 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
PyTorch Image Quality: Metrics for Image Quality Assessment
Aug 31, 2022

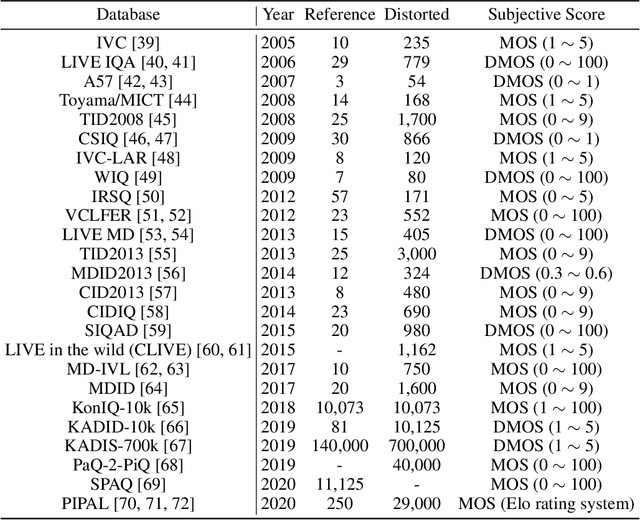
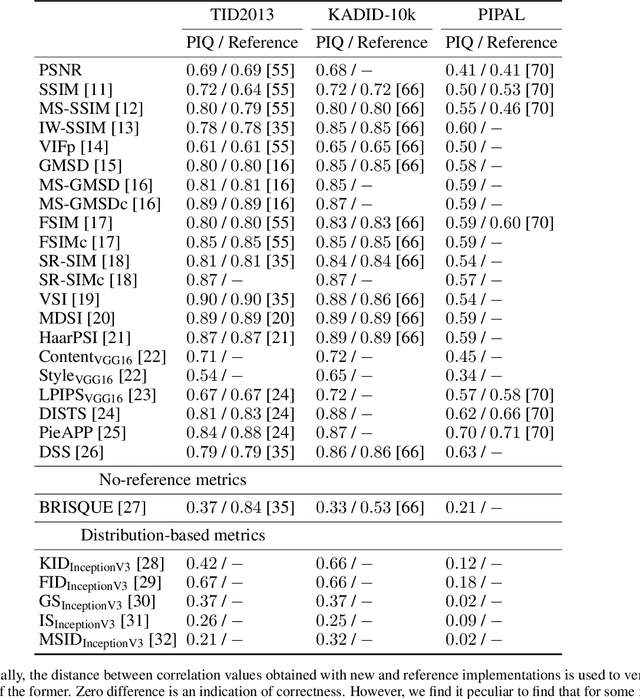
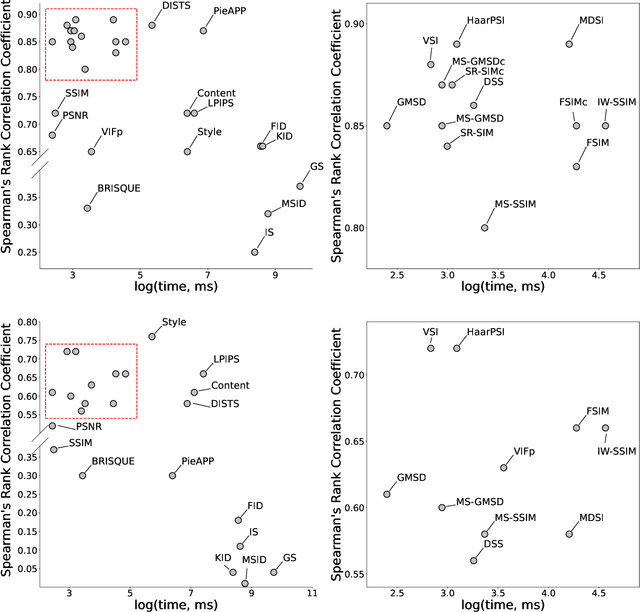
Image Quality Assessment (IQA) metrics are widely used to quantitatively estimate the extent of image degradation following some forming, restoring, transforming, or enhancing algorithms. We present PyTorch Image Quality (PIQ), a usability-centric library that contains the most popular modern IQA algorithms, guaranteed to be correctly implemented according to their original propositions and thoroughly verified. In this paper, we detail the principles behind the foundation of the library, describe the evaluation strategy that makes it reliable, provide the benchmarks that showcase the performance-time trade-offs, and underline the benefits of GPU acceleration given the library is used within the PyTorch backend. PyTorch Image Quality is an open source software: https://github.com/photosynthesis-team/piq/.
Patch-Craft Self-Supervised Training for Correlated Image Denoising
Nov 17, 2022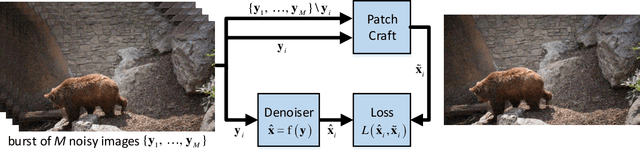
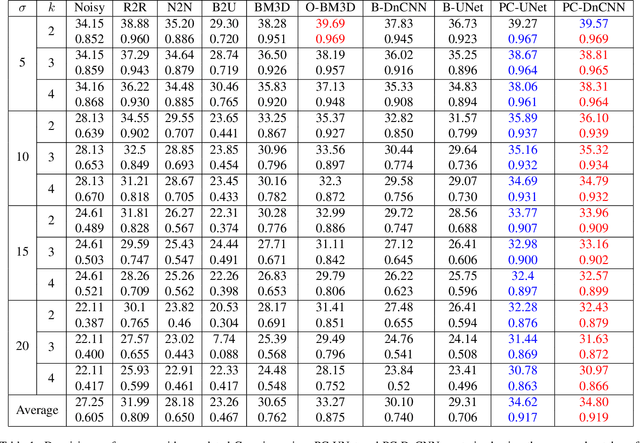
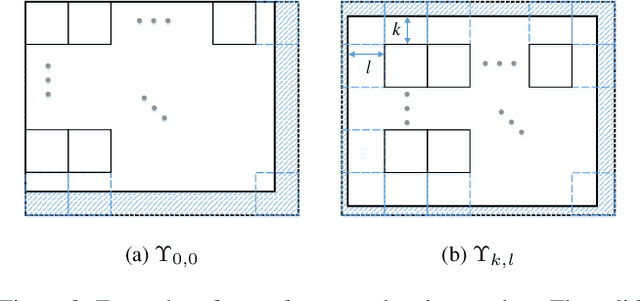
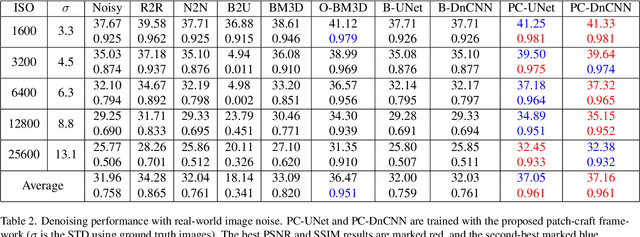
Supervised neural networks are known to achieve excellent results in various image restoration tasks. However, such training requires datasets composed of pairs of corrupted images and their corresponding ground truth targets. Unfortunately, such data is not available in many applications. For the task of image denoising in which the noise statistics is unknown, several self-supervised training methods have been proposed for overcoming this difficulty. Some of these require knowledge of the noise model, while others assume that the contaminating noise is uncorrelated, both assumptions are too limiting for many practical needs. This work proposes a novel self-supervised training technique suitable for the removal of unknown correlated noise. The proposed approach neither requires knowledge of the noise model nor access to ground truth targets. The input to our algorithm consists of easily captured bursts of noisy shots. Our algorithm constructs artificial patch-craft images from these bursts by patch matching and stitching, and the obtained crafted images are used as targets for the training. Our method does not require registration of the images within the burst. We evaluate the proposed framework through extensive experiments with synthetic and real image noise.
Learning to Generate Image Embeddings with User-level Differential Privacy
Nov 20, 2022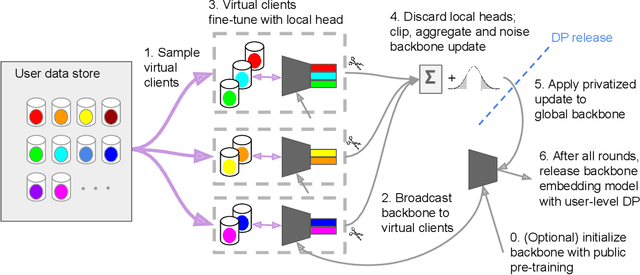
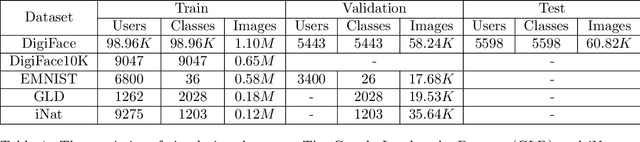

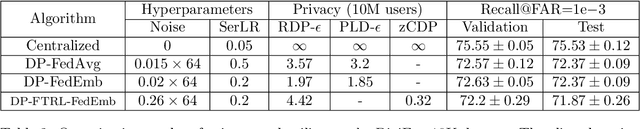
Small on-device models have been successfully trained with user-level differential privacy (DP) for next word prediction and image classification tasks in the past. However, existing methods can fail when directly applied to learn embedding models using supervised training data with a large class space. To achieve user-level DP for large image-to-embedding feature extractors, we propose DP-FedEmb, a variant of federated learning algorithms with per-user sensitivity control and noise addition, to train from user-partitioned data centralized in the datacenter. DP-FedEmb combines virtual clients, partial aggregation, private local fine-tuning, and public pretraining to achieve strong privacy utility trade-offs. We apply DP-FedEmb to train image embedding models for faces, landmarks and natural species, and demonstrate its superior utility under same privacy budget on benchmark datasets DigiFace, EMNIST, GLD and iNaturalist. We further illustrate it is possible to achieve strong user-level DP guarantees of $\epsilon<2$ while controlling the utility drop within 5%, when millions of users can participate in training.
CoCoNet: Coupled Contrastive Learning Network with Multi-level Feature Ensemble for Multi-modality Image Fusion
Nov 20, 2022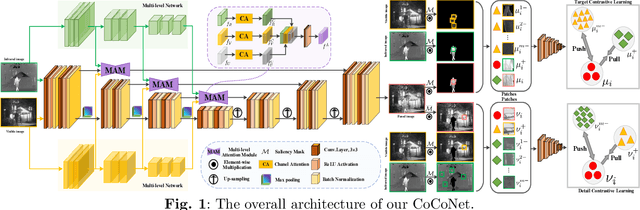
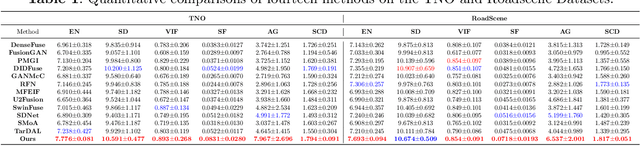

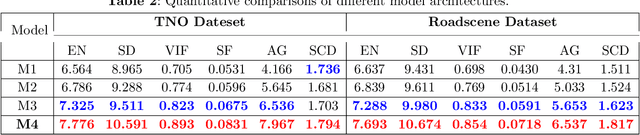
Infrared and visible image fusion targets to provide an informative image by combining complementary information from different sensors. Existing learning-based fusion approaches attempt to construct various loss functions to preserve complementary features from both modalities, while neglecting to discover the inter-relationship between the two modalities, leading to redundant or even invalid information on the fusion results. To alleviate these issues, we propose a coupled contrastive learning network, dubbed CoCoNet, to realize infrared and visible image fusion in an end-to-end manner. Concretely, to simultaneously retain typical features from both modalities and remove unwanted information emerging on the fused result, we develop a coupled contrastive constraint in our loss function.In a fused imge, its foreground target/background detail part is pulled close to the infrared/visible source and pushed far away from the visible/infrared source in the representation space. We further exploit image characteristics to provide data-sensitive weights, which allows our loss function to build a more reliable relationship with source images. Furthermore, to learn rich hierarchical feature representation and comprehensively transfer features in the fusion process, a multi-level attention module is established. In addition, we also apply the proposed CoCoNet on medical image fusion of different types, e.g., magnetic resonance image and positron emission tomography image, magnetic resonance image and single photon emission computed tomography image. Extensive experiments demonstrate that our method achieves the state-of-the-art (SOTA) performance under both subjective and objective evaluation, especially in preserving prominent targets and recovering vital textural details.
On representation of natural image patches
Oct 24, 2022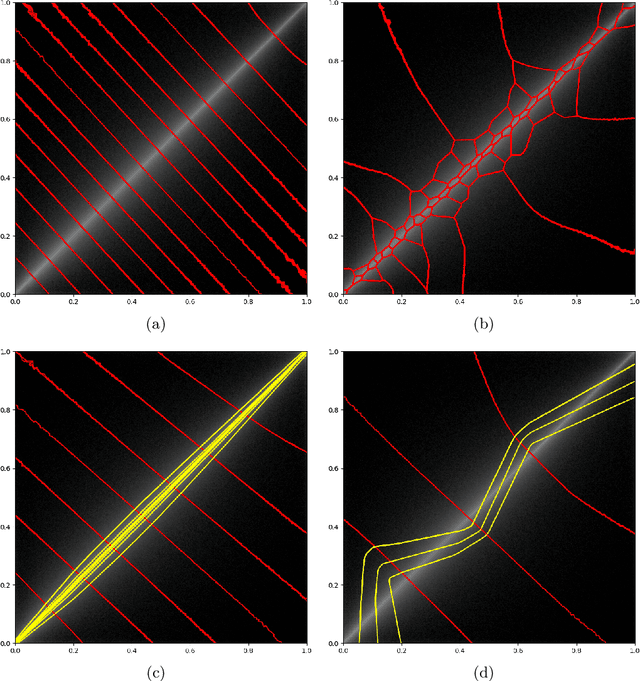


Starting from the first principle I derive an unsupervised learning method named even code to model local statistics of natural images. The first version uses orthogonal bases with independent states to model simple probability distribution of a few pixels. The second version uses a microscopic loss function to learn a nonlinear sparse binary representation of image patches. The distance in the binary representation space reflects image patch similarity. The learned model also has local edge detecting and orientation selective units like early visual systems.
DiffusionAD: Denoising Diffusion for Anomaly Detection
Mar 15, 2023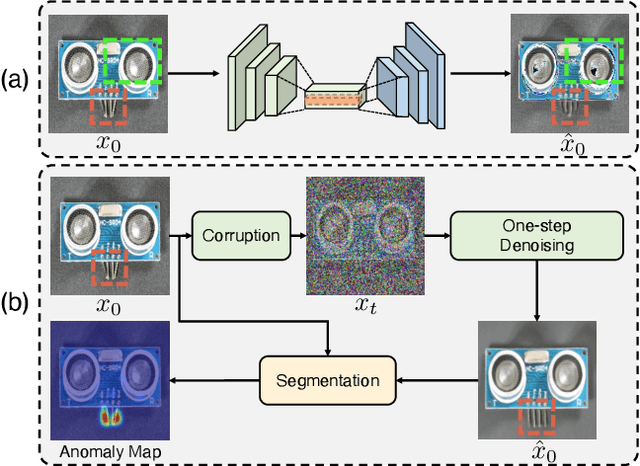
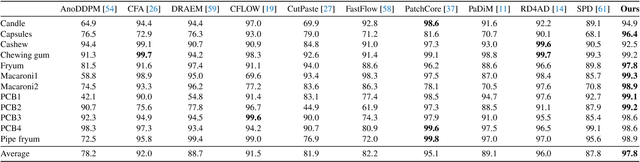
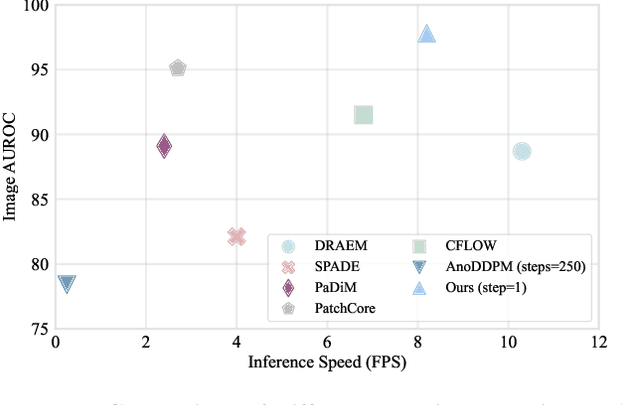
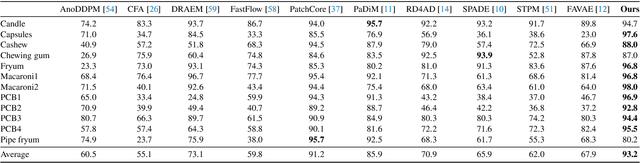
Anomaly detection is widely applied due to its remarkable effectiveness and efficiency in meeting the needs of real-world industrial manufacturing. We introduce a new pipeline, DiffusionAD, to anomaly detection. We frame anomaly detection as a ``noise-to-norm'' paradigm, in which anomalies are identified as inconsistencies between a query image and its flawless approximation. Our pipeline achieves this by restoring the anomalous regions from the noisy corrupted query image while keeping the normal regions unchanged. DiffusionAD includes a denoising sub-network and a segmentation sub-network, which work together to provide intuitive anomaly detection and localization in an end-to-end manner, without the need for complicated post-processing steps. Remarkably, during inference, this framework delivers satisfactory performance with just one diffusion reverse process step, which is tens to hundreds of times faster than general diffusion methods. Extensive evaluations on standard and challenging benchmarks including VisA and DAGM show that DiffusionAD outperforms current state-of-the-art paradigms, demonstrating the effectiveness and generalizability of the proposed pipeline.
Decomposed Diffusion Models for High-Quality Video Generation
Mar 15, 2023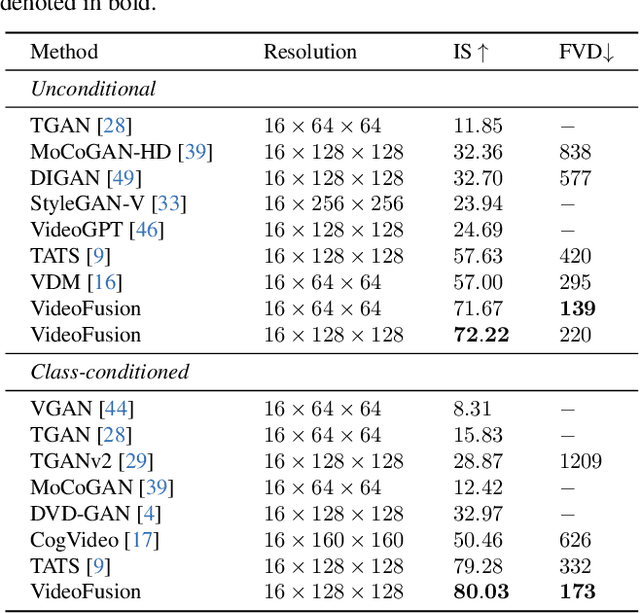


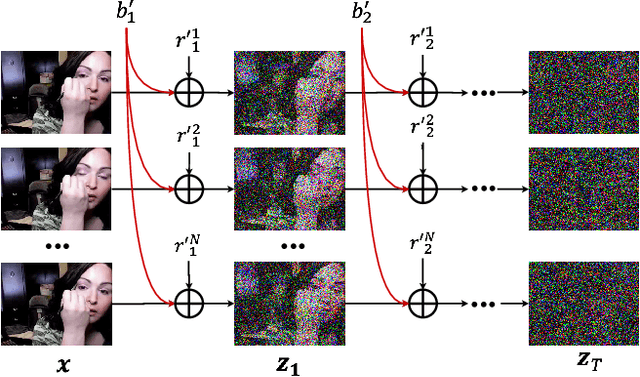
A diffusion probabilistic model (DPM), which constructs a forward diffusion process by gradually adding noise to data points and learns the reverse denoising process to generate new samples, has been shown to handle complex data distribution. Despite its recent success in image synthesis, applying DPMs to video generation is still challenging due to the high dimensional data space. Previous methods usually adopt a standard diffusion process, where frames in the same video clip are destroyed with independent noises, ignoring the content redundancy and temporal correlation. This work presents a decomposed diffusion process via resolving the per-frame noise into a base noise that is shared among all frames and a residual noise that varies along the time axis. The denoising pipeline employs two jointly-learned networks to match the noise decomposition accordingly. Experiments on various datasets confirm that our approach, termed as VideoFusion, surpasses both GAN-based and diffusion-based alternatives in high-quality video generation. We further show that our decomposed formulation can benefit from pre-trained image diffusion models and well-support text-conditioned video creation.
Sequential Recommendation with Diffusion Models
Apr 10, 2023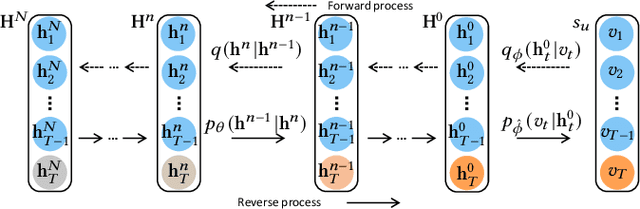
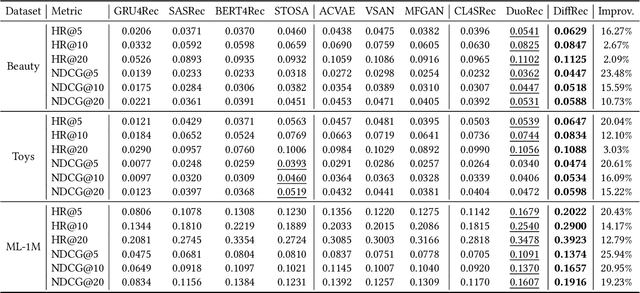

Generative models, such as Variational Auto-Encoder (VAE) and Generative Adversarial Network (GAN), have been successfully applied in sequential recommendation. These methods require sampling from probability distributions and adopt auxiliary loss functions to optimize the model, which can capture the uncertainty of user behaviors and alleviate exposure bias. However, existing generative models still suffer from the posterior collapse problem or the model collapse problem, thus limiting their applications in sequential recommendation. To tackle the challenges mentioned above, we leverage a new paradigm of the generative models, i.e., diffusion models, and present sequential recommendation with diffusion models (DiffRec), which can avoid the issues of VAE- and GAN-based models and show better performance. While diffusion models are originally proposed to process continuous image data, we design an additional transition in the forward process together with a transition in the reverse process to enable the processing of the discrete recommendation data. We also design a different noising strategy that only noises the target item instead of the whole sequence, which is more suitable for sequential recommendation. Based on the modified diffusion process, we derive the objective function of our framework using a simplification technique and design a denoise sequential recommender to fulfill the objective function. As the lengthened diffusion steps substantially increase the time complexity, we propose an efficient training strategy and an efficient inference strategy to reduce training and inference cost and improve recommendation diversity. Extensive experiment results on three public benchmark datasets verify the effectiveness of our approach and show that DiffRec outperforms the state-of-the-art sequential recommendation models.
A Structure-Guided Diffusion Model for Large-Hole Diverse Image Completion
Nov 18, 2022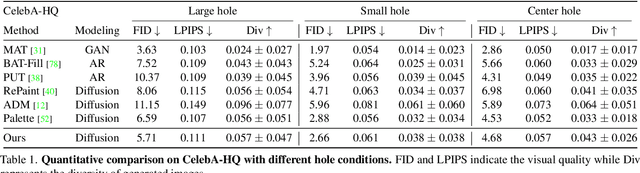

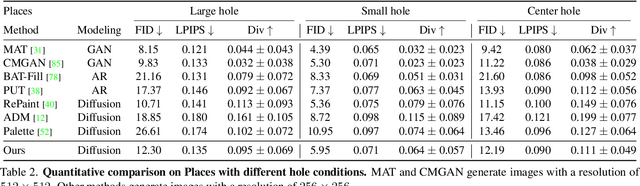
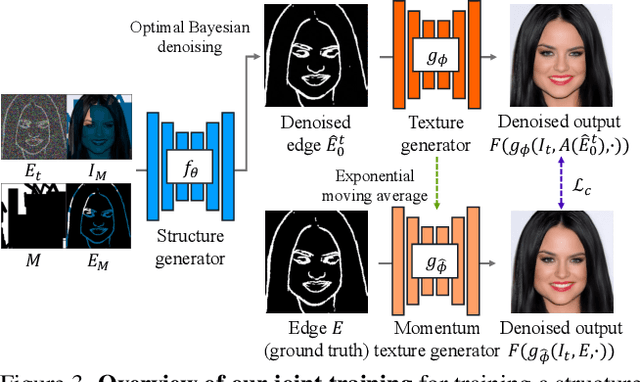
Diverse image completion, a problem of generating various ways of filling incomplete regions (i.e. holes) of an image, has made remarkable success. However, managing input images with large holes is still a challenging problem due to the corruption of semantically important structures. In this paper, we tackle this problem by incorporating explicit structural guidance. We propose a structure-guided diffusion model (SGDM) for the large-hole diverse completion problem. Our proposed SGDM consists of a structure generator and a texture generator, which are both diffusion probabilistic models (DMs). The structure generator generates an edge image representing a plausible structure within the holes, which is later used to guide the texture generation process. To jointly train these two generators, we design a strategy that combines optimal Bayesian denoising and a momentum framework. In addition to the quality improvement, auxiliary edge images generated by the structure generator can be manually edited to allow user-guided image editing. Our experiments using datasets of faces (CelebA-HQ) and natural scenes (Places) show that our method achieves a comparable or superior trade-off between visual quality and diversity compared to other state-of-the-art methods.
A New Benchmark: On the Utility of Synthetic Data with Blender for Bare Supervised Learning and Downstream Domain Adaptation
Mar 23, 2023
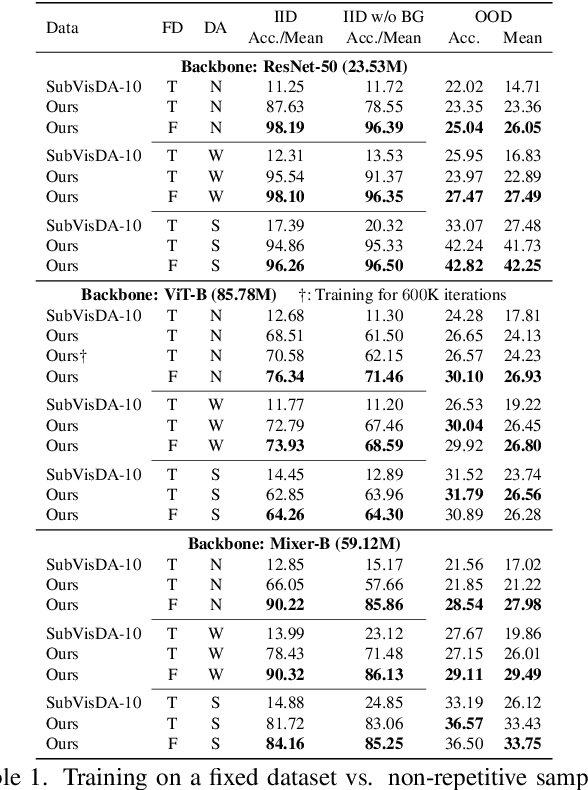

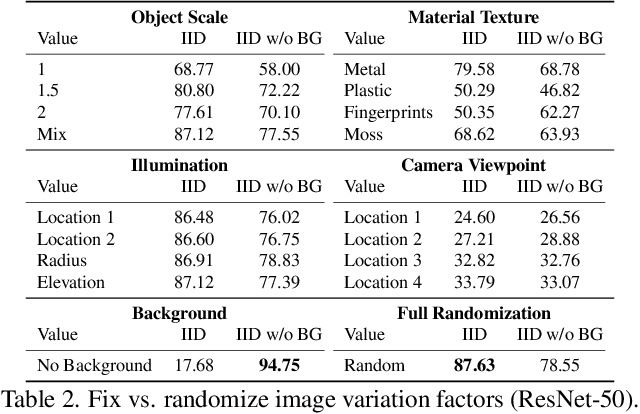
Deep learning in computer vision has achieved great success with the price of large-scale labeled training data. However, exhaustive data annotation is impracticable for each task of all domains of interest, due to high labor costs and unguaranteed labeling accuracy. Besides, the uncontrollable data collection process produces non-IID training and test data, where undesired duplication may exist. All these nuisances may hinder the verification of typical theories and exposure to new findings. To circumvent them, an alternative is to generate synthetic data via 3D rendering with domain randomization. We in this work push forward along this line by doing profound and extensive research on bare supervised learning and downstream domain adaptation. Specifically, under the well-controlled, IID data setting enabled by 3D rendering, we systematically verify the typical, important learning insights, e.g., shortcut learning, and discover the new laws of various data regimes and network architectures in generalization. We further investigate the effect of image formation factors on generalization, e.g., object scale, material texture, illumination, camera viewpoint, and background in a 3D scene. Moreover, we use the simulation-to-reality adaptation as a downstream task for comparing the transferability between synthetic and real data when used for pre-training, which demonstrates that synthetic data pre-training is also promising to improve real test results. Lastly, to promote future research, we develop a new large-scale synthetic-to-real benchmark for image classification, termed S2RDA, which provides more significant challenges for transfer from simulation to reality. The code and datasets are available at https://github.com/huitangtang/On_the_Utility_of_Synthetic_Data.