 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
MOST: Multiple Object localization with Self-supervised Transformers for object discovery
Apr 11, 2023

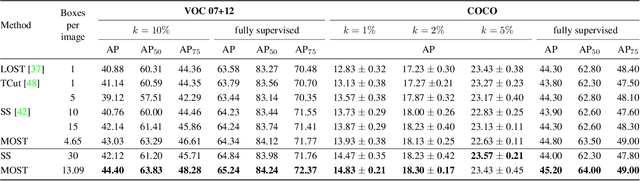
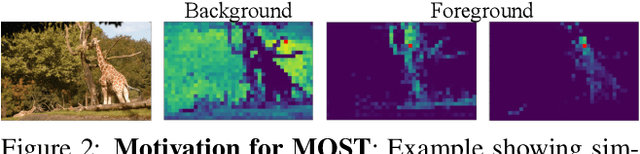
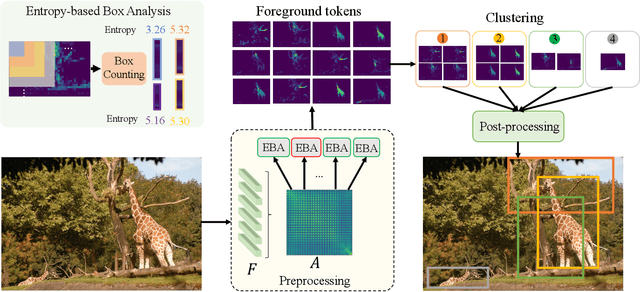
We tackle the challenging task of unsupervised object localization in this work. Recently, transformers trained with self-supervised learning have been shown to exhibit object localization properties without being trained for this task. In this work, we present Multiple Object localization with Self-supervised Transformers (MOST) that uses features of transformers trained using self-supervised learning to localize multiple objects in real world images. MOST analyzes the similarity maps of the features using box counting; a fractal analysis tool to identify tokens lying on foreground patches. The identified tokens are then clustered together, and tokens of each cluster are used to generate bounding boxes on foreground regions. Unlike recent state-of-the-art object localization methods, MOST can localize multiple objects per image and outperforms SOTA algorithms on several object localization and discovery benchmarks on PASCAL-VOC 07, 12 and COCO20k datasets. Additionally, we show that MOST can be used for self-supervised pre-training of object detectors, and yields consistent improvements on fully, semi-supervised object detection and unsupervised region proposal generation.
The MONET dataset: Multimodal drone thermal dataset recorded in rural scenarios
Apr 11, 2023
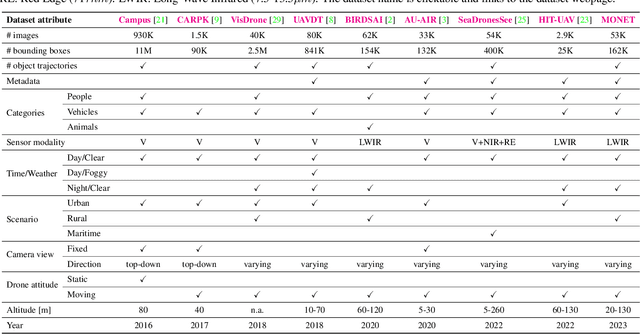
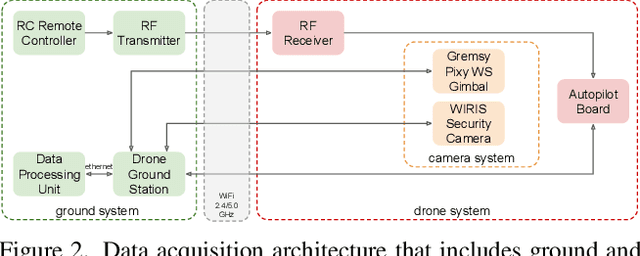
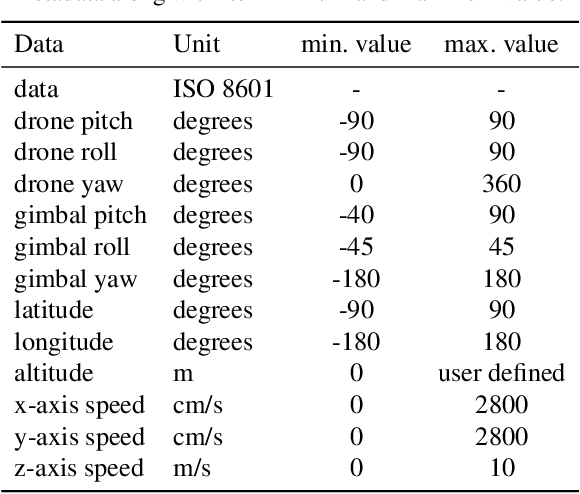
We present MONET, a new multimodal dataset captured using a thermal camera mounted on a drone that flew over rural areas, and recorded human and vehicle activities. We captured MONET to study the problem of object localisation and behaviour understanding of targets undergoing large-scale variations and being recorded from different and moving viewpoints. Target activities occur in two different land sites, each with unique scene structures and cluttered backgrounds. MONET consists of approximately 53K images featuring 162K manually annotated bounding boxes. Each image is timestamp-aligned with drone metadata that includes information about attitudes, speed, altitude, and GPS coordinates. MONET is different from previous thermal drone datasets because it features multimodal data, including rural scenes captured with thermal cameras containing both person and vehicle targets, along with trajectory information and metadata. We assessed the difficulty of the dataset in terms of transfer learning between the two sites and evaluated nine object detection algorithms to identify the open challenges associated with this type of data. Project page: https://github.com/fabiopoiesi/monet_dataset.
Boosting Cross-task Transferability of Adversarial Patches with Visual Relations
Apr 11, 2023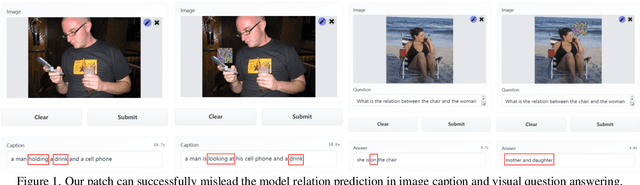
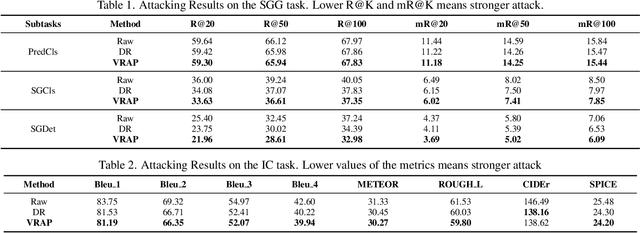
The transferability of adversarial examples is a crucial aspect of evaluating the robustness of deep learning systems, particularly in black-box scenarios. Although several methods have been proposed to enhance cross-model transferability, little attention has been paid to the transferability of adversarial examples across different tasks. This issue has become increasingly relevant with the emergence of foundational multi-task AI systems such as Visual ChatGPT, rendering the utility of adversarial samples generated by a single task relatively limited. Furthermore, these systems often entail inferential functions beyond mere recognition-like tasks. To address this gap, we propose a novel Visual Relation-based cross-task Adversarial Patch generation method called VRAP, which aims to evaluate the robustness of various visual tasks, especially those involving visual reasoning, such as Visual Question Answering and Image Captioning. VRAP employs scene graphs to combine object recognition-based deception with predicate-based relations elimination, thereby disrupting the visual reasoning information shared among inferential tasks. Our extensive experiments demonstrate that VRAP significantly surpasses previous methods in terms of black-box transferability across diverse visual reasoning tasks.
Pointless Global Bundle Adjustment With Relative Motions Hessians
Apr 11, 2023Bundle adjustment (BA) is the standard way to optimise camera poses and to produce sparse representations of a scene. However, as the number of camera poses and features grows, refinement through bundle adjustment becomes inefficient. Inspired by global motion averaging methods, we propose a new bundle adjustment objective which does not rely on image features' reprojection errors yet maintains precision on par with classical BA. Our method averages over relative motions while implicitly incorporating the contribution of the structure in the adjustment. To that end, we weight the objective function by local hessian matrices - a by-product of local bundle adjustments performed on relative motions (e.g., pairs or triplets) during the pose initialisation step. Such hessians are extremely rich as they encapsulate both the features' random errors and the geometric configuration between the cameras. These pieces of information propagated to the global frame help to guide the final optimisation in a more rigorous way. We argue that this approach is an upgraded version of the motion averaging approach and demonstrate its effectiveness on both photogrammetric datasets and computer vision benchmarks.
Robustmix: Improving Robustness by Regularizing the Frequency Bias of Deep Nets
Apr 06, 2023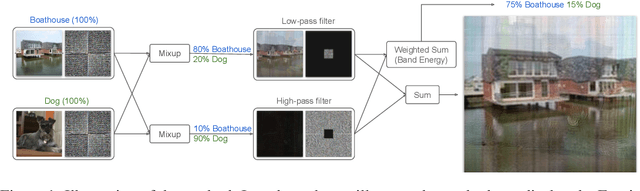
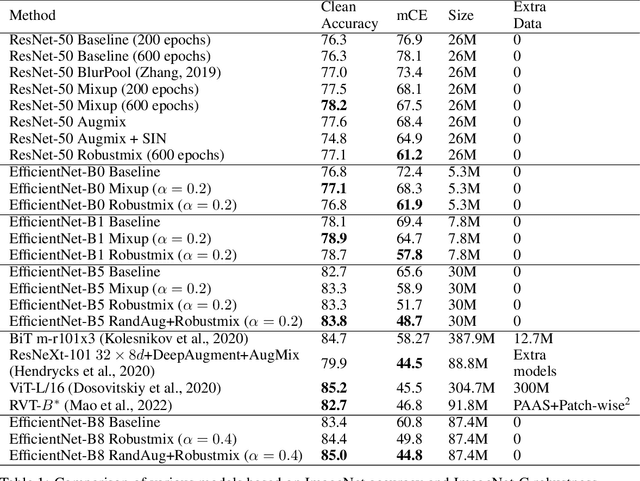
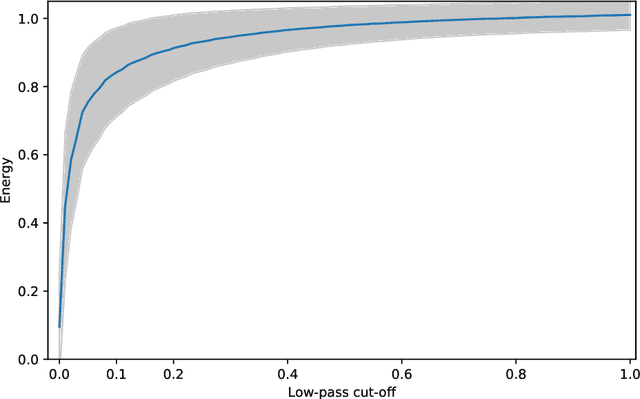
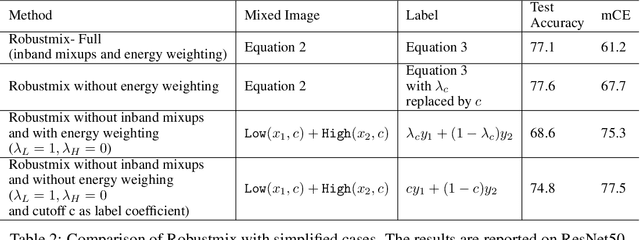
Deep networks have achieved impressive results on a range of well-curated benchmark datasets. Surprisingly, their performance remains sensitive to perturbations that have little effect on human performance. In this work, we propose a novel extension of Mixup called Robustmix that regularizes networks to classify based on lower-frequency spatial features. We show that this type of regularization improves robustness on a range of benchmarks such as Imagenet-C and Stylized Imagenet. It adds little computational overhead and, furthermore, does not require a priori knowledge of a large set of image transformations. We find that this approach further complements recent advances in model architecture and data augmentation, attaining a state-of-the-art mCE of 44.8 with an EfficientNet-B8 model and RandAugment, which is a reduction of 16 mCE compared to the baseline.
GI Software with fewer Data Cache Misses
Apr 06, 2023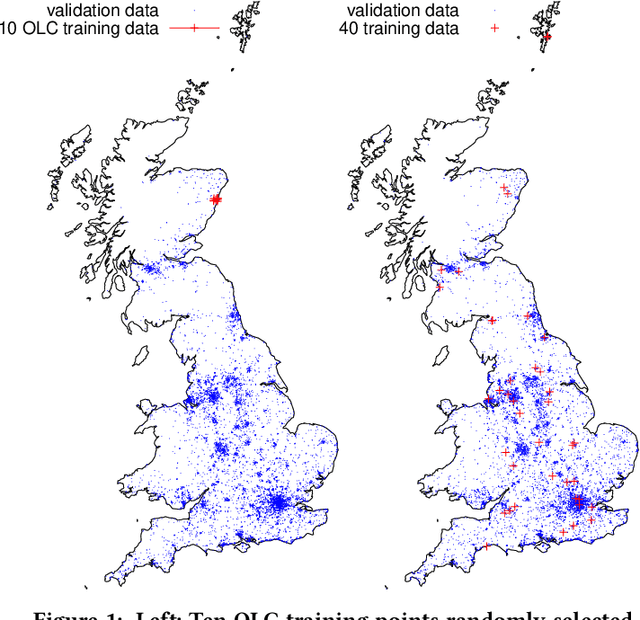
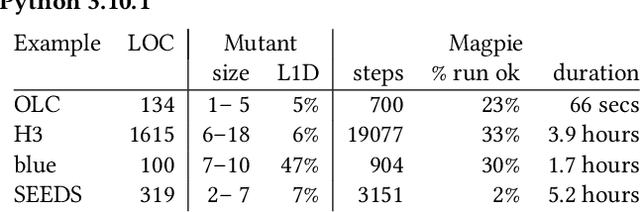

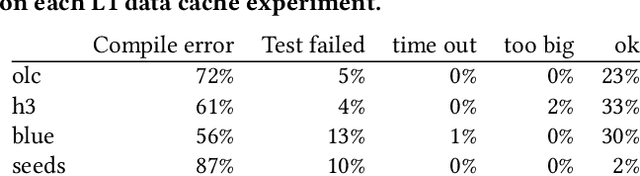
By their very name caches are often overlooked and yet play a vital role in the performance of modern and indeed future hardware. Using MAGPIE (Machine Automated General Performance Improvement via Evolution of software) we show genetic improvement GI can reduce the cache load of existing computer programs. Operating on lines of C and C++ source code using local search, Magpie can generate new functionally equivalent variants which generate fewer L1 data cache misses. Cache miss reduction is tested on two industrial open source programs (Google's Open Location Code OLC and Uber's Hexagonal Hierarchical Spatial Index H3) and two 2D photograph image processing tasks, counting pixels and OpenCV's SEEDS segmentation algorithm. Magpie's patches functionally generalise. In one case they reduce data misses on the highest performance L1 cache dramatically by 47 percent.
Multi-Linear Kernel Regression and Imputation in Data Manifolds
Apr 06, 2023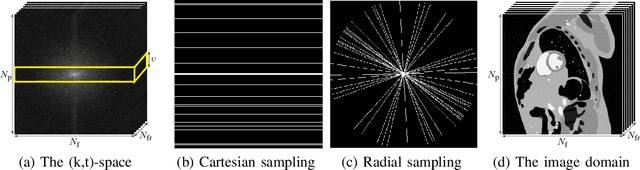
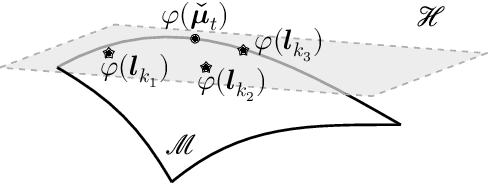
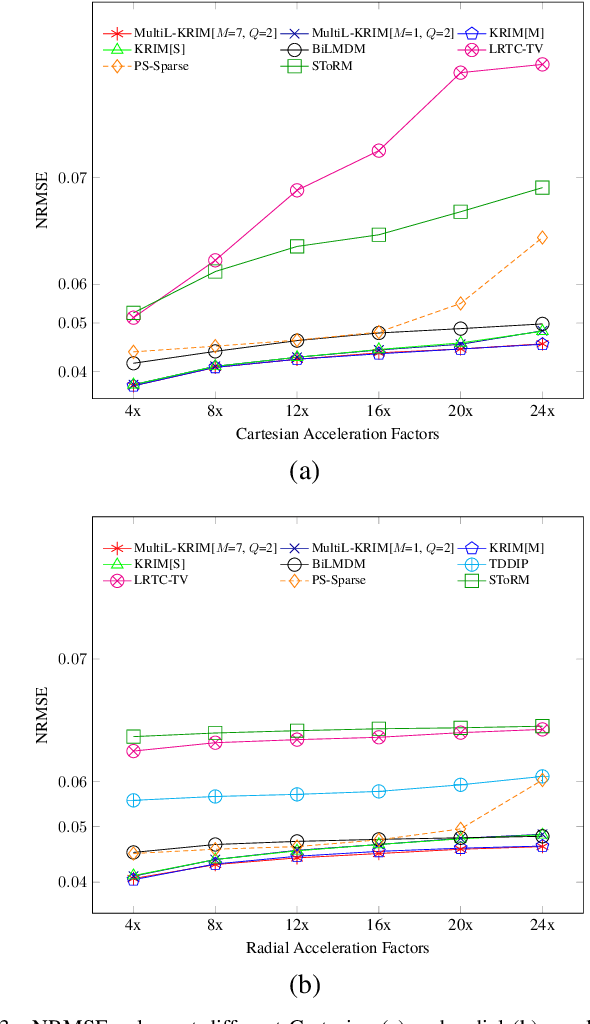
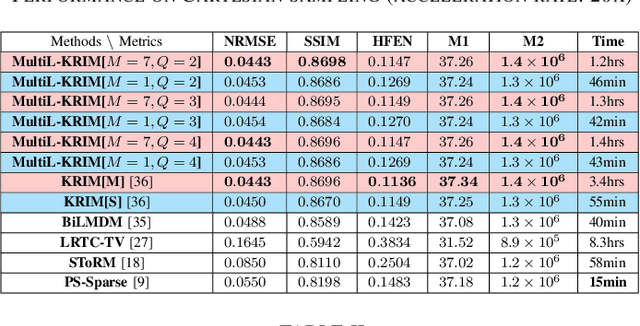
This paper introduces an efficient multi-linear nonparametric (kernel-based) approximation framework for data regression and imputation, and its application to dynamic magnetic-resonance imaging (dMRI). Data features are assumed to reside in or close to a smooth manifold embedded in a reproducing kernel Hilbert space. Landmark points are identified to describe concisely the point cloud of features by linear approximating patches which mimic the concept of tangent spaces to smooth manifolds. The multi-linear model effects dimensionality reduction, enables efficient computations, and extracts data patterns and their geometry without any training data or additional information. Numerical tests on dMRI data under severe under-sampling demonstrate remarkable improvements in efficiency and accuracy of the proposed approach over its predecessors, popular data modeling methods, as well as recent tensor-based and deep-image-prior schemes.
Bridging Component Learning with Degradation Modelling for Blind Image Super-Resolution
Dec 03, 2022
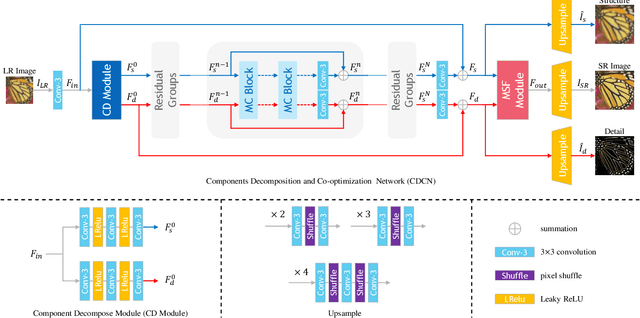
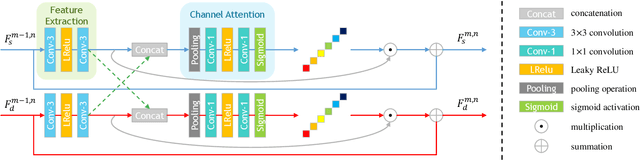
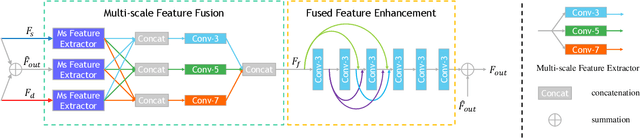
Convolutional Neural Network (CNN)-based image super-resolution (SR) has exhibited impressive success on known degraded low-resolution (LR) images. However, this type of approach is hard to hold its performance in practical scenarios when the degradation process is unknown. Despite existing blind SR methods proposed to solve this problem using blur kernel estimation, the perceptual quality and reconstruction accuracy are still unsatisfactory. In this paper, we analyze the degradation of a high-resolution (HR) image from image intrinsic components according to a degradation-based formulation model. We propose a components decomposition and co-optimization network (CDCN) for blind SR. Firstly, CDCN decomposes the input LR image into structure and detail components in feature space. Then, the mutual collaboration block (MCB) is presented to exploit the relationship between both two components. In this way, the detail component can provide informative features to enrich the structural context and the structure component can carry structural context for better detail revealing via a mutual complementary manner. After that, we present a degradation-driven learning strategy to jointly supervise the HR image detail and structure restoration process. Finally, a multi-scale fusion module followed by an upsampling layer is designed to fuse the structure and detail features and perform SR reconstruction. Empowered by such degradation-based components decomposition, collaboration, and mutual optimization, we can bridge the correlation between component learning and degradation modelling for blind SR, thereby producing SR results with more accurate textures. Extensive experiments on both synthetic SR datasets and real-world images show that the proposed method achieves the state-of-the-art performance compared to existing methods.
TinyDet: Accurate Small Object Detection in Lightweight Generic Detectors
Apr 07, 2023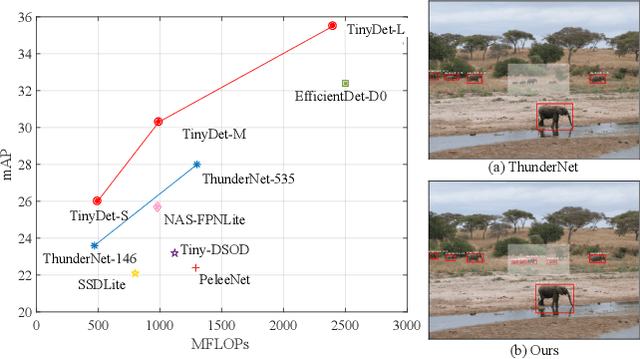
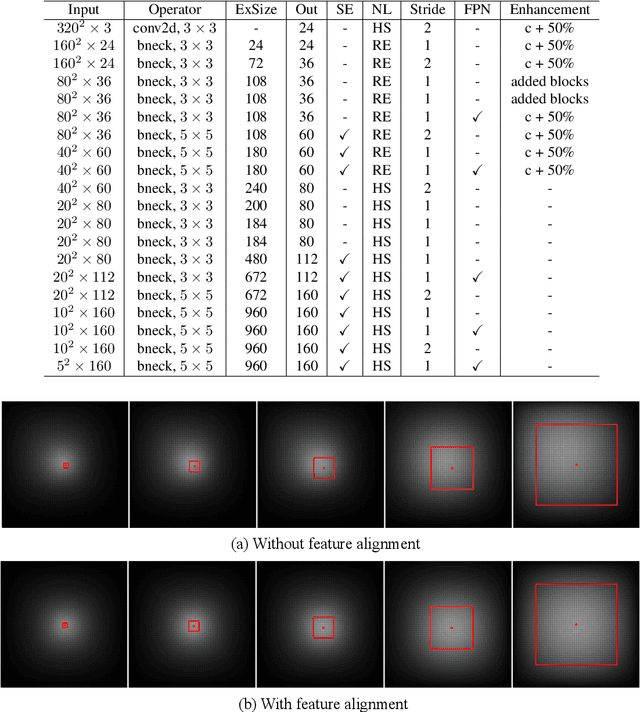
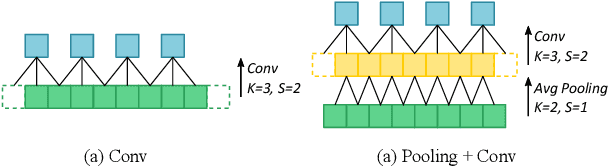
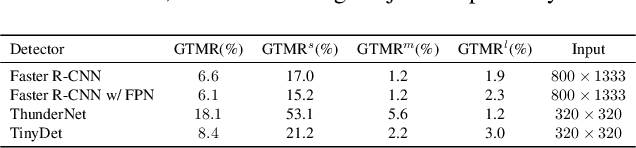
Small object detection requires the detection head to scan a large number of positions on image feature maps, which is extremely hard for computation- and energy-efficient lightweight generic detectors. To accurately detect small objects with limited computation, we propose a two-stage lightweight detection framework with extremely low computation complexity, termed as TinyDet. It enables high-resolution feature maps for dense anchoring to better cover small objects, proposes a sparsely-connected convolution for computation reduction, enhances the early stage features in the backbone, and addresses the feature misalignment problem for accurate small object detection. On the COCO benchmark, our TinyDet-M achieves 30.3 AP and 13.5 AP^s with only 991 MFLOPs, which is the first detector that has an AP over 30 with less than 1 GFLOPs; besides, TinyDet-S and TinyDet-L achieve promising performance under different computation limitation.
Towards Tumour Graph Learning for Survival Prediction in Head & Neck Cancer Patients
Apr 17, 2023With nearly one million new cases diagnosed worldwide in 2020, head \& neck cancer is a deadly and common malignity. There are challenges to decision making and treatment of such cancer, due to lesions in multiple locations and outcome variability between patients. Therefore, automated segmentation and prognosis estimation approaches can help ensure each patient gets the most effective treatment. This paper presents a framework to perform these functions on arbitrary field of view (FoV) PET and CT registered scans, thus approaching tasks 1 and 2 of the HECKTOR 2022 challenge as team \texttt{VokCow}. The method consists of three stages: localization, segmentation and survival prediction. First, the scans with arbitrary FoV are cropped to the head and neck region and a u-shaped convolutional neural network (CNN) is trained to segment the region of interest. Then, using the obtained regions, another CNN is combined with a support vector machine classifier to obtain the semantic segmentation of the tumours, which results in an aggregated Dice score of 0.57 in task 1. Finally, survival prediction is approached with an ensemble of Weibull accelerated failure times model and deep learning methods. In addition to patient health record data, we explore whether processing graphs of image patches centred at the tumours via graph convolutions can improve the prognostic predictions. A concordance index of 0.64 was achieved in the test set, ranking 6th in the challenge leaderboard for this task.