 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
The challenge of representation learning: Improved accuracy in deep vision models does not come with better predictions of perceptual similarity
Mar 13, 2023
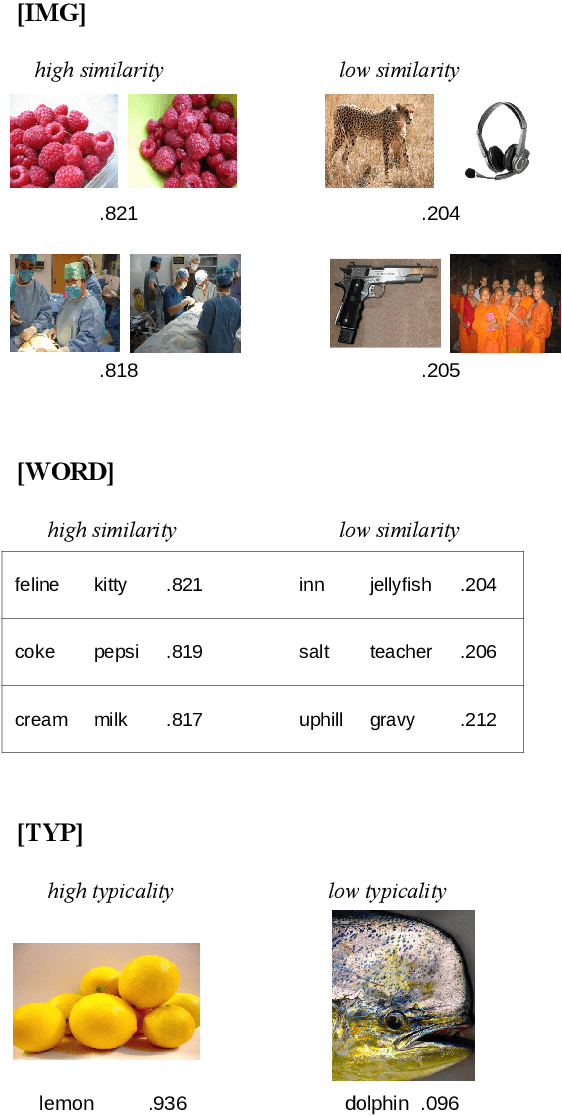
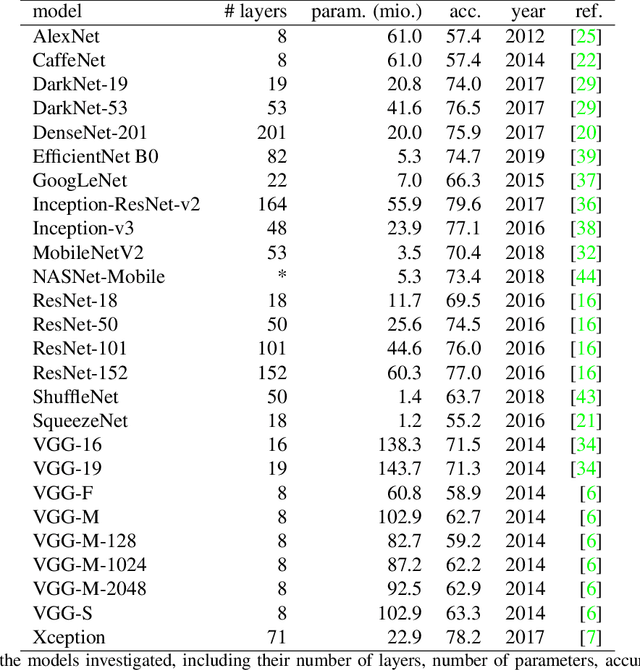
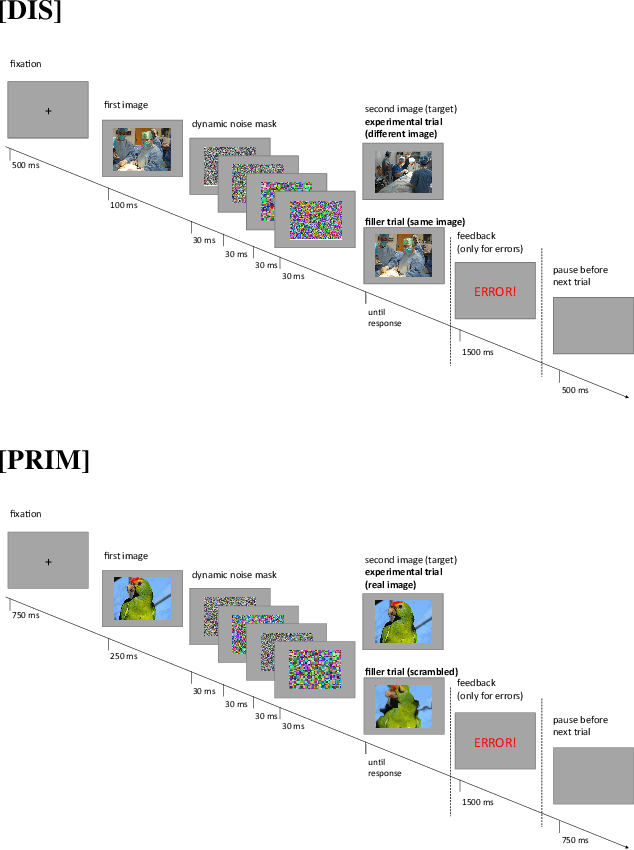
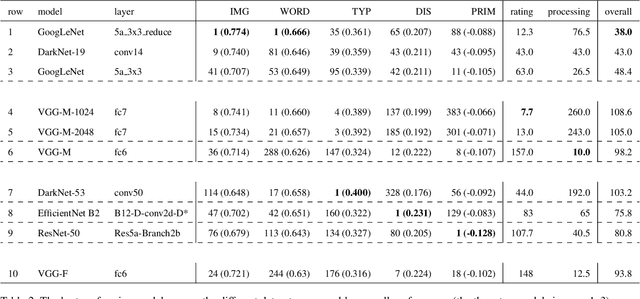
Over the last years, advancements in deep learning models for computer vision have led to a dramatic improvement in their image classification accuracy. However, models with a higher accuracy in the task they were trained on do not necessarily develop better image representations that allow them to also perform better in other tasks they were not trained on. In order to investigate the representation learning capabilities of prominent high-performing computer vision models, we investigated how well they capture various indices of perceptual similarity from large-scale behavioral datasets. We find that higher image classification accuracy rates are not associated with a better performance on these datasets, and in fact we observe no improvement in performance since GoogLeNet (released 2015) and VGG-M (released 2014). We speculate that more accurate classification may result from hyper-engineering towards very fine-grained distinctions between highly similar classes, which does not incentivize the models to capture overall perceptual similarities.
Online Backfilling with No Regret for Large-Scale Image Retrieval
Jan 10, 2023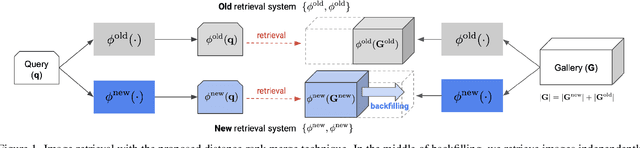
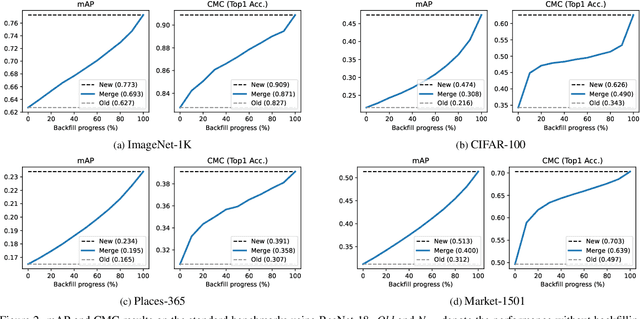
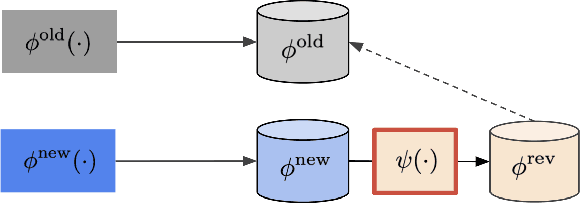
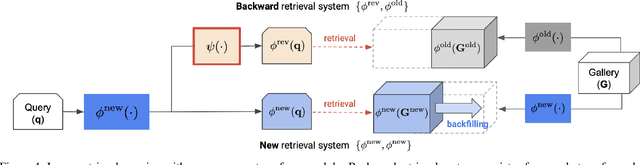
Backfilling is the process of re-extracting all gallery embeddings from upgraded models in image retrieval systems. It inevitably requires a prohibitively large amount of computational cost and even entails the downtime of the service. Although backward-compatible learning sidesteps this challenge by tackling query-side representations, this leads to suboptimal solutions in principle because gallery embeddings cannot benefit from model upgrades. We address this dilemma by introducing an online backfilling algorithm, which enables us to achieve a progressive performance improvement during the backfilling process while not sacrificing the final performance of new model after the completion of backfilling. To this end, we first propose a simple distance rank merge technique for online backfilling. Then, we incorporate a reverse transformation module for more effective and efficient merging, which is further enhanced by adopting a metric-compatible contrastive learning approach. These two components help to make the distances of old and new models compatible, resulting in desirable merge results during backfilling with no extra computational overhead. Extensive experiments show the effectiveness of our framework on four standard benchmarks in various settings.
Robust Split Federated Learning for U-shaped Medical Image Networks
Dec 13, 2022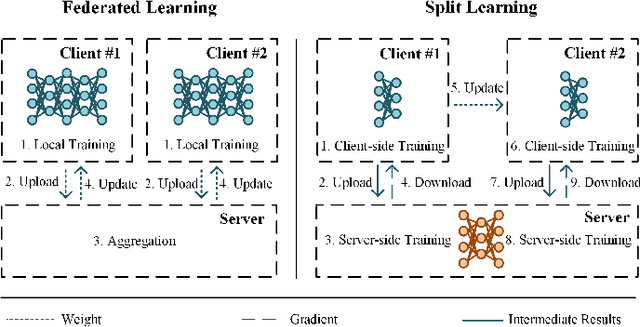

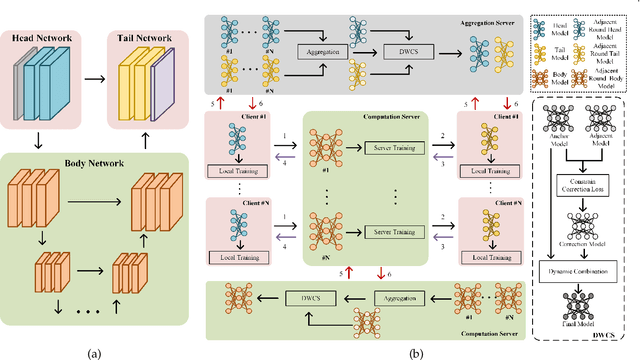
U-shaped networks are widely used in various medical image tasks, such as segmentation, restoration and reconstruction, but most of them usually rely on centralized learning and thus ignore privacy issues. To address the privacy concerns, federated learning (FL) and split learning (SL) have attracted increasing attention. However, it is hard for both FL and SL to balance the local computational cost, model privacy and parallel training simultaneously. To achieve this goal, in this paper, we propose Robust Split Federated Learning (RoS-FL) for U-shaped medical image networks, which is a novel hybrid learning paradigm of FL and SL. Previous works cannot preserve the data privacy, including the input, model parameters, label and output simultaneously. To effectively deal with all of them, we design a novel splitting method for U-shaped medical image networks, which splits the network into three parts hosted by different parties. Besides, the distributed learning methods usually suffer from a drift between local and global models caused by data heterogeneity. Based on this consideration, we propose a dynamic weight correction strategy (\textbf{DWCS}) to stabilize the training process and avoid model drift. Specifically, a weight correction loss is designed to quantify the drift between the models from two adjacent communication rounds. By minimizing this loss, a correction model is obtained. Then we treat the weighted sum of correction model and final round models as the result. The effectiveness of the proposed RoS-FL is supported by extensive experimental results on different tasks. Related codes will be released at https://github.com/Zi-YuanYang/RoS-FL.
Unified Out-Of-Distribution Detection: A Model-Specific Perspective
Apr 13, 2023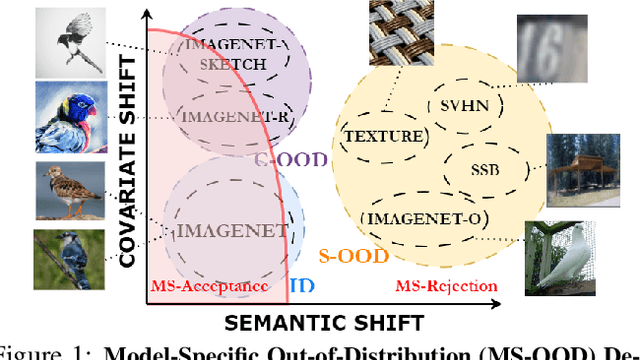
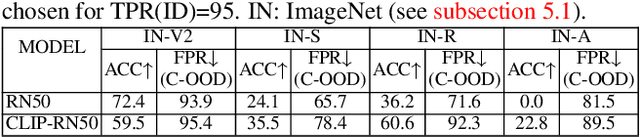
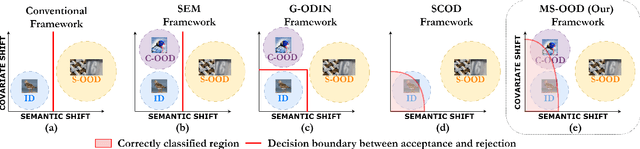
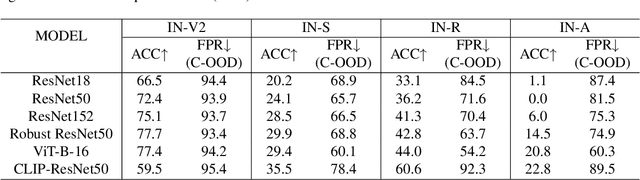
Out-of-distribution (OOD) detection aims to identify test examples that do not belong to the training distribution and are thus unlikely to be predicted reliably. Despite a plethora of existing works, most of them focused only on the scenario where OOD examples come from semantic shift (e.g., unseen categories), ignoring other possible causes (e.g., covariate shift). In this paper, we present a novel, unifying framework to study OOD detection in a broader scope. Instead of detecting OOD examples from a particular cause, we propose to detect examples that a deployed machine learning model (e.g., an image classifier) is unable to predict correctly. That is, whether a test example should be detected and rejected or not is ``model-specific''. We show that this framework unifies the detection of OOD examples caused by semantic shift and covariate shift, and closely addresses the concern of applying a machine learning model to uncontrolled environments. We provide an extensive analysis that involves a variety of models (e.g., different architectures and training strategies), sources of OOD examples, and OOD detection approaches, and reveal several insights into improving and understanding OOD detection in uncontrolled environments.
Learning-based Spatial and Angular Information Separation for Light Field Compression
Apr 13, 2023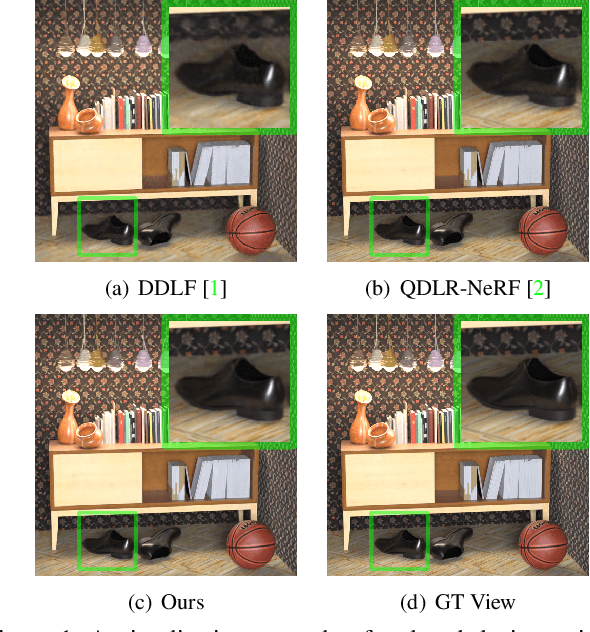
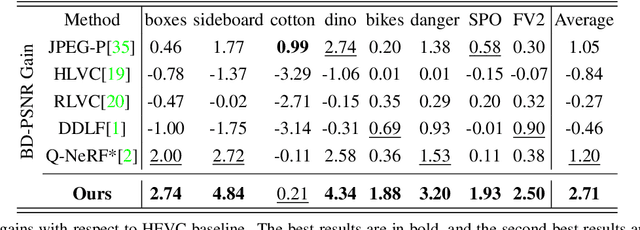
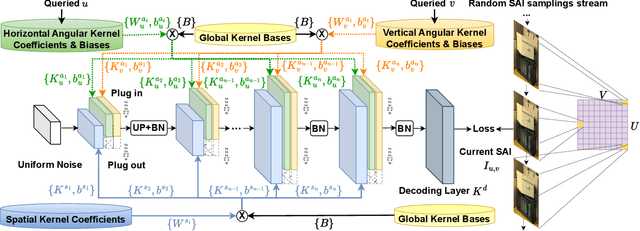
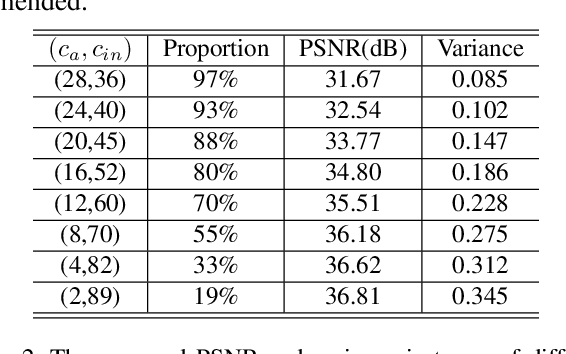
Light fields are a type of image data that capture both spatial and angular scene information by recording light rays emitted by a scene from different orientations. In this context, spatial information is defined as features that remain static regardless of perspectives, while angular information refers to features that vary between viewpoints. We propose a novel neural network that, by design, can separate angular and spatial information of a light field. The network represents spatial information using spatial kernels shared among all Sub-Aperture Images (SAIs), and angular information using sets of angular kernels for each SAI. To further improve the representation capability of the network without increasing parameter number, we also introduce angular kernel allocation and kernel tensor decomposition mechanisms. Extensive experiments demonstrate the benefits of information separation: when applied to the compression task, our network outperforms other state-of-the-art methods by a large margin. And angular information can be easily transferred to other scenes for rendering dense views, showing the successful separation and the potential use case for the view synthesis task. We plan to release the code upon acceptance of the paper to encourage further research on this topic.
RoSI: Recovering 3D Shape Interiors from Few Articulation Images
Apr 13, 2023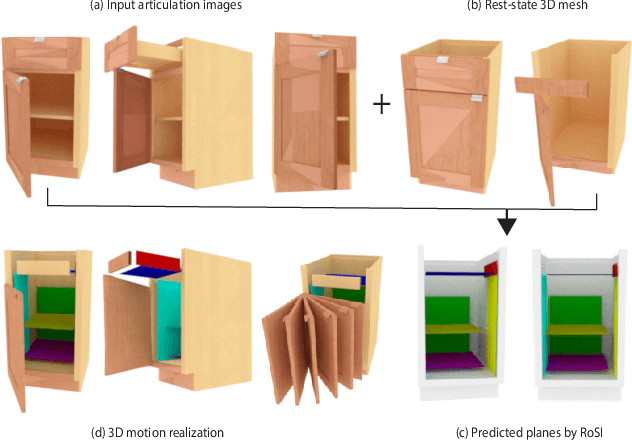

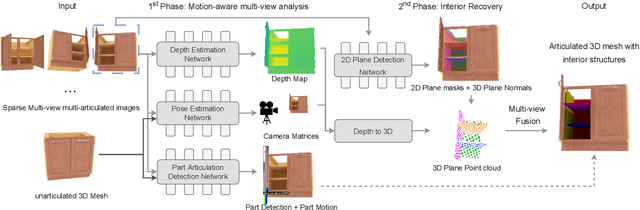

The dominant majority of 3D models that appear in gaming, VR/AR, and those we use to train geometric deep learning algorithms are incomplete, since they are modeled as surface meshes and missing their interior structures. We present a learning framework to recover the shape interiors (RoSI) of existing 3D models with only their exteriors from multi-view and multi-articulation images. Given a set of RGB images that capture a target 3D object in different articulated poses, possibly from only few views, our method infers the interior planes that are observable in the input images. Our neural architecture is trained in a category-agnostic manner and it consists of a motion-aware multi-view analysis phase including pose, depth, and motion estimations, followed by interior plane detection in images and 3D space, and finally multi-view plane fusion. In addition, our method also predicts part articulations and is able to realize and even extrapolate the captured motions on the target 3D object. We evaluate our method by quantitative and qualitative comparisons to baselines and alternative solutions, as well as testing on untrained object categories and real image inputs to assess its generalization capabilities.
Bridging Component Learning with Degradation Modelling for Blind Image Super-Resolution
Dec 03, 2022
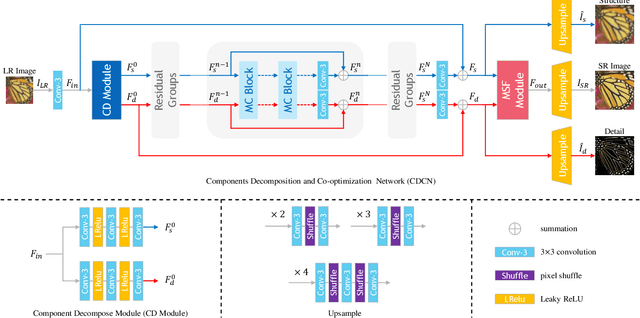
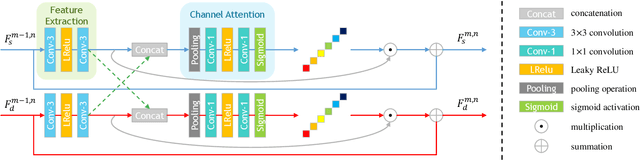
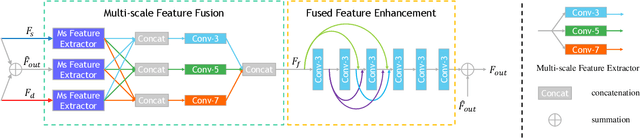
Convolutional Neural Network (CNN)-based image super-resolution (SR) has exhibited impressive success on known degraded low-resolution (LR) images. However, this type of approach is hard to hold its performance in practical scenarios when the degradation process is unknown. Despite existing blind SR methods proposed to solve this problem using blur kernel estimation, the perceptual quality and reconstruction accuracy are still unsatisfactory. In this paper, we analyze the degradation of a high-resolution (HR) image from image intrinsic components according to a degradation-based formulation model. We propose a components decomposition and co-optimization network (CDCN) for blind SR. Firstly, CDCN decomposes the input LR image into structure and detail components in feature space. Then, the mutual collaboration block (MCB) is presented to exploit the relationship between both two components. In this way, the detail component can provide informative features to enrich the structural context and the structure component can carry structural context for better detail revealing via a mutual complementary manner. After that, we present a degradation-driven learning strategy to jointly supervise the HR image detail and structure restoration process. Finally, a multi-scale fusion module followed by an upsampling layer is designed to fuse the structure and detail features and perform SR reconstruction. Empowered by such degradation-based components decomposition, collaboration, and mutual optimization, we can bridge the correlation between component learning and degradation modelling for blind SR, thereby producing SR results with more accurate textures. Extensive experiments on both synthetic SR datasets and real-world images show that the proposed method achieves the state-of-the-art performance compared to existing methods.
FindVehicle and VehicleFinder: A NER dataset for natural language-based vehicle retrieval and a keyword-based cross-modal vehicle retrieval system
Apr 21, 2023
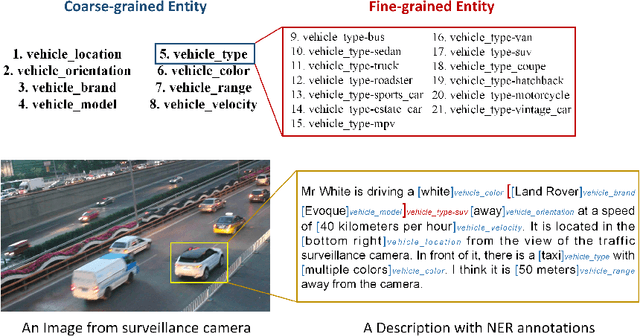
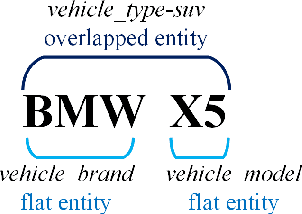
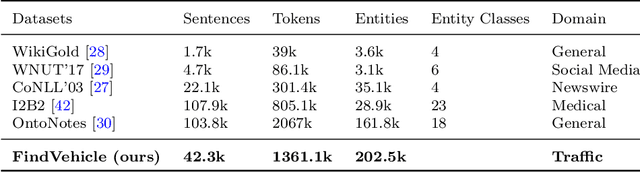
Natural language (NL) based vehicle retrieval is a task aiming to retrieve a vehicle that is most consistent with a given NL query from among all candidate vehicles. Because NL query can be easily obtained, such a task has a promising prospect in building an interactive intelligent traffic system (ITS). Current solutions mainly focus on extracting both text and image features and mapping them to the same latent space to compare the similarity. However, existing methods usually use dependency analysis or semantic role-labelling techniques to find keywords related to vehicle attributes. These techniques may require a lot of pre-processing and post-processing work, and also suffer from extracting the wrong keyword when the NL query is complex. To tackle these problems and simplify, we borrow the idea from named entity recognition (NER) and construct FindVehicle, a NER dataset in the traffic domain. It has 42.3k labelled NL descriptions of vehicle tracks, containing information such as the location, orientation, type and colour of the vehicle. FindVehicle also adopts both overlapping entities and fine-grained entities to meet further requirements. To verify its effectiveness, we propose a baseline NL-based vehicle retrieval model called VehicleFinder. Our experiment shows that by using text encoders pre-trained by FindVehicle, VehicleFinder achieves 87.7\% precision and 89.4\% recall when retrieving a target vehicle by text command on our homemade dataset based on UA-DETRAC. The time cost of VehicleFinder is 279.35 ms on one ARM v8.2 CPU and 93.72 ms on one RTX A4000 GPU, which is much faster than the Transformer-based system. The dataset is open-source via the link https://github.com/GuanRunwei/FindVehicle, and the implementation can be found via the link https://github.com/GuanRunwei/VehicleFinder-CTIM.
Color Image steganography using Deep convolutional Autoencoders based on ResNet architecture
Nov 17, 2022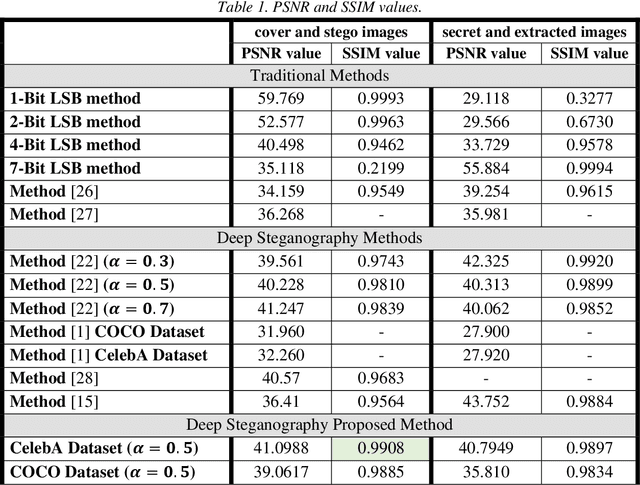
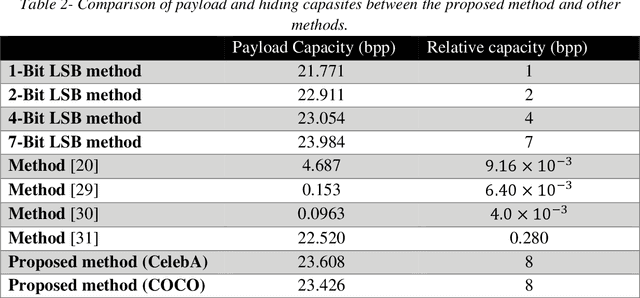

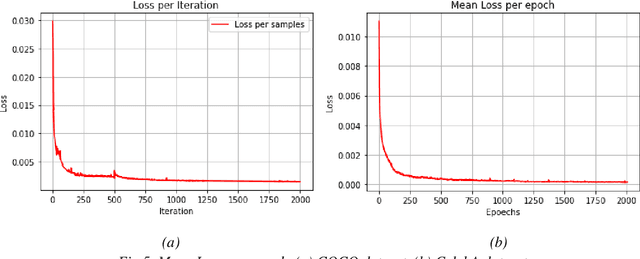
In this paper, a deep learning color image steganography scheme combining convolutional autoencoders and ResNet architecture is proposed. Traditional steganography methods suffer from some critical defects such as low capacity, security, and robustness. In recent decades, image hiding and image extraction were realized by autoencoder convolutional neural networks to solve the aforementioned challenges. The contribution of this paper is introducing a new scheme for color image steganography inspired by ResNet architecture. The reverse ResNet architecture is utilized to extract the secret image from the stego image. In the proposed method, all images are passed through the prepossess model which is a convolutional deep neural network with the aim of feature extraction. Then, the operational model generates stego and extracted images. In fact, the operational model is an autoencoder based on ResNet structure that produces an image from feature maps. The advantage of proposed structure is identity of models in embedding and extraction phases. The performance of the proposed method is studied using COCO and CelebA datasets. For quantitative comparisons with previous related works, peak signal-to-noise ratio (PSNR), the structural similarity index (SSIM) and hiding capacity are evaluated. The experimental results verify that the proposed scheme performs better than traditional and pervious deep steganography methods. The PSNR and SSIM are more than 40 dB and 0.98, respectively that implies high imperceptibility of the proposed method. Also, this method can hide a color image of the same size in another color image, which can be inferred that the relative capacity of the proposed method is 8 bits per pixel.
A Neural Network Transformer Model for Composite Microstructure Homogenization
Apr 16, 2023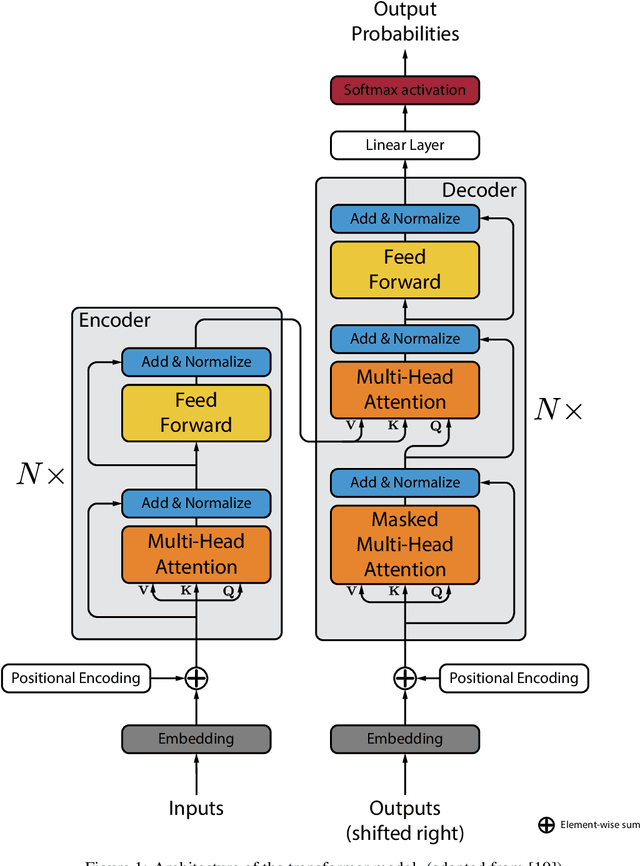

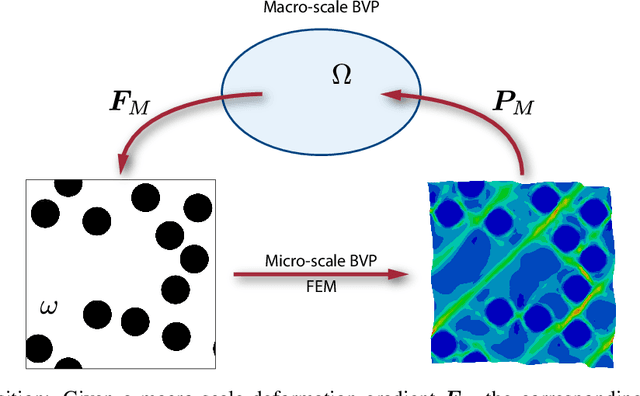
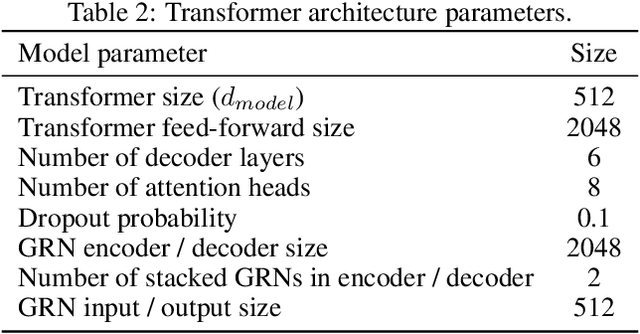
Heterogeneity and uncertainty in a composite microstructure lead to either computational bottlenecks if modeled rigorously, or to solution inaccuracies in the stress field and failure predictions if approximated. Although methods suitable for analyzing arbitrary and non-linear microstructures exist, their computational cost makes them impractical to use in large-scale structural analysis. Surrogate models or Reduced Order Models (ROM), commonly enhance efficiencies, but they are typically calibrated with a single microstructure. Homogenization methods, such as the Mori-Tanaka method, offer rapid homogenization for a wide range of constituent properties. However, simplifying assumptions, like stress and strain averaging in phases, render the consideration of both deterministic and stochastic variations in microstructure infeasible. This paper illustrates a transformer neural network architecture that captures the knowledge of various microstructures and constituents, enabling it to function as a computationally efficient homogenization surrogate model. Given an image or an abstraction of an arbitrary composite microstructure, the transformer network predicts the homogenized stress-strain response. Two methods were tested that encode features of the microstructure. The first method calculates two-point statistics of the microstructure and uses Principal Component Analysis for dimensionality reduction. The second method uses an autoencoder with a Convolutional Neural Network. Both microstructure encoding methods accurately predict the homogenized material response. The paper describes the network architecture, training and testing data generation and the performance of the transformer network under cycling and random loadings.