 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Few-view High-resolution Photon-counting Extremity CT at Halved Dose for a Clinical Trial
Mar 19, 2024
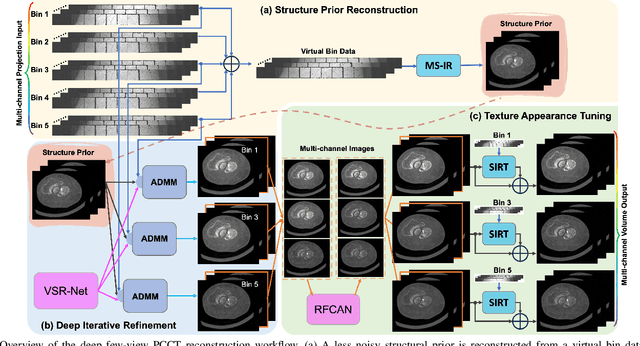
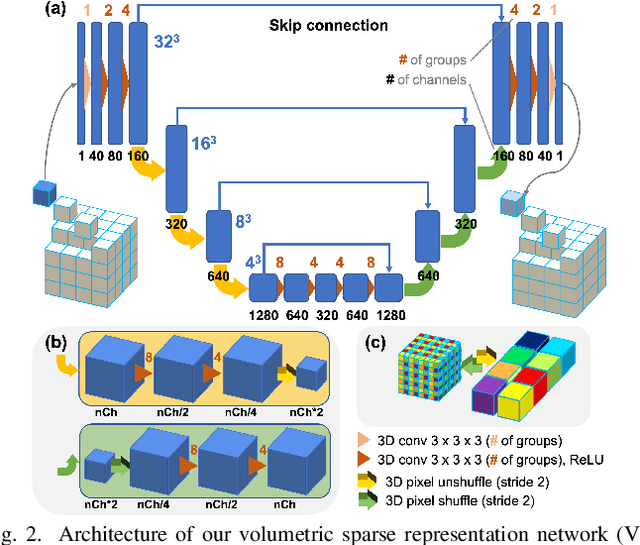
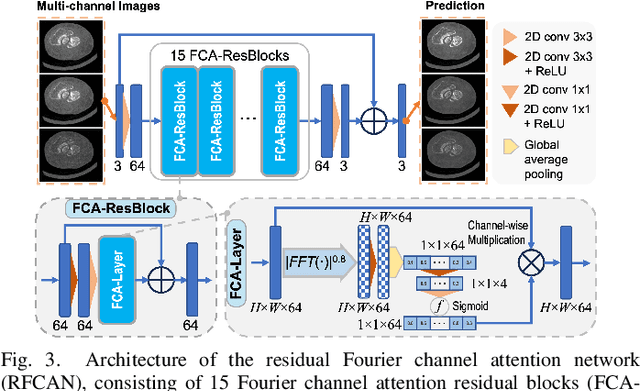
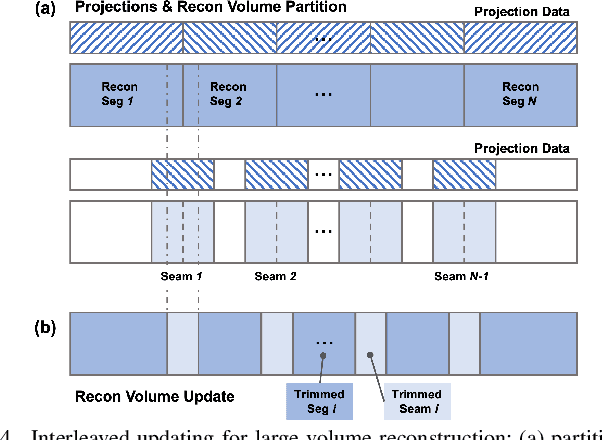
The latest X-ray photon-counting computed tomography (PCCT) for extremity allows multi-energy high-resolution (HR) imaging for tissue characterization and material decomposition. However, both radiation dose and imaging speed need improvement for contrast-enhanced and other studies. Despite the success of deep learning methods for 2D few-view reconstruction, applying them to HR volumetric reconstruction of extremity scans for clinical diagnosis has been limited due to GPU memory constraints, training data scarcity, and domain gap issues. In this paper, we propose a deep learning-based approach for PCCT image reconstruction at halved dose and doubled speed in a New Zealand clinical trial. Particularly, we present a patch-based volumetric refinement network to alleviate the GPU memory limitation, train network with synthetic data, and use model-based iterative refinement to bridge the gap between synthetic and real-world data. The simulation and phantom experiments demonstrate consistently improved results under different acquisition conditions on both in- and off-domain structures using a fixed network. The image quality of 8 patients from the clinical trial are evaluated by three radiologists in comparison with the standard image reconstruction with a full-view dataset. It is shown that our proposed approach is essentially identical to or better than the clinical benchmark in terms of diagnostic image quality scores. Our approach has a great potential to improve the safety and efficiency of PCCT without compromising image quality.
Doubly Abductive Counterfactual Inference for Text-based Image Editing
Mar 05, 2024

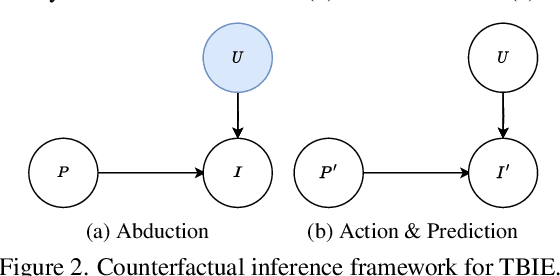

We study text-based image editing (TBIE) of a single image by counterfactual inference because it is an elegant formulation to precisely address the requirement: the edited image should retain the fidelity of the original one. Through the lens of the formulation, we find that the crux of TBIE is that existing techniques hardly achieve a good trade-off between editability and fidelity, mainly due to the overfitting of the single-image fine-tuning. To this end, we propose a Doubly Abductive Counterfactual inference framework (DAC). We first parameterize an exogenous variable as a UNet LoRA, whose abduction can encode all the image details. Second, we abduct another exogenous variable parameterized by a text encoder LoRA, which recovers the lost editability caused by the overfitted first abduction. Thanks to the second abduction, which exclusively encodes the visual transition from post-edit to pre-edit, its inversion -- subtracting the LoRA -- effectively reverts pre-edit back to post-edit, thereby accomplishing the edit. Through extensive experiments, our DAC achieves a good trade-off between editability and fidelity. Thus, we can support a wide spectrum of user editing intents, including addition, removal, manipulation, replacement, style transfer, and facial change, which are extensively validated in both qualitative and quantitative evaluations. Codes are in https://github.com/xuesong39/DAC.
HDRTransDC: High Dynamic Range Image Reconstruction with Transformer Deformation Convolution
Mar 11, 2024
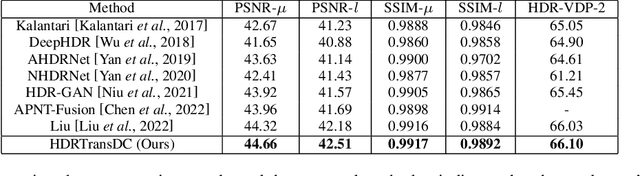
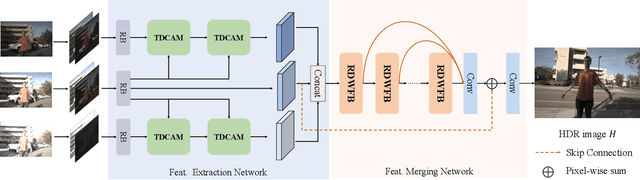
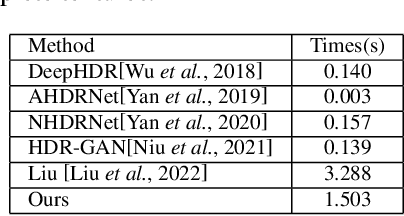
High Dynamic Range (HDR) imaging aims to generate an artifact-free HDR image with realistic details by fusing multi-exposure Low Dynamic Range (LDR) images. Caused by large motion and severe under-/over-exposure among input LDR images, HDR imaging suffers from ghosting artifacts and fusion distortions. To address these critical issues, we propose an HDR Transformer Deformation Convolution (HDRTransDC) network to generate high-quality HDR images, which consists of the Transformer Deformable Convolution Alignment Module (TDCAM) and the Dynamic Weight Fusion Block (DWFB). To solve the ghosting artifacts, the proposed TDCAM extracts long-distance content similar to the reference feature in the entire non-reference features, which can accurately remove misalignment and fill the content occluded by moving objects. For the purpose of eliminating fusion distortions, we propose DWFB to spatially adaptively select useful information across frames to effectively fuse multi-exposed features. Extensive experiments show that our method quantitatively and qualitatively achieves state-of-the-art performance.
ProMISe: Promptable Medical Image Segmentation using SAM
Mar 07, 2024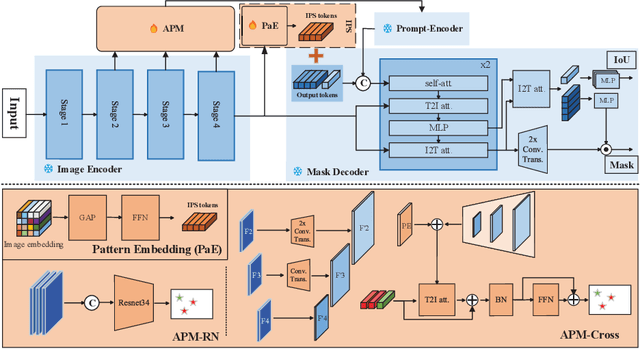
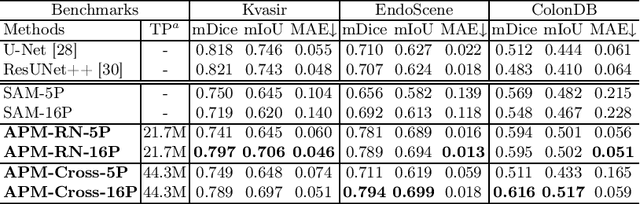

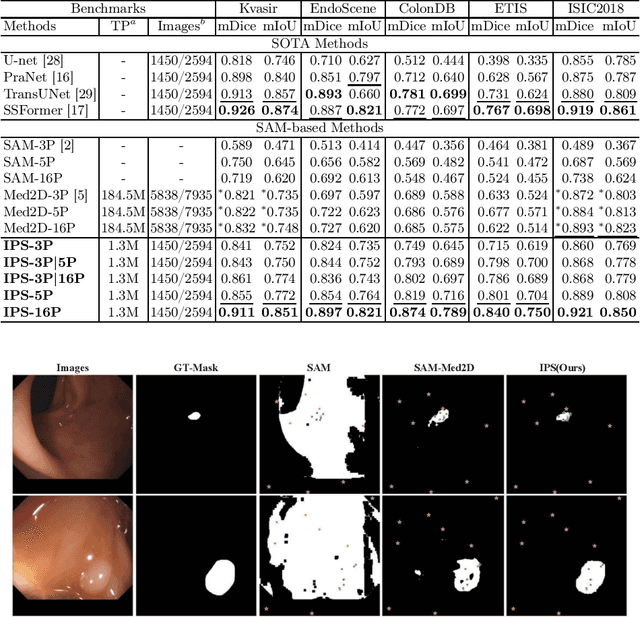
With the proposal of the Segment Anything Model (SAM), fine-tuning SAM for medical image segmentation (MIS) has become popular. However, due to the large size of the SAM model and the significant domain gap between natural and medical images, fine-tuning-based strategies are costly with potential risk of instability, feature damage and catastrophic forgetting. Furthermore, some methods of transferring SAM to a domain-specific MIS through fine-tuning strategies disable the model's prompting capability, severely limiting its utilization scenarios. In this paper, we propose an Auto-Prompting Module (APM), which provides SAM-based foundation model with Euclidean adaptive prompts in the target domain. Our experiments demonstrate that such adaptive prompts significantly improve SAM's non-fine-tuned performance in MIS. In addition, we propose a novel non-invasive method called Incremental Pattern Shifting (IPS) to adapt SAM to specific medical domains. Experimental results show that the IPS enables SAM to achieve state-of-the-art or competitive performance in MIS without the need for fine-tuning. By coupling these two methods, we propose ProMISe, an end-to-end non-fine-tuned framework for Promptable Medical Image Segmentation. Our experiments demonstrate that both using our methods individually or in combination achieves satisfactory performance in low-cost pattern shifting, with all of SAM's parameters frozen.
Tuning-Free Noise Rectification for High Fidelity Image-to-Video Generation
Mar 05, 2024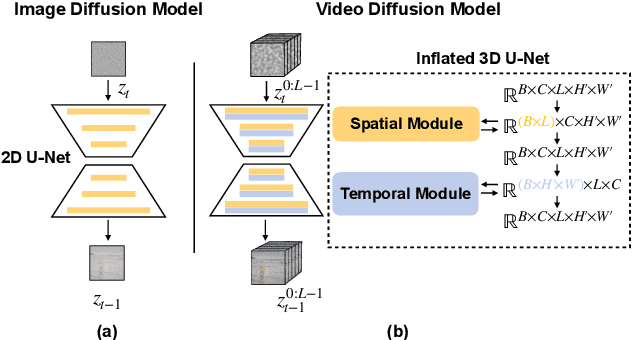
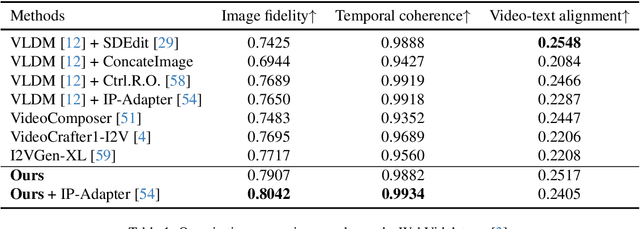
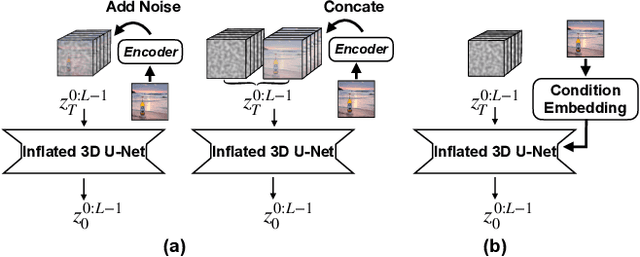
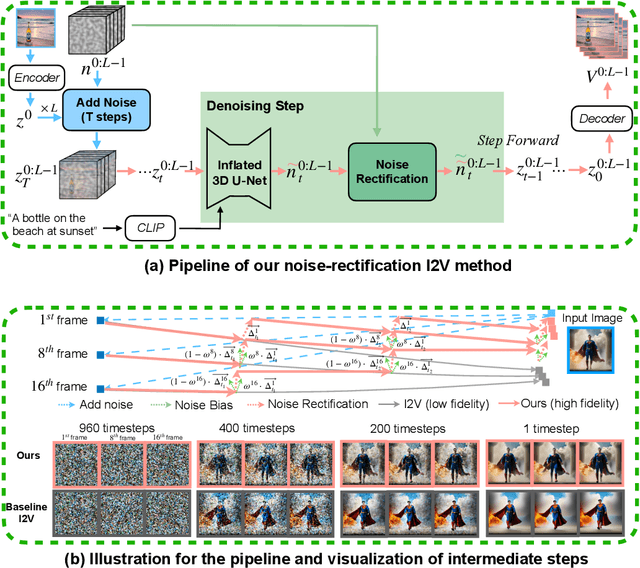
Image-to-video (I2V) generation tasks always suffer from keeping high fidelity in the open domains. Traditional image animation techniques primarily focus on specific domains such as faces or human poses, making them difficult to generalize to open domains. Several recent I2V frameworks based on diffusion models can generate dynamic content for open domain images but fail to maintain fidelity. We found that two main factors of low fidelity are the loss of image details and the noise prediction biases during the denoising process. To this end, we propose an effective method that can be applied to mainstream video diffusion models. This method achieves high fidelity based on supplementing more precise image information and noise rectification. Specifically, given a specified image, our method first adds noise to the input image latent to keep more details, then denoises the noisy latent with proper rectification to alleviate the noise prediction biases. Our method is tuning-free and plug-and-play. The experimental results demonstrate the effectiveness of our approach in improving the fidelity of generated videos. For more image-to-video generated results, please refer to the project website: https://noise-rectification.github.io.
Hyperpixels: Pixel Filter Arrays of Multivariate Optical Elements for Optimized Spectral Imaging
Mar 25, 2024We introduce the concept of `hyperpixels' in which each element of a pixel filter array (suitable for CMOS image sensor integration) has a spectral transmission tailored to a target spectral component expected in application-specific scenes. These are analogous to arrays of multivariate optical elements that could be used for sensing specific analytes. Spectral tailoring is achieved by engineering the heights of multiple sub-pixel Fabry-Perot resonators that cover each pixel area. We first present a design approach for hyperpixels, based on a matched filter concept and, as an exemplar, design a set of 4 hyperpixels tailored to optimally discriminate between 4 spectral reflectance targets. Next, we fabricate repeating 2x2 pixel filter arrays of these designs, alongside repeating 2x2 arrays of an optimal bandpass filters, perform both spectral and imaging characterization. Experimentally measured hyperpixel transmission spectra show a 2.4x reduction in unmixing matrix condition number (p=0.031) compared to the optimal band-pass set. Imaging experiments using the filter arrays with a monochrome sensor achieve a 3.47x reduction in unmixing matrix condition number (p=0.020) compared to the optimal band-pass set. This demonstrates the utility of the hyperpixel approach and shows its superiority even over the optimal bandpass case. We expect that with further improvements in design and fabrication processes increased performance may be obtained. Because the hyperpixels are straightforward to customize, fabricate and can be placed atop monochrome sensors, this approach is highly versatile and could be adapted to a wide range of real-time imaging applications which are limited by low SNR including micro-endoscopy, capsule endoscopy, industrial inspection and machine vision.
Fully automated workflow for the design of patient-specific orthopaedic implants: application to total knee arthroplasty
Mar 25, 2024Arthroplasty is commonly performed to treat joint osteoarthritis, reducing pain and improving mobility. While arthroplasty has known several technical improvements, a significant share of patients are still unsatisfied with their surgery. Personalised arthroplasty improves surgical outcomes however current solutions require delays, making it difficult to integrate in clinical routine. We propose a fully automated workflow to design patient-specific implants, presented for total knee arthroplasty, the most widely performed arthroplasty in the world nowadays. The proposed pipeline first uses artificial neural networks to segment the proximal and distal extremities of the femur and tibia. Then the full bones are reconstructed using augmented statistical shape models, combining shape and landmarks information. Finally, 77 morphological parameters are computed to design patient-specific implants. The developed workflow has been trained using 91 CT scans of lower limb and evaluated on 41 CT scans manually segmented, in terms of accuracy and execution time. The workflow accuracy was $0.4\pm0.2mm$ for the segmentation, $1.2\pm0.4mm$ for the full bones reconstruction, and $2.8\pm2.2mm$ for the anatomical landmarks determination. The custom implants fitted the patients' anatomy with $0.6\pm0.2mm$ accuracy. The whole process from segmentation to implants' design lasted about 5 minutes. The proposed workflow allows for a fast and reliable personalisation of knee implants, directly from the patient CT image without requiring any manual intervention. It establishes a patient-specific pre-operative planning for TKA in a very short time making it easily available for all patients. Combined with efficient implant manufacturing techniques, this solution could help answer the growing number of arthroplasties while reducing complications and improving the patients' satisfaction.
QUASAR: QUality and Aesthetics Scoring with Advanced Representations
Mar 20, 2024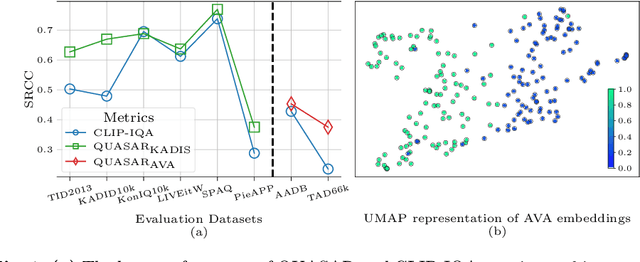
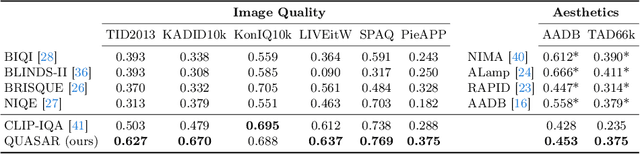
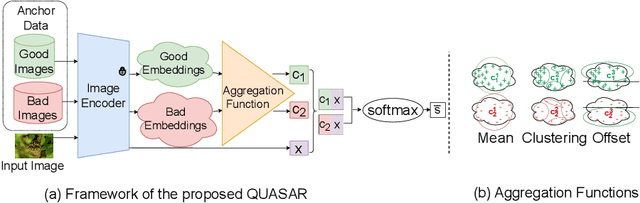

This paper introduces a new data-driven, non-parametric method for image quality and aesthetics assessment, surpassing existing approaches and requiring no prompt engineering or fine-tuning. We eliminate the need for expressive textual embeddings by proposing efficient image anchors in the data. Through extensive evaluations of 7 state-of-the-art self-supervised models, our method demonstrates superior performance and robustness across various datasets and benchmarks. Notably, it achieves high agreement with human assessments even with limited data and shows high robustness to the nature of data and their pre-processing pipeline. Our contributions offer a streamlined solution for assessment of images while providing insights into the perception of visual information.
Explorative Inbetweening of Time and Space
Mar 21, 2024



We introduce bounded generation as a generalized task to control video generation to synthesize arbitrary camera and subject motion based only on a given start and end frame. Our objective is to fully leverage the inherent generalization capability of an image-to-video model without additional training or fine-tuning of the original model. This is achieved through the proposed new sampling strategy, which we call Time Reversal Fusion, that fuses the temporally forward and backward denoising paths conditioned on the start and end frame, respectively. The fused path results in a video that smoothly connects the two frames, generating inbetweening of faithful subject motion, novel views of static scenes, and seamless video looping when the two bounding frames are identical. We curate a diverse evaluation dataset of image pairs and compare against the closest existing methods. We find that Time Reversal Fusion outperforms related work on all subtasks, exhibiting the ability to generate complex motions and 3D-consistent views guided by bounded frames. See project page at https://time-reversal.github.io.
An Active Contour Model Driven By the Hybrid Signed Pressure Function
Mar 21, 2024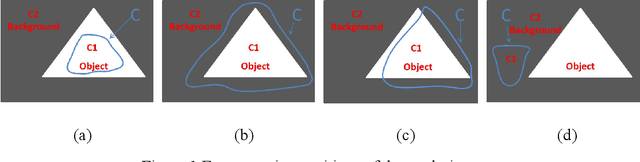
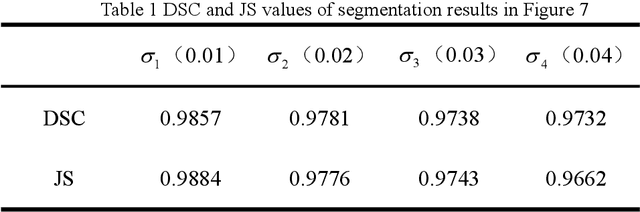
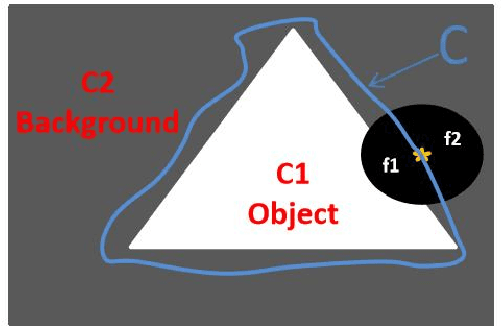
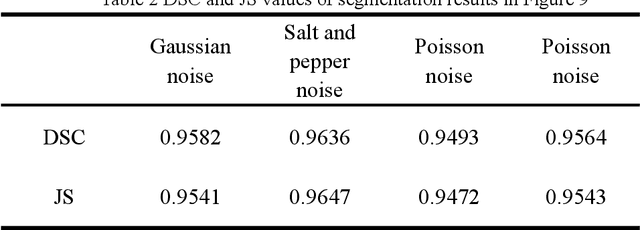
Due to the influence of imaging equipment and complex imaging environments, most images in daily life have features of intensity inhomogeneity and noise. Therefore, many scholars have designed many image segmentation algorithms to address these issues. Among them, the active contour model is one of the most effective image segmentation algorithms.This paper proposes an active contour model driven by the hybrid signed pressure function that combines global and local information construction. Firstly, a new global region-based signed pressure function is introduced by combining the average intensity of the inner and outer regions of the curve with the median intensity of the inner region of the evolution curve. Then, the paper uses the energy differences between the inner and outer regions of the curve in the local region to design the signed pressure function of the local term. Combine the two SPF function to obtain a new signed pressure function and get the evolution equation of the new model. Finally, experiments and numerical analysis show that the model has excellent segmentation performance for both intensity inhomogeneous images and noisy images.