 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multi-Linear Kernel Regression and Imputation in Data Manifolds
Apr 06, 2023
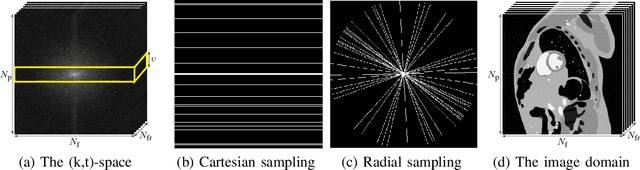
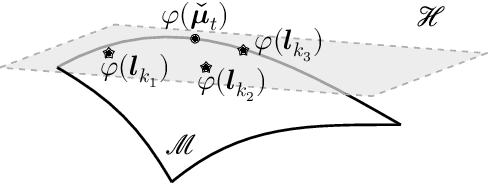
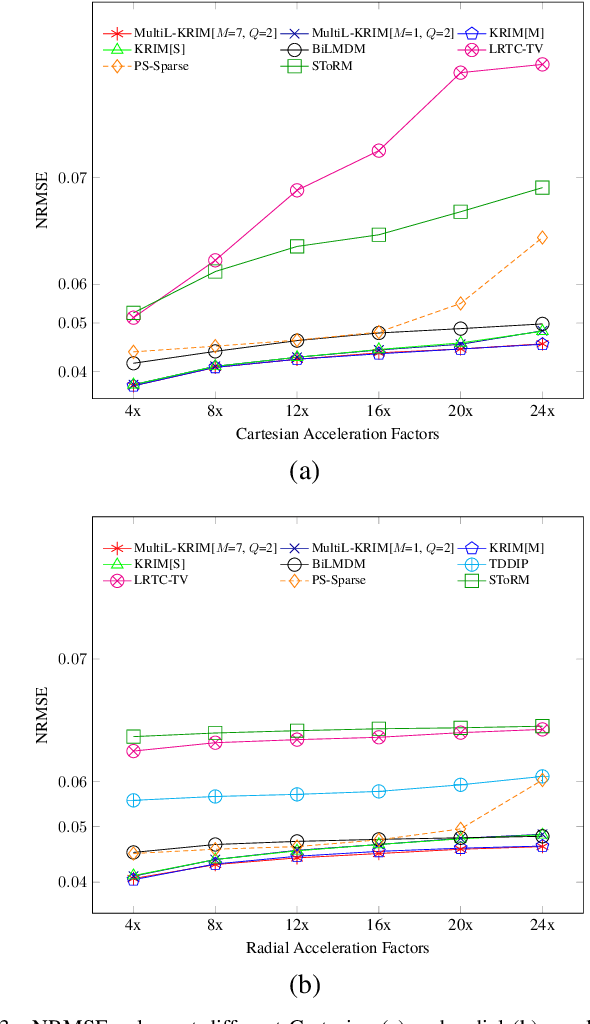
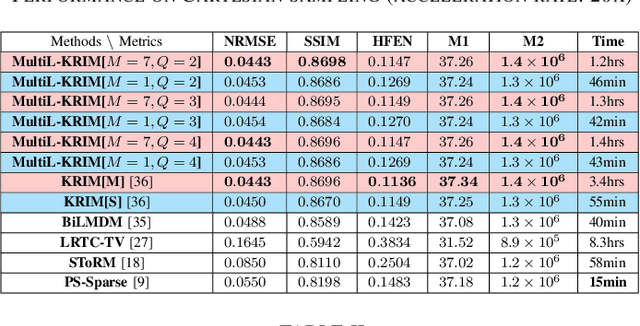
This paper introduces an efficient multi-linear nonparametric (kernel-based) approximation framework for data regression and imputation, and its application to dynamic magnetic-resonance imaging (dMRI). Data features are assumed to reside in or close to a smooth manifold embedded in a reproducing kernel Hilbert space. Landmark points are identified to describe concisely the point cloud of features by linear approximating patches which mimic the concept of tangent spaces to smooth manifolds. The multi-linear model effects dimensionality reduction, enables efficient computations, and extracts data patterns and their geometry without any training data or additional information. Numerical tests on dMRI data under severe under-sampling demonstrate remarkable improvements in efficiency and accuracy of the proposed approach over its predecessors, popular data modeling methods, as well as recent tensor-based and deep-image-prior schemes.
GI Software with fewer Data Cache Misses
Apr 06, 2023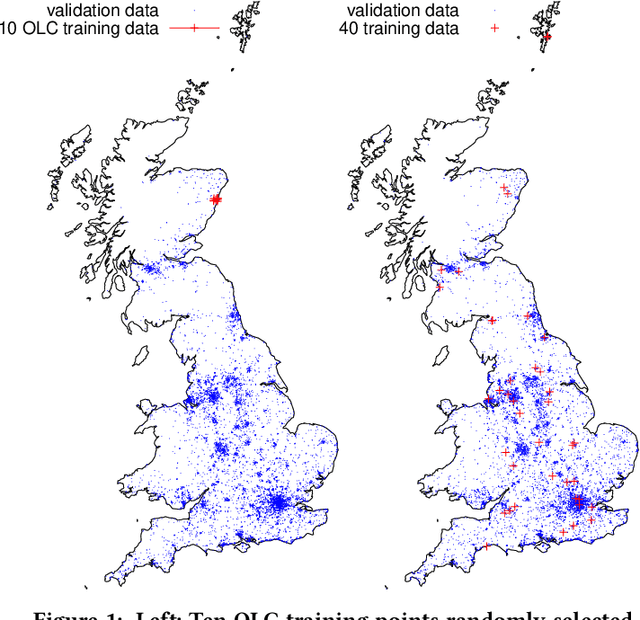
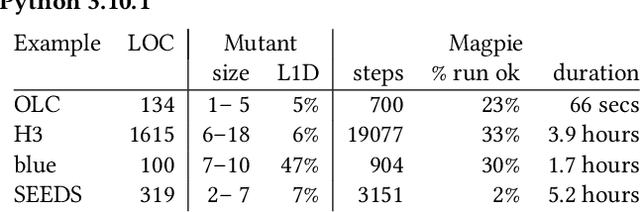

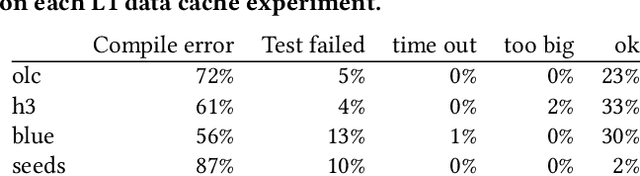
By their very name caches are often overlooked and yet play a vital role in the performance of modern and indeed future hardware. Using MAGPIE (Machine Automated General Performance Improvement via Evolution of software) we show genetic improvement GI can reduce the cache load of existing computer programs. Operating on lines of C and C++ source code using local search, Magpie can generate new functionally equivalent variants which generate fewer L1 data cache misses. Cache miss reduction is tested on two industrial open source programs (Google's Open Location Code OLC and Uber's Hexagonal Hierarchical Spatial Index H3) and two 2D photograph image processing tasks, counting pixels and OpenCV's SEEDS segmentation algorithm. Magpie's patches functionally generalise. In one case they reduce data misses on the highest performance L1 cache dramatically by 47 percent.
Generative Joint Source-Channel Coding for Semantic Image Transmission
Nov 24, 2022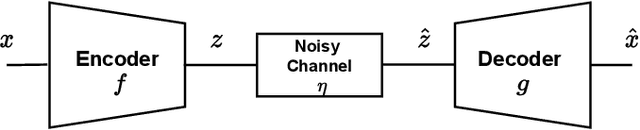
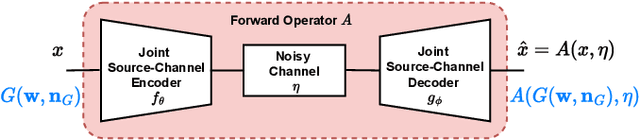
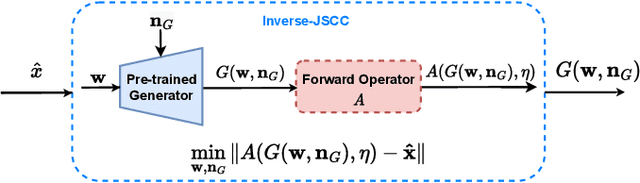
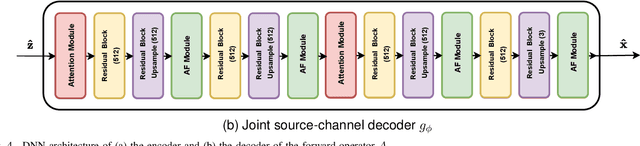
Recent works have shown that joint source-channel coding (JSCC) schemes using deep neural networks (DNNs), called DeepJSCC, provide promising results in wireless image transmission. However, these methods mostly focus on the distortion of the reconstructed signals with respect to the input image, rather than their perception by humans. However, focusing on traditional distortion metrics alone does not necessarily result in high perceptual quality, especially in extreme physical conditions, such as very low bandwidth compression ratio (BCR) and low signal-to-noise ratio (SNR) regimes. In this work, we propose two novel JSCC schemes that leverage the perceptual quality of deep generative models (DGMs) for wireless image transmission, namely InverseJSCC and GenerativeJSCC. While the former is an inverse problem approach to DeepJSCC, the latter is an end-to-end optimized JSCC scheme. In both, we optimize a weighted sum of mean squared error (MSE) and learned perceptual image patch similarity (LPIPS) losses, which capture more semantic similarities than other distortion metrics. InverseJSCC performs denoising on the distorted reconstructions of a DeepJSCC model by solving an inverse optimization problem using style-based generative adversarial network (StyleGAN). Our simulation results show that InverseJSCC significantly improves the state-of-the-art (SotA) DeepJSCC in terms of perceptual quality in edge cases. In GenerativeJSCC, we carry out end-to-end training of an encoder and a StyleGAN-based decoder, and show that GenerativeJSCC significantly outperforms DeepJSCC both in terms of distortion and perceptual quality.
Blind deblurring of hyperspectral document images
Mar 09, 2023Most computer vision and machine learning-based approaches for historical document analysis are tailored to grayscale or RGB images and thus, mostly exploit their spatial information. Multispectral (MS) and hyperspectral (HS) images contain, next to the spatial information, much richer spectral information than RGB images (usually spreading beyond the visible spectral range) that can facilitate more effective feature extraction, more accurate classification and recognition, and thus, improved analysis. Although utilization of rich spectral information can improve historical document analysis tremendously, there are still some potential limitations of HS imagery such as camera-induced noise and blur that require a carefully designed preprocessing step. Here, we propose novel blind HS image deblurring methods tailored to document images. We exploit a low-rank property of HS images (i.e., by projecting an HS image to a lower dimensional subspace) and utilize a text tailor image prior to performing a PSF estimation and deblurring of subspace components. The preliminary results show that the proposed approach gives good results over all spectral bands, removing successfully image artefacts introduced by blur and noise and significantly increasing the number of bands that can be used in further analysis.
* This project has received funding from the European Union's Horizon 2020 research and innovation programme under grant agreement No. 101026453. This work is published in the Lecture Notes in Computer Science book series (LNCS, volume 13373) as part of the Image Analysis and Processing, ICIAP 2022 Workshops
Virtual Inverse Perspective Mapping for Simultaneous Pose and Motion Estimation
Mar 09, 2023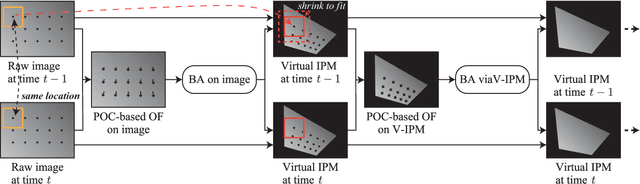
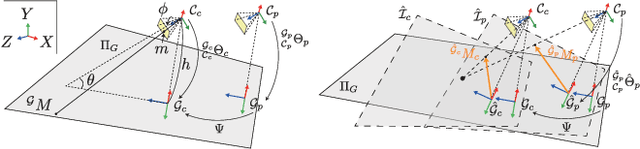
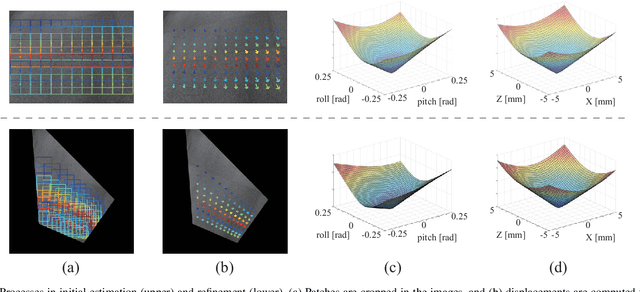
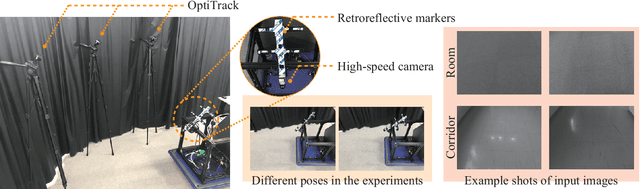
We propose an automatic method for pose and motion estimation against a ground surface for a ground-moving robot-mounted monocular camera. The framework adopts a semi-dense approach that benefits from both a feature-based method and an image-registration-based method by setting multiple patches in the image for displacement computation through a highly accurate image-registration technique. To improve accuracy, we introduce virtual inverse perspective mapping (IPM) in the refinement step to eliminate the perspective effect on image registration. The pose and motion are jointly and robustly estimated by a formulation of geometric bundle adjustment via virtual IPM. Unlike conventional visual odometry methods, the proposed method is free from cumulative error because it directly estimates pose and motion against the ground by taking advantage of a camera configuration mounted on a ground-moving robot where the camera's vertical motion is ignorable compared to its height within the frame interval and the nearby ground surface is approximately flat. We conducted experiments in which the relative mean error of the pitch and roll angles was approximately 1.0 degrees and the absolute mean error of the travel distance was 0.3 mm, even under camera shaking within a short period.
Interaction-Aware Prompting for Zero-Shot Spatio-Temporal Action Detection
Apr 11, 2023
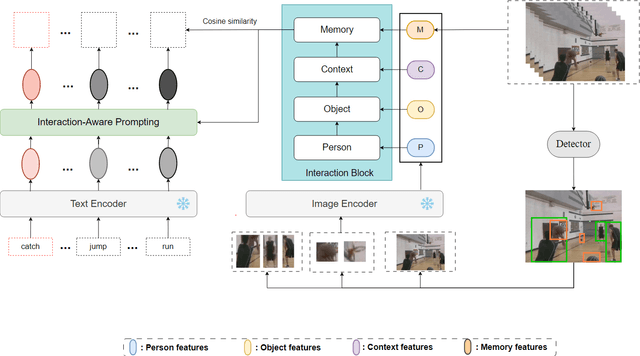

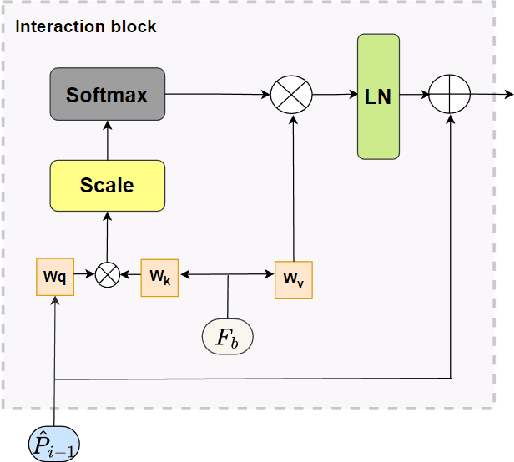
The goal of spatial-temporal action detection is to determine the time and place where each person's action occurs in a video and classify the corresponding action category. Most of the existing methods adopt fully-supervised learning, which requires a large amount of training data, making it very difficult to achieve zero-shot learning. In this paper, we propose to utilize a pre-trained visual-language model to extract the representative image and text features, and model the relationship between these features through different interaction modules to obtain the interaction feature. In addition, we use this feature to prompt each label to obtain more appropriate text features. Finally, we calculate the similarity between the interaction feature and the text feature for each label to determine the action category. Our experiments on J-HMDB and UCF101-24 datasets demonstrate that the proposed interaction module and prompting make the visual-language features better aligned, thus achieving excellent accuracy for zero-shot spatio-temporal action detection. The code will be released upon acceptance.
The MONET dataset: Multimodal drone thermal dataset recorded in rural scenarios
Apr 11, 2023
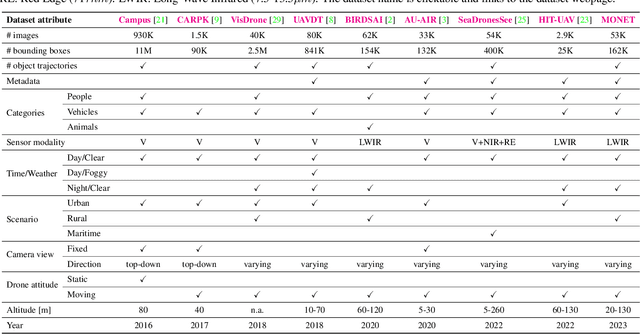
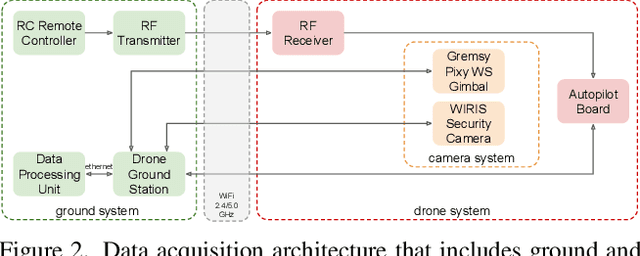
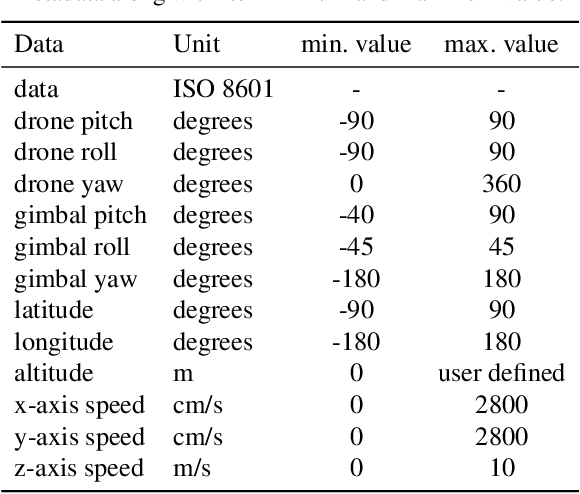
We present MONET, a new multimodal dataset captured using a thermal camera mounted on a drone that flew over rural areas, and recorded human and vehicle activities. We captured MONET to study the problem of object localisation and behaviour understanding of targets undergoing large-scale variations and being recorded from different and moving viewpoints. Target activities occur in two different land sites, each with unique scene structures and cluttered backgrounds. MONET consists of approximately 53K images featuring 162K manually annotated bounding boxes. Each image is timestamp-aligned with drone metadata that includes information about attitudes, speed, altitude, and GPS coordinates. MONET is different from previous thermal drone datasets because it features multimodal data, including rural scenes captured with thermal cameras containing both person and vehicle targets, along with trajectory information and metadata. We assessed the difficulty of the dataset in terms of transfer learning between the two sites and evaluated nine object detection algorithms to identify the open challenges associated with this type of data. Project page: https://github.com/fabiopoiesi/monet_dataset.
Boosting Cross-task Transferability of Adversarial Patches with Visual Relations
Apr 11, 2023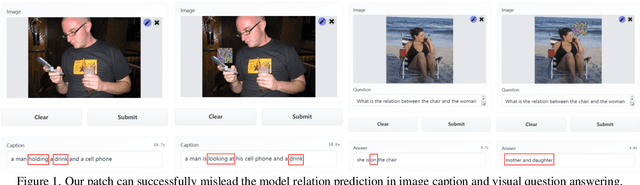
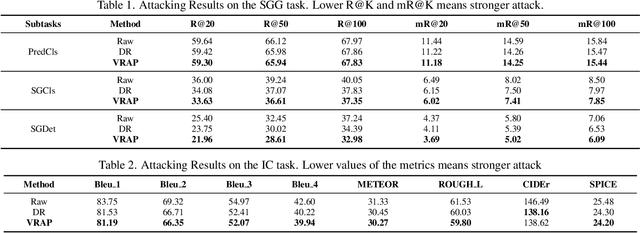
The transferability of adversarial examples is a crucial aspect of evaluating the robustness of deep learning systems, particularly in black-box scenarios. Although several methods have been proposed to enhance cross-model transferability, little attention has been paid to the transferability of adversarial examples across different tasks. This issue has become increasingly relevant with the emergence of foundational multi-task AI systems such as Visual ChatGPT, rendering the utility of adversarial samples generated by a single task relatively limited. Furthermore, these systems often entail inferential functions beyond mere recognition-like tasks. To address this gap, we propose a novel Visual Relation-based cross-task Adversarial Patch generation method called VRAP, which aims to evaluate the robustness of various visual tasks, especially those involving visual reasoning, such as Visual Question Answering and Image Captioning. VRAP employs scene graphs to combine object recognition-based deception with predicate-based relations elimination, thereby disrupting the visual reasoning information shared among inferential tasks. Our extensive experiments demonstrate that VRAP significantly surpasses previous methods in terms of black-box transferability across diverse visual reasoning tasks.
Pointless Global Bundle Adjustment With Relative Motions Hessians
Apr 11, 2023Bundle adjustment (BA) is the standard way to optimise camera poses and to produce sparse representations of a scene. However, as the number of camera poses and features grows, refinement through bundle adjustment becomes inefficient. Inspired by global motion averaging methods, we propose a new bundle adjustment objective which does not rely on image features' reprojection errors yet maintains precision on par with classical BA. Our method averages over relative motions while implicitly incorporating the contribution of the structure in the adjustment. To that end, we weight the objective function by local hessian matrices - a by-product of local bundle adjustments performed on relative motions (e.g., pairs or triplets) during the pose initialisation step. Such hessians are extremely rich as they encapsulate both the features' random errors and the geometric configuration between the cameras. These pieces of information propagated to the global frame help to guide the final optimisation in a more rigorous way. We argue that this approach is an upgraded version of the motion averaging approach and demonstrate its effectiveness on both photogrammetric datasets and computer vision benchmarks.
MOST: Multiple Object localization with Self-supervised Transformers for object discovery
Apr 11, 2023
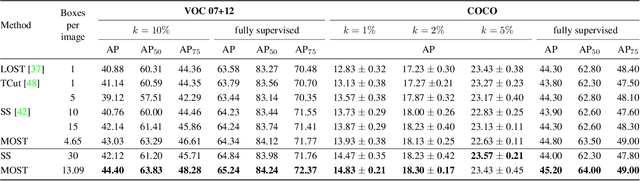
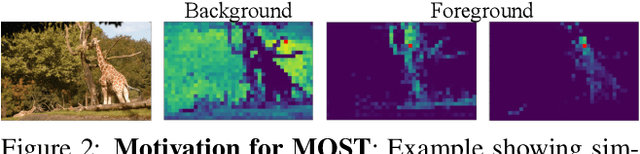
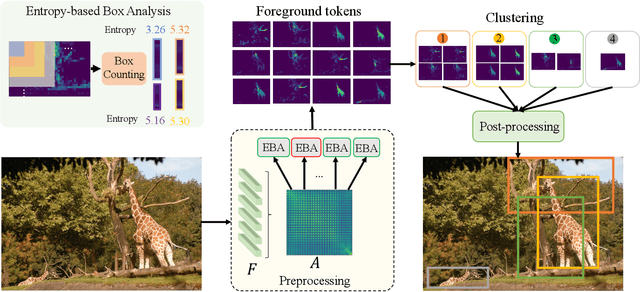
We tackle the challenging task of unsupervised object localization in this work. Recently, transformers trained with self-supervised learning have been shown to exhibit object localization properties without being trained for this task. In this work, we present Multiple Object localization with Self-supervised Transformers (MOST) that uses features of transformers trained using self-supervised learning to localize multiple objects in real world images. MOST analyzes the similarity maps of the features using box counting; a fractal analysis tool to identify tokens lying on foreground patches. The identified tokens are then clustered together, and tokens of each cluster are used to generate bounding boxes on foreground regions. Unlike recent state-of-the-art object localization methods, MOST can localize multiple objects per image and outperforms SOTA algorithms on several object localization and discovery benchmarks on PASCAL-VOC 07, 12 and COCO20k datasets. Additionally, we show that MOST can be used for self-supervised pre-training of object detectors, and yields consistent improvements on fully, semi-supervised object detection and unsupervised region proposal generation.