 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Predictive Heterogeneity: Measures and Applications
Apr 01, 2023
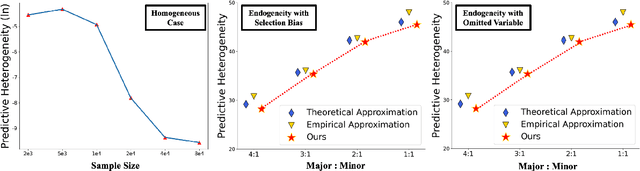

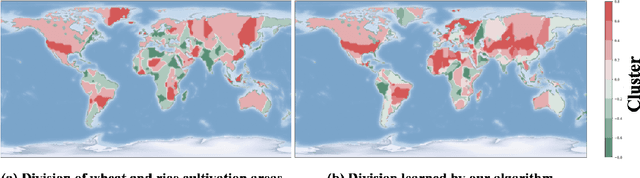
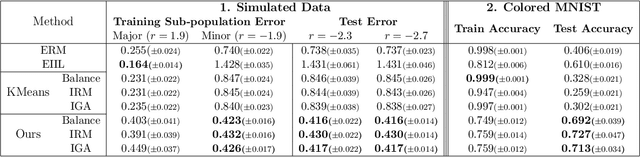
As an intrinsic and fundamental property of big data, data heterogeneity exists in a variety of real-world applications, such as precision medicine, autonomous driving, financial applications, etc. For machine learning algorithms, the ignorance of data heterogeneity will greatly hurt the generalization performance and the algorithmic fairness, since the prediction mechanisms among different sub-populations are likely to differ from each other. In this work, we focus on the data heterogeneity that affects the prediction of machine learning models, and firstly propose the \emph{usable predictive heterogeneity}, which takes into account the model capacity and computational constraints. We prove that it can be reliably estimated from finite data with probably approximately correct (PAC) bounds. Additionally, we design a bi-level optimization algorithm to explore the usable predictive heterogeneity from data. Empirically, the explored heterogeneity provides insights for sub-population divisions in income prediction, crop yield prediction and image classification tasks, and leveraging such heterogeneity benefits the out-of-distribution generalization performance.
Wavelet Diffusion Models are fast and scalable Image Generators
Nov 29, 2022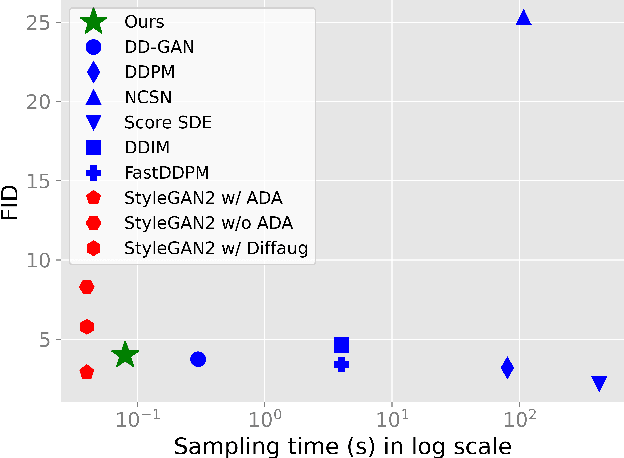
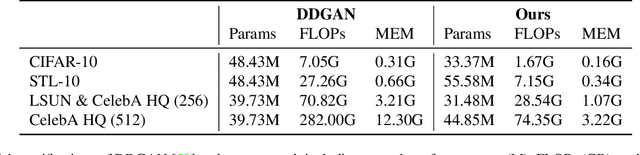
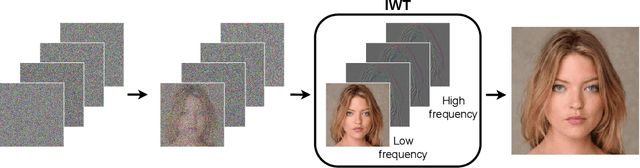
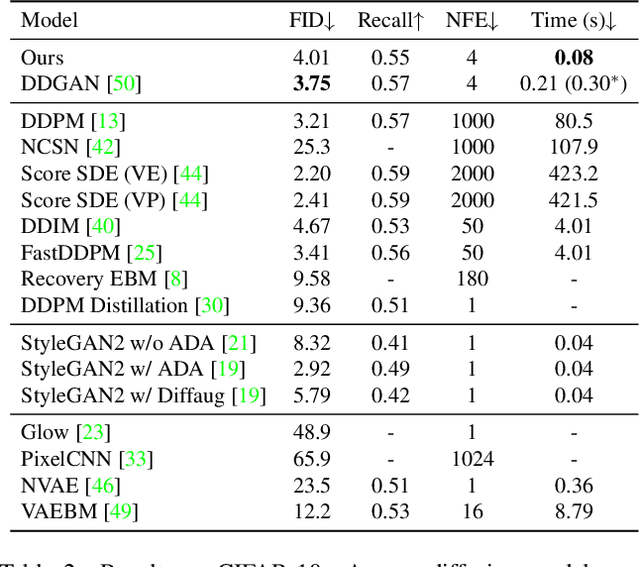
Diffusion models are rising as a powerful solution for high-fidelity image generation, which exceeds GANs in quality in many circumstances. However, their slow training and inference speed is a huge bottleneck, blocking them from being used in real-time applications. A recent DiffusionGAN method significantly decreases the models' running time by reducing the number of sampling steps from thousands to several, but their speeds still largely lag behind the GAN counterparts. This paper aims to reduce the speed gap by proposing a novel wavelet-based diffusion structure. We extract low-and-high frequency components from both image and feature levels via wavelet decomposition and adaptively handle these components for faster processing while maintaining good generation quality. Furthermore, we propose to use a reconstruction term, which effectively boosts the model training convergence. Experimental results on CelebA-HQ, CIFAR-10, LSUN-Church, and STL-10 datasets prove our solution is a stepping-stone to offering real-time and high-fidelity diffusion models. Our code and pre-trained checkpoints will be available at \url{https://github.com/VinAIResearch/WaveDiff.git}.
OSIC: A New One-Stage Image Captioner Coined
Nov 04, 2022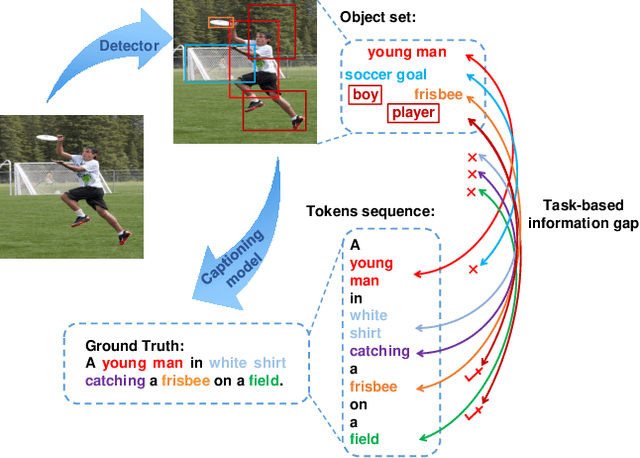
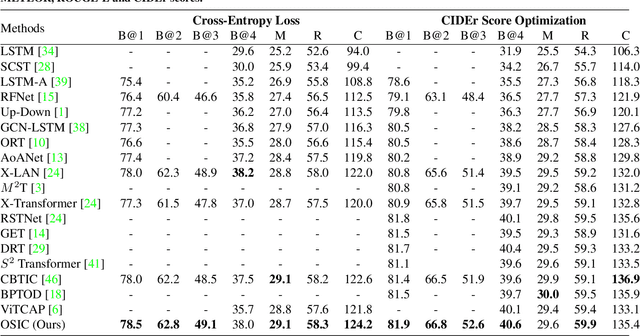
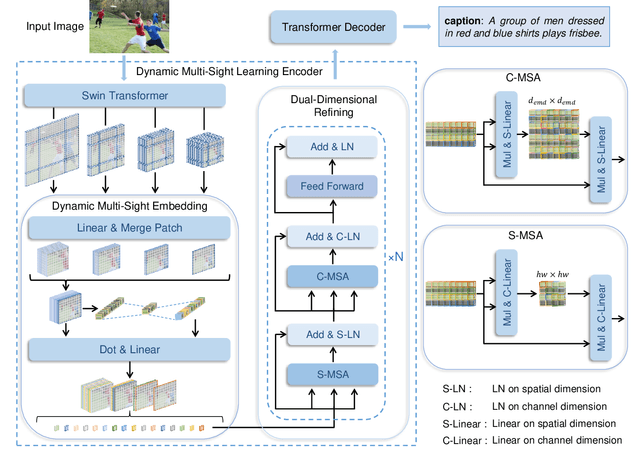
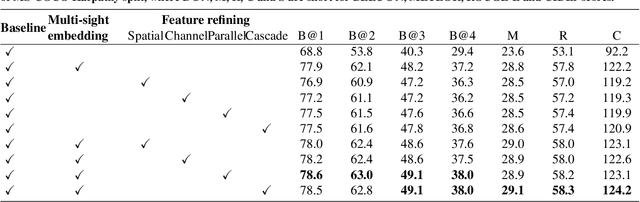
Mainstream image caption models are usually two-stage captioners, i.e., calculating object features by pre-trained detector, and feeding them into a language model to generate text descriptions. However, such an operation will cause a task-based information gap to decrease the performance, since the object features in detection task are suboptimal representation and cannot provide all necessary information for subsequent text generation. Besides, object features are usually represented by the last layer features that lose the local details of input images. In this paper, we propose a novel One-Stage Image Captioner (OSIC) with dynamic multi-sight learning, which directly transforms input image into descriptive sentences in one stage. As a result, the task-based information gap can be greatly reduced. To obtain rich features, we use the Swin Transformer to calculate multi-level features, and then feed them into a novel dynamic multi-sight embedding module to exploit both global structure and local texture of input images. To enhance the global modeling of encoder for caption, we propose a new dual-dimensional refining module to non-locally model the interaction of the embedded features. Finally, OSIC can obtain rich and useful information to improve the image caption task. Extensive comparisons on benchmark MS-COCO dataset verified the superior performance of our method.
Comparing PSDNet, pretrained networks, and traditional feature extraction for predicting the particle size distribution of granular materials from photographs
Mar 07, 2023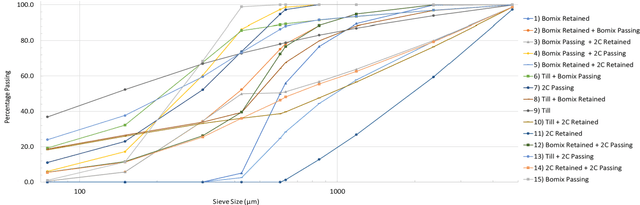
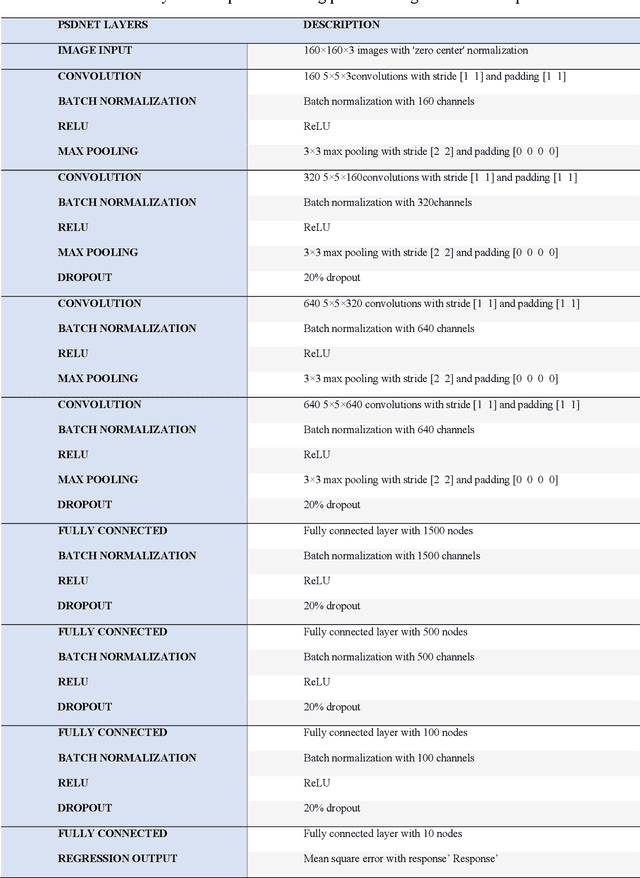

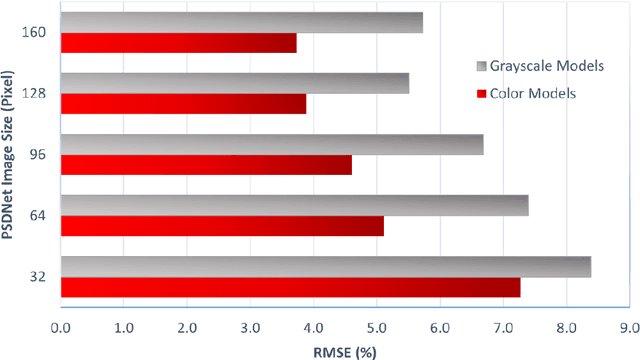
This study aims to evaluate PSDNet, a series of convolutional neural networks (ConvNets) trained with photographs to predict the particle size distribution of granular materials. Nine traditional feature extraction methods and 15 pretrained ConvNets were also evaluated and compared. A dataset including 9600 photographs of 15 different granular materials was used. The influence of image size and color band was verified by using six image sizes between 32 and 160 pixels, and both grayscale and color images as PSDNet inputs. In addition to random training, validation, and testing datasets, a material removal method was also used to evaluate the performances of each image analysis method. With this method, each material was successively removed from the training and validation datasets and used as the testing dataset. Results show that a combination of all PSDNet color and grayscale features can lead to a root mean square error (RMSE) on the percentages passing as low as 1.8 % with a random testing dataset and 9.1% with the material removal method. For the random datasets, a combination of all traditional features, and the features extracted from InceptionResNetV2 led to RMSE on the percentages passing of 2.3 and 1.7 %, respectively.
One-Step Detection Paradigm for Hyperspectral Anomaly Detection via Spectral Deviation Relationship Learning
Mar 22, 2023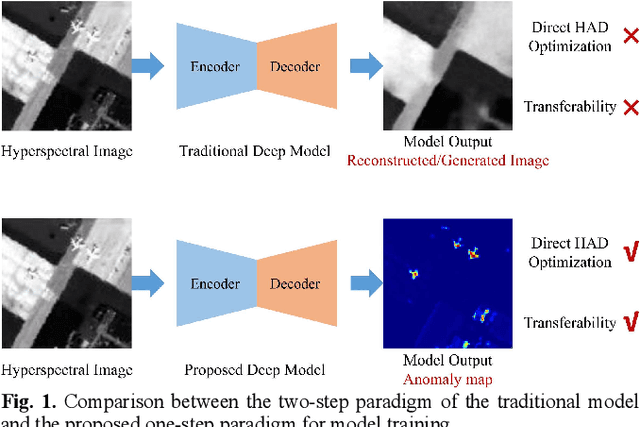
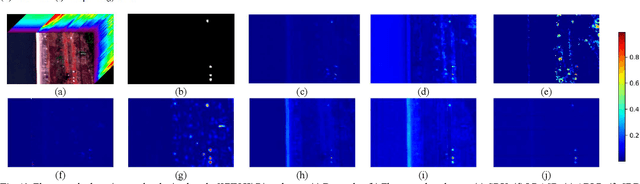
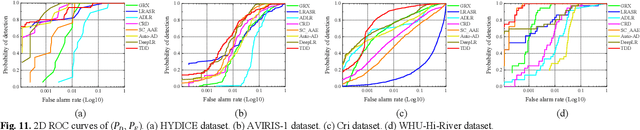
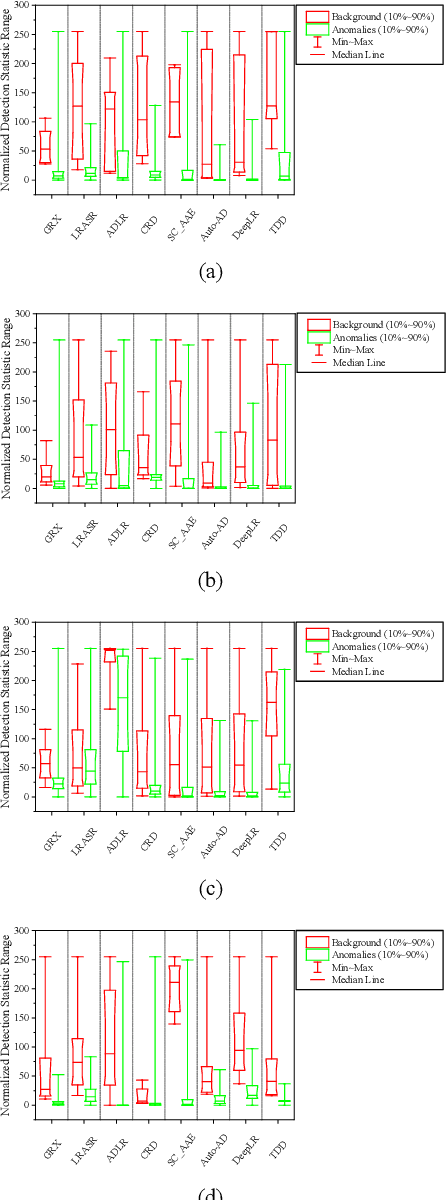
Hyperspectral anomaly detection (HAD) involves identifying the targets that deviate spectrally from their surroundings, without prior knowledge. Recently, deep learning based methods have become the mainstream HAD methods, due to their powerful spatial-spectral feature extraction ability. However, the current deep detection models are optimized to complete a proxy task (two-step paradigm), such as background reconstruction or generation, rather than achieving anomaly detection directly. This leads to suboptimal results and poor transferability, which means that the deep model is trained and tested on the same image. In this paper, an unsupervised transferred direct detection (TDD) model is proposed, which is optimized directly for the anomaly detection task (one-step paradigm) and has transferability. Specially, the TDD model is optimized to identify the spectral deviation relationship according to the anomaly definition. Compared to learning the specific background distribution as most models do, the spectral deviation relationship is universal for different images and guarantees the model transferability. To train the TDD model in an unsupervised manner, an anomaly sample simulation strategy is proposed to generate numerous pairs of anomaly samples. Furthermore, a global self-attention module and a local self-attention module are designed to help the model focus on the "spectrally deviating" relationship. The TDD model was validated on four public HAD datasets. The results show that the proposed TDD model can successfully overcome the limitation of traditional model training and testing on a single image, and the model has a powerful detection ability and excellent transferability.
Soft labelling for semantic segmentation: Bringing coherence to label down-sampling
Feb 27, 2023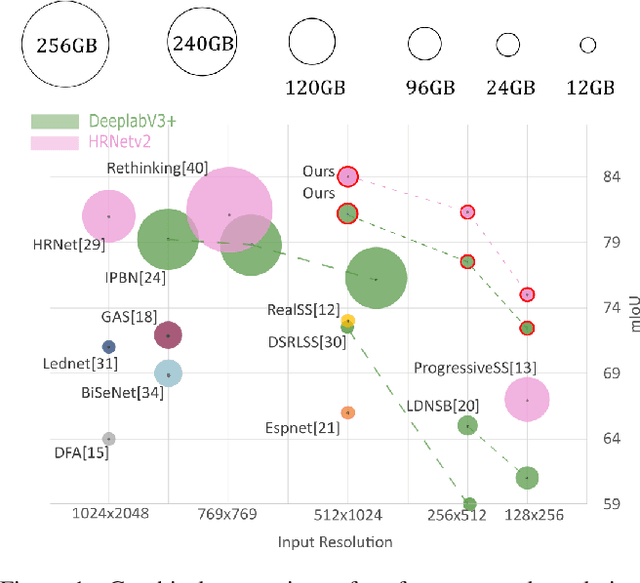


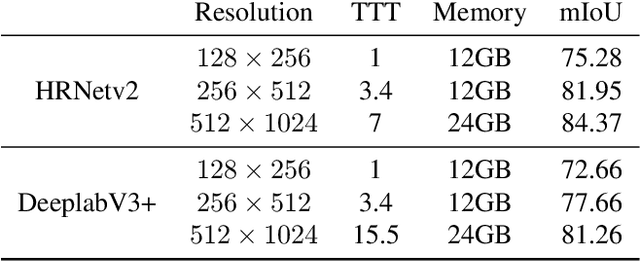
In semantic segmentation, training data down-sampling is commonly performed because of limited resources, adapting image size to the model input, or improving data augmentation. This down-sampling typically employs different strategies for the image data and the annotated labels. Such discrepancy leads to mismatches between the down-sampled pixels and labels. Hence, training performance significantly decreases as the down-sampling factor increases. In this paper, we bring together the downsampling strategies for the image data and annotated labels. To that aim, we propose a soft-labeling method for label down-sampling that takes advantage of structural content prior to down-sampling. Thereby, fully aligning softlabels with image data to keep the distribution of the sampled pixels. This proposal also produces richer annotations for under-represented semantic classes. Altogether, it permits training competitive models at lower resolutions. Experiments show that the proposal outperforms other downsampling strategies. Moreover, state of the art performance is achieved for reference benchmarks, but employing significantly less computational resources than other approaches. This proposal enables competitive research for semantic segmentation under resource constraints.
Tensor Factorization via Transformed Tensor-Tensor Product for Image Alignment
Dec 13, 2022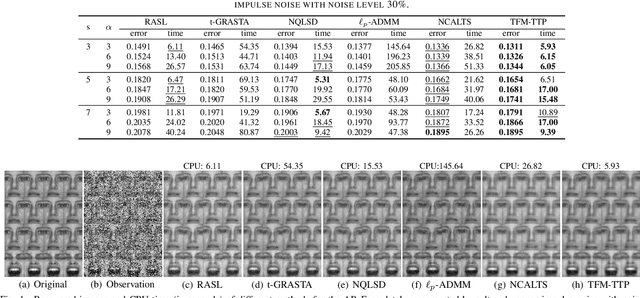
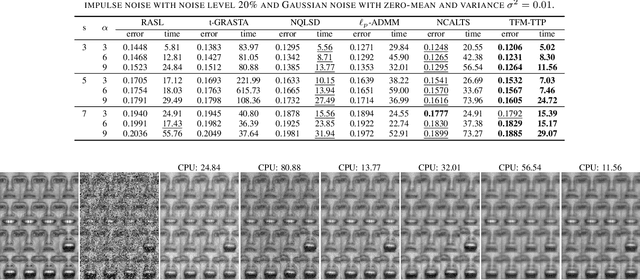
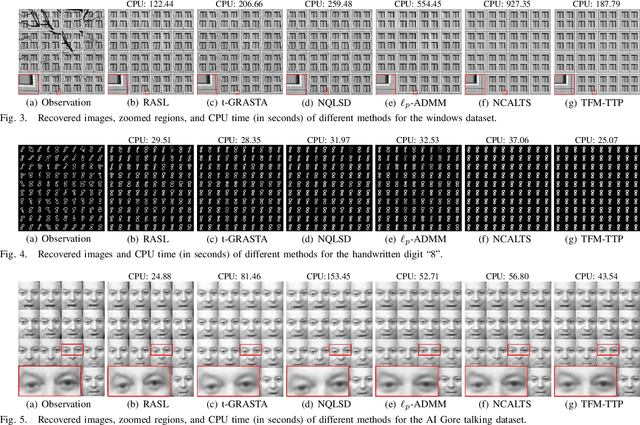

In this paper, we study the problem of a batch of linearly correlated image alignment, where the observed images are deformed by some unknown domain transformations, and corrupted by additive Gaussian noise and sparse noise simultaneously. By stacking these images as the frontal slices of a third-order tensor, we propose to utilize the tensor factorization method via transformed tensor-tensor product to explore the low-rankness of the underlying tensor, which is factorized into the product of two smaller tensors via transformed tensor-tensor product under any unitary transformation. The main advantage of transformed tensor-tensor product is that its computational complexity is lower compared with the existing literature based on transformed tensor nuclear norm. Moreover, the tensor $\ell_p$ $(0<p<1)$ norm is employed to characterize the sparsity of sparse noise and the tensor Frobenius norm is adopted to model additive Gaussian noise. A generalized Gauss-Newton algorithm is designed to solve the resulting model by linearizing the domain transformations and a proximal Gauss-Seidel algorithm is developed to solve the corresponding subproblem. Furthermore, the convergence of the proximal Gauss-Seidel algorithm is established, whose convergence rate is also analyzed based on the Kurdyka-$\L$ojasiewicz property. Extensive numerical experiments on real-world image datasets are carried out to demonstrate the superior performance of the proposed method as compared to several state-of-the-art methods in both accuracy and computational time.
Patch-Craft Self-Supervised Training for Correlated Image Denoising
Nov 17, 2022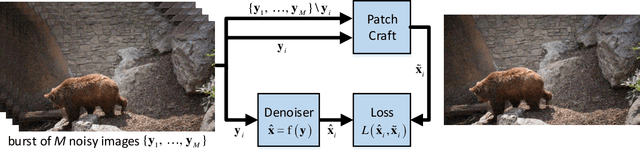
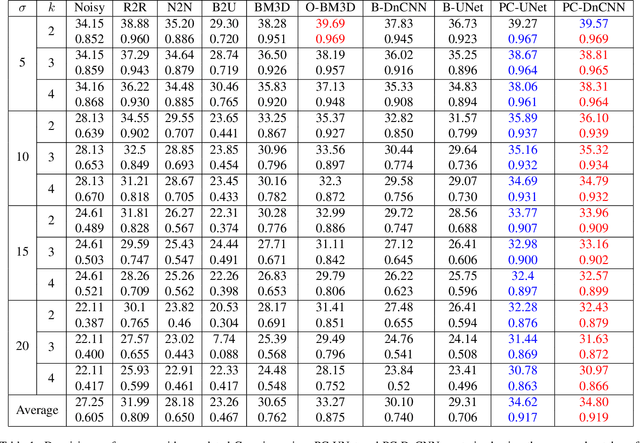
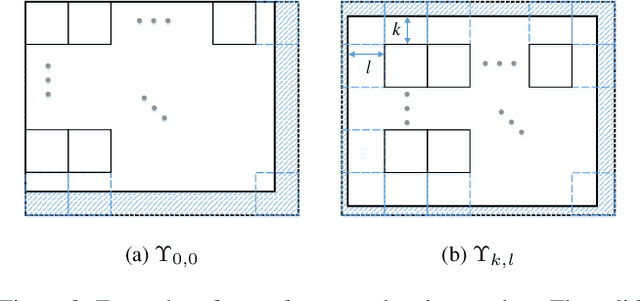
Supervised neural networks are known to achieve excellent results in various image restoration tasks. However, such training requires datasets composed of pairs of corrupted images and their corresponding ground truth targets. Unfortunately, such data is not available in many applications. For the task of image denoising in which the noise statistics is unknown, several self-supervised training methods have been proposed for overcoming this difficulty. Some of these require knowledge of the noise model, while others assume that the contaminating noise is uncorrelated, both assumptions are too limiting for many practical needs. This work proposes a novel self-supervised training technique suitable for the removal of unknown correlated noise. The proposed approach neither requires knowledge of the noise model nor access to ground truth targets. The input to our algorithm consists of easily captured bursts of noisy shots. Our algorithm constructs artificial patch-craft images from these bursts by patch matching and stitching, and the obtained crafted images are used as targets for the training. Our method does not require registration of the images within the burst. We evaluate the proposed framework through extensive experiments with synthetic and real image noise.
Sequential edge detection using joint hierarchical Bayesian learning
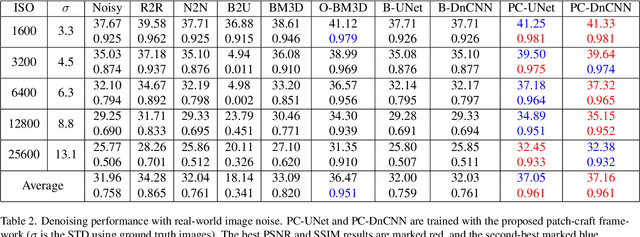
Feb 28, 2023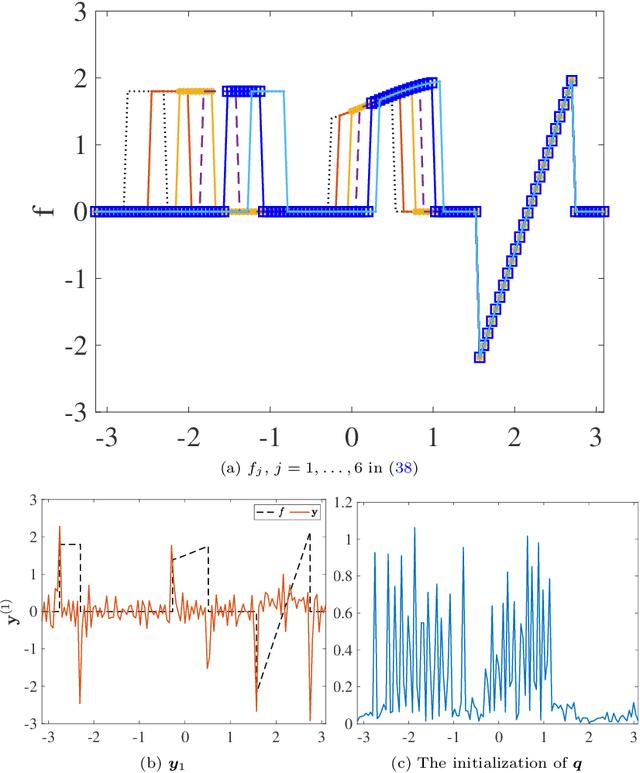
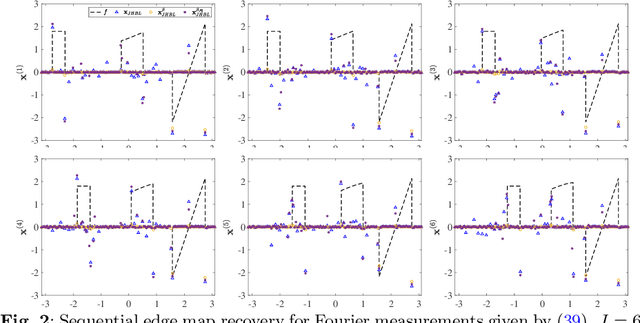
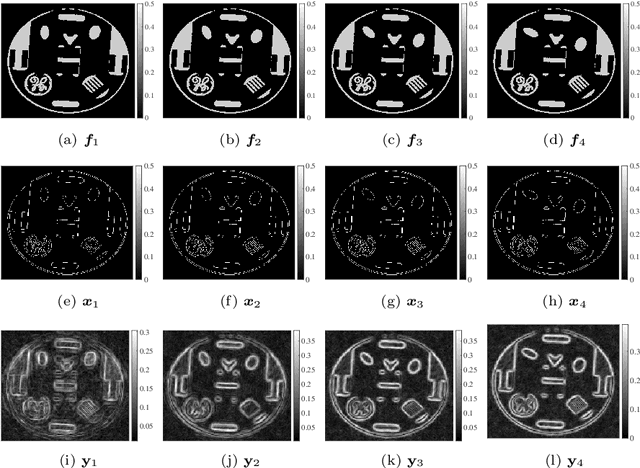

This paper introduces a new sparse Bayesian learning (SBL) algorithm that jointly recovers a temporal sequence of edge maps from noisy and under-sampled Fourier data. The new method is cast in a Bayesian framework and uses a prior that simultaneously incorporates intra-image information to promote sparsity in each individual edge map with inter-image information to promote similarities in any unchanged regions. By treating both the edges as well as the similarity between adjacent images as random variables, there is no need to separately form regions of change. Thus we avoid both additional computational cost as well as any information loss resulting from pre-processing the image. Our numerical examples demonstrate that our new method compares favorably with more standard SBL approaches.
Learning to Generate Image Embeddings with User-level Differential Privacy
Nov 20, 2022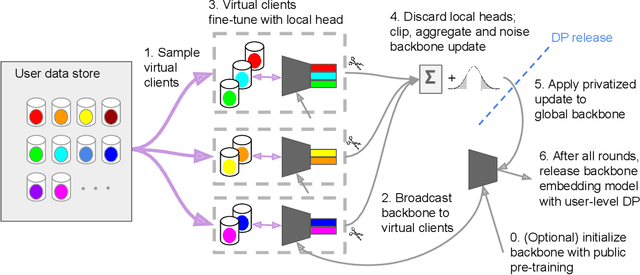
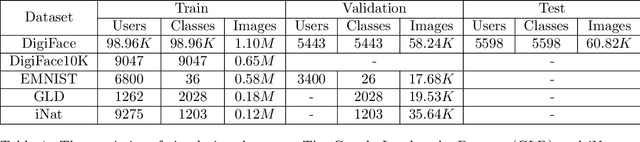

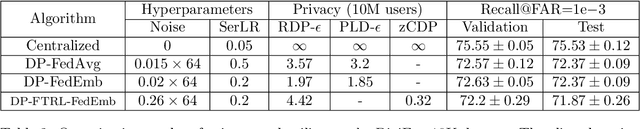
Small on-device models have been successfully trained with user-level differential privacy (DP) for next word prediction and image classification tasks in the past. However, existing methods can fail when directly applied to learn embedding models using supervised training data with a large class space. To achieve user-level DP for large image-to-embedding feature extractors, we propose DP-FedEmb, a variant of federated learning algorithms with per-user sensitivity control and noise addition, to train from user-partitioned data centralized in the datacenter. DP-FedEmb combines virtual clients, partial aggregation, private local fine-tuning, and public pretraining to achieve strong privacy utility trade-offs. We apply DP-FedEmb to train image embedding models for faces, landmarks and natural species, and demonstrate its superior utility under same privacy budget on benchmark datasets DigiFace, EMNIST, GLD and iNaturalist. We further illustrate it is possible to achieve strong user-level DP guarantees of $\epsilon<2$ while controlling the utility drop within 5%, when millions of users can participate in training.