 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
OTAvatar: One-shot Talking Face Avatar with Controllable Tri-plane Rendering
Mar 26, 2023
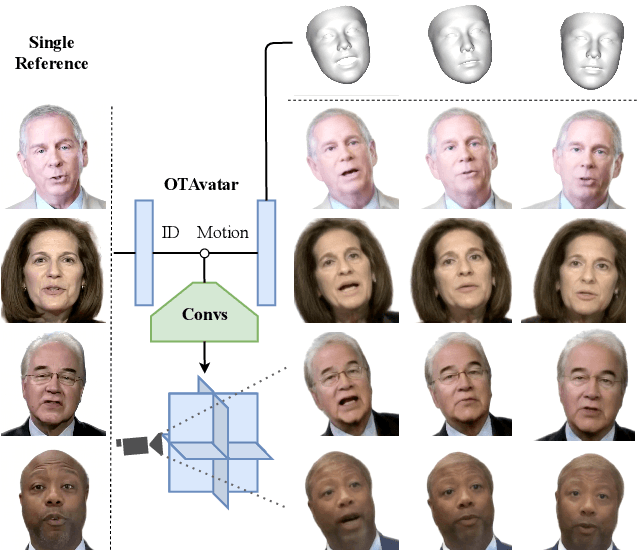

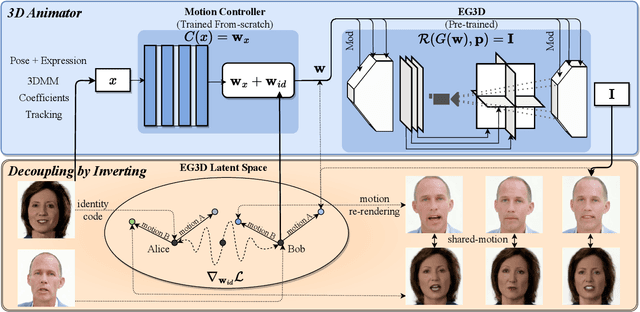

Controllability, generalizability and efficiency are the major objectives of constructing face avatars represented by neural implicit field. However, existing methods have not managed to accommodate the three requirements simultaneously. They either focus on static portraits, restricting the representation ability to a specific subject, or suffer from substantial computational cost, limiting their flexibility. In this paper, we propose One-shot Talking face Avatar (OTAvatar), which constructs face avatars by a generalized controllable tri-plane rendering solution so that each personalized avatar can be constructed from only one portrait as the reference. Specifically, OTAvatar first inverts a portrait image to a motion-free identity code. Second, the identity code and a motion code are utilized to modulate an efficient CNN to generate a tri-plane formulated volume, which encodes the subject in the desired motion. Finally, volume rendering is employed to generate an image in any view. The core of our solution is a novel decoupling-by-inverting strategy that disentangles identity and motion in the latent code via optimization-based inversion. Benefiting from the efficient tri-plane representation, we achieve controllable rendering of generalized face avatar at $35$ FPS on A100. Experiments show promising performance of cross-identity reenactment on subjects out of the training set and better 3D consistency.
Soft labelling for semantic segmentation: Bringing coherence to label down-sampling
Mar 08, 2023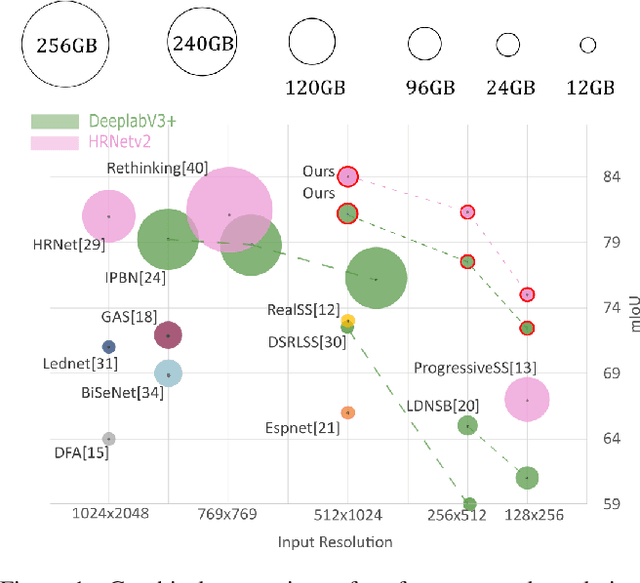


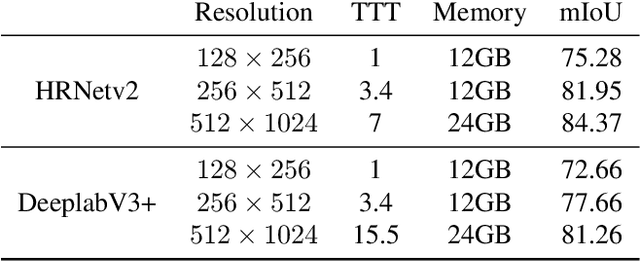
In semantic segmentation, training data down-sampling is commonly performed due to limited resources, the need to adapt image size to the model input, or improve data augmentation. This down-sampling typically employs different strategies for the image data and the annotated labels. Such discrepancy leads to mismatches between the down-sampled color and label images. Hence, the training performance significantly decreases as the down-sampling factor increases. In this paper, we bring together the down-sampling strategies for the image data and the training labels. To that aim, we propose a novel framework for label down-sampling via soft-labeling that better conserves label information after down-sampling. Therefore, fully aligning soft-labels with image data to keep the distribution of the sampled pixels. This proposal also produces reliable annotations for under-represented semantic classes. Altogether, it allows training competitive models at lower resolutions. Experiments show that the proposal outperforms other down-sampling strategies. Moreover, state-of-the-art performance is achieved for reference benchmarks, but employing significantly less computational resources than foremost approaches. This proposal enables competitive research for semantic segmentation under resource constraints.
A Dual-branch Self-supervised Representation Learning Framework for Tumour Segmentation in Whole Slide Images
Mar 20, 2023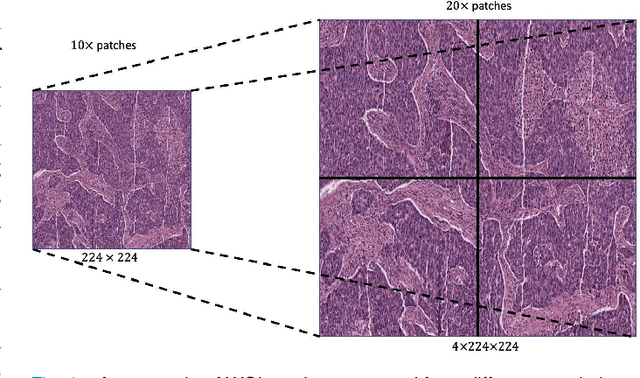
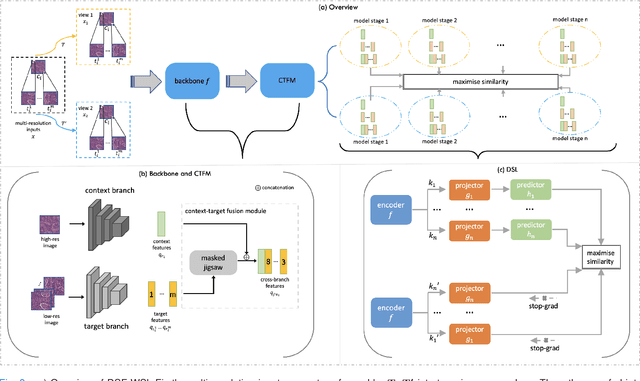
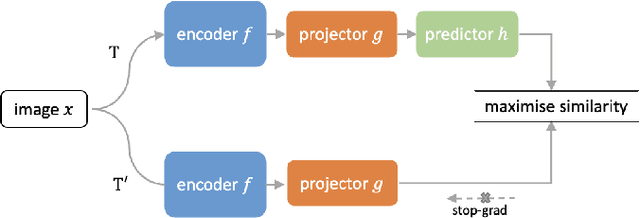
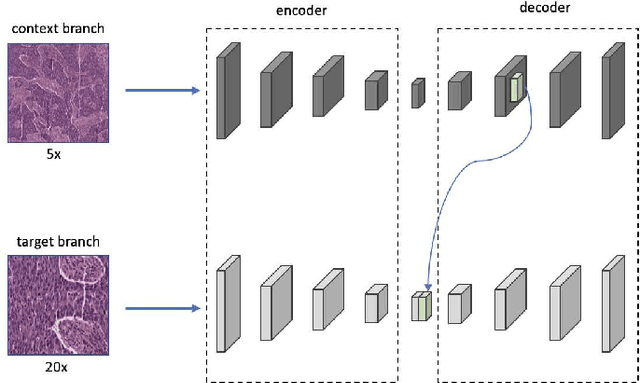
Supervised deep learning methods have achieved considerable success in medical image analysis, owing to the availability of large-scale and well-annotated datasets. However, creating such datasets for whole slide images (WSIs) in histopathology is a challenging task due to their gigapixel size. In recent years, self-supervised learning (SSL) has emerged as an alternative solution to reduce the annotation overheads in WSIs, as it does not require labels for training. These SSL approaches, however, are not designed for handling multi-resolution WSIs, which limits their performance in learning discriminative image features. In this paper, we propose a Dual-branch SSL Framework for WSI tumour segmentation (DSF-WSI) that can effectively learn image features from multi-resolution WSIs. Our DSF-WSI connected two branches and jointly learnt low and high resolution WSIs in a self-supervised manner. Moreover, we introduced a novel Context-Target Fusion Module (CTFM) and a masked jigsaw pretext task to align the learnt multi-resolution features. Furthermore, we designed a Dense SimSiam Learning (DSL) strategy to maximise the similarity of different views of WSIs, enabling the learnt representations to be more efficient and discriminative. We evaluated our method using two public datasets on breast and liver cancer segmentation tasks. The experiment results demonstrated that our DSF-WSI can effectively extract robust and efficient representations, which we validated through subsequent fine-tuning and semi-supervised settings. Our proposed method achieved better accuracy than other state-of-the-art approaches. Code is available at https://github.com/Dylan-H-Wang/dsf-wsi.
k-SALSA: k-anonymous synthetic averaging of retinal images via local style alignment
Mar 20, 2023The application of modern machine learning to retinal image analyses offers valuable insights into a broad range of human health conditions beyond ophthalmic diseases. Additionally, data sharing is key to fully realizing the potential of machine learning models by providing a rich and diverse collection of training data. However, the personally-identifying nature of retinal images, encompassing the unique vascular structure of each individual, often prevents this data from being shared openly. While prior works have explored image de-identification strategies based on synthetic averaging of images in other domains (e.g. facial images), existing techniques face difficulty in preserving both privacy and clinical utility in retinal images, as we demonstrate in our work. We therefore introduce k-SALSA, a generative adversarial network (GAN)-based framework for synthesizing retinal fundus images that summarize a given private dataset while satisfying the privacy notion of k-anonymity. k-SALSA brings together state-of-the-art techniques for training and inverting GANs to achieve practical performance on retinal images. Furthermore, k-SALSA leverages a new technique, called local style alignment, to generate a synthetic average that maximizes the retention of fine-grain visual patterns in the source images, thus improving the clinical utility of the generated images. On two benchmark datasets of diabetic retinopathy (EyePACS and APTOS), we demonstrate our improvement upon existing methods with respect to image fidelity, classification performance, and mitigation of membership inference attacks. Our work represents a step toward broader sharing of retinal images for scientific collaboration. Code is available at https://github.com/hcholab/k-salsa.
Generative Joint Source-Channel Coding for Semantic Image Transmission
Nov 24, 2022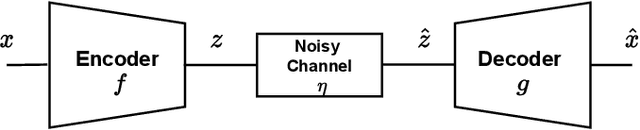
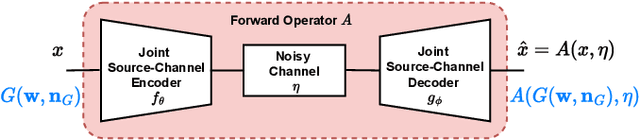
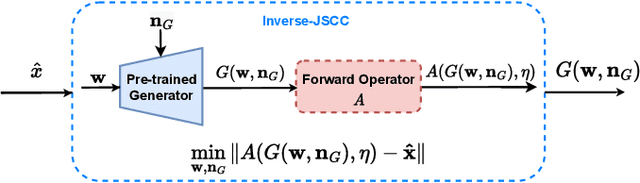
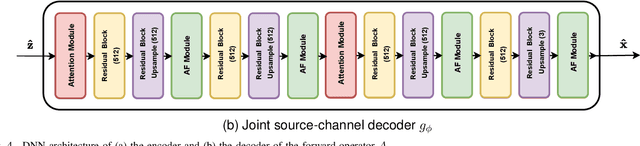
Recent works have shown that joint source-channel coding (JSCC) schemes using deep neural networks (DNNs), called DeepJSCC, provide promising results in wireless image transmission. However, these methods mostly focus on the distortion of the reconstructed signals with respect to the input image, rather than their perception by humans. However, focusing on traditional distortion metrics alone does not necessarily result in high perceptual quality, especially in extreme physical conditions, such as very low bandwidth compression ratio (BCR) and low signal-to-noise ratio (SNR) regimes. In this work, we propose two novel JSCC schemes that leverage the perceptual quality of deep generative models (DGMs) for wireless image transmission, namely InverseJSCC and GenerativeJSCC. While the former is an inverse problem approach to DeepJSCC, the latter is an end-to-end optimized JSCC scheme. In both, we optimize a weighted sum of mean squared error (MSE) and learned perceptual image patch similarity (LPIPS) losses, which capture more semantic similarities than other distortion metrics. InverseJSCC performs denoising on the distorted reconstructions of a DeepJSCC model by solving an inverse optimization problem using style-based generative adversarial network (StyleGAN). Our simulation results show that InverseJSCC significantly improves the state-of-the-art (SotA) DeepJSCC in terms of perceptual quality in edge cases. In GenerativeJSCC, we carry out end-to-end training of an encoder and a StyleGAN-based decoder, and show that GenerativeJSCC significantly outperforms DeepJSCC both in terms of distortion and perceptual quality.
Collage Diffusion
Mar 01, 2023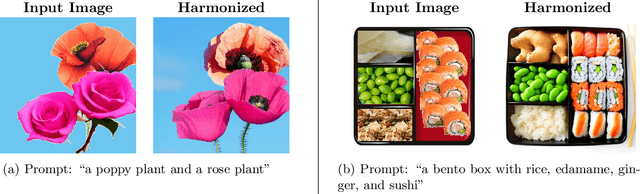
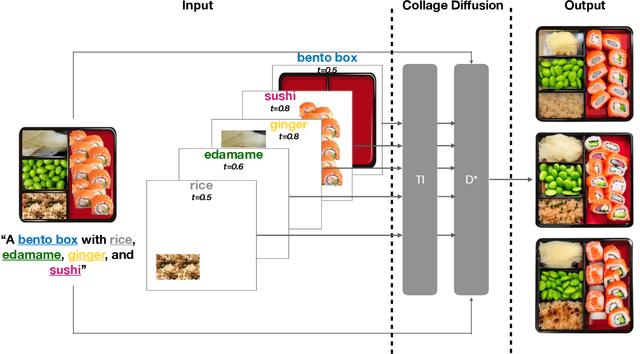
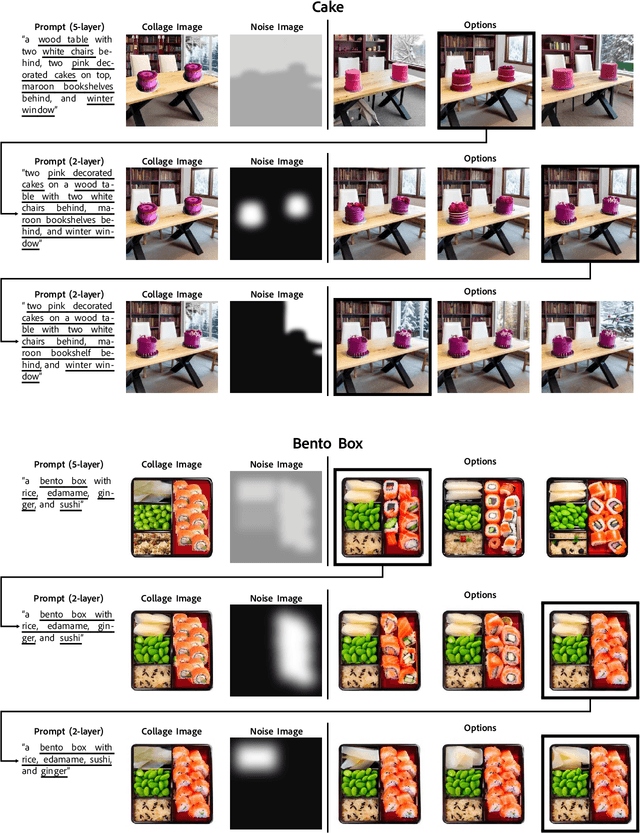

Text-conditional diffusion models generate high-quality, diverse images. However, text is often an ambiguous specification for a desired target image, creating the need for additional user-friendly controls for diffusion-based image generation. We focus on having precise control over image output for scenes with several objects. Users control image generation by defining a collage: a text prompt paired with an ordered sequence of layers, where each layer is an RGBA image and a corresponding text prompt. We introduce Collage Diffusion, a collage-conditional diffusion algorithm that allows users to control both the spatial arrangement and visual attributes of objects in the scene, and also enables users to edit individual components of generated images. To ensure that different parts of the input text correspond to the various locations specified in the input collage layers, Collage Diffusion modifies text-image cross-attention with the layers' alpha masks. To maintain characteristics of individual collage layers that are not specified in text, Collage Diffusion learns specialized text representations per layer. Collage input also enables layer-based controls that provide fine-grained control over the final output: users can control image harmonization on a layer-by-layer basis, and they can edit individual objects in generated images while keeping other objects fixed. Collage-conditional image generation requires harmonizing the input collage to make objects fit together--the key challenge involves minimizing changes in the positions and key visual attributes of objects in the input collage while allowing other attributes of the collage to change in the harmonization process. By leveraging the rich information present in layer input, Collage Diffusion generates globally harmonized images that maintain desired object locations and visual characteristics better than prior approaches.
Information-containing Adversarial Perturbation for Combating Facial Manipulation Systems
Mar 21, 2023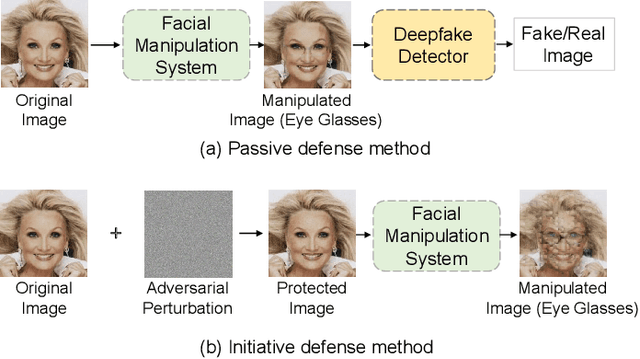
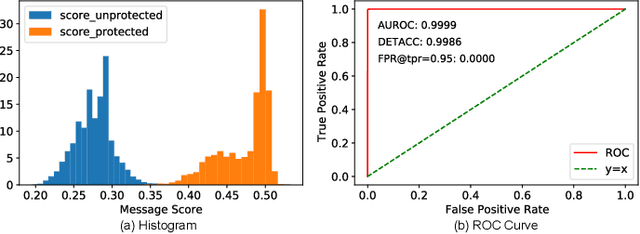


With the development of deep learning technology, the facial manipulation system has become powerful and easy to use. Such systems can modify the attributes of the given facial images, such as hair color, gender, and age. Malicious applications of such systems pose a serious threat to individuals' privacy and reputation. Existing studies have proposed various approaches to protect images against facial manipulations. Passive defense methods aim to detect whether the face is real or fake, which works for posterior forensics but can not prevent malicious manipulation. Initiative defense methods protect images upfront by injecting adversarial perturbations into images to disrupt facial manipulation systems but can not identify whether the image is fake. To address the limitation of existing methods, we propose a novel two-tier protection method named Information-containing Adversarial Perturbation (IAP), which provides more comprehensive protection for {facial images}. We use an encoder to map a facial image and its identity message to a cross-model adversarial example which can disrupt multiple facial manipulation systems to achieve initiative protection. Recovering the message in adversarial examples with a decoder serves passive protection, contributing to provenance tracking and fake image detection. We introduce a feature-level correlation measurement that is more suitable to measure the difference between the facial images than the commonly used mean squared error. Moreover, we propose a spectral diffusion method to spread messages to different frequency channels, thereby improving the robustness of the message against facial manipulation. Extensive experimental results demonstrate that our proposed IAP can recover the messages from the adversarial examples with high average accuracy and effectively disrupt the facial manipulation systems.
Advancing Medical Imaging with Language Models: A Journey from N-grams to ChatGPT
Apr 11, 2023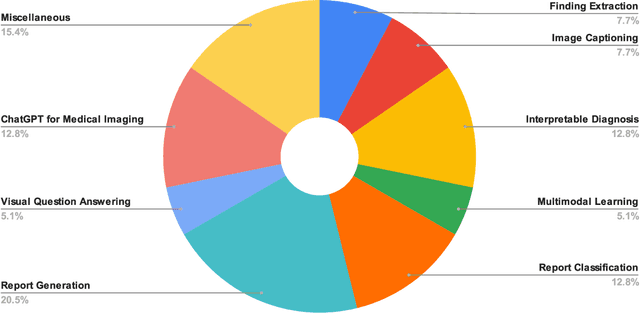


In this paper, we aimed to provide a review and tutorial for researchers in the field of medical imaging using language models to improve their tasks at hand. We began by providing an overview of the history and concepts of language models, with a special focus on large language models. We then reviewed the current literature on how language models are being used to improve medical imaging, emphasizing different applications such as image captioning, report generation, report classification, finding extraction, visual question answering, interpretable diagnosis, and more for various modalities and organs. The ChatGPT was specially highlighted for researchers to explore more potential applications. We covered the potential benefits of accurate and efficient language models for medical imaging analysis, including improving clinical workflow efficiency, reducing diagnostic errors, and assisting healthcare professionals in providing timely and accurate diagnoses. Overall, our goal was to bridge the gap between language models and medical imaging and inspire new ideas and innovations in this exciting area of research. We hope that this review paper will serve as a useful resource for researchers in this field and encourage further exploration of the possibilities of language models in medical imaging.
MRVM-NeRF: Mask-Based Pretraining for Neural Radiance Fields
Apr 11, 2023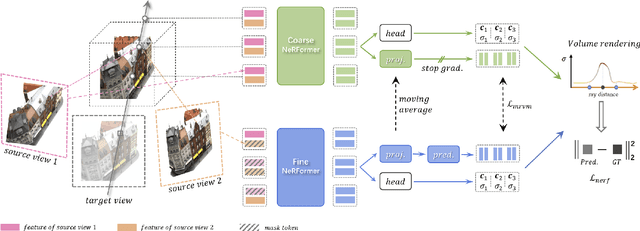
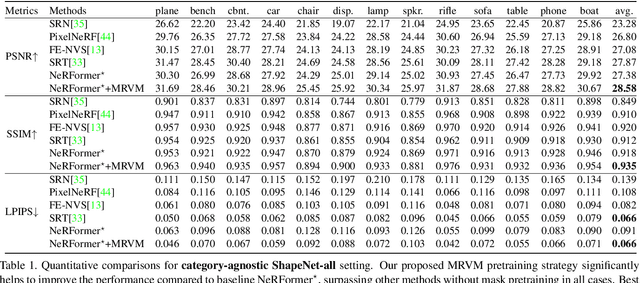
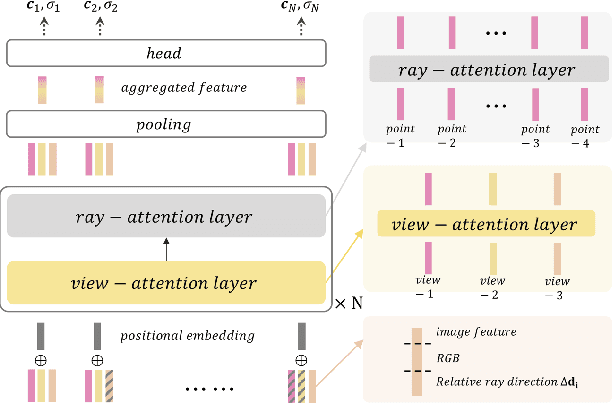
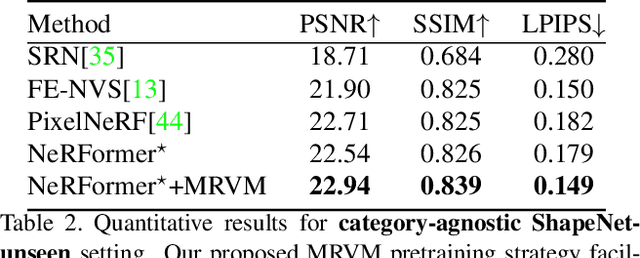
Most Neural Radiance Fields (NeRFs) have poor generalization ability, limiting their application when representing multiple scenes by a single model. To ameliorate this problem, existing methods simply condition NeRF models on image features, lacking the global understanding and modeling of the entire 3D scene. Inspired by the significant success of mask-based modeling in other research fields, we propose a masked ray and view modeling method for generalizable NeRF (MRVM-NeRF), the first attempt to incorporate mask-based pretraining into 3D implicit representations. Specifically, considering that the core of NeRFs lies in modeling 3D representations along the rays and across the views, we randomly mask a proportion of sampled points along the ray at fine stage by discarding partial information obtained from multi-viewpoints, targeting at predicting the corresponding features produced in the coarse branch. In this way, the learned prior knowledge of 3D scenes during pretraining helps the model generalize better to novel scenarios after finetuning. Extensive experiments demonstrate the superiority of our proposed MRVM-NeRF under various synthetic and real-world settings, both qualitatively and quantitatively. Our empirical studies reveal the effectiveness of our proposed innovative MRVM which is specifically designed for NeRF models.
Improving Neural Radiance Fields with Depth-aware Optimization for Novel View Synthesis
Apr 11, 2023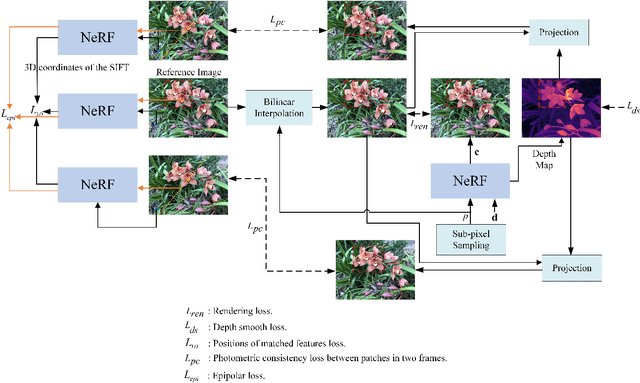

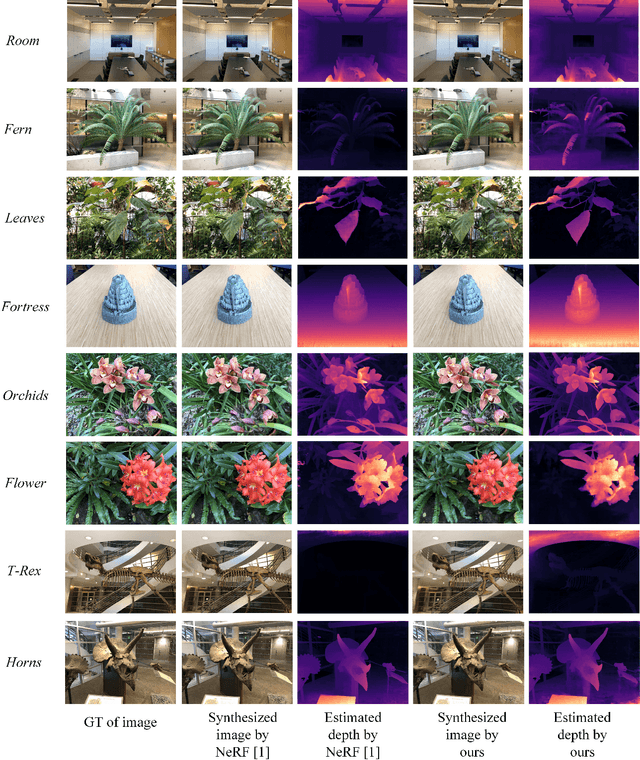

With dense inputs, Neural Radiance Fields (NeRF) is able to render photo-realistic novel views under static conditions. Although the synthesis quality is excellent, existing NeRF-based methods fail to obtain moderate three-dimensional (3D) structures. The novel view synthesis quality drops dramatically given sparse input due to the implicitly reconstructed inaccurate 3D-scene structure. We propose SfMNeRF, a method to better synthesize novel views as well as reconstruct the 3D-scene geometry. SfMNeRF leverages the knowledge from the self-supervised depth estimation methods to constrain the 3D-scene geometry during view synthesis training. Specifically, SfMNeRF employs the epipolar, photometric consistency, depth smoothness, and position-of-matches constraints to explicitly reconstruct the 3D-scene structure. Through these explicit constraints and the implicit constraint from NeRF, our method improves the view synthesis as well as the 3D-scene geometry performance of NeRF at the same time. In addition, SfMNeRF synthesizes novel sub-pixels in which the ground truth is obtained by image interpolation. This strategy enables SfMNeRF to include more samples to improve generalization performance. Experiments on two public datasets demonstrate that SfMNeRF surpasses state-of-the-art approaches. Code is available at https://github.com/XTU-PR-LAB/SfMNeRF