 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Source-free Domain Adaptation Requires Penalized Diversity
Apr 12, 2023
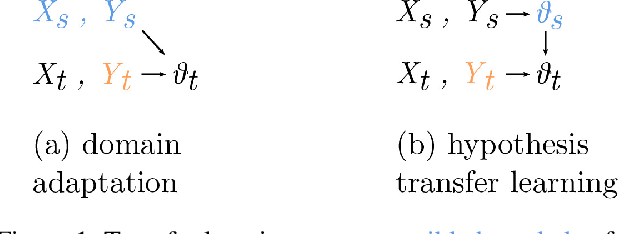
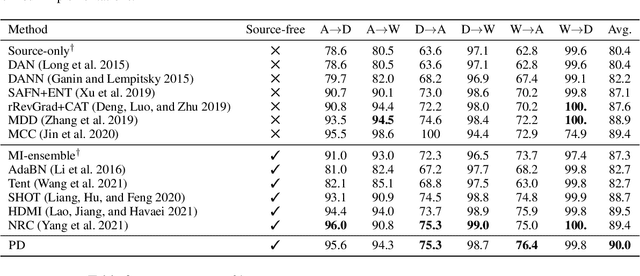
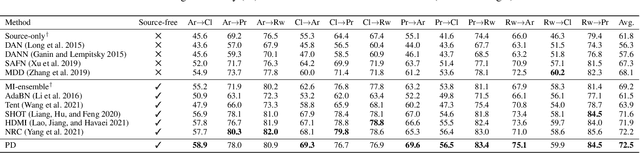
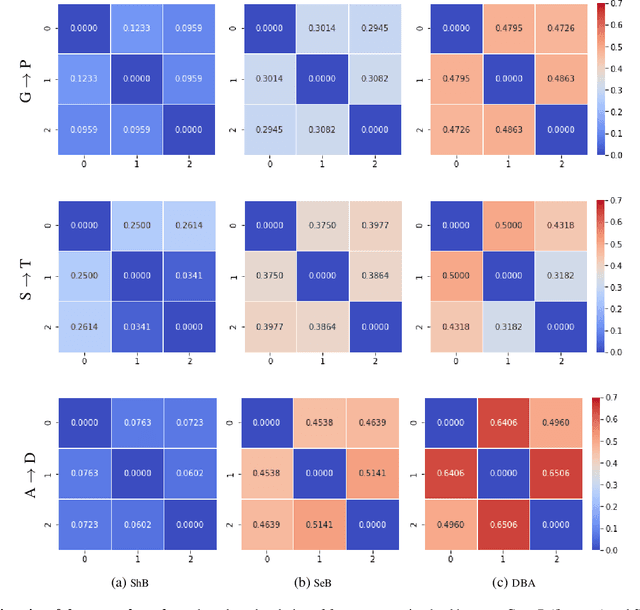
While neural networks are capable of achieving human-like performance in many tasks such as image classification, the impressive performance of each model is limited to its own dataset. Source-free domain adaptation (SFDA) was introduced to address knowledge transfer between different domains in the absence of source data, thus, increasing data privacy. Diversity in representation space can be vital to a model`s adaptability in varied and difficult domains. In unsupervised SFDA, the diversity is limited to learning a single hypothesis on the source or learning multiple hypotheses with a shared feature extractor. Motivated by the improved predictive performance of ensembles, we propose a novel unsupervised SFDA algorithm that promotes representational diversity through the use of separate feature extractors with Distinct Backbone Architectures (DBA). Although diversity in feature space is increased, the unconstrained mutual information (MI) maximization may potentially introduce amplification of weak hypotheses. Thus we introduce the Weak Hypothesis Penalization (WHP) regularizer as a mitigation strategy. Our work proposes Penalized Diversity (PD) where the synergy of DBA and WHP is applied to unsupervised source-free domain adaptation for covariate shift. In addition, PD is augmented with a weighted MI maximization objective for label distribution shift. Empirical results on natural, synthetic, and medical domains demonstrate the effectiveness of PD under different distributional shifts.
Surface-guided computing to analyze subcellular morphology and membrane-associated signals in 3D
Apr 12, 2023Signal transduction and cell function are governed by the spatiotemporal organization of membrane-associated molecules. Despite significant advances in visualizing molecular distributions by 3D light microscopy, cell biologists still have limited quantitative understanding of the processes implicated in the regulation of molecular signals at the whole cell scale. In particular, complex and transient cell surface morphologies challenge the complete sampling of cell geometry, membrane-associated molecular concentration and activity and the computing of meaningful parameters such as the cofluctuation between morphology and signals. Here, we introduce u-Unwrap3D, a framework to remap arbitrarily complex 3D cell surfaces and membrane-associated signals into equivalent lower dimensional representations. The mappings are bidirectional, allowing the application of image processing operations in the data representation best suited for the task and to subsequently present the results in any of the other representations, including the original 3D cell surface. Leveraging this surface-guided computing paradigm, we track segmented surface motifs in 2D to quantify the recruitment of Septin polymers by blebbing events; we quantify actin enrichment in peripheral ruffles; and we measure the speed of ruffle movement along topographically complex cell surfaces. Thus, u-Unwrap3D provides access to spatiotemporal analyses of cell biological parameters on unconstrained 3D surface geometries and signals.
Semantic-Aware Mixup for Domain Generalization
Apr 12, 2023
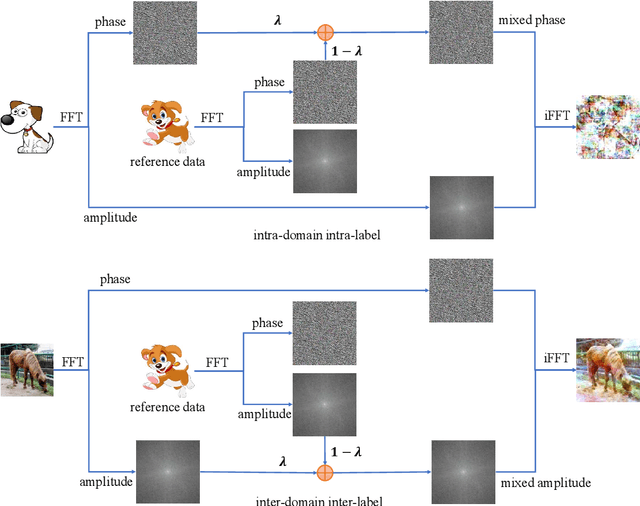


Deep neural networks (DNNs) have shown exciting performance in various tasks, yet suffer generalization failures when meeting unknown target domains. One of the most promising approaches to achieve domain generalization (DG) is generating unseen data, e.g., mixup, to cover the unknown target data. However, existing works overlook the challenges induced by the simultaneous appearance of changes in both the semantic and distribution space. Accordingly, such a challenge makes source distributions hard to fit for DNNs. To mitigate the hard-fitting issue, we propose to perform a semantic-aware mixup (SAM) for domain generalization, where whether to perform mixup depends on the semantic and domain information. The feasibility of SAM shares the same spirits with the Fourier-based mixup. Namely, the Fourier phase spectrum is expected to contain semantics information (relating to labels), while the Fourier amplitude retains other information (relating to style information). Built upon the insight, SAM applies different mixup strategies to the Fourier phase spectrum and amplitude information. For instance, SAM merely performs mixup on the amplitude spectrum when both the semantic and domain information changes. Consequently, the overwhelmingly large change can be avoided. We validate the effectiveness of SAM using image classification tasks on several DG benchmarks.
DeepSeeColor: Realtime Adaptive Color Correction for Autonomous Underwater Vehicles via Deep Learning Methods
Mar 07, 2023

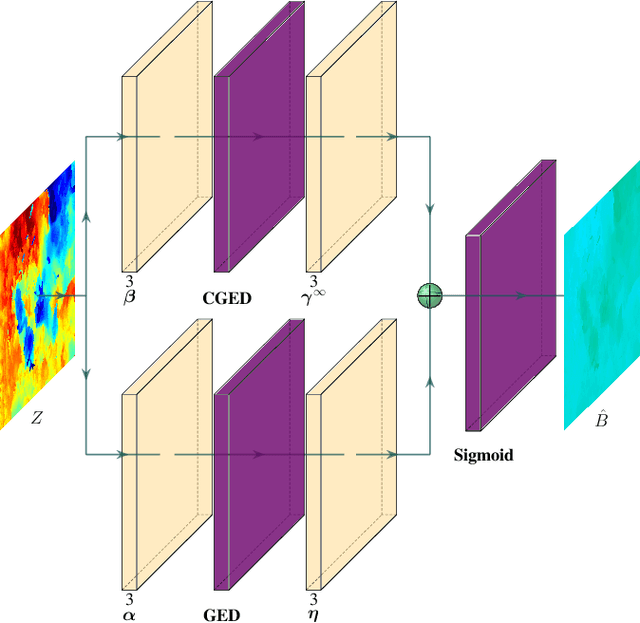
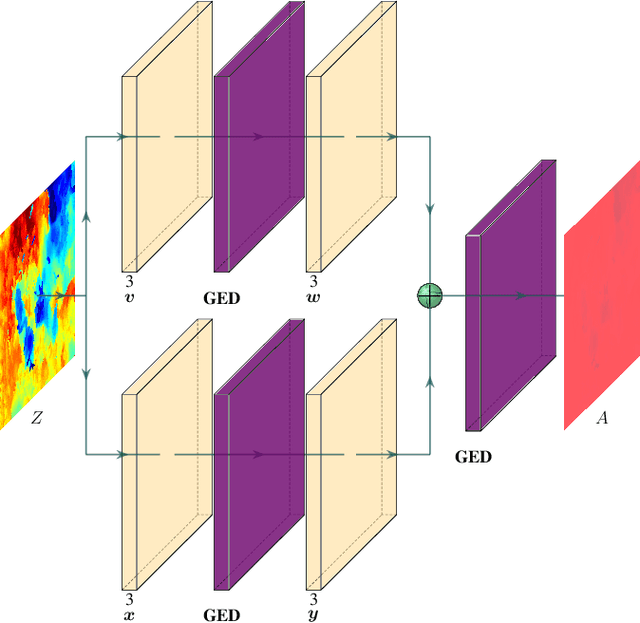
Successful applications of complex vision-based behaviours underwater have lagged behind progress in terrestrial and aerial domains. This is largely due to the degraded image quality resulting from the physical phenomena involved in underwater image formation. Spectrally-selective light attenuation drains some colors from underwater images while backscattering adds others, making it challenging to perform vision-based tasks underwater. State-of-the-art methods for underwater color correction optimize the parameters of image formation models to restore the full spectrum of color to underwater imagery. However, these methods have high computational complexity that is unfavourable for realtime use by autonomous underwater vehicles (AUVs), as a result of having been primarily designed for offline color correction. Here, we present DeepSeeColor, a novel algorithm that combines a state-of-the-art underwater image formation model with the computational efficiency of deep learning frameworks. In our experiments, we show that DeepSeeColor offers comparable performance to the popular "Sea-Thru" algorithm (Akkaynak & Treibitz, 2019) while being able to rapidly process images at up to 60Hz, thus making it suitable for use onboard AUVs as a preprocessing step to enable more robust vision-based behaviours.
Distribution Aligned Diffusion and Prototype-guided network for Unsupervised Domain Adaptive Segmentation
Mar 25, 2023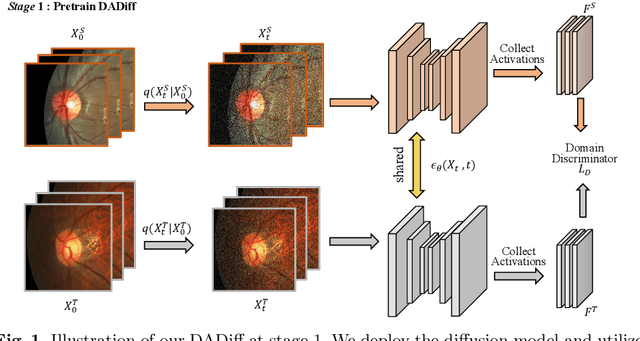
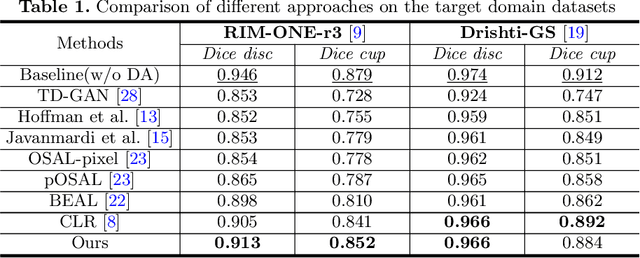
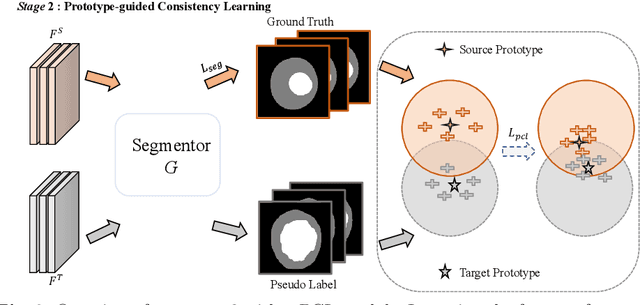
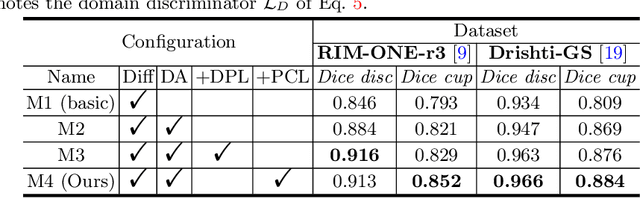
The Diffusion Probabilistic Model (DPM) has emerged as a highly effective generative model in the field of computer vision. Its intermediate latent vectors offer rich semantic information, making it an attractive option for various downstream tasks such as segmentation and detection. In order to explore its potential further, we have taken a step forward and considered a more complex scenario in the medical image domain, specifically, under an unsupervised adaptation condition. To this end, we propose a Diffusion-based and Prototype-guided network (DP-Net) for unsupervised domain adaptive segmentation. Concretely, our DP-Net consists of two stages: 1) Distribution Aligned Diffusion (DADiff), which involves training a domain discriminator to minimize the difference between the intermediate features generated by the DPM, thereby aligning the inter-domain distribution; and 2) Prototype-guided Consistency Learning (PCL), which utilizes feature centroids as prototypes and applies a prototype-guided loss to ensure that the segmentor learns consistent content from both source and target domains. Our approach is evaluated on fundus datasets through a series of experiments, which demonstrate that the performance of the proposed method is reliable and outperforms state-of-the-art methods. Our work presents a promising direction for using DPM in complex medical image scenarios, opening up new possibilities for further research in medical imaging.
Non-pooling Network for medical image segmentation
Feb 21, 2023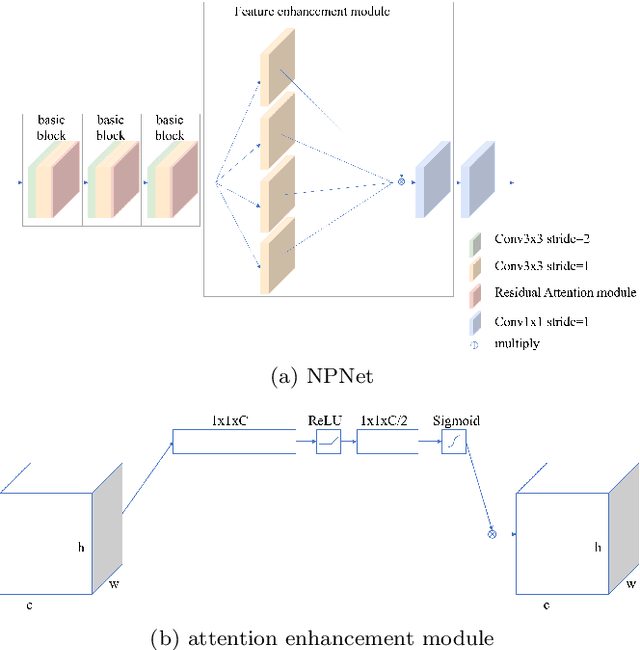
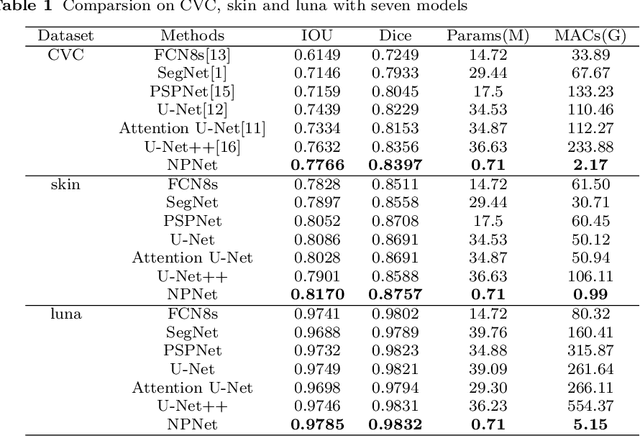
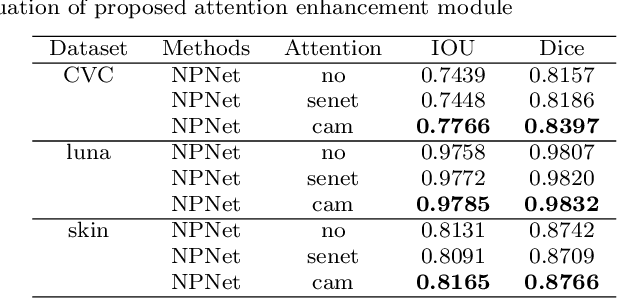
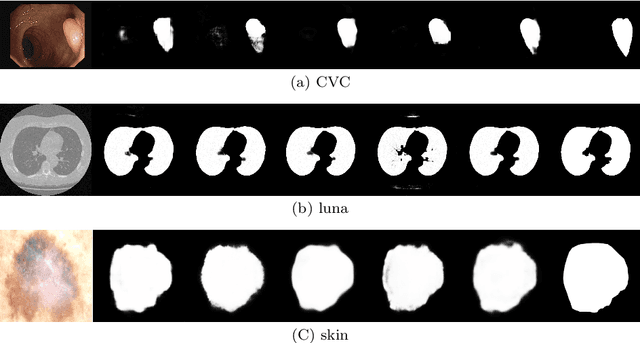
Existing studies tend tofocus onmodel modifications and integration with higher accuracy, which improve performance but also carry huge computational costs, resulting in longer detection times. Inmedical imaging, the use of time is extremely sensitive. And at present most of the semantic segmentation models have encoder-decoder structure or double branch structure. Their several times of the pooling use with high-level semantic information extraction operation cause information loss although there si a reverse pooling or other similar action to restore information loss of pooling operation. In addition, we notice that visual attention mechanism has superior performance on a variety of tasks. Given this, this paper proposes non-pooling network(NPNet), non-pooling commendably reduces the loss of information and attention enhancement m o d u l e ( A M ) effectively increases the weight of useful information. The method greatly reduces the number of parametersand computation costs by the shallow neural network structure. We evaluate the semantic segmentation model of our NPNet on three benchmark datasets comparing w i t h multiple current state-of-the-art(SOTA) models, and the implementation results show thatour NPNetachieves SOTA performance, with an excellent balance between accuracyand speed.
Medical visual question answering using joint self-supervised learning
Feb 25, 2023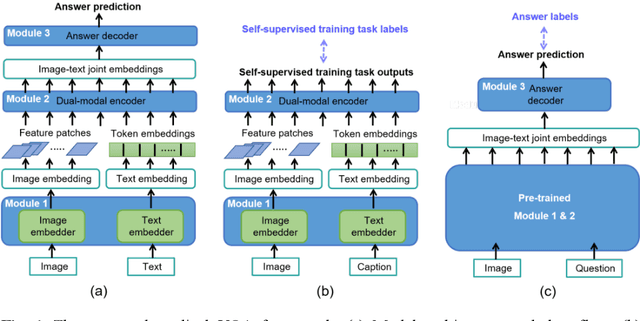

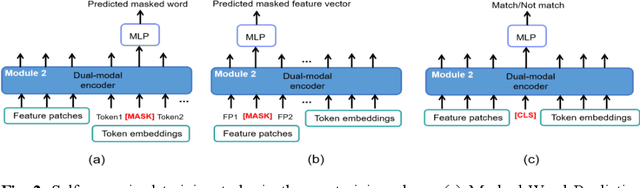
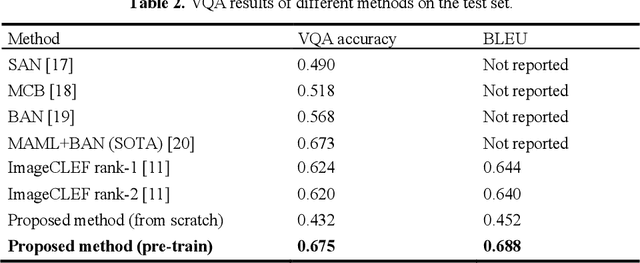
Visual Question Answering (VQA) becomes one of the most active research problems in the medical imaging domain. A well-known VQA challenge is the intrinsic diversity between the image and text modalities, and in the medical VQA task, there is another critical problem relying on the limited size of labelled image-question-answer data. In this study we propose an encoder-decoder framework that leverages the image-text joint representation learned from large-scaled medical image-caption data and adapted to the small-sized medical VQA task. The encoder embeds across the image-text dual modalities with self-attention mechanism and is independently pre-trained on the large-scaled medical image-caption dataset by multiple self-supervised learning tasks. Then the decoder is connected to the top of the encoder and fine-tuned using the small-sized medical VQA dataset. The experiment results present that our proposed method achieves better performance comparing with the baseline and SOTA methods.
Optimizing Prompts for Text-to-Image Generation
Dec 19, 2022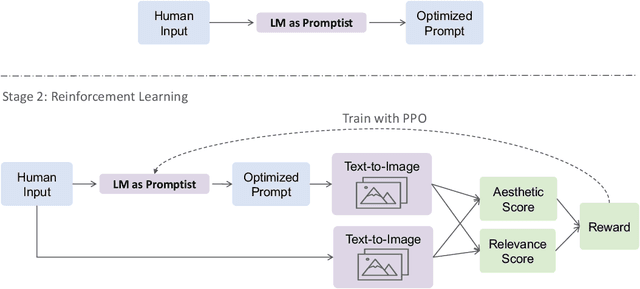
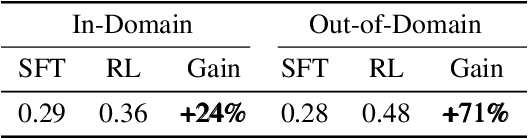
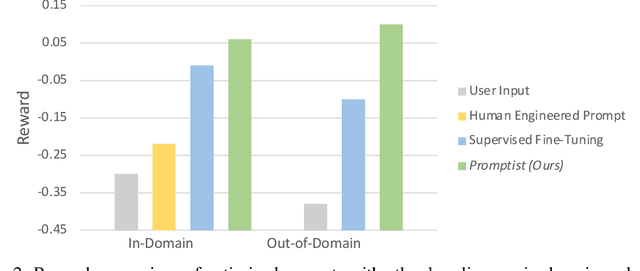

Well-designed prompts can guide text-to-image models to generate amazing images. However, the performant prompts are often model-specific and misaligned with user input. Instead of laborious human engineering, we propose prompt adaptation, a general framework that automatically adapts original user input to model-preferred prompts. Specifically, we first perform supervised fine-tuning with a pretrained language model on a small collection of manually engineered prompts. Then we use reinforcement learning to explore better prompts. We define a reward function that encourages the policy to generate more aesthetically pleasing images while preserving the original user intentions. Experimental results on Stable Diffusion show that our method outperforms manual prompt engineering in terms of both automatic metrics and human preference ratings. Moreover, reinforcement learning further boosts performance, especially on out-of-domain prompts. The pretrained checkpoints are available at https://aka.ms/promptist. The demo can be found at https://aka.ms/promptist-demo.
RenderDiffusion: Image Diffusion for 3D Reconstruction, Inpainting and Generation
Nov 17, 2022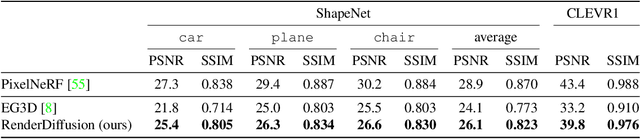
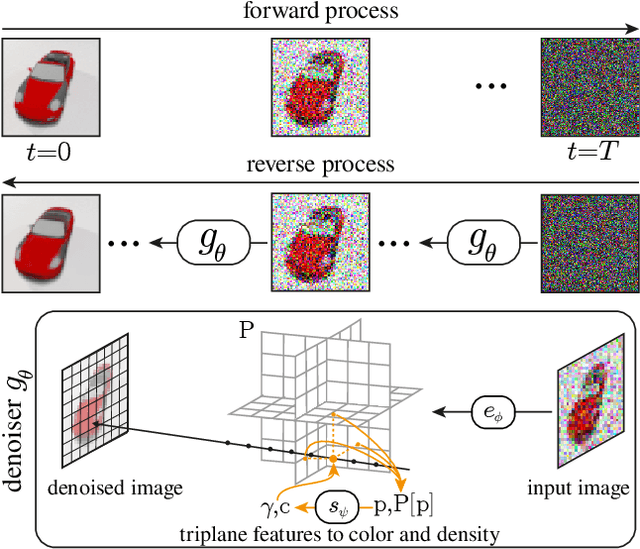

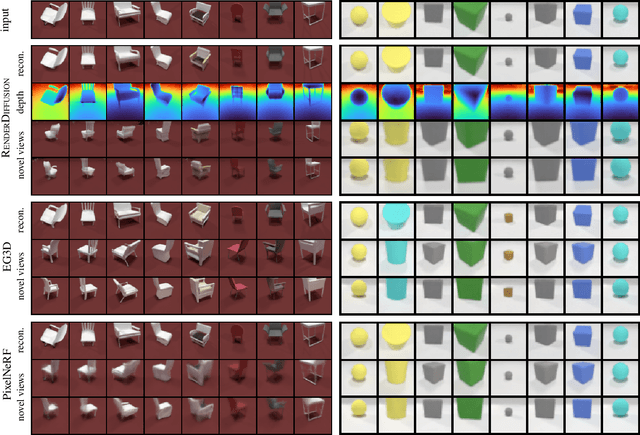
Diffusion models currently achieve state-of-the-art performance for both conditional and unconditional image generation. However, so far, image diffusion models do not support tasks required for 3D understanding, such as view-consistent 3D generation or single-view object reconstruction. In this paper, we present RenderDiffusion as the first diffusion model for 3D generation and inference that can be trained using only monocular 2D supervision. At the heart of our method is a novel image denoising architecture that generates and renders an intermediate three-dimensional representation of a scene in each denoising step. This enforces a strong inductive structure into the diffusion process that gives us a 3D consistent representation while only requiring 2D supervision. The resulting 3D representation can be rendered from any viewpoint. We evaluate RenderDiffusion on ShapeNet and Clevr datasets and show competitive performance for generation of 3D scenes and inference of 3D scenes from 2D images. Additionally, our diffusion-based approach allows us to use 2D inpainting to edit 3D scenes. We believe that our work promises to enable full 3D generation at scale when trained on massive image collections, thus circumventing the need to have large-scale 3D model collections for supervision.
MIC: Masked Image Consistency for Context-Enhanced Domain Adaptation
Dec 02, 2022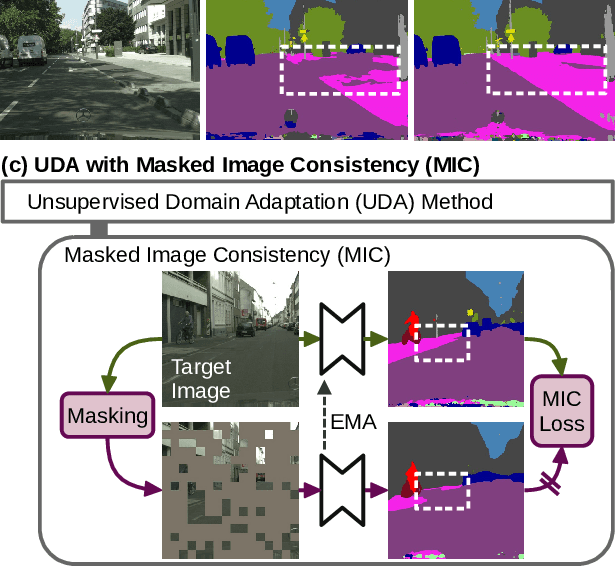
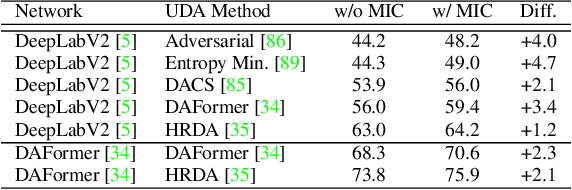
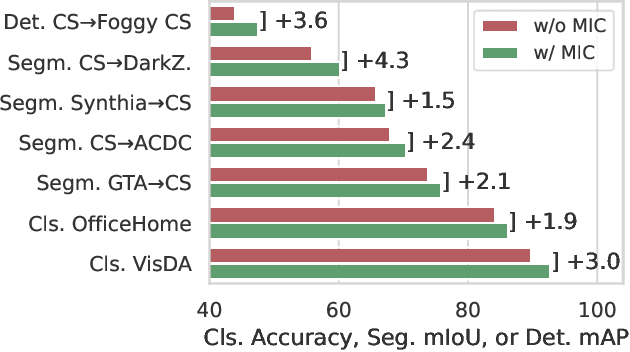
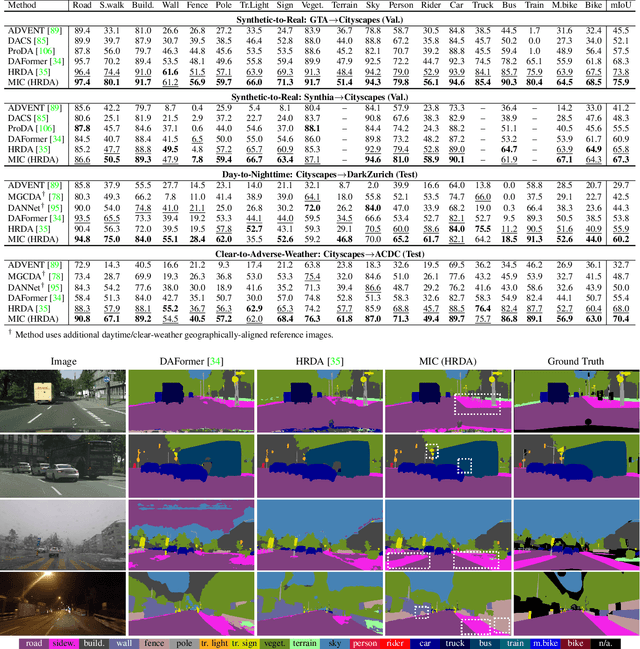
In unsupervised domain adaptation (UDA), a model trained on source data (e.g. synthetic) is adapted to target data (e.g. real-world) without access to target annotation. Most previous UDA methods struggle with classes that have a similar visual appearance on the target domain as no ground truth is available to learn the slight appearance differences. To address this problem, we propose a Masked Image Consistency (MIC) module to enhance UDA by learning spatial context relations of the target domain as additional clues for robust visual recognition. MIC enforces the consistency between predictions of masked target images, where random patches are withheld, and pseudo-labels that are generated based on the complete image by an exponential moving average teacher. To minimize the consistency loss, the network has to learn to infer the predictions of the masked regions from their context. Due to its simple and universal concept, MIC can be integrated into various UDA methods across different visual recognition tasks such as image classification, semantic segmentation, and object detection. MIC significantly improves the state-of-the-art performance across the different recognition tasks for synthetic-to-real, day-to-nighttime, and clear-to-adverse-weather UDA. For instance, MIC achieves an unprecedented UDA performance of 75.9 mIoU and 92.8% on GTA-to-Cityscapes and VisDA-2017, respectively, which corresponds to an improvement of +2.1 and +3.0 percent points over the previous state of the art. The implementation is available at https://github.com/lhoyer/MIC.