 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Fluctuation based interpretable analysis scheme for quantum many-body snapshots
Apr 12, 2023
Microscopically understanding and classifying phases of matter is at the heart of strongly-correlated quantum physics. With quantum simulations, genuine projective measurements (snapshots) of the many-body state can be taken, which include the full information of correlations in the system. The rise of deep neural networks has made it possible to routinely solve abstract processing and classification tasks of large datasets, which can act as a guiding hand for quantum data analysis. However, though proven to be successful in differentiating between different phases of matter, conventional neural networks mostly lack interpretability on a physical footing. Here, we combine confusion learning with correlation convolutional neural networks, which yields fully interpretable phase detection in terms of correlation functions. In particular, we study thermodynamic properties of the 2D Heisenberg model, whereby the trained network is shown to pick up qualitative changes in the snapshots above and below a characteristic temperature where magnetic correlations become significantly long-range. We identify the full counting statistics of nearest neighbor spin correlations as the most important quantity for the decision process of the neural network, which go beyond averages of local observables. With access to the fluctuations of second-order correlations -- which indirectly include contributions from higher order, long-range correlations -- the network is able to detect changes of the specific heat and spin susceptibility, the latter being in analogy to magnetic properties of the pseudogap phase in high-temperature superconductors. By combining the confusion learning scheme with transformer neural networks, our work opens new directions in interpretable quantum image processing being sensible to long-range order.
eDiff-I: Text-to-Image Diffusion Models with an Ensemble of Expert Denoisers
Nov 17, 2022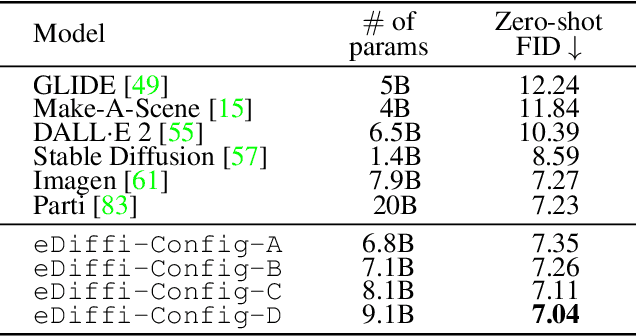
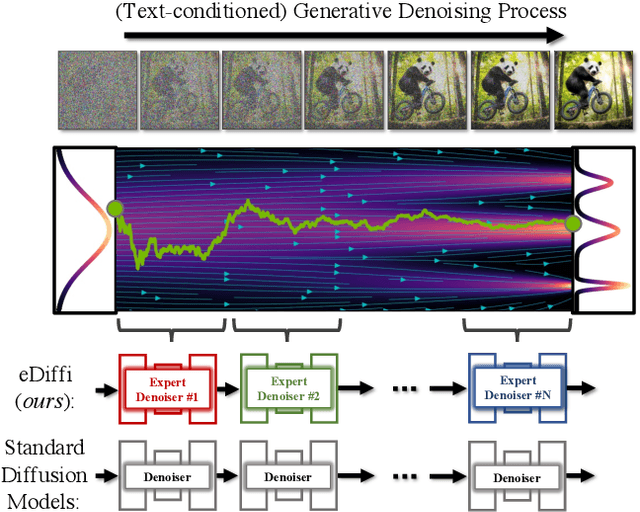

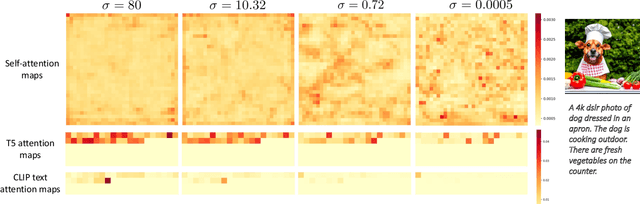
Large-scale diffusion-based generative models have led to breakthroughs in text-conditioned high-resolution image synthesis. Starting from random noise, such text-to-image diffusion models gradually synthesize images in an iterative fashion while conditioning on text prompts. We find that their synthesis behavior qualitatively changes throughout this process: Early in sampling, generation strongly relies on the text prompt to generate text-aligned content, while later, the text conditioning is almost entirely ignored. This suggests that sharing model parameters throughout the entire generation process may not be ideal. Therefore, in contrast to existing works, we propose to train an ensemble of text-to-image diffusion models specialized for different synthesis stages. To maintain training efficiency, we initially train a single model, which is then split into specialized models that are trained for the specific stages of the iterative generation process. Our ensemble of diffusion models, called eDiff-I, results in improved text alignment while maintaining the same inference computation cost and preserving high visual quality, outperforming previous large-scale text-to-image diffusion models on the standard benchmark. In addition, we train our model to exploit a variety of embeddings for conditioning, including the T5 text, CLIP text, and CLIP image embeddings. We show that these different embeddings lead to different behaviors. Notably, the CLIP image embedding allows an intuitive way of transferring the style of a reference image to the target text-to-image output. Lastly, we show a technique that enables eDiff-I's "paint-with-words" capability. A user can select the word in the input text and paint it in a canvas to control the output, which is very handy for crafting the desired image in mind. The project page is available at https://deepimagination.cc/eDiff-I/
Self-Supervised Pre-training of 3D Point Cloud Networks with Image Data
Nov 21, 2022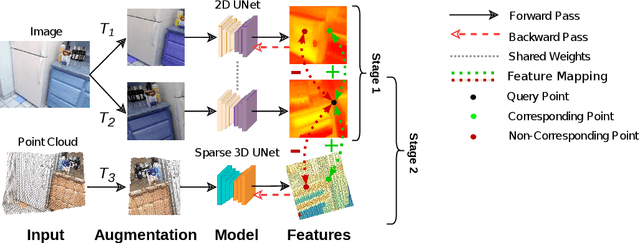
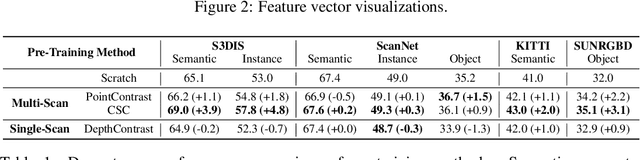

Reducing the quantity of annotations required for supervised training is vital when labels are scarce and costly. This reduction is especially important for semantic segmentation tasks involving 3D datasets that are often significantly smaller and more challenging to annotate than their image-based counterparts. Self-supervised pre-training on large unlabelled datasets is one way to reduce the amount of manual annotations needed. Previous work has focused on pre-training with point cloud data exclusively; this approach often requires two or more registered views. In the present work, we combine image and point cloud modalities, by first learning self-supervised image features and then using these features to train a 3D model. By incorporating image data, which is often included in many 3D datasets, our pre-training method only requires a single scan of a scene. We demonstrate that our pre-training approach, despite using single scans, achieves comparable performance to other multi-scan, point cloud-only methods.
Cascaded Local Implicit Transformer for Arbitrary-Scale Super-Resolution
Mar 29, 2023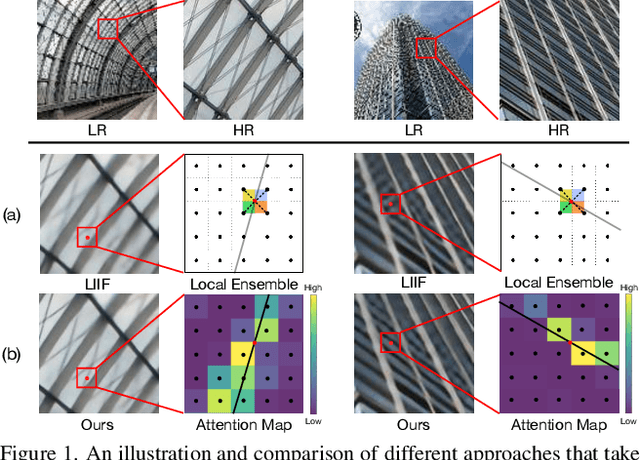
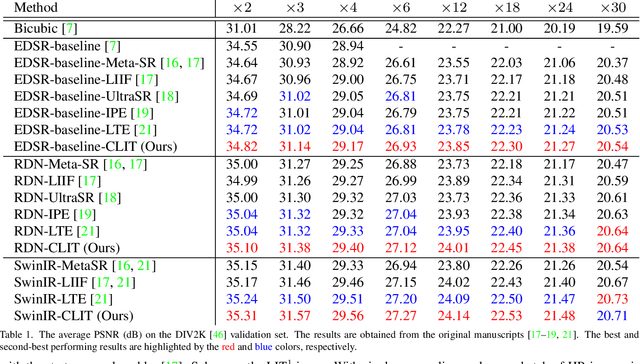
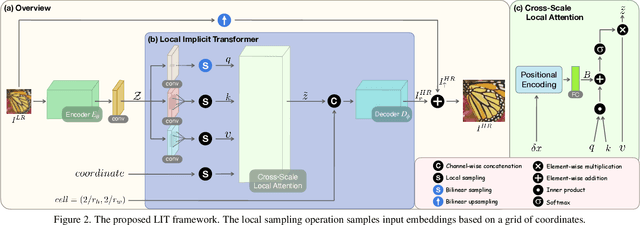
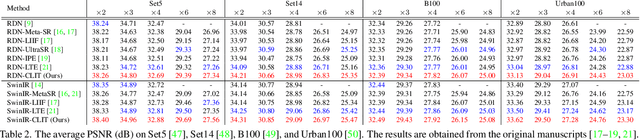
Implicit neural representation has recently shown a promising ability in representing images with arbitrary resolutions. In this paper, we present a Local Implicit Transformer (LIT), which integrates the attention mechanism and frequency encoding technique into a local implicit image function. We design a cross-scale local attention block to effectively aggregate local features. To further improve representative power, we propose a Cascaded LIT (CLIT) that exploits multi-scale features, along with a cumulative training strategy that gradually increases the upsampling scales during training. We have conducted extensive experiments to validate the effectiveness of these components and analyze various training strategies. The qualitative and quantitative results demonstrate that LIT and CLIT achieve favorable results and outperform the prior works in arbitrary super-resolution tasks.
BiCro: Noisy Correspondence Rectification for Multi-modality Data via Bi-directional Cross-modal Similarity Consistency
Mar 22, 2023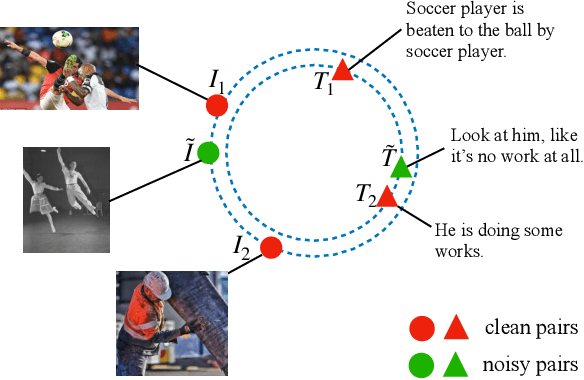
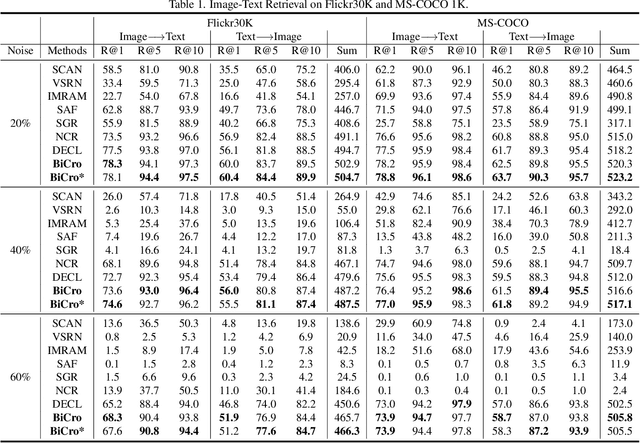

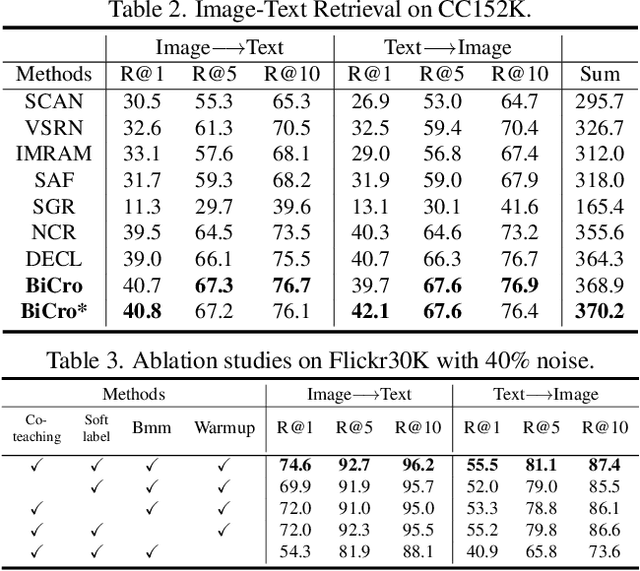
As one of the most fundamental techniques in multimodal learning, cross-modal matching aims to project various sensory modalities into a shared feature space. To achieve this, massive and correctly aligned data pairs are required for model training. However, unlike unimodal datasets, multimodal datasets are extremely harder to collect and annotate precisely. As an alternative, the co-occurred data pairs (e.g., image-text pairs) collected from the Internet have been widely exploited in the area. Unfortunately, the cheaply collected dataset unavoidably contains many mismatched data pairs, which have been proven to be harmful to the model's performance. To address this, we propose a general framework called BiCro (Bidirectional Cross-modal similarity consistency), which can be easily integrated into existing cross-modal matching models and improve their robustness against noisy data. Specifically, BiCro aims to estimate soft labels for noisy data pairs to reflect their true correspondence degree. The basic idea of BiCro is motivated by that -- taking image-text matching as an example -- similar images should have similar textual descriptions and vice versa. Then the consistency of these two similarities can be recast as the estimated soft labels to train the matching model. The experiments on three popular cross-modal matching datasets demonstrate that our method significantly improves the noise-robustness of various matching models, and surpass the state-of-the-art by a clear margin.
Blowing in the Wind: CycleNet for Human Cinemagraphs from Still Images
Mar 15, 2023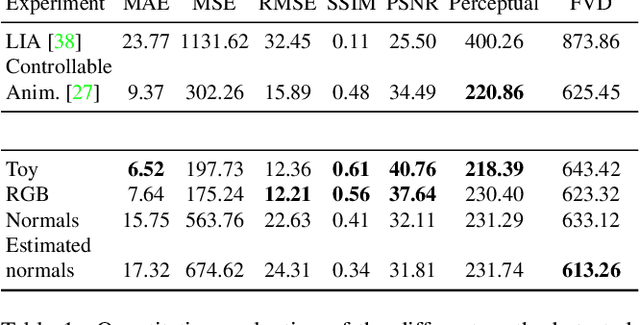
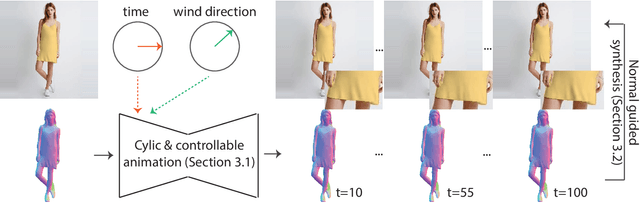
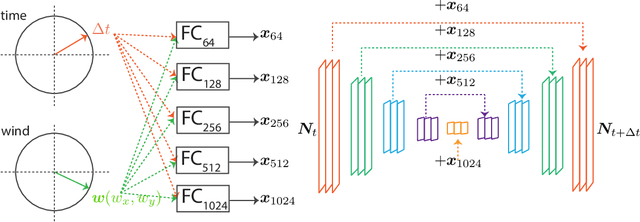

Cinemagraphs are short looping videos created by adding subtle motions to a static image. This kind of media is popular and engaging. However, automatic generation of cinemagraphs is an underexplored area and current solutions require tedious low-level manual authoring by artists. In this paper, we present an automatic method that allows generating human cinemagraphs from single RGB images. We investigate the problem in the context of dressed humans under the wind. At the core of our method is a novel cyclic neural network that produces looping cinemagraphs for the target loop duration. To circumvent the problem of collecting real data, we demonstrate that it is possible, by working in the image normal space, to learn garment motion dynamics on synthetic data and generalize to real data. We evaluate our method on both synthetic and real data and demonstrate that it is possible to create compelling and plausible cinemagraphs from single RGB images.
Improving Multi-generation Robustness of Learned Image Compression
Oct 31, 2022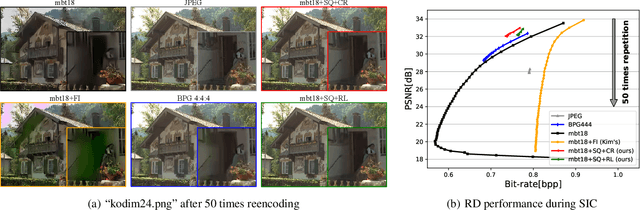

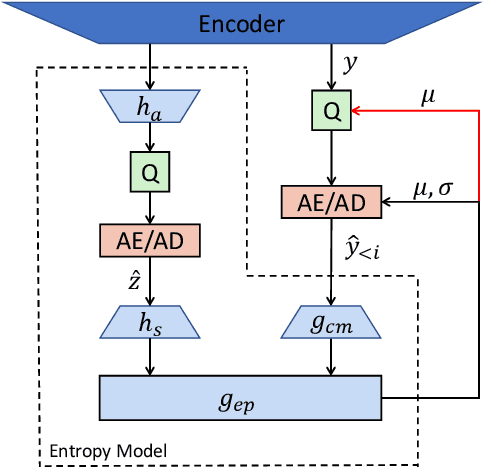
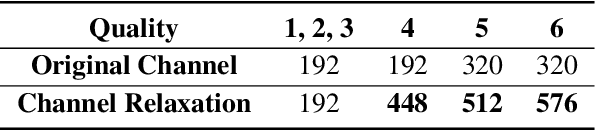
Benefit from flexible network designs and end-to-end joint optimization approach, learned image compression (LIC) has demonstrated excellent coding performance and practical feasibility in recent years. However, existing compression models suffer from serious multi-generation loss, which always occurs during image editing and transcoding. During the process of repeatedly encoding and decoding, the quality of the image will rapidly degrade, resulting in various types of distortion, which significantly limits the practical application of LIC. In this paper, a thorough analysis is carried out to determine the source of generative loss in successive image compression (SIC). We point out and solve the quantization drift problem that affects SIC, reversibility loss function as well as channel relaxation method are proposed to further reduce the generation loss. Experiments show that by using our proposed solutions, LIC can achieve comparable performance to the first compression of BPG even after 50 times reencoding without any change of the network structure.
Mask Detection and Classification in Thermal Face Images
Apr 06, 2023
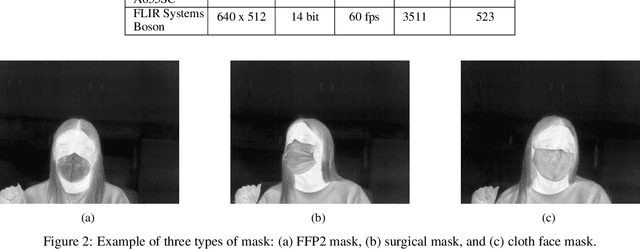
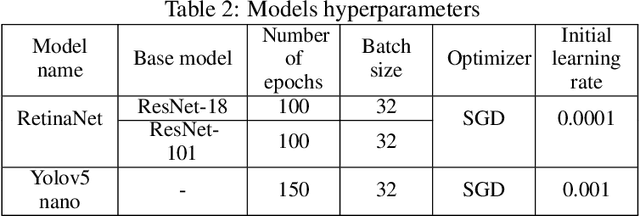

Face masks are recommended to reduce the transmission of many viruses, especially SARS-CoV-2. Therefore, the automatic detection of whether there is a mask on the face, what type of mask is worn, and how it is worn is an important research topic. In this work, the use of thermal imaging was considered to analyze the possibility of detecting (localizing) a mask on the face, as well as to check whether it is possible to classify the type of mask on the face. The previously proposed dataset of thermal images was extended and annotated with the description of a type of mask and a location of a mask within a face. Different deep learning models were adapted. The best model for face mask detection turned out to be the Yolov5 model in the "nano" version, reaching mAP higher than 97% and precision of about 95%. High accuracy was also obtained for mask type classification. The best results were obtained for the convolutional neural network model built on an autoencoder initially trained in the thermal image reconstruction problem. The pretrained encoder was used to train a classifier which achieved an accuracy of 91%.
Towards an Effective and Efficient Transformer for Rain-by-snow Weather Removal
Apr 06, 2023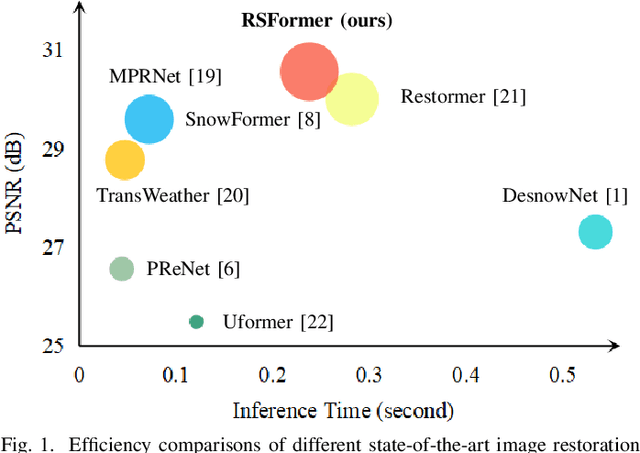
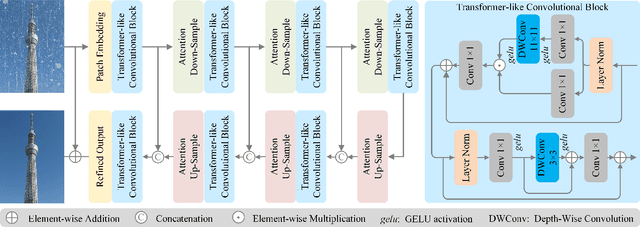
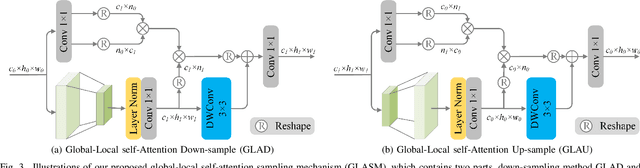
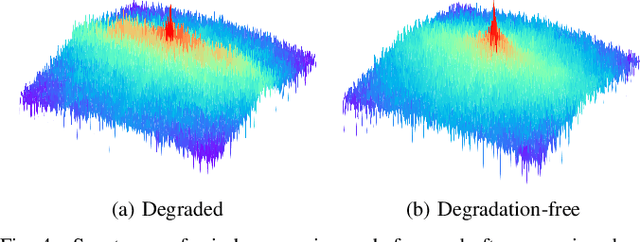
Rain-by-snow weather removal is a specialized task in weather-degraded image restoration aiming to eliminate coexisting rain streaks and snow particles. In this paper, we propose RSFormer, an efficient and effective Transformer that addresses this challenge. Initially, we explore the proximity of convolution networks (ConvNets) and vision Transformers (ViTs) in hierarchical architectures and experimentally find they perform approximately at intra-stage feature learning. On this basis, we utilize a Transformer-like convolution block (TCB) that replaces the computationally expensive self-attention while preserving attention characteristics for adapting to input content. We also demonstrate that cross-stage progression is critical for performance improvement, and propose a global-local self-attention sampling mechanism (GLASM) that down-/up-samples features while capturing both global and local dependencies. Finally, we synthesize two novel rain-by-snow datasets, RSCityScape and RS100K, to evaluate our proposed RSFormer. Extensive experiments verify that RSFormer achieves the best trade-off between performance and time-consumption compared to other restoration methods. For instance, it outperforms Restormer with a 1.53% reduction in the number of parameters and a 15.6% reduction in inference time. Datasets, source code and pre-trained models are available at \url{https://github.com/chdwyb/RSFormer}.
DreamAvatar: Text-and-Shape Guided 3D Human Avatar Generation via Diffusion Models
Apr 06, 2023
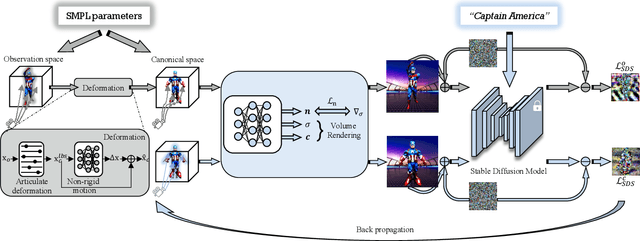


We present DreamAvatar, a text-and-shape guided framework for generating high-quality 3D human avatars with controllable poses. While encouraging results have been produced by recent methods on text-guided 3D common object generation, generating high-quality human avatars remains an open challenge due to the complexity of the human body's shape, pose, and appearance. We propose DreamAvatar to tackle this challenge, which utilizes a trainable NeRF for predicting density and color features for 3D points and a pre-trained text-to-image diffusion model for providing 2D self-supervision. Specifically, we leverage SMPL models to provide rough pose and shape guidance for the generation. We introduce a dual space design that comprises a canonical space and an observation space, which are related by a learnable deformation field through the NeRF, allowing for the transfer of well-optimized texture and geometry from the canonical space to the target posed avatar. Additionally, we exploit a normal-consistency regularization to allow for more vivid generation with detailed geometry and texture. Through extensive evaluations, we demonstrate that DreamAvatar significantly outperforms existing methods, establishing a new state-of-the-art for text-and-shape guided 3D human generation.