 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Unsupervised Traffic Scene Generation with Synthetic 3D Scene Graphs
Mar 15, 2023

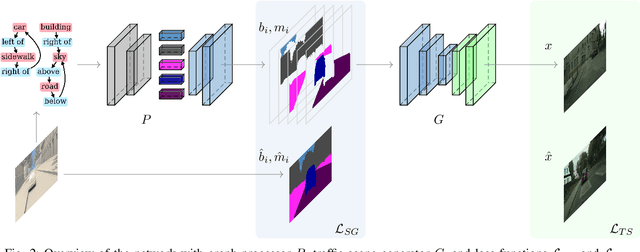
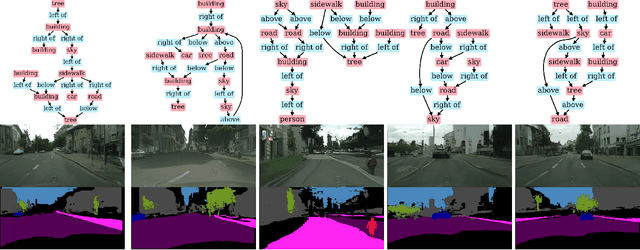
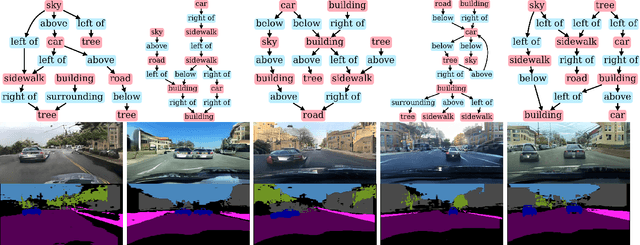
Image synthesis driven by computer graphics achieved recently a remarkable realism, yet synthetic image data generated this way reveals a significant domain gap with respect to real-world data. This is especially true in autonomous driving scenarios, which represent a critical aspect for overcoming utilizing synthetic data for training neural networks. We propose a method based on domain-invariant scene representation to directly synthesize traffic scene imagery without rendering. Specifically, we rely on synthetic scene graphs as our internal representation and introduce an unsupervised neural network architecture for realistic traffic scene synthesis. We enhance synthetic scene graphs with spatial information about the scene and demonstrate the effectiveness of our approach through scene manipulation.
Learning 3D Representations from 2D Pre-trained Models via Image-to-Point Masked Autoencoders
Dec 13, 2022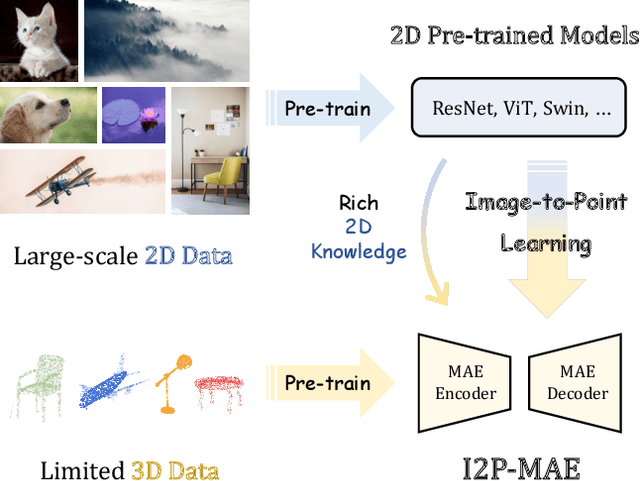
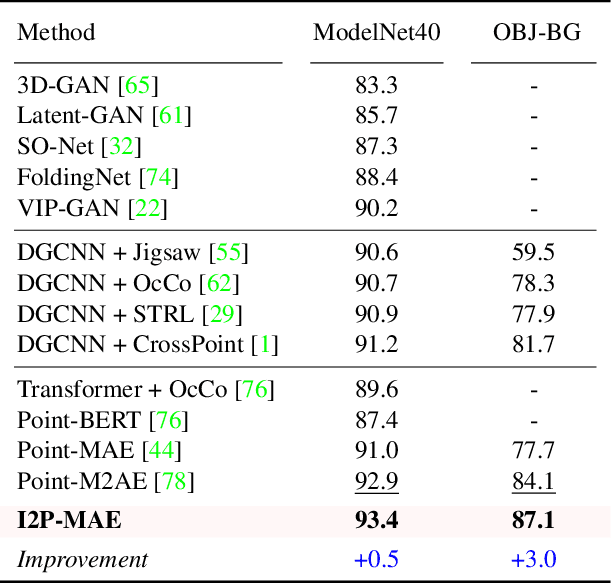
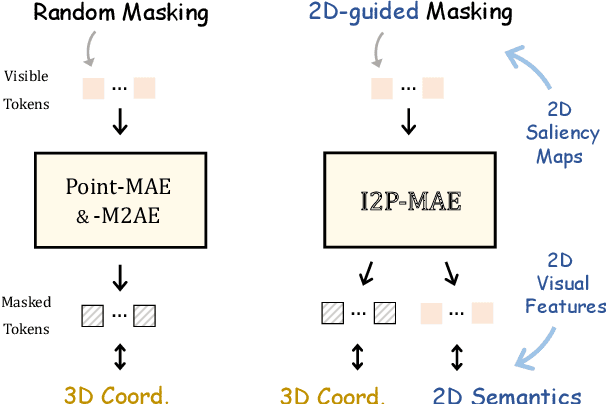
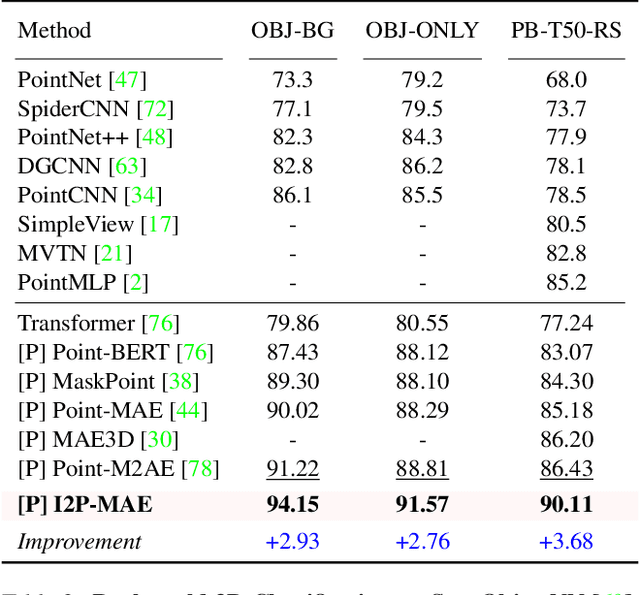
Pre-training by numerous image data has become de-facto for robust 2D representations. In contrast, due to the expensive data acquisition and annotation, a paucity of large-scale 3D datasets severely hinders the learning for high-quality 3D features. In this paper, we propose an alternative to obtain superior 3D representations from 2D pre-trained models via Image-to-Point Masked Autoencoders, named as I2P-MAE. By self-supervised pre-training, we leverage the well learned 2D knowledge to guide 3D masked autoencoding, which reconstructs the masked point tokens with an encoder-decoder architecture. Specifically, we first utilize off-the-shelf 2D models to extract the multi-view visual features of the input point cloud, and then conduct two types of image-to-point learning schemes on top. For one, we introduce a 2D-guided masking strategy that maintains semantically important point tokens to be visible for the encoder. Compared to random masking, the network can better concentrate on significant 3D structures and recover the masked tokens from key spatial cues. For another, we enforce these visible tokens to reconstruct the corresponding multi-view 2D features after the decoder. This enables the network to effectively inherit high-level 2D semantics learned from rich image data for discriminative 3D modeling. Aided by our image-to-point pre-training, the frozen I2P-MAE, without any fine-tuning, achieves 93.4% accuracy for linear SVM on ModelNet40, competitive to the fully trained results of existing methods. By further fine-tuning on on ScanObjectNN's hardest split, I2P-MAE attains the state-of-the-art 90.11% accuracy, +3.68% to the second-best, demonstrating superior transferable capacity. Code will be available at https://github.com/ZrrSkywalker/I2P-MAE.
Learnable Graph Matching: A Practical Paradigm for Data Association
Mar 27, 2023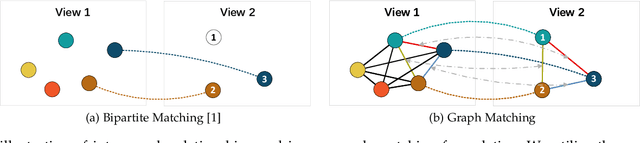
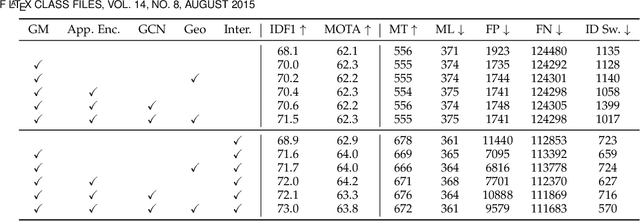
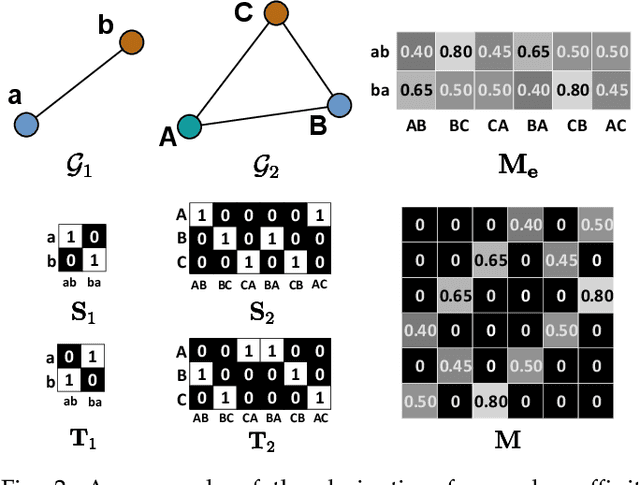

Data association is at the core of many computer vision tasks, e.g., multiple object tracking, image matching, and point cloud registration. Existing methods usually solve the data association problem by network flow optimization, bipartite matching, or end-to-end learning directly. Despite their popularity, we find some defects of the current solutions: they mostly ignore the intra-view context information; besides, they either train deep association models in an end-to-end way and hardly utilize the advantage of optimization-based assignment methods, or only use an off-the-shelf neural network to extract features. In this paper, we propose a general learnable graph matching method to address these issues. Especially, we model the intra-view relationships as an undirected graph. Then data association turns into a general graph matching problem between graphs. Furthermore, to make optimization end-to-end differentiable, we relax the original graph matching problem into continuous quadratic programming and then incorporate training into a deep graph neural network with KKT conditions and implicit function theorem. In MOT task, our method achieves state-of-the-art performance on several MOT datasets. For image matching, our method outperforms state-of-the-art methods with half training data and iterations on a popular indoor dataset, ScanNet. Code will be available at https://github.com/jiaweihe1996/GMTracker.
Classifier Robustness Enhancement Via Test-Time Transformation
Mar 27, 2023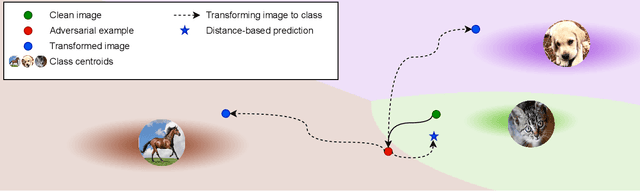
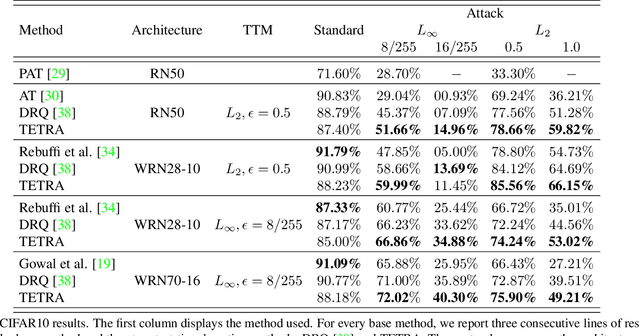

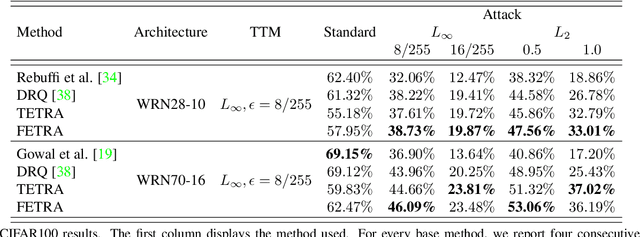
It has been recently discovered that adversarially trained classifiers exhibit an intriguing property, referred to as perceptually aligned gradients (PAG). PAG implies that the gradients of such classifiers possess a meaningful structure, aligned with human perception. Adversarial training is currently the best-known way to achieve classification robustness under adversarial attacks. The PAG property, however, has yet to be leveraged for further improving classifier robustness. In this work, we introduce Classifier Robustness Enhancement Via Test-Time Transformation (TETRA) -- a novel defense method that utilizes PAG, enhancing the performance of trained robust classifiers. Our method operates in two phases. First, it modifies the input image via a designated targeted adversarial attack into each of the dataset's classes. Then, it classifies the input image based on the distance to each of the modified instances, with the assumption that the shortest distance relates to the true class. We show that the proposed method achieves state-of-the-art results and validate our claim through extensive experiments on a variety of defense methods, classifier architectures, and datasets. We also empirically demonstrate that TETRA can boost the accuracy of any differentiable adversarial training classifier across a variety of attacks, including ones unseen at training. Specifically, applying TETRA leads to substantial improvement of up to $+23\%$, $+20\%$, and $+26\%$ on CIFAR10, CIFAR100, and ImageNet, respectively.
VideoFusion: Decomposed Diffusion Models for High-Quality Video Generation
Mar 22, 2023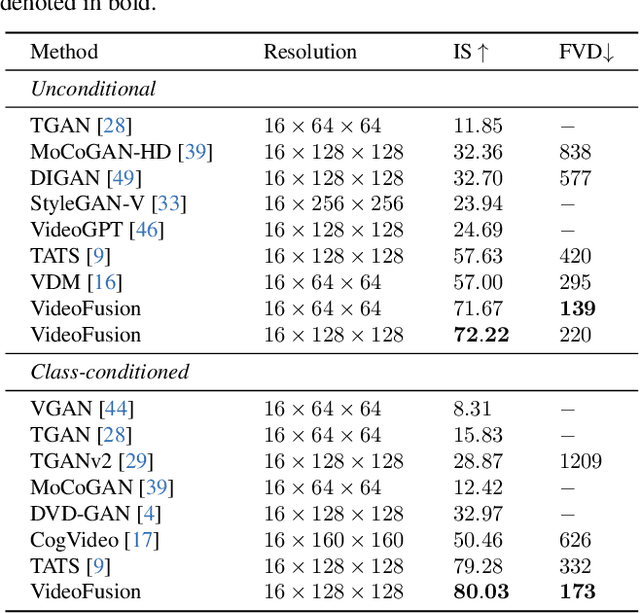


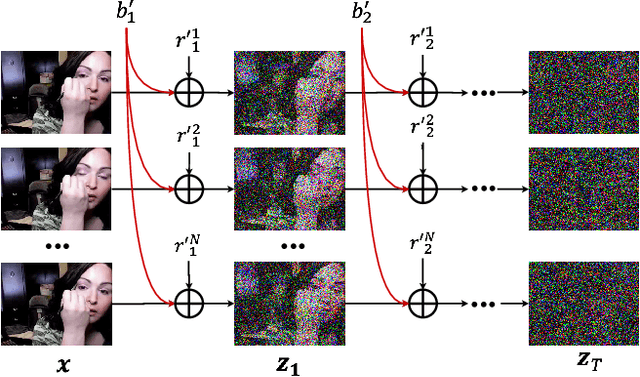
A diffusion probabilistic model (DPM), which constructs a forward diffusion process by gradually adding noise to data points and learns the reverse denoising process to generate new samples, has been shown to handle complex data distribution. Despite its recent success in image synthesis, applying DPMs to video generation is still challenging due to high-dimensional data spaces. Previous methods usually adopt a standard diffusion process, where frames in the same video clip are destroyed with independent noises, ignoring the content redundancy and temporal correlation. This work presents a decomposed diffusion process via resolving the per-frame noise into a base noise that is shared among all frames and a residual noise that varies along the time axis. The denoising pipeline employs two jointly-learned networks to match the noise decomposition accordingly. Experiments on various datasets confirm that our approach, termed as VideoFusion, surpasses both GAN-based and diffusion-based alternatives in high-quality video generation. We further show that our decomposed formulation can benefit from pre-trained image diffusion models and well-support text-conditioned video creation.
EVA-02: A Visual Representation for Neon Genesis
Mar 22, 2023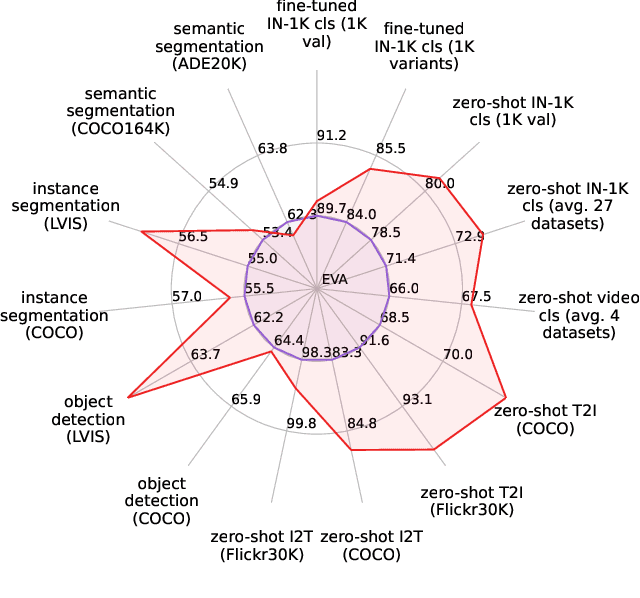

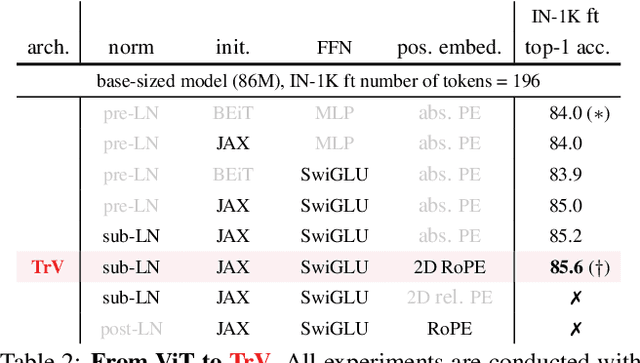
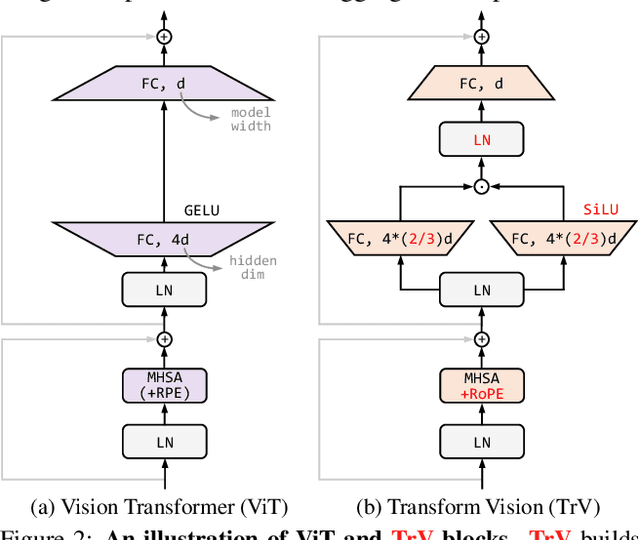
We launch EVA-02, a next-generation Transformer-based visual representation pre-trained to reconstruct strong and robust language-aligned vision features via masked image modeling. With an updated plain Transformer architecture as well as extensive pre-training from an open & accessible giant CLIP vision encoder, EVA-02 demonstrates superior performance compared to prior state-of-the-art approaches across various representative vision tasks, while utilizing significantly fewer parameters and compute budgets. Notably, using exclusively publicly accessible training data, EVA-02 with only 304M parameters achieves a phenomenal 90.0 fine-tuning top-1 accuracy on ImageNet-1K val set. Additionally, our EVA-02-CLIP can reach up to 80.4 zero-shot top-1 on ImageNet-1K, outperforming the previous largest & best open-sourced CLIP with only ~1/6 parameters and ~1/6 image-text training data. We offer four EVA-02 variants in various model sizes, ranging from 6M to 304M parameters, all with impressive performance. To facilitate open access and open research, we release the complete suite of EVA-02 to the community at https://github.com/baaivision/EVA/tree/master/EVA-02.
360BEV: Panoramic Semantic Mapping for Indoor Bird's-Eye View
Mar 22, 2023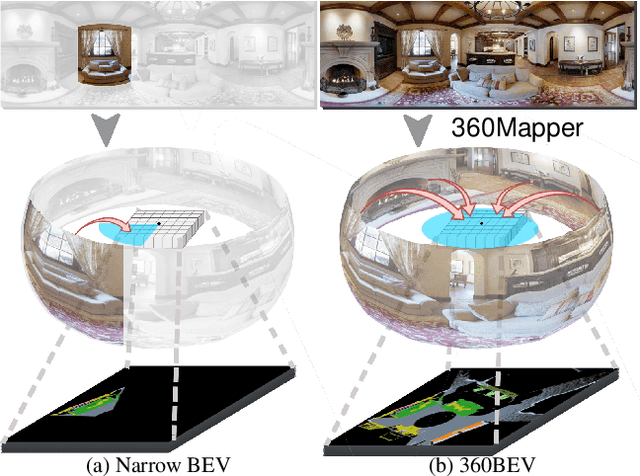
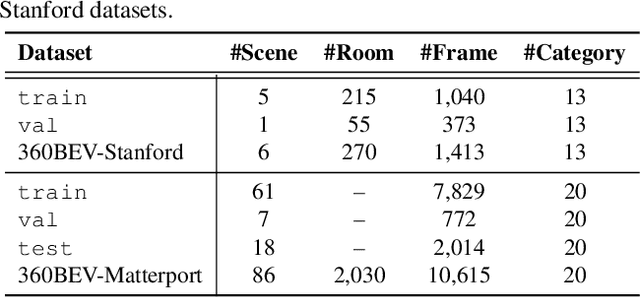
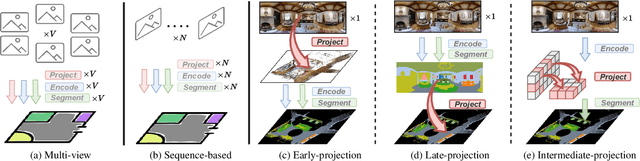
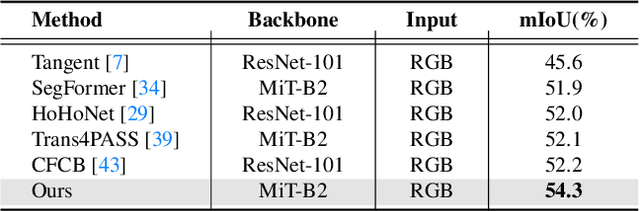
Seeing only a tiny part of the whole is not knowing the full circumstance. Bird's-eye-view (BEV) perception, a process of obtaining allocentric maps from egocentric views, is restricted when using a narrow Field of View (FoV) alone. In this work, mapping from 360{\deg} panoramas to BEV semantics, the 360BEV task, is established for the first time to achieve holistic representations of indoor scenes in a top-down view. Instead of relying on narrow-FoV image sequences, a panoramic image with depth information is sufficient to generate a holistic BEV semantic map. To benchmark 360BEV, we present two indoor datasets, 360BEV-Matterport and 360BEV-Stanford, both of which include egocentric panoramic images and semantic segmentation labels, as well as allocentric semantic maps. Besides delving deep into different mapping paradigms, we propose a dedicated solution for panoramic semantic mapping, namely 360Mapper. Through extensive experiments, our methods achieve 44.32% and 45.78% in mIoU on both datasets respectively, surpassing previous counterparts with gains of +7.60% and +9.70% in mIoU. Code and datasets will be available at: https://jamycheung.github.io/360BEV.html.
VecFontSDF: Learning to Reconstruct and Synthesize High-quality Vector Fonts via Signed Distance Functions
Mar 22, 2023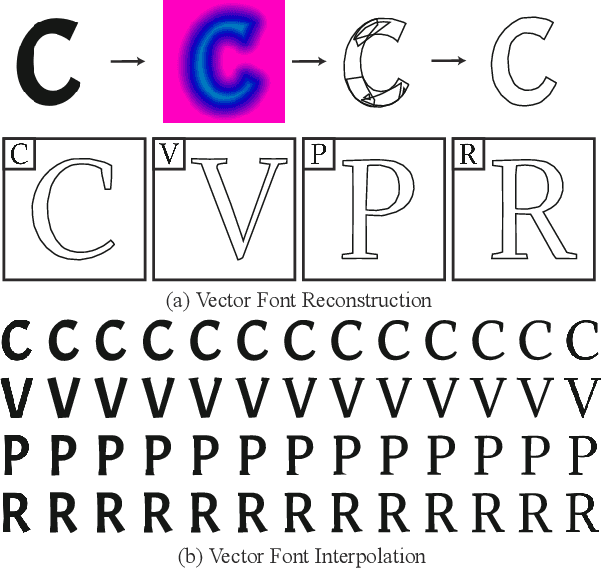
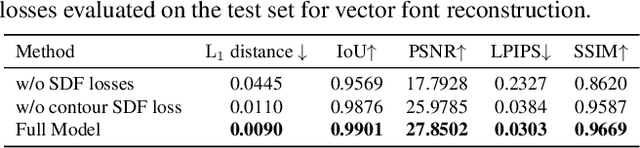
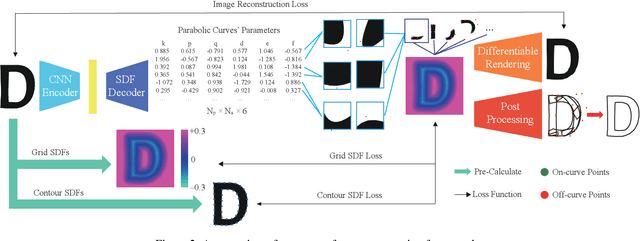
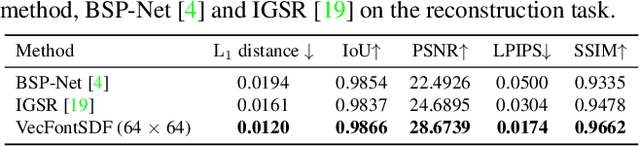
Font design is of vital importance in the digital content design and modern printing industry. Developing algorithms capable of automatically synthesizing vector fonts can significantly facilitate the font design process. However, existing methods mainly concentrate on raster image generation, and only a few approaches can directly synthesize vector fonts. This paper proposes an end-to-end trainable method, VecFontSDF, to reconstruct and synthesize high-quality vector fonts using signed distance functions (SDFs). Specifically, based on the proposed SDF-based implicit shape representation, VecFontSDF learns to model each glyph as shape primitives enclosed by several parabolic curves, which can be precisely converted to quadratic B\'ezier curves that are widely used in vector font products. In this manner, most image generation methods can be easily extended to synthesize vector fonts. Qualitative and quantitative experiments conducted on a publicly-available dataset demonstrate that our method obtains high-quality results on several tasks, including vector font reconstruction, interpolation, and few-shot vector font synthesis, markedly outperforming the state of the art.
Make Encoder Great Again in 3D GAN Inversion through Geometry and Occlusion-Aware Encoding
Mar 22, 2023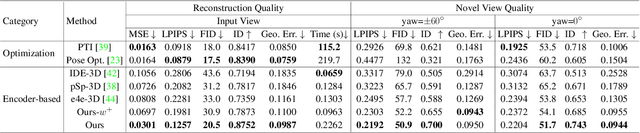
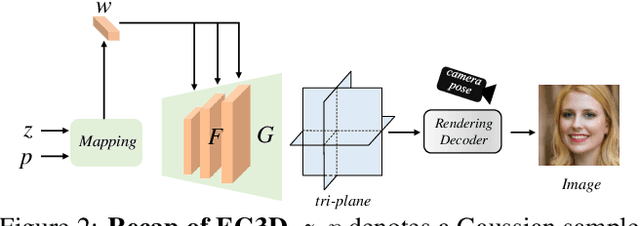


3D GAN inversion aims to achieve high reconstruction fidelity and reasonable 3D geometry simultaneously from a single image input. However, existing 3D GAN inversion methods rely on time-consuming optimization for each individual case. In this work, we introduce a novel encoder-based inversion framework based on EG3D, one of the most widely-used 3D GAN models. We leverage the inherent properties of EG3D's latent space to design a discriminator and a background depth regularization. This enables us to train a geometry-aware encoder capable of converting the input image into corresponding latent code. Additionally, we explore the feature space of EG3D and develop an adaptive refinement stage that improves the representation ability of features in EG3D to enhance the recovery of fine-grained textural details. Finally, we propose an occlusion-aware fusion operation to prevent distortion in unobserved regions. Our method achieves impressive results comparable to optimization-based methods while operating up to 500 times faster. Our framework is well-suited for applications such as semantic editing.
Spatial-Aware Token for Weakly Supervised Object Localization
Mar 18, 2023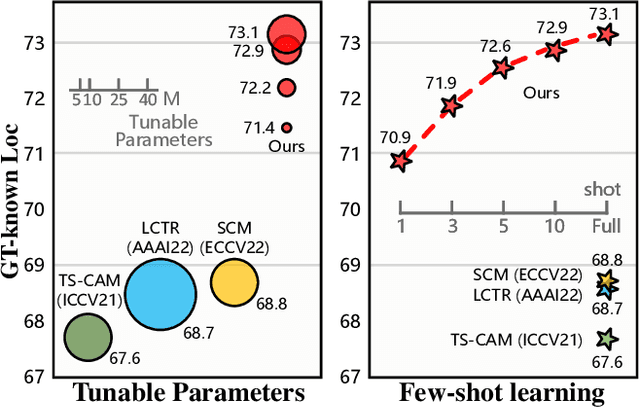
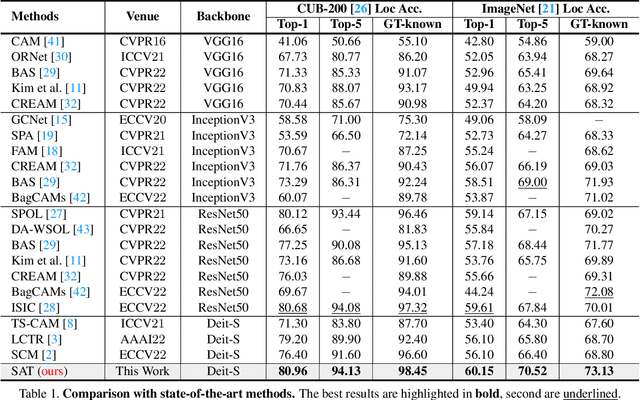
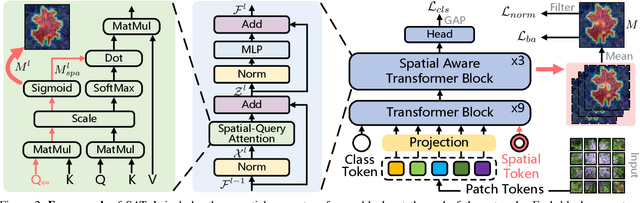
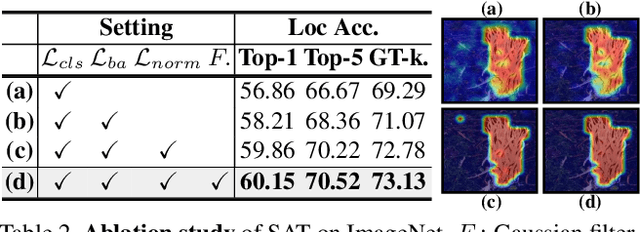
Weakly supervised object localization (WSOL) is a challenging task aiming to localize objects with only image-level supervision. Recent works apply visual transformer to WSOL and achieve significant success by exploiting the long-range feature dependency in self-attention mechanism. However, existing transformer-based methods synthesize the classification feature maps as the localization map, which leads to optimization conflicts between classification and localization tasks. To address this problem, we propose to learn a task-specific spatial-aware token (SAT) to condition localization in a weakly supervised manner. Specifically, a spatial token is first introduced in the input space to aggregate representations for localization task. Then a spatial aware attention module is constructed, which allows spatial token to generate foreground probabilities of different patches by querying and to extract localization knowledge from the classification task. Besides, for the problem of sparse and unbalanced pixel-level supervision obtained from the image-level label, two spatial constraints, including batch area loss and normalization loss, are designed to compensate and enhance this supervision. Experiments show that the proposed SAT achieves state-of-the-art performance on both CUB-200 and ImageNet, with 98.45% and 73.13% GT-known Loc, respectively. Even under the extreme setting of using only 1 image per class from ImageNet for training, SAT already exceeds the SOTA method by 2.1% GT-known Loc. Code and models are available at https://github.com/wpy1999/SAT.