 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CROVIA: Seeing Drone Scenes from Car Perspective via Cross-View Adaptation
Apr 14, 2023
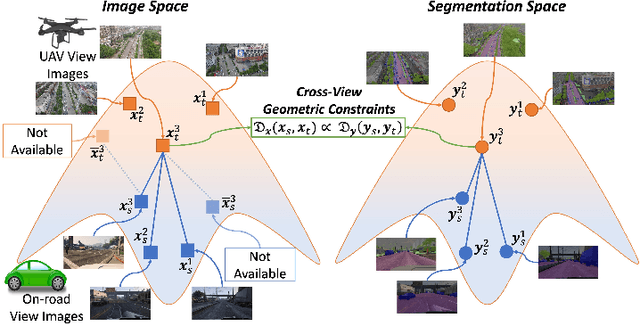
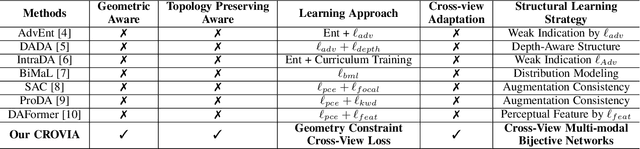
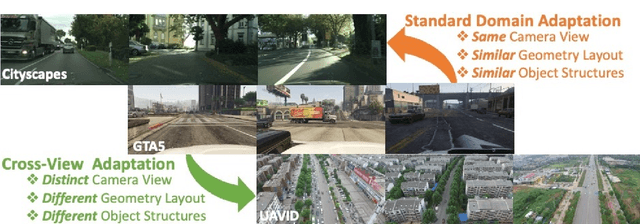
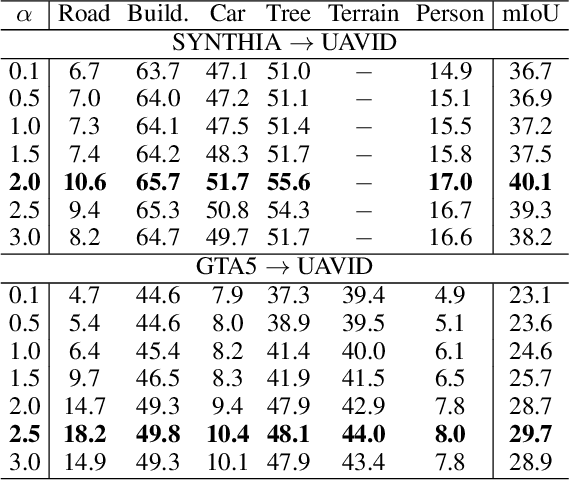
Understanding semantic scene segmentation of urban scenes captured from the Unmanned Aerial Vehicles (UAV) perspective plays a vital role in building a perception model for UAV. With the limitations of large-scale densely labeled data, semantic scene segmentation for UAV views requires a broad understanding of an object from both its top and side views. Adapting from well-annotated autonomous driving data to unlabeled UAV data is challenging due to the cross-view differences between the two data types. Our work proposes a novel Cross-View Adaptation (CROVIA) approach to effectively adapt the knowledge learned from on-road vehicle views to UAV views. First, a novel geometry-based constraint to cross-view adaptation is introduced based on the geometry correlation between views. Second, cross-view correlations from image space are effectively transferred to segmentation space without any requirement of paired on-road and UAV view data via a new Geometry-Constraint Cross-View (GeiCo) loss. Third, the multi-modal bijective networks are introduced to enforce the global structural modeling across views. Experimental results on new cross-view adaptation benchmarks introduced in this work, i.e., SYNTHIA to UAVID and GTA5 to UAVID, show the State-of-the-Art (SOTA) performance of our approach over prior adaptation methods
WYTIWYR: A User Intent-Aware Framework with Multi-modal Inputs for Visualization Retrieval
Apr 14, 2023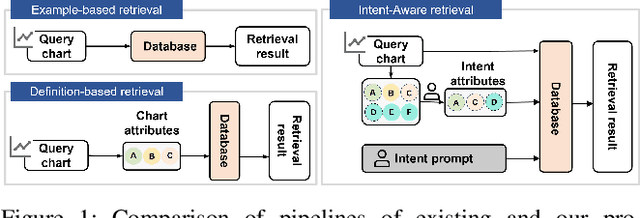
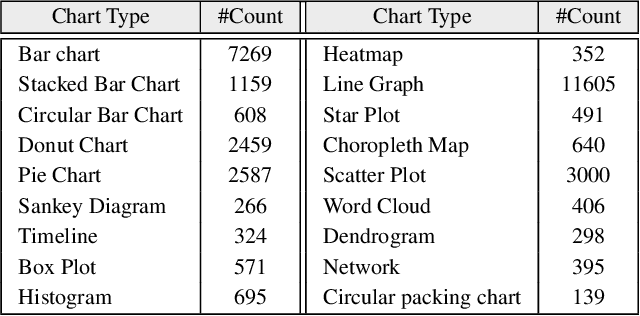
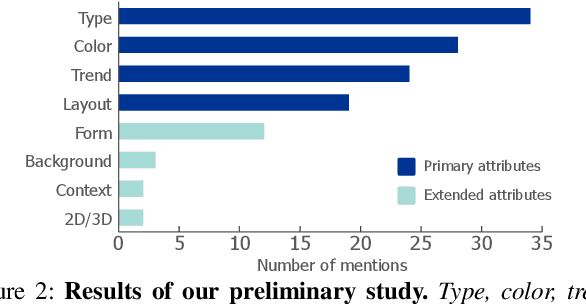

Retrieving charts from a large corpus is a fundamental task that can benefit numerous applications such as visualization recommendations.The retrieved results are expected to conform to both explicit visual attributes (e.g., chart type, colormap) and implicit user intents (e.g., design style, context information) that vary upon application scenarios. However, existing example-based chart retrieval methods are built upon non-decoupled and low-level visual features that are hard to interpret, while definition-based ones are constrained to pre-defined attributes that are hard to extend. In this work, we propose a new framework, namely WYTIWYR (What-You-Think-Is-What-You-Retrieve), that integrates user intents into the chart retrieval process. The framework consists of two stages: first, the Annotation stage disentangles the visual attributes within the bitmap query chart; and second, the Retrieval stage embeds the user's intent with customized text prompt as well as query chart, to recall targeted retrieval result. We develop a prototype WYTIWYR system leveraging a contrastive language-image pre-training (CLIP) model to achieve zero-shot classification, and test the prototype on a large corpus with charts crawled from the Internet. Quantitative experiments, case studies, and qualitative interviews are conducted. The results demonstrate the usability and effectiveness of our proposed framework.
Frequency Decomposition to Tap the Potential of Single Domain for Generalization
Apr 14, 2023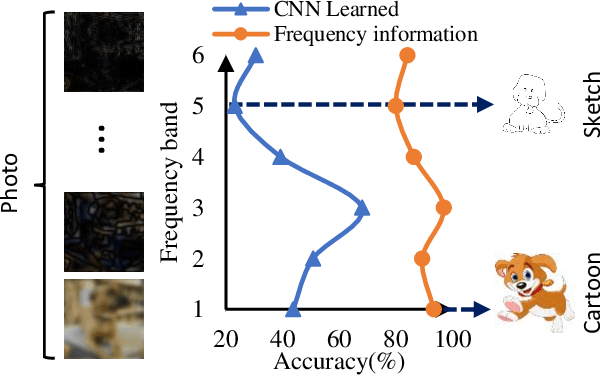
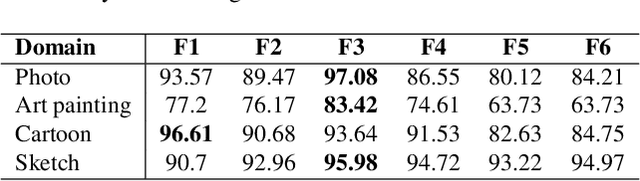
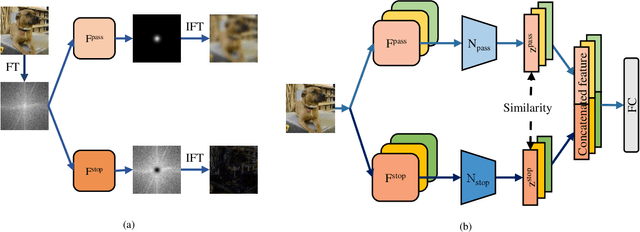
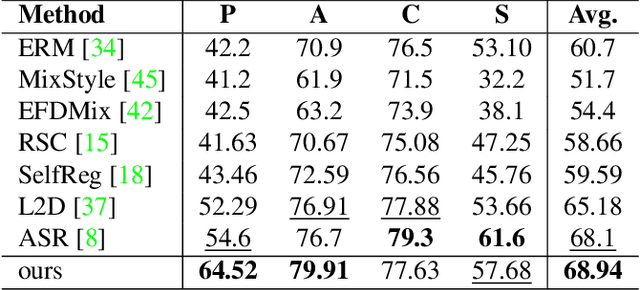
Domain generalization (DG), aiming at models able to work on multiple unseen domains, is a must-have characteristic of general artificial intelligence. DG based on single source domain training data is more challenging due to the lack of comparable information to help identify domain invariant features. In this paper, it is determined that the domain invariant features could be contained in the single source domain training samples, then the task is to find proper ways to extract such domain invariant features from the single source domain samples. An assumption is made that the domain invariant features are closely related to the frequency. Then, a new method that learns through multiple frequency domains is proposed. The key idea is, dividing the frequency domain of each original image into multiple subdomains, and learning features in the subdomain by a designed two branches network. In this way, the model is enforced to learn features from more samples of the specifically limited spectrum, which increases the possibility of obtaining the domain invariant features that might have previously been defiladed by easily learned features. Extensive experimental investigation reveals that 1) frequency decomposition can help the model learn features that are difficult to learn. 2) the proposed method outperforms the state-of-the-art methods of single-source domain generalization.
Content-Based Medical Image Retrieval with Opponent Class Adaptive Margin Loss
Nov 22, 2022
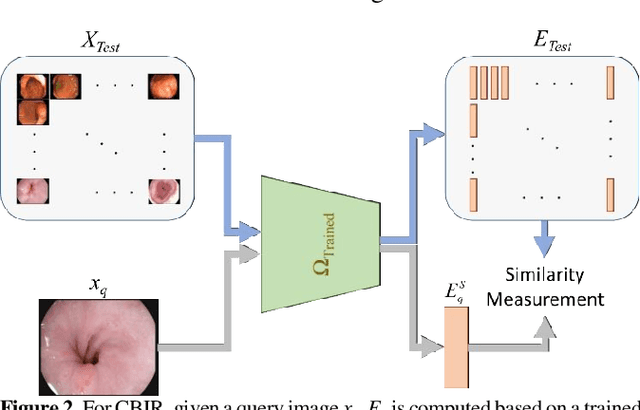
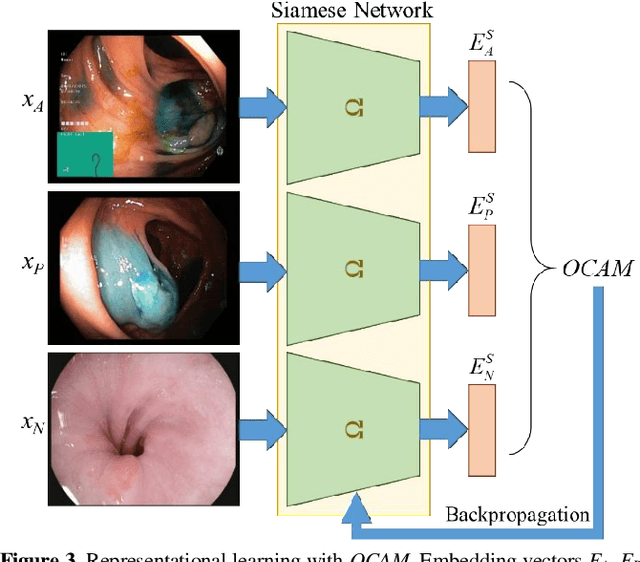
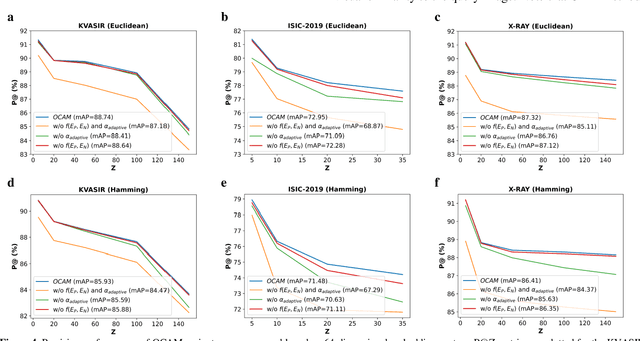
Broadspread use of medical imaging devices with digital storage has paved the way for curation of substantial data repositories. Fast access to image samples with similar appearance to suspected cases can help establish a consulting system for healthcare professionals, and improve diagnostic procedures while minimizing processing delays. However, manual querying of large data repositories is labor intensive. Content-based image retrieval (CBIR) offers an automated solution based on dense embedding vectors that represent image features to allow quantitative similarity assessments. Triplet learning has emerged as a powerful approach to recover embeddings in CBIR, albeit traditional loss functions ignore the dynamic relationship between opponent image classes. Here, we introduce a triplet-learning method for automated querying of medical image repositories based on a novel Opponent Class Adaptive Margin (OCAM) loss. OCAM uses a variable margin value that is updated continually during the course of training to maintain optimally discriminative representations. CBIR performance of OCAM is compared against state-of-the-art loss functions for representational learning on three public databases (gastrointestinal disease, skin lesion, lung disease). Comprehensive experiments in each application domain demonstrate the superior performance of OCAM against baselines.
DeAR: Debiasing Vision-Language Models with Additive Residuals
Mar 18, 2023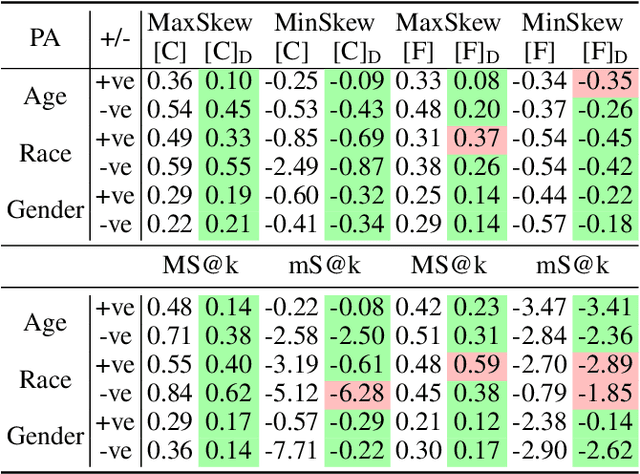
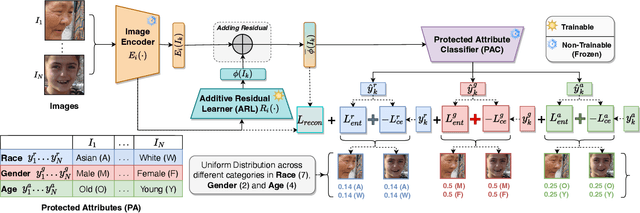
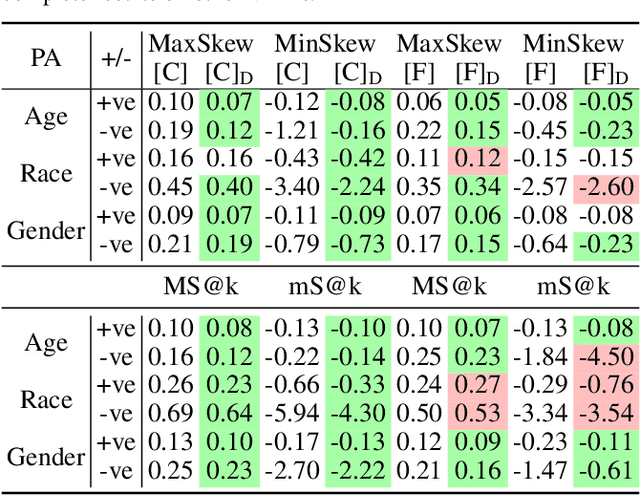
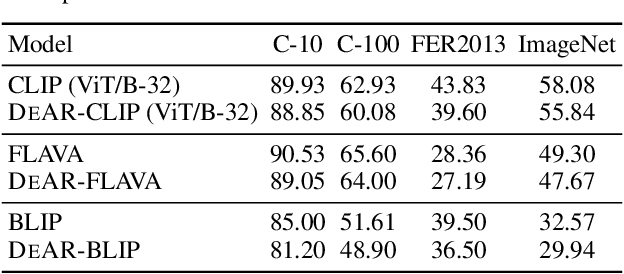
Large pre-trained vision-language models (VLMs) reduce the time for developing predictive models for various vision-grounded language downstream tasks by providing rich, adaptable image and text representations. However, these models suffer from societal biases owing to the skewed distribution of various identity groups in the training data. These biases manifest as the skewed similarity between the representations for specific text concepts and images of people of different identity groups and, therefore, limit the usefulness of such models in real-world high-stakes applications. In this work, we present DeAR (Debiasing with Additive Residuals), a novel debiasing method that learns additive residual image representations to offset the original representations, ensuring fair output representations. In doing so, it reduces the ability of the representations to distinguish between the different identity groups. Further, we observe that the current fairness tests are performed on limited face image datasets that fail to indicate why a specific text concept should/should not apply to them. To bridge this gap and better evaluate DeAR, we introduce the Protected Attribute Tag Association (PATA) dataset - a new context-based bias benchmarking dataset for evaluating the fairness of large pre-trained VLMs. Additionally, PATA provides visual context for a diverse human population in different scenarios with both positive and negative connotations. Experimental results for fairness and zero-shot performance preservation using multiple datasets demonstrate the efficacy of our framework.
Multi-Exposure HDR Composition by Gated Swin Transformer
Mar 15, 2023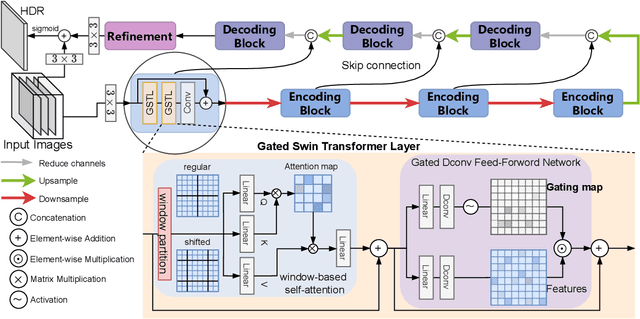
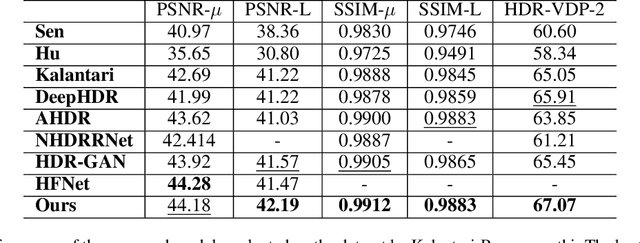


Fusing a sequence of perfectly aligned images captured at various exposures, has shown great potential to approach High Dynamic Range (HDR) imaging by sensors with limited dynamic range. However, in the presence of large motion of scene objects or the camera, mis-alignment is almost inevitable and leads to the notorious ``ghost'' artifacts. Besides, factors such as the noise in the dark region or color saturation in the over-bright region may also fail to fill local image details to the HDR image. This paper provides a novel multi-exposure fusion model based on Swin Transformer. Particularly, we design feature selection gates, which are integrated with the feature extraction layers to detect outliers and block them from HDR image synthesis. To reconstruct the missing local details by well-aligned and properly-exposed regions, we exploit the long distance contextual dependency in the exposure-space pyramid by the self-attention mechanism. Extensive numerical and visual evaluation has been conducted on a variety of benchmark datasets. The experiments show that our model achieves the accuracy on par with current top performing multi-exposure HDR imaging models, while gaining higher efficiency.
Certifiable (Multi)Robustness Against Patch Attacks Using ERM
Mar 15, 2023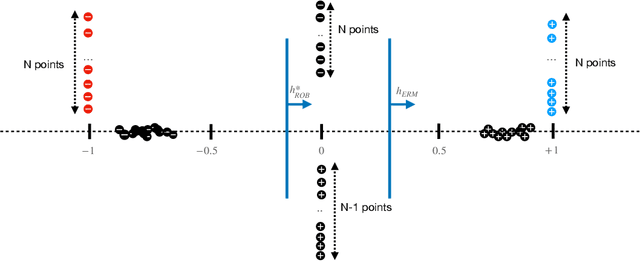
Consider patch attacks, where at test-time an adversary manipulates a test image with a patch in order to induce a targeted misclassification. We consider a recent defense to patch attacks, Patch-Cleanser (Xiang et al. [2022]). The Patch-Cleanser algorithm requires a prediction model to have a ``two-mask correctness'' property, meaning that the prediction model should correctly classify any image when any two blank masks replace portions of the image. Xiang et al. learn a prediction model to be robust to two-mask operations by augmenting the training set with pairs of masks at random locations of training images and performing empirical risk minimization (ERM) on the augmented dataset. However, in the non-realizable setting when no predictor is perfectly correct on all two-mask operations on all images, we exhibit an example where ERM fails. To overcome this challenge, we propose a different algorithm that provably learns a predictor robust to all two-mask operations using an ERM oracle, based on prior work by Feige et al. [2015]. We also extend this result to a multiple-group setting, where we can learn a predictor that achieves low robust loss on all groups simultaneously.
On the impact of incorporating task-information in learning-based image denoising
Nov 23, 2022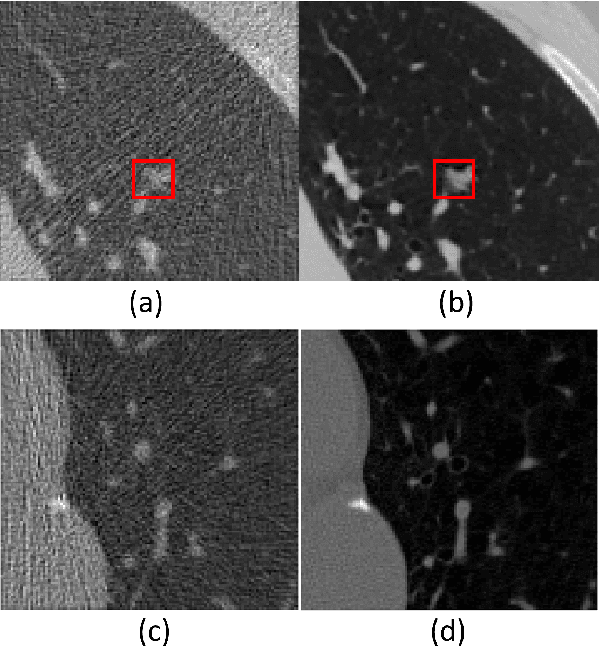
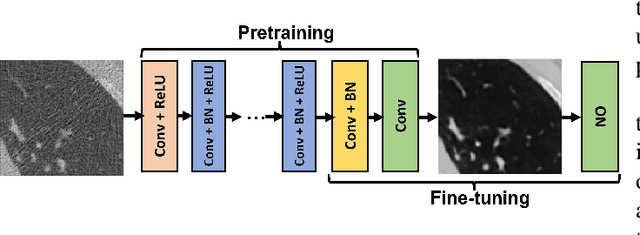
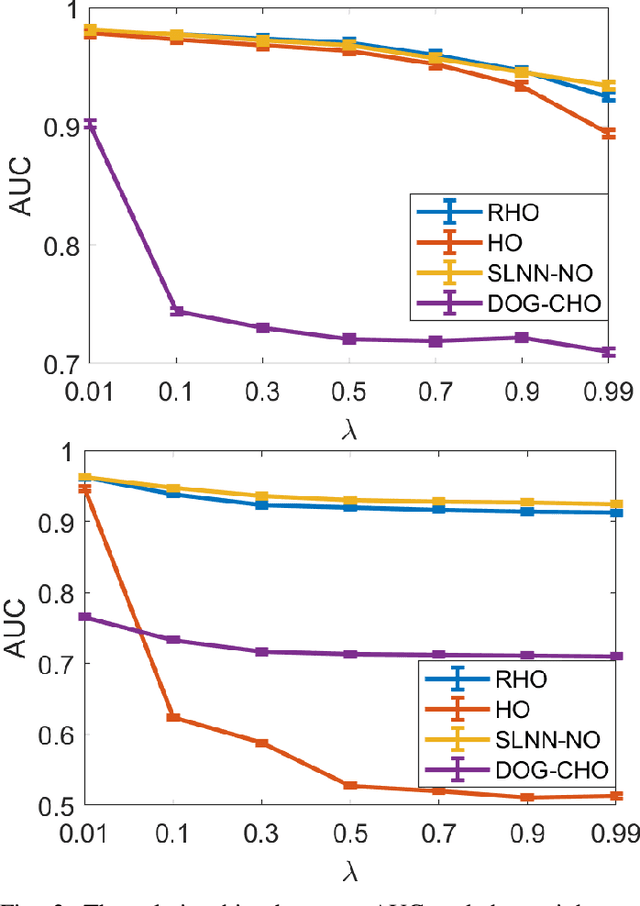
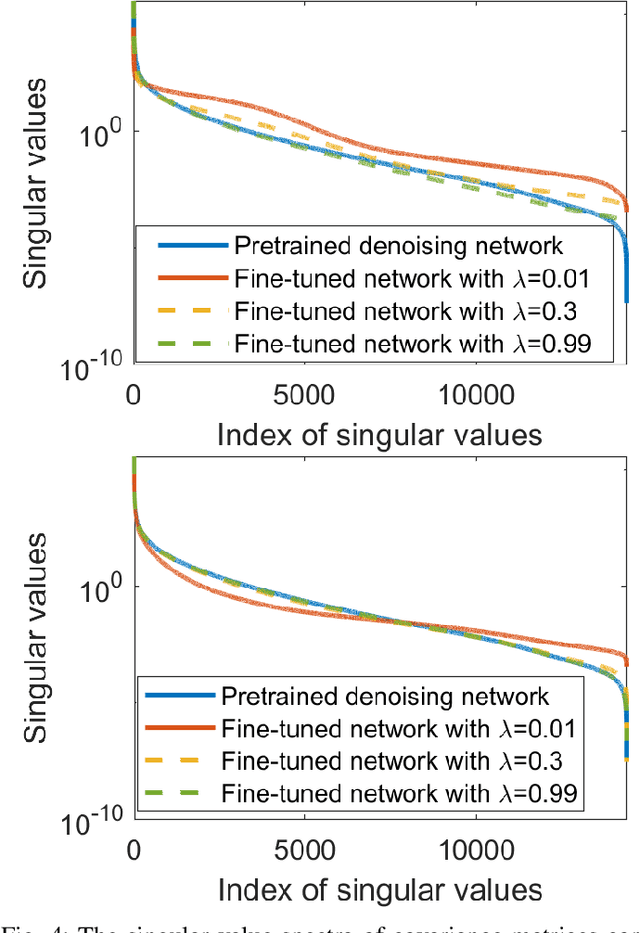
A variety of deep neural network (DNN)-based image denoising methods have been proposed for use with medical images. These methods are typically trained by minimizing loss functions that quantify a distance between the denoised image, or a transformed version of it, and the defined target image (e.g., a noise-free or low-noise image). They have demonstrated high performance in terms of traditional image quality metrics such as root mean square error (RMSE), structural similarity index measure (SSIM), or peak signal-to-noise ratio (PSNR). However, it has been reported recently that such denoising methods may not always improve objective measures of image quality. In this work, a task-informed DNN-based image denoising method was established and systematically evaluated. A transfer learning approach was employed, in which the DNN is first pre-trained by use of a conventional (non-task-informed) loss function and subsequently fine-tuned by use of the hybrid loss that includes a task-component. The task-component was designed to measure the performance of a numerical observer (NO) on a signal detection task. The impact of network depth and constraining the fine-tuning to specific layers of the DNN was explored. The task-informed training method was investigated in a stylized low-dose X-ray computed tomography (CT) denoising study for which binary signal detection tasks under signal-known-statistically (SKS) with background-known-statistically (BKS) conditions were considered. The impact of changing the specified task at inference time to be different from that employed for model training, a phenomenon we refer to as "task-shift", was also investigated. The presented results indicate that the task-informed training method can improve observer performance while providing control over the trade off between traditional and task-based measures of image quality.
Learning 3D Representations from 2D Pre-trained Models via Image-to-Point Masked Autoencoders
Dec 13, 2022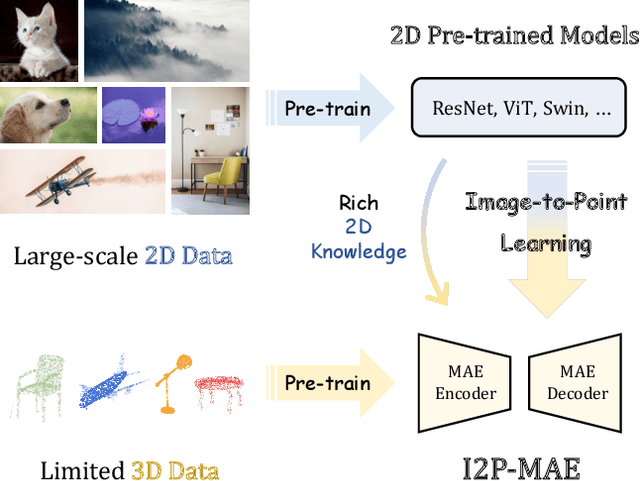
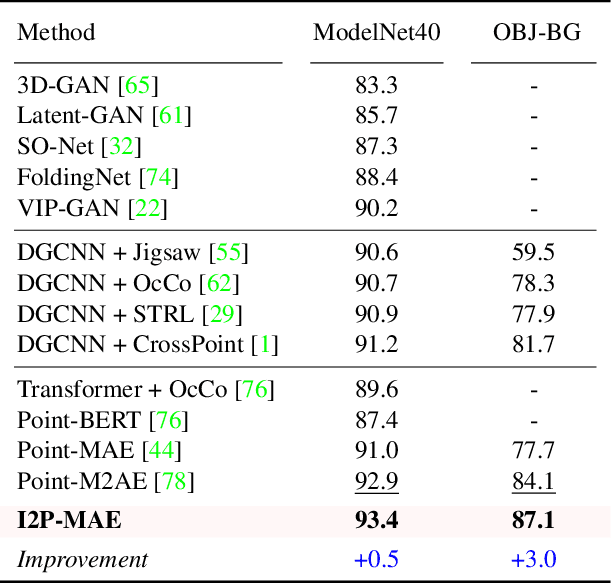
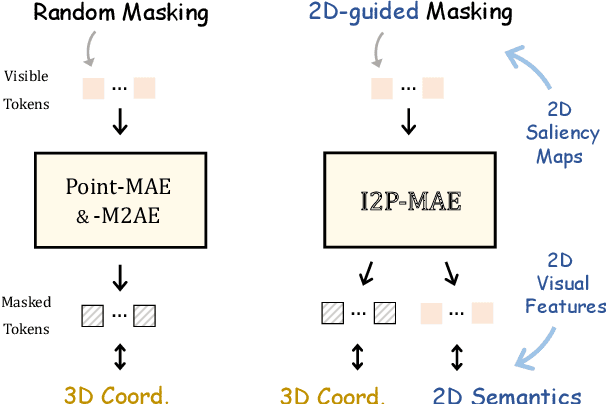
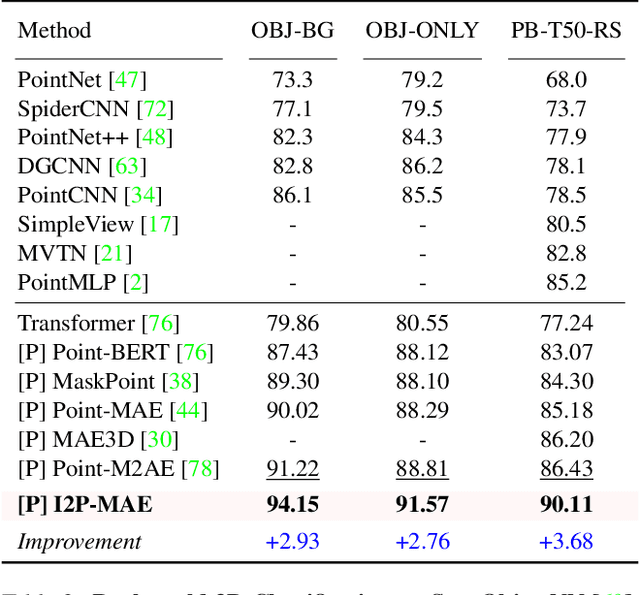
Pre-training by numerous image data has become de-facto for robust 2D representations. In contrast, due to the expensive data acquisition and annotation, a paucity of large-scale 3D datasets severely hinders the learning for high-quality 3D features. In this paper, we propose an alternative to obtain superior 3D representations from 2D pre-trained models via Image-to-Point Masked Autoencoders, named as I2P-MAE. By self-supervised pre-training, we leverage the well learned 2D knowledge to guide 3D masked autoencoding, which reconstructs the masked point tokens with an encoder-decoder architecture. Specifically, we first utilize off-the-shelf 2D models to extract the multi-view visual features of the input point cloud, and then conduct two types of image-to-point learning schemes on top. For one, we introduce a 2D-guided masking strategy that maintains semantically important point tokens to be visible for the encoder. Compared to random masking, the network can better concentrate on significant 3D structures and recover the masked tokens from key spatial cues. For another, we enforce these visible tokens to reconstruct the corresponding multi-view 2D features after the decoder. This enables the network to effectively inherit high-level 2D semantics learned from rich image data for discriminative 3D modeling. Aided by our image-to-point pre-training, the frozen I2P-MAE, without any fine-tuning, achieves 93.4% accuracy for linear SVM on ModelNet40, competitive to the fully trained results of existing methods. By further fine-tuning on on ScanObjectNN's hardest split, I2P-MAE attains the state-of-the-art 90.11% accuracy, +3.68% to the second-best, demonstrating superior transferable capacity. Code will be available at https://github.com/ZrrSkywalker/I2P-MAE.
Meta Compositional Referring Expression Segmentation
Apr 12, 2023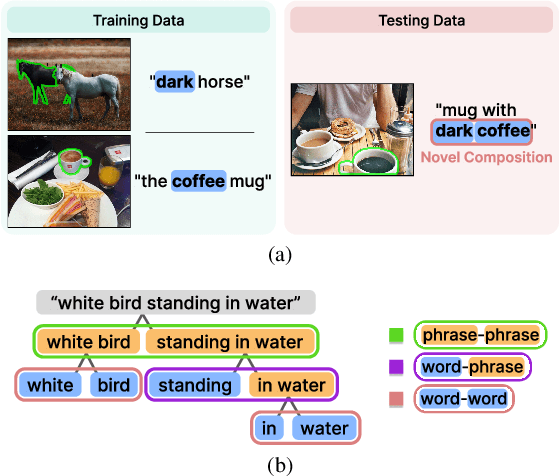
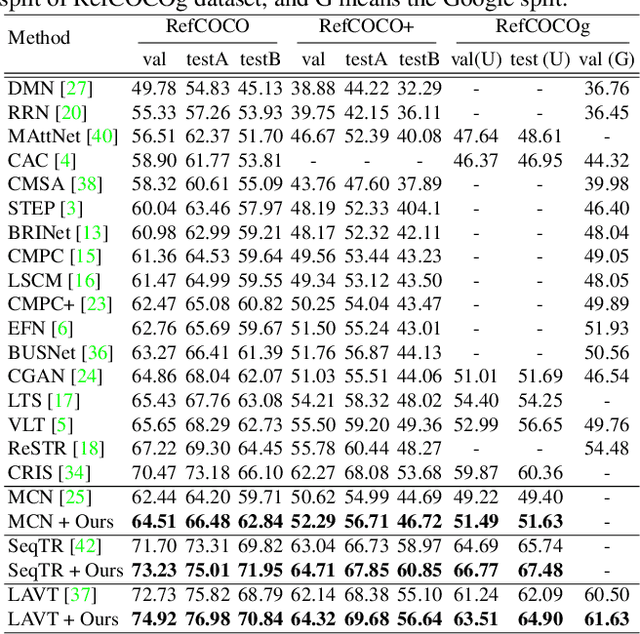
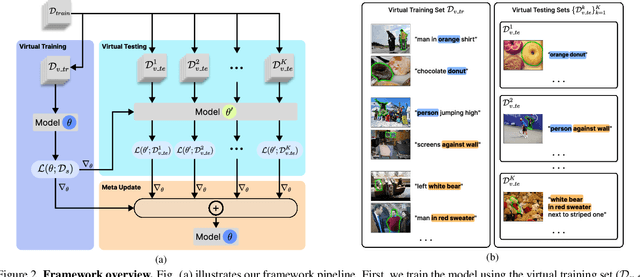
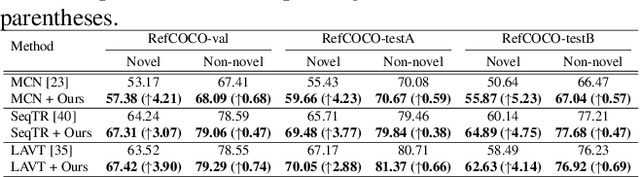
Referring expression segmentation aims to segment an object described by a language expression from an image. Despite the recent progress on this task, existing models tackling this task may not be able to fully capture semantics and visual representations of individual concepts, which limits their generalization capability, especially when handling novel compositions of learned concepts. In this work, through the lens of meta learning, we propose a Meta Compositional Referring Expression Segmentation (MCRES) framework to enhance model compositional generalization performance. Specifically, to handle various levels of novel compositions, our framework first uses training data to construct a virtual training set and multiple virtual testing sets, where data samples in each virtual testing set contain a level of novel compositions w.r.t. the virtual training set. Then, following a novel meta optimization scheme to optimize the model to obtain good testing performance on the virtual testing sets after training on the virtual training set, our framework can effectively drive the model to better capture semantics and visual representations of individual concepts, and thus obtain robust generalization performance even when handling novel compositions. Extensive experiments on three benchmark datasets demonstrate the effectiveness of our framework.