 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Phantom Embeddings: Using Embedding Space for Model Regularization in Deep Neural Networks
Apr 14, 2023
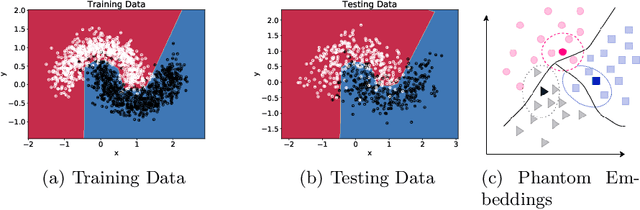
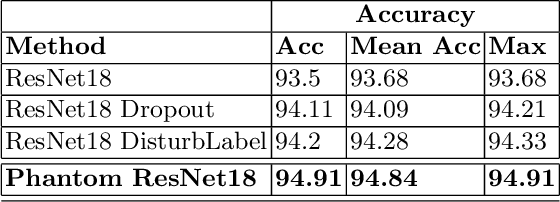
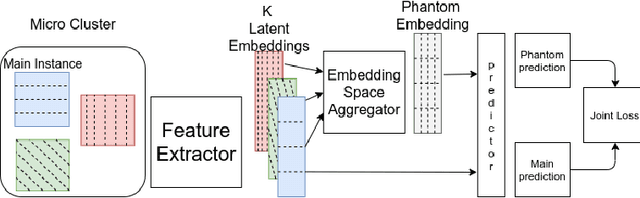
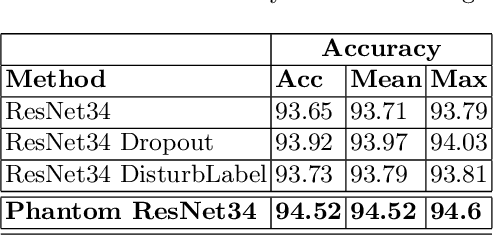
The strength of machine learning models stems from their ability to learn complex function approximations from data; however, this strength also makes training deep neural networks challenging. Notably, the complex models tend to memorize the training data, which results in poor regularization performance on test data. The regularization techniques such as L1, L2, dropout, etc. are proposed to reduce the overfitting effect; however, they bring in additional hyperparameters tuning complexity. These methods also fall short when the inter-class similarity is high due to the underlying data distribution, leading to a less accurate model. In this paper, we present a novel approach to regularize the models by leveraging the information-rich latent embeddings and their high intra-class correlation. We create phantom embeddings from a subset of homogenous samples and use these phantom embeddings to decrease the inter-class similarity of instances in their latent embedding space. The resulting models generalize better as a combination of their embedding and regularize them without requiring an expensive hyperparameter search. We evaluate our method on two popular and challenging image classification datasets (CIFAR and FashionMNIST) and show how our approach outperforms the standard baselines while displaying better training behavior.
Diffusion Models as Masked Autoencoders
Apr 06, 2023
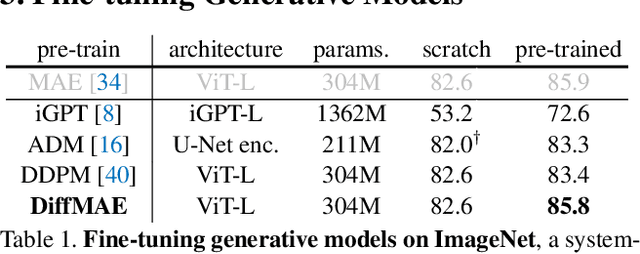

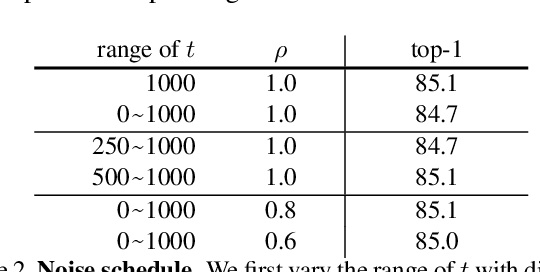
There has been a longstanding belief that generation can facilitate a true understanding of visual data. In line with this, we revisit generatively pre-training visual representations in light of recent interest in denoising diffusion models. While directly pre-training with diffusion models does not produce strong representations, we condition diffusion models on masked input and formulate diffusion models as masked autoencoders (DiffMAE). Our approach is capable of (i) serving as a strong initialization for downstream recognition tasks, (ii) conducting high-quality image inpainting, and (iii) being effortlessly extended to video where it produces state-of-the-art classification accuracy. We further perform a comprehensive study on the pros and cons of design choices and build connections between diffusion models and masked autoencoders.
Anomaly Detection via Gumbel Noise Score Matching
Apr 06, 2023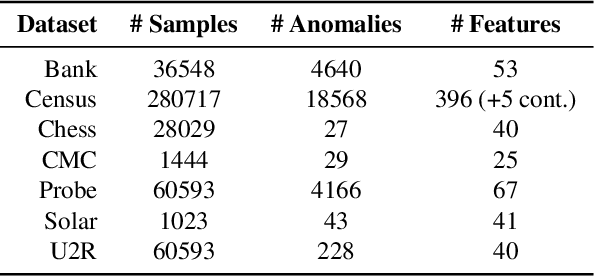
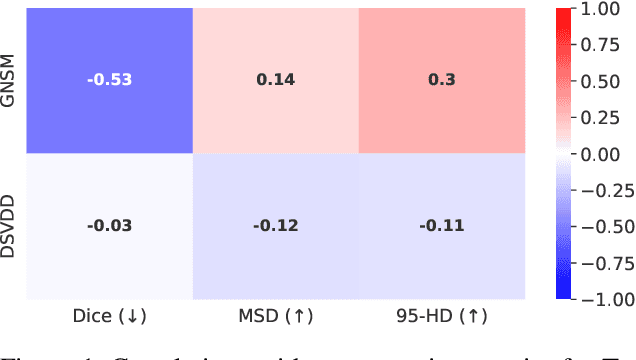
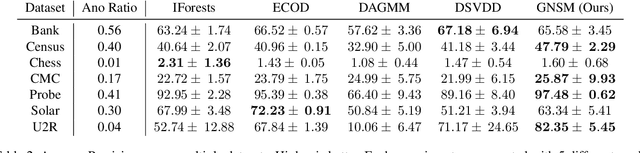

We propose Gumbel Noise Score Matching (GNSM), a novel unsupervised method to detect anomalies in categorical data. GNSM accomplishes this by estimating the scores, i.e. the gradients of log likelihoods w.r.t.~inputs, of continuously relaxed categorical distributions. We test our method on a suite of anomaly detection tabular datasets. GNSM achieves a consistently high performance across all experiments. We further demonstrate the flexibility of GNSM by applying it to image data where the model is tasked to detect poor segmentation predictions. Images ranked anomalous by GNSM show clear segmentation failures, with the outputs of GNSM strongly correlating with segmentation metrics computed on ground-truth. We outline the score matching training objective utilized by GNSM and provide an open-source implementation of our work.
Iterative Data Refinement for Self-Supervised MR Image Reconstruction
Nov 24, 2022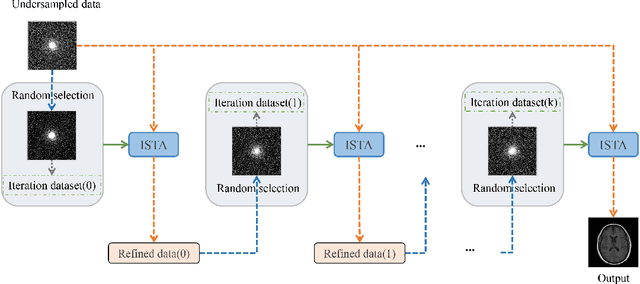
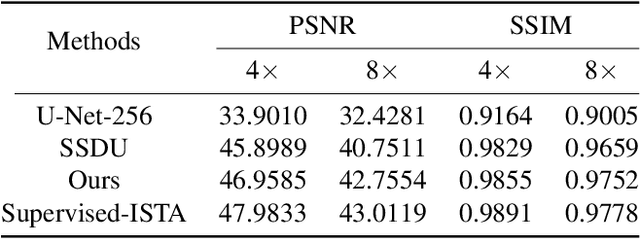
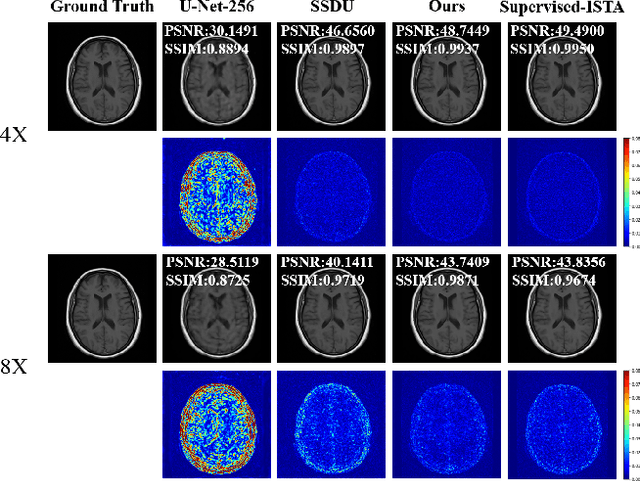
Magnetic Resonance Imaging (MRI) has become an important technique in the clinic for the visualization, detection, and diagnosis of various diseases. However, one bottleneck limitation of MRI is the relatively slow data acquisition process. Fast MRI based on k-space undersampling and high-quality image reconstruction has been widely utilized, and many deep learning-based methods have been developed in recent years. Although promising results have been achieved, most existing methods require fully-sampled reference data for training the deep learning models. Unfortunately, fully-sampled MRI data are difficult if not impossible to obtain in real-world applications. To address this issue, we propose a data refinement framework for self-supervised MR image reconstruction. Specifically, we first analyze the reason of the performance gap between self-supervised and supervised methods and identify that the bias in the training datasets between the two is one major factor. Then, we design an effective self-supervised training data refinement method to reduce this data bias. With the data refinement, an enhanced self-supervised MR image reconstruction framework is developed to prompt accurate MR imaging. We evaluate our method on an in-vivo MRI dataset. Experimental results show that without utilizing any fully sampled MRI data, our self-supervised framework possesses strong capabilities in capturing image details and structures at high acceleration factors.
Spatio-Temporal driven Attention Graph Neural Network with Block Adjacency matrix (STAG-NN-BA)
Mar 25, 2023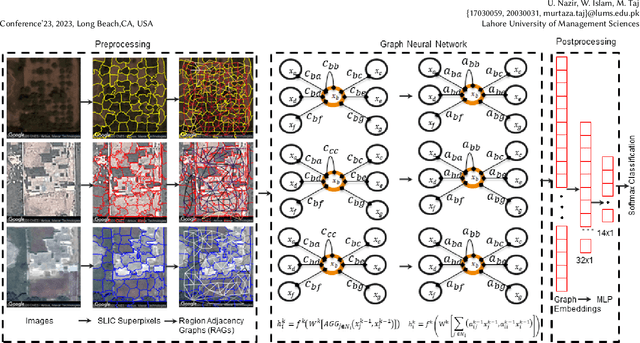


Despite the recent advances in deep neural networks, standard convolutional kernels limit the applications of these networks to the Euclidean domain only. Considering the geodesic nature of the measurement of the earth's surface, remote sensing is one such area that can benefit from non-Euclidean and spherical domains. For this purpose, we propose a novel Graph Neural Network architecture for spatial and spatio-temporal classification using satellite imagery. We propose a hybrid attention method to learn the relative importance of irregular neighbors in remote sensing data. Instead of classifying each pixel, we propose a method based on Simple Linear Iterative Clustering (SLIC) image segmentation and Graph Attention GAT. The superpixels obtained from SLIC become the nodes of our Graph Convolution Network (GCN). We then construct a region adjacency graph (RAG) where each superpixel is connected to every other adjacent superpixel in the image, enabling information to propagate globally. Finally, we propose a Spatially driven Attention Graph Neural Network (SAG-NN) to classify each RAG. We also propose an extension to our SAG-NN for spatio-temporal data. Unlike regular grids of pixels in images, superpixels are irregular in nature and cannot be used to create spatio-temporal graphs. We introduce temporal bias by combining unconnected RAGs from each image into one supergraph. This is achieved by introducing block adjacency matrices resulting in novel Spatio-Temporal driven Attention Graph Neural Network with Block Adjacency matrix (STAG-NN-BA). We evaluate our proposed methods on two remote sensing datasets namely Asia14 and C2D2. In comparison with both non-graph and graph-based approaches our SAG-NN and STAG-NN-BA achieved superior accuracy on all the datasets while incurring less computation cost. The code and dataset will be made public via our GitHub repository.
High Dynamic Range Imaging with Context-aware Transformer
Apr 17, 2023
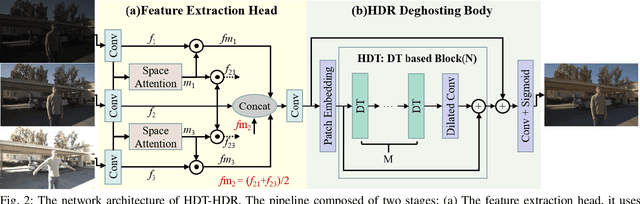
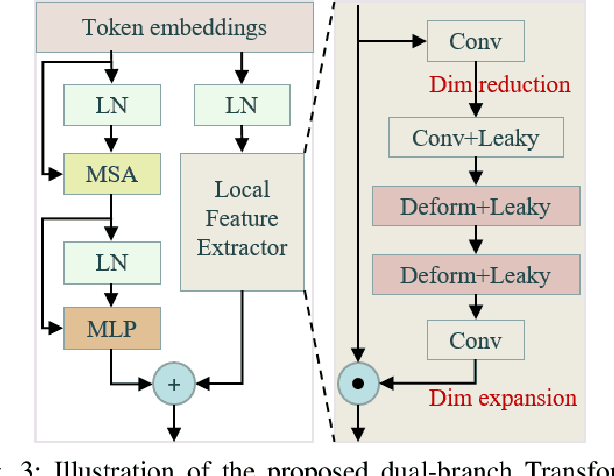

Avoiding the introduction of ghosts when synthesising LDR images as high dynamic range (HDR) images is a challenging task. Convolutional neural networks (CNNs) are effective for HDR ghost removal in general, but are challenging to deal with the LDR images if there are large movements or oversaturation/undersaturation. Existing dual-branch methods combining CNN and Transformer omit part of the information from non-reference images, while the features extracted by the CNN-based branch are bound to the kernel size with small receptive field, which are detrimental to the deblurring and the recovery of oversaturated/undersaturated regions. In this paper, we propose a novel hierarchical dual Transformer method for ghost-free HDR (HDT-HDR) images generation, which extracts global features and local features simultaneously. First, we use a CNN-based head with spatial attention mechanisms to extract features from all the LDR images. Second, the LDR features are delivered to the Hierarchical Dual Transformer (HDT). In each Dual Transformer (DT), the global features are extracted by the window-based Transformer, while the local details are extracted using the channel attention mechanism with deformable CNNs. Finally, the ghost free HDR image is obtained by dimensional mapping on the HDT output. Abundant experiments demonstrate that our HDT-HDR achieves the state-of-the-art performance among existing HDR ghost removal methods.
MaMMUT: A Simple Architecture for Joint Learning for MultiModal Tasks
Mar 30, 2023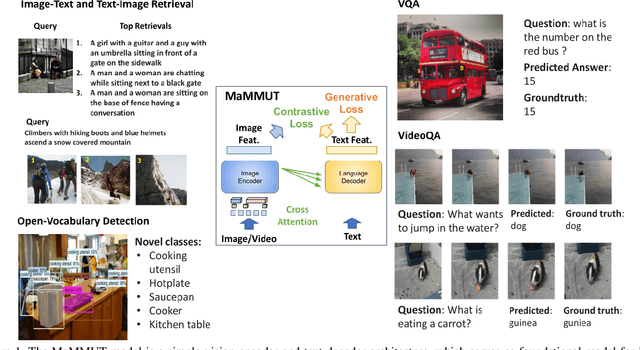
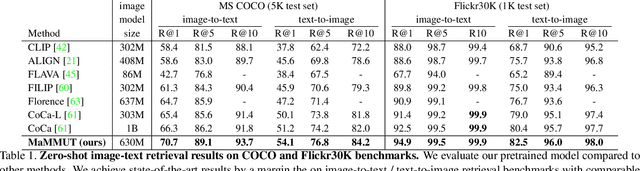
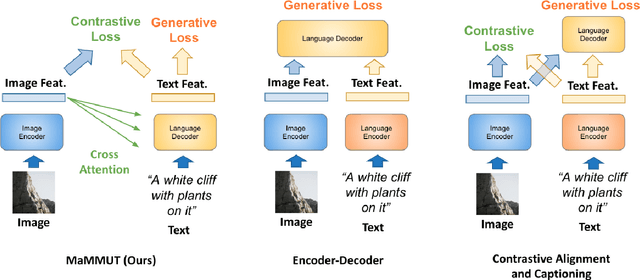
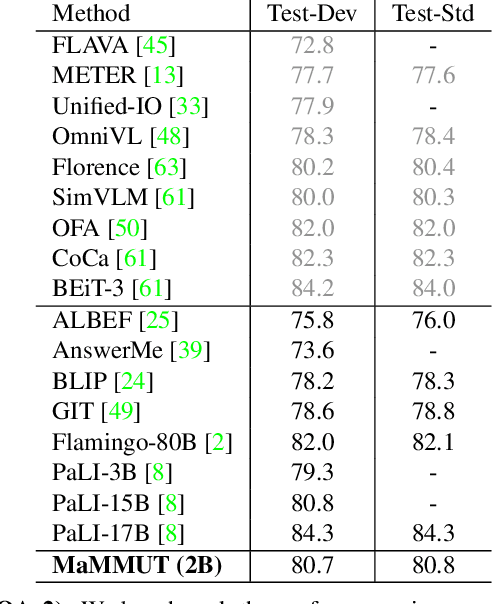
The development of language models have moved from encoder-decoder to decoder-only designs. In addition, the common knowledge has it that the two most popular multimodal tasks, the generative and contrastive tasks, tend to conflict with one another, are hard to accommodate in one architecture, and further need complex adaptations for downstream tasks. We propose a novel paradigm of training with a decoder-only model for multimodal tasks, which is surprisingly effective in jointly learning of these disparate vision-language tasks. This is done with a simple model, called MaMMUT. It consists of a single vision encoder and a text decoder, and is able to accommodate contrastive and generative learning by a novel two-pass approach on the text decoder. We demonstrate that joint learning of these diverse objectives is simple, effective, and maximizes the weight-sharing of the model across these tasks. Furthermore, the same architecture enables straightforward extensions to open-vocabulary object detection and video-language tasks. The model tackles a diverse range of tasks, while being modest in capacity. Our model achieves the state of the art on image-text and text-image retrieval, video question answering and open-vocabulary detection tasks, outperforming much larger and more extensively trained foundational models. It shows very competitive results on VQA and Video Captioning, especially considering its capacity. Ablations confirm the flexibility and advantages of our approach.
DuDoRNeXt: A hybrid model for dual-domain undersampled MRI reconstruction
Mar 19, 2023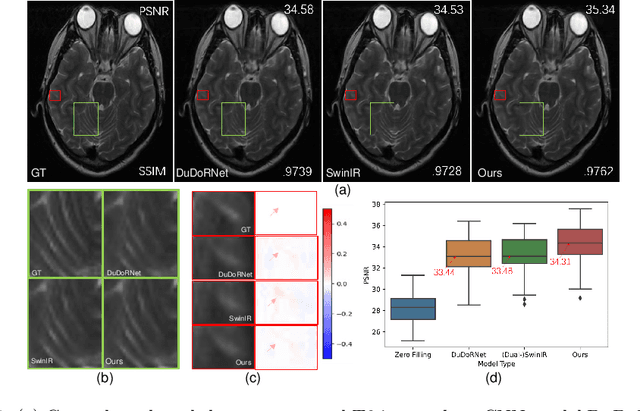
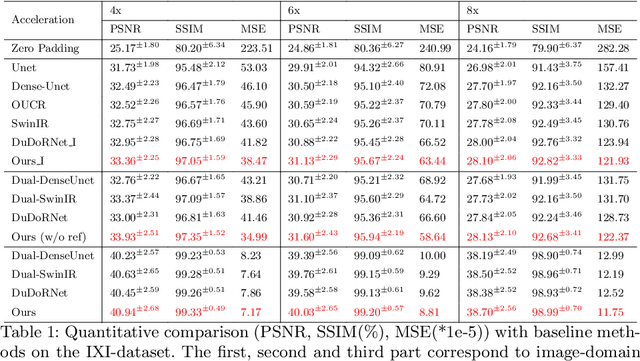
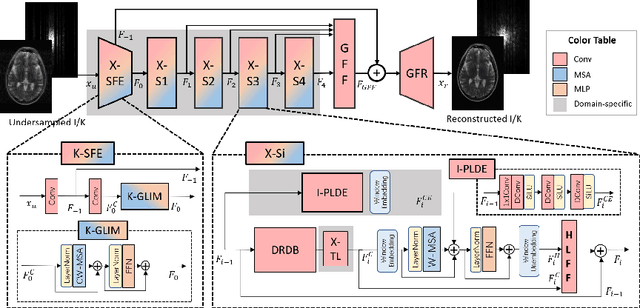
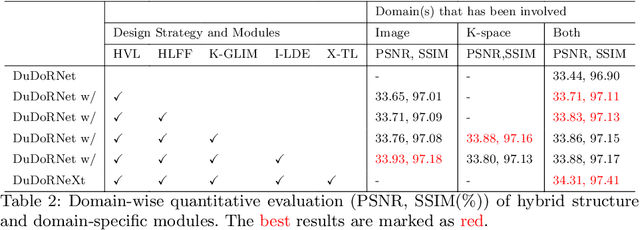
Undersampled MRI reconstruction is crucial for accelerating clinical scanning procedures. Recent deep learning methods for MRI reconstruction adopt CNN or ViT as backbone, which lack in utilizing the complementary properties of CNN and ViT. In this paper, we propose DuDoRNeXt, whose backbone hybridizes CNN and ViT in an domain-specific, intra-stage way. Besides our hybrid vertical layout design, we introduce domain-specific modules for dual-domain reconstruction, namely image-domain parallel local detail enhancement and k-space global initialization. We evaluate different conventions of MRI reconstruction including image-domain, k-space-domain, and dual-domain reconstruction with a reference protocol on the IXI dataset and an in-house multi-contrast dataset. DuDoRNeXt achieves significant improvements over competing deep learning methods.
Learning cross space mapping via DNN using large scale click-through logs
Feb 26, 2023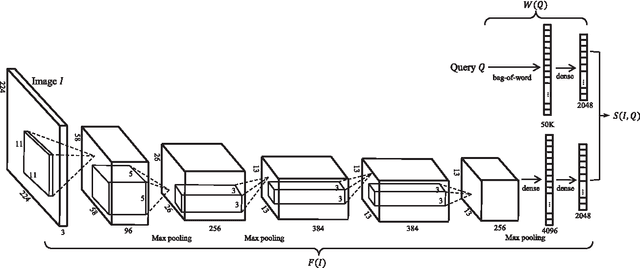
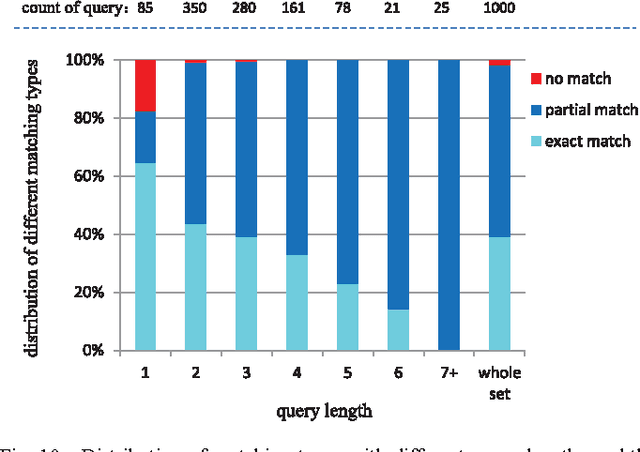
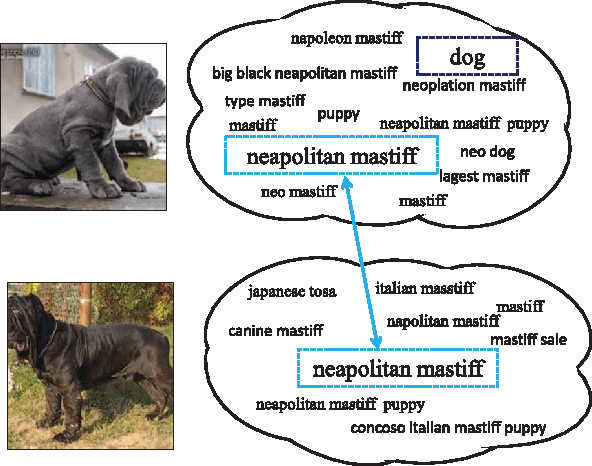
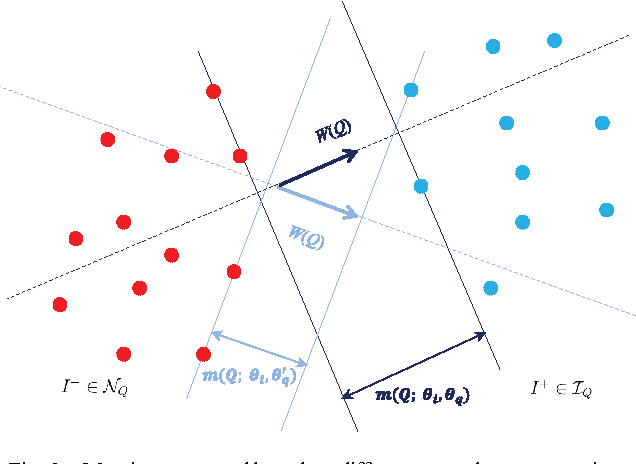
The gap between low-level visual signals and high-level semantics has been progressively bridged by continuous development of deep neural network (DNN). With recent progress of DNN, almost all image classification tasks have achieved new records of accuracy. To extend the ability of DNN to image retrieval tasks, we proposed a unified DNN model for image-query similarity calculation by simultaneously modeling image and query in one network. The unified DNN is named the cross space mapping (CSM) model, which contains two parts, a convolutional part and a query-embedding part. The image and query are mapped to a common vector space via these two parts respectively, and image-query similarity is naturally defined as an inner product of their mappings in the space. To ensure good generalization ability of the DNN, we learn weights of the DNN from a large number of click-through logs which consists of 23 million clicked image-query pairs between 1 million images and 11.7 million queries. Both the qualitative results and quantitative results on an image retrieval evaluation task with 1000 queries demonstrate the superiority of the proposed method.
* Accepted by IEEE Transactions on Multimedia 2015
Towards Enhanced Controllability of Diffusion Models
Mar 15, 2023
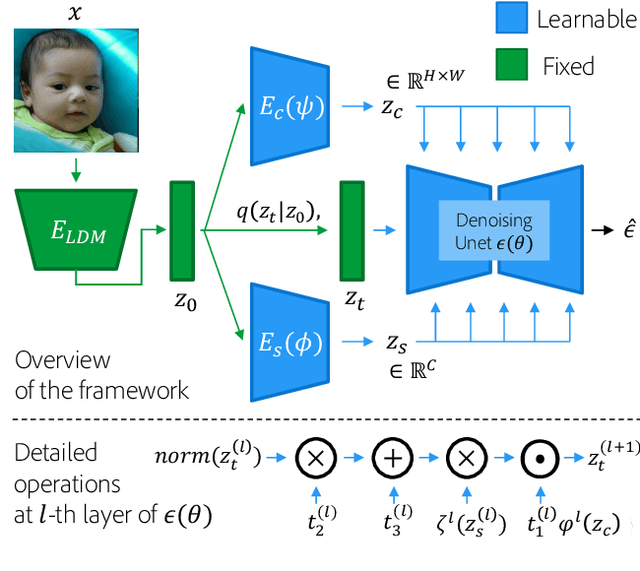
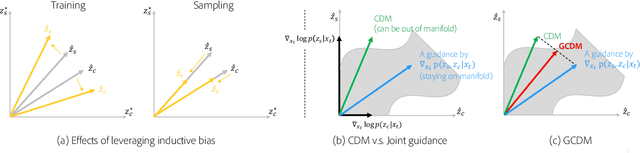

Denoising Diffusion models have shown remarkable capabilities in generating realistic, high-quality and diverse images. However, the extent of controllability during generation is underexplored. Inspired by techniques based on GAN latent space for image manipulation, we train a diffusion model conditioned on two latent codes, a spatial content mask and a flattened style embedding. We rely on the inductive bias of the progressive denoising process of diffusion models to encode pose/layout information in the spatial structure mask and semantic/style information in the style code. We propose two generic sampling techniques for improving controllability. We extend composable diffusion models to allow for some dependence between conditional inputs, to improve the quality of generations while also providing control over the amount of guidance from each latent code and their joint distribution. We also propose timestep dependent weight scheduling for content and style latents to further improve the translations. We observe better controllability compared to existing methods and show that without explicit training objectives, diffusion models can be used for effective image manipulation and image translation.