 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
ObjectCompose: Evaluating Resilience of Vision-Based Models on Object-to-Background Compositional Changes
Mar 15, 2024

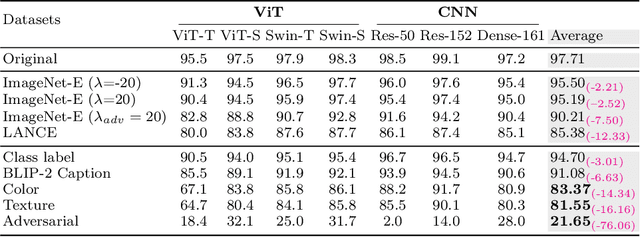
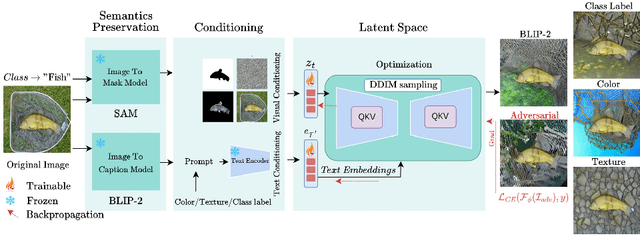
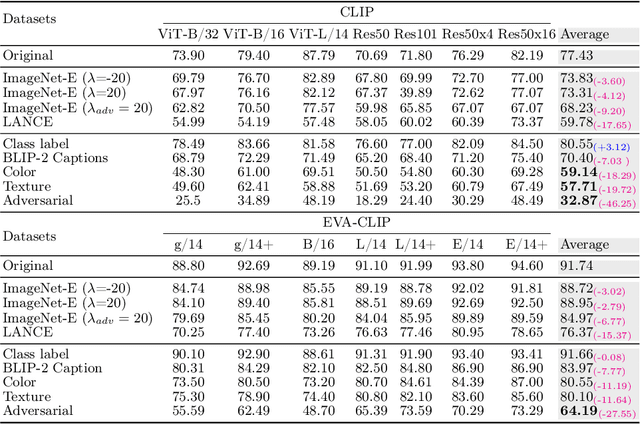
Given the large-scale multi-modal training of recent vision-based models and their generalization capabilities, understanding the extent of their robustness is critical for their real-world deployment. In this work, we evaluate the resilience of current vision-based models against diverse object-to-background context variations. The majority of robustness evaluation methods have introduced synthetic datasets to induce changes to object characteristics (viewpoints, scale, color) or utilized image transformation techniques (adversarial changes, common corruptions) on real images to simulate shifts in distributions. Recent works have explored leveraging large language models and diffusion models to generate changes in the background. However, these methods either lack in offering control over the changes to be made or distort the object semantics, making them unsuitable for the task. Our method, on the other hand, can induce diverse object-to-background changes while preserving the original semantics and appearance of the object. To achieve this goal, we harness the generative capabilities of text-to-image, image-to-text, and image-to-segment models to automatically generate a broad spectrum of object-to-background changes. We induce both natural and adversarial background changes by either modifying the textual prompts or optimizing the latents and textual embedding of text-to-image models. This allows us to quantify the role of background context in understanding the robustness and generalization of deep neural networks. We produce various versions of standard vision datasets (ImageNet, COCO), incorporating either diverse and realistic backgrounds into the images or introducing color, texture, and adversarial changes in the background. We conduct extensive experiment to analyze the robustness of vision-based models against object-to-background context variations across diverse tasks.
Robust NAS under adversarial training: benchmark, theory, and beyond
Mar 19, 2024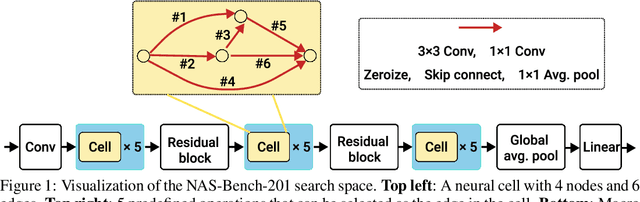
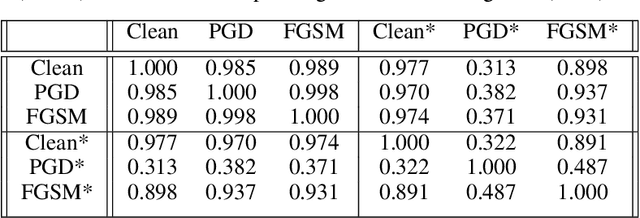
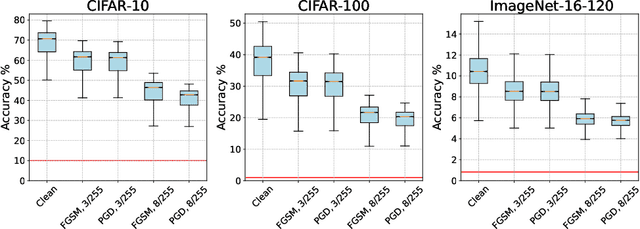
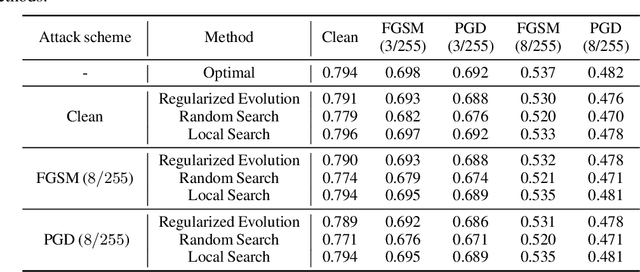
Recent developments in neural architecture search (NAS) emphasize the significance of considering robust architectures against malicious data. However, there is a notable absence of benchmark evaluations and theoretical guarantees for searching these robust architectures, especially when adversarial training is considered. In this work, we aim to address these two challenges, making twofold contributions. First, we release a comprehensive data set that encompasses both clean accuracy and robust accuracy for a vast array of adversarially trained networks from the NAS-Bench-201 search space on image datasets. Then, leveraging the neural tangent kernel (NTK) tool from deep learning theory, we establish a generalization theory for searching architecture in terms of clean accuracy and robust accuracy under multi-objective adversarial training. We firmly believe that our benchmark and theoretical insights will significantly benefit the NAS community through reliable reproducibility, efficient assessment, and theoretical foundation, particularly in the pursuit of robust architectures.
Structure Similarity Preservation Learning for Asymmetric Image Retrieval
Mar 01, 2024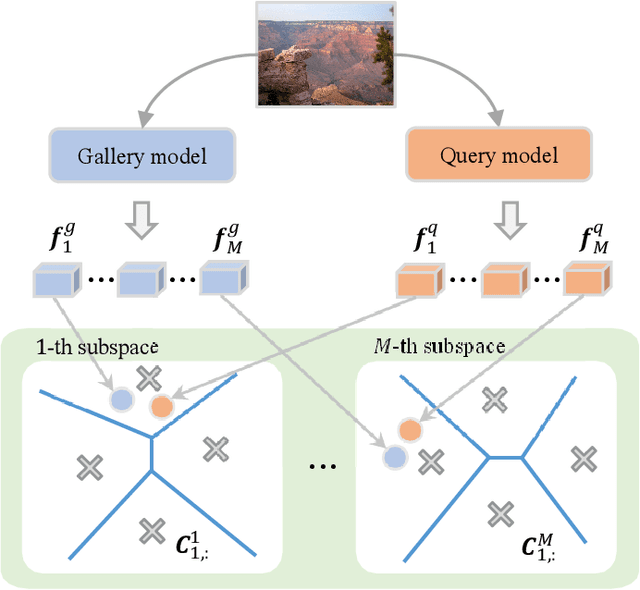
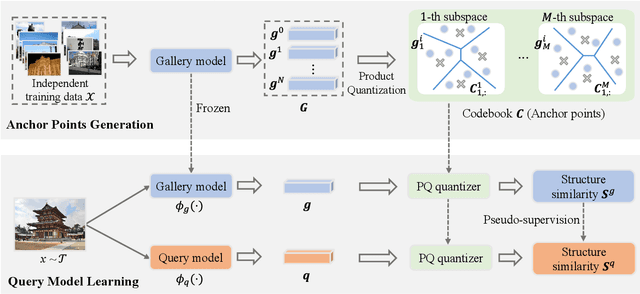
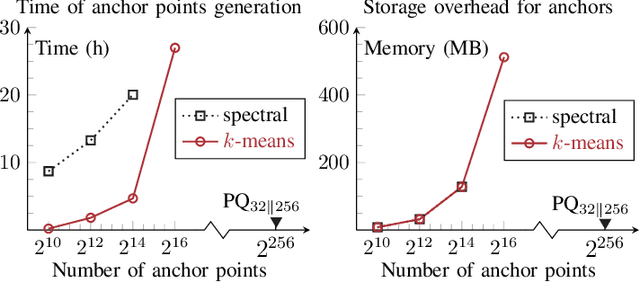
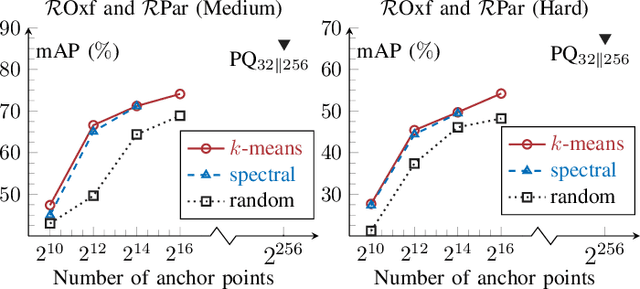
Asymmetric image retrieval is a task that seeks to balance retrieval accuracy and efficiency by leveraging lightweight and large models for the query and gallery sides, respectively. The key to asymmetric image retrieval is realizing feature compatibility between different models. Despite the great progress, most existing approaches either rely on classifiers inherited from gallery models or simply impose constraints at the instance level, ignoring the structure of embedding space. In this work, we propose a simple yet effective structure similarity preserving method to achieve feature compatibility between query and gallery models. Specifically, we first train a product quantizer offline with the image features embedded by the gallery model. The centroid vectors in the quantizer serve as anchor points in the embedding space of the gallery model to characterize its structure. During the training of the query model, anchor points are shared by the query and gallery models. The relationships between image features and centroid vectors are considered as structure similarities and constrained to be consistent. Moreover, our approach makes no assumption about the existence of any labeled training data and thus can be extended to an unlimited amount of data. Comprehensive experiments on large-scale landmark retrieval demonstrate the effectiveness of our approach. Our code is released at: https://github.com/MCC-WH/SSP.
Adversarial Testing for Visual Grounding via Image-Aware Property Reduction
Mar 02, 2024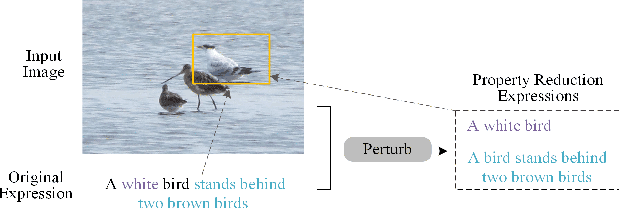

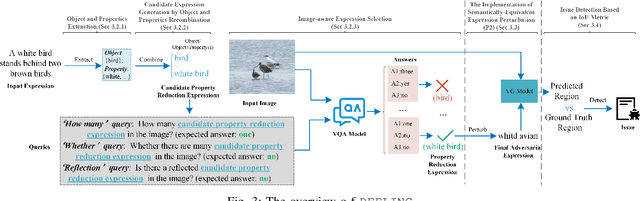

Due to the advantages of fusing information from various modalities, multimodal learning is gaining increasing attention. Being a fundamental task of multimodal learning, Visual Grounding (VG), aims to locate objects in images through natural language expressions. Ensuring the quality of VG models presents significant challenges due to the complex nature of the task. In the black box scenario, existing adversarial testing techniques often fail to fully exploit the potential of both modalities of information. They typically apply perturbations based solely on either the image or text information, disregarding the crucial correlation between the two modalities, which would lead to failures in test oracles or an inability to effectively challenge VG models. To this end, we propose PEELING, a text perturbation approach via image-aware property reduction for adversarial testing of the VG model. The core idea is to reduce the property-related information in the original expression meanwhile ensuring the reduced expression can still uniquely describe the original object in the image. To achieve this, PEELING first conducts the object and properties extraction and recombination to generate candidate property reduction expressions. It then selects the satisfied expressions that accurately describe the original object while ensuring no other objects in the image fulfill the expression, through querying the image with a visual understanding technique. We evaluate PEELING on the state-of-the-art VG model, i.e. OFA-VG, involving three commonly used datasets. Results show that the adversarial tests generated by PEELING achieves 21.4% in MultiModal Impact score (MMI), and outperforms state-of-the-art baselines for images and texts by 8.2%--15.1%.
Anatomical Structure-Guided Medical Vision-Language Pre-training
Mar 14, 2024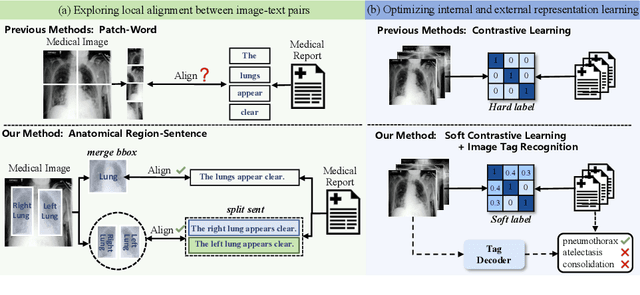
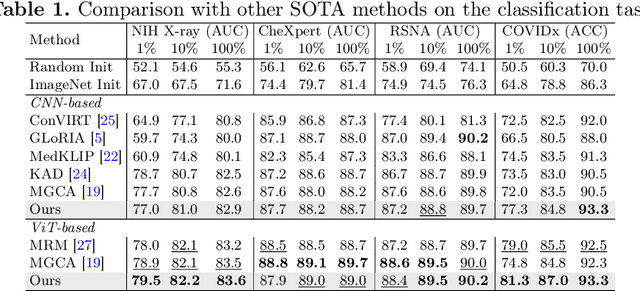
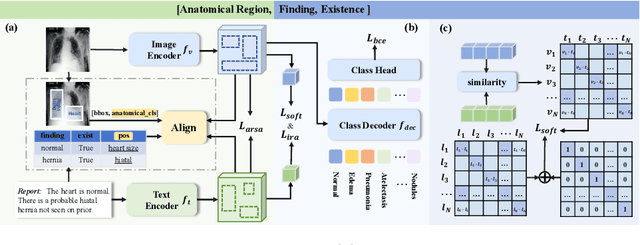
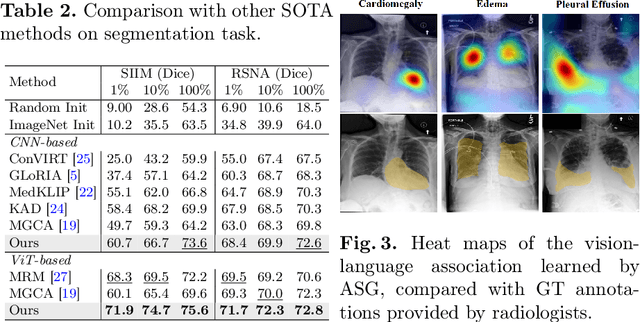
Learning medical visual representations through vision-language pre-training has reached remarkable progress. Despite the promising performance, it still faces challenges, i.e., local alignment lacks interpretability and clinical relevance, and the insufficient internal and external representation learning of image-report pairs. To address these issues, we propose an Anatomical Structure-Guided (ASG) framework. Specifically, we parse raw reports into triplets <anatomical region, finding, existence>, and fully utilize each element as supervision to enhance representation learning. For anatomical region, we design an automatic anatomical region-sentence alignment paradigm in collaboration with radiologists, considering them as the minimum semantic units to explore fine-grained local alignment. For finding and existence, we regard them as image tags, applying an image-tag recognition decoder to associate image features with their respective tags within each sample and constructing soft labels for contrastive learning to improve the semantic association of different image-report pairs. We evaluate the proposed ASG framework on two downstream tasks, including five public benchmarks. Experimental results demonstrate that our method outperforms the state-of-the-art methods.
Visual Decoding and Reconstruction via EEG Embeddings with Guided Diffusion
Mar 14, 2024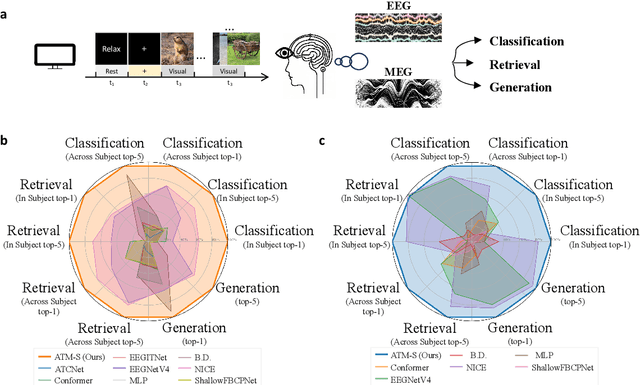
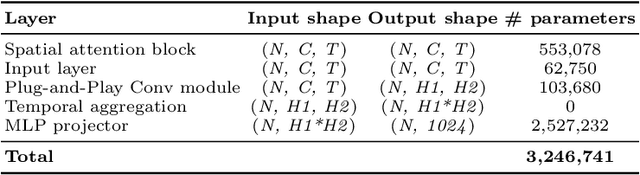
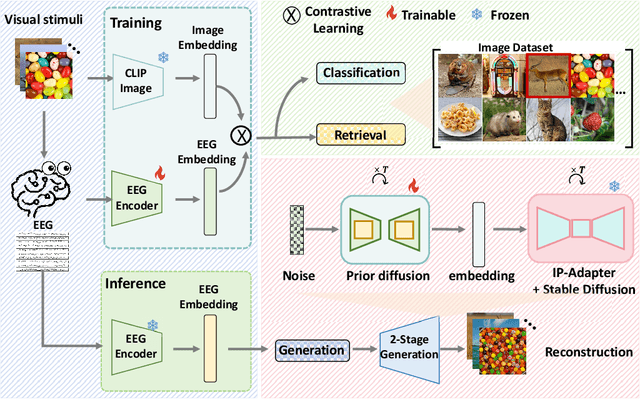

How to decode human vision through neural signals has attracted a long-standing interest in neuroscience and machine learning. Modern contrastive learning and generative models improved the performance of fMRI-based visual decoding and reconstruction. However, the high cost and low temporal resolution of fMRI limit their applications in brain-computer interfaces (BCIs), prompting a high need for EEG-based visual reconstruction. In this study, we present an EEG-based visual reconstruction framework. It consists of a plug-and-play EEG encoder called the Adaptive Thinking Mapper (ATM), which is aligned with image embeddings, and a two-stage EEG guidance image generator that first transforms EEG features into image priors and then reconstructs the visual stimuli with a pre-trained image generator. Our approach allows EEG embeddings to achieve superior performance in image classification and retrieval tasks. Our two-stage image generation strategy vividly reconstructs images seen by humans. Furthermore, we analyzed the impact of signals from different time windows and brain regions on decoding and reconstruction. The versatility of our framework is demonstrated in the magnetoencephalogram (MEG) data modality. We report that EEG-based visual decoding achieves SOTA performance, highlighting the portability, low cost, and high temporal resolution of EEG, enabling a wide range of BCI applications. The code of ATM is available at https://github.com/dongyangli-del/EEG_Image_decode.
Artifact Feature Purification for Cross-domain Detection of AI-generated Images
Mar 17, 2024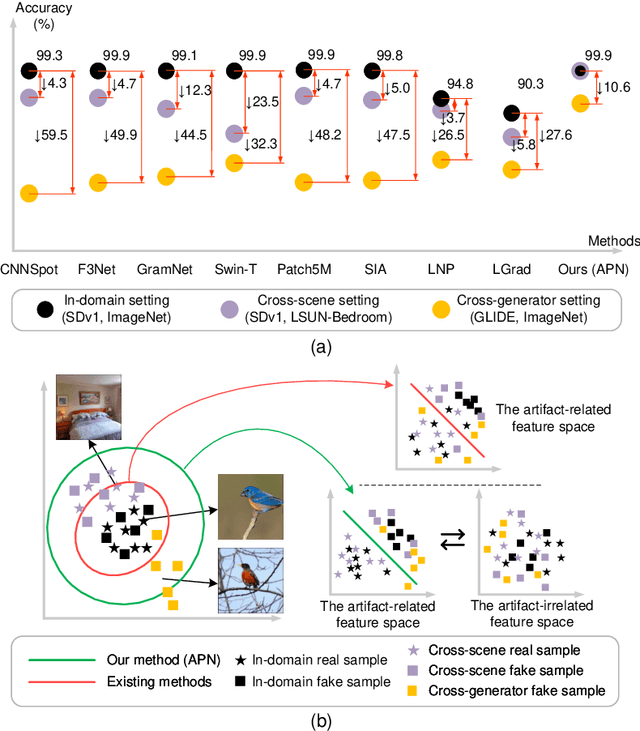
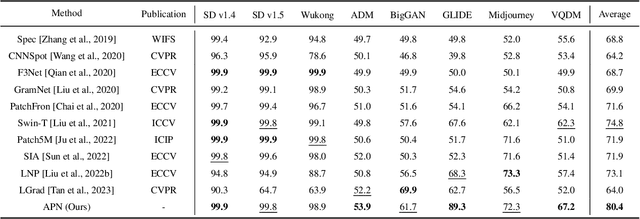
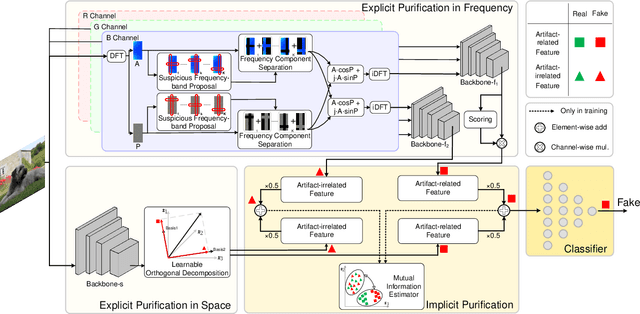
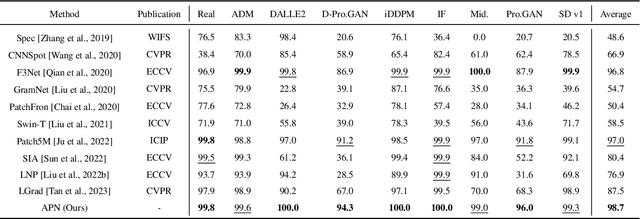
In the era of AIGC, the fast development of visual content generation technologies, such as diffusion models, bring potential security risks to our society. Existing generated image detection methods suffer from performance drop when faced with out-of-domain generators and image scenes. To relieve this problem, we propose Artifact Purification Network (APN) to facilitate the artifact extraction from generated images through the explicit and implicit purification processes. For the explicit one, a suspicious frequency-band proposal method and a spatial feature decomposition method are proposed to extract artifact-related features. For the implicit one, a training strategy based on mutual information estimation is proposed to further purify the artifact-related features. Experiments show that for cross-generator detection, the average accuracy of APN is 5.6% ~ 16.4% higher than the previous 10 methods on GenImage dataset and 1.7% ~ 50.1% on DiffusionForensics dataset. For cross-scene detection, APN maintains its high performance. Via visualization analysis, we find that the proposed method extracts flexible forgery patterns and condenses the forgery information diluted in irrelevant features. We also find that the artifact features APN focuses on across generators and scenes are global and diverse. The code will be available on GitHub.
Ensembling and Test Augmentation for Covid-19 Detection and Covid-19 Domain Adaptation from 3D CT-Scans
Mar 17, 2024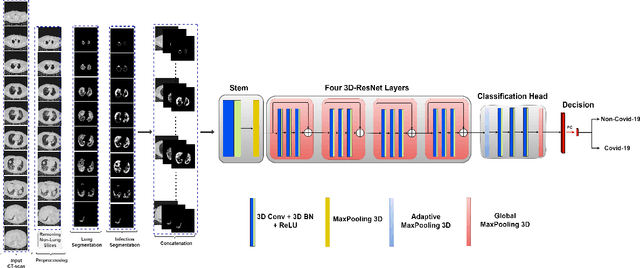



Since the emergence of Covid-19 in late 2019, medical image analysis using artificial intelligence (AI) has emerged as a crucial research area, particularly with the utility of CT-scan imaging for disease diagnosis. This paper contributes to the 4th COV19D competition, focusing on Covid-19 Detection and Covid-19 Domain Adaptation Challenges. Our approach centers on lung segmentation and Covid-19 infection segmentation employing the recent CNN-based segmentation architecture PDAtt-Unet, which simultaneously segments lung regions and infections. Departing from traditional methods, we concatenate the input slice (grayscale) with segmented lung and infection, generating three input channels akin to color channels. Additionally, we employ three 3D CNN backbones Customized Hybrid-DeCoVNet, along with pretrained 3D-Resnet-18 and 3D-Resnet-50 models to train Covid-19 recognition for both challenges. Furthermore, we explore ensemble approaches and testing augmentation to enhance performance. Comparison with baseline results underscores the substantial efficiency of our approach, with a significant margin in terms of F1-score (14 %). This study advances the field by presenting a comprehensive methodology for accurate Covid-19 detection and adaptation, leveraging cutting-edge AI techniques in medical image analysis.
Image-Guided Autonomous Guidewire Navigation in Robot-Assisted Endovascular Interventions using Reinforcement Learning
Mar 09, 2024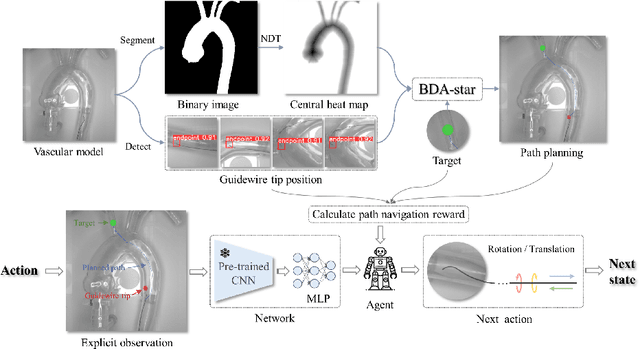
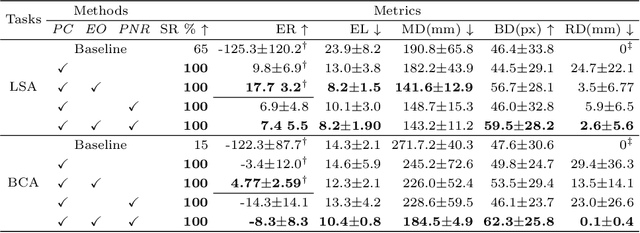

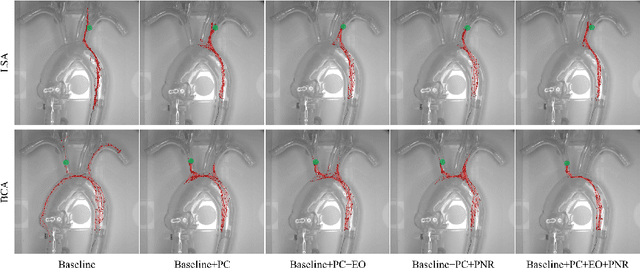
Autonomous robots in endovascular interventions possess the potential to navigate guidewires with safety and reliability, while reducing human error and shortening surgical time. However, current methods of guidewire navigation based on Reinforcement Learning (RL) depend on manual demonstration data or magnetic guidance. In this work, we propose an Image-guided Autonomous Guidewire Navigation (IAGN) method. Specifically, we introduce BDA-star, a path planning algorithm with boundary distance constraints, for the trajectory planning of guidewire navigation. We established an IAGN-RL environment where the observations are real-time guidewire feeding images highlighting the position of the guidewire tip and the planned path. We proposed a reward function based on the distances from both the guidewire tip to the planned path and the target to evaluate the agent's actions. Furthermore, in policy network, we employ a pre-trained convolutional neural network to extract features, mitigating stability issues and slow convergence rates associated with direct learning from raw pixels. Experiments conducted on the aortic simulation IAGN platform demonstrated that the proposed method, targeting the left subclavian artery and the brachiocephalic artery, achieved a 100% guidewire navigation success rate, along with reduced movement and retraction distances and trajectories tend to the center of the vessels.
An Image is Worth 1/2 Tokens After Layer 2: Plug-and-Play Inference Acceleration for Large Vision-Language Models
Mar 11, 2024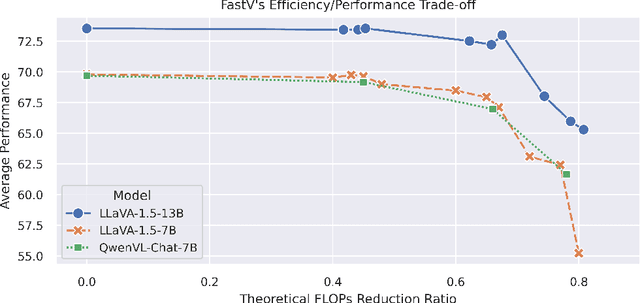
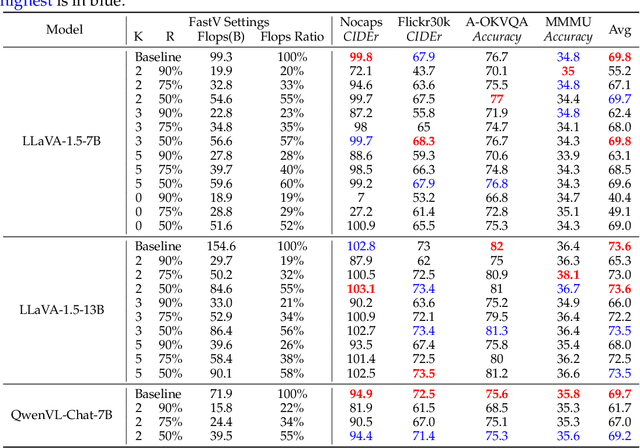
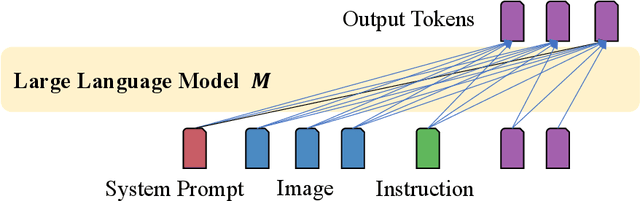

In this study, we identify the inefficient attention phenomena in Large Vision-Language Models (LVLMs), notably within prominent models like LLaVA-1.5, QwenVL-Chat and Video-LLaVA. We find out that the attention computation over visual tokens is of extreme inefficiency in the deep layers of popular LVLMs, suggesting a need for a sparser approach compared to textual data handling. To this end, we introduce FastV, a versatile plug-and-play method designed to optimize computational efficiency by learning adaptive attention patterns in early layers and pruning visual tokens in subsequent ones. Our evaluations demonstrate FastV's ability to dramatically reduce computational costs (e.g., a 45 reduction in FLOPs for LLaVA-1.5-13B) without sacrificing performance in a wide range of image and video understanding tasks. The computational efficiency and performance trade-off of FastV are highly customizable and pareto-efficient. It can compress the FLOPs of a 13B-parameter model to achieve a lower budget than that of a 7B-parameter model, while still maintaining superior performance. We believe FastV has practical values for deployment of LVLMs in edge devices and commercial models. Code is released at https://github.com/pkunlp-icler/FastV.