 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
OneFormer: One Transformer to Rule Universal Image Segmentation
Nov 10, 2022
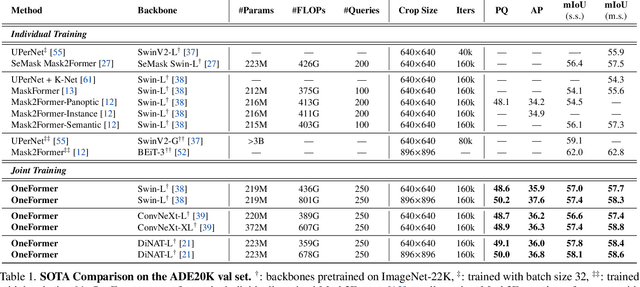
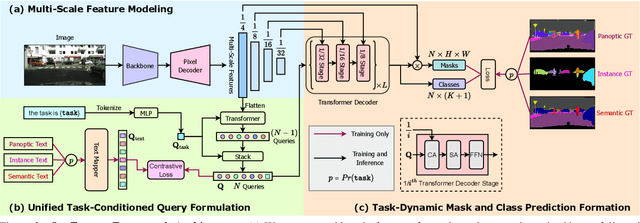
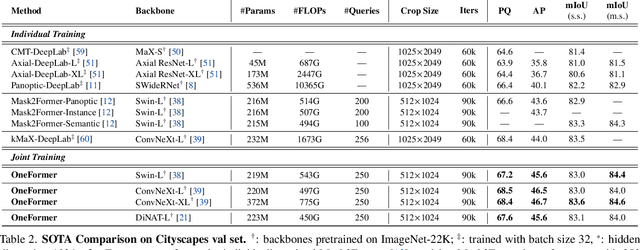
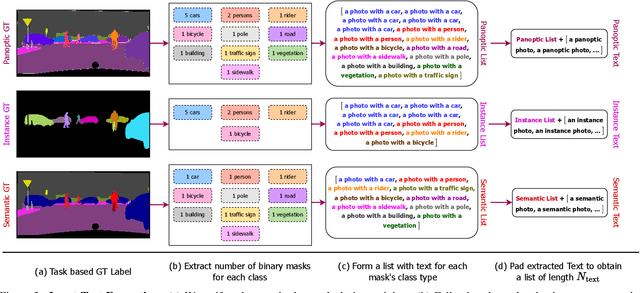
Universal Image Segmentation is not a new concept. Past attempts to unify image segmentation in the last decades include scene parsing, panoptic segmentation, and, more recently, new panoptic architectures. However, such panoptic architectures do not truly unify image segmentation because they need to be trained individually on the semantic, instance, or panoptic segmentation to achieve the best performance. Ideally, a truly universal framework should be trained only once and achieve SOTA performance across all three image segmentation tasks. To that end, we propose OneFormer, a universal image segmentation framework that unifies segmentation with a multi-task train-once design. We first propose a task-conditioned joint training strategy that enables training on ground truths of each domain (semantic, instance, and panoptic segmentation) within a single multi-task training process. Secondly, we introduce a task token to condition our model on the task at hand, making our model task-dynamic to support multi-task training and inference. Thirdly, we propose using a query-text contrastive loss during training to establish better inter-task and inter-class distinctions. Notably, our single OneFormer model outperforms specialized Mask2Former models across all three segmentation tasks on ADE20k, CityScapes, and COCO, despite the latter being trained on each of the three tasks individually with three times the resources. With new ConvNeXt and DiNAT backbones, we observe even more performance improvement. We believe OneFormer is a significant step towards making image segmentation more universal and accessible. To support further research, we open-source our code and models at https://github.com/SHI-Labs/OneFormer
Online Backfilling with No Regret for Large-Scale Image Retrieval
Jan 10, 2023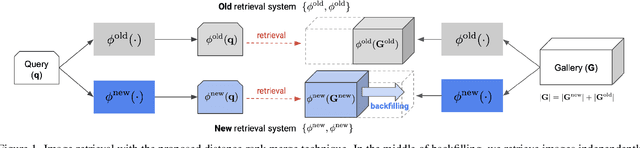
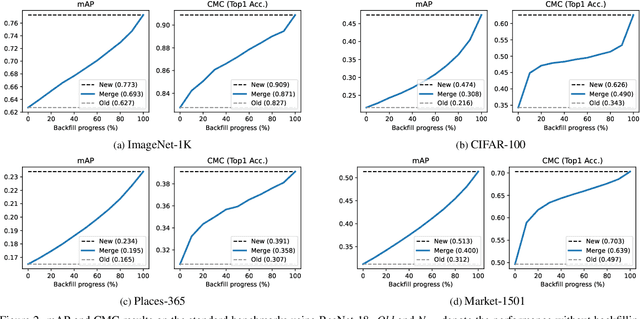
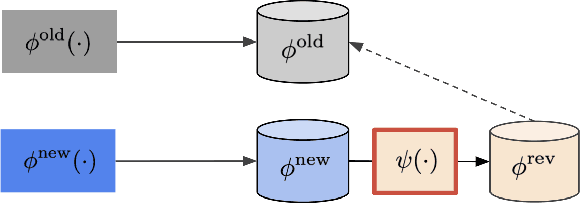
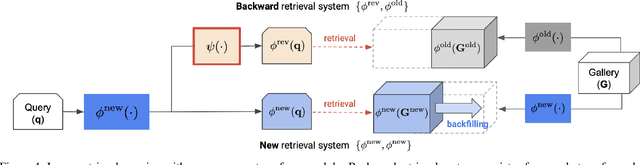
Backfilling is the process of re-extracting all gallery embeddings from upgraded models in image retrieval systems. It inevitably requires a prohibitively large amount of computational cost and even entails the downtime of the service. Although backward-compatible learning sidesteps this challenge by tackling query-side representations, this leads to suboptimal solutions in principle because gallery embeddings cannot benefit from model upgrades. We address this dilemma by introducing an online backfilling algorithm, which enables us to achieve a progressive performance improvement during the backfilling process while not sacrificing the final performance of new model after the completion of backfilling. To this end, we first propose a simple distance rank merge technique for online backfilling. Then, we incorporate a reverse transformation module for more effective and efficient merging, which is further enhanced by adopting a metric-compatible contrastive learning approach. These two components help to make the distances of old and new models compatible, resulting in desirable merge results during backfilling with no extra computational overhead. Extensive experiments show the effectiveness of our framework on four standard benchmarks in various settings.
An End-to-End Framework For Universal Lesion Detection With Missing Annotations
Mar 27, 2023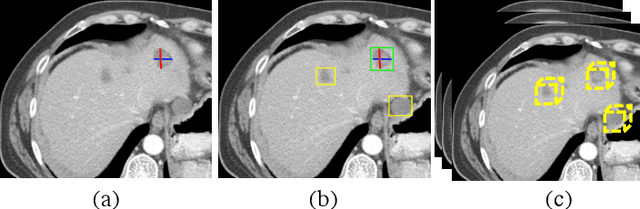
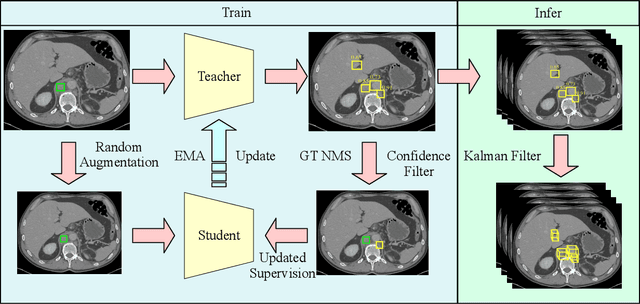
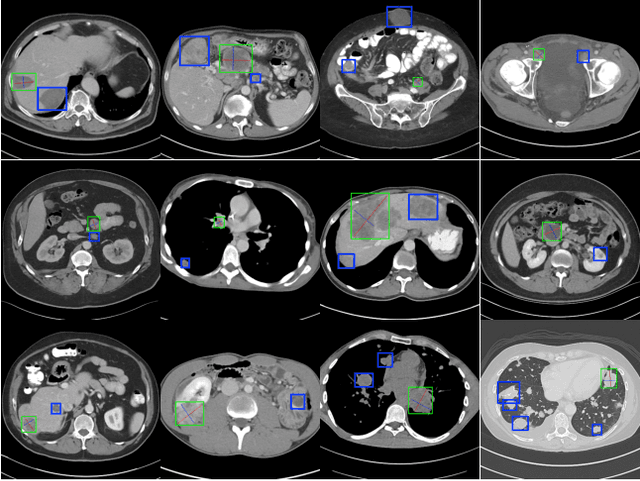
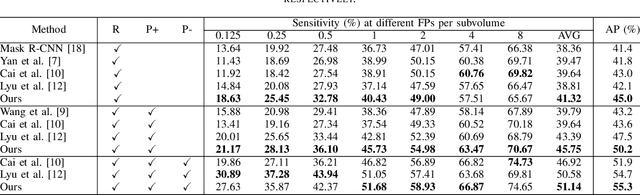
Fully annotated large-scale medical image datasets are highly valuable. However, because labeling medical images is tedious and requires specialized knowledge, the large-scale datasets available often have missing annotation issues. For instance, DeepLesion, a large-scale CT image dataset with labels for various kinds of lesions, is reported to have a missing annotation rate of 50\%. Directly training a lesion detector on it would suffer from false negative supervision caused by unannotated lesions. To address this issue, previous works have used sophisticated multi-stage strategies to switch between lesion mining and detector training. In this work, we present a novel end-to-end framework for mining unlabeled lesions while simultaneously training the detector. Our framework follows the teacher-student paradigm. In each iteration, the teacher model infers the input data and creates a set of predictions. High-confidence predictions are combined with partially-labeled ground truth for training the student model. On the DeepLesion dataset, using the original partially labeled training set, our model can outperform all other more complicated methods and surpass the previous best method by 2.3\% on average sensitivity and 2.7\% on average precision, achieving state-of-the-art universal lesion detection results.
Transformer-based Multi-Instance Learning for Weakly Supervised Object Detection
Mar 27, 2023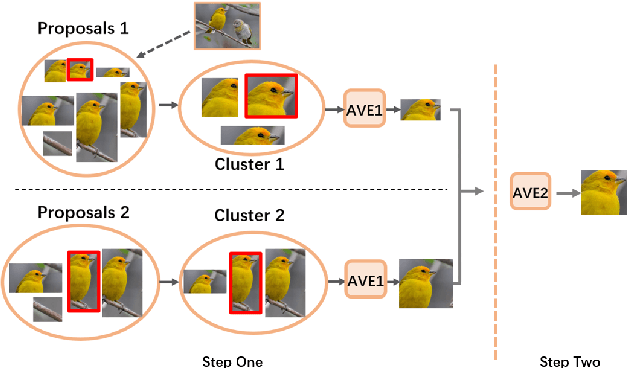
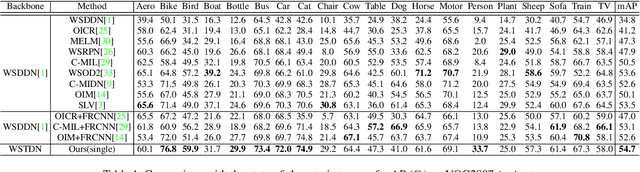
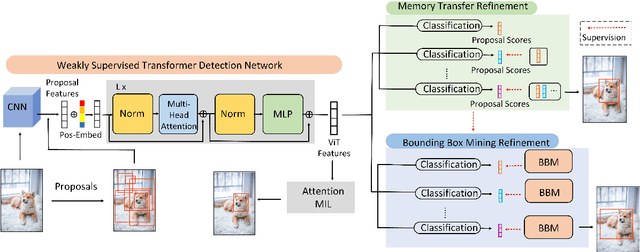
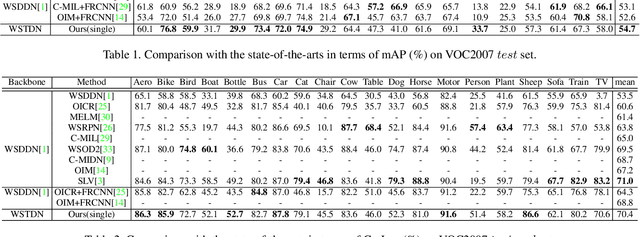
Weakly Supervised Object Detection (WSOD) enables the training of object detection models using only image-level annotations. State-of-the-art WSOD detectors commonly rely on multi-instance learning (MIL) as the backbone of their detectors and assume that the bounding box proposals of an image are independent of each other. However, since such approaches only utilize the highest score proposal and discard the potentially useful information from other proposals, their independent MIL backbone often limits models to salient parts of an object or causes them to detect only one object per class. To solve the above problems, we propose a novel backbone for WSOD based on our tailored Vision Transformer named Weakly Supervised Transformer Detection Network (WSTDN). Our algorithm is not only the first to demonstrate that self-attention modules that consider inter-instance relationships are effective backbones for WSOD, but also we introduce a novel bounding box mining method (BBM) integrated with a memory transfer refinement (MTR) procedure to utilize the instance dependencies for facilitating instance refinements. Experimental results on PASCAL VOC2007 and VOC2012 benchmarks demonstrate the effectiveness of our proposed WSTDN and modified instance refinement modules.
Sketch-Guided Text-to-Image Diffusion Models
Nov 24, 2022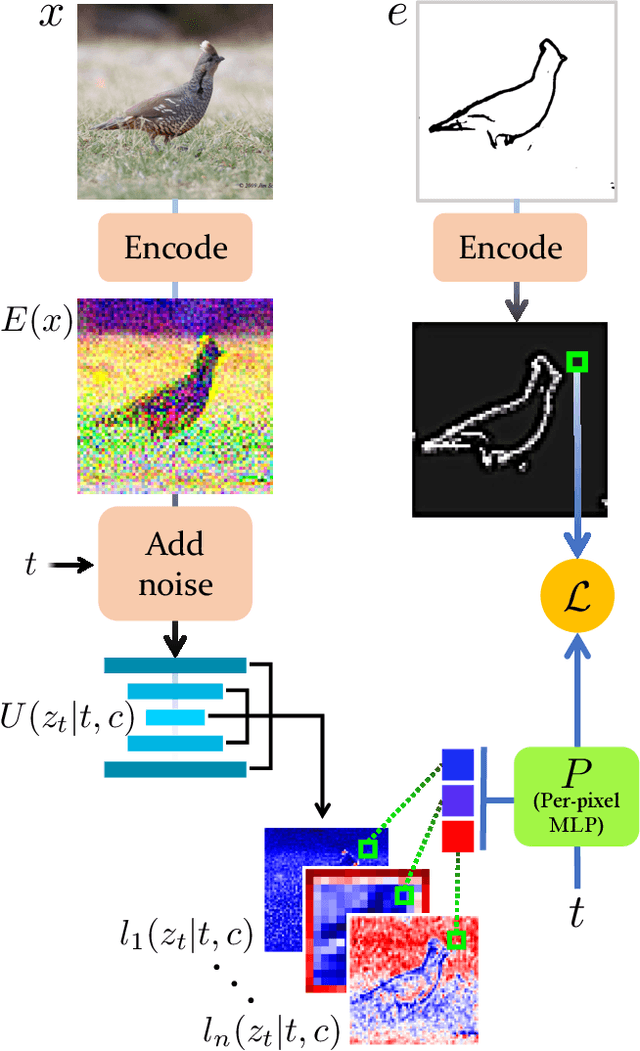
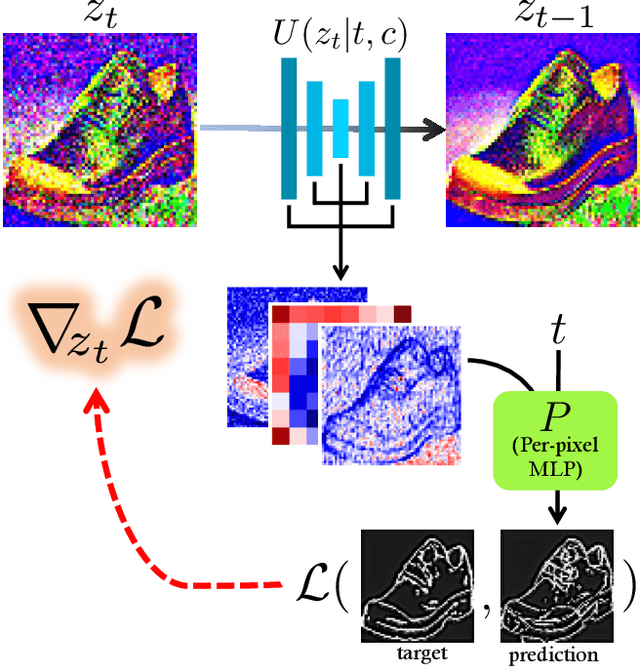

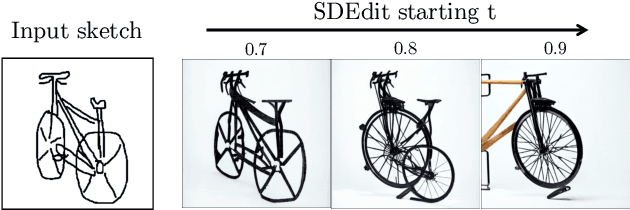
Text-to-Image models have introduced a remarkable leap in the evolution of machine learning, demonstrating high-quality synthesis of images from a given text-prompt. However, these powerful pretrained models still lack control handles that can guide spatial properties of the synthesized images. In this work, we introduce a universal approach to guide a pretrained text-to-image diffusion model, with a spatial map from another domain (e.g., sketch) during inference time. Unlike previous works, our method does not require to train a dedicated model or a specialized encoder for the task. Our key idea is to train a Latent Guidance Predictor (LGP) - a small, per-pixel, Multi-Layer Perceptron (MLP) that maps latent features of noisy images to spatial maps, where the deep features are extracted from the core Denoising Diffusion Probabilistic Model (DDPM) network. The LGP is trained only on a few thousand images and constitutes a differential guiding map predictor, over which the loss is computed and propagated back to push the intermediate images to agree with the spatial map. The per-pixel training offers flexibility and locality which allows the technique to perform well on out-of-domain sketches, including free-hand style drawings. We take a particular focus on the sketch-to-image translation task, revealing a robust and expressive way to generate images that follow the guidance of a sketch of arbitrary style or domain. Project page: sketch-guided-diffusion.github.io
DCFace: Synthetic Face Generation with Dual Condition Diffusion Model
Apr 14, 2023

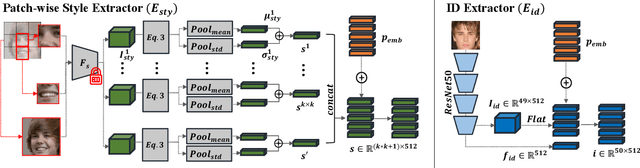
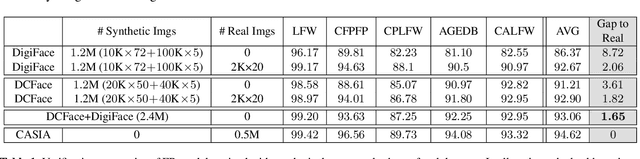
Generating synthetic datasets for training face recognition models is challenging because dataset generation entails more than creating high fidelity images. It involves generating multiple images of same subjects under different factors (\textit{e.g.}, variations in pose, illumination, expression, aging and occlusion) which follows the real image conditional distribution. Previous works have studied the generation of synthetic datasets using GAN or 3D models. In this work, we approach the problem from the aspect of combining subject appearance (ID) and external factor (style) conditions. These two conditions provide a direct way to control the inter-class and intra-class variations. To this end, we propose a Dual Condition Face Generator (DCFace) based on a diffusion model. Our novel Patch-wise style extractor and Time-step dependent ID loss enables DCFace to consistently produce face images of the same subject under different styles with precise control. Face recognition models trained on synthetic images from the proposed DCFace provide higher verification accuracies compared to previous works by $6.11\%$ on average in $4$ out of $5$ test datasets, LFW, CFP-FP, CPLFW, AgeDB and CALFW. Code is available at https://github.com/mk-minchul/dcface
CiPR: An Efficient Framework with Cross-instance Positive Relations for Generalized Category Discovery
Apr 14, 2023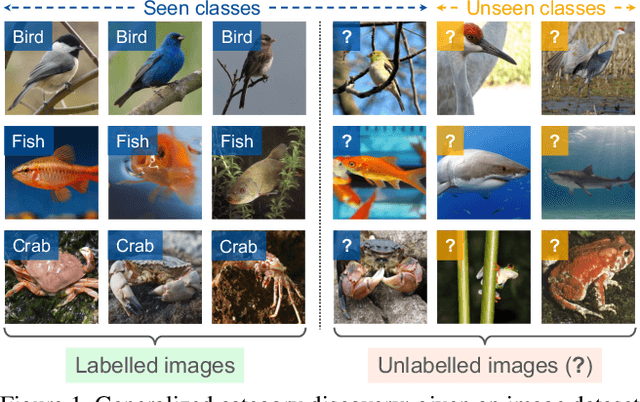
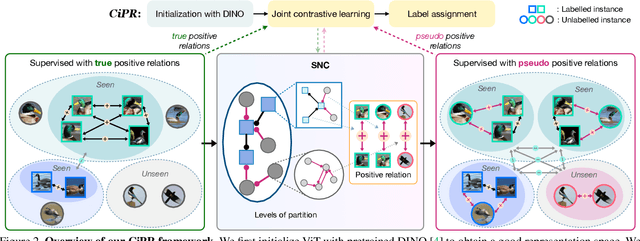
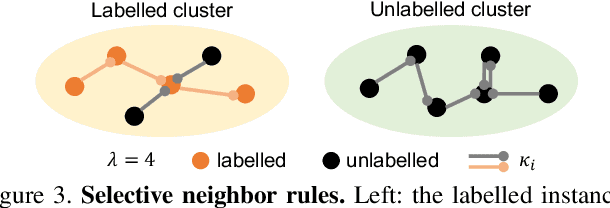
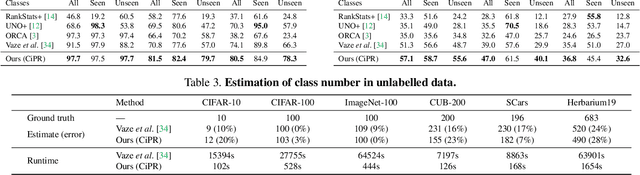
We tackle the issue of generalized category discovery (GCD). GCD considers the open-world problem of automatically clustering a partially labelled dataset, in which the unlabelled data contain instances from novel categories and also the labelled classes. In this paper, we address the GCD problem without a known category number in the unlabelled data. We propose a framework, named CiPR, to bootstrap the representation by exploiting Cross-instance Positive Relations for contrastive learning in the partially labelled data which are neglected in existing methods. First, to obtain reliable cross-instance relations to facilitate the representation learning, we introduce a semi-supervised hierarchical clustering algorithm, named selective neighbor clustering (SNC), which can produce a clustering hierarchy directly from the connected components in the graph constructed by selective neighbors. We also extend SNC to be capable of label assignment for the unlabelled instances with the given class number. Moreover, we present a method to estimate the unknown class number using SNC with a joint reference score considering clustering indexes of both labelled and unlabelled data. Finally, we thoroughly evaluate our framework on public generic image recognition datasets and challenging fine-grained datasets, all establishing the new state-of-the-art.
Tailored Multi-Organ Segmentation with Model Adaptation and Ensemble
Apr 14, 2023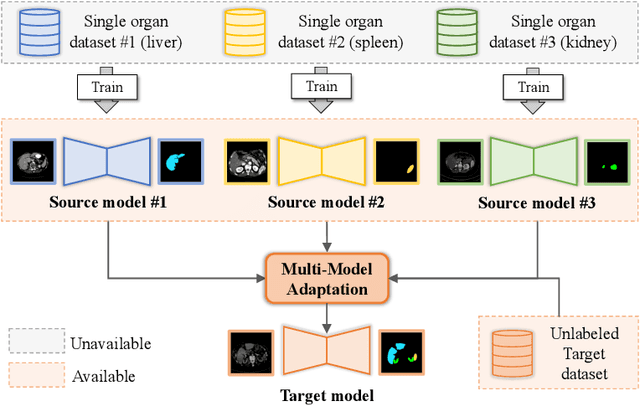
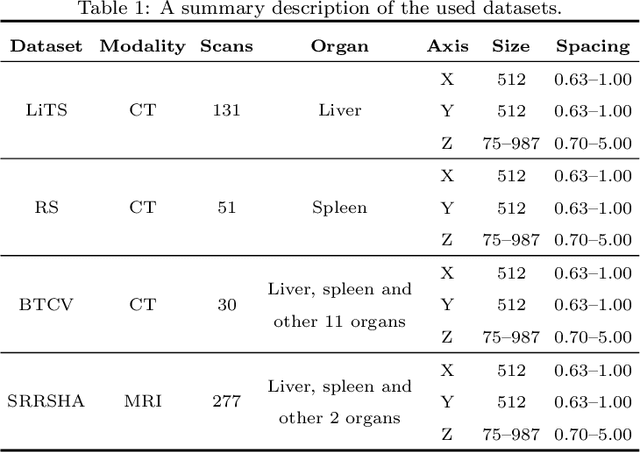
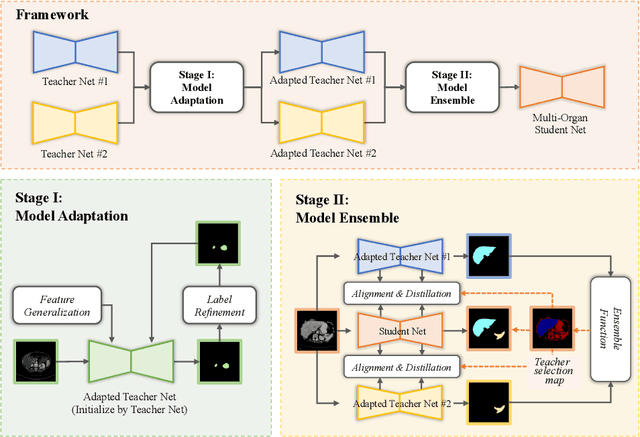
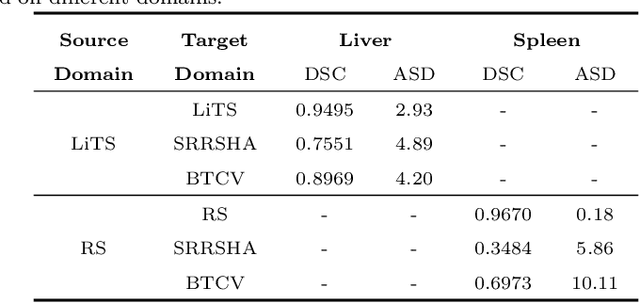
Multi-organ segmentation, which identifies and separates different organs in medical images, is a fundamental task in medical image analysis. Recently, the immense success of deep learning motivated its wide adoption in multi-organ segmentation tasks. However, due to expensive labor costs and expertise, the availability of multi-organ annotations is usually limited and hence poses a challenge in obtaining sufficient training data for deep learning-based methods. In this paper, we aim to address this issue by combining off-the-shelf single-organ segmentation models to develop a multi-organ segmentation model on the target dataset, which helps get rid of the dependence on annotated data for multi-organ segmentation. To this end, we propose a novel dual-stage method that consists of a Model Adaptation stage and a Model Ensemble stage. The first stage enhances the generalization of each off-the-shelf segmentation model on the target domain, while the second stage distills and integrates knowledge from multiple adapted single-organ segmentation models. Extensive experiments on four abdomen datasets demonstrate that our proposed method can effectively leverage off-the-shelf single-organ segmentation models to obtain a tailored model for multi-organ segmentation with high accuracy.
Phantom Embeddings: Using Embedding Space for Model Regularization in Deep Neural Networks
Apr 14, 2023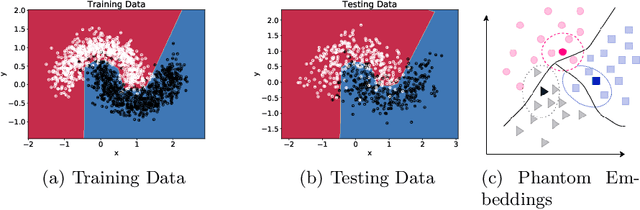
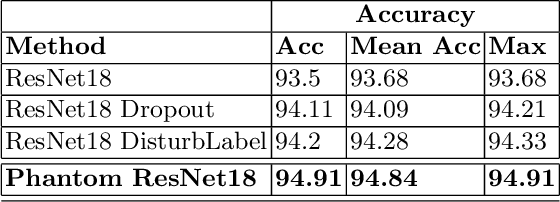
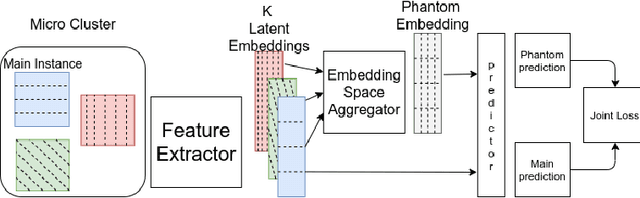
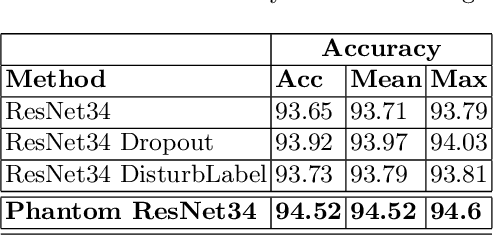
The strength of machine learning models stems from their ability to learn complex function approximations from data; however, this strength also makes training deep neural networks challenging. Notably, the complex models tend to memorize the training data, which results in poor regularization performance on test data. The regularization techniques such as L1, L2, dropout, etc. are proposed to reduce the overfitting effect; however, they bring in additional hyperparameters tuning complexity. These methods also fall short when the inter-class similarity is high due to the underlying data distribution, leading to a less accurate model. In this paper, we present a novel approach to regularize the models by leveraging the information-rich latent embeddings and their high intra-class correlation. We create phantom embeddings from a subset of homogenous samples and use these phantom embeddings to decrease the inter-class similarity of instances in their latent embedding space. The resulting models generalize better as a combination of their embedding and regularize them without requiring an expensive hyperparameter search. We evaluate our method on two popular and challenging image classification datasets (CIFAR and FashionMNIST) and show how our approach outperforms the standard baselines while displaying better training behavior.
Bag of Tricks with Quantized Convolutional Neural Networks for image classification
Mar 13, 2023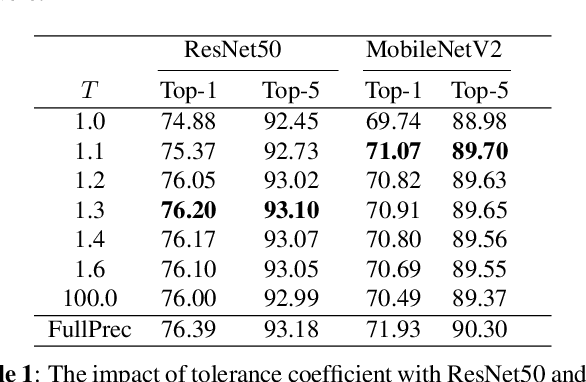

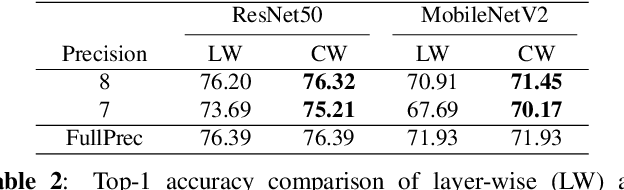
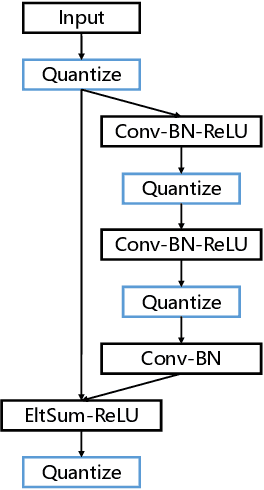
Deep neural networks have been proven effective in a wide range of tasks. However, their high computational and memory costs make them impractical to deploy on resource-constrained devices. To address this issue, quantization schemes have been proposed to reduce the memory footprint and improve inference speed. While numerous quantization methods have been proposed, they lack systematic analysis for their effectiveness. To bridge this gap, we collect and improve existing quantization methods and propose a gold guideline for post-training quantization. We evaluate the effectiveness of our proposed method with two popular models, ResNet50 and MobileNetV2, on the ImageNet dataset. By following our guidelines, no accuracy degradation occurs even after directly quantizing the model to 8-bits without additional training. A quantization-aware training based on the guidelines can further improve the accuracy in lower-bits quantization. Moreover, we have integrated a multi-stage fine-tuning strategy that works harmoniously with existing pruning techniques to reduce costs even further. Remarkably, our results reveal that a quantized MobileNetV2 with 30\% sparsity actually surpasses the performance of the equivalent full-precision model, underscoring the effectiveness and resilience of our proposed scheme.