 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning Accurate Performance Predictors for Ultrafast Automated Model Compression
Apr 13, 2023
In this paper, we propose an ultrafast automated model compression framework called SeerNet for flexible network deployment. Conventional non-differen-tiable methods discretely search the desirable compression policy based on the accuracy from exhaustively trained lightweight models, and existing differentiable methods optimize an extremely large supernet to obtain the required compressed model for deployment. They both cause heavy computational cost due to the complex compression policy search and evaluation process. On the contrary, we obtain the optimal efficient networks by directly optimizing the compression policy with an accurate performance predictor, where the ultrafast automated model compression for various computational cost constraint is achieved without complex compression policy search and evaluation. Specifically, we first train the performance predictor based on the accuracy from uncertain compression policies actively selected by efficient evolutionary search, so that informative supervision is provided to learn the accurate performance predictor with acceptable cost. Then we leverage the gradient that maximizes the predicted performance under the barrier complexity constraint for ultrafast acquisition of the desirable compression policy, where adaptive update stepsizes with momentum are employed to enhance optimality of the acquired pruning and quantization strategy. Compared with the state-of-the-art automated model compression methods, experimental results on image classification and object detection show that our method achieves competitive accuracy-complexity trade-offs with significant reduction of the search cost.
PALF: Pre-Annotation and Camera-LiDAR Late Fusion for the Easy Annotation of Point Clouds
Apr 13, 2023

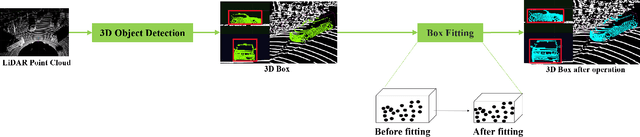
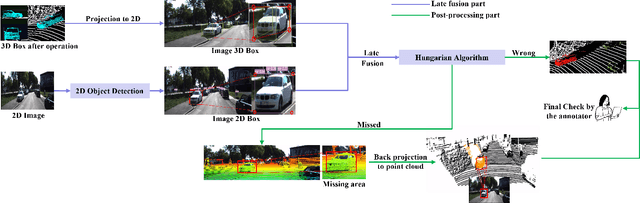
3D object detection has become indispensable in the field of autonomous driving. To date, gratifying breakthroughs have been recorded in 3D object detection research, attributed to deep learning. However, deep learning algorithms are data-driven and require large amounts of annotated point cloud data for training and evaluation. Unlike 2D image labels, annotating point cloud data is difficult due to the limitations of sparsity, irregularity, and low resolution, which requires more manual work, and the annotation efficiency is much lower than 2D image.Therefore, we propose an annotation algorithm for point cloud data, which is pre-annotation and camera-LiDAR late fusion algorithm to easily and accurately annotate. The contributions of this study are as follows. We propose (1) a pre-annotation algorithm that employs 3D object detection and auto fitting for the easy annotation of point clouds, (2) a camera-LiDAR late fusion algorithm using 2D and 3D results for easily error checking, which helps annotators easily identify missing objects, and (3) a point cloud annotation evaluation pipeline to evaluate our experiments. The experimental results show that the proposed algorithm improves the annotating speed by 6.5 times and the annotation quality in terms of the 3D Intersection over Union and precision by 8.2 points and 5.6 points, respectively; additionally, the miss rate is reduced by 31.9 points.
Self-Supervised Visual Representation Learning on Food Images
Mar 16, 2023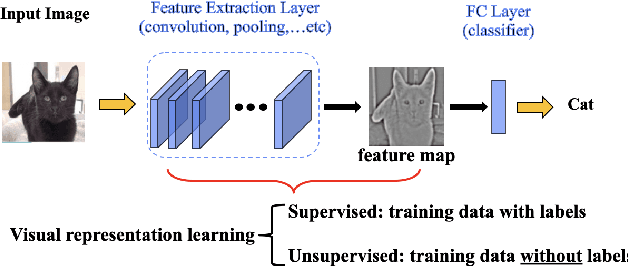
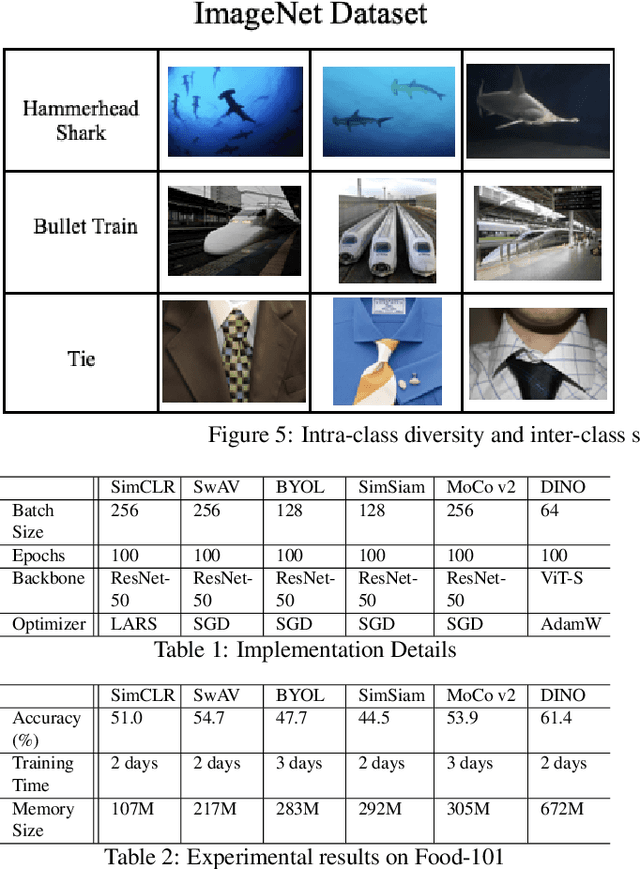
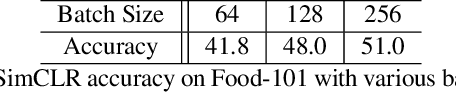

Food image analysis is the groundwork for image-based dietary assessment, which is the process of monitoring what kinds of food and how much energy is consumed using captured food or eating scene images. Existing deep learning-based methods learn the visual representation for downstream tasks based on human annotation of each food image. However, most food images in real life are obtained without labels, and data annotation requires plenty of time and human effort, which is not feasible for real-world applications. To make use of the vast amount of unlabeled images, many existing works focus on unsupervised or self-supervised learning of visual representations directly from unlabeled data. However, none of these existing works focus on food images, which is more challenging than general objects due to its high inter-class similarity and intra-class variance. In this paper, we focus on the implementation and analysis of existing representative self-supervised learning methods on food images. Specifically, we first compare the performance of six selected self-supervised learning models on the Food-101 dataset. Then we analyze the pros and cons of each selected model when training on food data to identify the key factors that can help improve the performance. Finally, we propose several ideas for future work on self-supervised visual representation learning for food images.
Learning Physical-Spatio-Temporal Features for Video Shadow Removal
Mar 16, 2023
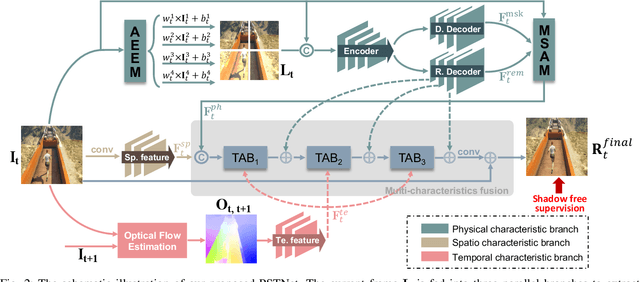
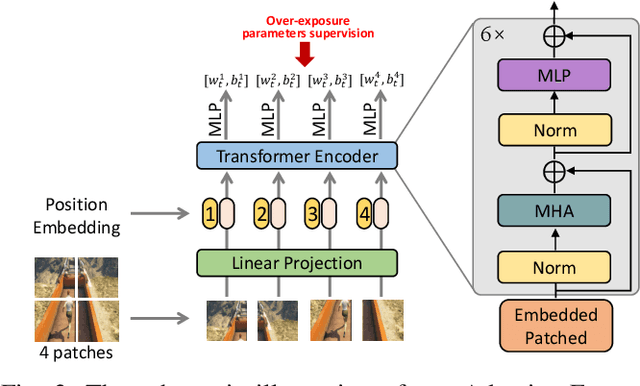
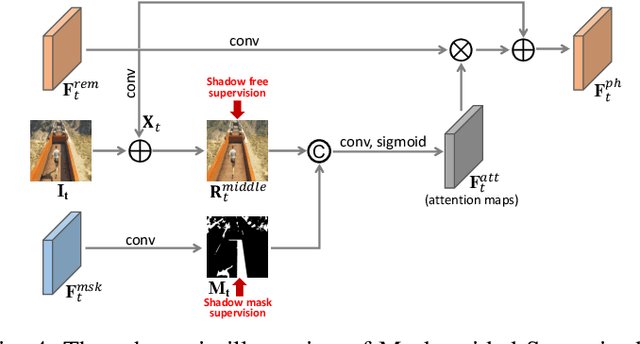
Shadow removal in a single image has received increasing attention in recent years. However, removing shadows over dynamic scenes remains largely under-explored. In this paper, we propose the first data-driven video shadow removal model, termed PSTNet, by exploiting three essential characteristics of video shadows, i.e., physical property, spatio relation, and temporal coherence. Specifically, a dedicated physical branch was established to conduct local illumination estimation, which is more applicable for scenes with complex lighting and textures, and then enhance the physical features via a mask-guided attention strategy. Then, we develop a progressive aggregation module to enhance the spatio and temporal characteristics of features maps, and effectively integrate the three kinds of features. Furthermore, to tackle the lack of datasets of paired shadow videos, we synthesize a dataset (SVSRD-85) with aid of the popular game GTAV by controlling the switch of the shadow renderer. Experiments against 9 state-of-the-art models, including image shadow removers and image/video restoration methods, show that our method improves the best SOTA in terms of RMSE error for the shadow area by 14.7. In addition, we develop a lightweight model adaptation strategy to make our synthetic-driven model effective in real world scenes. The visual comparison on the public SBU-TimeLapse dataset verifies the generalization ability of our model in real scenes.
Multi-granularity Interaction Simulation for Unsupervised Interactive Segmentation
Mar 23, 2023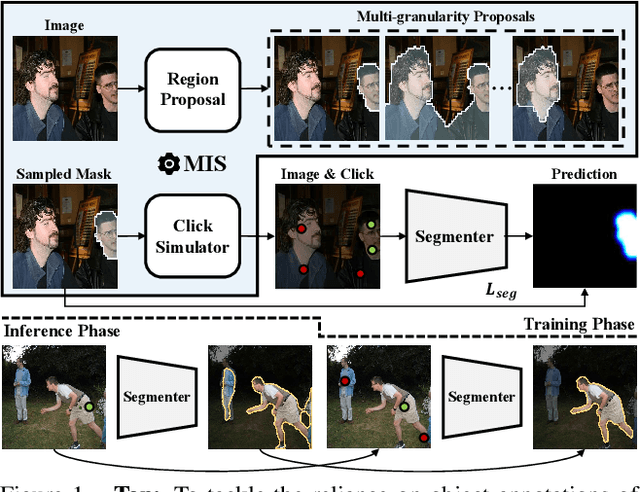
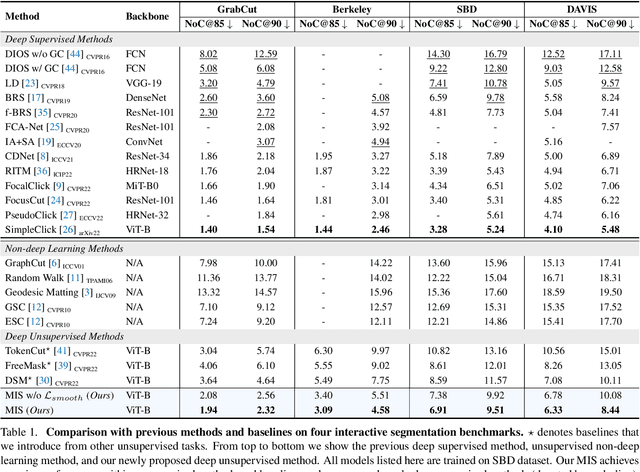

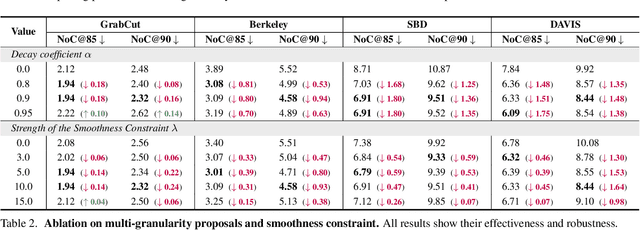
Interactive segmentation enables users to segment as needed by providing cues of objects, which introduces human-computer interaction for many fields, such as image editing and medical image analysis. Typically, massive and expansive pixel-level annotations are spent to train deep models by object-oriented interactions with manually labeled object masks. In this work, we reveal that informative interactions can be made by simulation with semantic-consistent yet diverse region exploration in an unsupervised paradigm. Concretely, we introduce a Multi-granularity Interaction Simulation (MIS) approach to open up a promising direction for unsupervised interactive segmentation. Drawing on the high-quality dense features produced by recent self-supervised models, we propose to gradually merge patches or regions with similar features to form more extensive regions and thus, every merged region serves as a semantic-meaningful multi-granularity proposal. By randomly sampling these proposals and simulating possible interactions based on them, we provide meaningful interaction at multiple granularities to teach the model to understand interactions. Our MIS significantly outperforms non-deep learning unsupervised methods and is even comparable with some previous deep-supervised methods without any annotation.
NeurEPDiff: Neural Operators to Predict Geodesics in Deformation Spaces
Mar 13, 2023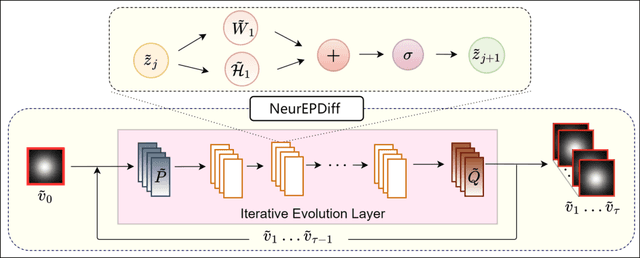
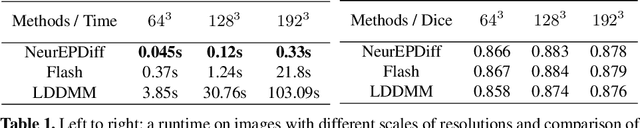
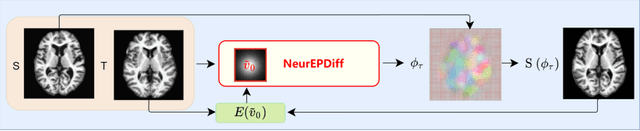

This paper presents NeurEPDiff, a novel network to fast predict the geodesics in deformation spaces generated by a well known Euler-Poincar\'e differential equation (EPDiff). To achieve this, we develop a neural operator that for the first time learns the evolving trajectory of geodesic deformations parameterized in the tangent space of diffeomorphisms(a.k.a velocity fields). In contrast to previous methods that purely fit the training images, our proposed NeurEPDiff learns a nonlinear mapping function between the time-dependent velocity fields. A composition of integral operators and smooth activation functions is formulated in each layer of NeurEPDiff to effectively approximate such mappings. The fact that NeurEPDiff is able to rapidly provide the numerical solution of EPDiff (given any initial condition) results in a significantly reduced computational cost of geodesic shooting of diffeomorphisms in a high-dimensional image space. Additionally, the properties of discretiztion/resolution-invariant of NeurEPDiff make its performance generalizable to multiple image resolutions after being trained offline. We demonstrate the effectiveness of NeurEPDiff in registering two image datasets: 2D synthetic data and 3D brain resonance imaging (MRI). The registration accuracy and computational efficiency are compared with the state-of-the-art diffeomophic registration algorithms with geodesic shooting.
Learning Visual Representations via Language-Guided Sampling
Feb 23, 2023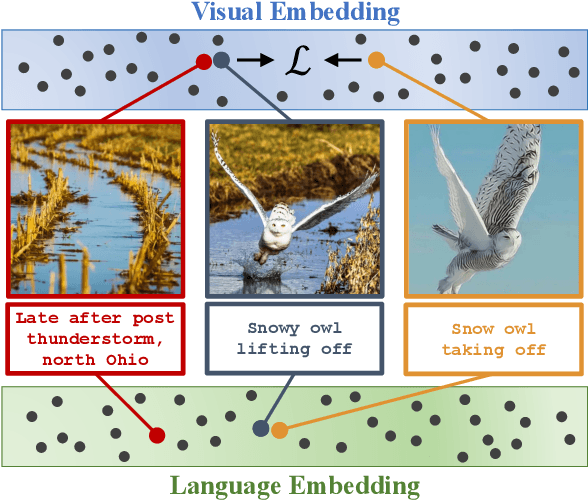
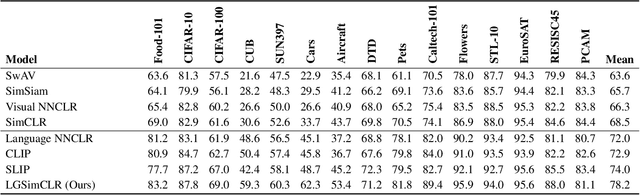


Although an object may appear in numerous contexts, we often describe it in a limited number of ways. This happens because language abstracts away visual variation to represent and communicate concepts. Building on this intuition, we propose an alternative approach to visual learning: using language similarity to sample semantically similar image pairs for contrastive learning. Our approach deviates from image-based contrastive learning by using language to sample pairs instead of hand-crafted augmentations or learned clusters. Our approach also deviates from image-text contrastive learning by relying on pre-trained language models to guide the learning rather than minimize a cross-modal similarity. Through a series of experiments, we show that language-guided learning can learn better features than both image-image and image-text representation learning approaches.
MOREA: a GPU-accelerated Evolutionary Algorithm for Multi-Objective Deformable Registration of 3D Medical Images
Mar 08, 2023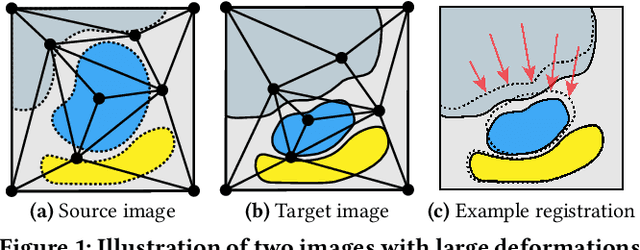

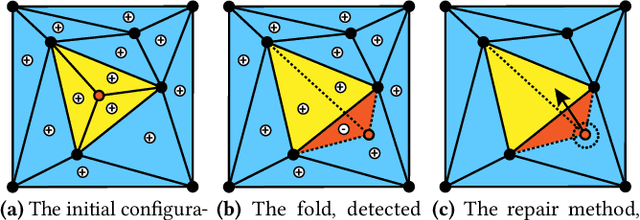
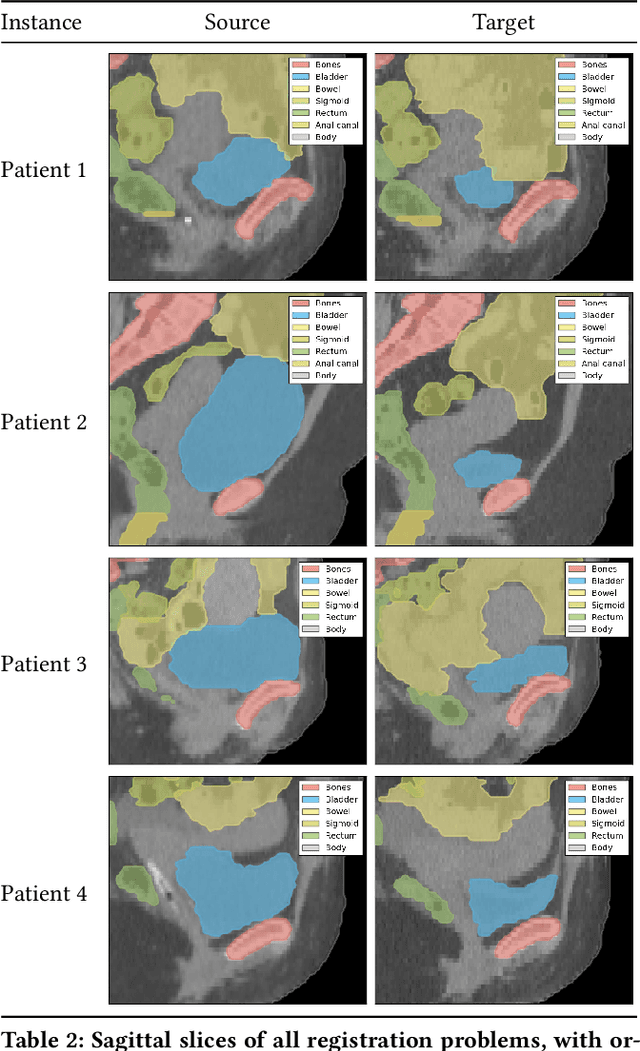
Finding a realistic deformation that transforms one image into another, in case large deformations are required, is considered a key challenge in medical image analysis. Having a proper image registration approach to achieve this could unleash a number of applications requiring information to be transferred between images. Clinical adoption is currently hampered by many existing methods requiring extensive configuration effort before each use, or not being able to (realistically) capture large deformations. A recent multi-objective approach that uses the Multi-Objective Real-Valued Gene-pool Optimal Mixing Evolutionary Algorithm (MO-RV-GOMEA) and a dual-dynamic mesh transformation model has shown promise, exposing the trade-offs inherent to image registration problems and modeling large deformations in 2D. This work builds on this promise and introduces MOREA: the first evolutionary algorithm-based multi-objective approach to deformable registration of 3D images capable of tackling large deformations. MOREA includes a 3D biomechanical mesh model for physical plausibility and is fully GPU-accelerated. We compare MOREA to two state-of-the-art approaches on abdominal CT scans of 4 cervical cancer patients, with the latter two approaches configured for the best results per patient. Without requiring per-patient configuration, MOREA significantly outperforms these approaches on 3 of the 4 patients that represent the most difficult cases.
Audio-Visual Grouping Network for Sound Localization from Mixtures
Mar 29, 2023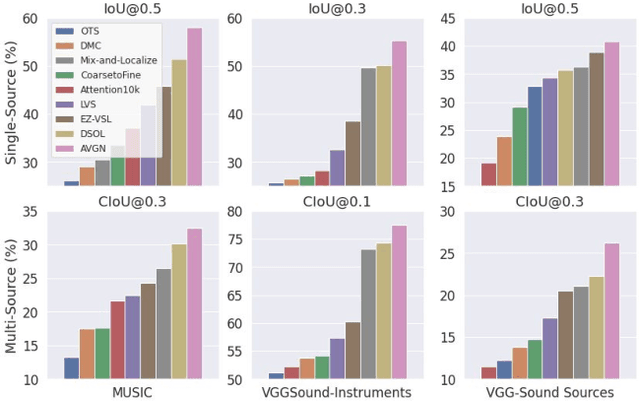
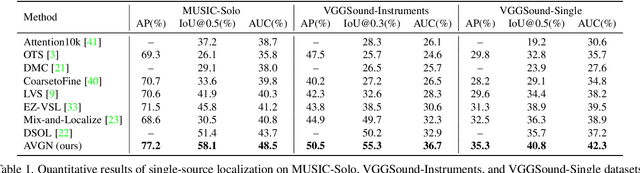
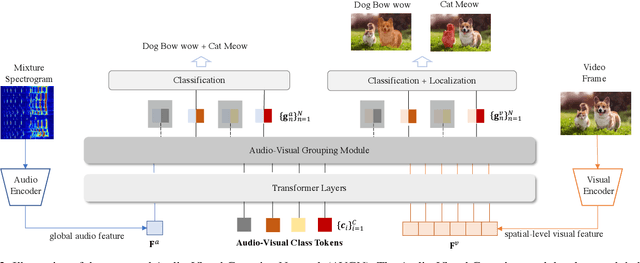
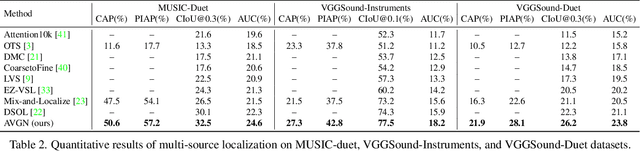
Sound source localization is a typical and challenging task that predicts the location of sound sources in a video. Previous single-source methods mainly used the audio-visual association as clues to localize sounding objects in each image. Due to the mixed property of multiple sound sources in the original space, there exist rare multi-source approaches to localizing multiple sources simultaneously, except for one recent work using a contrastive random walk in the graph with images and separated sound as nodes. Despite their promising performance, they can only handle a fixed number of sources, and they cannot learn compact class-aware representations for individual sources. To alleviate this shortcoming, in this paper, we propose a novel audio-visual grouping network, namely AVGN, that can directly learn category-wise semantic features for each source from the input audio mixture and image to localize multiple sources simultaneously. Specifically, our AVGN leverages learnable audio-visual class tokens to aggregate class-aware source features. Then, the aggregated semantic features for each source can be used as guidance to localize the corresponding visual regions. Compared to existing multi-source methods, our new framework can localize a flexible number of sources and disentangle category-aware audio-visual representations for individual sound sources. We conduct extensive experiments on MUSIC, VGGSound-Instruments, and VGG-Sound Sources benchmarks. The results demonstrate that the proposed AVGN can achieve state-of-the-art sounding object localization performance on both single-source and multi-source scenarios. Code is available at \url{https://github.com/stoneMo/AVGN}.
Domain Adaptive Semantic Segmentation by Optimal Transport
Mar 29, 2023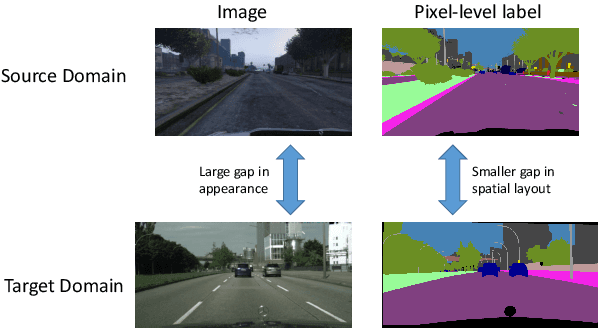
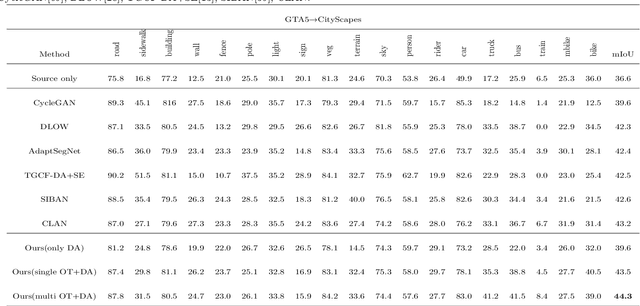
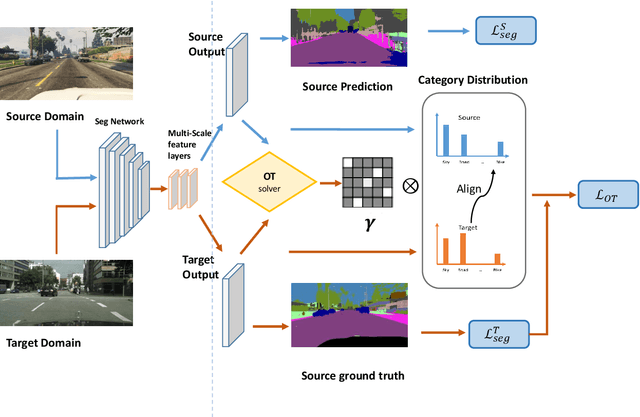
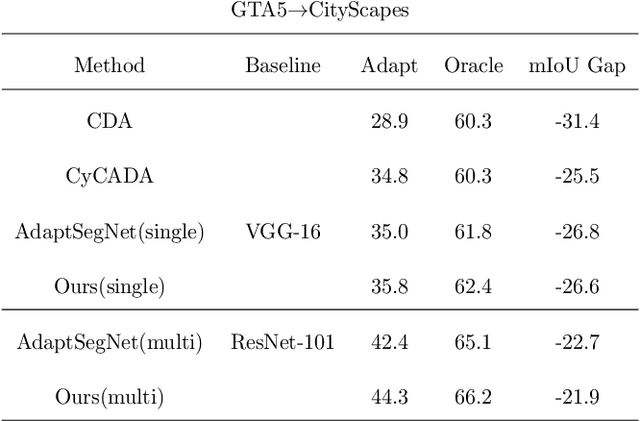
Scene segmentation is widely used in the field of autonomous driving for environment perception, and semantic scene segmentation (3S) has received a great deal of attention due to the richness of the semantic information it contains. It aims to assign labels to pixels in an image, thus enabling automatic image labeling. Current approaches are mainly based on convolutional neural networks (CNN), but they rely on a large number of labels. Therefore, how to use a small size of labeled data to achieve semantic segmentation becomes more and more important. In this paper, we propose a domain adaptation (DA) framework based on optimal transport (OT) and attention mechanism to address this issue. Concretely, first we generate the output space via CNN due to its superiority of feature representation. Second, we utilize OT to achieve a more robust alignment of source and target domains in output space, where the OT plan defines a well attention mechanism to improve the adaptation of the model. In particular, with OT, the number of network parameters has been reduced and the network has been better interpretable. Third, to better describe the multi-scale property of features, we construct a multi-scale segmentation network to perform domain adaptation. Finally, in order to verify the performance of our proposed method, we conduct experimental comparison with three benchmark and four SOTA methods on three scene datasets, and the mean intersection-over-union (mIOU) has been significant improved, and visualization results under multiple domain adaptation scenarios also show that our proposed method has better performance than compared semantic segmentation methods.