 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Inverse problem regularization with hierarchical variational autoencoders
Mar 20, 2023
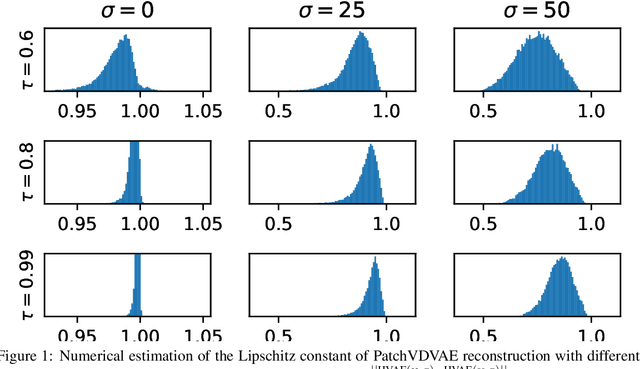
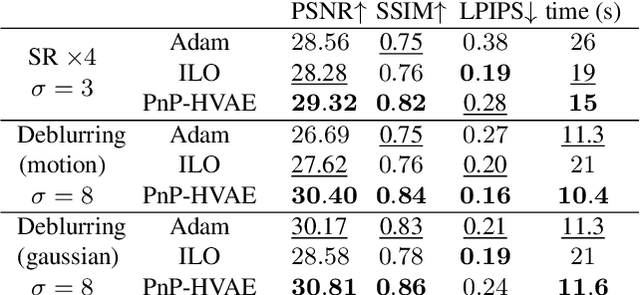
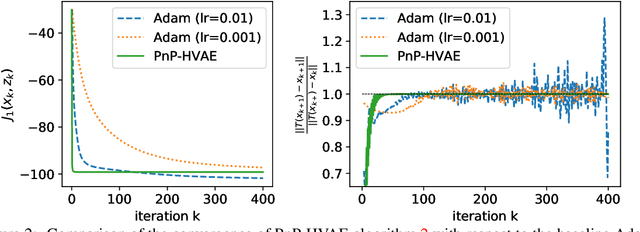
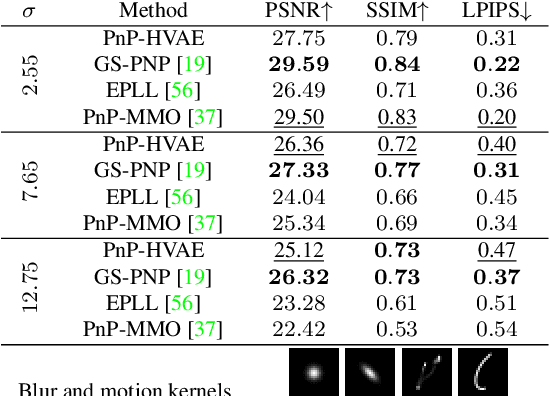
In this paper, we propose to regularize ill-posed inverse problems using a deep hierarchical variational autoencoder (HVAE) as an image prior. The proposed method synthesizes the advantages of i) denoiser-based Plug \& Play approaches and ii) generative model based approaches to inverse problems. First, we exploit VAE properties to design an efficient algorithm that benefits from convergence guarantees of Plug-and-Play (PnP) methods. Second, our approach is not restricted to specialized datasets and the proposed PnP-HVAE model is able to solve image restoration problems on natural images of any size. Our experiments show that the proposed PnP-HVAE method is competitive with both SOTA denoiser-based PnP approaches, and other SOTA restoration methods based on generative models.
Optimal Goal-Reaching Reinforcement Learning via Quasimetric Learning
Apr 03, 2023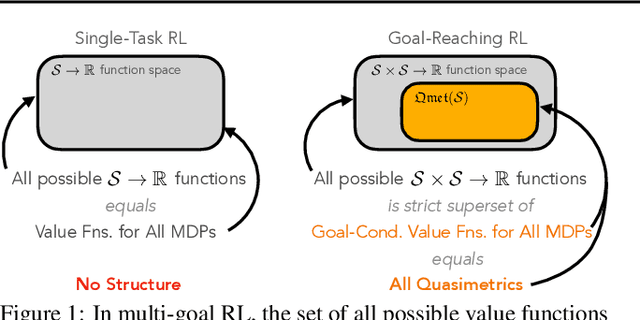
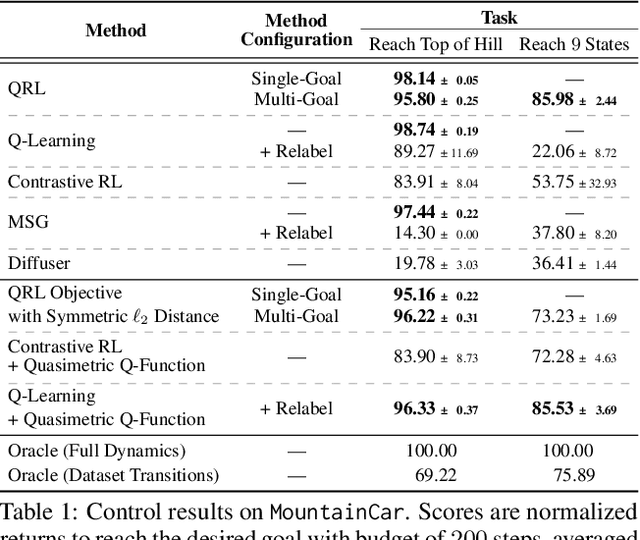
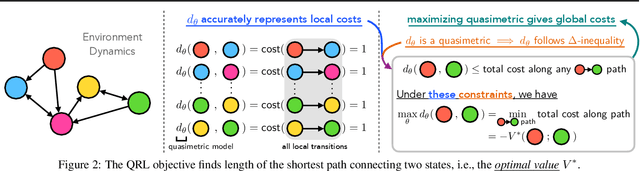
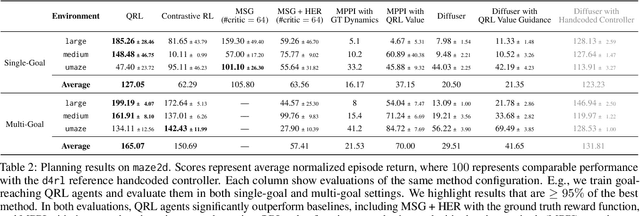
In goal-reaching reinforcement learning (RL), the optimal value function has a particular geometry, called quasimetric structure. This paper introduces Quasimetric Reinforcement Learning (QRL), a new RL method that utilizes quasimetric models to learn optimal value functions. Distinct from prior approaches, the QRL objective is specifically designed for quasimetrics, and provides strong theoretical recovery guarantees. Empirically, we conduct thorough analyses on a discretized MountainCar environment, identifying properties of QRL and its advantages over alternatives. On offline and online goal-reaching benchmarks, QRL also demonstrates improved sample efficiency and performance, across both state-based and image-based observations.
Decoding natural image stimuli from fMRI data with a surface-based convolutional network
Dec 05, 2022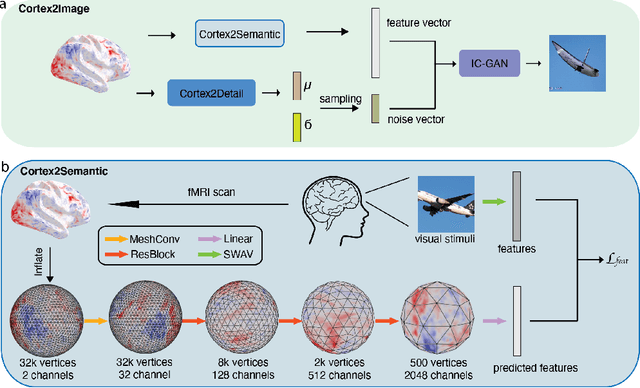

Due to the low signal-to-noise ratio and limited resolution of functional MRI data, and the high complexity of natural images, reconstructing a visual stimulus from human brain fMRI measurements is a challenging task. In this work, we propose a novel approach for this task, which we call Cortex2Image, to decode visual stimuli with high semantic fidelity and rich fine-grained detail. In particular, we train a surface-based convolutional network model that maps from brain response to semantic image features first (Cortex2Semantic). We then combine this model with a high-quality image generator (Instance-Conditioned GAN) to train another mapping from brain response to fine-grained image features using a variational approach (Cortex2Detail). Image reconstructions obtained by our proposed method achieve state-of-the-art semantic fidelity, while yielding good fine-grained similarity with the ground-truth stimulus. Our code is available at: https://github.com/zijin-gu/meshconv-decoding.git.
Reverse Engineering Breast MRIs: Predicting Acquisition Parameters Directly from Images
Mar 08, 2023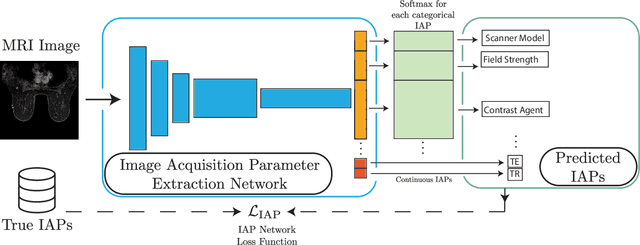
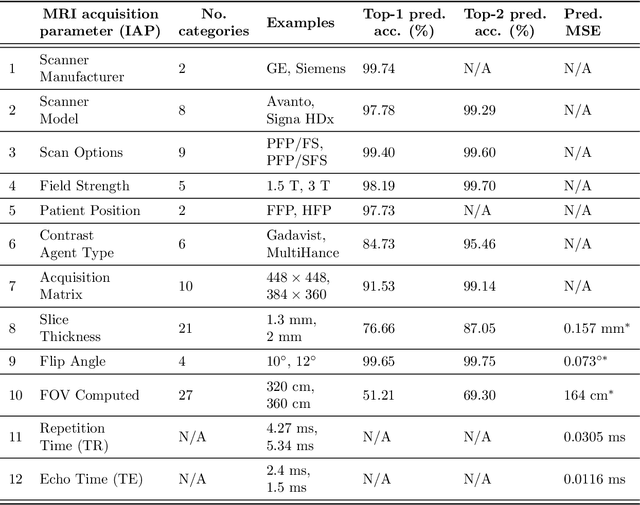
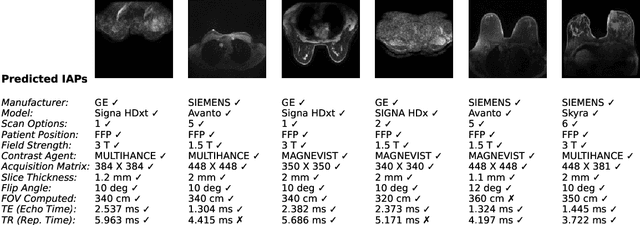

The image acquisition parameters (IAPs) used to create MRI scans are central to defining the appearance of the images. Deep learning models trained on data acquired using certain parameters might not generalize well to images acquired with different parameters. Being able to recover such parameters directly from an image could help determine whether a deep learning model is applicable, and could assist with data harmonization and/or domain adaptation. Here, we introduce a neural network model that can predict many complex IAPs used to generate an MR image with high accuracy solely using the image, with a single forward pass. These predicted parameters include field strength, echo and repetition times, acquisition matrix, scanner model, scan options, and others. Even challenging parameters such as contrast agent type can be predicted with good accuracy. We perform a variety of experiments and analyses of our model's ability to predict IAPs on many MRI scans of new patients, and demonstrate its usage in a realistic application. Predicting IAPs from the images is an important step toward better understanding the relationship between image appearance and IAPs. This in turn will advance the understanding of many concepts related to the generalizability of neural network models on medical images, including domain shift, domain adaptation, and data harmonization.
Reflected Diffusion Models
Apr 13, 2023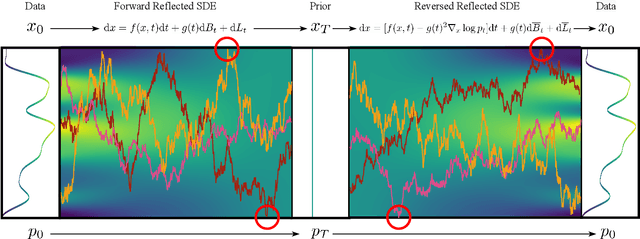
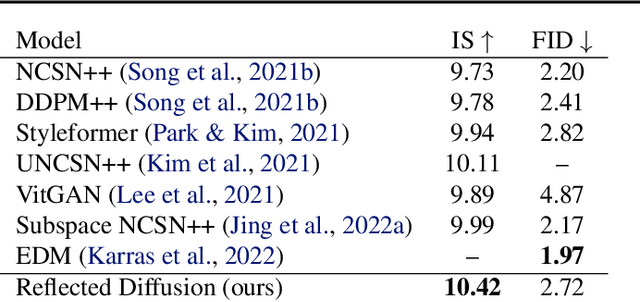
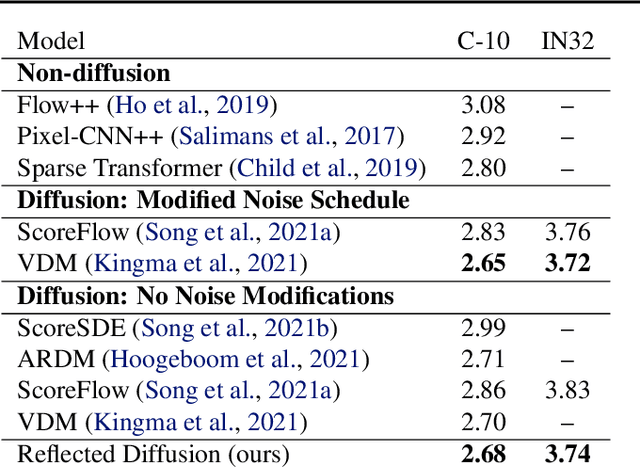
Score-based diffusion models learn to reverse a stochastic differential equation that maps data to noise. However, for complex tasks, numerical error can compound and result in highly unnatural samples. Previous work mitigates this drift with thresholding, which projects to the natural data domain (such as pixel space for images) after each diffusion step, but this leads to a mismatch between the training and generative processes. To incorporate data constraints in a principled manner, we present Reflected Diffusion Models, which instead reverse a reflected stochastic differential equation evolving on the support of the data. Our approach learns the perturbed score function through a generalized score matching loss and extends key components of standard diffusion models including diffusion guidance, likelihood-based training, and ODE sampling. We also bridge the theoretical gap with thresholding: such schemes are just discretizations of reflected SDEs. On standard image benchmarks, our method is competitive with or surpasses the state of the art and, for classifier-free guidance, our approach enables fast exact sampling with ODEs and produces more faithful samples under high guidance weight.
Optimizing Multi-Domain Performance with Active Learning-based Improvement Strategies
Apr 13, 2023Improving performance in multiple domains is a challenging task, and often requires significant amounts of data to train and test models. Active learning techniques provide a promising solution by enabling models to select the most informative samples for labeling, thus reducing the amount of labeled data required to achieve high performance. In this paper, we present an active learning-based framework for improving performance across multiple domains. Our approach consists of two stages: first, we use an initial set of labeled data to train a base model, and then we iteratively select the most informative samples for labeling to refine the model. We evaluate our approach on several multi-domain datasets, including image classification, sentiment analysis, and object recognition. Our experiments demonstrate that our approach consistently outperforms baseline methods and achieves state-of-the-art performance on several datasets. We also show that our method is highly efficient, requiring significantly fewer labeled samples than other active learning-based methods. Overall, our approach provides a practical and effective solution for improving performance across multiple domains using active learning techniques.
Focus! Relevant and Sufficient Context Selection for News Image Captioning
Dec 01, 2022
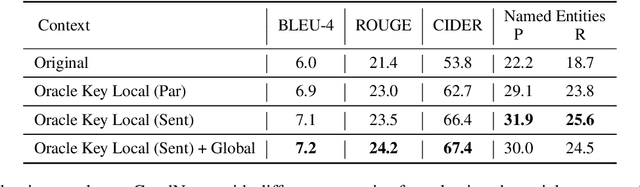
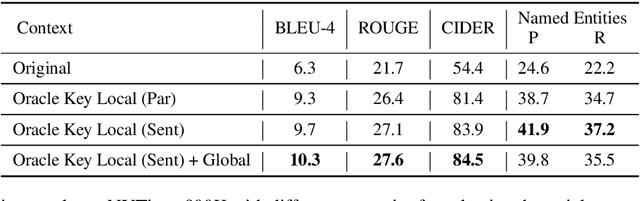
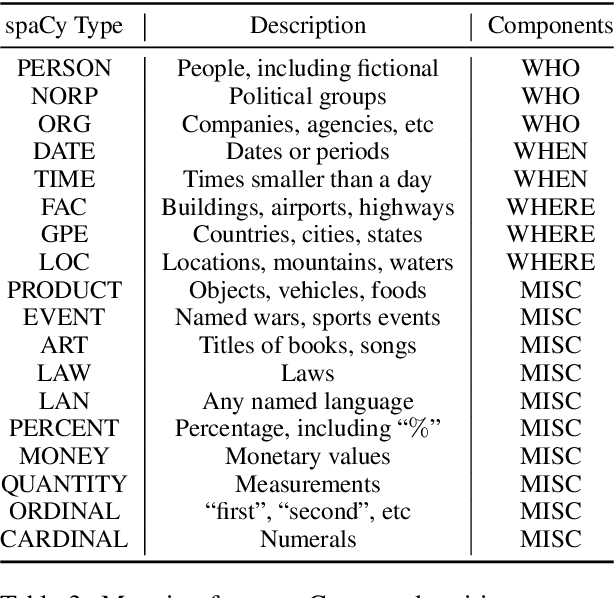
News Image Captioning requires describing an image by leveraging additional context from a news article. Previous works only coarsely leverage the article to extract the necessary context, which makes it challenging for models to identify relevant events and named entities. In our paper, we first demonstrate that by combining more fine-grained context that captures the key named entities (obtained via an oracle) and the global context that summarizes the news, we can dramatically improve the model's ability to generate accurate news captions. This begs the question, how to automatically extract such key entities from an image? We propose to use the pre-trained vision and language retrieval model CLIP to localize the visually grounded entities in the news article and then capture the non-visual entities via an open relation extraction model. Our experiments demonstrate that by simply selecting a better context from the article, we can significantly improve the performance of existing models and achieve new state-of-the-art performance on multiple benchmarks.
Color Image steganography using Deep convolutional Autoencoders based on ResNet architecture
Nov 17, 2022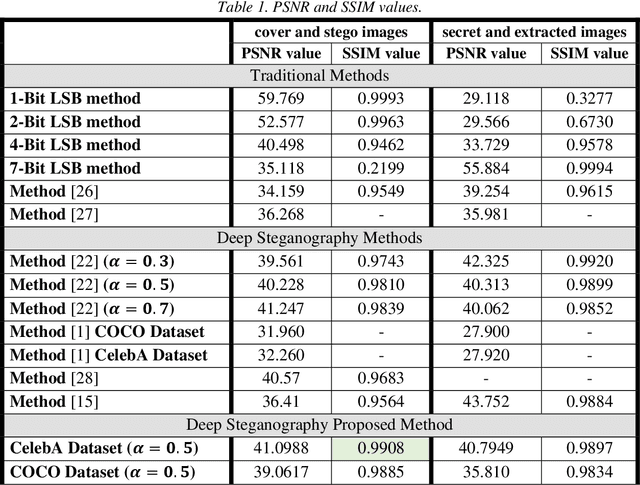
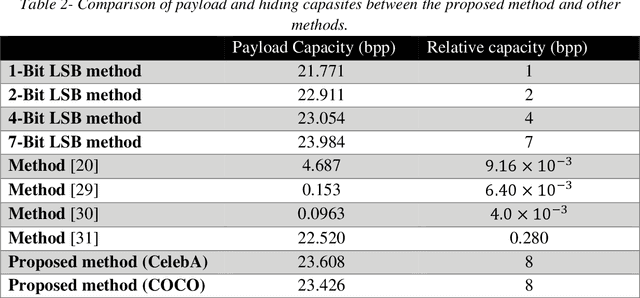

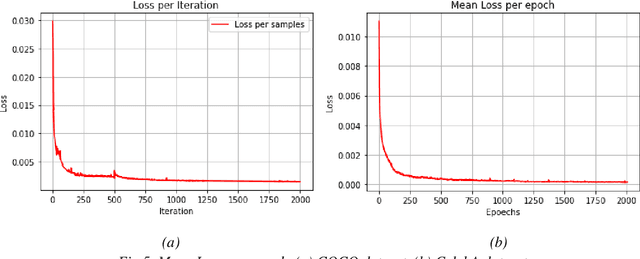
In this paper, a deep learning color image steganography scheme combining convolutional autoencoders and ResNet architecture is proposed. Traditional steganography methods suffer from some critical defects such as low capacity, security, and robustness. In recent decades, image hiding and image extraction were realized by autoencoder convolutional neural networks to solve the aforementioned challenges. The contribution of this paper is introducing a new scheme for color image steganography inspired by ResNet architecture. The reverse ResNet architecture is utilized to extract the secret image from the stego image. In the proposed method, all images are passed through the prepossess model which is a convolutional deep neural network with the aim of feature extraction. Then, the operational model generates stego and extracted images. In fact, the operational model is an autoencoder based on ResNet structure that produces an image from feature maps. The advantage of proposed structure is identity of models in embedding and extraction phases. The performance of the proposed method is studied using COCO and CelebA datasets. For quantitative comparisons with previous related works, peak signal-to-noise ratio (PSNR), the structural similarity index (SSIM) and hiding capacity are evaluated. The experimental results verify that the proposed scheme performs better than traditional and pervious deep steganography methods. The PSNR and SSIM are more than 40 dB and 0.98, respectively that implies high imperceptibility of the proposed method. Also, this method can hide a color image of the same size in another color image, which can be inferred that the relative capacity of the proposed method is 8 bits per pixel.
Human Motion Detection Based on Dual-Graph and Weighted Nuclear Norm Regularizations
Apr 10, 2023
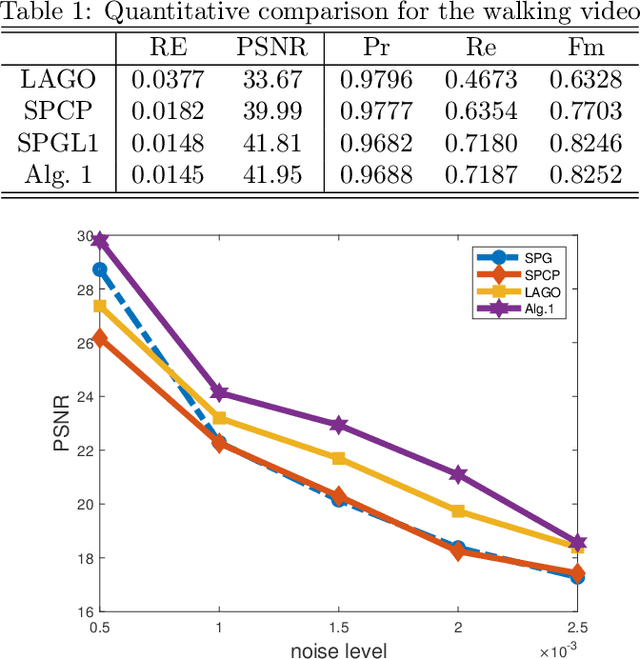


Motion detection has been widely used in many applications, such as surveillance and robotics. Due to the presence of the static background, a motion video can be decomposed into a low-rank background and a sparse foreground. Many regularization techniques that preserve low-rankness of matrices can therefore be imposed on the background. In the meanwhile, geometry-based regularizations, such as graph regularizations, can be imposed on the foreground. Recently, weighted regularization techniques including the weighted nuclear norm regularization have been proposed in the image processing community to promote adaptive sparsity while achieving efficient performance. In this paper, we propose a robust dual graph regularized moving object detection model based on a novel weighted nuclear norm regularization and spatiotemporal graph Laplacians. Numerical experiments on realistic human motion data sets have demonstrated the effectiveness and robustness of this approach in separating moving objects from background, and the enormous potential in robotic applications.
Asymmetric Polynomial Loss For Multi-Label Classification
Apr 10, 2023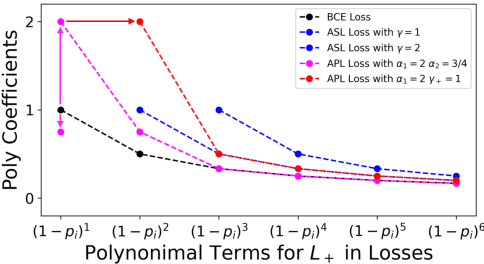
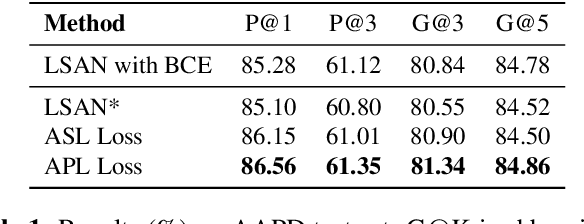
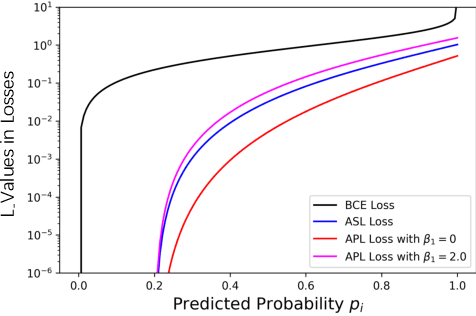

Various tasks are reformulated as multi-label classification problems, in which the binary cross-entropy (BCE) loss is frequently utilized for optimizing well-designed models. However, the vanilla BCE loss cannot be tailored for diverse tasks, resulting in a suboptimal performance for different models. Besides, the imbalance between redundant negative samples and rare positive samples could degrade the model performance. In this paper, we propose an effective Asymmetric Polynomial Loss (APL) to mitigate the above issues. Specifically, we first perform Taylor expansion on BCE loss. Then we ameliorate the coefficients of polynomial functions. We further employ the asymmetric focusing mechanism to decouple the gradient contribution from the negative and positive samples. Moreover, we validate that the polynomial coefficients can recalibrate the asymmetric focusing hyperparameters. Experiments on relation extraction, text classification, and image classification show that our APL loss can consistently improve performance without extra training burden.