 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Efficient Multimodal Sampling via Tempered Distribution Flow
Apr 08, 2023
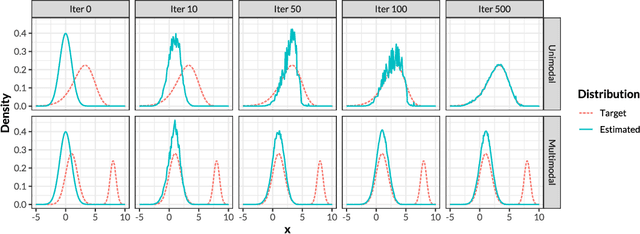


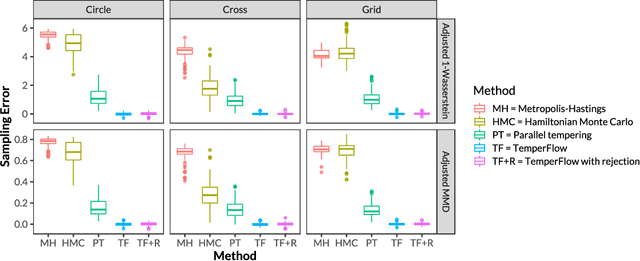
Sampling from high-dimensional distributions is a fundamental problem in statistical research and practice. However, great challenges emerge when the target density function is unnormalized and contains isolated modes. We tackle this difficulty by fitting an invertible transformation mapping, called a transport map, between a reference probability measure and the target distribution, so that sampling from the target distribution can be achieved by pushing forward a reference sample through the transport map. We theoretically analyze the limitations of existing transport-based sampling methods using the Wasserstein gradient flow theory, and propose a new method called TemperFlow that addresses the multimodality issue. TemperFlow adaptively learns a sequence of tempered distributions to progressively approach the target distribution, and we prove that it overcomes the limitations of existing methods. Various experiments demonstrate the superior performance of this novel sampler compared to traditional methods, and we show its applications in modern deep learning tasks such as image generation. The programming code for the numerical experiments is available at https://github.com/yixuan/temperflow.
Machine Learning for Brain Disorders: Transformers and Visual Transformers
Mar 21, 2023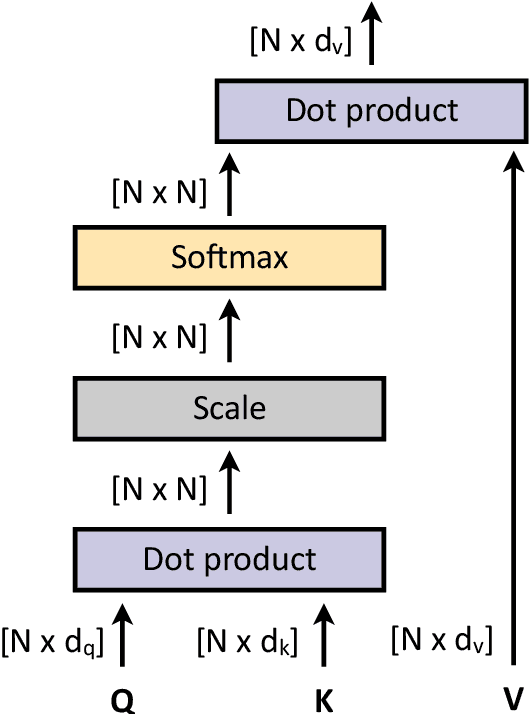
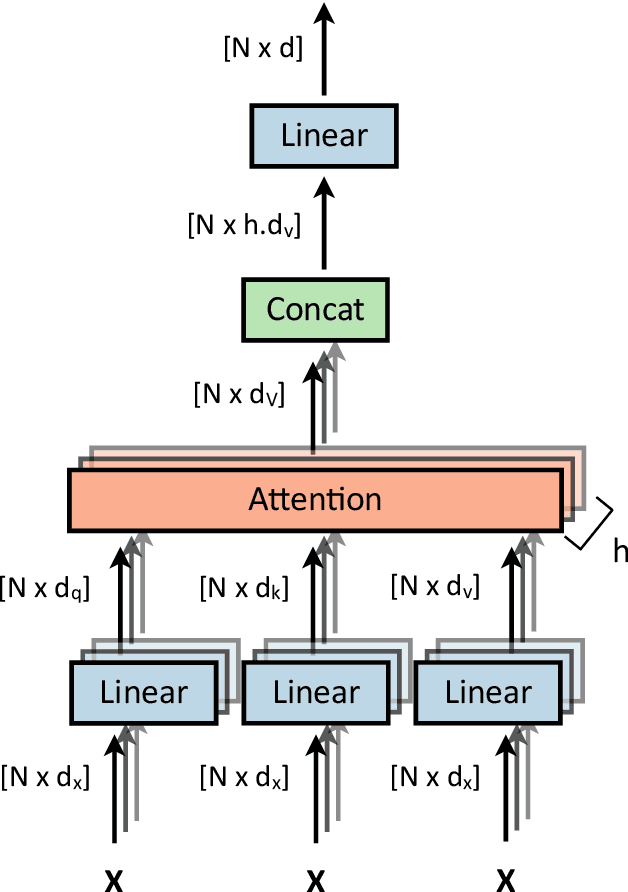

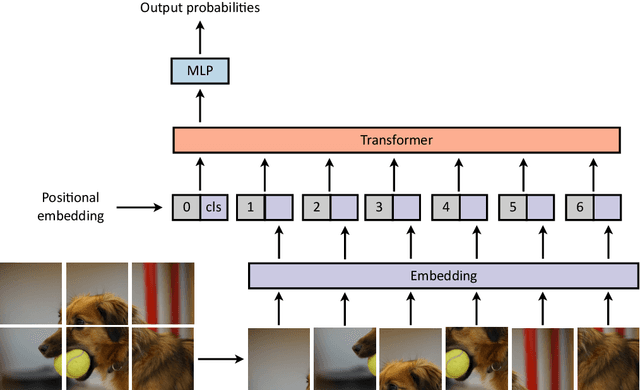
Transformers were initially introduced for natural language processing (NLP) tasks, but fast they were adopted by most deep learning fields, including computer vision. They measure the relationships between pairs of input tokens (words in the case of text strings, parts of images for visual Transformers), termed attention. The cost is exponential with the number of tokens. For image classification, the most common Transformer Architecture uses only the Transformer Encoder in order to transform the various input tokens. However, there are also numerous other applications in which the decoder part of the traditional Transformer Architecture is also used. Here, we first introduce the Attention mechanism (Section 1), and then the Basic Transformer Block including the Vision Transformer (Section 2). Next, we discuss some improvements of visual Transformers to account for small datasets or less computation(Section 3). Finally, we introduce Visual Transformers applied to tasks other than image classification, such as detection, segmentation, generation and training without labels (Section 4) and other domains, such as video or multimodality using text or audio data (Section 5).
SC-ML: Self-supervised Counterfactual Metric Learning for Debiased Visual Question Answering
Apr 04, 2023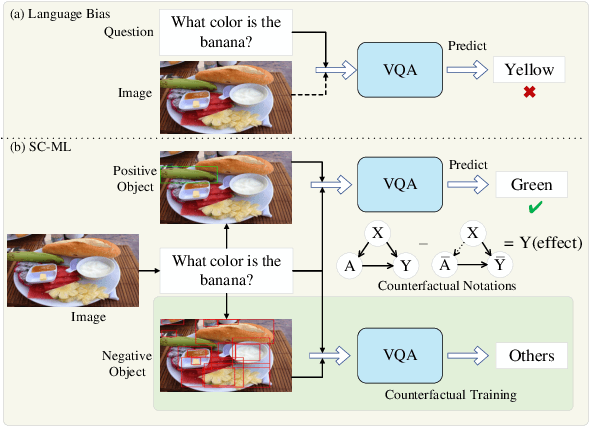
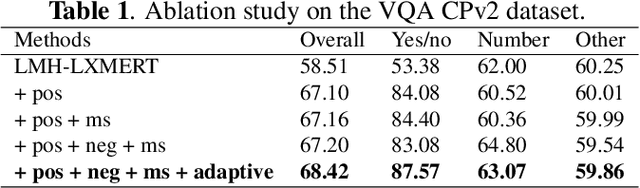
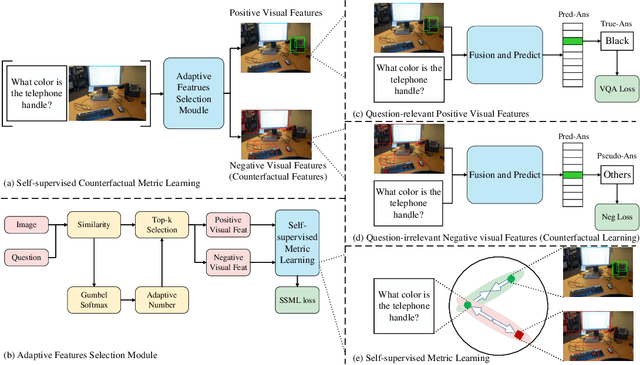
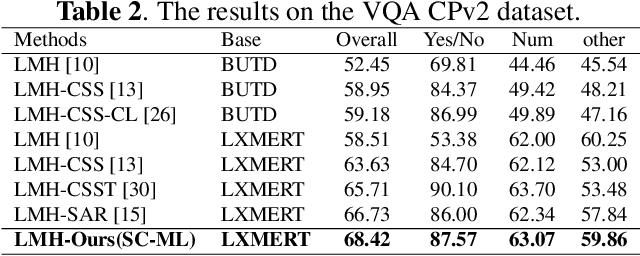
Visual question answering (VQA) is a critical multimodal task in which an agent must answer questions according to the visual cue. Unfortunately, language bias is a common problem in VQA, which refers to the model generating answers only by associating with the questions while ignoring the visual content, resulting in biased results. We tackle the language bias problem by proposing a self-supervised counterfactual metric learning (SC-ML) method to focus the image features better. SC-ML can adaptively select the question-relevant visual features to answer the question, reducing the negative influence of question-irrelevant visual features on inferring answers. In addition, question-irrelevant visual features can be seamlessly incorporated into counterfactual training schemes to further boost robustness. Extensive experiments have proved the effectiveness of our method with improved results on the VQA-CP dataset. Our code will be made publicly available.
I Hear Your True Colors: Image Guided Audio Generation
Nov 06, 2022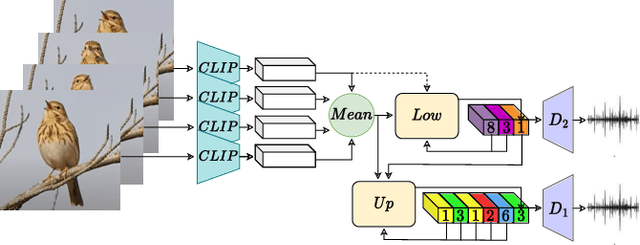
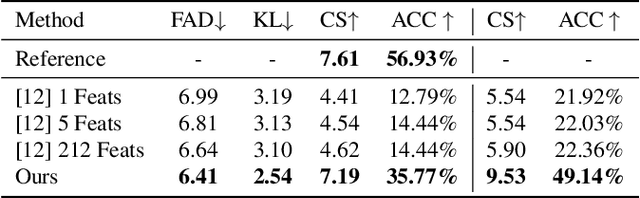
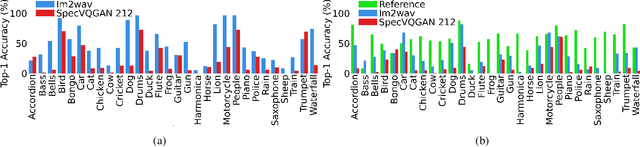
We propose Im2Wav, an image guided open-domain audio generation system. Given an input image or a sequence of images, Im2Wav generates a semantically relevant sound. Im2Wav is based on two Transformer language models, that operate over a hierarchical discrete audio representation obtained from a VQ-VAE based model. We first produce a low-level audio representation using a language model. Then, we upsample the audio tokens using an additional language model to generate a high-fidelity audio sample. We use the rich semantics of a pre-trained CLIP embedding as a visual representation to condition the language model. In addition, to steer the generation process towards the conditioning image, we apply the classifier-free guidance method. Results suggest that Im2Wav significantly outperforms the evaluated baselines in both fidelity and relevance evaluation metrics. Additionally, we provide an ablation study to better assess the impact of each of the method components on overall performance. Lastly, to better evaluate image-to-audio models, we propose an out-of-domain image dataset, denoted as ImageHear. ImageHear can be used as a benchmark for evaluating future image-to-audio models. Samples and code can be found inside the manuscript.
Learning Knowledge-Rich Sequential Model for Planar Homography Estimation in Aerial Video
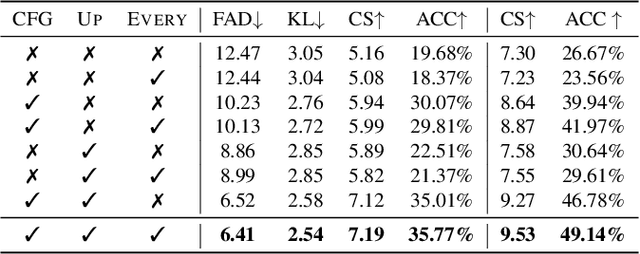
Apr 05, 2023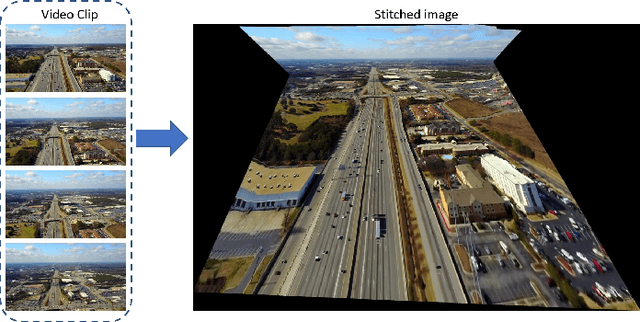
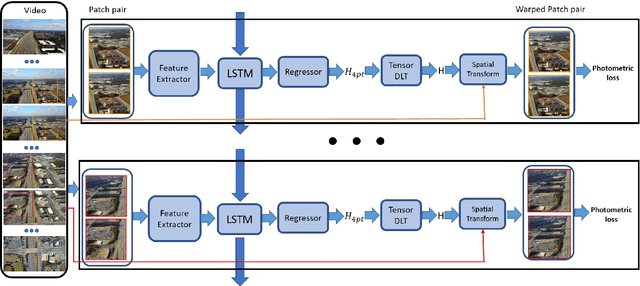

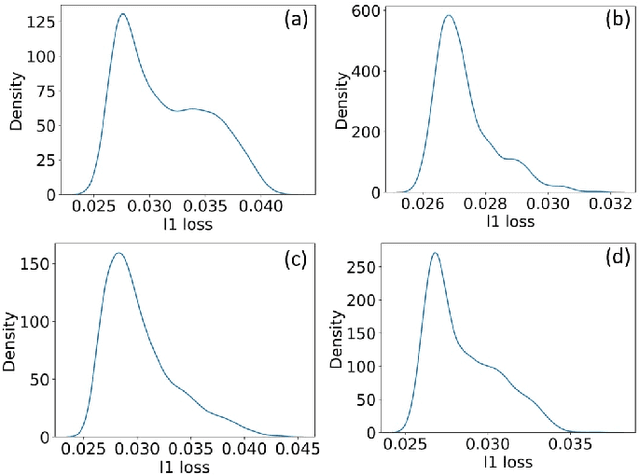
This paper presents an unsupervised approach that leverages raw aerial videos to learn to estimate planar homographic transformation between consecutive video frames. Previous learning-based estimators work on pairs of images to estimate their planar homographic transformations but suffer from severe over-fitting issues, especially when applying over aerial videos. To address this concern, we develop a sequential estimator that directly processes a sequence of video frames and estimates their pairwise planar homographic transformations in batches. We also incorporate a set of spatial-temporal knowledge to regularize the learning of such a sequence-to-sequence model. We collect a set of challenging aerial videos and compare the proposed method to the alternative algorithms. Empirical studies suggest that our sequential model achieves significant improvement over alternative image-based methods and the knowledge-rich regularization further boosts our system performance. Our codes and dataset could be found at https://github.com/Paul-LiPu/DeepVideoHomography
Towards Self-Explainability of Deep Neural Networks with Heatmap Captioning and Large-Language Models
Apr 05, 2023
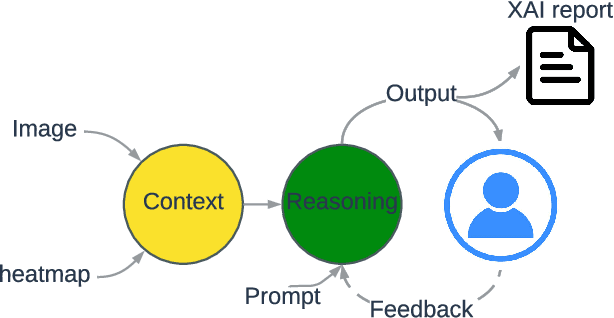
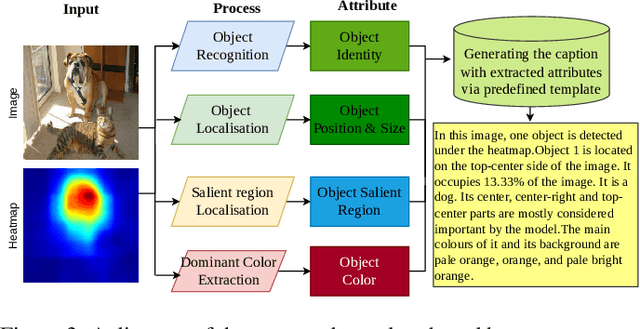
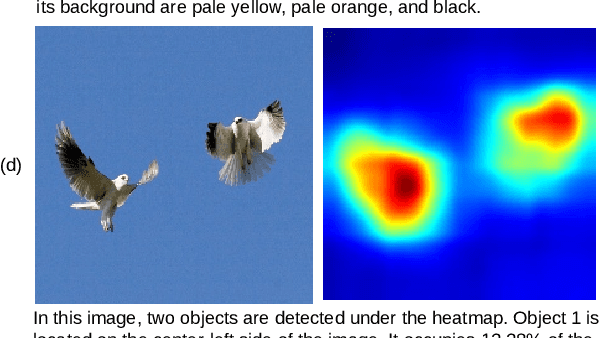
Heatmaps are widely used to interpret deep neural networks, particularly for computer vision tasks, and the heatmap-based explainable AI (XAI) techniques are a well-researched topic. However, most studies concentrate on enhancing the quality of the generated heatmap or discovering alternate heatmap generation techniques, and little effort has been devoted to making heatmap-based XAI automatic, interactive, scalable, and accessible. To address this gap, we propose a framework that includes two modules: (1) context modelling and (2) reasoning. We proposed a template-based image captioning approach for context modelling to create text-based contextual information from the heatmap and input data. The reasoning module leverages a large language model to provide explanations in combination with specialised knowledge. Our qualitative experiments demonstrate the effectiveness of our framework and heatmap captioning approach. The code for the proposed template-based heatmap captioning approach will be publicly available.
Synthesizing Anyone, Anywhere, in Any Pose
Apr 06, 2023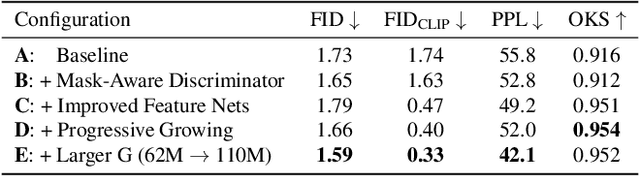
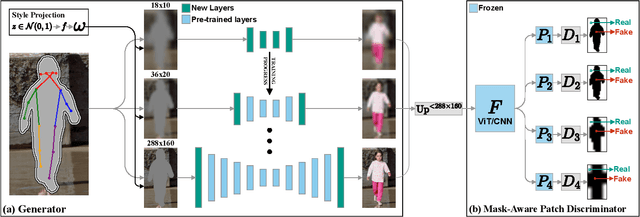

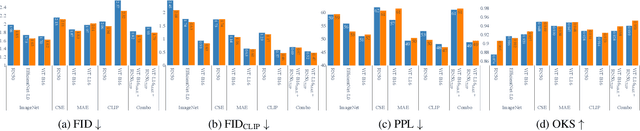
We address the task of in-the-wild human figure synthesis, where the primary goal is to synthesize a full body given any region in any image. In-the-wild human figure synthesis has long been a challenging and under-explored task, where current methods struggle to handle extreme poses, occluding objects, and complex backgrounds. Our main contribution is TriA-GAN, a keypoint-guided GAN that can synthesize Anyone, Anywhere, in Any given pose. Key to our method is projected GANs combined with a well-crafted training strategy, where our simple generator architecture can successfully handle the challenges of in-the-wild full-body synthesis. We show that TriA-GAN significantly improves over previous in-the-wild full-body synthesis methods, all while requiring less conditional information for synthesis (keypoints vs. DensePose). Finally, we show that the latent space of \methodName is compatible with standard unconditional editing techniques, enabling text-guided editing of generated human figures.
Weighted Siamese Network to Predict the Time to Onset of Alzheimer's Disease from MRI Images
Apr 14, 2023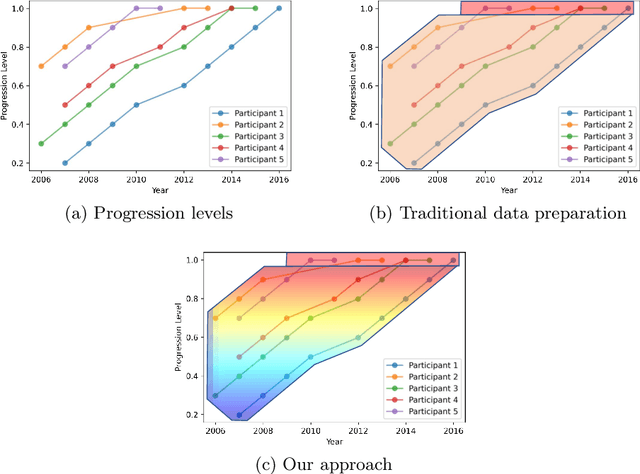

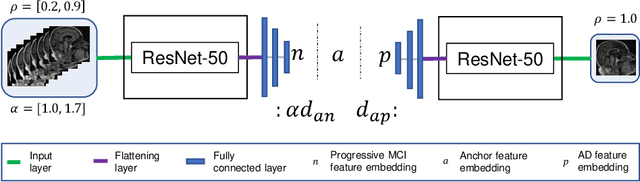

Alzheimer's Disease (AD), which is the most common cause of dementia, is a progressive disease preceded by Mild Cognitive Impairment (MCI). Early detection of the disease is crucial for making treatment decisions. However, most of the literature on computer-assisted detection of AD focuses on classifying brain images into one of three major categories: healthy, MCI, and AD; or categorising MCI patients into one of (1) progressive: those who progress from MCI to AD at a future examination time during a given study period, and (2) stable: those who stay as MCI and never progress to AD. This misses the opportunity to accurately identify the trajectory of progressive MCI patients. In this paper, we revisit the brain image classification task for AD identification and re-frame it as an ordinal classification task to predict how close a patient is to the severe AD stage. To this end, we select progressive MCI patients from the Alzheimer's Disease Neuroimaging Initiative (ADNI) dataset and construct an ordinal dataset with a prediction target that indicates the time to progression to AD. We train a siamese network model to predict the time to onset of AD based on MRI brain images. We also propose a weighted variety of siamese networks and compare its performance to a baseline model. Our evaluations show that incorporating a weighting factor to siamese networks brings considerable performance gain at predicting how close input brain MRI images are to progressing to AD.
BoundaryCAM: A Boundary-based Refinement Framework for Weakly Supervised Semantic Segmentation of Medical Images
Mar 14, 2023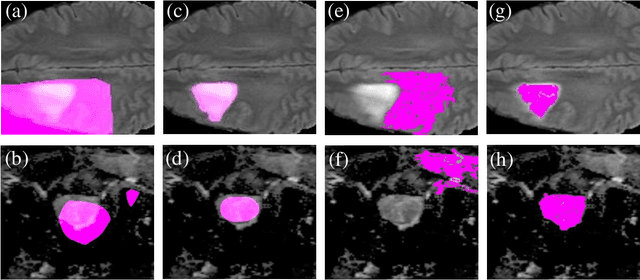
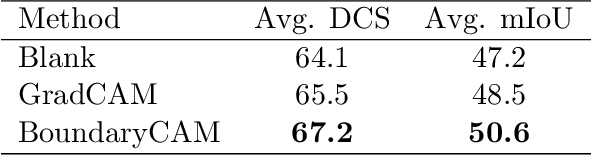
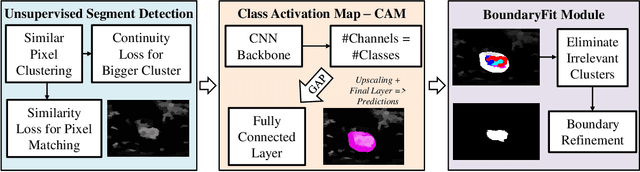
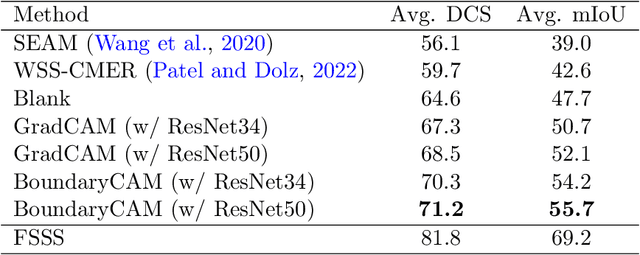
Weakly Supervised Semantic Segmentation (WSSS) with only image-level supervision is a promising approach to deal with the need for Segmentation networks, especially for generating a large number of pixel-wise masks in a given dataset. However, most state-of-the-art image-level WSSS techniques lack an understanding of the geometric features embedded in the images since the network cannot derive any object boundary information from just image-level labels. We define a boundary here as the line separating an object and its background, or two different objects. To address this drawback, we propose our novel BoundaryCAM framework, which deploys state-of-the-art class activation maps combined with various post-processing techniques in order to achieve fine-grained higher-accuracy segmentation masks. To achieve this, we investigate a state-of-the-art unsupervised semantic segmentation network that can be used to construct a boundary map, which enables BoundaryCAM to predict object locations with sharper boundaries. By applying our method to WSSS predictions, we were able to achieve up to 10% improvements even to the benefit of the current state-of-the-art WSSS methods for medical imaging. The framework is open-source and accessible online at https://github.com/bharathprabakaran/BoundaryCAM.
Fracture Detection in Pediatric Wrist Trauma X-ray Images Using YOLOv8 Algorithm
Apr 11, 2023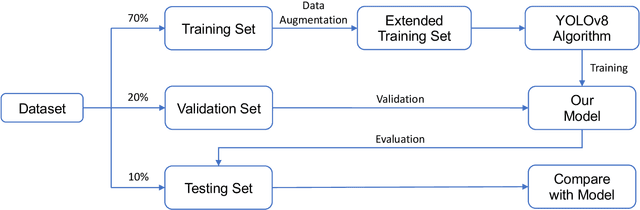
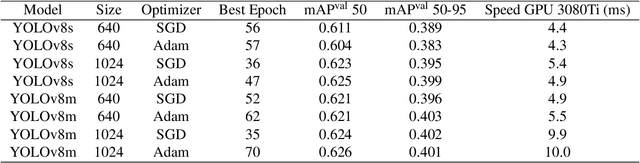
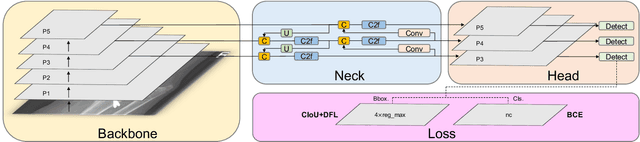
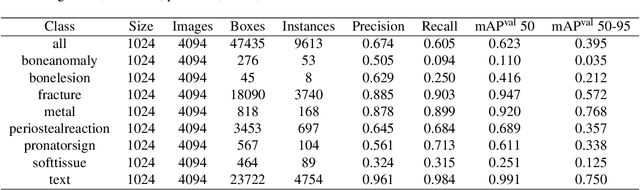
Hospital emergency departments frequently receive lots of bone fracture cases, with pediatric wrist trauma fracture accounting for the majority of them. Before pediatric surgeons perform surgery, they need to ask patients how the fracture occurred and analyze the fracture situation by interpreting X-ray images. The interpretation of X-ray images often requires a combination of techniques from radiologists and surgeons, which requires time-consuming specialized training. With the rise of deep learning in the field of computer vision, network models applying for fracture detection has become an important research topic. In this paper, YOLOv8 algorithm is used to train models on the GRAZPEDWRI-DX dataset, which includes X-ray images from 6,091 pediatric patients with wrist trauma. The experimental results show that YOLOv8 algorithm models have different advantages for different model sizes, with YOLOv8l model achieving the highest mean average precision (mAP 50) of 63.6\%, and YOLOv8n model achieving the inference time of 67.4ms per X-ray image on one single CPU with low computing power. In this way, we create "Fracture Detection Using YOLOv8 App" to assist surgeons in interpreting X-ray images without the help of radiologists. Our implementation code is released at https://github.com/RuiyangJu/Bone_Fracture_Detection_YOLOv8.