 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
RoSI: Recovering 3D Shape Interiors from Few Articulation Images
Apr 13, 2023
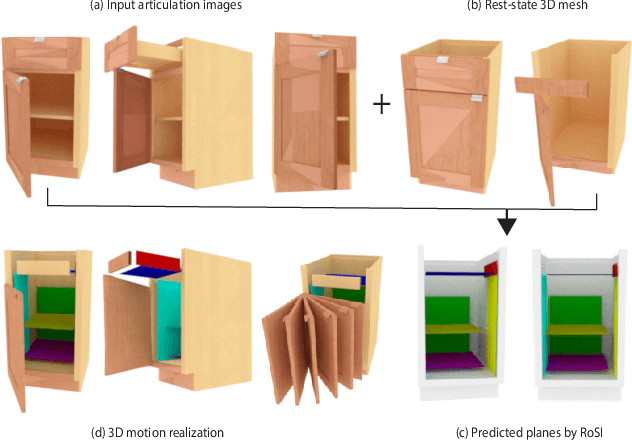

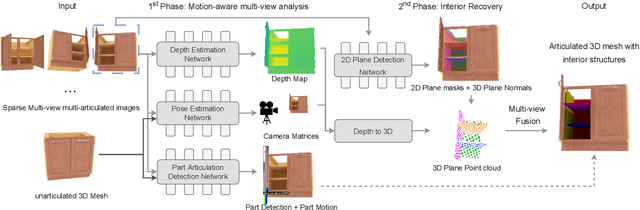

The dominant majority of 3D models that appear in gaming, VR/AR, and those we use to train geometric deep learning algorithms are incomplete, since they are modeled as surface meshes and missing their interior structures. We present a learning framework to recover the shape interiors (RoSI) of existing 3D models with only their exteriors from multi-view and multi-articulation images. Given a set of RGB images that capture a target 3D object in different articulated poses, possibly from only few views, our method infers the interior planes that are observable in the input images. Our neural architecture is trained in a category-agnostic manner and it consists of a motion-aware multi-view analysis phase including pose, depth, and motion estimations, followed by interior plane detection in images and 3D space, and finally multi-view plane fusion. In addition, our method also predicts part articulations and is able to realize and even extrapolate the captured motions on the target 3D object. We evaluate our method by quantitative and qualitative comparisons to baselines and alternative solutions, as well as testing on untrained object categories and real image inputs to assess its generalization capabilities.
Blind deblurring of hyperspectral document images
Mar 09, 2023Most computer vision and machine learning-based approaches for historical document analysis are tailored to grayscale or RGB images and thus, mostly exploit their spatial information. Multispectral (MS) and hyperspectral (HS) images contain, next to the spatial information, much richer spectral information than RGB images (usually spreading beyond the visible spectral range) that can facilitate more effective feature extraction, more accurate classification and recognition, and thus, improved analysis. Although utilization of rich spectral information can improve historical document analysis tremendously, there are still some potential limitations of HS imagery such as camera-induced noise and blur that require a carefully designed preprocessing step. Here, we propose novel blind HS image deblurring methods tailored to document images. We exploit a low-rank property of HS images (i.e., by projecting an HS image to a lower dimensional subspace) and utilize a text tailor image prior to performing a PSF estimation and deblurring of subspace components. The preliminary results show that the proposed approach gives good results over all spectral bands, removing successfully image artefacts introduced by blur and noise and significantly increasing the number of bands that can be used in further analysis.
* This project has received funding from the European Union's Horizon 2020 research and innovation programme under grant agreement No. 101026453. This work is published in the Lecture Notes in Computer Science book series (LNCS, volume 13373) as part of the Image Analysis and Processing, ICIAP 2022 Workshops
Virtual Inverse Perspective Mapping for Simultaneous Pose and Motion Estimation
Mar 09, 2023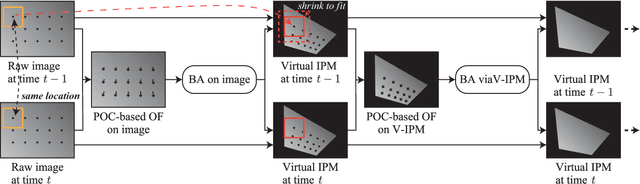
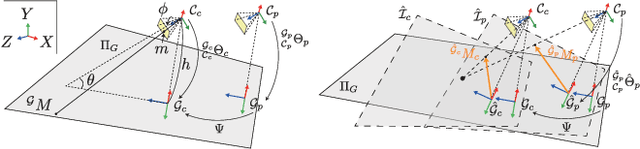
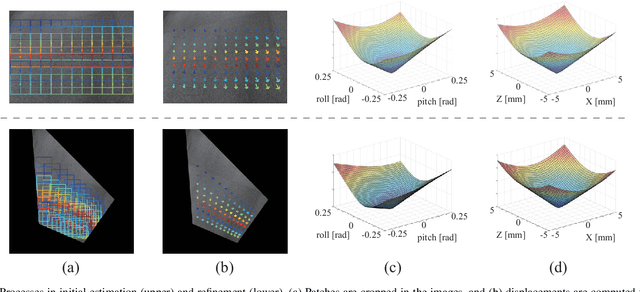
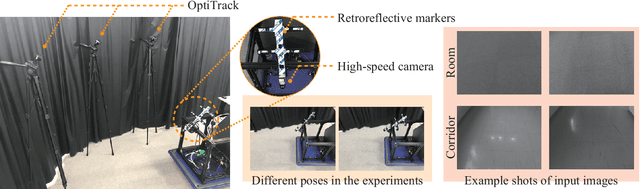
We propose an automatic method for pose and motion estimation against a ground surface for a ground-moving robot-mounted monocular camera. The framework adopts a semi-dense approach that benefits from both a feature-based method and an image-registration-based method by setting multiple patches in the image for displacement computation through a highly accurate image-registration technique. To improve accuracy, we introduce virtual inverse perspective mapping (IPM) in the refinement step to eliminate the perspective effect on image registration. The pose and motion are jointly and robustly estimated by a formulation of geometric bundle adjustment via virtual IPM. Unlike conventional visual odometry methods, the proposed method is free from cumulative error because it directly estimates pose and motion against the ground by taking advantage of a camera configuration mounted on a ground-moving robot where the camera's vertical motion is ignorable compared to its height within the frame interval and the nearby ground surface is approximately flat. We conducted experiments in which the relative mean error of the pitch and roll angles was approximately 1.0 degrees and the absolute mean error of the travel distance was 0.3 mm, even under camera shaking within a short period.
Multimodal Shannon Game with Images
Mar 20, 2023

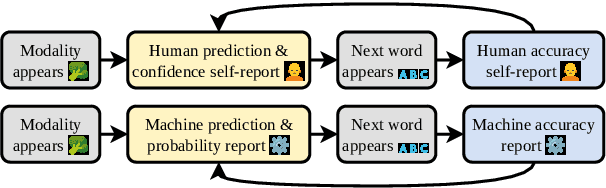

The Shannon game has long been used as a thought experiment in linguistics and NLP, asking participants to guess the next letter in a sentence based on its preceding context. We extend the game by introducing an optional extra modality in the form of image information. To investigate the impact of multimodal information in this game, we use human participants and a language model (LM, GPT-2). We show that the addition of image information improves both self-reported confidence and accuracy for both humans and LM. Certain word classes, such as nouns and determiners, benefit more from the additional modality information. The priming effect in both humans and the LM becomes more apparent as the context size (extra modality information + sentence context) increases. These findings highlight the potential of multimodal information in improving language understanding and modeling.
Multidimensional Uncertainty Quantification for Deep Neural Networks
Apr 20, 2023
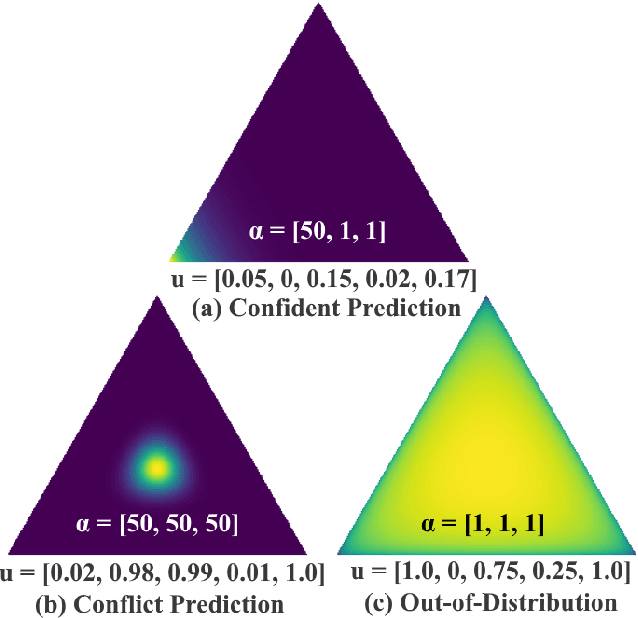
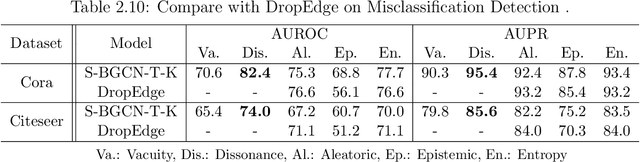

Deep neural networks (DNNs) have received tremendous attention and achieved great success in various applications, such as image and video analysis, natural language processing, recommendation systems, and drug discovery. However, inherent uncertainties derived from different root causes have been realized as serious hurdles for DNNs to find robust and trustworthy solutions for real-world problems. A lack of consideration of such uncertainties may lead to unnecessary risk. For example, a self-driving autonomous car can misdetect a human on the road. A deep learning-based medical assistant may misdiagnose cancer as a benign tumor. In this work, we study how to measure different uncertainty causes for DNNs and use them to solve diverse decision-making problems more effectively. In the first part of this thesis, we develop a general learning framework to quantify multiple types of uncertainties caused by different root causes, such as vacuity (i.e., uncertainty due to a lack of evidence) and dissonance (i.e., uncertainty due to conflicting evidence), for graph neural networks. We provide a theoretical analysis of the relationships between different uncertainty types. We further demonstrate that dissonance is most effective for misclassification detection and vacuity is most effective for Out-of-Distribution (OOD) detection. In the second part of the thesis, we study the significant impact of OOD objects on semi-supervised learning (SSL) for DNNs and develop a novel framework to improve the robustness of existing SSL algorithms against OODs. In the last part of the thesis, we create a general learning framework to quantity multiple uncertainty types for multi-label temporal neural networks. We further develop novel uncertainty fusion operators to quantify the fused uncertainty of a subsequence for early event detection.
Backpropagation-free Training of Deep Physical Neural Networks
Apr 20, 2023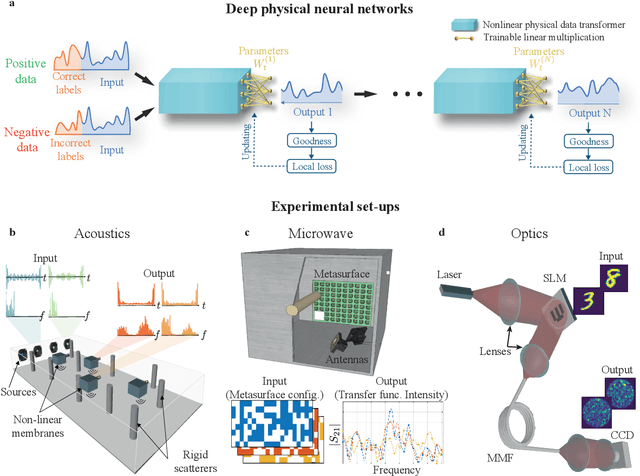
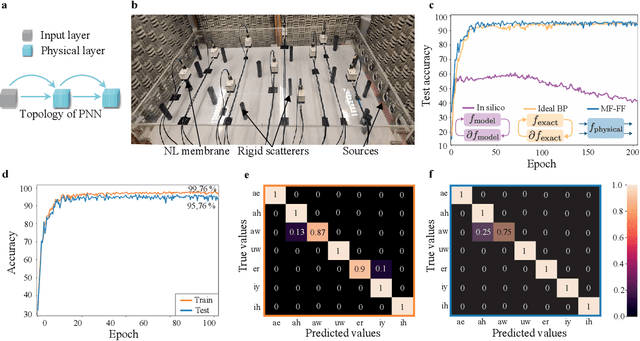
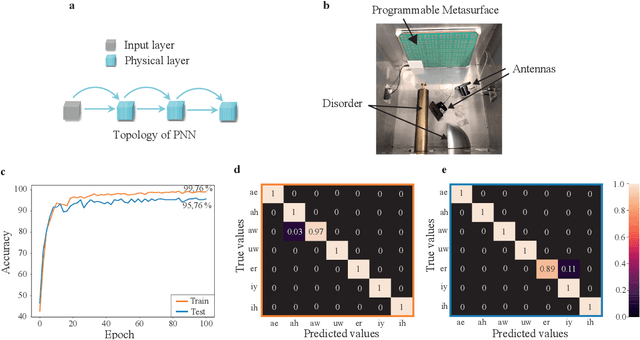
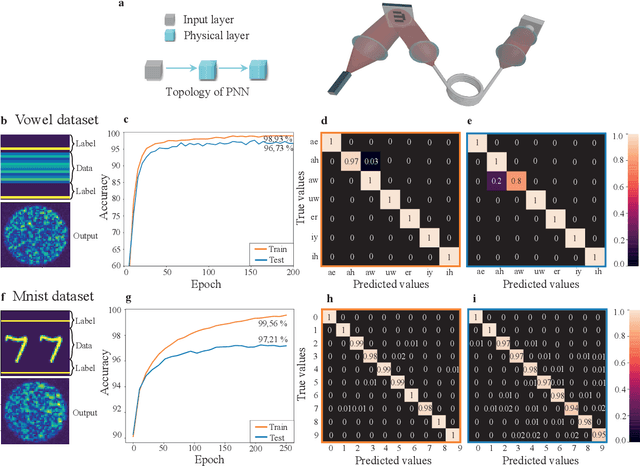
Recent years have witnessed the outstanding success of deep learning in various fields such as vision and natural language processing. This success is largely indebted to the massive size of deep learning models that is expected to increase unceasingly. This growth of the deep learning models is accompanied by issues related to their considerable energy consumption, both during the training and inference phases, as well as their scalability. Although a number of work based on unconventional physical systems have been proposed which addresses the issue of energy efficiency in the inference phase, efficient training of deep learning models has remained unaddressed. So far, training of digital deep learning models mainly relies on backpropagation, which is not suitable for physical implementation as it requires perfect knowledge of the computation performed in the so-called forward pass of the neural network. Here, we tackle this issue by proposing a simple deep neural network architecture augmented by a biologically plausible learning algorithm, referred to as "model-free forward-forward training". The proposed architecture enables training deep physical neural networks consisting of layers of physical nonlinear systems, without requiring detailed knowledge of the nonlinear physical layers' properties. We show that our method outperforms state-of-the-art hardware-aware training methods by improving training speed, decreasing digital computations, and reducing power consumption in physical systems. We demonstrate the adaptability of the proposed method, even in systems exposed to dynamic or unpredictable external perturbations. To showcase the universality of our approach, we train diverse wave-based physical neural networks that vary in the underlying wave phenomenon and the type of non-linearity they use, to perform vowel and image classification tasks experimentally.
Robustmix: Improving Robustness by Regularizing the Frequency Bias of Deep Nets
Apr 06, 2023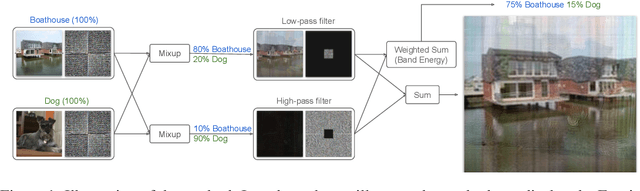
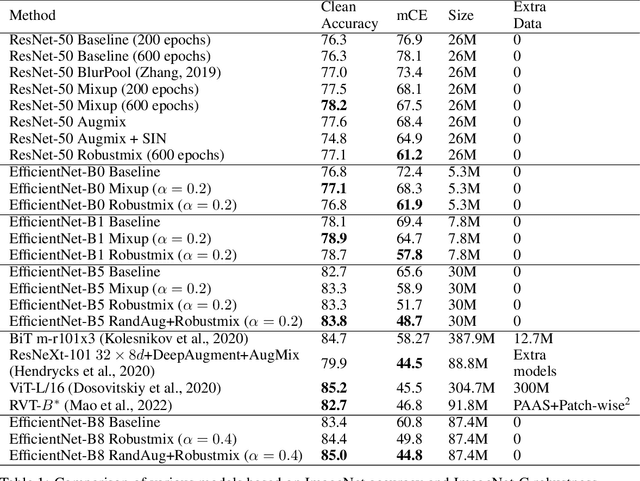
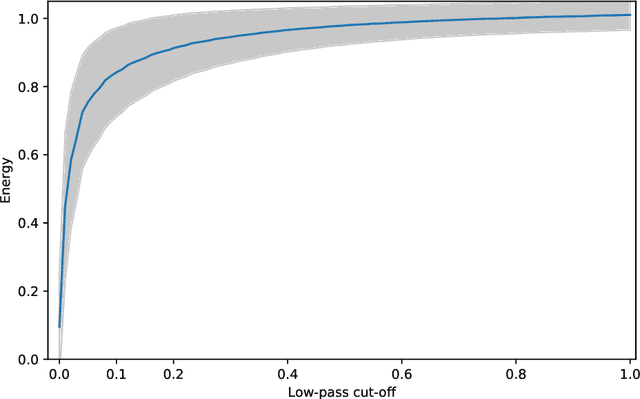
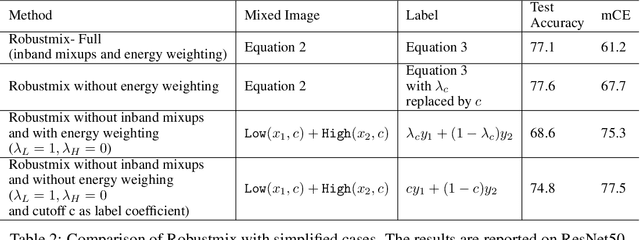
Deep networks have achieved impressive results on a range of well-curated benchmark datasets. Surprisingly, their performance remains sensitive to perturbations that have little effect on human performance. In this work, we propose a novel extension of Mixup called Robustmix that regularizes networks to classify based on lower-frequency spatial features. We show that this type of regularization improves robustness on a range of benchmarks such as Imagenet-C and Stylized Imagenet. It adds little computational overhead and, furthermore, does not require a priori knowledge of a large set of image transformations. We find that this approach further complements recent advances in model architecture and data augmentation, attaining a state-of-the-art mCE of 44.8 with an EfficientNet-B8 model and RandAugment, which is a reduction of 16 mCE compared to the baseline.
Multi-Linear Kernel Regression and Imputation in Data Manifolds
Apr 06, 2023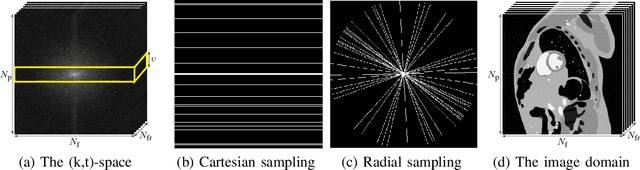
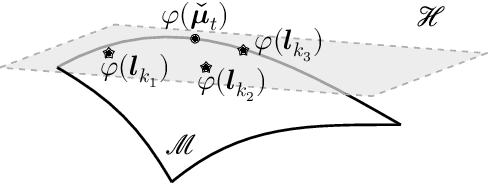
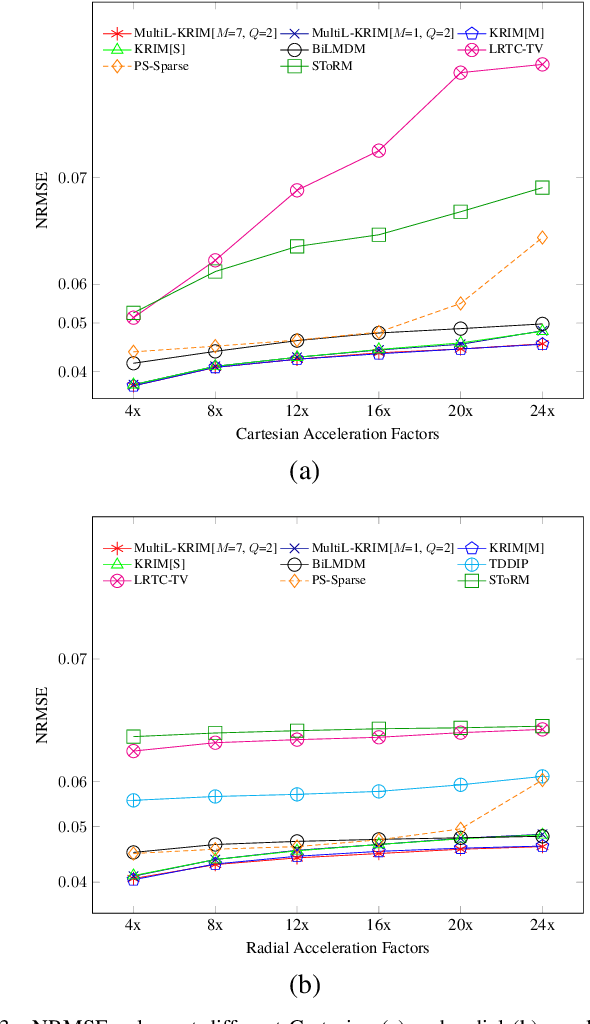
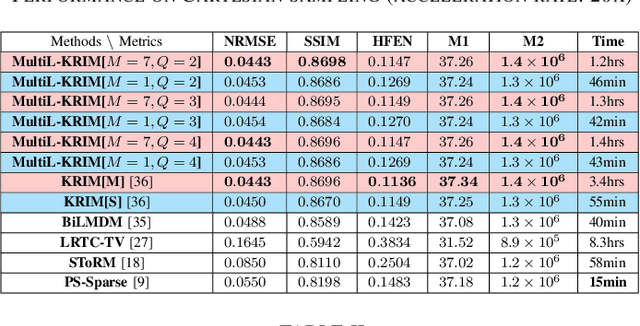
This paper introduces an efficient multi-linear nonparametric (kernel-based) approximation framework for data regression and imputation, and its application to dynamic magnetic-resonance imaging (dMRI). Data features are assumed to reside in or close to a smooth manifold embedded in a reproducing kernel Hilbert space. Landmark points are identified to describe concisely the point cloud of features by linear approximating patches which mimic the concept of tangent spaces to smooth manifolds. The multi-linear model effects dimensionality reduction, enables efficient computations, and extracts data patterns and their geometry without any training data or additional information. Numerical tests on dMRI data under severe under-sampling demonstrate remarkable improvements in efficiency and accuracy of the proposed approach over its predecessors, popular data modeling methods, as well as recent tensor-based and deep-image-prior schemes.
GI Software with fewer Data Cache Misses
Apr 06, 2023
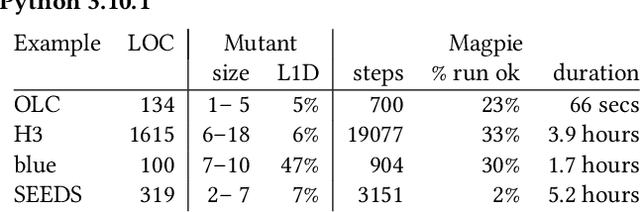

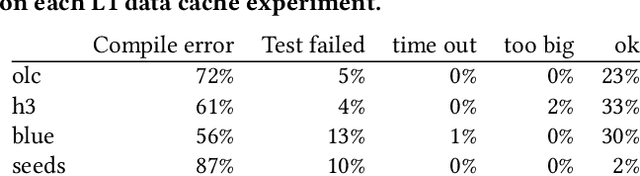
By their very name caches are often overlooked and yet play a vital role in the performance of modern and indeed future hardware. Using MAGPIE (Machine Automated General Performance Improvement via Evolution of software) we show genetic improvement GI can reduce the cache load of existing computer programs. Operating on lines of C and C++ source code using local search, Magpie can generate new functionally equivalent variants which generate fewer L1 data cache misses. Cache miss reduction is tested on two industrial open source programs (Google's Open Location Code OLC and Uber's Hexagonal Hierarchical Spatial Index H3) and two 2D photograph image processing tasks, counting pixels and OpenCV's SEEDS segmentation algorithm. Magpie's patches functionally generalise. In one case they reduce data misses on the highest performance L1 cache dramatically by 47 percent.
A Neural Network Transformer Model for Composite Microstructure Homogenization
Apr 16, 2023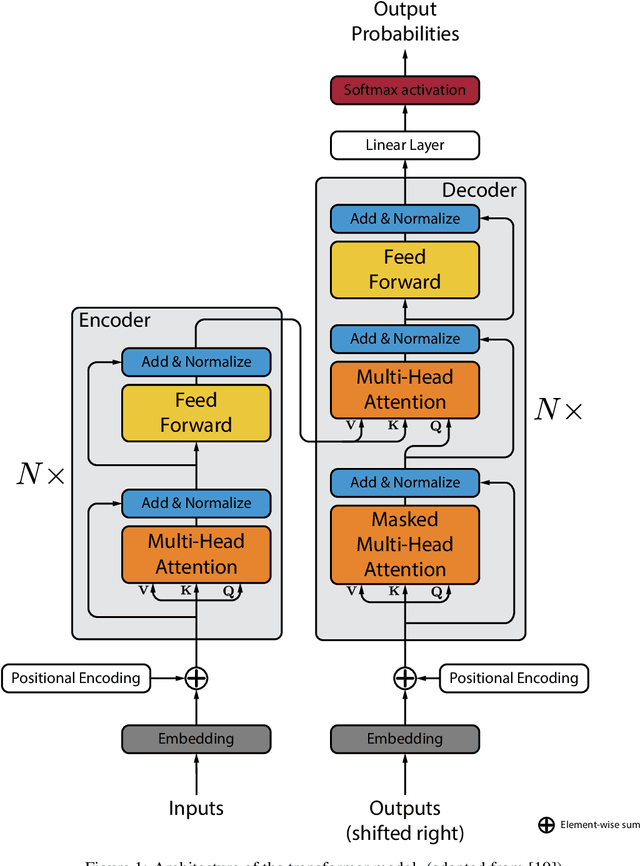

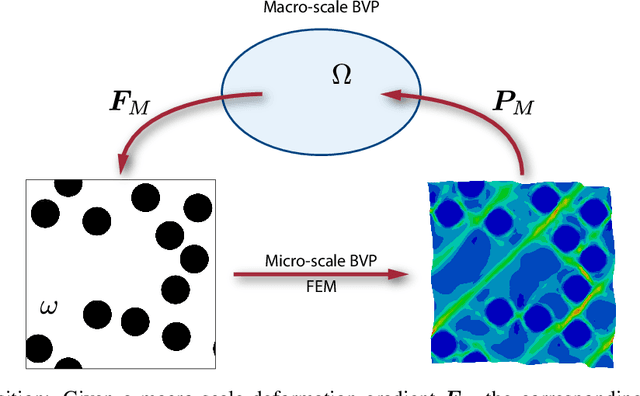
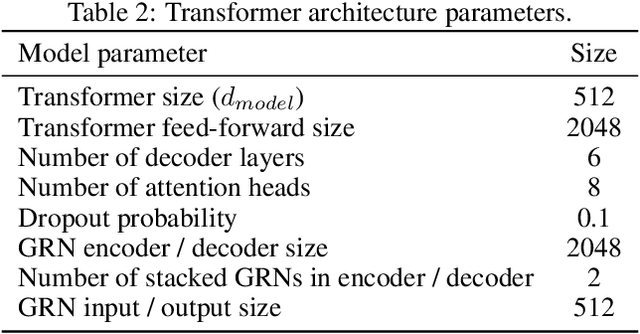
Heterogeneity and uncertainty in a composite microstructure lead to either computational bottlenecks if modeled rigorously, or to solution inaccuracies in the stress field and failure predictions if approximated. Although methods suitable for analyzing arbitrary and non-linear microstructures exist, their computational cost makes them impractical to use in large-scale structural analysis. Surrogate models or Reduced Order Models (ROM), commonly enhance efficiencies, but they are typically calibrated with a single microstructure. Homogenization methods, such as the Mori-Tanaka method, offer rapid homogenization for a wide range of constituent properties. However, simplifying assumptions, like stress and strain averaging in phases, render the consideration of both deterministic and stochastic variations in microstructure infeasible. This paper illustrates a transformer neural network architecture that captures the knowledge of various microstructures and constituents, enabling it to function as a computationally efficient homogenization surrogate model. Given an image or an abstraction of an arbitrary composite microstructure, the transformer network predicts the homogenized stress-strain response. Two methods were tested that encode features of the microstructure. The first method calculates two-point statistics of the microstructure and uses Principal Component Analysis for dimensionality reduction. The second method uses an autoencoder with a Convolutional Neural Network. Both microstructure encoding methods accurately predict the homogenized material response. The paper describes the network architecture, training and testing data generation and the performance of the transformer network under cycling and random loadings.