 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DeepVecFont-v2: Exploiting Transformers to Synthesize Vector Fonts with Higher Quality
Mar 25, 2023
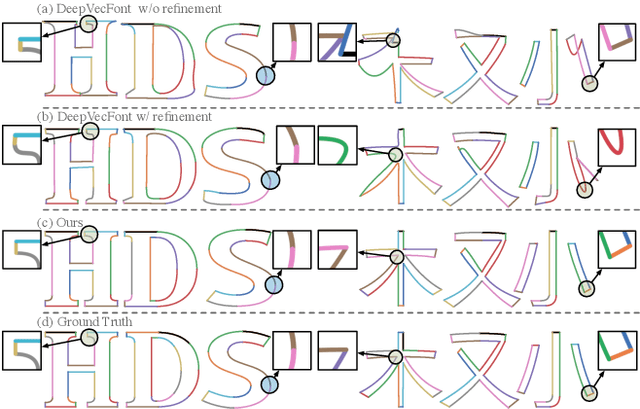

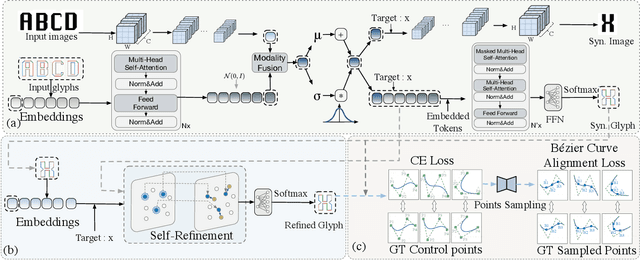
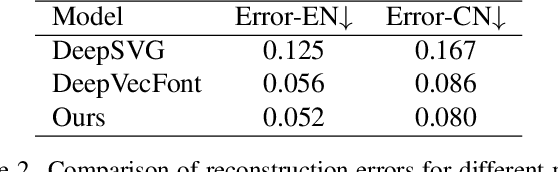
Vector font synthesis is a challenging and ongoing problem in the fields of Computer Vision and Computer Graphics. The recently-proposed DeepVecFont achieved state-of-the-art performance by exploiting information of both the image and sequence modalities of vector fonts. However, it has limited capability for handling long sequence data and heavily relies on an image-guided outline refinement post-processing. Thus, vector glyphs synthesized by DeepVecFont still often contain some distortions and artifacts and cannot rival human-designed results. To address the above problems, this paper proposes an enhanced version of DeepVecFont mainly by making the following three novel technical contributions. First, we adopt Transformers instead of RNNs to process sequential data and design a relaxation representation for vector outlines, markedly improving the model's capability and stability of synthesizing long and complex outlines. Second, we propose to sample auxiliary points in addition to control points to precisely align the generated and target B\'ezier curves or lines. Finally, to alleviate error accumulation in the sequential generation process, we develop a context-based self-refinement module based on another Transformer-based decoder to remove artifacts in the initially synthesized glyphs. Both qualitative and quantitative results demonstrate that the proposed method effectively resolves those intrinsic problems of the original DeepVecFont and outperforms existing approaches in generating English and Chinese vector fonts with complicated structures and diverse styles.
Renderable Neural Radiance Map for Visual Navigation
Mar 01, 2023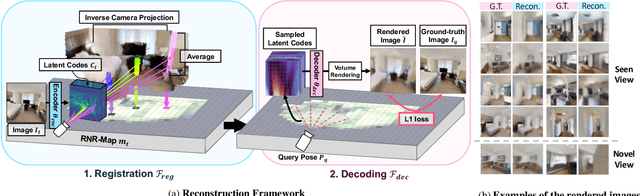
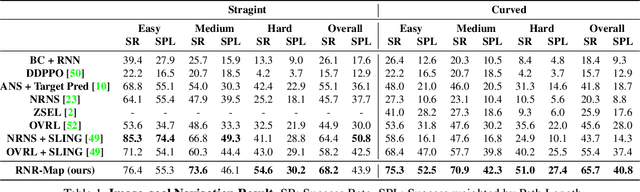
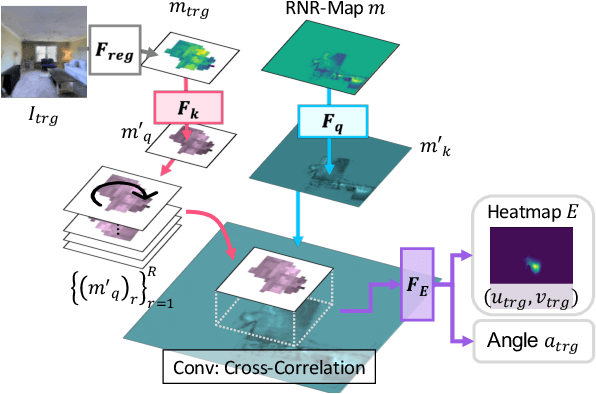
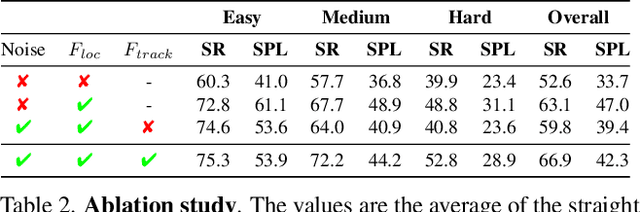
We propose a novel type of map for visual navigation, a renderable neural radiance map (RNR-Map), which is designed to contain the overall visual information of a 3D environment. The RNR-Map has a grid form and consists of latent codes at each pixel. These latent codes are embedded from image observations, and can be converted to the neural radiance field which enables image rendering given a camera pose. The recorded latent codes implicitly contain visual information about the environment, which makes the RNR-Map visually descriptive. This visual information in RNR-Map can be a useful guideline for visual localization and navigation. We develop localization and navigation frameworks that can effectively utilize the RNR-Map. We evaluate the proposed frameworks on camera tracking, visual localization, and image-goal navigation. Experimental results show that the RNR-Map-based localization framework can find the target location based on a single query image with fast speed and competitive accuracy compared to other baselines. Also, this localization framework is robust to environmental changes, and even finds the most visually similar places when a query image from a different environment is given. The proposed navigation framework outperforms the existing image-goal navigation methods in difficult scenarios, under odometry and actuation noises. The navigation framework shows 65.7% success rate in curved scenarios of the NRNS dataset, which is an improvement of 18.6% over the current state-of-the-art.
Viewpoint Equivariance for Multi-View 3D Object Detection
Apr 07, 2023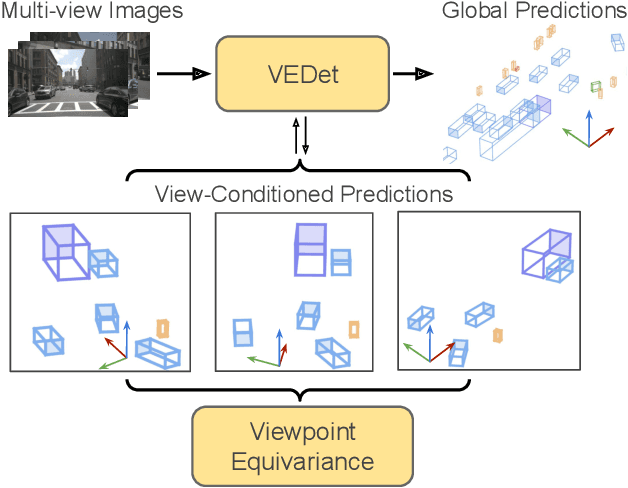
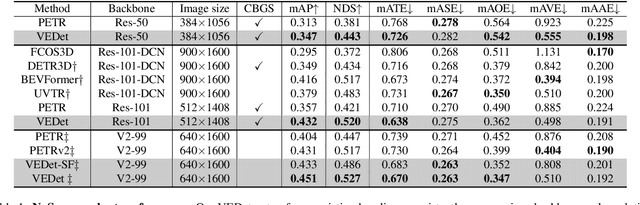
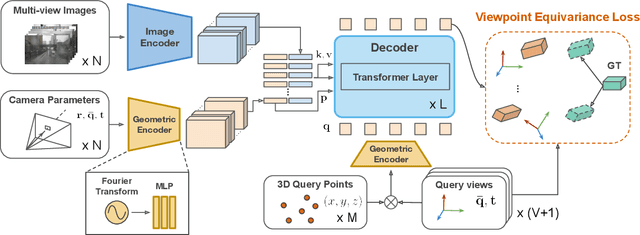
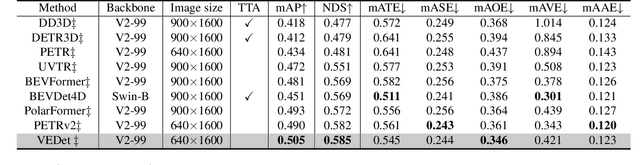
3D object detection from visual sensors is a cornerstone capability of robotic systems. State-of-the-art methods focus on reasoning and decoding object bounding boxes from multi-view camera input. In this work we gain intuition from the integral role of multi-view consistency in 3D scene understanding and geometric learning. To this end, we introduce VEDet, a novel 3D object detection framework that exploits 3D multi-view geometry to improve localization through viewpoint awareness and equivariance. VEDet leverages a query-based transformer architecture and encodes the 3D scene by augmenting image features with positional encodings from their 3D perspective geometry. We design view-conditioned queries at the output level, which enables the generation of multiple virtual frames during training to learn viewpoint equivariance by enforcing multi-view consistency. The multi-view geometry injected at the input level as positional encodings and regularized at the loss level provides rich geometric cues for 3D object detection, leading to state-of-the-art performance on the nuScenes benchmark. The code and model are made available at https://github.com/TRI-ML/VEDet.
Devil's on the Edges: Selective Quad Attention for Scene Graph Generation
Apr 07, 2023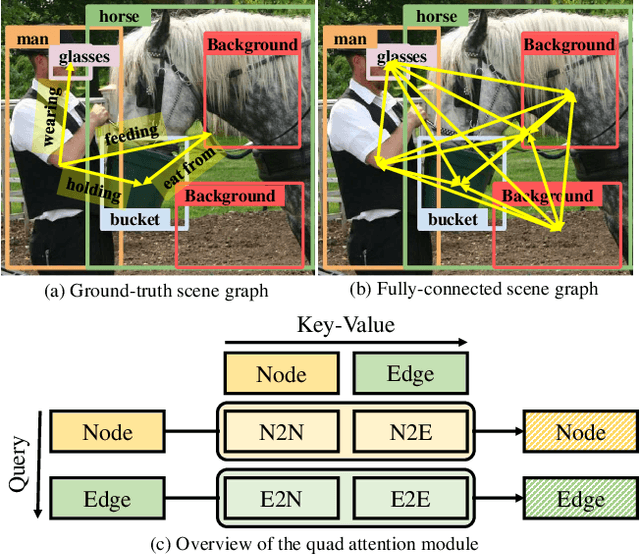
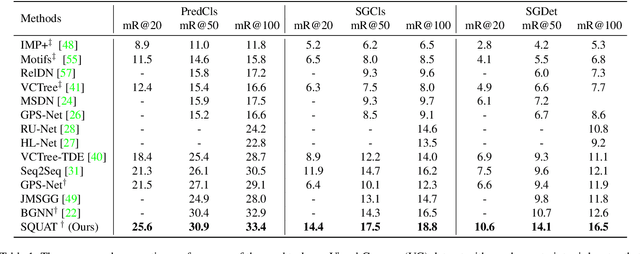
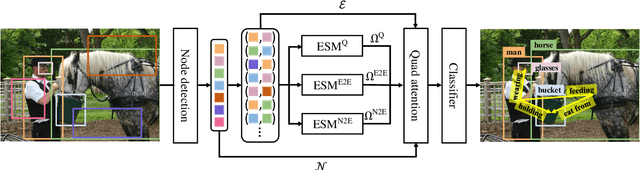
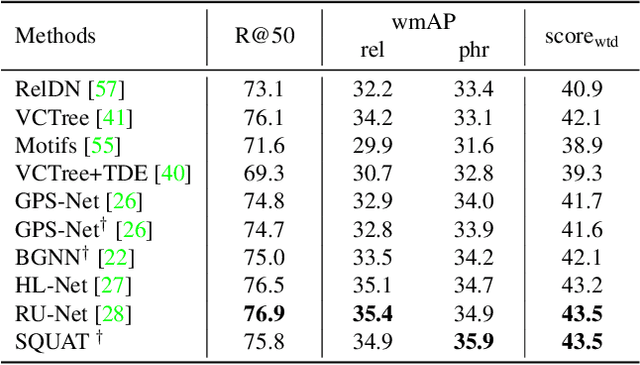
Scene graph generation aims to construct a semantic graph structure from an image such that its nodes and edges respectively represent objects and their relationships. One of the major challenges for the task lies in the presence of distracting objects and relationships in images; contextual reasoning is strongly distracted by irrelevant objects or backgrounds and, more importantly, a vast number of irrelevant candidate relations. To tackle the issue, we propose the Selective Quad Attention Network (SQUAT) that learns to select relevant object pairs and disambiguate them via diverse contextual interactions. SQUAT consists of two main components: edge selection and quad attention. The edge selection module selects relevant object pairs, i.e., edges in the scene graph, which helps contextual reasoning, and the quad attention module then updates the edge features using both edge-to-node and edge-to-edge cross-attentions to capture contextual information between objects and object pairs. Experiments demonstrate the strong performance and robustness of SQUAT, achieving the state of the art on the Visual Genome and Open Images v6 benchmarks.
EVA-02: A Visual Representation for Neon Genesis
Mar 20, 2023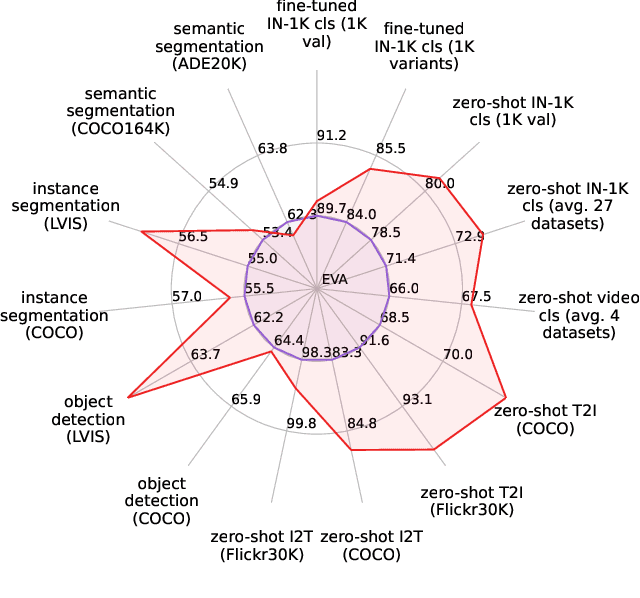

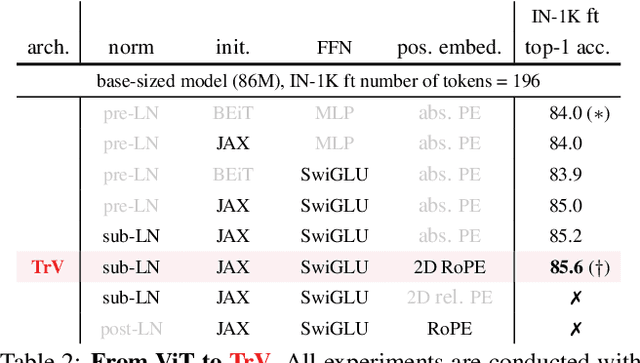
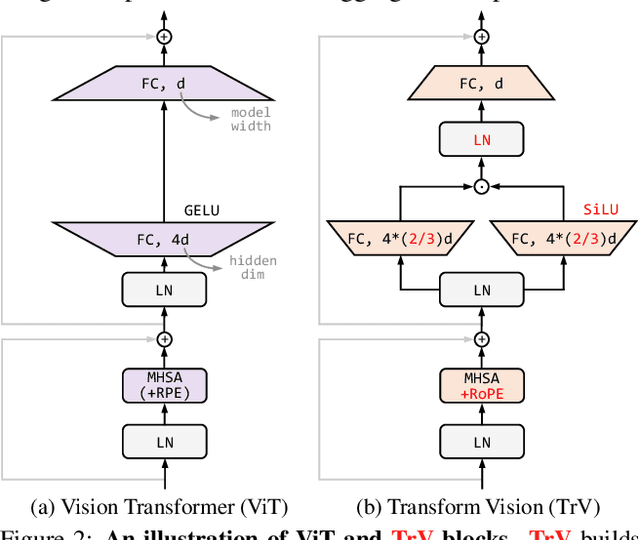
We launch EVA-02, a next-generation Transformer-based visual representation pre-trained to reconstruct strong and robust language-aligned vision features via masked image modeling. With an updated plain Transformer architecture as well as extensive pre-training from an open & accessible giant CLIP vision encoder, EVA-02 demonstrates superior performance compared to prior state-of-the-art approaches across various representative vision tasks, while utilizing significantly fewer parameters and compute budgets. Notably, using exclusively publicly accessible training data, EVA-02 with only 304M parameters achieves a phenomenal 90.0 fine-tuning top-1 accuracy on ImageNet-1K val set. Additionally, our EVA-02-CLIP can reach up to 80.4 zero-shot top-1 on ImageNet-1K, outperforming the previous largest & best open-sourced CLIP with only ~1/6 parameters and ~1/6 image-text training data. We offer four EVA-02 variants in various model sizes, ranging from 6M to 304M parameters, all with impressive performance. To facilitate open access and open research, we release the complete suite of EVA-02 to the community at https://github.com/baaivision/EVA/tree/master/EVA-02.
Joint Multi-Echo/Respiratory Motion-Resolved Compressed Sensing Reconstruction of Free-Breathing Non-Cartesian Abdominal MRI
Apr 03, 2023
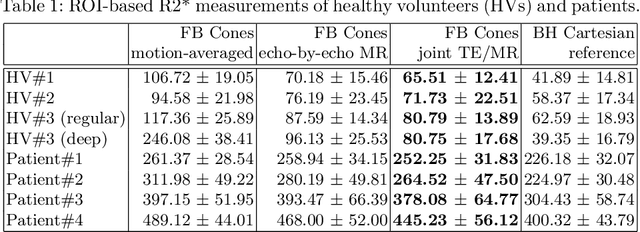
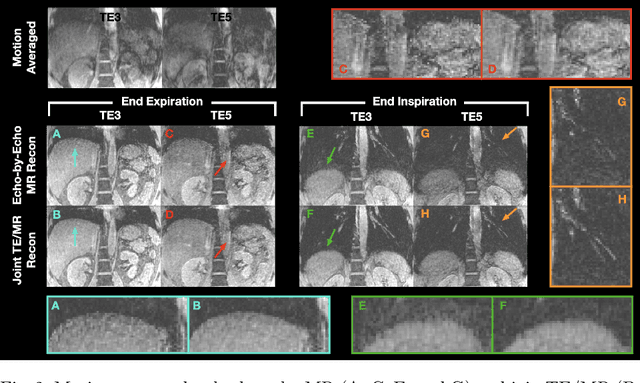
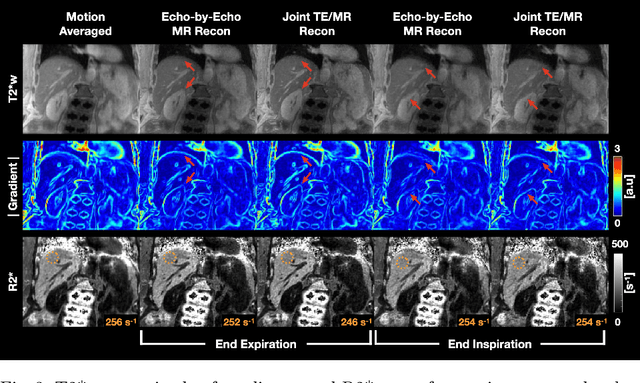
We propose a novel respiratory motion-resolved MR image reconstruction method that jointly treats multi-echo k-space raw data. Continuously acquired non-Cartesian multi-echo/multi-coil k-space data with free breathing are sorted/binned into the motion states from end-expiratory to end-inspiratory phases based on a respiratory motion signal. Temporal total variation applied to the motion state dimension of each echo is then coupled in the $\ell_2$ sense for joint reconstruction of the multiple echoes. Reconstructed source images of the proposed method are compared with conventional echo-by-echo motion-resolved reconstruction, and R2* of the proposed and echo-by-echo methods are compared with respect to a clinical reference. We demonstrate that inconsistency between echoes is successfully suppressed in the proposed joint reconstruction method, producing high-quality source images and R2* measurements compared to clinical reference.
Efficient View Synthesis and 3D-based Multi-Frame Denoising with Multiplane Feature Representations
Apr 05, 2023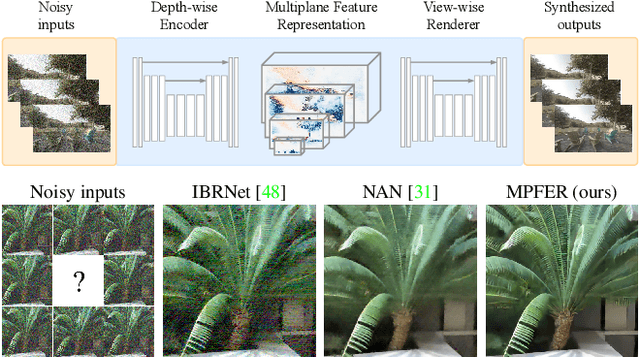
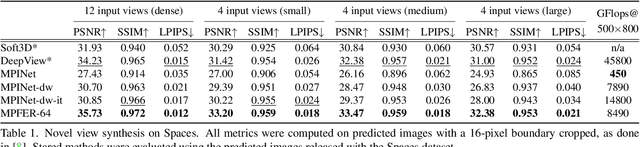
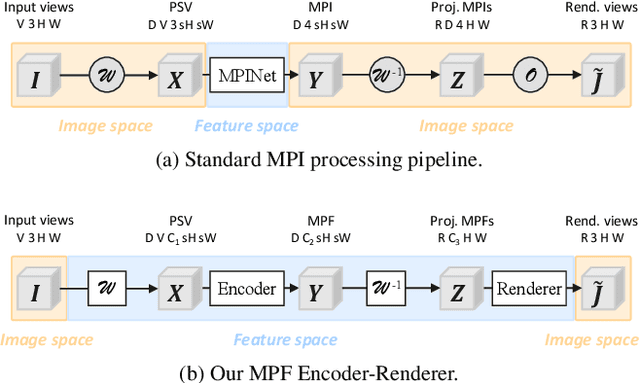
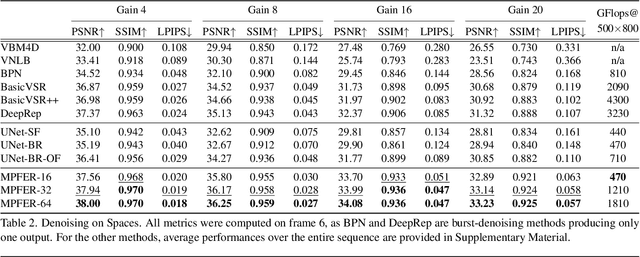
While current multi-frame restoration methods combine information from multiple input images using 2D alignment techniques, recent advances in novel view synthesis are paving the way for a new paradigm relying on volumetric scene representations. In this work, we introduce the first 3D-based multi-frame denoising method that significantly outperforms its 2D-based counterparts with lower computational requirements. Our method extends the multiplane image (MPI) framework for novel view synthesis by introducing a learnable encoder-renderer pair manipulating multiplane representations in feature space. The encoder fuses information across views and operates in a depth-wise manner while the renderer fuses information across depths and operates in a view-wise manner. The two modules are trained end-to-end and learn to separate depths in an unsupervised way, giving rise to Multiplane Feature (MPF) representations. Experiments on the Spaces and Real Forward-Facing datasets as well as on raw burst data validate our approach for view synthesis, multi-frame denoising, and view synthesis under noisy conditions.
Exploring the Utility of Self-Supervised Pretraining Strategies for the Detection of Absent Lung Sliding in M-Mode Lung Ultrasound
Apr 05, 2023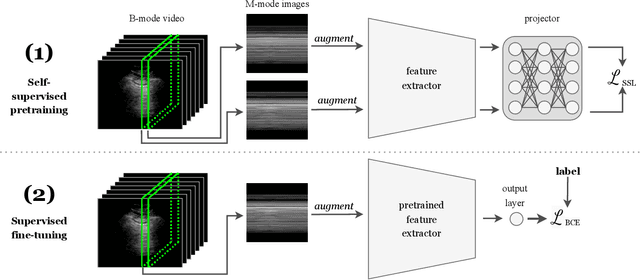
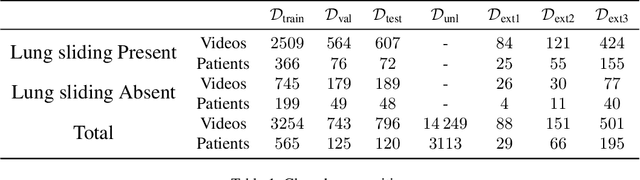
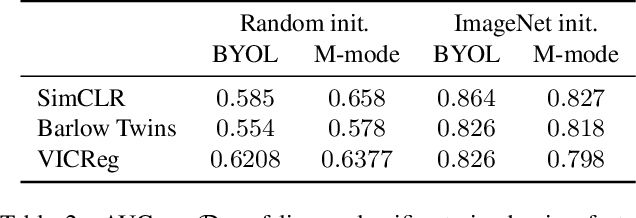
Self-supervised pretraining has been observed to improve performance in supervised learning tasks in medical imaging. This study investigates the utility of self-supervised pretraining prior to conducting supervised fine-tuning for the downstream task of lung sliding classification in M-mode lung ultrasound images. We propose a novel pairwise relationship that couples M-mode images constructed from the same B-mode image and investigate the utility of data augmentation procedure specific to M-mode lung ultrasound. The results indicate that self-supervised pretraining yields better performance than full supervision, most notably for feature extractors not initialized with ImageNet-pretrained weights. Moreover, we observe that including a vast volume of unlabelled data results in improved performance on external validation datasets, underscoring the value of self-supervision for improving generalizability in automatic ultrasound interpretation. To the authors' best knowledge, this study is the first to characterize the influence of self-supervised pretraining for M-mode ultrasound.
Robust Hyperspectral Image Fusion with Simultaneous Guide Image Denoising via Constrained Convex Optimization
Sep 24, 2022
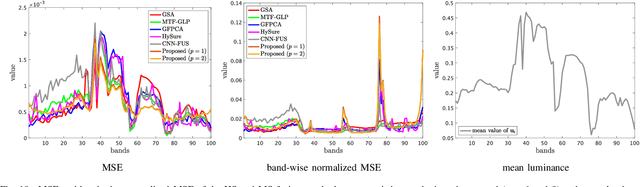

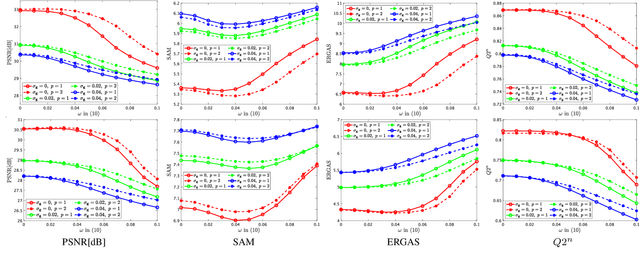
The paper proposes a new high spatial resolution hyperspectral (HR-HS) image estimation method based on convex optimization. The method assumes a low spatial resolution HS (LR-HS) image and a guide image as observations, where both observations are contaminated by noise. Our method simultaneously estimates an HR-HS image and a noiseless guide image, so the method can utilize spatial information in a guide image even if it is contaminated by heavy noise. The proposed estimation problem adopts hybrid spatio-spectral total variation as regularization and evaluates the edge similarity between HR-HS and guide images to effectively use apriori knowledge on an HR-HS image and spatial detail information in a guide image. To efficiently solve the problem, we apply a primal-dual splitting method. Experiments demonstrate the performance of our method and the advantage over several existing methods.
Improving 3D Imaging with Pre-Trained Perpendicular 2D Diffusion Models
Mar 15, 2023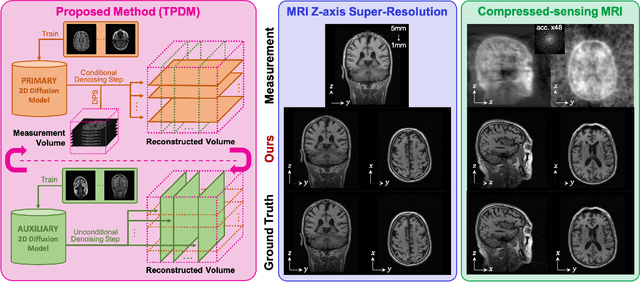
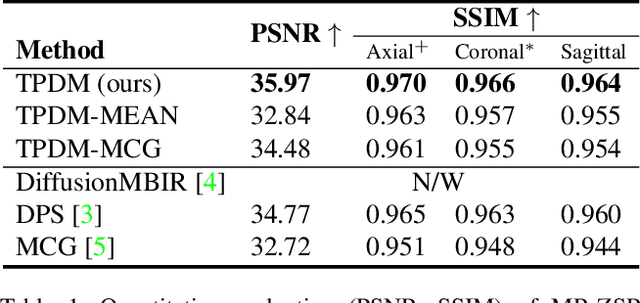
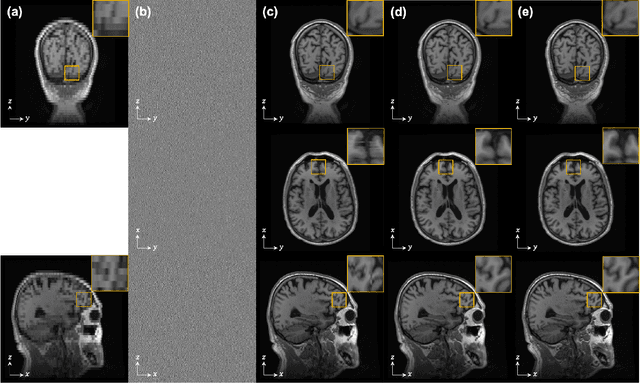
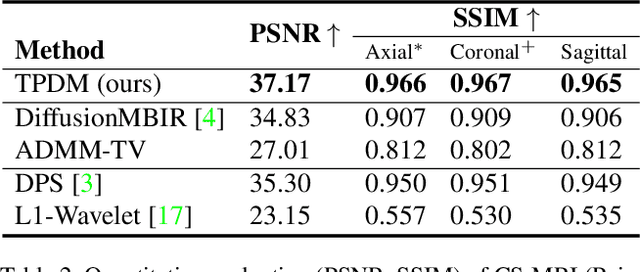
Diffusion models have become a popular approach for image generation and reconstruction due to their numerous advantages. However, most diffusion-based inverse problem-solving methods only deal with 2D images, and even recently published 3D methods do not fully exploit the 3D distribution prior. To address this, we propose a novel approach using two perpendicular pre-trained 2D diffusion models to solve the 3D inverse problem. By modeling the 3D data distribution as a product of 2D distributions sliced in different directions, our method effectively addresses the curse of dimensionality. Our experimental results demonstrate that our method is highly effective for 3D medical image reconstruction tasks, including MRI Z-axis super-resolution, compressed sensing MRI, and sparse-view CT. Our method can generate high-quality voxel volumes suitable for medical applications.