 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
FindVehicle and VehicleFinder: A NER dataset for natural language-based vehicle retrieval and a keyword-based cross-modal vehicle retrieval system
Apr 21, 2023

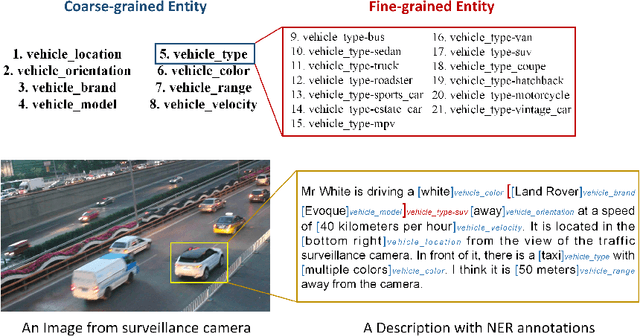
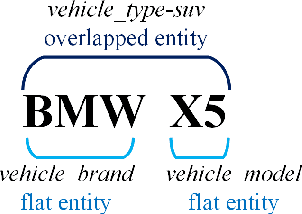
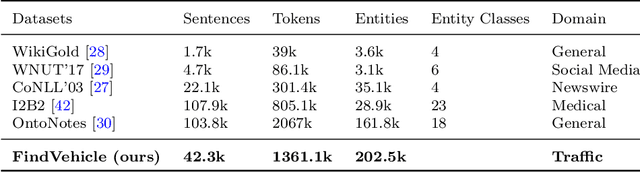
Natural language (NL) based vehicle retrieval is a task aiming to retrieve a vehicle that is most consistent with a given NL query from among all candidate vehicles. Because NL query can be easily obtained, such a task has a promising prospect in building an interactive intelligent traffic system (ITS). Current solutions mainly focus on extracting both text and image features and mapping them to the same latent space to compare the similarity. However, existing methods usually use dependency analysis or semantic role-labelling techniques to find keywords related to vehicle attributes. These techniques may require a lot of pre-processing and post-processing work, and also suffer from extracting the wrong keyword when the NL query is complex. To tackle these problems and simplify, we borrow the idea from named entity recognition (NER) and construct FindVehicle, a NER dataset in the traffic domain. It has 42.3k labelled NL descriptions of vehicle tracks, containing information such as the location, orientation, type and colour of the vehicle. FindVehicle also adopts both overlapping entities and fine-grained entities to meet further requirements. To verify its effectiveness, we propose a baseline NL-based vehicle retrieval model called VehicleFinder. Our experiment shows that by using text encoders pre-trained by FindVehicle, VehicleFinder achieves 87.7\% precision and 89.4\% recall when retrieving a target vehicle by text command on our homemade dataset based on UA-DETRAC. The time cost of VehicleFinder is 279.35 ms on one ARM v8.2 CPU and 93.72 ms on one RTX A4000 GPU, which is much faster than the Transformer-based system. The dataset is open-source via the link https://github.com/GuanRunwei/FindVehicle, and the implementation can be found via the link https://github.com/GuanRunwei/VehicleFinder-CTIM.
The Role of Pre-training Data in Transfer Learning
Mar 01, 2023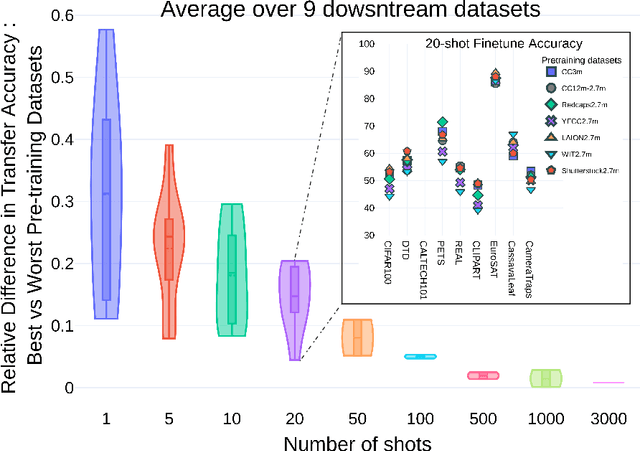
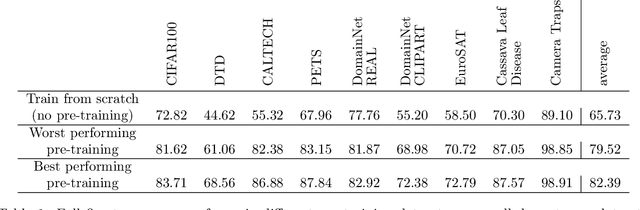
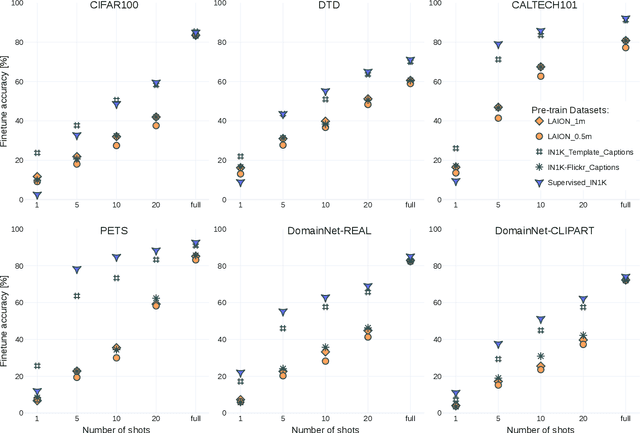

The transfer learning paradigm of model pre-training and subsequent fine-tuning produces high-accuracy models. While most studies recommend scaling the pre-training size to benefit most from transfer learning, a question remains: what data and method should be used for pre-training? We investigate the impact of pre-training data distribution on the few-shot and full fine-tuning performance using 3 pre-training methods (supervised, contrastive language-image and image-image), 7 pre-training datasets, and 9 downstream datasets. Through extensive controlled experiments, we find that the choice of the pre-training data source is essential for the few-shot transfer, but its role decreases as more data is made available for fine-tuning. Additionally, we explore the role of data curation and examine the trade-offs between label noise and the size of the pre-training dataset. We find that using 2000X more pre-training data from LAION can match the performance of supervised ImageNet pre-training. Furthermore, we investigate the effect of pre-training methods, comparing language-image contrastive vs. image-image contrastive, and find that the latter leads to better downstream accuracy
TinyDet: Accurate Small Object Detection in Lightweight Generic Detectors
Apr 07, 2023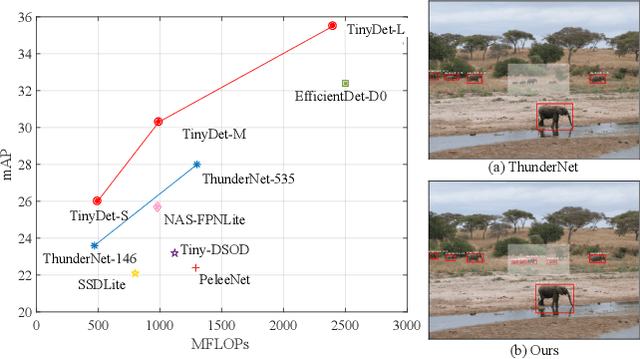
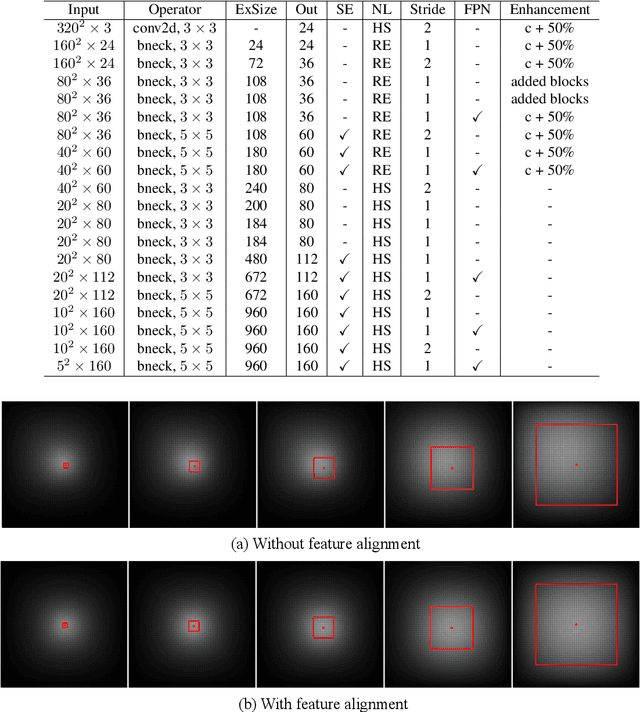
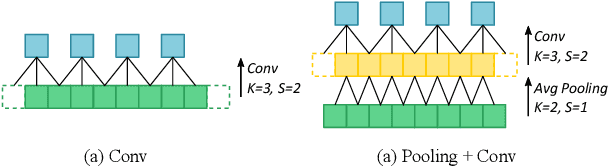
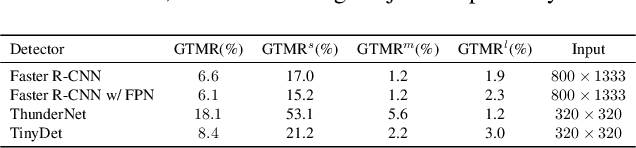
Small object detection requires the detection head to scan a large number of positions on image feature maps, which is extremely hard for computation- and energy-efficient lightweight generic detectors. To accurately detect small objects with limited computation, we propose a two-stage lightweight detection framework with extremely low computation complexity, termed as TinyDet. It enables high-resolution feature maps for dense anchoring to better cover small objects, proposes a sparsely-connected convolution for computation reduction, enhances the early stage features in the backbone, and addresses the feature misalignment problem for accurate small object detection. On the COCO benchmark, our TinyDet-M achieves 30.3 AP and 13.5 AP^s with only 991 MFLOPs, which is the first detector that has an AP over 30 with less than 1 GFLOPs; besides, TinyDet-S and TinyDet-L achieve promising performance under different computation limitation.
Interaction-Aware Prompting for Zero-Shot Spatio-Temporal Action Detection
Apr 11, 2023
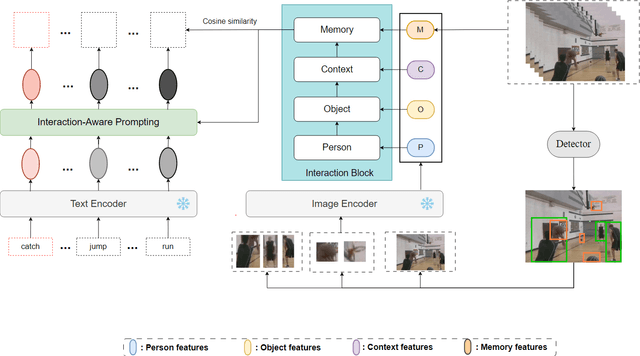

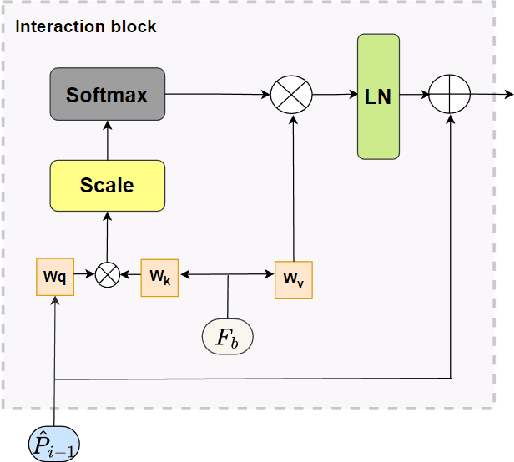
The goal of spatial-temporal action detection is to determine the time and place where each person's action occurs in a video and classify the corresponding action category. Most of the existing methods adopt fully-supervised learning, which requires a large amount of training data, making it very difficult to achieve zero-shot learning. In this paper, we propose to utilize a pre-trained visual-language model to extract the representative image and text features, and model the relationship between these features through different interaction modules to obtain the interaction feature. In addition, we use this feature to prompt each label to obtain more appropriate text features. Finally, we calculate the similarity between the interaction feature and the text feature for each label to determine the action category. Our experiments on J-HMDB and UCF101-24 datasets demonstrate that the proposed interaction module and prompting make the visual-language features better aligned, thus achieving excellent accuracy for zero-shot spatio-temporal action detection. The code will be released upon acceptance.
The MONET dataset: Multimodal drone thermal dataset recorded in rural scenarios
Apr 11, 2023
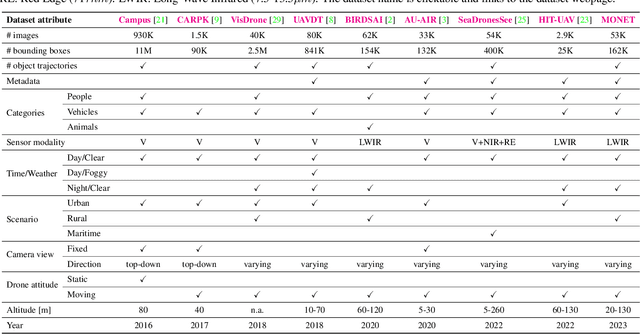
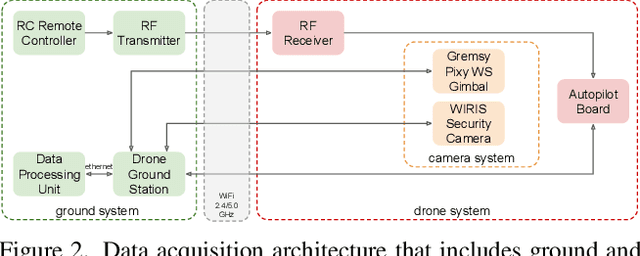
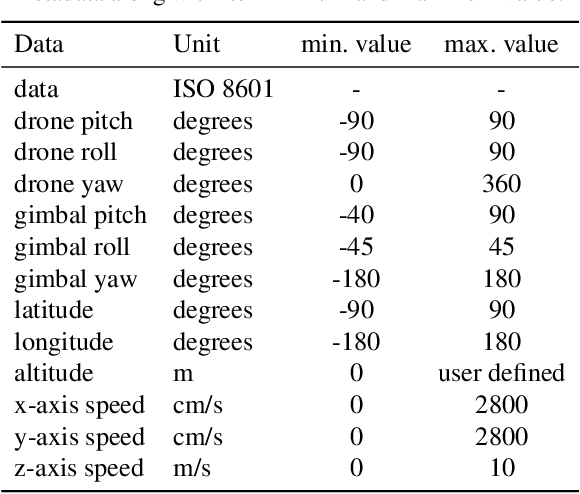
We present MONET, a new multimodal dataset captured using a thermal camera mounted on a drone that flew over rural areas, and recorded human and vehicle activities. We captured MONET to study the problem of object localisation and behaviour understanding of targets undergoing large-scale variations and being recorded from different and moving viewpoints. Target activities occur in two different land sites, each with unique scene structures and cluttered backgrounds. MONET consists of approximately 53K images featuring 162K manually annotated bounding boxes. Each image is timestamp-aligned with drone metadata that includes information about attitudes, speed, altitude, and GPS coordinates. MONET is different from previous thermal drone datasets because it features multimodal data, including rural scenes captured with thermal cameras containing both person and vehicle targets, along with trajectory information and metadata. We assessed the difficulty of the dataset in terms of transfer learning between the two sites and evaluated nine object detection algorithms to identify the open challenges associated with this type of data. Project page: https://github.com/fabiopoiesi/monet_dataset.
Boosting Cross-task Transferability of Adversarial Patches with Visual Relations
Apr 11, 2023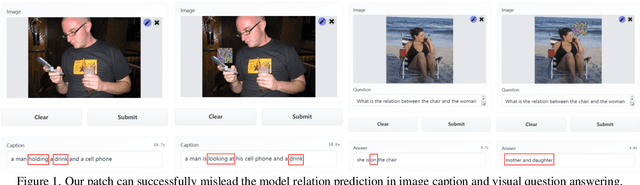
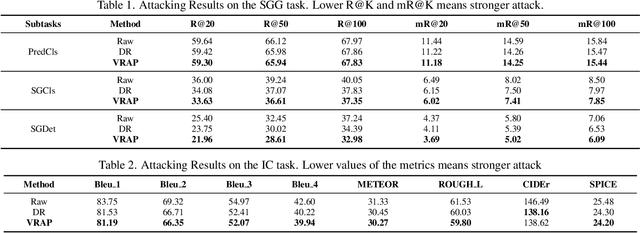
The transferability of adversarial examples is a crucial aspect of evaluating the robustness of deep learning systems, particularly in black-box scenarios. Although several methods have been proposed to enhance cross-model transferability, little attention has been paid to the transferability of adversarial examples across different tasks. This issue has become increasingly relevant with the emergence of foundational multi-task AI systems such as Visual ChatGPT, rendering the utility of adversarial samples generated by a single task relatively limited. Furthermore, these systems often entail inferential functions beyond mere recognition-like tasks. To address this gap, we propose a novel Visual Relation-based cross-task Adversarial Patch generation method called VRAP, which aims to evaluate the robustness of various visual tasks, especially those involving visual reasoning, such as Visual Question Answering and Image Captioning. VRAP employs scene graphs to combine object recognition-based deception with predicate-based relations elimination, thereby disrupting the visual reasoning information shared among inferential tasks. Our extensive experiments demonstrate that VRAP significantly surpasses previous methods in terms of black-box transferability across diverse visual reasoning tasks.
Pointless Global Bundle Adjustment With Relative Motions Hessians
Apr 11, 2023Bundle adjustment (BA) is the standard way to optimise camera poses and to produce sparse representations of a scene. However, as the number of camera poses and features grows, refinement through bundle adjustment becomes inefficient. Inspired by global motion averaging methods, we propose a new bundle adjustment objective which does not rely on image features' reprojection errors yet maintains precision on par with classical BA. Our method averages over relative motions while implicitly incorporating the contribution of the structure in the adjustment. To that end, we weight the objective function by local hessian matrices - a by-product of local bundle adjustments performed on relative motions (e.g., pairs or triplets) during the pose initialisation step. Such hessians are extremely rich as they encapsulate both the features' random errors and the geometric configuration between the cameras. These pieces of information propagated to the global frame help to guide the final optimisation in a more rigorous way. We argue that this approach is an upgraded version of the motion averaging approach and demonstrate its effectiveness on both photogrammetric datasets and computer vision benchmarks.
MOST: Multiple Object localization with Self-supervised Transformers for object discovery
Apr 11, 2023
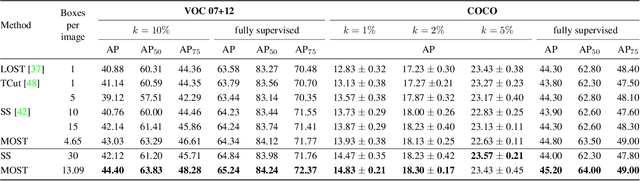
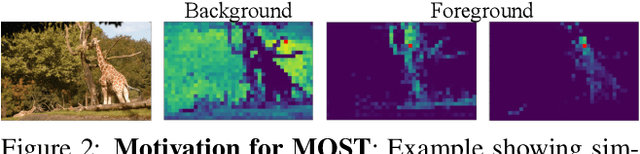
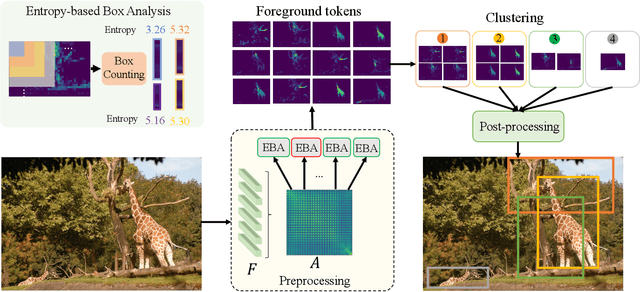
We tackle the challenging task of unsupervised object localization in this work. Recently, transformers trained with self-supervised learning have been shown to exhibit object localization properties without being trained for this task. In this work, we present Multiple Object localization with Self-supervised Transformers (MOST) that uses features of transformers trained using self-supervised learning to localize multiple objects in real world images. MOST analyzes the similarity maps of the features using box counting; a fractal analysis tool to identify tokens lying on foreground patches. The identified tokens are then clustered together, and tokens of each cluster are used to generate bounding boxes on foreground regions. Unlike recent state-of-the-art object localization methods, MOST can localize multiple objects per image and outperforms SOTA algorithms on several object localization and discovery benchmarks on PASCAL-VOC 07, 12 and COCO20k datasets. Additionally, we show that MOST can be used for self-supervised pre-training of object detectors, and yields consistent improvements on fully, semi-supervised object detection and unsupervised region proposal generation.
Robust One-shot Segmentation of Brain Tissues via Image-aligned Style Transformation
Nov 30, 2022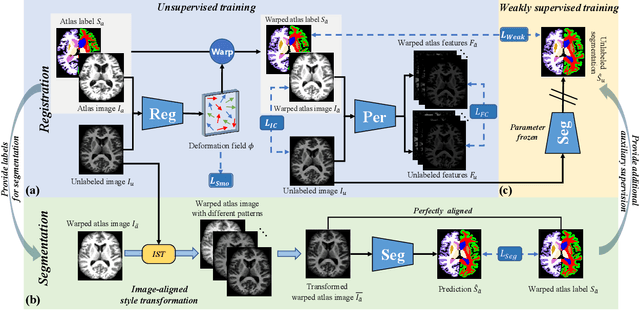
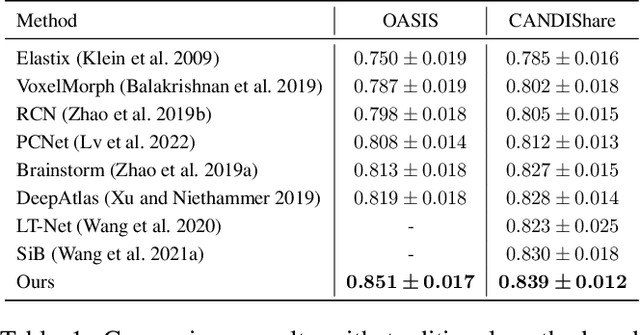
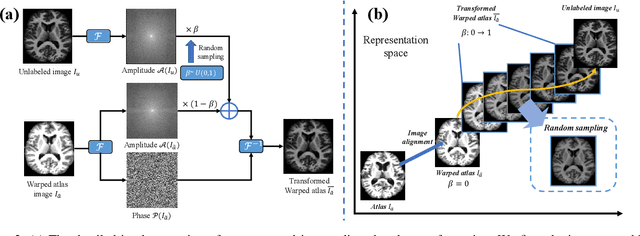
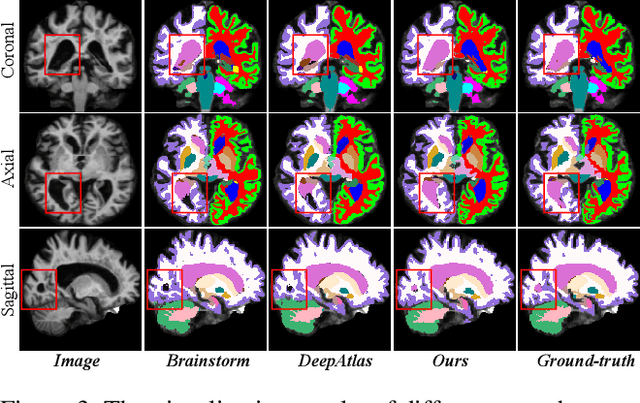
One-shot segmentation of brain tissues is typically a dual-model iterative learning: a registration model (reg-model) warps a carefully-labeled atlas onto unlabeled images to initialize their pseudo masks for training a segmentation model (seg-model); the seg-model revises the pseudo masks to enhance the reg-model for a better warping in the next iteration. However, there is a key weakness in such dual-model iteration that the spatial misalignment inevitably caused by the reg-model could misguide the seg-model, which makes it converge on an inferior segmentation performance eventually. In this paper, we propose a novel image-aligned style transformation to reinforce the dual-model iterative learning for robust one-shot segmentation of brain tissues. Specifically, we first utilize the reg-model to warp the atlas onto an unlabeled image, and then employ the Fourier-based amplitude exchange with perturbation to transplant the style of the unlabeled image into the aligned atlas. This allows the subsequent seg-model to learn on the aligned and style-transferred copies of the atlas instead of unlabeled images, which naturally guarantees the correct spatial correspondence of an image-mask training pair, without sacrificing the diversity of intensity patterns carried by the unlabeled images. Furthermore, we introduce a feature-aware content consistency in addition to the image-level similarity to constrain the reg-model for a promising initialization, which avoids the collapse of image-aligned style transformation in the first iteration. Experimental results on two public datasets demonstrate 1) a competitive segmentation performance of our method compared to the fully-supervised method, and 2) a superior performance over other state-of-the-art with an increase of average Dice by up to 4.67%. The source code is available at: https://github.com/JinxLv/One-shot-segmentation-via-IST.
Learning 3D Representations from 2D Pre-trained Models via Image-to-Point Masked Autoencoders
Dec 13, 2022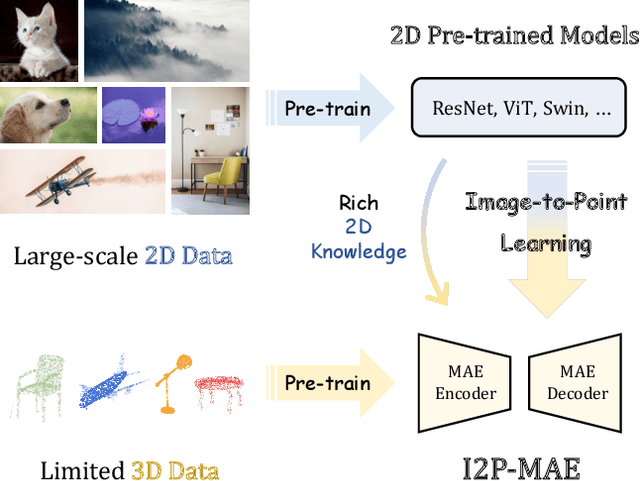
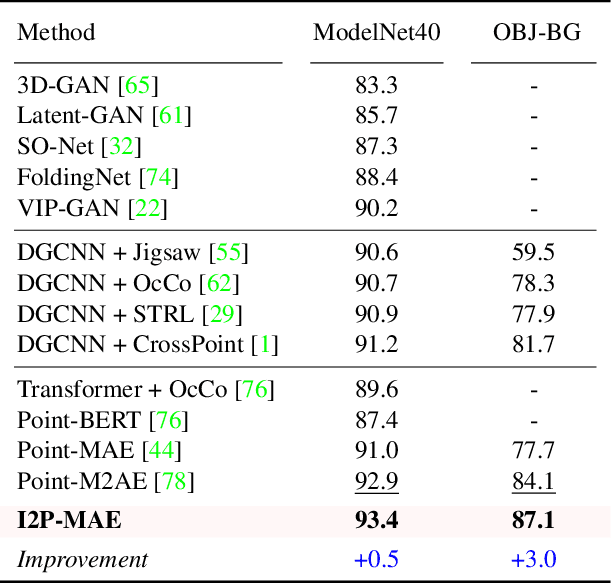
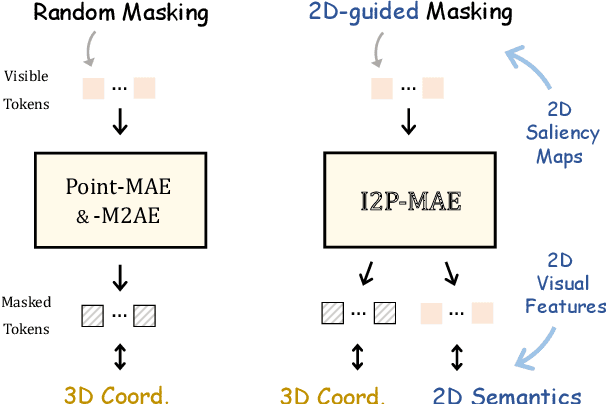
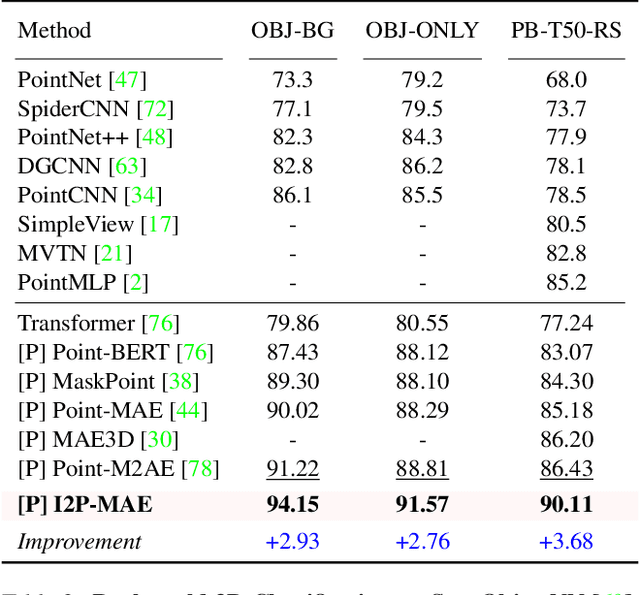
Pre-training by numerous image data has become de-facto for robust 2D representations. In contrast, due to the expensive data acquisition and annotation, a paucity of large-scale 3D datasets severely hinders the learning for high-quality 3D features. In this paper, we propose an alternative to obtain superior 3D representations from 2D pre-trained models via Image-to-Point Masked Autoencoders, named as I2P-MAE. By self-supervised pre-training, we leverage the well learned 2D knowledge to guide 3D masked autoencoding, which reconstructs the masked point tokens with an encoder-decoder architecture. Specifically, we first utilize off-the-shelf 2D models to extract the multi-view visual features of the input point cloud, and then conduct two types of image-to-point learning schemes on top. For one, we introduce a 2D-guided masking strategy that maintains semantically important point tokens to be visible for the encoder. Compared to random masking, the network can better concentrate on significant 3D structures and recover the masked tokens from key spatial cues. For another, we enforce these visible tokens to reconstruct the corresponding multi-view 2D features after the decoder. This enables the network to effectively inherit high-level 2D semantics learned from rich image data for discriminative 3D modeling. Aided by our image-to-point pre-training, the frozen I2P-MAE, without any fine-tuning, achieves 93.4% accuracy for linear SVM on ModelNet40, competitive to the fully trained results of existing methods. By further fine-tuning on on ScanObjectNN's hardest split, I2P-MAE attains the state-of-the-art 90.11% accuracy, +3.68% to the second-best, demonstrating superior transferable capacity. Code will be available at https://github.com/ZrrSkywalker/I2P-MAE.