 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Towards Composable Distributions of Latent Space Augmentations
Mar 06, 2023
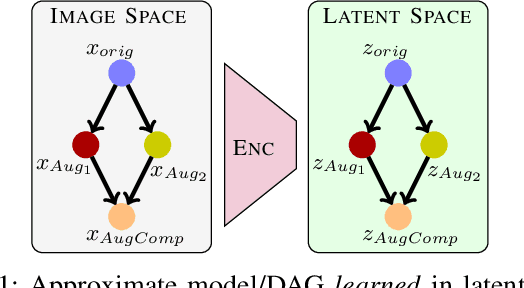
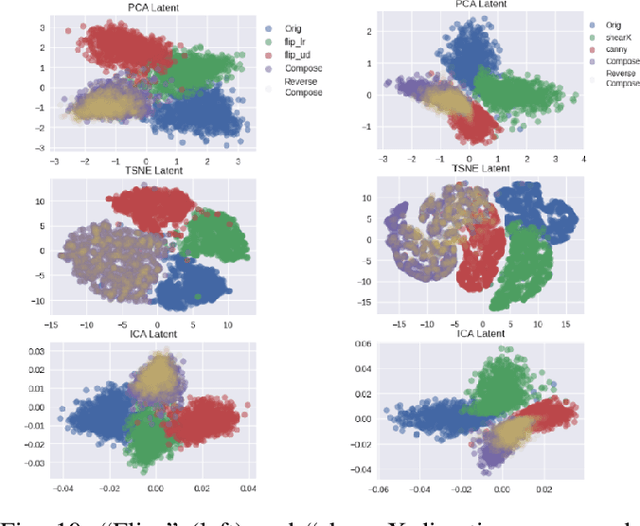
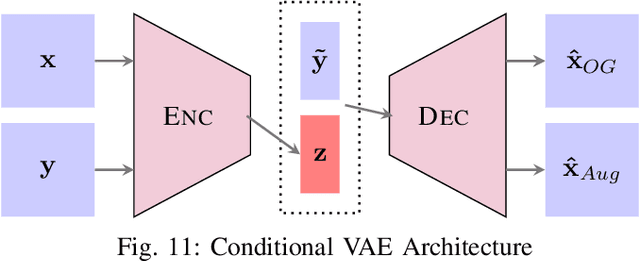

We propose a composable framework for latent space image augmentation that allows for easy combination of multiple augmentations. Image augmentation has been shown to be an effective technique for improving the performance of a wide variety of image classification and generation tasks. Our framework is based on the Variational Autoencoder architecture and uses a novel approach for augmentation via linear transformation within the latent space itself. We explore losses and augmentation latent geometry to enforce the transformations to be composable and involuntary, thus allowing the transformations to be readily combined or inverted. Finally, we show these properties are better performing with certain pairs of augmentations, but we can transfer the latent space to other sets of augmentations to modify performance, effectively constraining the VAE's bottleneck to preserve the variance of specific augmentations and features of the image which we care about. We demonstrate the effectiveness of our approach with initial results on the MNIST dataset against both a standard VAE and a Conditional VAE. This latent augmentation method allows for much greater control and geometric interpretability of the latent space, making it a valuable tool for researchers and practitioners in the field.
Robust Hyperspectral Image Fusion with Simultaneous Guide Image Denoising via Constrained Convex Optimization
Sep 24, 2022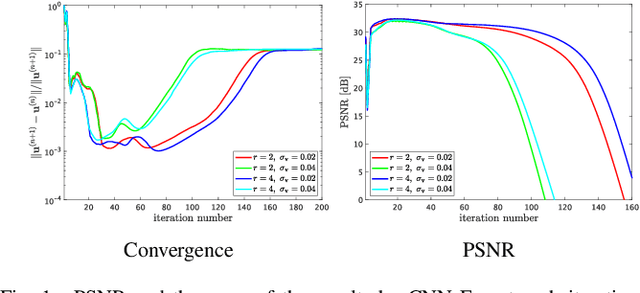
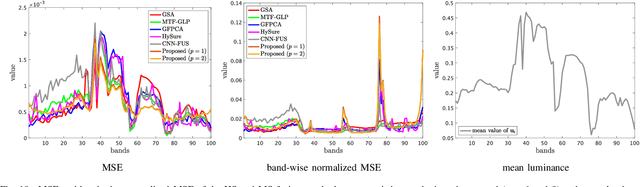

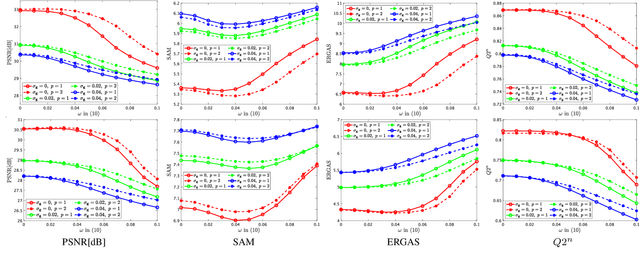
The paper proposes a new high spatial resolution hyperspectral (HR-HS) image estimation method based on convex optimization. The method assumes a low spatial resolution HS (LR-HS) image and a guide image as observations, where both observations are contaminated by noise. Our method simultaneously estimates an HR-HS image and a noiseless guide image, so the method can utilize spatial information in a guide image even if it is contaminated by heavy noise. The proposed estimation problem adopts hybrid spatio-spectral total variation as regularization and evaluates the edge similarity between HR-HS and guide images to effectively use apriori knowledge on an HR-HS image and spatial detail information in a guide image. To efficiently solve the problem, we apply a primal-dual splitting method. Experiments demonstrate the performance of our method and the advantage over several existing methods.
CDDFuse: Correlation-Driven Dual-Branch Feature Decomposition for Multi-Modality Image Fusion
Nov 26, 2022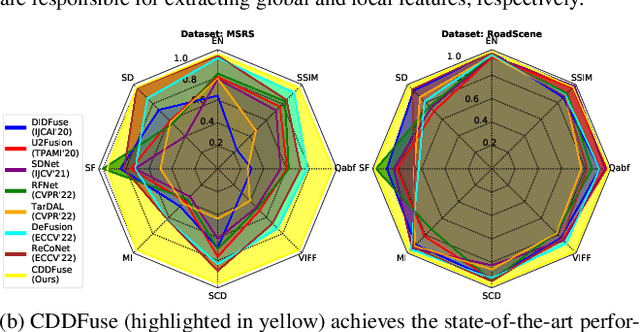
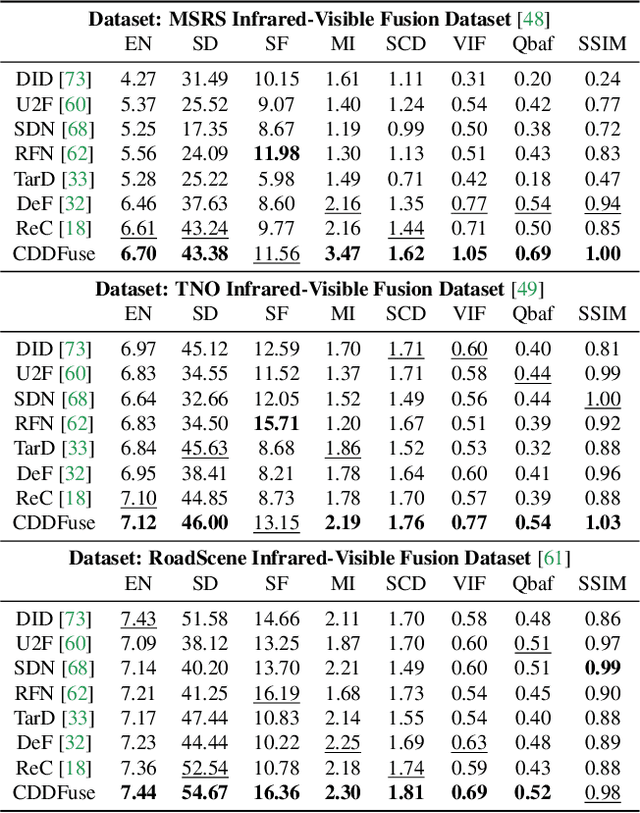
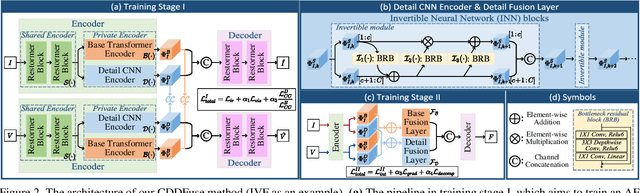
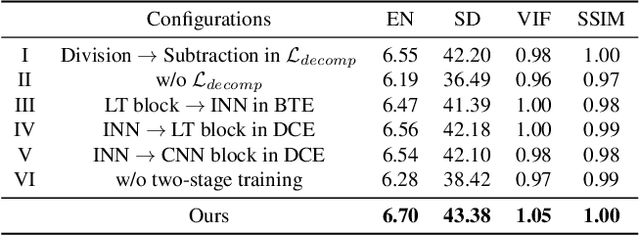
Multi-modality (MM) image fusion aims to render fused images that maintain the merits of different modalities, e.g., functional highlight and detailed textures. To tackle the challenge in modeling cross-modality features and decomposing desirable modality-specific and modality-shared features, we propose a novel Correlation-Driven feature Decomposition Fusion (CDDFuse) network for end-to-end MM feature decomposition and image fusion. In the first stage of the two-stage architectures, CDDFuse uses Restormer blocks to extract cross-modality shallow features. We then introduce a dual-branch Transformer-CNN feature extractor with Lite Transformer (LT) blocks leveraging long-range attention to handle low-frequency global features and Invertible Neural Networks (INN) blocks focusing on extracting high-frequency local information. Upon the embedded semantic information, the low-frequency features should be correlated while the high-frequency features should be uncorrelated. Thus, we propose a correlation-driven loss for better feature decomposition. In the second stage, the LT-based global fusion and INN-based local fusion layers output the fused image. Extensive experiments demonstrate that our CDDFuse achieves promising results in multiple fusion tasks, including infrared-visible image fusion and medical image fusion. We also show that CDDFuse can boost the performance in downstream infrared-visible semantic segmentation and object detection in a unified benchmark.
Weighted Siamese Network to Predict the Time to Onset of Alzheimer's Disease from MRI Images
Apr 14, 2023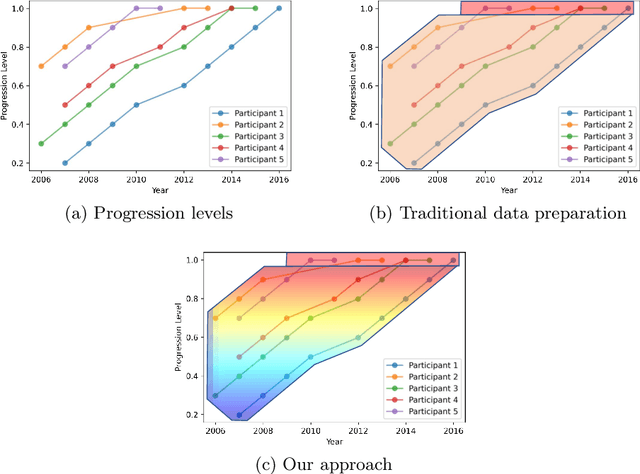

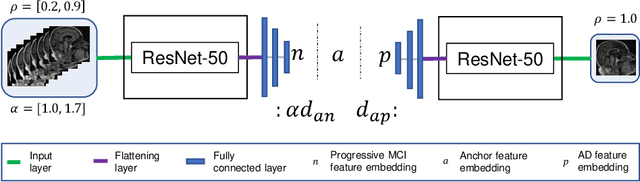

Alzheimer's Disease (AD), which is the most common cause of dementia, is a progressive disease preceded by Mild Cognitive Impairment (MCI). Early detection of the disease is crucial for making treatment decisions. However, most of the literature on computer-assisted detection of AD focuses on classifying brain images into one of three major categories: healthy, MCI, and AD; or categorising MCI patients into one of (1) progressive: those who progress from MCI to AD at a future examination time during a given study period, and (2) stable: those who stay as MCI and never progress to AD. This misses the opportunity to accurately identify the trajectory of progressive MCI patients. In this paper, we revisit the brain image classification task for AD identification and re-frame it as an ordinal classification task to predict how close a patient is to the severe AD stage. To this end, we select progressive MCI patients from the Alzheimer's Disease Neuroimaging Initiative (ADNI) dataset and construct an ordinal dataset with a prediction target that indicates the time to progression to AD. We train a siamese network model to predict the time to onset of AD based on MRI brain images. We also propose a weighted variety of siamese networks and compare its performance to a baseline model. Our evaluations show that incorporating a weighting factor to siamese networks brings considerable performance gain at predicting how close input brain MRI images are to progressing to AD.
Sensitive Region-based Metamorphic Testing Framework using Explainable AI
Mar 30, 2023


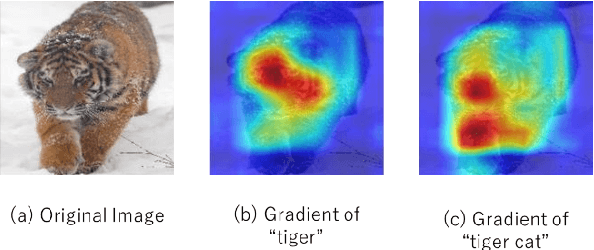
Deep Learning (DL) is one of the most popular research topics in machine learning and DL-driven image recognition systems have developed rapidly. Recent research has employed metamorphic testing (MT) to detect misclassified images. Most of them discuss metamorphic relations (MR), with limited attention given to which regions should be transformed. We focus on the fact that there are sensitive regions where even small transformations can easily change the prediction results and propose an MT framework that efficiently tests for regions prone to misclassification by transforming these sensitive regions. Our evaluation demonstrated that the sensitive regions can be specified by Explainable AI (XAI) and our framework effectively detects faults.
CoLa-Diff: Conditional Latent Diffusion Model for Multi-Modal MRI Synthesis
Mar 24, 2023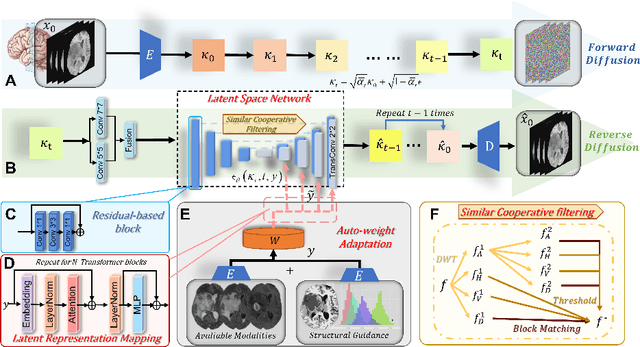
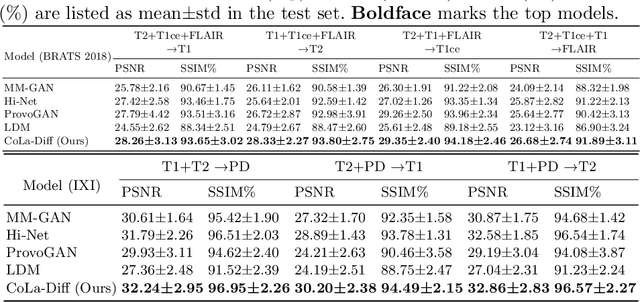
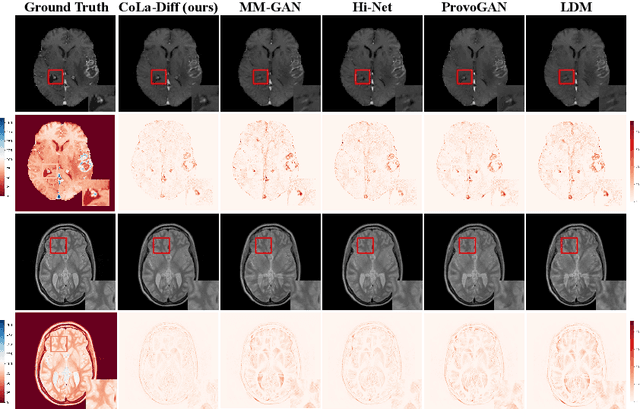
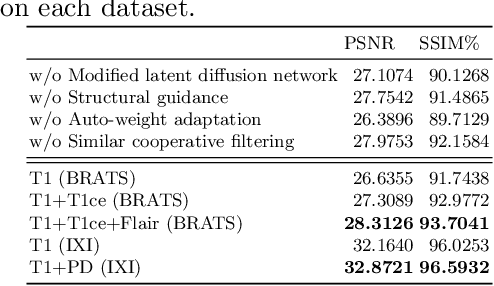
MRI synthesis promises to mitigate the challenge of missing MRI modality in clinical practice. Diffusion model has emerged as an effective technique for image synthesis by modelling complex and variable data distributions. However, most diffusion-based MRI synthesis models are using a single modality. As they operate in the original image domain, they are memory-intensive and less feasible for multi-modal synthesis. Moreover, they often fail to preserve the anatomical structure in MRI. Further, balancing the multiple conditions from multi-modal MRI inputs is crucial for multi-modal synthesis. Here, we propose the first diffusion-based multi-modality MRI synthesis model, namely Conditioned Latent Diffusion Model (CoLa-Diff). To reduce memory consumption, we design CoLa-Diff to operate in the latent space. We propose a novel network architecture, e.g., similar cooperative filtering, to solve the possible compression and noise in latent space. To better maintain the anatomical structure, brain region masks are introduced as the priors of density distributions to guide diffusion process. We further present auto-weight adaptation to employ multi-modal information effectively. Our experiments demonstrate that CoLa-Diff outperforms other state-of-the-art MRI synthesis methods, promising to serve as an effective tool for multi-modal MRI synthesis.
Optimal Smoothing Distribution Exploration for Backdoor Neutralization in Deep Learning-based Traffic Systems
Mar 24, 2023
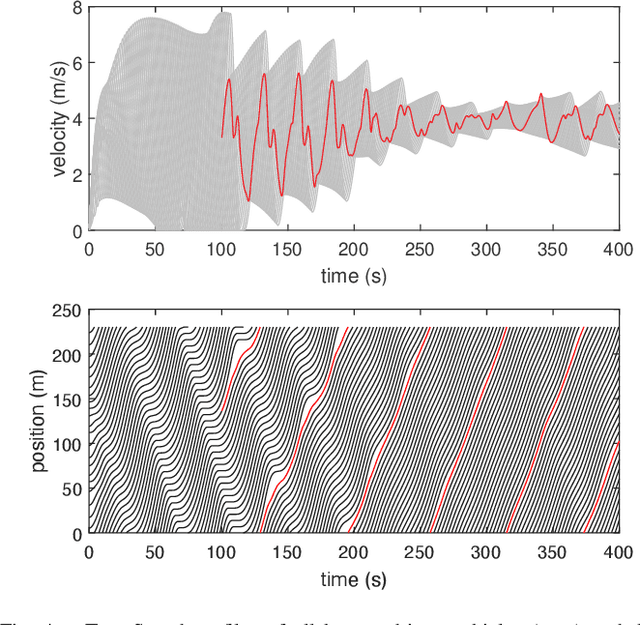
Deep Reinforcement Learning (DRL) enhances the efficiency of Autonomous Vehicles (AV), but also makes them susceptible to backdoor attacks that can result in traffic congestion or collisions. Backdoor functionality is typically incorporated by contaminating training datasets with covert malicious data to maintain high precision on genuine inputs while inducing the desired (malicious) outputs for specific inputs chosen by adversaries. Current defenses against backdoors mainly focus on image classification using image-based features, which cannot be readily transferred to the regression task of DRL-based AV controllers since the inputs are continuous sensor data, i.e., the combinations of velocity and distance of AV and its surrounding vehicles. Our proposed method adds well-designed noise to the input to neutralize backdoors. The approach involves learning an optimal smoothing (noise) distribution to preserve the normal functionality of genuine inputs while neutralizing backdoors. By doing so, the resulting model is expected to be more resilient against backdoor attacks while maintaining high accuracy on genuine inputs. The effectiveness of the proposed method is verified on a simulated traffic system based on a microscopic traffic simulator, where experimental results showcase that the smoothed traffic controller can neutralize all trigger samples and maintain the performance of relieving traffic congestion
Fantasia3D: Disentangling Geometry and Appearance for High-quality Text-to-3D Content Creation
Mar 24, 2023

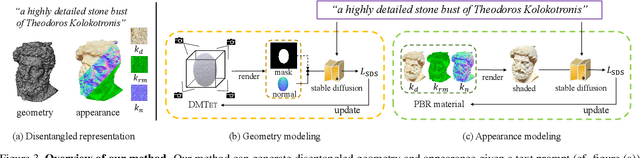
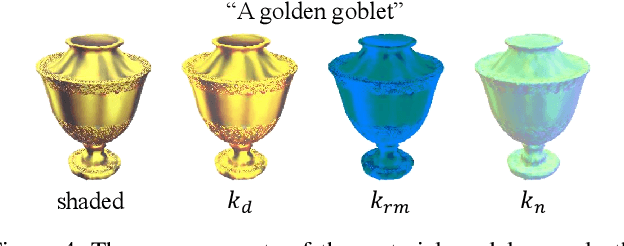
Automatic 3D content creation has achieved rapid progress recently due to the availability of pre-trained, large language models and image diffusion models, forming the emerging topic of text-to-3D content creation. Existing text-to-3D methods commonly use implicit scene representations, which couple the geometry and appearance via volume rendering and are suboptimal in terms of recovering finer geometries and achieving photorealistic rendering; consequently, they are less effective for generating high-quality 3D assets. In this work, we propose a new method of Fantasia3D for high-quality text-to-3D content creation. Key to Fantasia3D is the disentangled modeling and learning of geometry and appearance. For geometry learning, we rely on a hybrid scene representation, and propose to encode surface normal extracted from the representation as the input of the image diffusion model. For appearance modeling, we introduce the spatially varying bidirectional reflectance distribution function (BRDF) into the text-to-3D task, and learn the surface material for photorealistic rendering of the generated surface. Our disentangled framework is more compatible with popular graphics engines, supporting relighting, editing, and physical simulation of the generated 3D assets. We conduct thorough experiments that show the advantages of our method over existing ones under different text-to-3D task settings. Project page and source codes: https://fantasia3d.github.io/.
CF-Font: Content Fusion for Few-shot Font Generation
Mar 24, 2023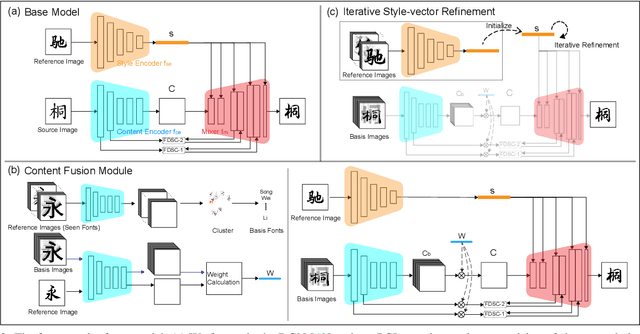
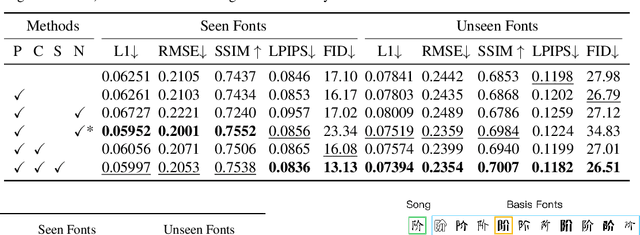
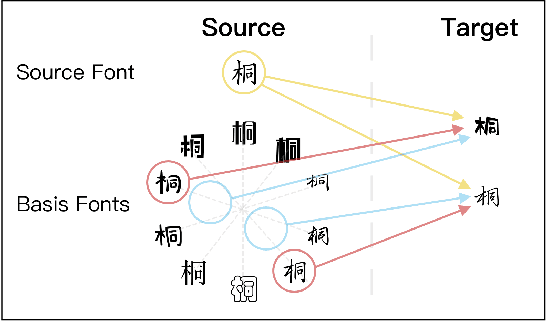
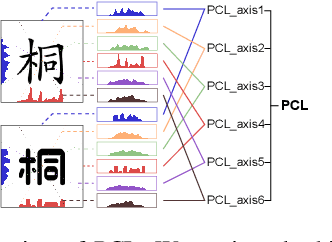
Content and style disentanglement is an effective way to achieve few-shot font generation. It allows to transfer the style of the font image in a source domain to the style defined with a few reference images in a target domain. However, the content feature extracted using a representative font might not be optimal. In light of this, we propose a content fusion module (CFM) to project the content feature into a linear space defined by the content features of basis fonts, which can take the variation of content features caused by different fonts into consideration. Our method also allows to optimize the style representation vector of reference images through a lightweight iterative style-vector refinement (ISR) strategy. Moreover, we treat the 1D projection of a character image as a probability distribution and leverage the distance between two distributions as the reconstruction loss (namely projected character loss, PCL). Compared to L2 or L1 reconstruction loss, the distribution distance pays more attention to the global shape of characters. We have evaluated our method on a dataset of 300 fonts with 6.5k characters each. Experimental results verify that our method outperforms existing state-of-the-art few-shot font generation methods by a large margin. The source code can be found at https://github.com/wangchi95/CF-Font.
Semantic-visual Guided Transformer for Few-shot Class-incremental Learning
Mar 27, 2023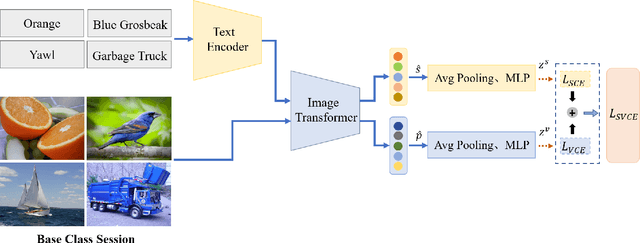
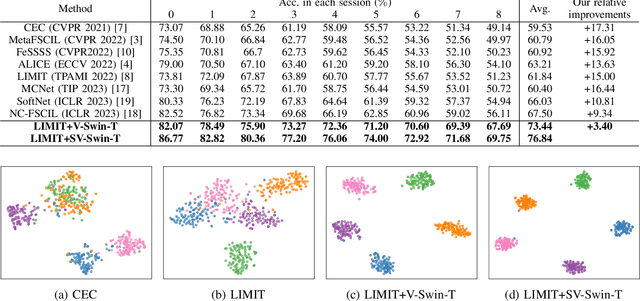
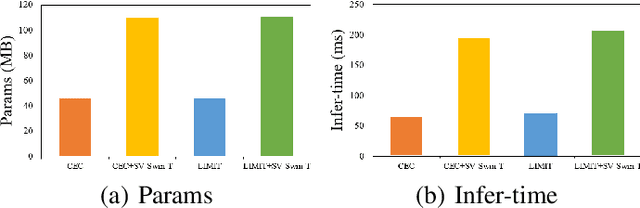
Few-shot class-incremental learning (FSCIL) has recently attracted extensive attention in various areas. Existing FSCIL methods highly depend on the robustness of the feature backbone pre-trained on base classes. In recent years, different Transformer variants have obtained significant processes in the feature representation learning of massive fields. Nevertheless, the progress of the Transformer in FSCIL scenarios has not achieved the potential promised in other fields so far. In this paper, we develop a semantic-visual guided Transformer (SV-T) to enhance the feature extracting capacity of the pre-trained feature backbone on incremental classes. Specifically, we first utilize the visual (image) labels provided by the base classes to supervise the optimization of the Transformer. And then, a text encoder is introduced to automatically generate the corresponding semantic (text) labels for each image from the base classes. Finally, the constructed semantic labels are further applied to the Transformer for guiding its hyperparameters updating. Our SV-T can take full advantage of more supervision information from base classes and further enhance the training robustness of the feature backbone. More importantly, our SV-T is an independent method, which can directly apply to the existing FSCIL architectures for acquiring embeddings of various incremental classes. Extensive experiments on three benchmarks, two FSCIL architectures, and two Transformer variants show that our proposed SV-T obtains a significant improvement in comparison to the existing state-of-the-art FSCIL methods.