 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning and generalization of compositional representations of visual scenes
Mar 23, 2023
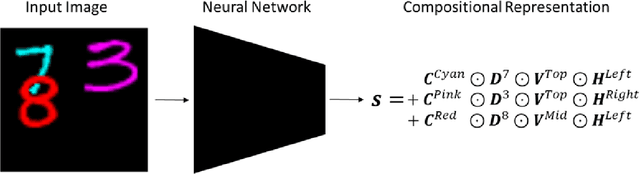
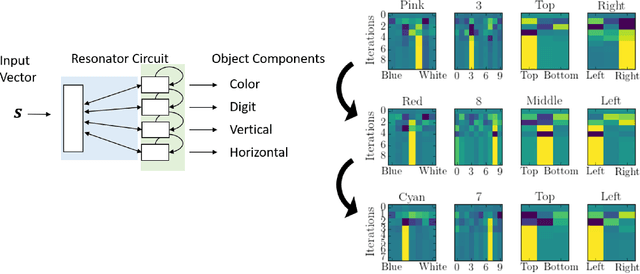
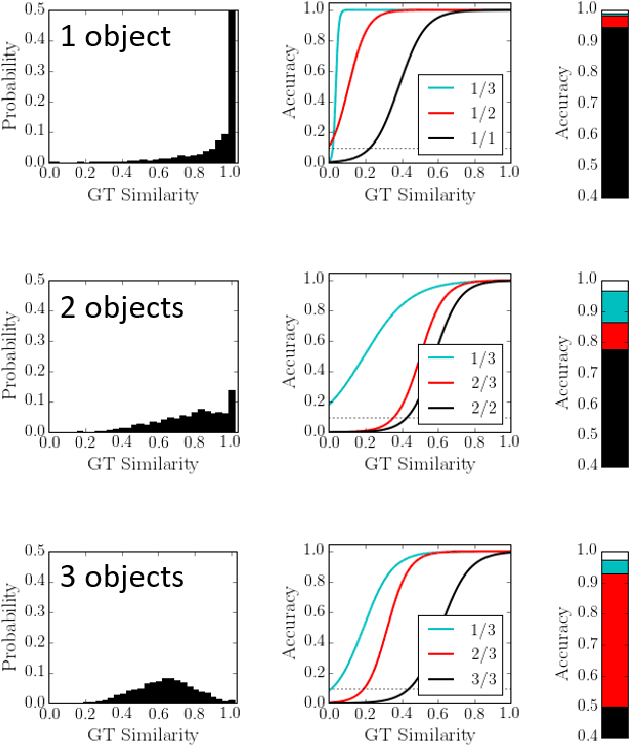
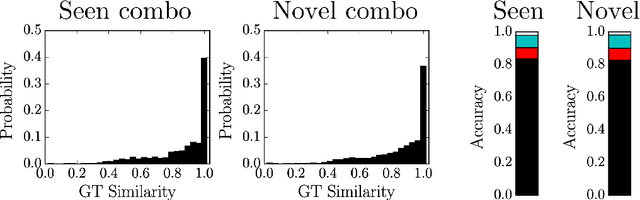
Complex visual scenes that are composed of multiple objects, each with attributes, such as object name, location, pose, color, etc., are challenging to describe in order to train neural networks. Usually,deep learning networks are trained supervised by categorical scene descriptions. The common categorical description of a scene contains the names of individual objects but lacks information about other attributes. Here, we use distributed representations of object attributes and vector operations in a vector symbolic architecture to create a full compositional description of a scene in a high-dimensional vector. To control the scene composition, we use artificial images composed of multiple, translated and colored MNIST digits. In contrast to learning category labels, here we train deep neural networks to output the full compositional vector description of an input image. The output of the deep network can then be interpreted by a VSA resonator network, to extract object identity or other properties of indiviual objects. We evaluate the performance and generalization properties of the system on randomly generated scenes. Specifically, we show that the network is able to learn the task and generalize to unseen seen digit shapes and scene configurations. Further, the generalisation ability of the trained model is limited. For example, with a gap in the training data, like an object not shown in a particular image location during training, the learning does not automatically fill this gap.
Breast Cancer Histopathology Image based Gene Expression Prediction using Spatial Transcriptomics data and Deep Learning
Mar 17, 2023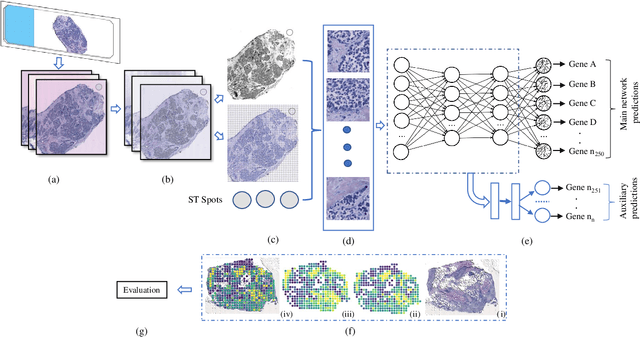
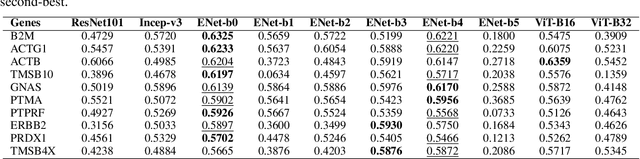
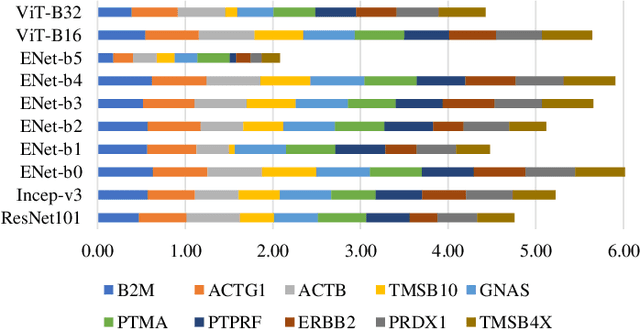
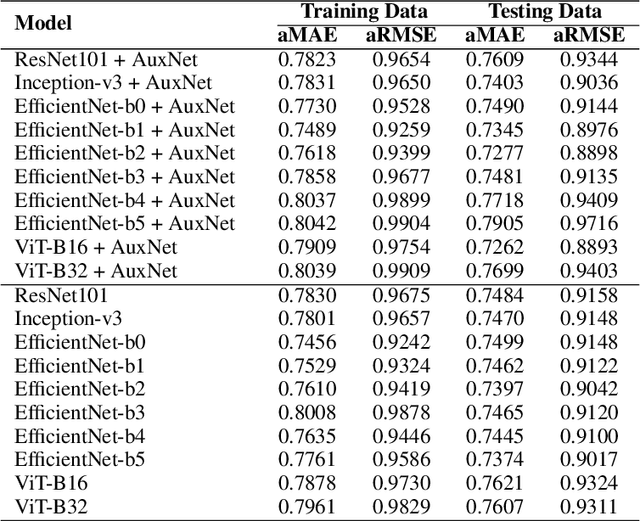
Tumour heterogeneity in breast cancer poses challenges in predicting outcome and response to therapy. Spatial transcriptomics technologies may address these challenges, as they provide a wealth of information about gene expression at the cell level, but they are expensive, hindering their use in large-scale clinical oncology studies. Predicting gene expression from hematoxylin and eosin stained histology images provides a more affordable alternative for such studies. Here we present BrST-Net, a deep learning framework for predicting gene expression from histopathology images using spatial transcriptomics data. Using this framework, we trained and evaluated 10 state-of-the-art deep learning models without utilizing pretrained weights for the prediction of 250 genes. To enhance the generalisation performance of the main network, we introduce an auxiliary network into the framework. Our methodology outperforms previous studies, with 237 genes identified with positive correlation, including 24 genes with a median correlation coefficient greater than 0.50. This is a notable improvement over previous studies, which could predict only 102 genes with positive correlation, with the highest correlation values ranging from 0.29 to 0.34.
Unsupervised Structure-Consistent Image-to-Image Translation
Aug 24, 2022
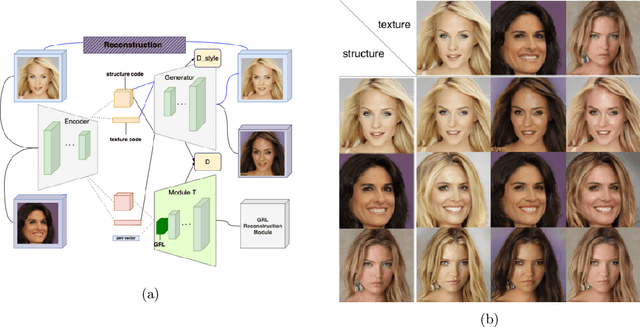


The Swapping Autoencoder achieved state-of-the-art performance in deep image manipulation and image-to-image translation. We improve this work by introducing a simple yet effective auxiliary module based on gradient reversal layers. The auxiliary module's loss forces the generator to learn to reconstruct an image with an all-zero texture code, encouraging better disentanglement between the structure and texture information. The proposed attribute-based transfer method enables refined control in style transfer while preserving structural information without using a semantic mask. To manipulate an image, we encode both the geometry of the objects and the general style of the input images into two latent codes with an additional constraint that enforces structure consistency. Moreover, due to the auxiliary loss, training time is significantly reduced. The superiority of the proposed model is demonstrated in complex domains such as satellite images where state-of-the-art are known to fail. Lastly, we show that our model improves the quality metrics for a wide range of datasets while achieving comparable results with multi-modal image generation techniques.
Using Large Text-to-Image Models with Structured Prompts for Skin Disease Identification: A Case Study
Jan 17, 2023

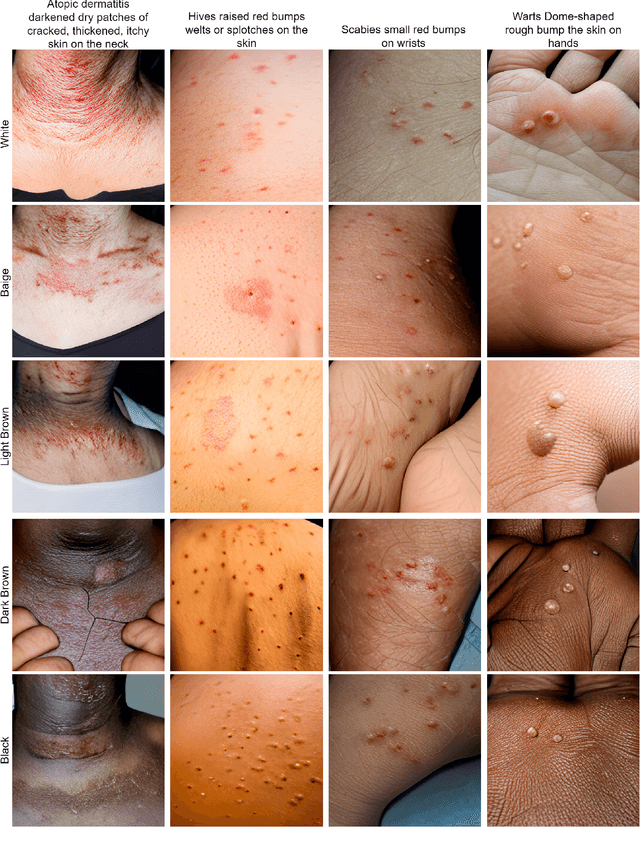
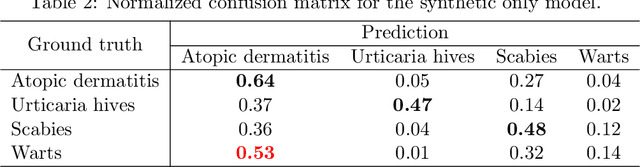
This paper investigates the potential usage of large text-to-image (LTI) models for the automated diagnosis of a few skin conditions with rarity or a serious lack of annotated datasets. As the input to the LTI model, we provide the targeted instantiation of a generic but succinct prompt structure designed upon careful observations of the conditional narratives from the standard medical textbooks. In this regard, we pave the path to utilizing accessible textbook descriptions for automated diagnosis of conditions with data scarcity through the lens of LTI models. Experiments show the efficacy of the proposed framework, including much better localization of the infected regions. Moreover, it has the immense possibility for generalization across the medical sub-domains, not only to mitigate the data scarcity issue but also to debias automated diagnostics from the all-pervasive racial biases.
Evaluating the Effectiveness of 2D and 3D Features for Predicting Tumor Response to Chemotherapy
Apr 14, 2023
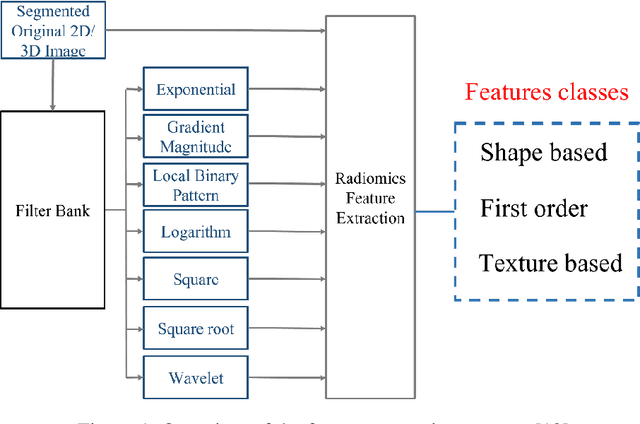

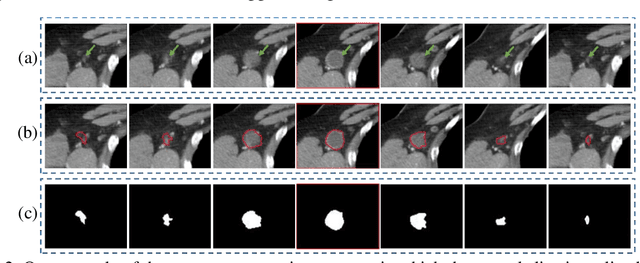
2D and 3D tumor features are widely used in a variety of medical image analysis tasks. However, for chemotherapy response prediction, the effectiveness between different kinds of 2D and 3D features are not comprehensively assessed, especially in ovarian cancer-related applications. This investigation aims to accomplish such a comprehensive evaluation. For this purpose, CT images were collected retrospectively from 188 advanced-stage ovarian cancer patients. All the metastatic tumors that occurred in each patient were segmented and then processed by a set of six filters. Next, three categories of features, namely geometric, density, and texture features, were calculated from both the filtered results and the original segmented tumors, generating a total of 1595 and 1403 features for the 3D and 2D tumors, respectively. In addition to the conventional single-slice 2D and full-volume 3D tumor features, we also computed the incomplete-3D tumor features, which were achieved by sequentially adding one individual CT slice and calculating the corresponding features. Support vector machine (SVM) based prediction models were developed and optimized for each feature set. 5-fold cross-validation was used to assess the performance of each individual model. The results show that the 2D feature-based model achieved an AUC (area under the ROC curve [receiver operating characteristic]) of 0.84+-0.02. When adding more slices, the AUC first increased to reach the maximum and then gradually decreased to 0.86+-0.02. The maximum AUC was yielded when adding two adjacent slices, with a value of 0.91+-0.01. This initial result provides meaningful information for optimizing machine learning-based decision-making support tools in the future.
SpectFormer: Frequency and Attention is what you need in a Vision Transformer
Apr 14, 2023

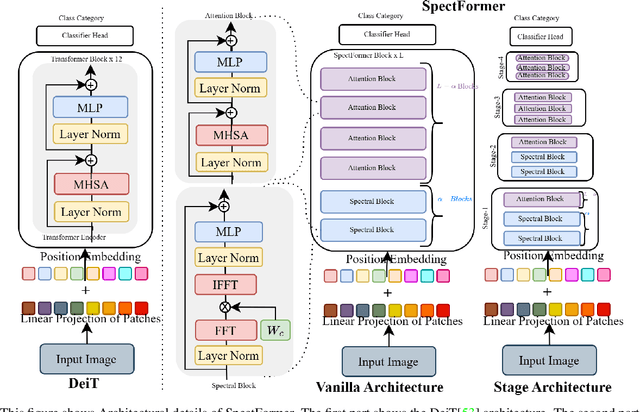
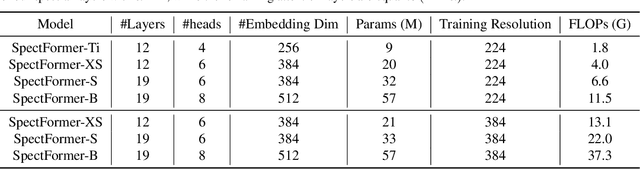
Vision transformers have been applied successfully for image recognition tasks. There have been either multi-headed self-attention based (ViT \cite{dosovitskiy2020image}, DeIT, \cite{touvron2021training}) similar to the original work in textual models or more recently based on spectral layers (Fnet\cite{lee2021fnet}, GFNet\cite{rao2021global}, AFNO\cite{guibas2021efficient}). We hypothesize that both spectral and multi-headed attention plays a major role. We investigate this hypothesis through this work and observe that indeed combining spectral and multi-headed attention layers provides a better transformer architecture. We thus propose the novel Spectformer architecture for transformers that combines spectral and multi-headed attention layers. We believe that the resulting representation allows the transformer to capture the feature representation appropriately and it yields improved performance over other transformer representations. For instance, it improves the top-1 accuracy by 2\% on ImageNet compared to both GFNet-H and LiT. SpectFormer-S reaches 84.25\% top-1 accuracy on ImageNet-1K (state of the art for small version). Further, Spectformer-L achieves 85.7\% that is the state of the art for the comparable base version of the transformers. We further ensure that we obtain reasonable results in other scenarios such as transfer learning on standard datasets such as CIFAR-10, CIFAR-100, Oxford-IIIT-flower, and Standford Car datasets. We then investigate its use in downstream tasks such of object detection and instance segmentation on the MS-COCO dataset and observe that Spectformer shows consistent performance that is comparable to the best backbones and can be further optimized and improved. Hence, we believe that combined spectral and attention layers are what are needed for vision transformers.
Single-Image HDR Reconstruction by Multi-Exposure Generation
Oct 28, 2022High dynamic range (HDR) imaging is an indispensable technique in modern photography. Traditional methods focus on HDR reconstruction from multiple images, solving the core problems of image alignment, fusion, and tone mapping, yet having a perfect solution due to ghosting and other visual artifacts in the reconstruction. Recent attempts at single-image HDR reconstruction show a promising alternative: by learning to map pixel values to their irradiance using a neural network, one can bypass the align-and-merge pipeline completely yet still obtain a high-quality HDR image. In this work, we propose a weakly supervised learning method that inverts the physical image formation process for HDR reconstruction via learning to generate multiple exposures from a single image. Our neural network can invert the camera response to reconstruct pixel irradiance before synthesizing multiple exposures and hallucinating details in under- and over-exposed regions from a single input image. To train the network, we propose a representation loss, a reconstruction loss, and a perceptual loss applied on pairs of under- and over-exposure images and thus do not require HDR images for training. Our experiments show that our proposed model can effectively reconstruct HDR images. Our qualitative and quantitative results show that our method achieves state-of-the-art performance on the DrTMO dataset. Our code is available at https://github.com/VinAIResearch/single_image_hdr.
Amortized Normalizing Flows for Transcranial Ultrasound with Uncertainty Quantification
Mar 06, 2023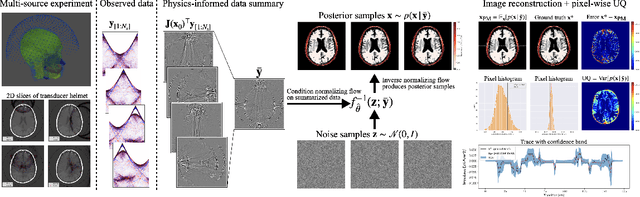

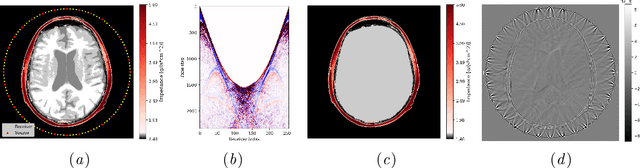
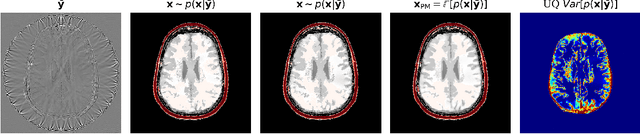
We present a novel approach to transcranial ultrasound computed tomography that utilizes normalizing flows to improve the speed of imaging and provide Bayesian uncertainty quantification. Our method combines physics-informed methods and data-driven methods to accelerate the reconstruction of the final image. We make use of a physics-informed summary statistic to incorporate the known ultrasound physics with the goal of compressing large incoming observations. This compression enables efficient training of the normalizing flow and standardizes the size of the data regardless of imaging configurations. The combinations of these methods results in fast uncertainty-aware image reconstruction that generalizes to a variety of transducer configurations. We evaluate our approach with in silico experiments and demonstrate that it can significantly improve the imaging speed while quantifying uncertainty. We validate the quality of our image reconstructions by comparing against the traditional physics-only method and also verify that our provided uncertainty is calibrated with the error.
Zero-shot Image Captioning by Anchor-augmented Vision-Language Space Alignment
Nov 14, 2022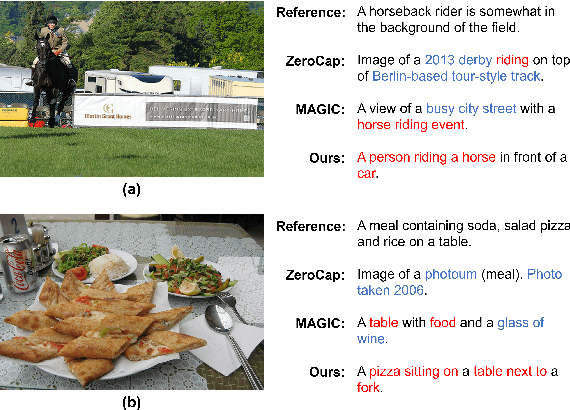
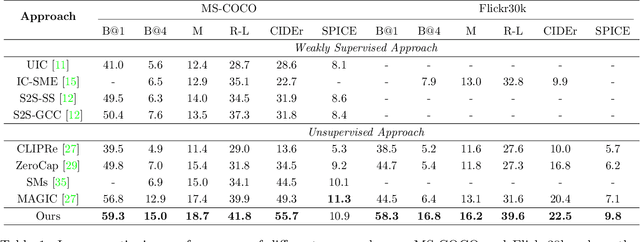
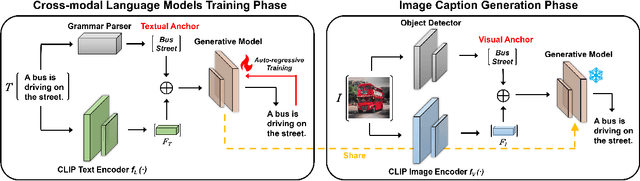

CLIP (Contrastive Language-Image Pre-Training) has shown remarkable zero-shot transfer capabilities in cross-modal correlation tasks such as visual classification and image retrieval. However, its performance in cross-modal generation tasks like zero-shot image captioning remains unsatisfied. In this work, we discuss that directly employing CLIP for zero-shot image captioning relies more on the textual modality in context and largely ignores the visual information, which we call \emph{contextual language prior}. To address this, we propose Cross-modal Language Models (CLMs) to facilitate unsupervised cross-modal learning. We further propose Anchor Augment to guide the generative model's attention to the fine-grained information in the representation of CLIP. Experiments on MS COCO and Flickr 30K validate the promising performance of proposed approach in both captioning quality and computational efficiency.
NeRFInvertor: High Fidelity NeRF-GAN Inversion for Single-shot Real Image Animation
Nov 30, 2022
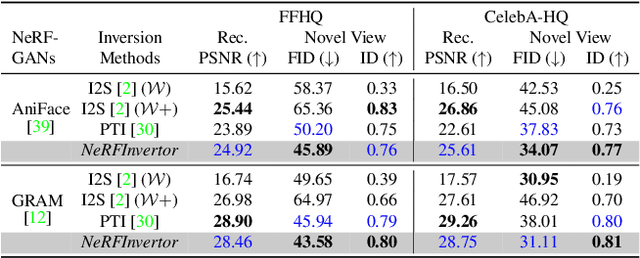

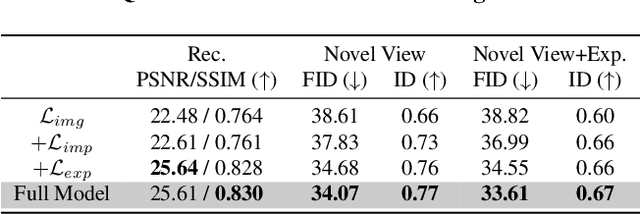
Nerf-based Generative models have shown impressive capacity in generating high-quality images with consistent 3D geometry. Despite successful synthesis of fake identity images randomly sampled from latent space, adopting these models for generating face images of real subjects is still a challenging task due to its so-called inversion issue. In this paper, we propose a universal method to surgically fine-tune these NeRF-GAN models in order to achieve high-fidelity animation of real subjects only by a single image. Given the optimized latent code for an out-of-domain real image, we employ 2D loss functions on the rendered image to reduce the identity gap. Furthermore, our method leverages explicit and implicit 3D regularizations using the in-domain neighborhood samples around the optimized latent code to remove geometrical and visual artifacts. Our experiments confirm the effectiveness of our method in realistic, high-fidelity, and 3D consistent animation of real faces on multiple NeRF-GAN models across different datasets.