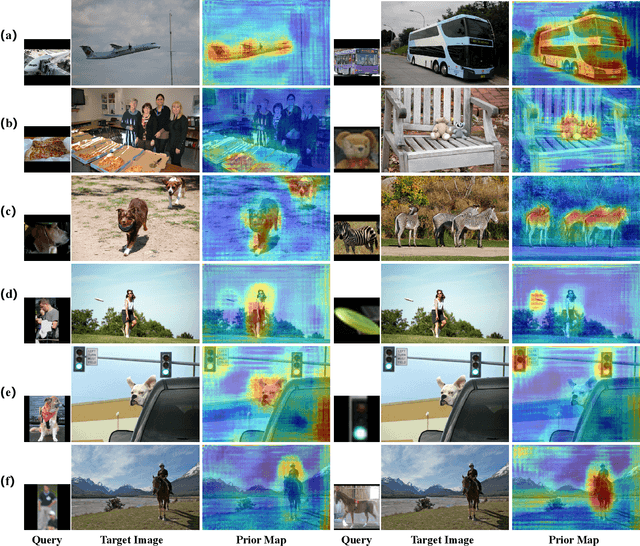
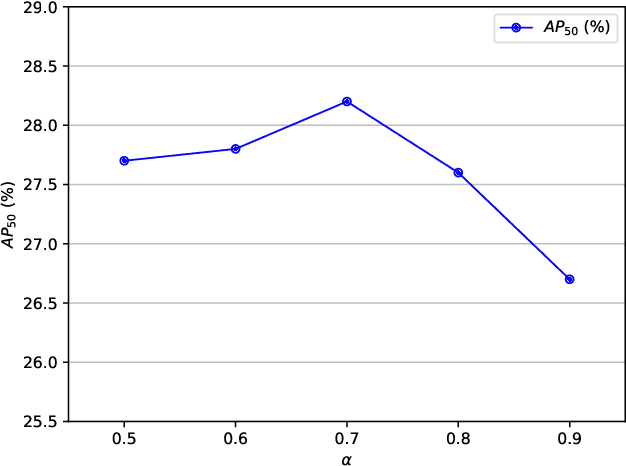
One-shot object detection (OSOD) aims to detect all object instances towards the given category specified by a query image. Most existing studies in OSOD endeavor to explore effective cross-image correlation and alleviate the semantic feature misalignment, however, ignoring the phenomenon of the model bias towards the base classes and the generalization degradation on the novel classes. Observing this, we propose a novel framework, namely Base-class Suppression and Prior Guidance (BSPG) network to overcome the problem. Specifically, the objects of base categories can be explicitly detected by a base-class predictor and adaptively eliminated by our base-class suppression module. Moreover, a prior guidance module is designed to calculate the correlation of high-level features in a non-parametric manner, producing a class-agnostic prior map to provide the target features with rich semantic cues and guide the subsequent detection process. Equipped with the proposed two modules, we endow the model with a strong discriminative ability to distinguish the target objects from distractors belonging to the base classes. Extensive experiments show that our method outperforms the previous techniques by a large margin and achieves new state-of-the-art performance under various evaluation settings.
Perceptual Quality Assessment of NeRF and Neural View Synthesis Methods for Front-Facing Views
Mar 24, 2023
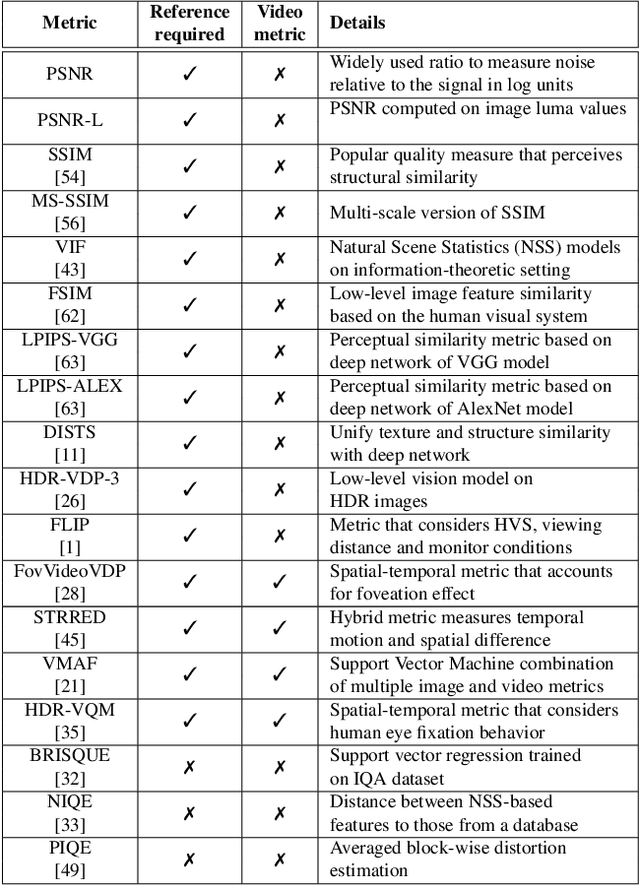
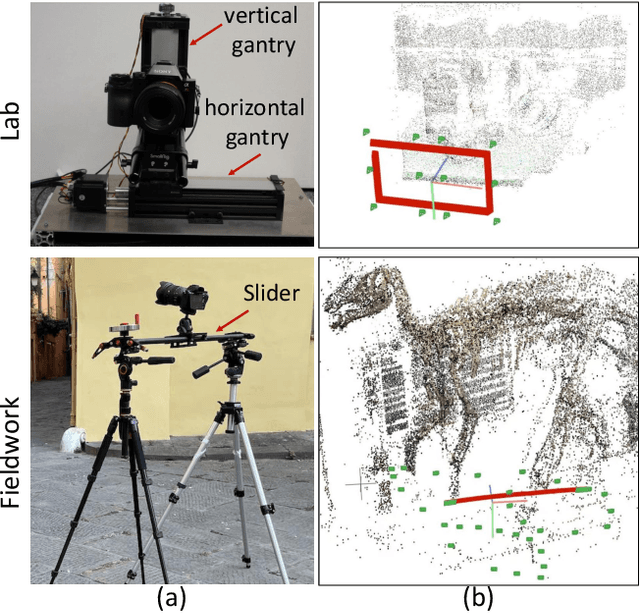

Neural view synthesis (NVS) is one of the most successful techniques for synthesizing free viewpoint videos, capable of achieving high fidelity from only a sparse set of captured images. This success has led to many variants of the techniques, each evaluated on a set of test views typically using image quality metrics such as PSNR, SSIM, or LPIPS. There has been a lack of research on how NVS methods perform with respect to perceived video quality. We present the first study on perceptual evaluation of NVS and NeRF variants. For this study, we collected two datasets of scenes captured in a controlled lab environment as well as in-the-wild. In contrast to existing datasets, these scenes come with reference video sequences, allowing us to test for temporal artifacts and subtle distortions that are easily overlooked when viewing only static images. We measured the quality of videos synthesized by several NVS methods in a well-controlled perceptual quality assessment experiment as well as with many existing state-of-the-art image/video quality metrics. We present a detailed analysis of the results and recommendations for dataset and metric selection for NVS evaluation.
Unsupervised Traffic Scene Generation with Synthetic 3D Scene Graphs
Mar 15, 2023
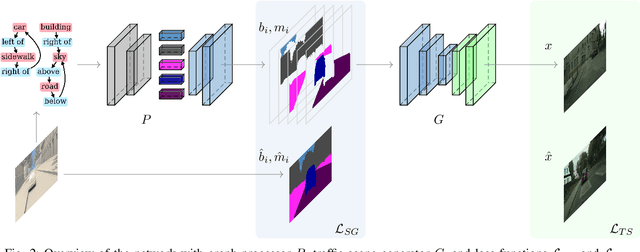
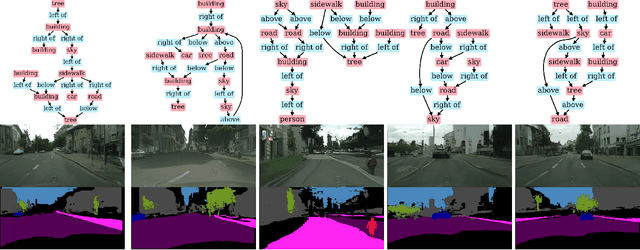
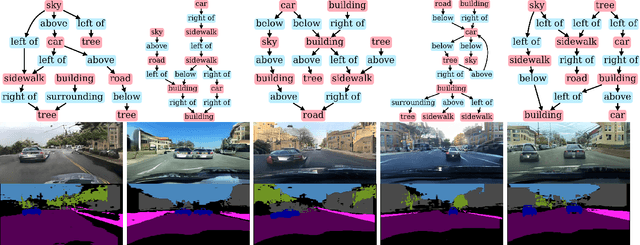
Image synthesis driven by computer graphics achieved recently a remarkable realism, yet synthetic image data generated this way reveals a significant domain gap with respect to real-world data. This is especially true in autonomous driving scenarios, which represent a critical aspect for overcoming utilizing synthetic data for training neural networks. We propose a method based on domain-invariant scene representation to directly synthesize traffic scene imagery without rendering. Specifically, we rely on synthetic scene graphs as our internal representation and introduce an unsupervised neural network architecture for realistic traffic scene synthesis. We enhance synthetic scene graphs with spatial information about the scene and demonstrate the effectiveness of our approach through scene manipulation.
Medical visual question answering using joint self-supervised learning
Feb 25, 2023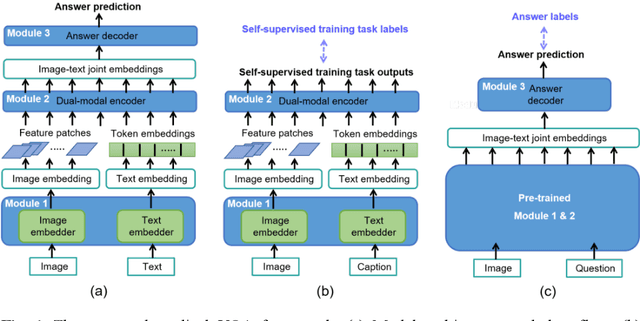

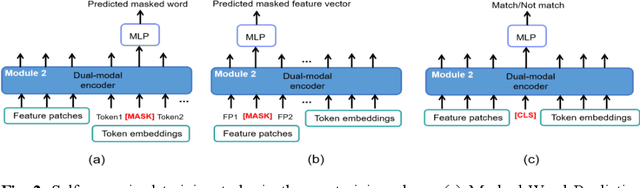
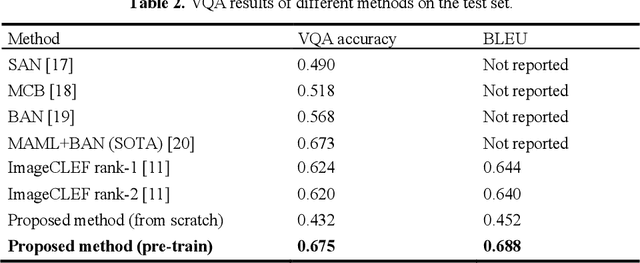
Visual Question Answering (VQA) becomes one of the most active research problems in the medical imaging domain. A well-known VQA challenge is the intrinsic diversity between the image and text modalities, and in the medical VQA task, there is another critical problem relying on the limited size of labelled image-question-answer data. In this study we propose an encoder-decoder framework that leverages the image-text joint representation learned from large-scaled medical image-caption data and adapted to the small-sized medical VQA task. The encoder embeds across the image-text dual modalities with self-attention mechanism and is independently pre-trained on the large-scaled medical image-caption dataset by multiple self-supervised learning tasks. Then the decoder is connected to the top of the encoder and fine-tuned using the small-sized medical VQA dataset. The experiment results present that our proposed method achieves better performance comparing with the baseline and SOTA methods.
Analysis of Tomographic Reconstruction of 2D Images using the Distribution of Unknown Projection Angles
Apr 13, 2023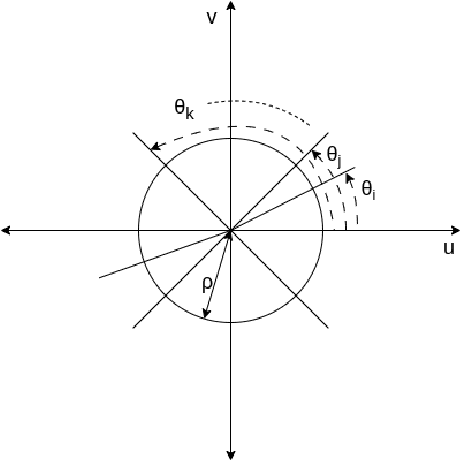
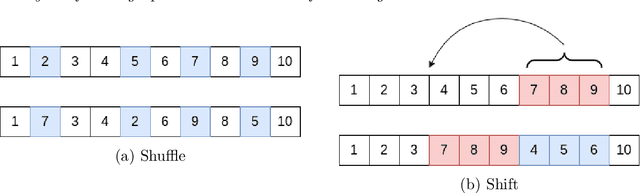
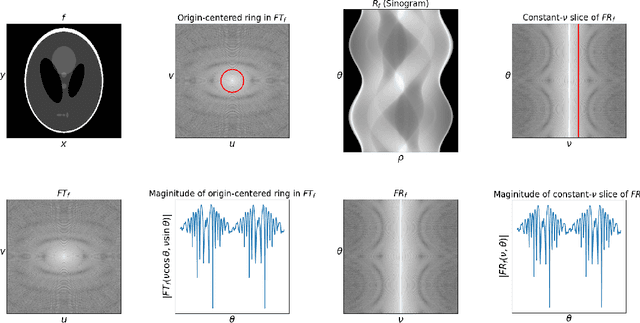
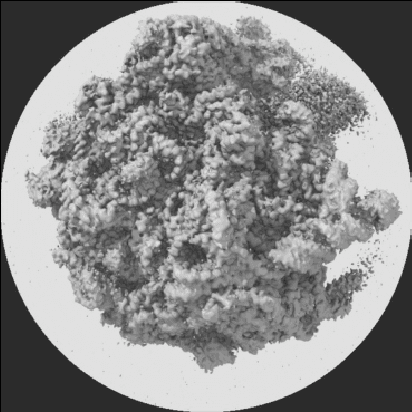
It is well known that a band-limited signal can be reconstructed from its uniformly spaced samples if the sampling rate is sufficiently high. More recently, it has been proved that one can reconstruct a 1D band-limited signal even if the exact sample locations are unknown, but given just the distribution of the sample locations and their ordering in 1D. In this work, we extend the analytical bounds on the reconstruction error in such scenarios for quasi-bandlimited signals. We also prove that the method for such a reconstruction is resilient to a certain proportion of errors in the specification of the sample location ordering. We then express the problem of tomographic reconstruction of 2D images from 1D Radon projections under unknown angles with known angle distribution, as a special case for reconstruction of quasi-bandlimited signals from samples at unknown locations with known distribution. Building upon our theoretical background, we present asymptotic bounds for 2D quasi-bandlimited image reconstruction from 1D Radon projections in the unknown angles setting, which commonly occurs in cryo-electron microscopy (cryo-EM). To the best of our knowledge, this is the first piece of work to perform such an analysis for 2D cryo-EM, even though the associated reconstruction algorithms have been known for a long time.
Learning Visual Representations via Language-Guided Sampling
Feb 23, 2023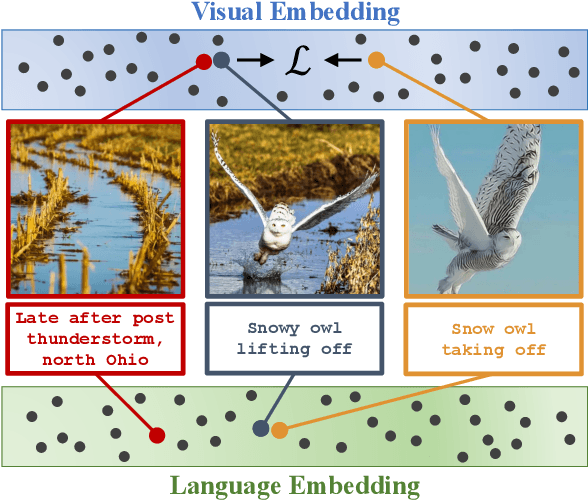
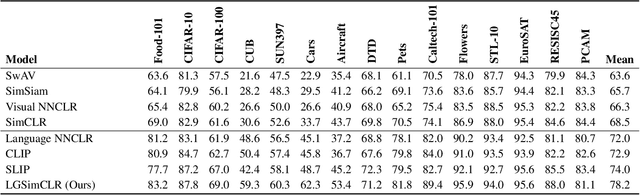


Although an object may appear in numerous contexts, we often describe it in a limited number of ways. This happens because language abstracts away visual variation to represent and communicate concepts. Building on this intuition, we propose an alternative approach to visual learning: using language similarity to sample semantically similar image pairs for contrastive learning. Our approach deviates from image-based contrastive learning by using language to sample pairs instead of hand-crafted augmentations or learned clusters. Our approach also deviates from image-text contrastive learning by relying on pre-trained language models to guide the learning rather than minimize a cross-modal similarity. Through a series of experiments, we show that language-guided learning can learn better features than both image-image and image-text representation learning approaches.
Human Evaluation of Text-to-Image Models on a Multi-Task Benchmark
Nov 22, 2022
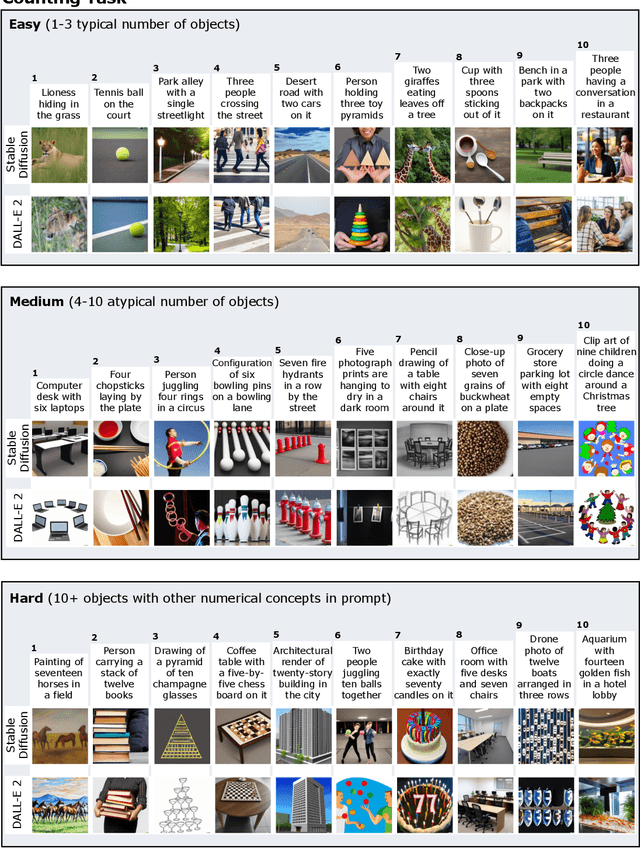

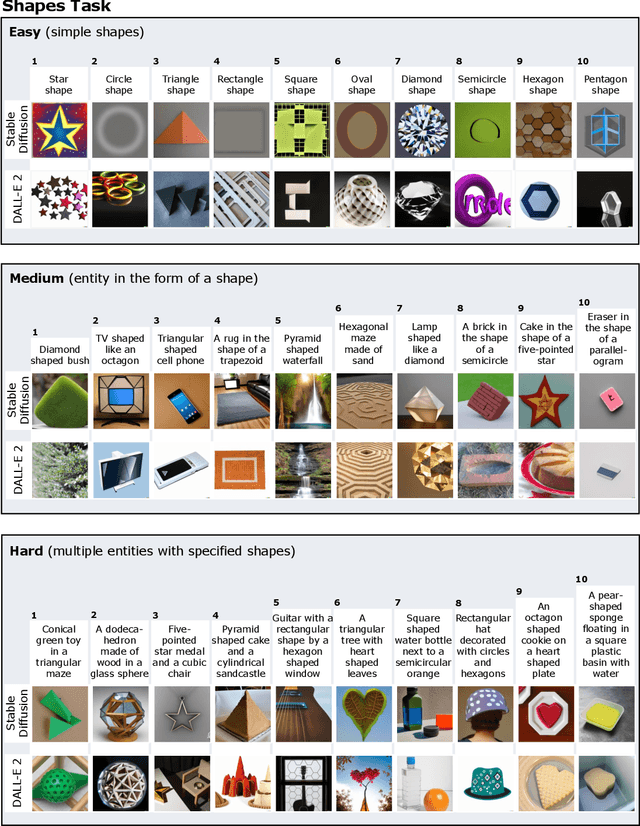
We provide a new multi-task benchmark for evaluating text-to-image models. We perform a human evaluation comparing the most common open-source (Stable Diffusion) and commercial (DALL-E 2) models. Twenty computer science AI graduate students evaluated the two models, on three tasks, at three difficulty levels, across ten prompts each, providing 3,600 ratings. Text-to-image generation has seen rapid progress to the point that many recent models have demonstrated their ability to create realistic high-resolution images for various prompts. However, current text-to-image methods and the broader body of research in vision-language understanding still struggle with intricate text prompts that contain many objects with multiple attributes and relationships. We introduce a new text-to-image benchmark that contains a suite of thirty-two tasks over multiple applications that capture a model's ability to handle different features of a text prompt. For example, asking a model to generate a varying number of the same object to measure its ability to count or providing a text prompt with several objects that each have a different attribute to identify its ability to match objects and attributes correctly. Rather than subjectively evaluating text-to-image results on a set of prompts, our new multi-task benchmark consists of challenge tasks at three difficulty levels (easy, medium, and hard) and human ratings for each generated image.
Spatial-Aware Token for Weakly Supervised Object Localization
Mar 18, 2023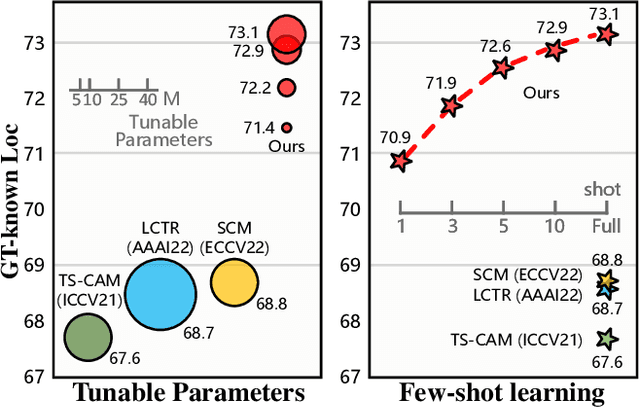
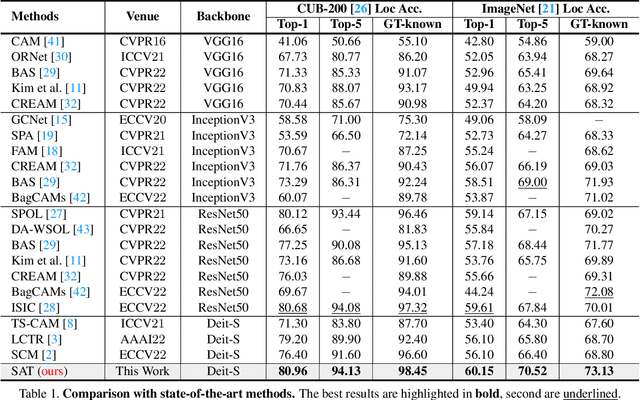
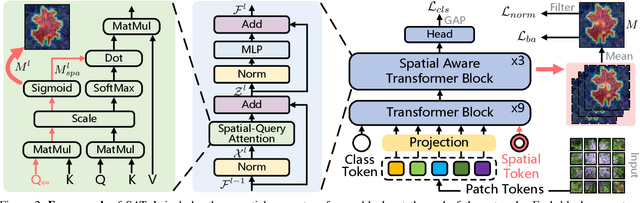
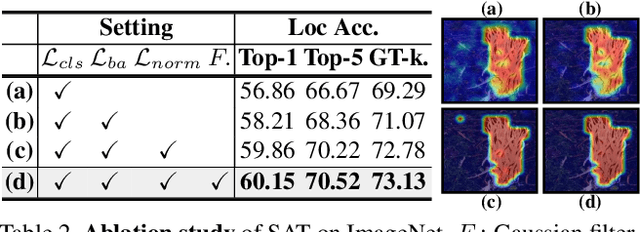
Weakly supervised object localization (WSOL) is a challenging task aiming to localize objects with only image-level supervision. Recent works apply visual transformer to WSOL and achieve significant success by exploiting the long-range feature dependency in self-attention mechanism. However, existing transformer-based methods synthesize the classification feature maps as the localization map, which leads to optimization conflicts between classification and localization tasks. To address this problem, we propose to learn a task-specific spatial-aware token (SAT) to condition localization in a weakly supervised manner. Specifically, a spatial token is first introduced in the input space to aggregate representations for localization task. Then a spatial aware attention module is constructed, which allows spatial token to generate foreground probabilities of different patches by querying and to extract localization knowledge from the classification task. Besides, for the problem of sparse and unbalanced pixel-level supervision obtained from the image-level label, two spatial constraints, including batch area loss and normalization loss, are designed to compensate and enhance this supervision. Experiments show that the proposed SAT achieves state-of-the-art performance on both CUB-200 and ImageNet, with 98.45% and 73.13% GT-known Loc, respectively. Even under the extreme setting of using only 1 image per class from ImageNet for training, SAT already exceeds the SOTA method by 2.1% GT-known Loc. Code and models are available at https://github.com/wpy1999/SAT.