 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Not All Features Matter: Enhancing Few-shot CLIP with Adaptive Prior Refinement
Apr 03, 2023
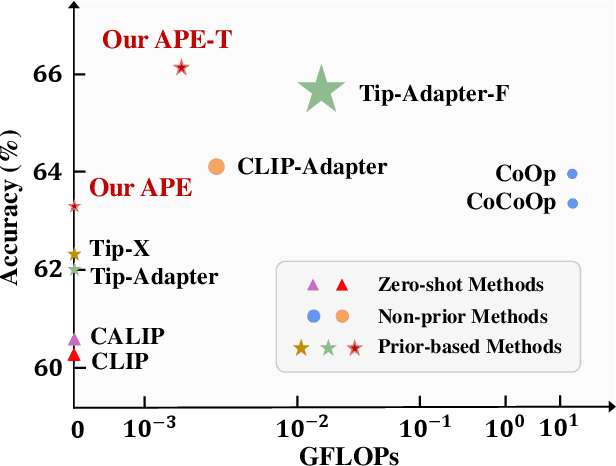
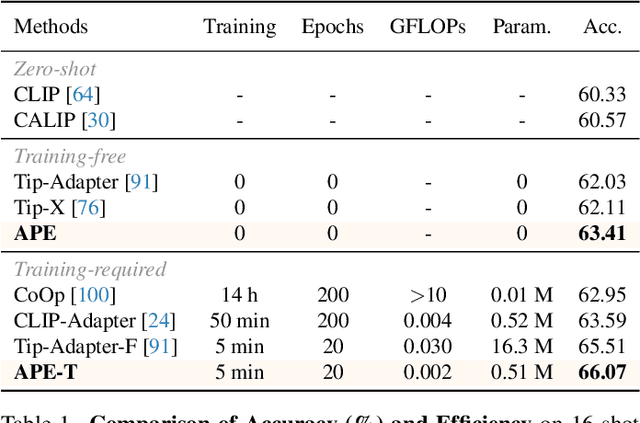
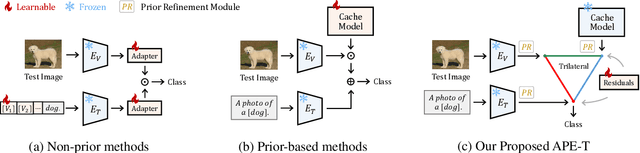
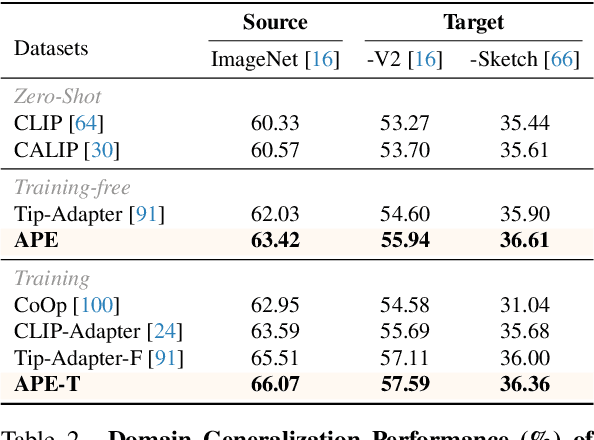
The popularity of Contrastive Language-Image Pre-training (CLIP) has propelled its application to diverse downstream vision tasks. To improve its capacity on downstream tasks, few-shot learning has become a widely-adopted technique. However, existing methods either exhibit limited performance or suffer from excessive learnable parameters. In this paper, we propose APE, an Adaptive Prior rEfinement method for CLIP's pre-trained knowledge, which achieves superior accuracy with high computational efficiency. Via a prior refinement module, we analyze the inter-class disparity in the downstream data and decouple the domain-specific knowledge from the CLIP-extracted cache model. On top of that, we introduce two model variants, a training-free APE and a training-required APE-T. We explore the trilateral affinities between the test image, prior cache model, and textual representations, and only enable a lightweight category-residual module to be trained. For the average accuracy over 11 benchmarks, both APE and APE-T attain state-of-the-art and respectively outperform the second-best by +1.59% and +1.99% under 16 shots with x30 less learnable parameters.
Zero-Shot Semantic Segmentation with Decoupled One-Pass Network
Apr 03, 2023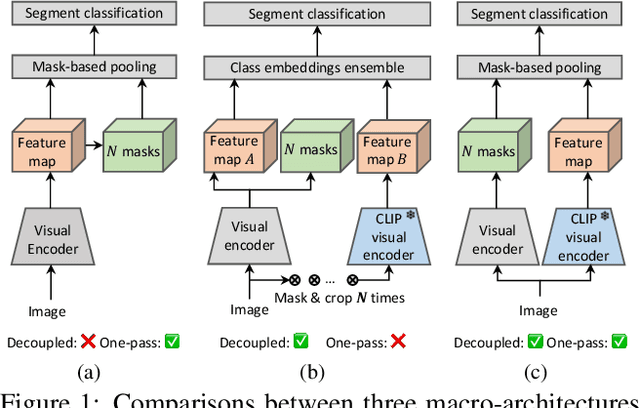
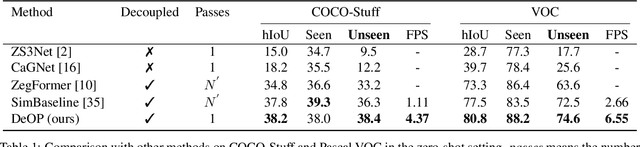
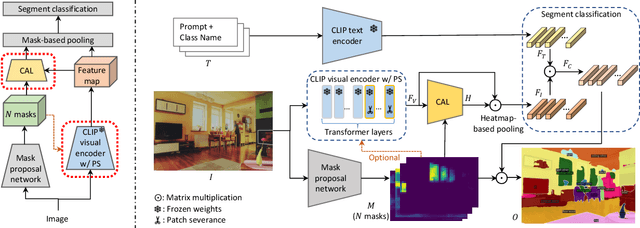

Recently, the zero-shot semantic segmentation problem has attracted increasing attention, and the best performing methods are based on two-stream networks: one stream for proposal mask generation and the other for segment classification using a pre-trained visual-language model. However, existing two-stream methods require passing a great number of (up to a hundred) image crops into the visuallanguage model, which is highly inefficient. To address the problem, we propose a network that only needs a single pass through the visual-language model for each input image. Specifically, we first propose a novel network adaptation approach, termed patch severance, to restrict the harmful interference between the patch embeddings in the pre-trained visual encoder. We then propose classification anchor learning to encourage the network to spatially focus on more discriminative features for classification. Extensive experiments demonstrate that the proposed method achieves outstanding performance, surpassing state-of-theart methods while being 4 to 7 times faster at inference. We release our code at https://github.com/CongHan0808/DeOP.git.
CoReFusion: Contrastive Regularized Fusion for Guided Thermal Super-Resolution
Apr 03, 2023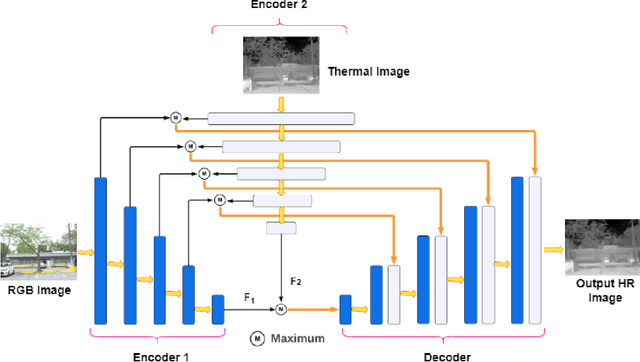

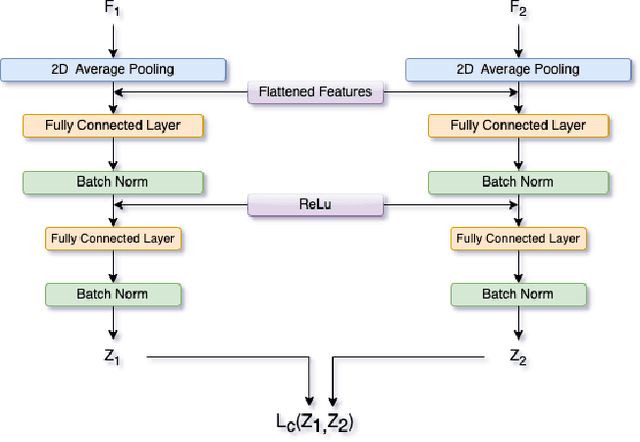
Thermal imaging has numerous advantages over regular visible-range imaging since it performs well in low-light circumstances. Super-Resolution approaches can broaden their usefulness by replicating accurate high-resolution thermal pictures using measurements from low-cost, low-resolution thermal sensors. Because of the spectral range mismatch between the images, Guided Super-Resolution of thermal images utilizing visible range images is difficult. However, In case of failure to capture Visible Range Images can prevent the operations of applications in critical areas. We present a novel data fusion framework and regularization technique for Guided Super Resolution of Thermal images. The proposed architecture is computationally in-expensive and lightweight with the ability to maintain performance despite missing one of the modalities, i.e., high-resolution RGB image or the lower-resolution thermal image, and is designed to be robust in the presence of missing data. The proposed method presents a promising solution to the frequently occurring problem of missing modalities in a real-world scenario. Code is available at https://github.com/Kasliwal17/CoReFusion.
COSST: Multi-organ Segmentation with Partially Labeled Datasets Using Comprehensive Supervisions and Self-training
Apr 28, 2023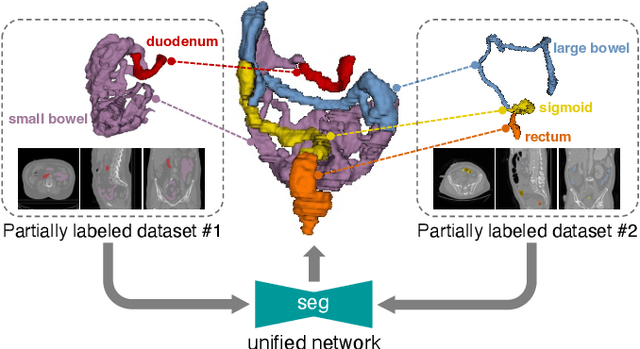
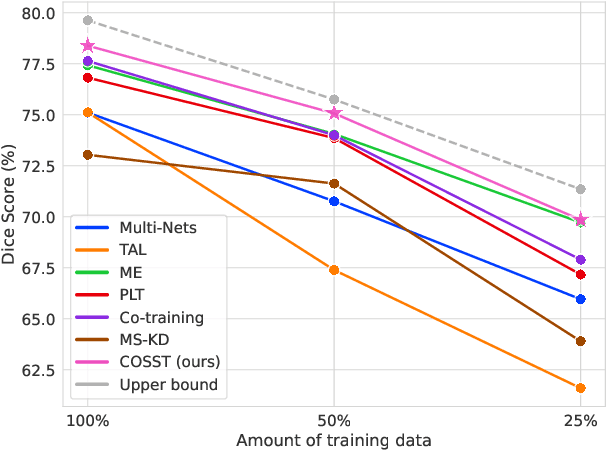
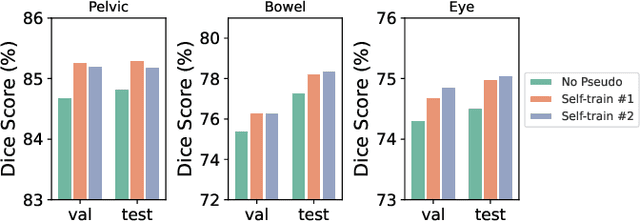
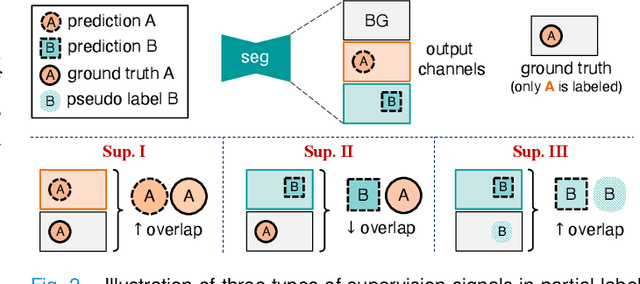
Deep learning models have demonstrated remarkable success in multi-organ segmentation but typically require large-scale datasets with all organs of interest annotated. However, medical image datasets are often low in sample size and only partially labeled, i.e., only a subset of organs are annotated. Therefore, it is crucial to investigate how to learn a unified model on the available partially labeled datasets to leverage their synergistic potential. In this paper, we empirically and systematically study the partial-label segmentation with in-depth analyses on the existing approaches and identify three distinct types of supervision signals, including two signals derived from ground truth and one from pseudo label. We propose a novel training framework termed COSST, which effectively and efficiently integrates comprehensive supervision signals with self-training. Concretely, we first train an initial unified model using two ground truth-based signals and then iteratively incorporate the pseudo label signal to the initial model using self-training. To mitigate performance degradation caused by unreliable pseudo labels, we assess the reliability of pseudo labels via outlier detection in latent space and exclude the most unreliable pseudo labels from each self-training iteration. Extensive experiments are conducted on six CT datasets for three partial-label segmentation tasks. Experimental results show that our proposed COSST achieves significant improvement over the baseline method, i.e., individual networks trained on each partially labeled dataset. Compared to the state-of-the-art partial-label segmentation methods, COSST demonstrates consistent superior performance on various segmentation tasks and with different training data size.
Towards Robust Text-Prompted Semantic Criterion for In-the-Wild Video Quality Assessment
Apr 28, 2023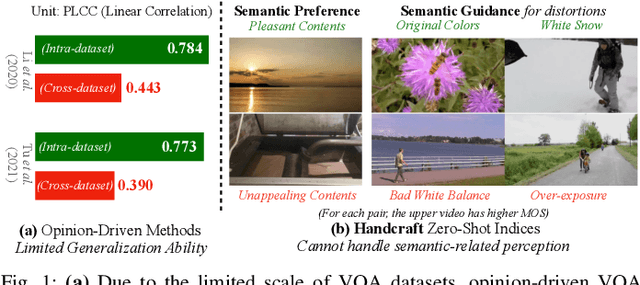
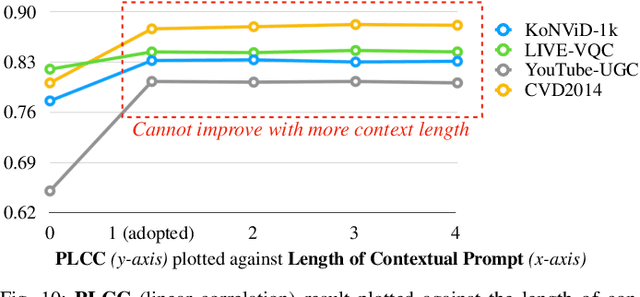
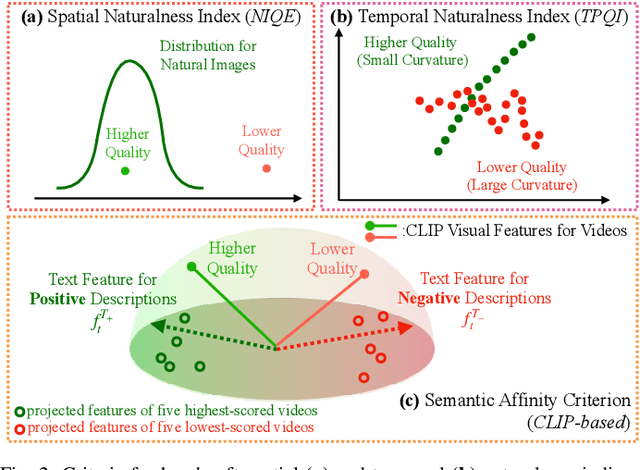
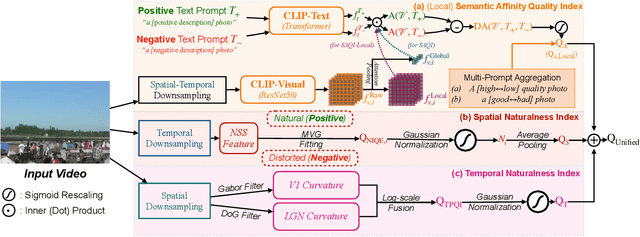
The proliferation of videos collected during in-the-wild natural settings has pushed the development of effective Video Quality Assessment (VQA) methodologies. Contemporary supervised opinion-driven VQA strategies predominantly hinge on training from expensive human annotations for quality scores, which limited the scale and distribution of VQA datasets and consequently led to unsatisfactory generalization capacity of methods driven by these data. On the other hand, although several handcrafted zero-shot quality indices do not require training from human opinions, they are unable to account for the semantics of videos, rendering them ineffective in comprehending complex authentic distortions (e.g., white balance, exposure) and assessing the quality of semantic content within videos. To address these challenges, we introduce the text-prompted Semantic Affinity Quality Index (SAQI) and its localized version (SAQI-Local) using Contrastive Language-Image Pre-training (CLIP) to ascertain the affinity between textual prompts and visual features, facilitating a comprehensive examination of semantic quality concerns without the reliance on human quality annotations. By amalgamating SAQI with existing low-level metrics, we propose the unified Blind Video Quality Index (BVQI) and its improved version, BVQI-Local, which demonstrates unprecedented performance, surpassing existing zero-shot indices by at least 24\% on all datasets. Moreover, we devise an efficient fine-tuning scheme for BVQI-Local that jointly optimizes text prompts and final fusion weights, resulting in state-of-the-art performance and superior generalization ability in comparison to prevalent opinion-driven VQA methods. We conduct comprehensive analyses to investigate different quality concerns of distinct indices, demonstrating the effectiveness and rationality of our design.
Mixture-Net: Low-Rank Deep Image Prior Inspired by Mixture Models for Spectral Image Recovery
Nov 05, 2022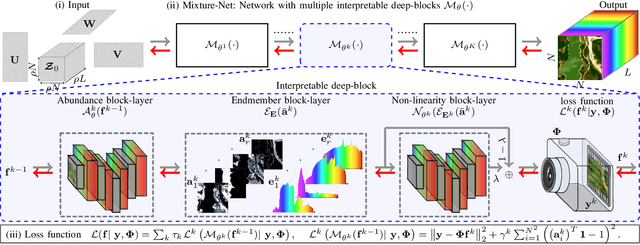
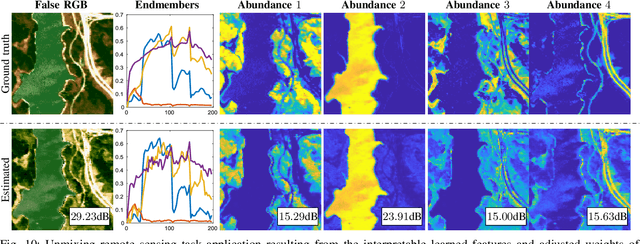

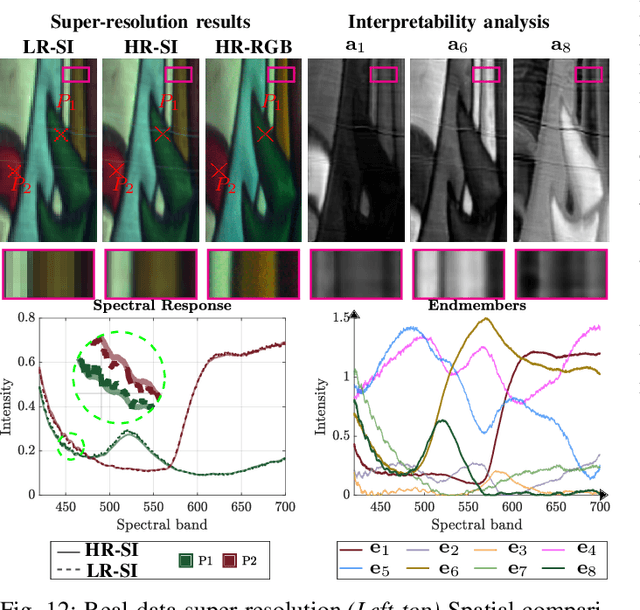
This paper proposes a non-data-driven deep neural network for spectral image recovery problems such as denoising, single hyperspectral image super-resolution, and compressive spectral imaging reconstruction. Unlike previous methods, the proposed approach, dubbed Mixture-Net, implicitly learns the prior information through the network. Mixture-Net consists of a deep generative model whose layers are inspired by the linear and non-linear low-rank mixture models, where the recovered image is composed of a weighted sum between the linear and non-linear decomposition. Mixture-Net also provides a low-rank decomposition interpreted as the spectral image abundances and endmembers, helpful in achieving remote sensing tasks without running additional routines. The experiments show the MixtureNet effectiveness outperforming state-of-the-art methods in recovery quality with the advantage of architecture interpretability.
Self-Supervised Pre-training of 3D Point Cloud Networks with Image Data
Dec 13, 2022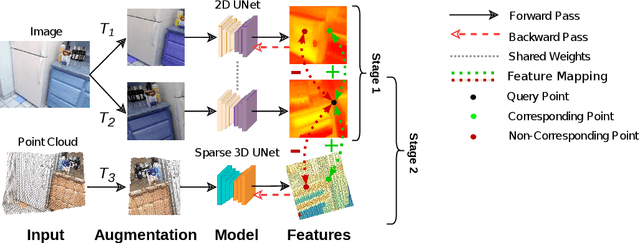

Reducing the quantity of annotations required for supervised training is vital when labels are scarce and costly. This reduction is especially important for semantic segmentation tasks involving 3D datasets that are often significantly smaller and more challenging to annotate than their image-based counterparts. Self-supervised pre-training on large unlabelled datasets is one way to reduce the amount of manual annotations needed. Previous work has focused on pre-training with point cloud data exclusively; this approach often requires two or more registered views. In the present work, we combine image and point cloud modalities, by first learning self-supervised image features and then using these features to train a 3D model. By incorporating image data, which is often included in many 3D datasets, our pre-training method only requires a single scan of a scene. We demonstrate that our pre-training approach, despite using single scans, achieves comparable performance to other multi-scan, point cloud-only methods.
Optimization of Image Transmission in a Cooperative Semantic Communication Networks
Jan 01, 2023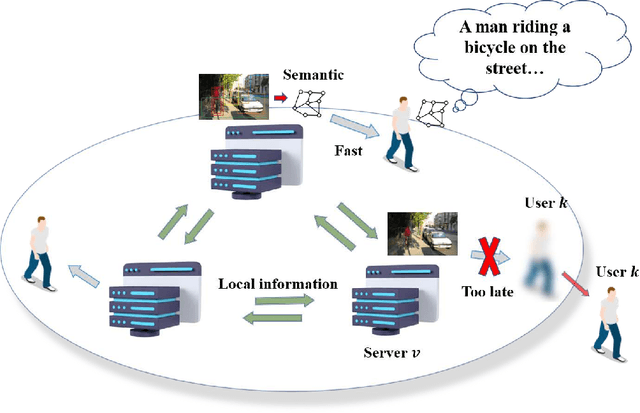
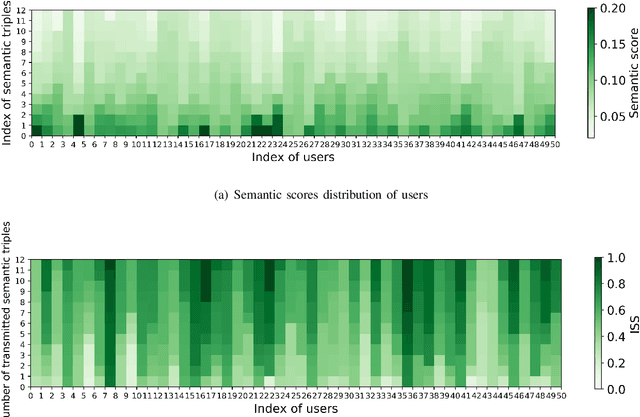
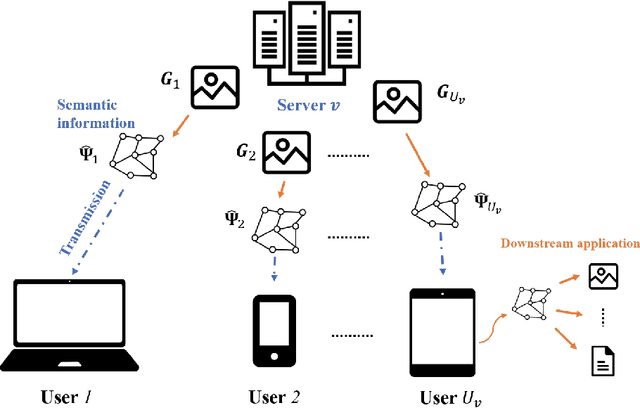
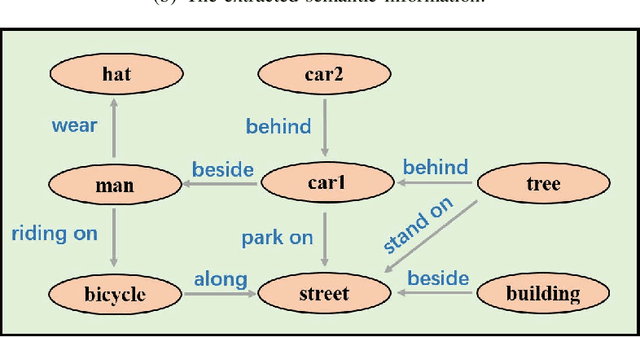
In this paper, a semantic communication framework for image transmission is developed. In the investigated framework, a set of servers cooperatively transmit images to a set of users utilizing semantic communication techniques. To evaluate the performance of studied semantic communication system, a multimodal metric is proposed to measure the correlation between the extracted semantic information and the original image. To meet the ISS requirement of each user, each server must jointly determine the semantic information to be transmitted and the resource blocks (RBs) used for semantic information transmission. We formulate this problem as an optimization problem aiming to minimize each server's transmission latency while reaching the ISS requirement. To solve this problem, a value decomposition based entropy-maximized multi-agent reinforcement learning (RL) is proposed, which enables servers to coordinate for training and execute RB allocation in a distributed manner to approach to a globally optimal performance with less training iterations. Compared to traditional multi-agent RL, the proposed RL improves the valuable action exploration of servers and the probability of finding a globally optimal RB allocation policy based on local observation. Simulation results show that the proposed algorithm can reduce the transmission delay by up to 16.1% compared to traditional multi-agent RL.
From Smart to Intelligent Utility Meters in Natural Gas Distribution Networks
Apr 01, 2023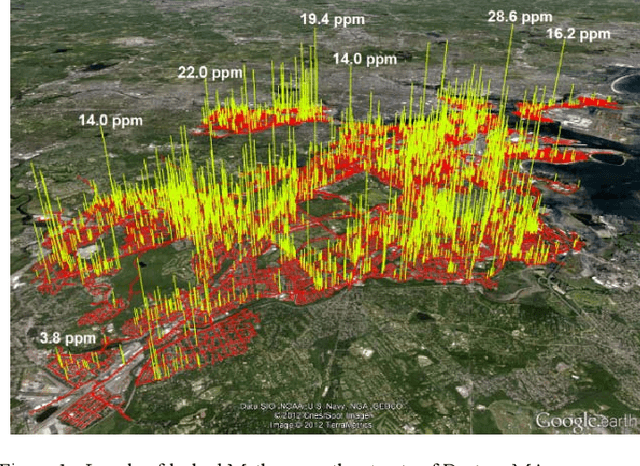
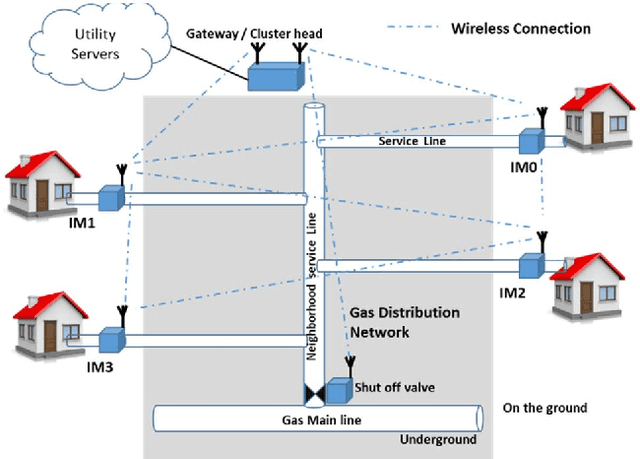
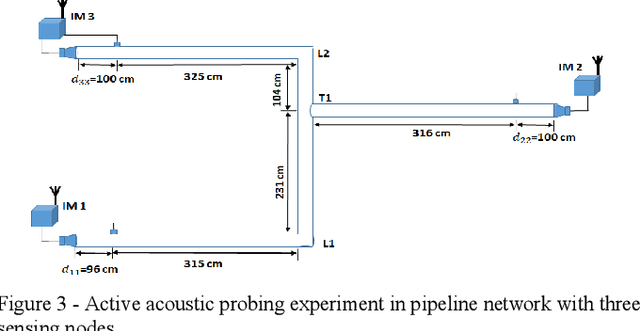
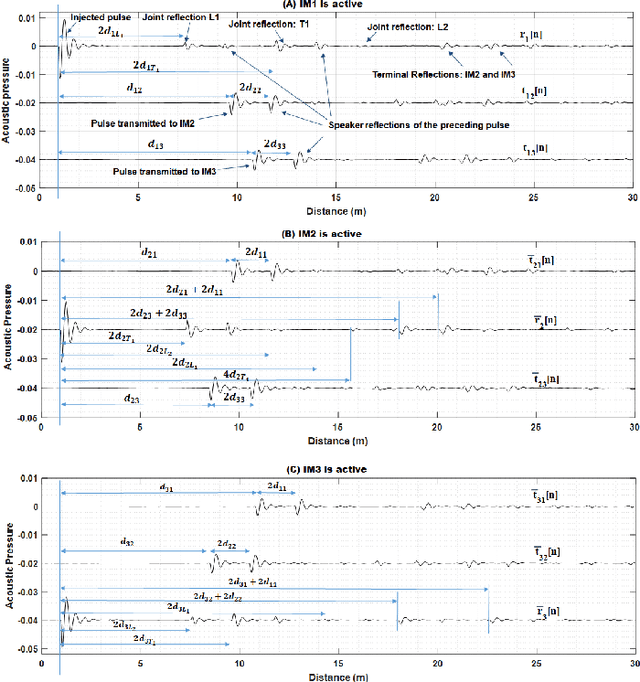
We propose a novel method for monitoring gas distribution networks (GDNs) using intelligent sensor nodes that can be integrated with existing smart gas meters (intelligent meters). The method aims at detecting and locating gas leaks in GDNs in real time. The intelligent meters leverage wireless connectivity in existing smart meters to collaborate in implementing this method, which comprises an active acoustic probing phase and a passive linear imaging phase. In the active acoustic phase, the intelligent meters collaboratively discover the topology of the monitored pipeline network using a novel acoustic pulse reflectometry technique. In the passive linear imaging phase, the intelligent meters use their knowledge of the pipeline network topology to create a linear image of the pipeline using the Time-Exposure Acoustic (TEA) algorithm. The resulting image reveals the presence and locations of active gas leaks in the network. We present the theoretical basis of the method and show results of implementing it on experimental data collected in the lab.
Image Semantic Relation Generation
Oct 19, 2022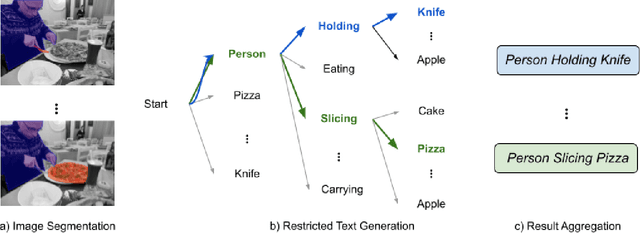


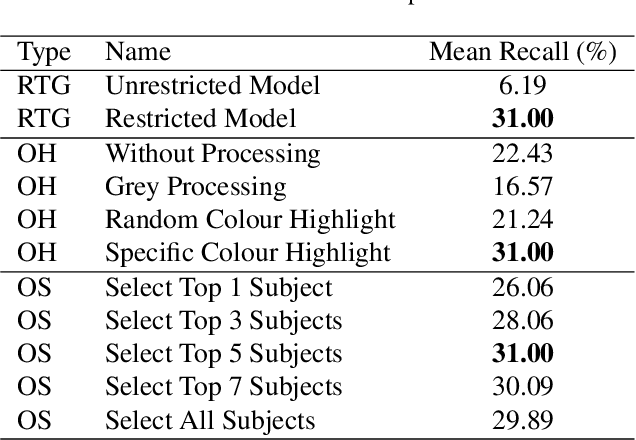
Scene graphs provide structured semantic understanding beyond images. For downstream tasks, such as image retrieval, visual question answering, visual relationship detection, and even autonomous vehicle technology, scene graphs can not only distil complex image information but also correct the bias of visual models using semantic-level relations, which has broad application prospects. However, the heavy labour cost of constructing graph annotations may hinder the application of PSG in practical scenarios. Inspired by the observation that people usually identify the subject and object first and then determine the relationship between them, we proposed to decouple the scene graphs generation task into two sub-tasks: 1) an image segmentation task to pick up the qualified objects. 2) a restricted auto-regressive text generation task to generate the relation between given objects. Therefore, in this work, we introduce image semantic relation generation (ISRG), a simple but effective image-to-text model, which achieved 31 points on the OpenPSG dataset and outperforms strong baselines respectively by 16 points (ResNet-50) and 5 points (CLIP).